

FPGA Hybrid PLB Architecture for Highly Efficient Resource Utilization
-
摘要: 商用现场可编程门阵列(FPGA)普遍采用6输入查找表(LUT)构建可编程逻辑块.而相关实验表明6输入LUT在电路中的应用平均不超过30%,造成了严重的可编程资源浪费。该文在可拆分因子概念基础上将6输入LUT进行不同粒度拆分并进行重新组合,构建出三种新的混合粒度可编程逻辑单元;然后基于混合粒度可编程逻辑单元组合成三种新的混合可编程逻辑块结构用以替换Xilinx的可编程逻辑块;同时提出了一种对映射后网表进行统计的优化评估算法;最后对三种改进结构进行相应实验验证和评估。结果表明:在不增加输入端口资源的情况下,三种混合粒度可编程逻辑块对Xilinx可编程逻辑块结构替换后面积优化平均超过30%;综合PLB使用数量和面积优化来看,可拆分因子N=3时候构建的混合可编程逻辑块结构优化效果最好,在MCNC电路集和VTR电路集下,资源利用率平均分别提高了8.27%和27.64%,有效提升了FPGA的资源利用率。Abstract:
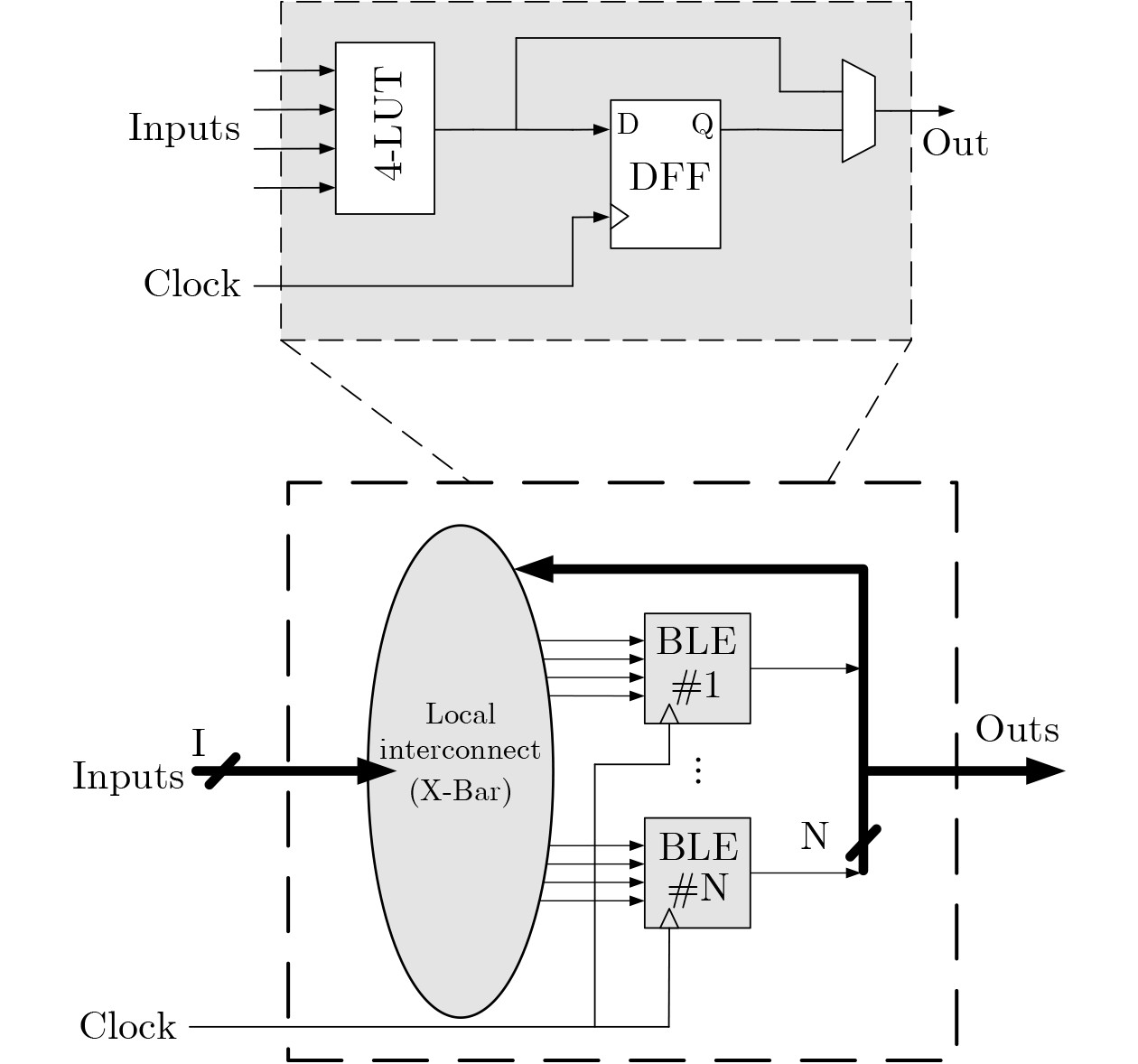
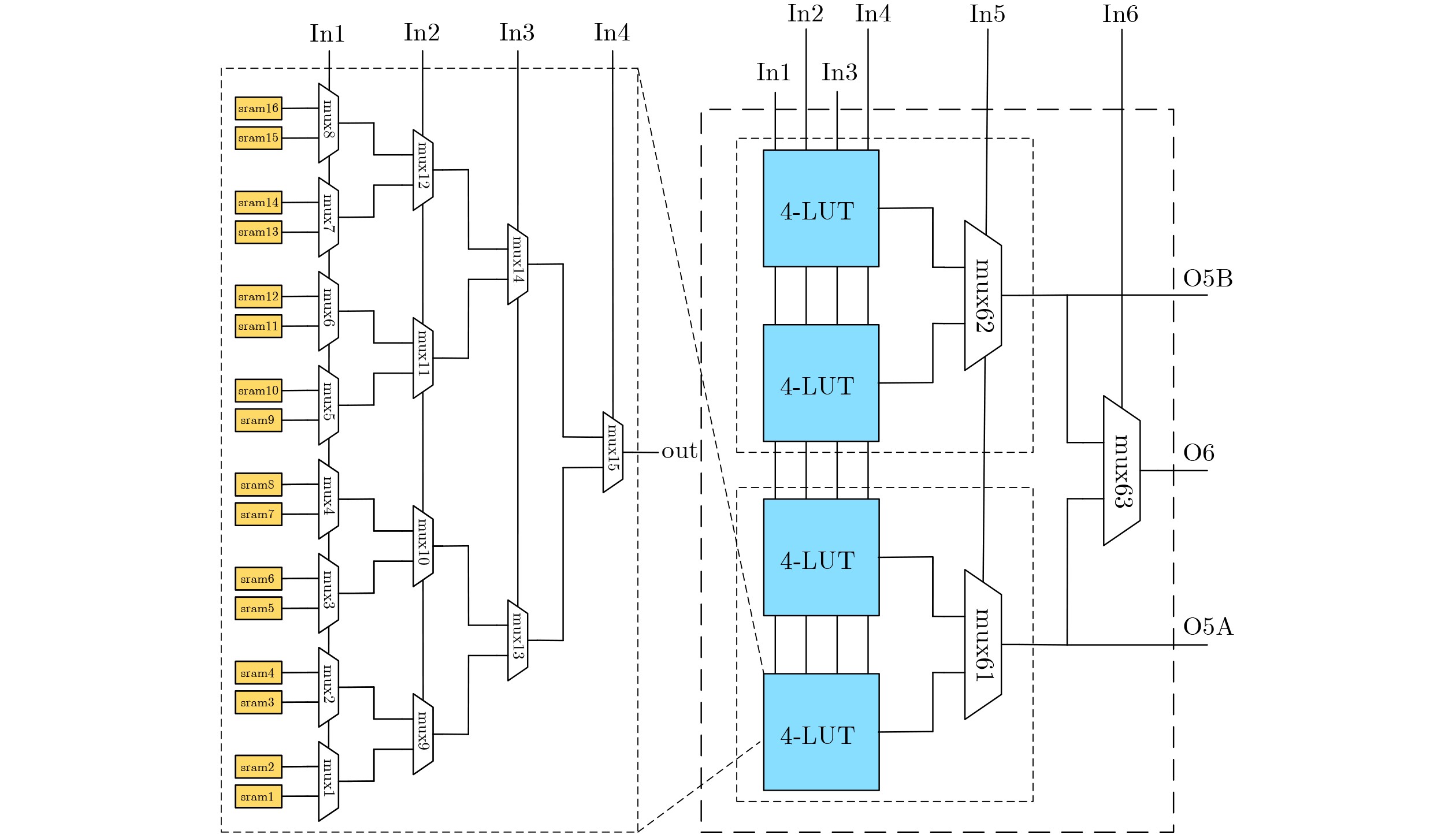
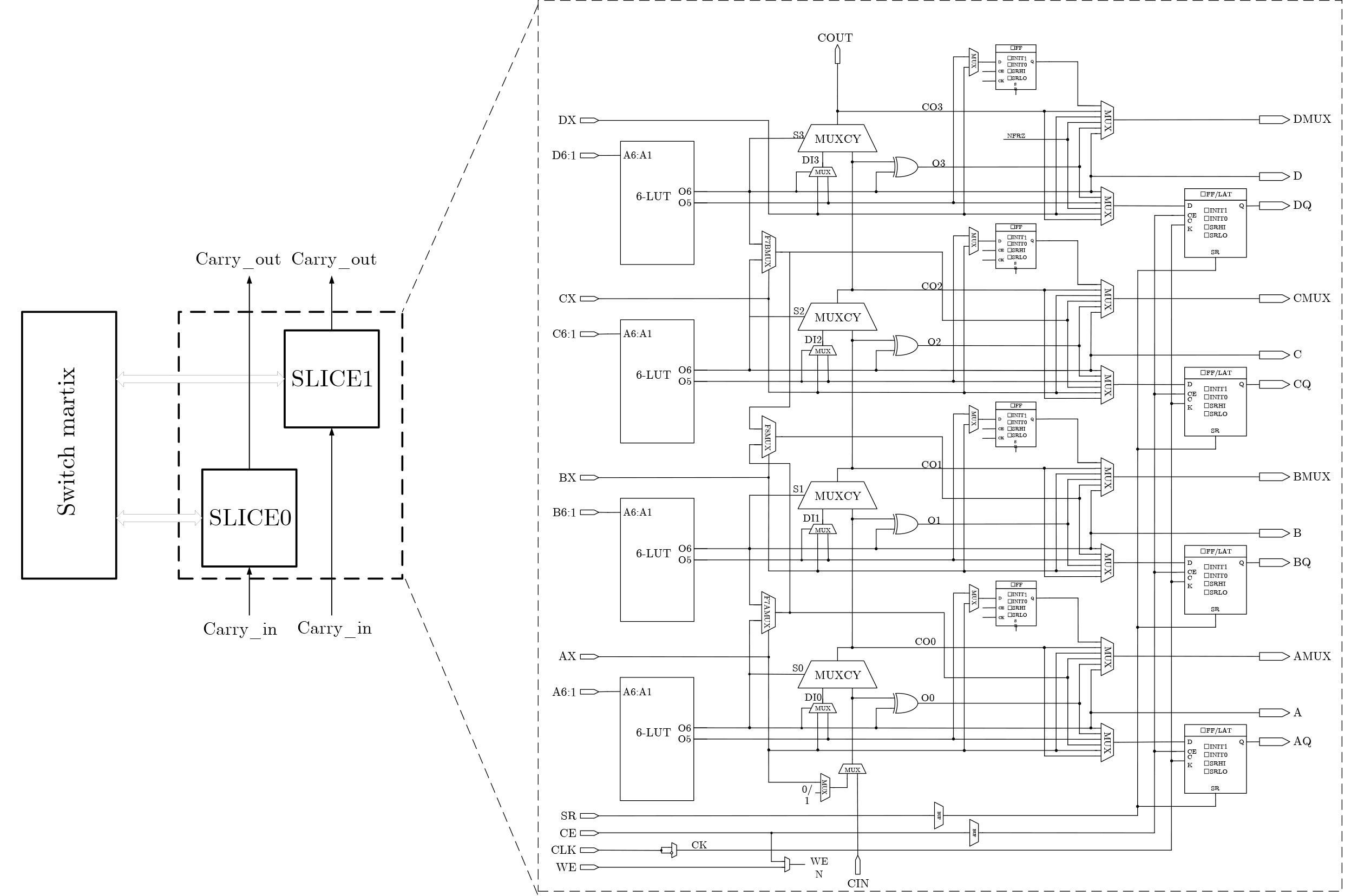
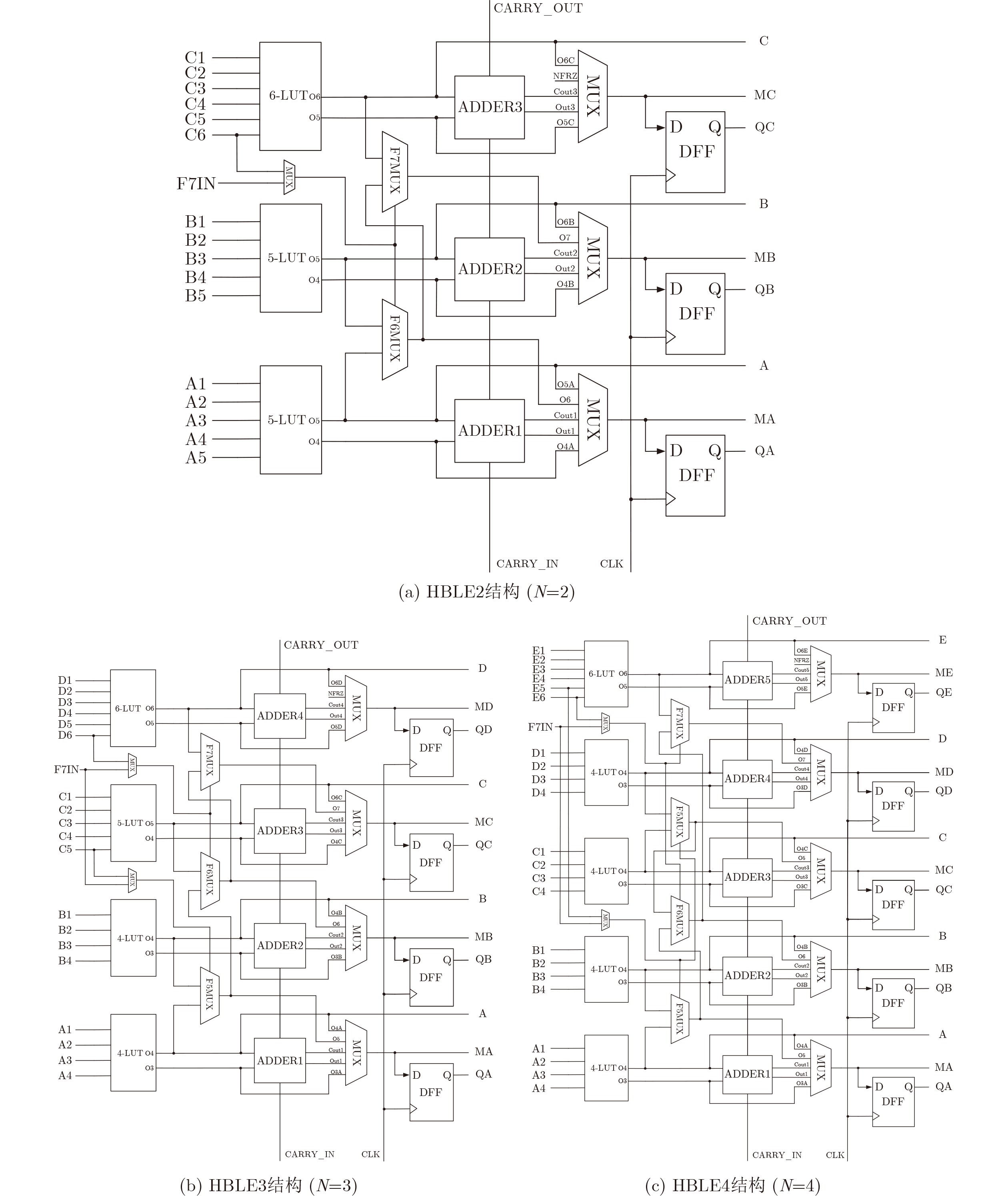
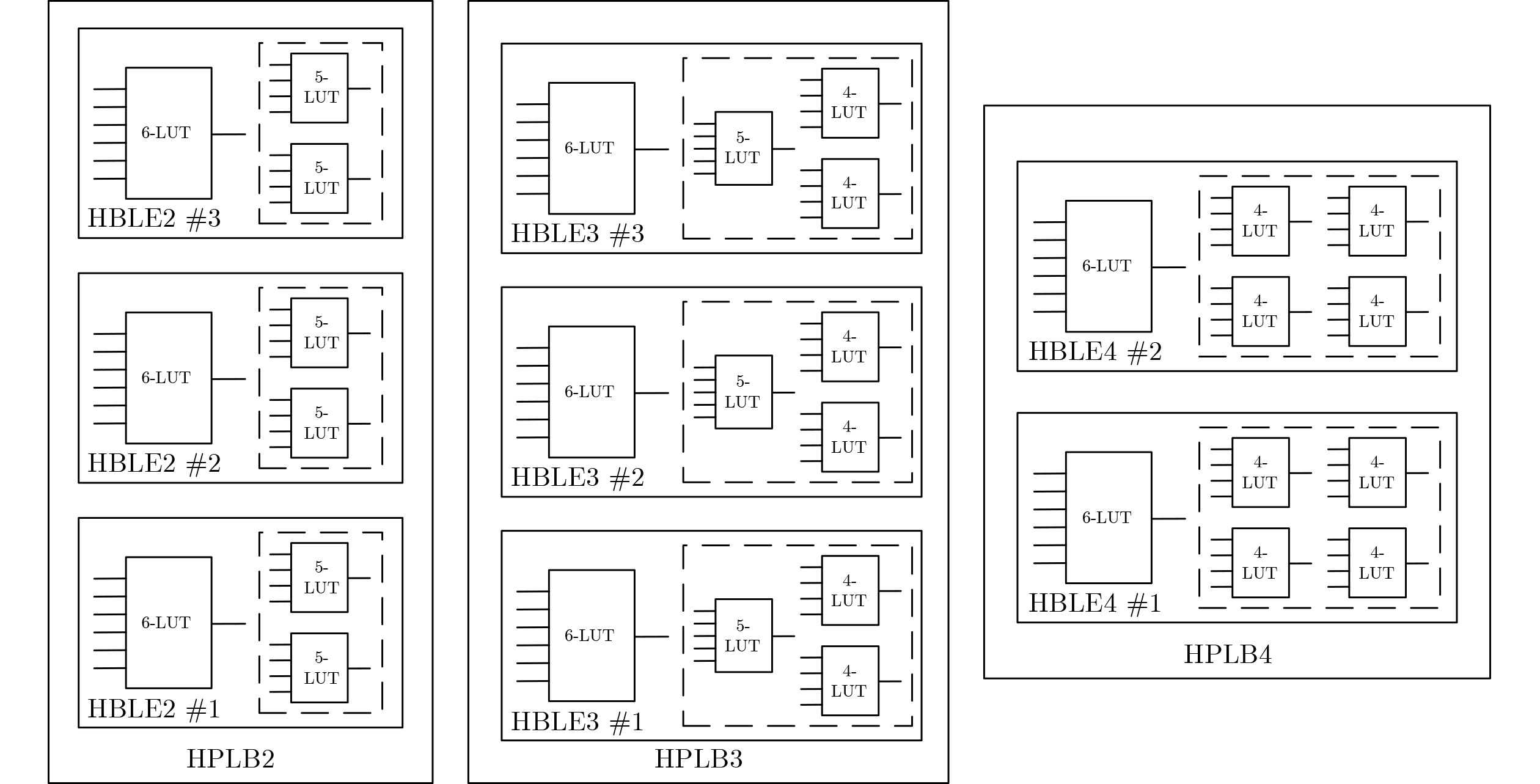
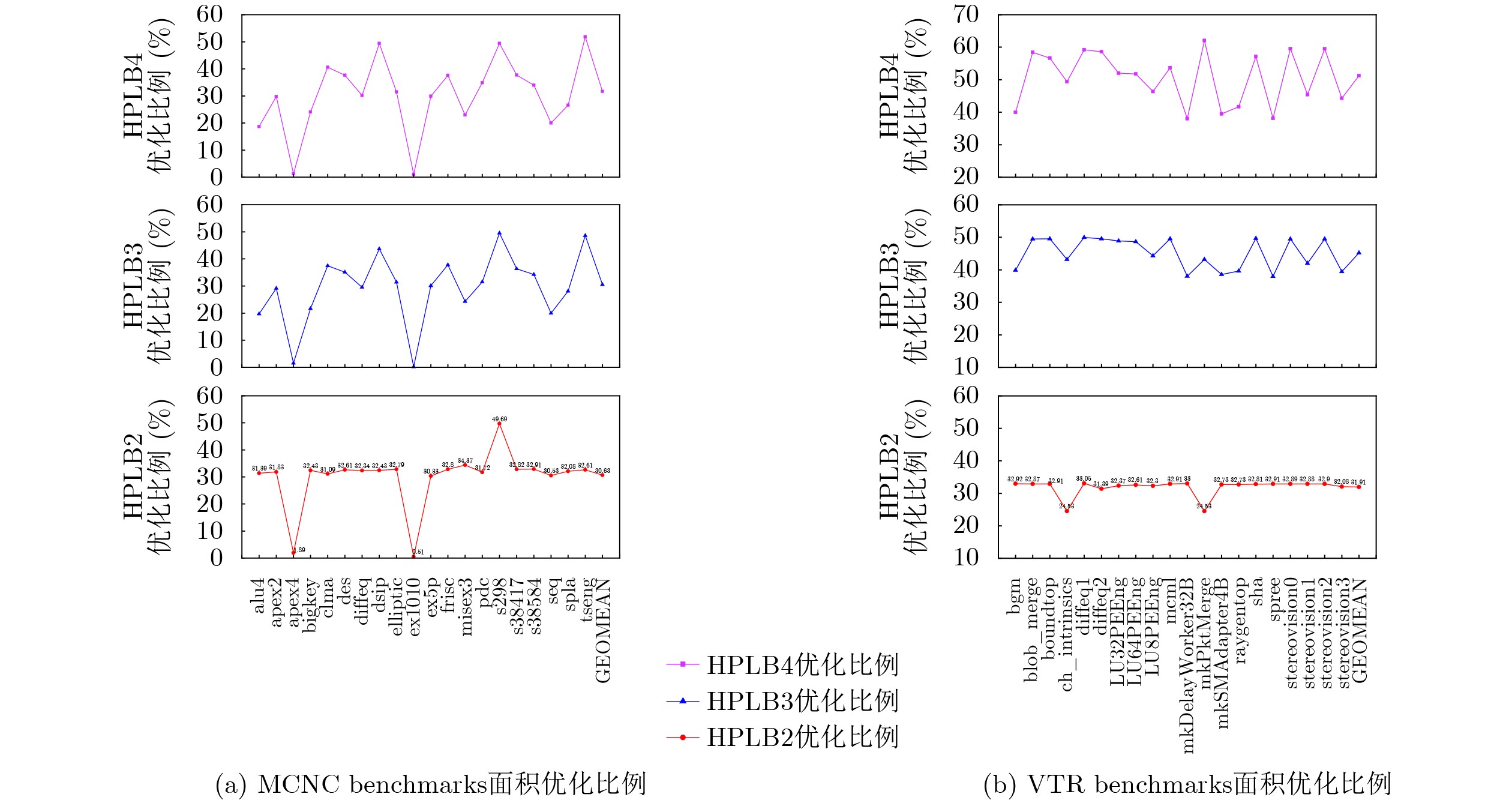
6-input look-up tables (LUTs) are frequently used in commercial Field-Programmable Gate Arrays (FPGAs) to build programmable logic blocks, while related experiments reveal that their average application in circuits is less than 30%, resulting in a significant waste of programmable resources. In this paper, the 6-input LUTs are fractured based on fracturable factors and recombined with different granularities to construct several new Hybrid Basic Logic Elements (HBLE). Based on HBLE, several novel Hybrid Programmable Logic Block (HPLB) architectures are proposed. Then the Programmable Logic Blocks (PLB) of Xilinx is replaced by several innovative HPLB architectures. Concurrently, a statistical evaluation algorithm for the mapped netlist is proposed. Finally, several HPLB architectures are experimentally verified and evaluated as appropriate. Experimental evaluations of the three enhanced architectures show that the HPLBs achieve an average area reduction of more than 30% when compared to Xilinx’s PLBs without adding more input ports. The hybrid HPLB architectures constructed with a fracturable factor N=3 produces the best optimization results when taking into account both HPLB utilization and area optimization. Based on the MCNC and VTR benchmarks, resource consumption increased by an average of 8.27% and 27.64%, respectively, thereby improving FPGA logic efficiency. Objective Currently, modern commercial FPGA architectures employ 6-LUTs as the fundamental building blocks for Basic Logic Elements (BLEs). Only about 30% of the Logic Elements (LEs) in the circuit are ultimately translated to 6-LUTs when mapping 6-LUT BLEs, according to experimental results. Nevertheless, more than half of the logic resources are wasted when 6-LUTs implement functions with inputs smaller than 6. Programmable resources will unavoidably be significantly wasted as a result. A circuit design mapped to 100 4-LUTs can be mapped to 78 6-LUTs during 6-LUT mapping studies, according to experimental data, with the {6,5,4,3,2}-LUT function distribution being {23,32,17,9,13}. The findings indicate that only around 25% of the 6-LUTs are ultimately mapped to 6-input functions, with the remaining 6-LUTs being underutilized. This illustrates even more how inefficient technical mapping is for LUTs with large input K.Methods The fracturable factor N, which is the number of sub-LUTs that may be obtained from a single LUT, characterizes the fracturable and reconfigurable nature of LUT architectures in FPGAs. Motivated by this, we decompose a 6-LUT into several granularities according to the fracturable factor in order to address the previously described problem of low resource utilization. Three novel hybrid-granularity divisible logic (HBLE) structures are created by connecting and reconfiguring the resultant sub-LUTs with additional input ports and multiplexer modules. We shall now investigate how FPGA performance is optimized by these three HBLE topologies. We shall now investigate how FPGA performance is optimized by these three HBLE topologies. One undivided 6-LUT and one divisible 6-LUT, divided into two 5-LUTs with a divisibility factor N=2, make up the HBLE2 structure. One undivided 6-LUT and one divisible 6-LUT, divided into one 5-LUT and two 4-LUTs, with a divisibility factor N=3, are included in the HBLE3 structure. One undivided 6-LUT and one divisible 6-LUT, which divides into four 4-LUTs with a divisibility factor N=4, make up the HBLE4 structure. Adder units are supported by all three HBLE structures, allowing for both latched and direct combinational logic output. Additionally, they allow direct latched output by avoiding combinational logic. A Hybrid Programmable Logic Block (HPLB) is a novel structure created by merging several HBLEs. The MCNC circuit set and the VTR circuit set, the two most well-known academic circuit benchmarks (BMs), are chosen for experimental assessment. A Xilinx Virtex-7 FPGA is used to map each circuit set. The mapped netlist is then used to tally the kinds and numbers of LUTs that were utilized. The minimum number of CLBs needed is found once the data has been arranged using the corresponding greedy algorithms. Since each Xilinx CLB has eight 6-LUTs, the greedy approach uses # Total LUT Number / 8 to determine the smallest number of CLBs needed following BM mapping. In order to guarantee similar conditions, each structure also needs to be sorted using the greedy algorithm after Xilinx’s CLB structure is replaced with the HPLB structure suggested in this research. This results in the bare minimum of HPLBs needed. It is not possible to use every LUT in the mapped CLBs during actual packing owing to routing constraints. As a result, the smallest value that may be achieved in a theoretical optimization scenario is represented by the optimized result that is acquired following greedy algorithm restructuring. Results and Discussions The average number of HPLBs needed for both HPLB2 and HPLB3 structures drops by about 8% when CLB structures are swapped out for HPLBs in order to map the MCNC circuit set. However, the number of HPLBs needed increases by more than 30% on average as a result of the HPLB4 structure. The needed count is smaller when HPLBs are used in place of CLBs for mapping the VTR circuit set. On average, the HPLB2 and HPLB4 counts drop by less than 10%, whereas the HPLB3 count drops by around 30%. This enables SRAM scheduling and complete input pin use. On the other hand, because of resource waste, the uniform CLB structure results in higher CLB requirements when implementing functions with a tiny LUT input K. The HPLB4 structure performs worse than the HPLB3 structure, according to post-mapping HPLB counts. Both the MCNC and VTR circuit sets achieve average area reduction ratios over 30%, according to analysis of post-mapping area optimization. All three HPLB structures attained area optimization ratios of about 31% on the MCNC test set. Different optimization effects were seen in the VTR test circuit set: HPLB2 produced an average area reduction of 30.63%, whereas HPLB4 produced an average decrease of 51.21%. The HPLB2 structure produced a 45.22% area reduction, even though its optimization effect was marginally less than that of HPLB4. A thorough examination of the area optimization results showed that a higher divisibility factor N produces more noticeable benefits for integrating small-scale LUTs in circuits, resulting in higher area reduction ratios from the enhanced architectures. Conclusions In order to solve the issue of low resource utilization in 6-LUTs, this research proposes three split granularity-based HPLB enhancement architectures. In addition to establishing an assessment procedure and matching algorithms for the enhanced structures, these HPLBs take the place of Xilinx’s CLB structure in order to examine the new structure’s benefits in resource utilization. Based on the proportion differences of different LUTs in the post-mapping netlist, evaluation experiments using the MCNC and VTR circuit test suites show that, although HPLB4 achieves significant area optimization, it requires additional HPLBs, resulting in increased interconnect area. While both HPLB2 and HPLB3 structures obtain average area optimizations over 30%, HPLB3 produces a significantly greater HPLB count and area optimization than HPLB2 as the test circuit scale grows. Thus, after replacing the CLB structure, the HPLB3 structure provides a more balanced optimization impact, greatly improving the utilization of programmable resources when taking into account the combined aspects of HPLB usage count and area optimization. -
Key words:
- Field Programmable Gate Array /
- Programmable Logic Block /
- Look-up Table /
- Mapping /
- Fracturable factor
-
表 1 贪心算法优化HPLB2替换Virtex-7 CLB结构后HPLB数量统计
输入:netlist_lut_set:BMs电路映射后网表中统计出来的所有类型LUT对应数量的集合;
lut5_set/lut6_set:netlist_lut中5-LUT/6-LUT的数量;
slut4_set:netlist_lut中K-LUT (K=1,2,3,4)的数量之和;输出:ple:netlist_lut中用贪心算法计算出来的所需的PLE的数目(向上取整); 1: read(netlist_lut_set); 2: stop←max (slut4_set/6,lut5_set/3,lut6_set/3); 3: for ple←1 to stop do 4: x←lut6_set-ple*3; 5: if x≥0 then 6: y←ple*3-x-lut_set5; 7: if y<0 then 8: z←ple*6-x*2+y*2; 9: result←z-slut4; 10: if result≥0 then 11: write(ple); 12: endif 13: else 14: z←ple*6-x*2+y; 15: result←z-slut_set4; 16: if result≥0 then 17: write(ple); 18: else 19: y←ple*3 -x-lut_set5; 20: if y<0 then 21: z←ple*6+y*2; 22: result←z-lut4_set; 23: if result≥0 then 24: write(ple); 25: endif 26: else 27: z←ple*6+y; 28: result←z-slut4_set; 29: if result≥0 then 30: write(ple); 31: endif 32: endif 33: endif 34: endif 35: endif 36: endfor  下载: 导出CSV
下载: 导出CSV
表 2 CLB和HPLB结构对MCNC和VTR电路测试集映射后所需PLB数目
MCNC BM #Xilinx CLB #HPLB2 #HPLB3 #HPLB4 VTR BM #Xilinx CLB #HPLB2 #HPLB3 #HPLB4 alu4 33 30 35 53 bgm 1565 1391 1243 1856 apex2 31 28 29 43 blob_merge 778 692 519 639 apex4 20 26 26 39 boundtop 153 136 102 131 bigkey 86 77 89 129 ch_intrinsics 4 4 3 4 clma 23 21 19 27 diffeq1 62 55 41 50 des 56 50 48 69 diffeq2 33 30 22 27 diffeq 58 52 54 80 LU32PEEng 77 69 52 73 dsip 86 77 64 86 LU64PEEng 84 75 57 80 elliptic 201 179 182 272 LU8PEEng 68 61 50 72 ex1010 22 29 29 43 mcml 6599 5866 4399 6036 ex5p 13 12 12 18 mkDelayWorker32B 303 269 248 371 frisc 219 195 180 270 mkPktMerge 4 4 3 3 misex3 23 20 23 35 mkSMAdapter4B 138 123 112 165 pdc 21 19 19 27 raygentop 138 123 110 159 s298 3 2 2 3 sha 164 146 109 139 s38417 182 162 153 224 spree 72 64 59 88 s38584 243 216 211 317 stereovision0 397 353 265 317 seq 88 81 93 139 stereovision1 2070 1841 1585 2232 spla 20 18 19 29 stereovision2 1181 1050 788 945 tseng 84 75 57 80 stereovision3 10 9 8 11 几何平均值 75.6 68.45 67.2 99.15 几何平均值 695 618.05 488.75 669.9 优化比例 - 8.09% 8.27% -34.97% 优化比例 - 9.78% 27.64% 3.62%
下载: 导出CSV
表 3 三种HPLB结构优化效果及结构特点对比你
架构 BMs 平均HPLB数量优化(%) BMs平均面积优化(%) 结构特点 HPLB2 8.94 31.27 ① HPLB2 Tile端口数量与Xilinx CLB接近
② 面积优化比例超过30%
③ HPLB3数量优化比例不到10%HPLB3 18.53 38.32 ① HPLB数量优化效果最好,接近20%
② 面积优化较高,接近40%
③ HPLB3 Tile端口数量最多HPLB4 –14.05 42.26 ① 面积优化效果最好,超过40%
② 每个HPLB中只包含两个HBLE, Tile端口数量最少
③ HPLB数量增加超过10%
下载: 导出CSV
-
[1] BETZ V, ROSE J, and MARQUARDT A. Architecture and CAD for Deep-Submicron FPGAs[M]. New York: Springer, 1999: 127–150. doi: 10.1007/978-1-4615-5145-4. [2] JIANG Xun, WANG Jiarui, MAI Jing, et al. A robust FPGA router with optimization of high-fanout nets and intra-CLB connections[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2025, 44(3): 1003–1016. doi: 10.1109/TCAD.2024.3447218. [3] DAHIYA S. Area and delay trade offs in fracturable LUT-based FPGA architectures[J]. Journal of Integrated Science and Technology, 2024, 12(2): 733–733. (查阅网上资料, 未找到本条文献信息, 请确认). [4] KUMARI J L V R, KUMAR V K, ABHIGNYA M, et al. Design and performance analysis of configurable logic block (CLB) for FPGA using various circuit topologies[C]. 2024 3rd International Conference for Innovation in Technology (INOCON), Bangalore, India, 2024: 1–5. doi: 10.1109/INOCON60754.2024.10511683. [5] PUN J, DAI X, ZGHEIB G, et al. Double duty: FPGA architecture to enable concurrent LUT and adder chain usage[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2025, 33(2): 412–425. doi: 10.1109/TVLSI.2024.3512345. (查阅网上资料,未找到本条文献信息且doi打不开,请确认). [6] GUO Yi, ZHOU Qilin, CHEN Xiu, et al. High-efficiency FPGA - based approximate multipliers with LUT sharing and carry switching[C]. 2024 Design, Automation & Test in Europe Conference & Exhibition (DATE), Valencia, Spain, 2024: 1–2. doi: 10.23919/DATE58400.2024.10546667. [7] XIE Yanyue, LI Zhengang, DIACONU D, et al. LUTMUL: Exceed conventional FPGA roofline limit by LUT-based efficient multiplication for neural network inference[C]. Proceedings of the 30th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 2024: 713–719. doi: 10.1145/3658617.3697687. [8] Xilinx Inc. 7 series FPGAs configurable logic block[EB/OL]. https://www.xilinx.com/support/documentation/user_guides/ug474_7Series_CLB.pdf, 2016. (查阅网上资料,请核对网址与文献是否相符). [9] HUTTON M, SCHLEICHER J, LEWIS D, et al. Improving FPGA performance and area using an adaptive logic module[C]. Proceedings of the 14th International Conference on Field Programmable Logic and Application, Leuven, Belgium, 2004: 135–144. doi: 10.1007/978-3-540-30117-2_16. [10] 徐宇, 林郁, 江政泓, 等. 拆分粒度对FPGA可拆分逻辑结构性能的影响[J]. 太赫兹科学与电子信息学报, 2017, 15(2): 307–312. doi: 10.11805/TKYDA201702.0307.XU Yu, LIN Yu, JIANG Zhenghong, et al. Influences of fracturable factor on FPGA performance[J]. Journal of Terahertz Science and Electronic Information Technology, 2017, 15(2): 307–312. doi: 10.11805/TKYDA201702.0307. [11] ROSE J, EL GAMAL A, and SANGIOVANNI-VINCENTELLI A. Architecture of field-programmable gate arrays[J]. Proceedings of the IEEE, 1993, 81(7): 1013–1029. doi: 10.1109/5.231340. [12] AHMED E and ROSE J. The effect of LUT and cluster size on deep-submicron FPGA performance and density[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2004, 12(3): 288–298. doi: 10.1109/TVLSI.2004.824300. [13] HE Jianshe. Technology mapping and architecture of heterogeneous field-programmable gate arrays[D]. [Master dissertation], University of Toronto, 1993. [14] CONG J and XU Songjie. Delay-optimal technology mapping for FPGAs with heterogeneous LUTs[C]. Proceedings of the 35th Design and Automation Conference, San Francisco, USA, 1998: 704–707. doi: 10.1145/277044.277221. [15] DAHIYA S. Evaluating the impact of cluster parameters on FPGA performance and density[J]. Journal of Integrated Science and Technology, 2023, 11(3): 520. doi: 10.31083/j.jist1130520. (查阅网上资料,未找到本条文献信息且doi打不开,请确认). [16] SHI Xinyu, YANG Moucheng, LI Zhen, et al. Exploration of FPGA PLB architecture base on LUT and microgates[C]. 2023 International Symposium of Electronics Design Automation (ISEDA), Nanjing, China, 2023: 184–189. doi: 10.1109/ISEDA59274.2023.10218468. [17] SUDHANYA P and JOY VASANTHA RANI S P. Analysis of FPGA architecture with hybrid logic blocks based on ULG and LUT[J]. Journal of Circuits, Systems and Computers, 2025, 34(2): 2550059. doi: 10.1142/S0218126625500598. [18] 高丽江, 杨海钢, 李威, 等. 具有高资源利用率特征的改进型查找表电路结构与优化方法[J]. 电子与信息学报, 2019, 41(10): 2382–2388. doi: 10.11999/JEIT190095.GAO Lijiang, YANG Haigang, LI Wei, et al. A circuit optimization method of improved lookup table for highly efficient resource utilization[J]. Journal of Electronics & Information Technology, 2019, 41(10): 2382–2388. doi: 10.11999/JEIT190095. [19] GARCÍA A. Greedy algorithms: A review and open problems[J]. Journal of Inequalities and Applications, 2025, 2025(1): 11. doi: 10.1186/s13660-025-03254-1. -

 下载:
下载:


图(7) / 表(3)
计量
- 文章访问数: 310
- HTML全文浏览量: 222
- PDF下载量: 15
- 被引次数: 0
