

Design and Verification of Robust Modulation Recognition Framework Under Blind Adversarial Attacks
-
摘要: 针对对抗性攻击下深度学习调制识别模型鲁棒性不足且现有防御方法依赖攻击先验、计算开销大的问题,本文提出一种盲对抗性攻击下的稳健调制识别框架。首先,特征净化自编码器从信号特征中提取高维流形结构,并在瓶颈层创新性地引入动态净化机制,通过基于统计特征的自适应阈值与Top-K稀疏化操作,精准识别并抑制由对抗扰动引起的异常特征激活,最后利用解码器将净化后的特征重构为逼近干净信号的表征。目标函数依次引入重构损失、特征稀疏性约束与语义一致性损失,确保净化后信号在结构与语义上均贴近干净样本。实验结果表明,在包含12种调制类型的仿真数据集上,所提框架在面对有/无目标下的白盒攻击与黑盒攻击时,能将调制识别准确率分别提升至83.2%/85.7%与86.1%/89.3%,验证了其在盲对抗性攻击场景下的有效性与稳健性。Abstract:
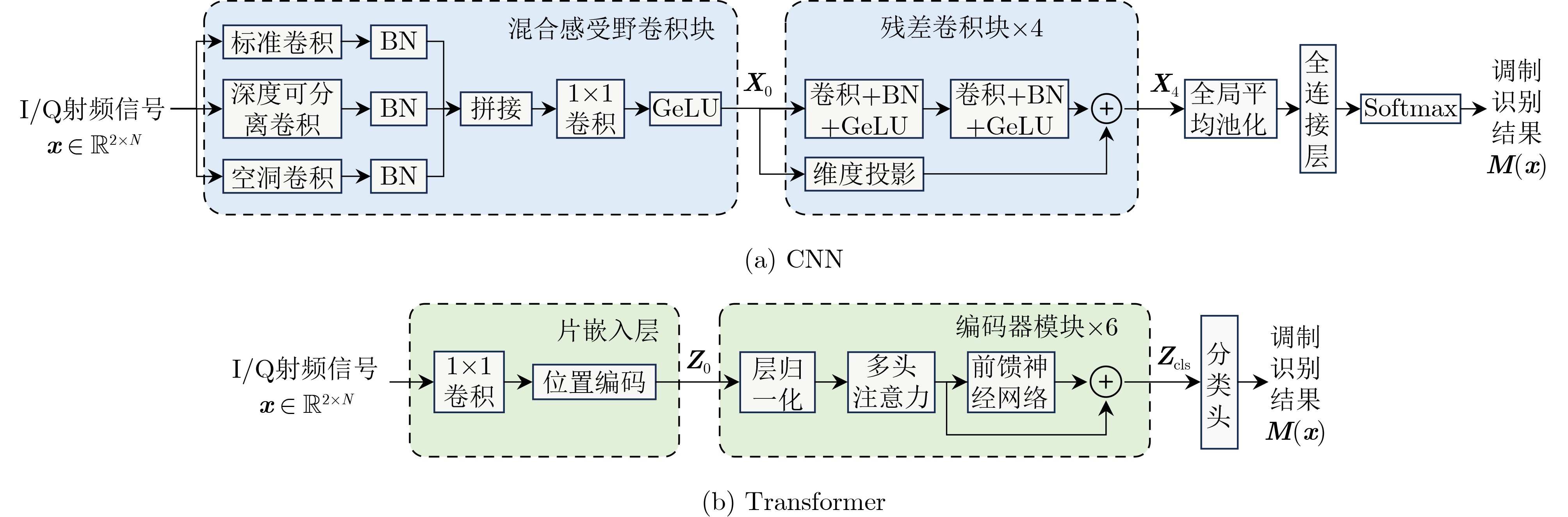
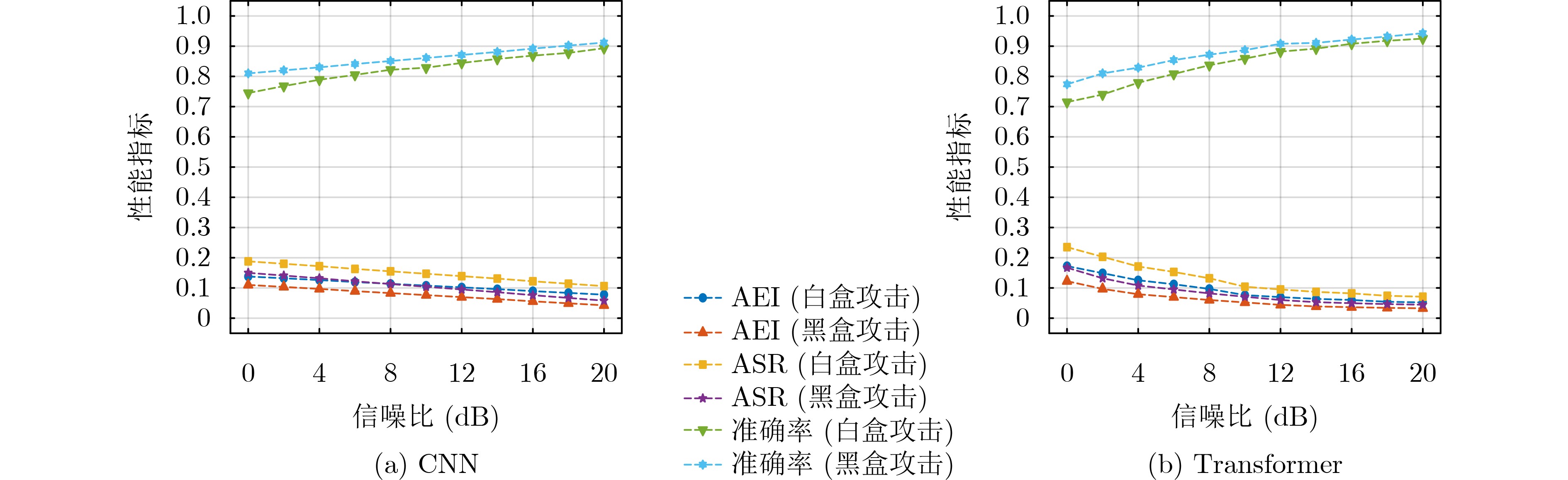
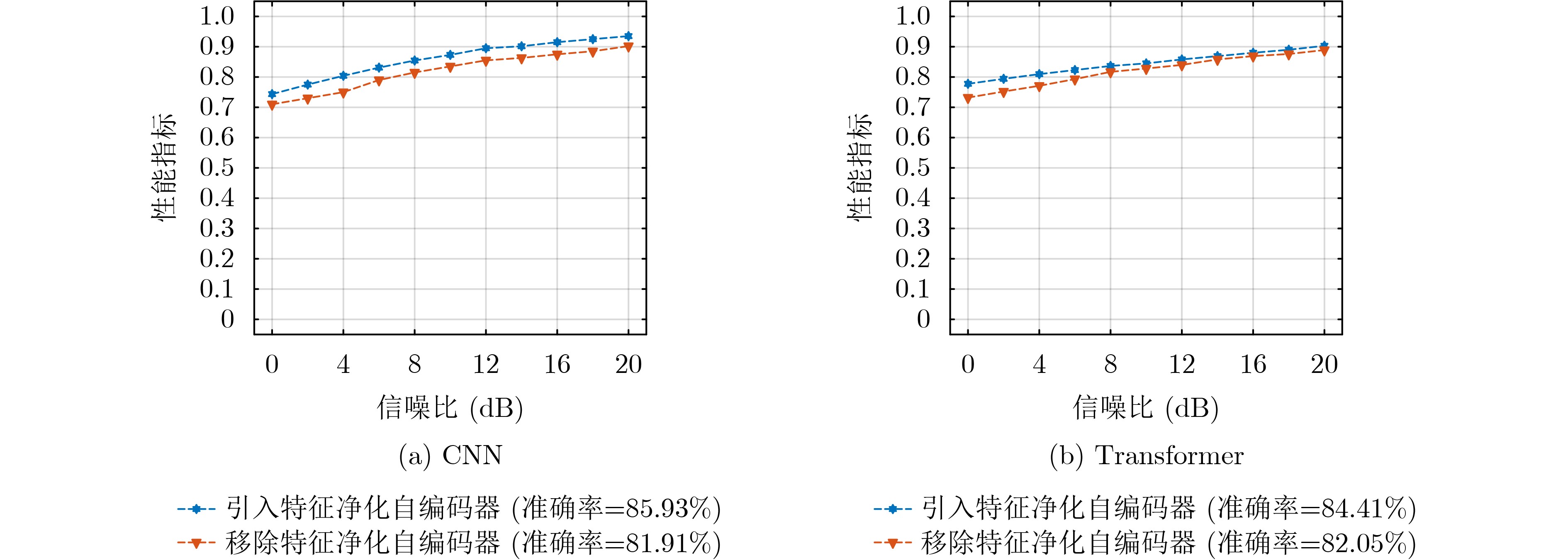
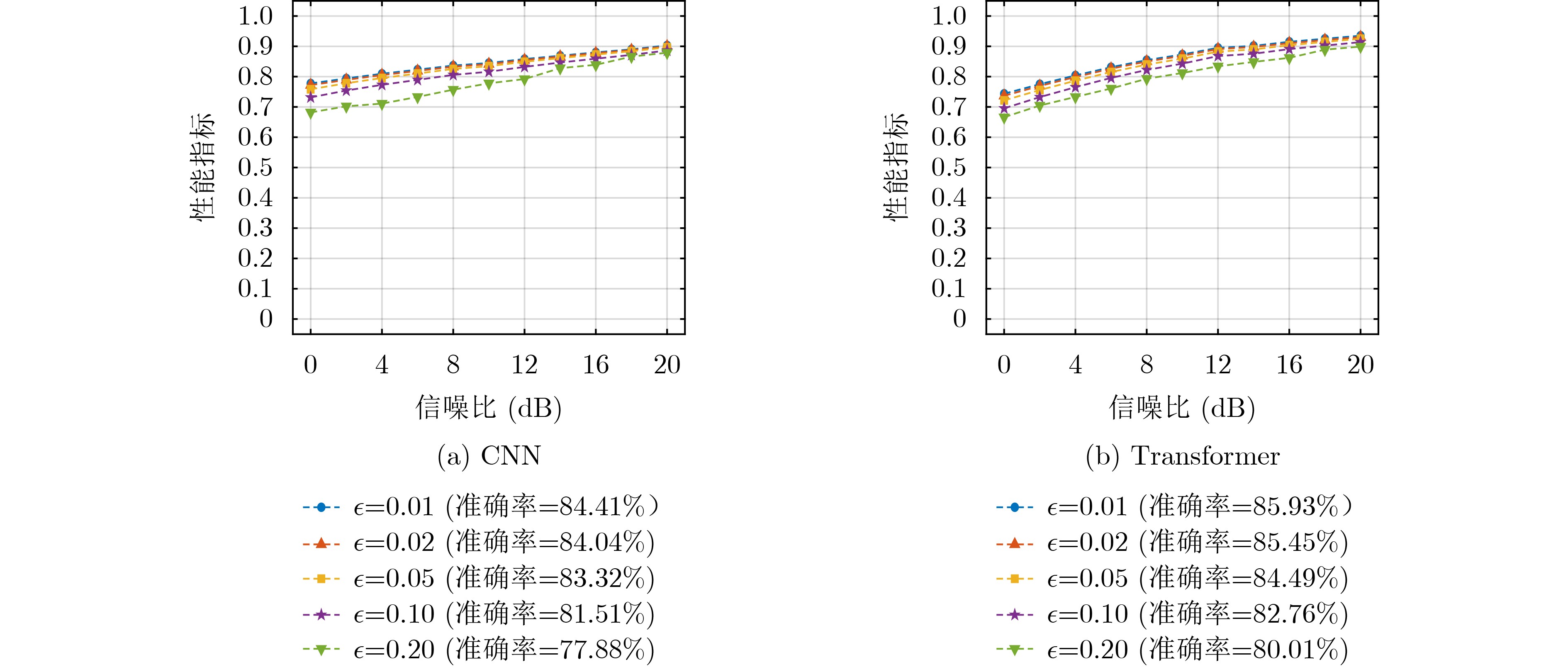
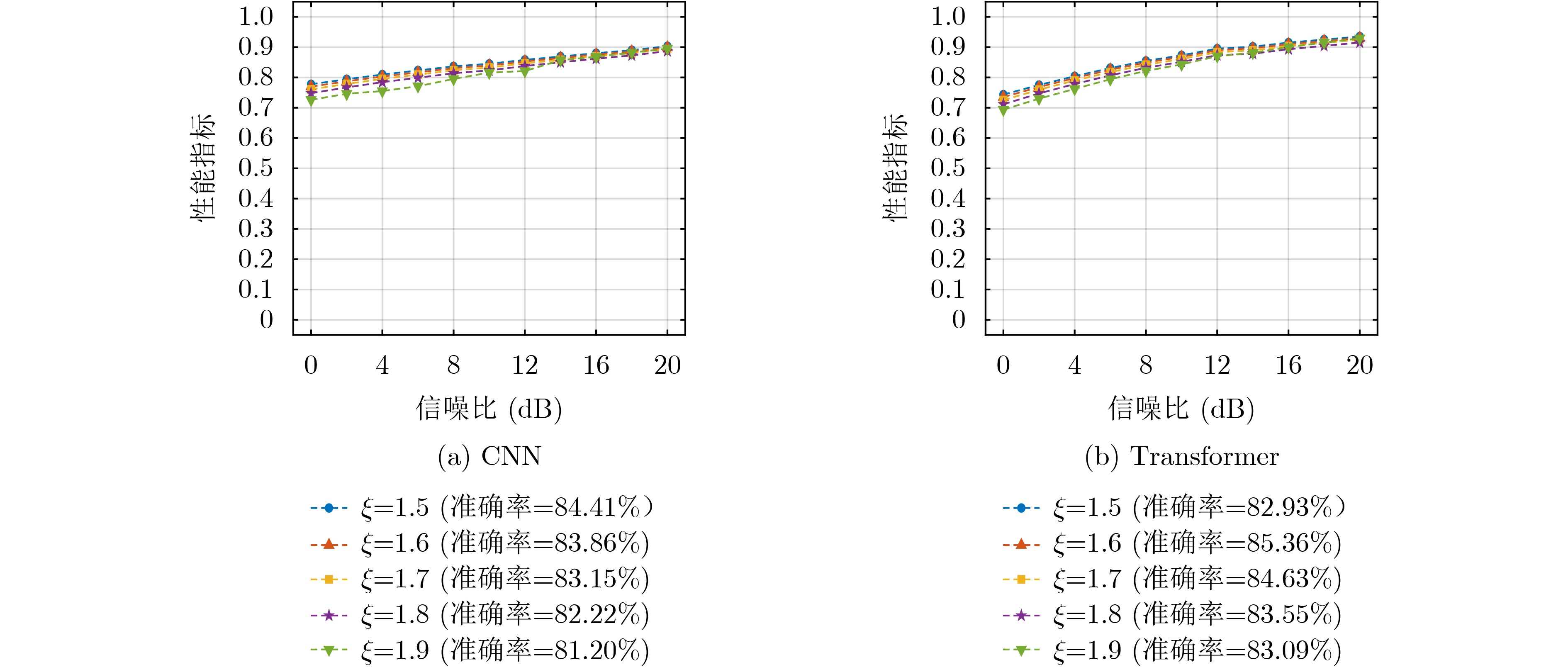
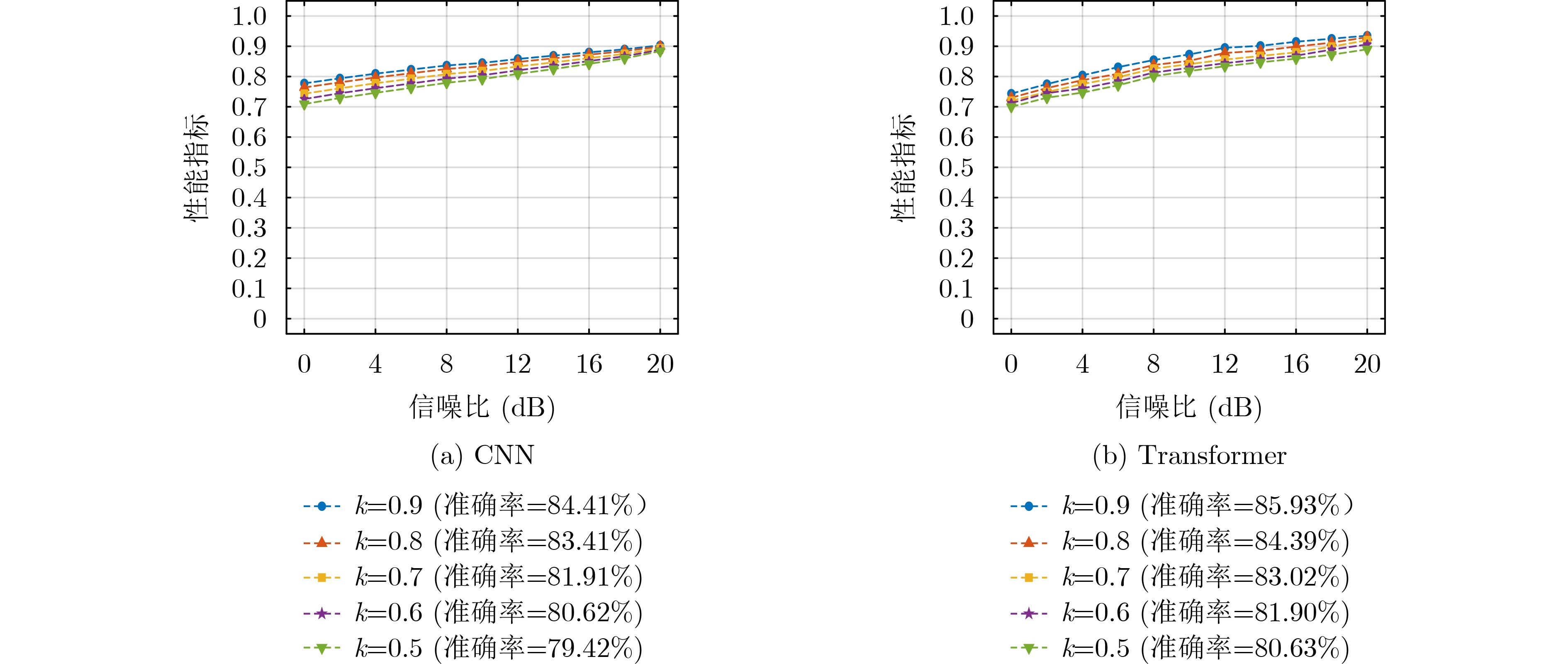
Objective Deep learning-based automatic modulation recognition (AMR) models have demonstrated superior performance in non-cooperative communication systems such as cognitive radio and spectrum monitoring. However, the inherent vulnerability of deep learning models to adversarial attacks, where imperceptible perturbations can cause catastrophic misclassification, poses the severe security threat. Existing defense methods, including adversarial training, often rely on prior knowledge of specific attacks, incur significant computational overhead, and face the trade-off between robustness and accuracy on clean samples. To address these limitations, this paper aims to design and validate a robust modulation recognition framework that can operate effectively under blind adversarial attack scenarios without prior knowledge of the attack type and strategy, thereby ensuring the reliable deployment of intelligent communication systems in adversarial environments. Methods The proposed framework integrates a novel feature-purifying autoencoder module with standard modulation classifiers (CNN and Transformer). The core innovation lies in the autoencoder’s bottleneck layer, which incorporates a dynamic purification mechanism. This mechanism first calculates an adaptive threshold based on the statistical properties of the encoded latent features to identify anomalies. Subsequently, the Top-K sparsification operation selectively preserves only the most significant feature activations, effectively suppressing noise and adversarial perturbations while retaining essential signal characteristics. Then the autoencoder is trained via a three-stage curriculum learning strategy that sequentially optimizes reconstruction fidelity, feature sparsity, and semantic consistency between the purified and original clean signals, ensuring the output aligns with the true modulation manifold. This model-agnostic module can be seamlessly prepended to any trained classifier without retraining. Results and Discussions Comprehensive experiments are conducted on a simulated dataset encompassing 12 digital modulation types under multipath fading channels. The framework demonstrated substantial performance improvements. For the CNN and Transformer, the recognition accuracies under challenging targeted white-box attacks increased to 82.1% and 83.2%, and under non-targeted black-box attacks reached 87.7% and 89.4%, respectively ( Table 1 ). The attack success rate (ASR) and attack effectiveness index (AEI) remained at low levels, confirming strong defensive capability.Figure 4 shows that defense efficacy improves with higher SNR. Crucially, the ablation study inFigure 5 highlights the indispensable role of the autoencoder, whose removal caused accuracy to plummet by 4.02% and 2.36% on CNN and Transformer under strong attacks. Further analysis (Figure 6 ) indicates that the framework maintains robustness across a wide range of perturbation bounds ($ \epsilon \leq 0.1 $). Moreover, parameter sensitivity studies (Figures 7 and8 ) show stable performance for threshold coefficient $ \xi $ in [1.5, 1.9] and sparsity rate k around 0.7, confirming its practical deployability.Conclusions This paper presents a robust, blind defense framework for robust AMR based on the feature-purifying autoencoder. The key advantages are threefold: 1) It provides effective defense against diverse white-box and black-box attacks without requiring any prior knowledge of various attack methods, achieving true blind defense; 2) As a preprocessing module, it eliminates the need for computationally expensive retraining of the primary classifier and is compatible with various backbone networks; 3) The multi-stage training strategy successfully balances robustness against attacks with the preservation of high accuracy on clean samples. Finally, experimental results on the comprehensive dataset validate the framework’s superiority. Future work will focus on lightweight architectural designs to reduce inference latency and further investigate performance boundaries under extreme low-SNR conditions combined with complex nonlinear channel impairments. -
1 特征净化自编码器多阶段训练算法
(1) 输入:干净训练样本集$ {D}_{\text{train}} $,初始化特征净化自编码器$ \{\boldsymbol{W},\boldsymbol{b}\} $,迭代次数$ {E}_{\text{total}} $,阶段边界$ {E}_{\text{1}} $和$ {E}_{\text{2}} $,加权系数$ {\lambda }_{1} $和$ {\lambda }_{2} $。 (2) 循环(迭代次数e从1至$ {E}_{\text{total}} $)执行 (3) 循环(批量样本集合$ {D}_{\text{batch}}\subseteq {D}_{\text{train}} $)执行 (4) 循环(每个样本$ (x,y)\in {D}_{\text{batch}} $)执行 (5) $ {\boldsymbol{x}}_{\text{recon}}\leftarrow \text{Decoder(Bottleneck(Encoder(}{\boldsymbol{x}}_{\text{manifold}}\text{)))} $; (6) 参照公式(32)计算$ {\mathcal{L}}_{\text{recon}} $; (7) 判断($ e \lt {E}_{\text{1}} $)执行 (8) $ {\mathcal{L}}_{\text{total}}\leftarrow {\mathcal{L}}_{\text{recon}} $ //阶段1:计算重构损失 (9) 分支判断($ e \lt {E}_{\text{2}} $)执行 (10) 参照公式(33)计算$ {\mathcal{L}}_{\text{sparse}} $; (11) $ {\lambda }_{1}\leftarrow 0.01+(e-{E}_{1})\times 0.09/({E}_{2}-{E}_{1}) $; (12) $ {\mathcal{L}}_{\text{total}}\leftarrow {\mathcal{L}}_{\text{recon}}+{\lambda }_{1}\cdot {\mathcal{L}}_{\text{sparse}} $ //阶段2:引入稀疏约束 (13) 否则执行 (14) 参照公式(34)计算$ {\mathcal{L}}_{\text{consis}} $; (15) $ {\lambda }_{2}\leftarrow 0.1+(e-{E}_{2})\times 0.04 $; (16) $ {\mathcal{L}}_{\text{total}}\leftarrow {\mathcal{L}}_{\text{recon}}+{\lambda }_{1}\cdot {\mathcal{L}}_{\text{sparse}}+{\lambda }_{2}\cdot {\mathcal{L}}_{\text{consis}} $ //阶段3:全目标函数优化 (17) 结束判断 (18) $ \{{\boldsymbol{W}}^{\text{e}},{\boldsymbol{b}}^{e}\}\leftarrow \text{Adam}({\mathcal{L}}_{\text{total}},\{{\boldsymbol{W}}^{\textit{e-1}},{\boldsymbol{b}}^{\mathrm{e}-1}\}) $; (19) 结束循环 (20) 结束循环 (21) 结束循环 (22) 输出:收敛的特征净化自编码器$ \{{\boldsymbol{W}}^{\ast },{\boldsymbol{b}}^{\ast }\} $。  下载: 导出CSV
下载: 导出CSV
表 1 对抗攻击防御性能
基线模型 性能指标 白盒攻击 黑盒攻击 有目标/无目标 有目标/无目标 CNN ASR 0.128/0.166 0.084/0.123 AEI 0.094/0.121 0.062/0.090 准确率 0.821/0.834 0.845/0.877 Transformer ASR 0.097/0.143 0.065/0.107 AEI 0.071/0.105 0.048/0.078 准确率 0.832/0.857 0.861/0.894
下载: 导出CSV
-
[1] 郑庆河, 刘方霖, 余礼苏, 等. 基于改进Kolmogorov-Arnold混合卷积神经网络的调制识别方法[J]. 电子与信息学报, 2025, 47(8): 2584–2597. doi: 10.11999/JEIT250161.ZHENG Qinghe, LIU Fanglin, YU Lisu, et al. An improved modulation recognition method based on hybrid Kolmogorov-Arnold convolutional neural network[J]. Journal of Electronics & Information Technology, 2025, 47(8): 2584–2597. doi: 10.11999/JEIT250161. [2] 王文萱, 汪成磊, 齐慧慧, 等. 面向深度模型的对抗攻击与对抗防御技术综述[J]. 信号处理, 2025, 41(2): 198–223. doi: 10.12466/xhcl.2025.02.002.WANG Wenxuan, WANG Chenglei, QI Huihui, et al. Survey on adversarial attack and adversarial defense technologies for deep learning models[J]. Journal of Signal Processing, 2025, 41(2): 198–223. doi: 10.12466/xhcl.2025.02.002. [3] 吴涛, 纪琼辉, 先兴平, 等. 信息熵驱动的图神经网络黑盒迁移对抗攻击方法[J]. 电子与信息学报, 2025, 47(10): 3814–3825. doi: 10.11999/JEIT250303.WU Tao, JI Qionghui, XIAN Xingping, et al. Information entropy-driven black-box transferable adversarial attack method for graph neural networks[J]. Journal of Electronics & Information Technology, 2025, 47(10): 3814–3825. doi: 10.11999/JEIT250303. [4] 张剑, 周侠, 张一然, 等. 基于雅可比显著图的电磁信号快速对抗攻击方法[J]. 通信学报, 2024, 45(1): 180–193. doi: 10.11959/j.issn.1000−436x.2024021.ZHANG Jian, ZHOU Xia, ZHANG Yiran, et al. Electromagnetic signal fast adversarial attack method based on Jacobian saliency map[J]. Journal on Communications, 2024, 45(1): 180–193. doi: 10.11959/j.issn.1000−436x.2024021. [5] 钱亚冠, 孔亚鑫, 陈科成, 等. 利用频谱衰减增强深度神经网络对抗迁移攻击[J]. 电子与信息学报, 2025, 47(10): 3847–3857. doi: 10.11999/JEIT250157.QIAN Yaguan, KONG Yaxin, CHEN Kecheng, et al. Adversarial transferability attack on deep neural networks through spectral coefficient decay[J]. Journal of Electronics & Information Technology, 2025, 47(10): 3847–3857. doi: 10.11999/JEIT250157. [6] KONG Weisi, JIAO Xun, XU Yuhua, et al. A transformer-based contrastive semi-supervised learning framework for automatic modulation recognition[J]. IEEE Transactions on Cognitive Communications and Networking, 2023, 9(4): 950–962. doi: 10.1109/TCCN.2023.3264908. [7] 徐东伟, 蒋斌, 陈嘉峻, 等. 基于特征融合的电磁信号对抗样本检测方法[J]. 电波科学学报, 2024, 39(5): 926–933. doi: 10.12265/j.cjors.2023268.XU Dongwei, JIANG Bin, CHEN Jiajun, et al. An electromagnetic signal adversarial sample detection method based on feature fusion[J]. Chinese Journal of Radio Science, 2024, 39(5): 926–933. doi: 10.12265/j.cjors.2023268. [8] CAO Feilong, YE Xing, and YE Hailiang. A multi-view graph contrastive learning framework for defending against adversarial attacks[J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2024, 8(6): 4022–4032. doi: 10.1109/TETCI.2024.3382230. [9] CHEN Tao, ZHENG Shilian, QIU Kunfeng, et al. Augmenting radio signals with wavelet transform for deep learning-based modulation recognition[J]. IEEE Transactions on Cognitive Communications and Networking, 2024, 10(6): 2029–2044. doi: 10.1109/TCCN.2024.3400525. [10] ZHANG Lin, LIU Heng, YANG Xiaoling, et al. Intelligent denoising-aided deep learning modulation recognition with cyclic spectrum features for higher accuracy[J]. IEEE Transactions on Aerospace and Electronic Systems, 2021, 57(6): 3749–3757. doi: 10.1109/TAES.2021.3083406. [11] ZHANG Sicheng, LIN Yun, YU Jiarun, et al. HFAD: Homomorphic filtering adversarial defense against adversarial attacks in automatic modulation classification[J]. IEEE Transactions on Cognitive Communications and Networking, 2024, 10(3): 880–892. doi: 10.1109/TCCN.2024.3360514. [12] 魏宣宣, 刘万平, 卢玲. 基于多模态特征融合的对抗样本防御方法研究[J]. 网络与信息安全学报, 2025, 11(2): 175–188. doi: 10.11959/j.issn.2096-109x.2025023.WEI Xuanxuan, LIU Wanping, and LU Ling. Research on adversarial examples defense method based on multi-modal feature fusion[J]. Chinese Journal of Network and Information Security, 2025, 11(2): 175–188. doi: 10.11959/j.issn.2096-109x.2025023. [13] CHEN Zhuangzhi, WANG Zhangwei, XU Dongwei, et al. Learn to defend: Adversarial multi-distillation for automatic modulation recognition models[J]. IEEE Transactions on Information Forensics and Security, 2024, 19: 3690–3702. doi: 10.1109/TIFS.2024.3361172. [14] ZHANG Zhenju, MA Linru, LIU Mingqian, et al. Robust generative defense against adversarial attacks in intelligent modulation recognition[J]. IEEE Transactions on Cognitive Communications and Networking, 2025, 11(2): 1041–1052. doi: 10.1109/TCCN.2024.3524184. [15] WANG Wenyu, ZHU Lei, GU Yuantao, et al. Adversarial samples detection based on feature attribution and contrast in modulation recognition[J]. IEEE Communications Letters, 2024, 28(11): 2483–2487. doi: 10.1109/LCOMM.2024.3463949. [16] ZHAO Yuhang, WNAG Yajie, ZHANG Chuan, et al. Boosting robustness in automatic modulation recognition for wireless communications[J]. IEEE Transactions on Cognitive Communications and Networking, 2025, 11(3): 1635–1648. doi: 10.1109/TCCN.2024.3499362. [17] ZHANG Sicheng, FU Jiangzhi, YU Jiarun, et al. Channel-robust class-universal spectrum-focused frequency adversarial attacks on modulated classification models[J]. IEEE Transactions on Cognitive Communications and Networking, 2024, 10(4): 1280–1293. doi: 10.1109/TCCN.2024.3382126. [18] HAMEED M Z, GYÖRGY A, and GÜNDÜZ D. The best defense is a good offense: Adversarial attacks to avoid modulation detection[J]. IEEE Transactions on Information Forensics and Security, 2021, 16: 1074–1087. doi: 10.1109/TIFS.2020.3025441. [19] WANG Chao, WEI Xianglin, FAN Jianhua, et al. Universal attack against automatic modulation classification DNNs under frequency and data constraints[J]. IEEE Internet of Things Journal, 2023, 10(14): 12938–12950. doi: 10.1109/JIOT.2023.3254648. -





图(8) / 表(2)
计量
- 文章访问数: 289
- HTML全文浏览量: 136
- PDF下载量: 20
- 被引次数: 0
 下载:
下载:
