

Spatial Information-guided Diffusion for Domain Adaptation Semantic Segmentation of Remote Sensing Images
-
摘要: 为提高遥感图像域自适应语义分割(DASS)的跨域适应效果,该文提出基于协同训练与空间引导扩散模型的域自适应语义分割框架(CoSG-DASS)。CoSG-DASS使用空间引导扩散模型构成图像翻译减少域间差异,并利用协同训练提升模型对目标域的自适应能力:在图像翻译阶段,设计新型空间信息引导扩散模型,通过向潜在扩散模型注入水平语义分布伪标签与垂直语义分布深度估计重构空间引导信息,实现源域到目标域的语义无偏转换。其中针对伪标签质量问题,提出基于熵的引导强度自适应模块,通过熵值筛选高置信度区域特征以抑制噪声干扰,有效提升跨域成像差异下的语义对齐精度;在协同训练阶段,提出融合深度信息与对抗损失的训练策略,通过增强多维知识表征缩减类内差异并增大类间差异,提升模型的跨域自适应能力。通过在3类典型遥感跨域差异任务(跨地理环境、跨成像模式、标签语义异质)中仿真验证,该文所提CoSG-DASS表现优异,相较于已有方法在平均交并比(mIoU)分别有1.14%, 3.78%和2.49%的提升。Abstract:
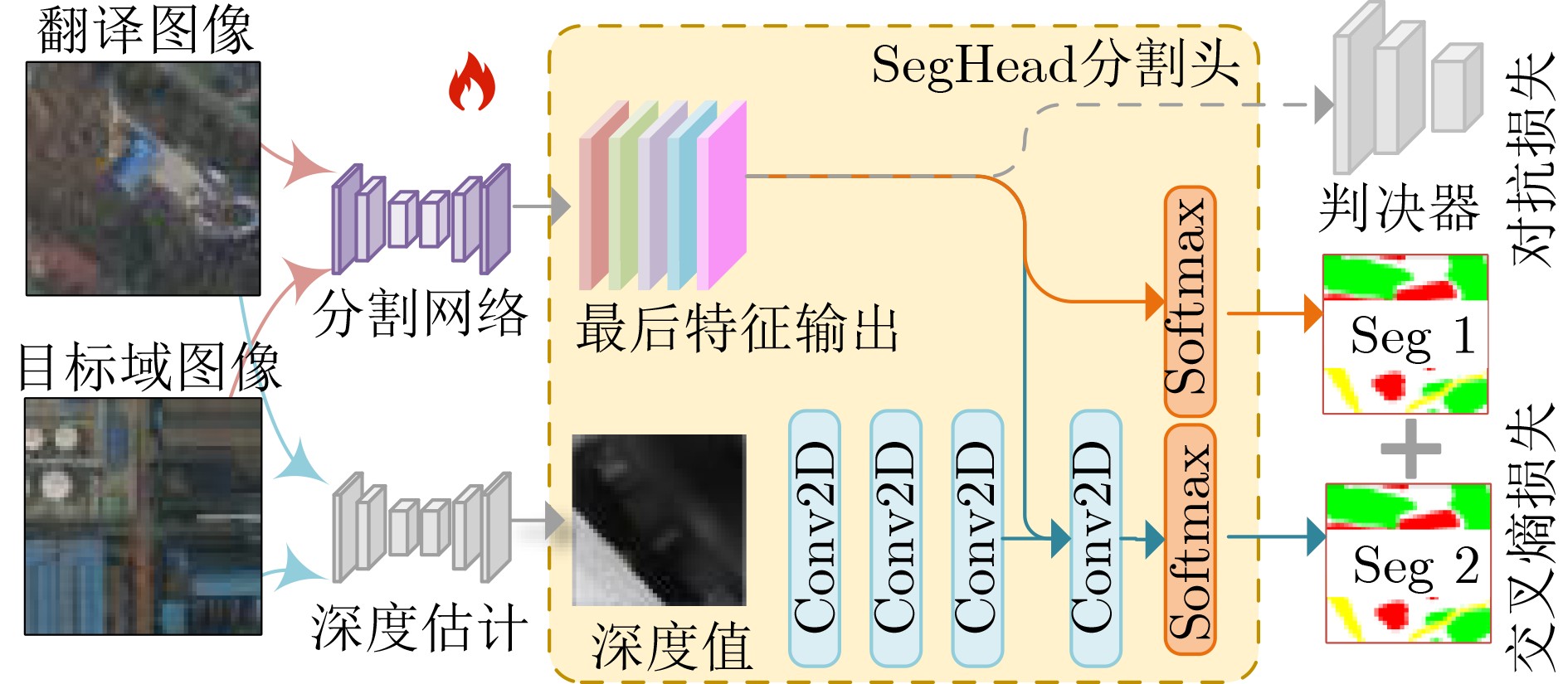
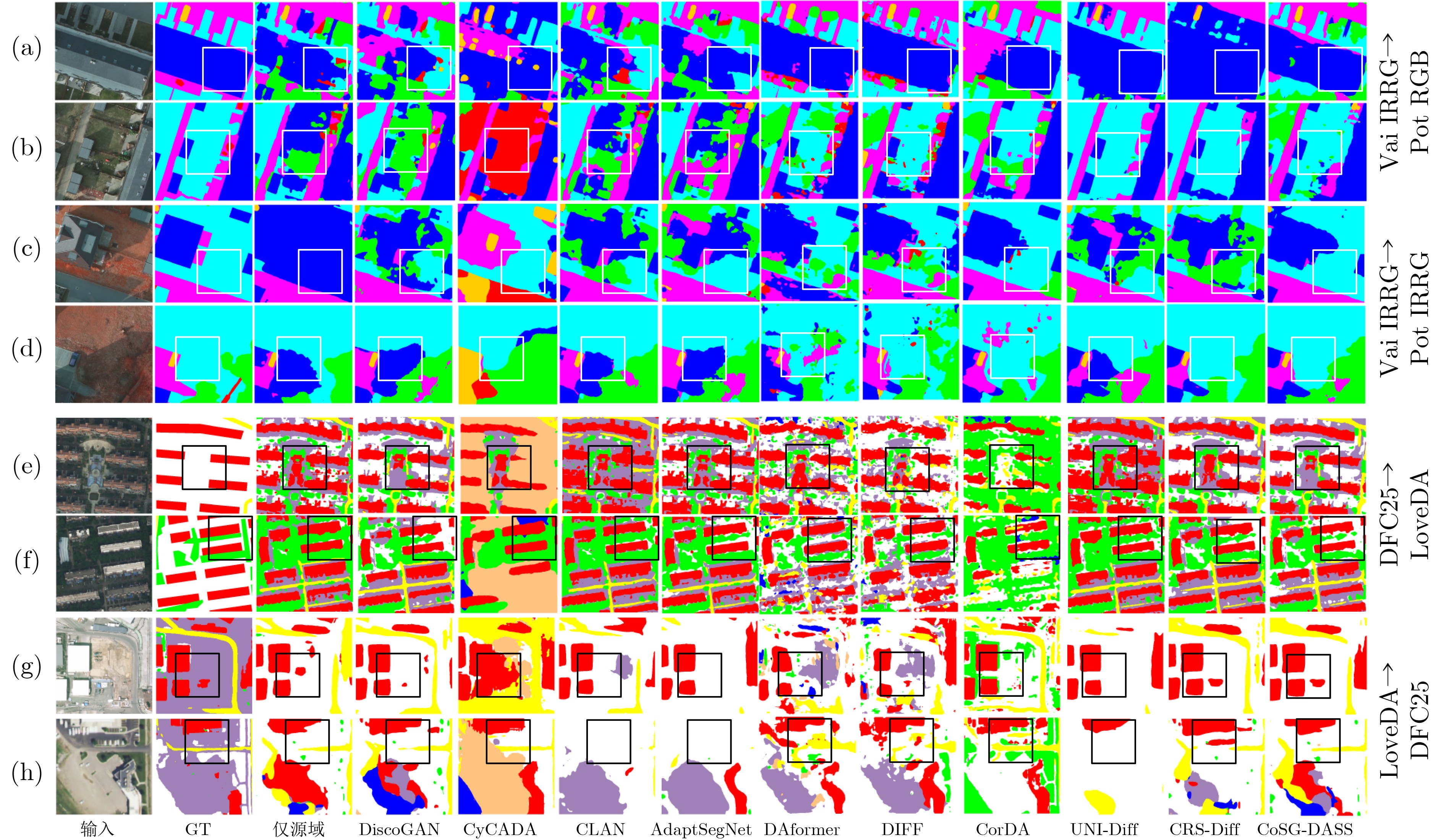
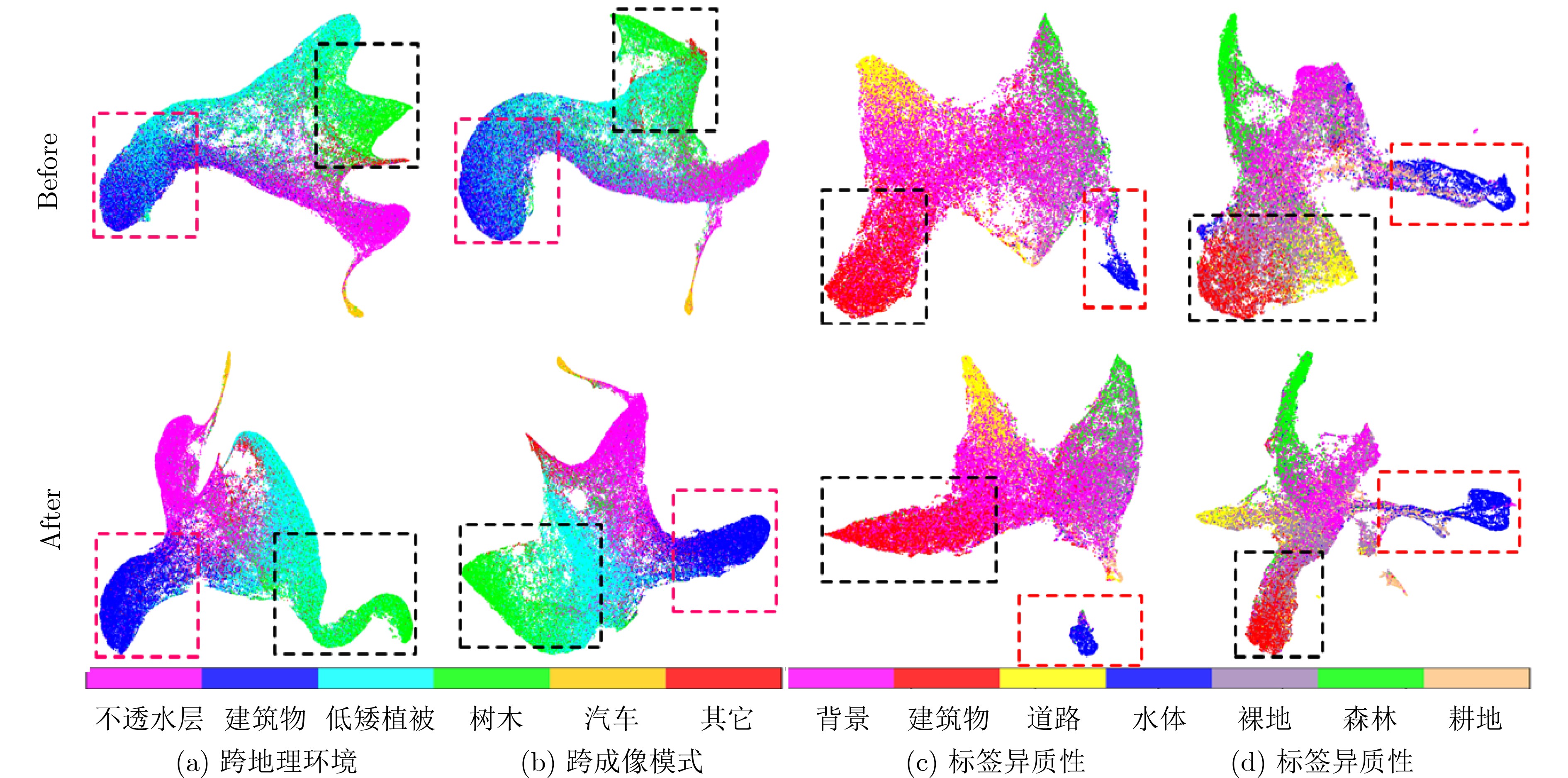
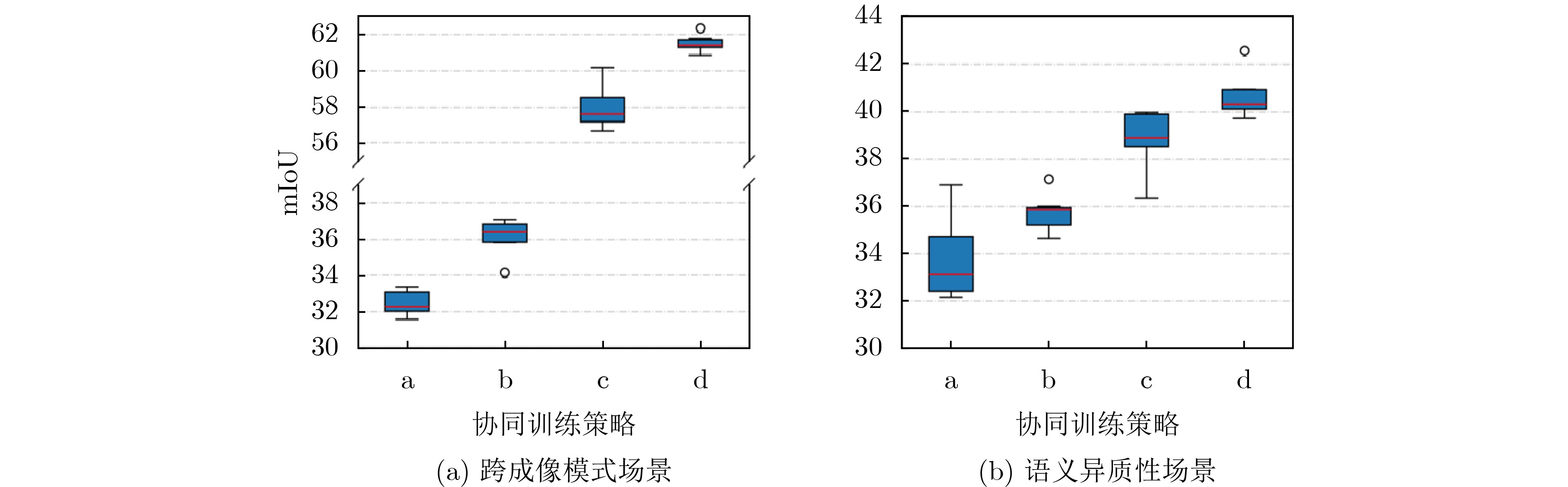
Objective Domain Adaptation Semantic Segmentation (DASS) is critical for remote sensing applications, including land-cover mapping, urban planning, and environmental monitoring. However, deep learning models often show severe performance degradation under domain shifts caused by imaging variation, geographic differences, and label-semantic heterogeneity. Conventional feature-alignment and generative adversarial network-based methods often fail to preserve semantic consistency. They are also sensitive to noisy supervision, especially when cross-domain gaps are large. This work aims to construct a robust DASS framework for semantically consistent image translation and reliable knowledge transfer. Methods A two-stage framework, termed Co-training Spatial-Guided DASS (CoSG-DASS), is proposed by integrating image translation and co-training. In the image-translation stage, a spatial information-guided latent diffusion model enhanced by ControlNet is designed. Semantic pseudo-labels and depth estimates are used as horizontal semantic and vertical spatial conditions to guide target-style image generation. To reduce the effect of noisy pseudo-labels, an Entropy-based Adaptive Guidance Intensity Module (EAGIM) is introduced. EAGIM estimates pixel-level confidence using information entropy and suppresses unreliable features. In the co-training stage, translated target-style images and unlabeled real target-domain images are used to train a segmentation model with a depth-guided segmentation head. Cross-entropy loss and adversarial loss are jointly used for optimization. Results and Discussions Extensive experiments are conducted on three cross-domain tasks. CoSG-DASS generates images that better match target-domain distributions. Quantitative results based on Fréchet Inception Distance (FID) show that the proposed method outperforms CycleGAN, UNI-Diff, and CRS-Diff in most settings ( Table 1 ). Visual comparisons (Fig. 6 ) show that the method reduces edge blurring and category confusion. It also improves the separation of roads and vegetation and preserves small objects, such as vehicles. In the semantic segmentation stage, CoSG-DASS outperforms state-of-the-art domain adaptation methods. It improves mean Intersection over Union (mIoU) by 1.14%, 3.78%, and 2.49% on the cross-geographic task (Vaihingen IRRG→Potsdam IRRG), cross-imaging-mode task (Vaihingen IRRG→Potsdam RGB), and bidirectional label-semantic-heterogeneity tasks between DFC25 and LoveDA, respectively (Tables 2 ~4 ). Visual segmentation results (Fig. 7 ) confirm its strong boundary preservation and high accuracy in complex scenes. Ablation studies (Table 5 ) verify the contribution of the core components, including depth control, pseudo-label guidance, EAGIM, and the co-training strategy. Feature-distribution visualization based on Uniform Manifold Approximation and Projection (UMAP) further shows that CoSG-DASS reduces intra-class variation and increases inter-class separation after adaptation (Fig. 8 ).Conclusions CoSG-DASS alleviates domain shifts in remote sensing images through semantic-preserving diffusion-based translation and depth-guided co-training. It improves both image-translation quality and segmentation accuracy over existing methods. The proposed framework provides an effective solution for multi-source remote sensing interpretation. Future work will focus on extreme label-semantic heterogeneity and lightweight diffusion architectures. -
表 2 跨地理区域场景Vaihingen IRRG(源域)→Potsdam IRRG(目标域)语义分割对比(%)
任务 自适应方法 不透水层 建筑物 低矮植被 树木 汽车 其它 mIoU Vaihingen IRRG ↓
Potsdam IRRG未适应 57.82 44.82 22.18 28.61 69.60 23.31 44.61 仅源域 86.49 90.71 73.70 73.62 74.20 72.01 79.74 CycleGAN[11] 58.01 67.46 38.61 39.19 57.02 22.06 52.06 DiscoGAN[20] 59.08 66.61 44.94 34.78 54.23 16.35 51.93 CyCADA[12] 12.55 29.24 47.38 51.27 3.53 9.83 28.79 CLAN[21] 66.29 72.66 42.72 45.48 67.46 21.44 58.92 FADA[22] 65.73 73.96 43.36 46.72 59.03 19.03 57.76 CorDA[10] 67.39 69.43 54.83 48.67 68.52 9.30 61.77 AdaptSegNet[23] 66.33 70.80 52.03 44.61 70.10 21.80 60.77 DAFormer[24] 68.45 76.18 53.67 49.52 68.93 20.12 62.85 DIFF[25] 67.82 73.54 52.51 49.03 68.21 17.84 62.10 UNI-Diff[14] 69.81 78.73 51.95 50.28 67.84 23.57 63.72 CRS-Diff[15] 67.81 80.45 58.40 50.74 69.44 18.56 65.37 本文(COSG-DASS) 70.27 79.78 54.99 55.70 71.81 21.71 66.51  下载: 导出CSV
下载: 导出CSV
表 3 跨成像模式场景Vaihingen IRRG(源域)→Potsdam RGB(目标域)语义分割对比(%)
任务 自适应方法 不透水层 建筑物 低矮植被 树木 汽车 其它 mIoU Vaihingen IRRG
↓
Potsdam RGB未适应 50.36 43.60 1.81 2.35 69.64 11.89 33.55 仅源域 86.49 90.71 73.70 73.62 74.20 72.01 79.74 CycleGAN[11] 53.80 64.03 32.35 33.05 50.78 17.68 46.80 DiscoGAN[20] 65.08 69.93 49.13 41.16 59.49 18.89 56.92 CyCADA[12] 35.29 42.24 26.51 24.70 6.86 7.82 27.12 CLAN[21] 62.98 71.91 47.51 47.77 66.19 10.91 59.27 FADA[22] 63.99 73.56 37.11 39.57 59.01 15.27 54.65 CorDA[10] 65.93 72.52 51.80 46.47 64.63 15.78 60.27 AdaptSegNet[23] 58.65 65.31 37.95 39.34 69.70 14.34 54.19 DAFormer[24] 63.25 71.38 48.76 46.82 65.74 14.85 58.80 DIFF[25] 64.87 74.06 50.24 47.15 66.82 15.93 59.85 UNI-Diff[14] 60.27 72.63 42.51 45.64 68.67 11.47 57.94 CRS-Diff[15] 59.63 76.01 44.37 43.38 69.41 13.22 58.56 本文(COSG-DASS) 66.80 79.80 50.20 44.78 70.15 6.56 62.34
下载: 导出CSV
表 4 语义异质性场景(DFC25与LoveDA数据集互相迁移)语义分割对比(%)
任务 自适应方法 背景 建筑 道路 水体 裸地/开发区 森林/树木 耕地 mIoU DFC25
↓
LoveDA未适应 24.83 53.47 41.57 64.90 1.13 32.88 18.30 36.46 仅源域 76.15 81.78 68.86 88.50 71.74 83.60 72.91 78.44 CycleGAN[11] 23.19 53.31 43.69 65.50 3.79 32.53 21.85 37.00 DiscoGAN[20] 23.45 50.34 42.72 56.92 1.35 28.57 12.43 33.89↓ CyCADA[12] 26.30 46.72 41.11 52.93 0.78 32.78 14.04 33.43↓ CLAN[21] 26.99 52.08 39.79 68.76 0.77 31.85 15.61 36.71 FADA[22] 24.85 52.41 42.07 61.32 1.14 33.04 18.22 35.81↓ CorDA[10] 37.50 38.77 23.25 63.56 3.32 64.07 7.69 38.41 AdaptSegNet[23] 25.69 52.80 46.38 57.42 1.63 36.33 19.47 36.71 DAFormer[24] 24.97 53.11 48.25 70.12 2.18 34.86 20.35 38.25 DIFF[25] 23.86 52.94 47.53 69.87 1.95 34.22 19.87 37.75 UNI-Diff[14] 21.44 53.07 45.70 70.69 2.36 34.75 20.68 38.00 CRS-Diff[15] 20.86 52.29 46.61 73.46 2.54 35.72 18.23 38.58 本文(COSG-DASS) 25.82 53.24 49.67 71.64 1.27 33.94 20.46 39.26 LoveDA
↓
DFC25未适应 22.28 48.03 37.42 45.85 9.13 47.57 3.43 35.05 仅源域 40.42 63.82 61.46 71.09 33.08 43.99 43.17 52.31 CycleGAN[11] 22.07 53.48 29.43 58.74 4.95 29.17 8.69 32.97↓ DiscoGAN[20] 24.10 48.54 30.85 55.80 6.20 52.43 5.16 36.32 CyCADA[12] 21.60 50.31 32.12 39.50 4.05 49.37 6.99 32.82↓ CLAN[21] 22.24 49.10 33.25 41.58 6.26 46.73 11.66 33.19↓ FADA[22] 28.23 48.40 32.32 53.69 4.61 45.78 10.64 35.50 CorDA[10] 24.07 39.07 31.09 49.78 7.74 22.77 26.23 29.09↓ AdaptSegNet[23] 21.59 47.48 29.72 51.83 11.05 54.99 6.21 36.11 DAFormer[24] 30.08 49.82 33.56 65.43 5.17 59.04 11.3 39.2 DIFF[25] 29.54 48.76 32.18 64.05 3.82 58.47 10.68 38.5 UNI-Diff[14] 29.22 48.27 31.03 63.32 2.63 58.32 3.22 38.80 CRS-Diff[15] 30.63 50.65 31.01 60.90 5.04 59.62 10.57 39.64 本文(COSG-DASS) 31.55 50.19 35.47 70.07 6.20 59.32 14.40 42.13
下载: 导出CSV
表 5 全局模块消融实验
任务 基线 深度控制 伪标签 EAGIM 协同
训练mIoU
(%)增量(%) Vaihingen
IRRG
↓
Potsdam
RGB√ 33.55 - √ √ 55.64 22.09 √ √ 50.16 16.61 √ √ √ √ 58.23 24.68 √ √ 35.76 0.21 √ √ √ √ √ 62.34 28.8 DFC25
↓
LoveDA√ 36.46 - √ √ 37.73 1.27 √ √ 37.19 0.73 √ √ √ √ 38.76 2.30 √ √ 37.36 0.90 √ √ √ √ √ 39.26 2.80
下载: 导出CSV
表 6 EAGIM系数对模型精度mIoU的影响(%)
EAGIM系数 跨地理区域 跨成像模式 标签语义异质 0.3 64.86 60.12 37.06 0.5 66.51 62.08 42.13 0.7 65.72 60.65 41.95 0.9 65.13 59.43 39.63
下载: 导出CSV
表 7 $ {\lambda }_{\text{adv}} $参数对模型精度mIoU影响实验(%)
$ {\lambda }_{\text{adv}} $ 0.05 0.10 0.15 0.20 0.50 VIR→PR 62.20 62.34 62.33 61.31 61.74 VIR→PIR 66.34 66.51 65.56 64.17 63.12 D→L 39.65 39.26 39.11 39.07 39.12 L→D 41.15 42.13 42.14 40.42 39.07
下载: 导出CSV
-
[1] 宋淼, 陈志强, 王培松, 等. DetDiffRS: 面向细节优化的遥感图像超分辨率扩散模型[J]. 电子与信息学报, 2025, 47(12): 4763–4778. doi: 10.11999/JEIT250995.SONG Miao, CHEN Zhiqiang, WANG Peisong, et al. DetDiffRS: A detail-enhanced diffusion model for remote sensing image super-resolution[J]. Journal of Electronics & Information Technology, 2025, 47(12): 4763–4778. doi: 10.11999/JEIT250995. [2] 刁文辉, 龚铄, 辛林霖, 等. 针对多模态遥感数据的自监督策略模型预训练方法[J]. 电子与信息学报, 2025, 47(6): 1658–1668. doi: 10.11999/JEIT241016.DIAO Wenhui, GONG Shuo, XIN Linlin, et al. A model pre-training method with self-supervised strategies for multimodal remote sensing data[J]. Journal of Electronics & Information Technology, 2025, 47(6): 1658–1668. doi: 10.11999/JEIT241016. [3] 余翔, 庞志濠. 融合FEB的YOLOX遥感图像目标检测算法[J]. 重庆邮电大学学报: 自然科学版, 2024, 36(2): 319–327. doi: 10.3979/j.issn.1673-825X.202302120032.YU Xiang and PANG Zhihao. YOLOX remote sensing image object detection algorithm based on FEB[J]. Journal of Chongqing University of Posts and Telecommunications: Natural Science Edition, 2024, 36(2): 319–327. doi: 10.3979/j.issn.1673-825X.202302120032. [4] 厉行, 樊养余, 郭哲, 等. 基于边缘领域自适应的立体匹配算法[J]. 电子与信息学报, 2024, 46(7): 2970–2980. doi: 10.11999/JEIT231113.LI Xing, FAN Yangyu, GUO Zhe, et al. Edge domain adaptation for stereo matching[J]. Journal of Electronics & Information Technology, 2024, 46(7): 2970–2980. doi: 10.11999/JEIT231113. [5] TEE Y Y, HONG Xuenong, CHENG Deruo, et al. Unsupervised domain adaptation with pseudo shape supervision for IC image segmentation[C]. 2024 IEEE International Symposium on the Physical and Failure Analysis of Integrated Circuits (IPFA), Singapore, Singapore, 2024: 1–6. doi: 10.1109/IPFA61654.2024.10690992. [6] HOFFMAN J, WANG Dequan, YU F, et al. FCNs in the wild: Pixel-level adversarial and constraint-based adaptation[EB/OL]. https://arxiv.org/abs/1612.02649, 2016. [7] VU T H, JAIN H, BUCHER M, et al. ADVENT: Adversarial entropy minimization for domain adaptation in semantic segmentation[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 2512–2521. doi: 10.1109/CVPR.2019.00262. [8] ZOU Yang, YU Zhiding, VIJAYA KUMAR B V K, et al. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training[C]. 15th European Conference on Computer Vision, Munich, Germany, 2018: 297–313. doi: 10.1007/978-3-030-01219-9_18. [9] VU T H, JAIN H, BUCHER M, et al. DADA: Depth-aware domain adaptation in semantic segmentation[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 2019: 7363–7372. doi: 10.1109/ICCV.2019.00746. [10] WANG Qin, DAI Dengxin, HOYER L, et al. Domain adaptive semantic segmentation with self-supervised depth estimation[C]. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 8495–8505. doi: 10.1109/ICCV48922.2021.00840. [11] ZHU Junyan, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]. 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 2242–2251. doi: 10.1109/ICCV.2017.244. [12] HOFFMAN J, TZENG E, PARK T, et al. CyCADA: Cycle-consistent adversarial domain adaptation[C]. 35th International Conference on Machine Learning, Stockholm, Sweden, 2018: 1989–1998. [13] ZHANG Lvmin, RAO Anyi, and AGRAWALA M. Adding conditional control to text-to-image diffusion models[C]. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 3813–3824. doi: 10.1109/ICCV51070.2023.00355. [14] DONG Xiao, HUANG Runhui, WEI Xiaoyong, et al. UniDiff: Advancing vision-language models with generative and discriminative learning[EB/OL]. https://arxiv.org/abs/2306.00813, 2023. [15] TANG Datao, CAO Xiangyong, HOU Xingsong, et al. CRS-Diff: Controllable remote sensing image generation with diffusion model[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5638714. doi: 10.1109/TGRS.2024.3453414. [16] KINGMA D P and WELLING M. Auto-encoding variational Bayes[EB/OL]. https://arxiv.org/abs/1312.6114v11, 2022. [17] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]. 38th International Conference on Machine Learning, 2021: 8748–8763. [18] PARK T, LIU Mingyu, WANG Tingchun, et al. Semantic image synthesis with spatially-adaptive normalization[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 2332–2341. doi: 10.1109/CVPR.2019.00244. [19] 梁燕, 易春霞, 王光宇, 等. 基于多尺度语义编解码网络的遥感图像语义分割[J]. 电子学报, 2023, 51(11): 3199–3214. doi: 10.12263/DZXB.20220503.LIANG Yan, YI Chunxia, WANG Guangyu, et al. Semantic segmentation of remote sensing image based on multi-scale semantic encoder-decoder network[J]. Acta Electronica Sinica, 2023, 51(11): 3199–3214. doi: 10.12263/DZXB.20220503. [20] ZHANG Xiaoke, HU Zongsheng, ZHANG Guoliang, et al. Dose calculation in proton therapy using a discovery cross-domain generative adversarial network (DiscoGAN)[J]. Medical Physics, 2021, 48(5): 2646–2660. doi: 10.1002/mp.14781. [21] LUO Yawei, ZHENG Liang, GUAN Tao, et al. Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 2502–2511. doi: 10.1109/CVPR.2019.00261. [22] XU Tao, SUN Xian, DIAO Wenhui, et al. FADA: Feature aligned domain adaptive object detection in remote sensing imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5617916. doi: 10.1109/TGRS.2022.3147224. [23] TSAI Y H, HUNG W C, SCHULTER S, et al. Learning to adapt structured output space for semantic segmentation[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7472–7481. doi: 10.1109/CVPR.2018.00780. [24] HOYER L, DAI Dengxin, and VAN GOOL L. DAFormer: Improving network architectures and training strategies for domain-adaptive semantic segmentation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 9914–9925. doi: 10.1109/CVPR52688.2022.00969. [25] JI Yuxiang, HE Boyong, QU Chenyuan, et al. Diffusion features to bridge domain gap for semantic segmentation[C]. 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 2025: 1–5. doi: 10.1109/ICASSP49660.2025.10888537. [26] WANG Libo, LI Rui, ZHANG Ce, et al. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 190: 196–214. doi: 10.1016/j.isprsjprs.2022.06.008. [27] 梁燕, 杨会林, 邵凯. 自适应特征选择的车路协同3D目标检测方案[J]. 电子与信息学报, 2025, 47(12): 5214–5225. doi: 10.11999/JEIT250601.LIANG Yan, YANG Huilin, and SHAO Kai. A vehicle-infrastructure cooperative 3D object detection scheme based on adaptive feature selection[J]. Journal of Electronics & Information Technology, 2025, 47(12): 5214–5225. doi: 10.11999/JEIT250601. -

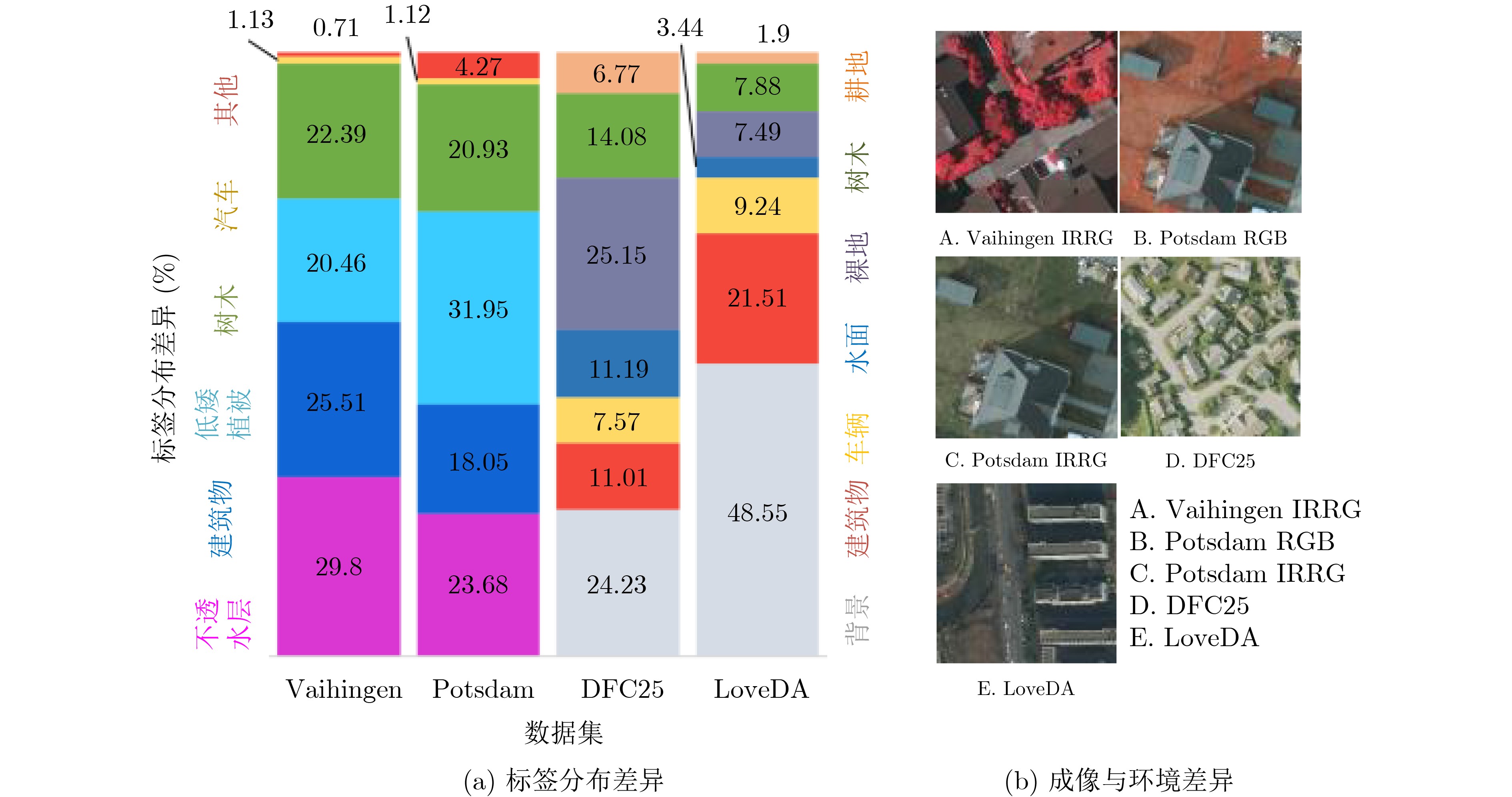
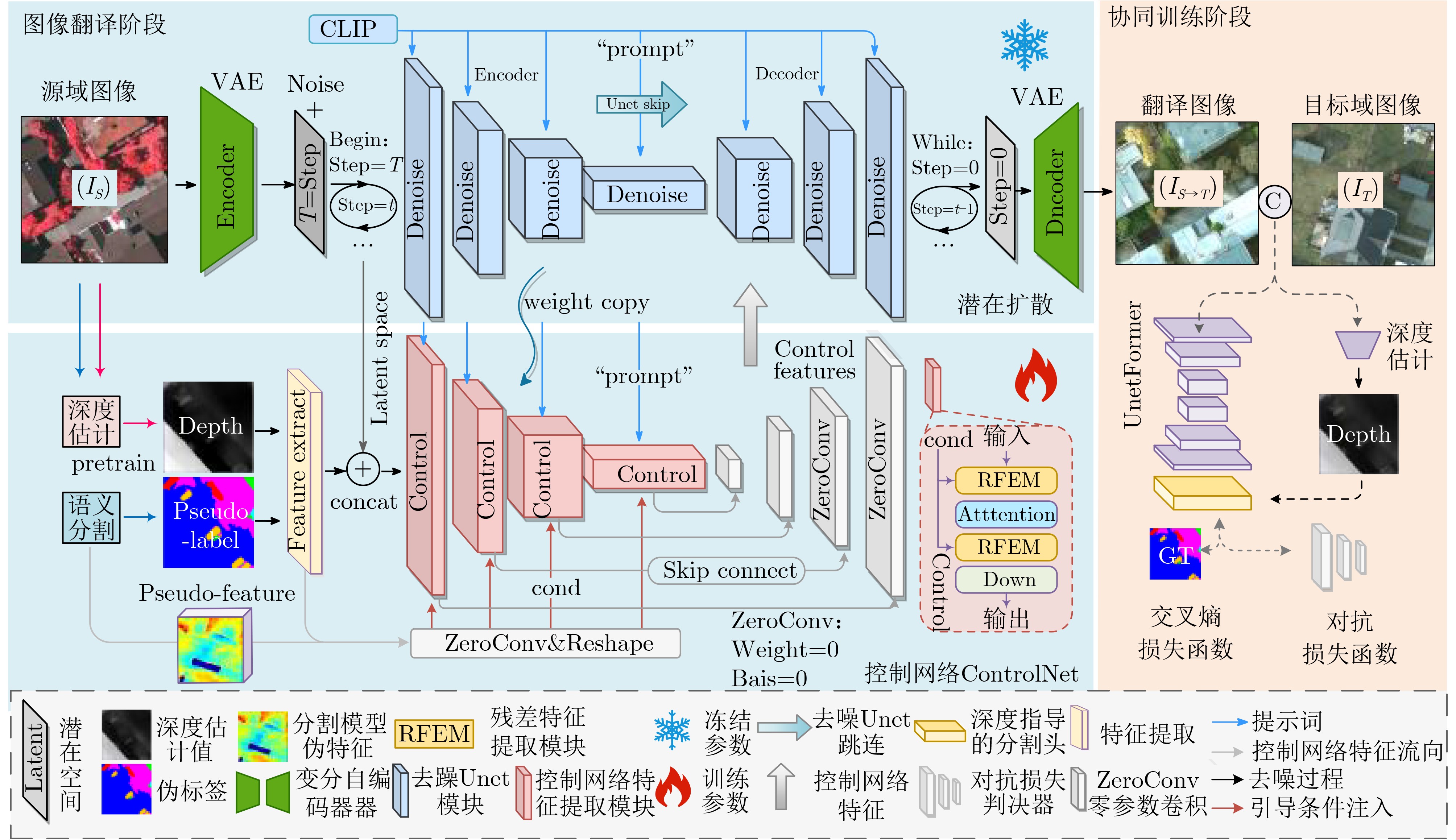
 下载:
下载:
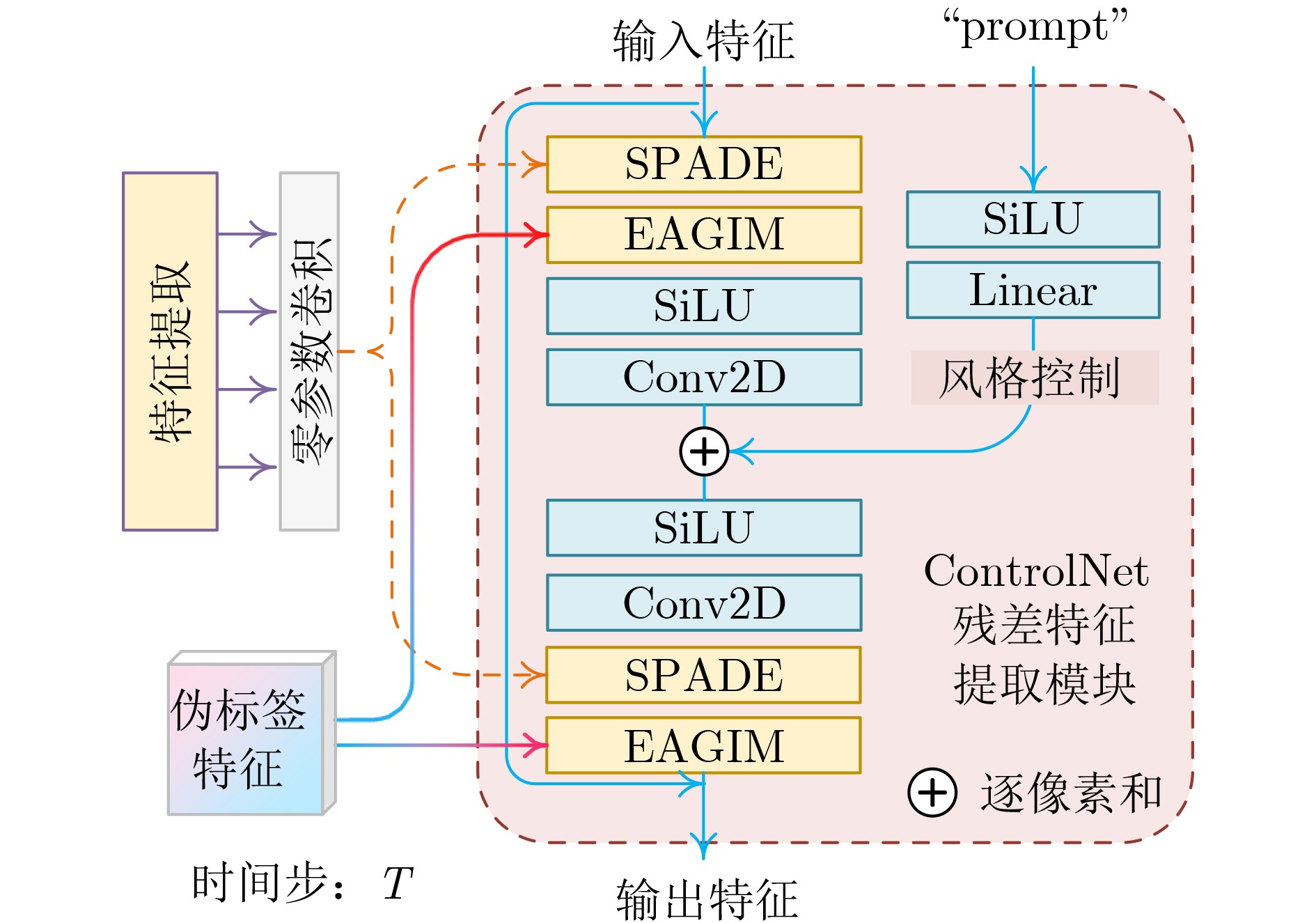
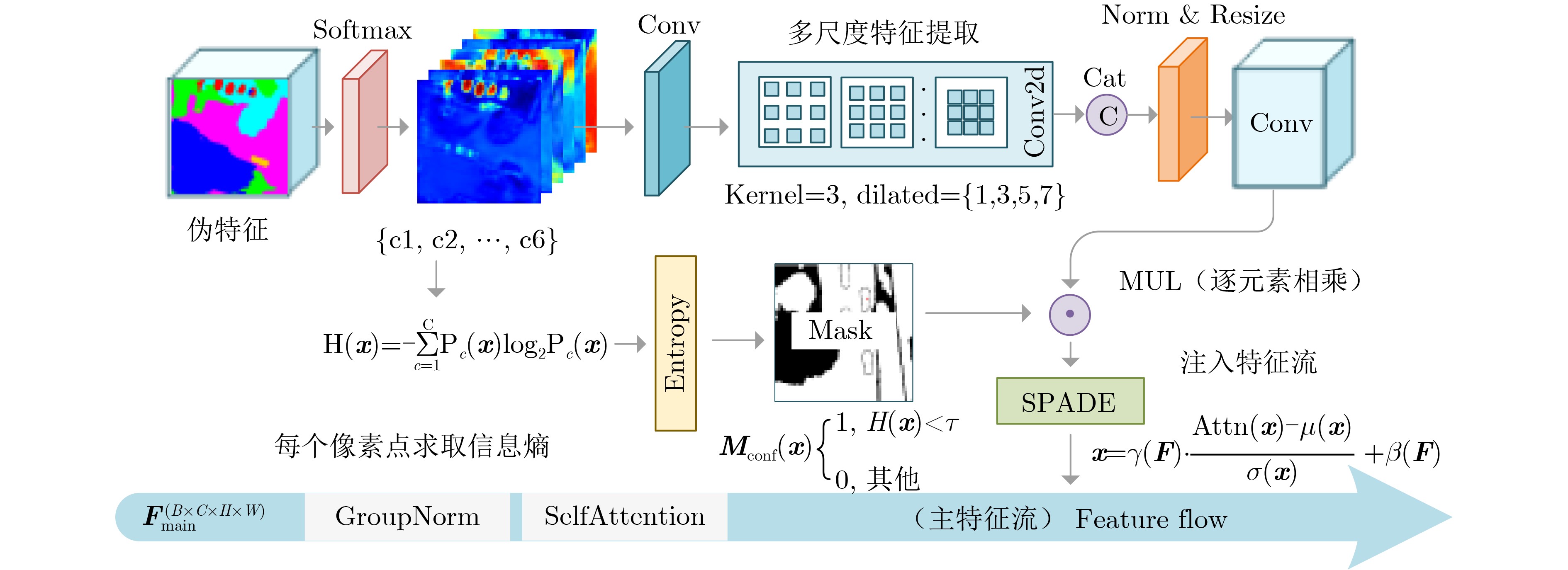



图(9) / 表(7)
计量
- 文章访问数: 355
- HTML全文浏览量: 141
- PDF下载量: 42
- 被引次数: 0
