

Multi-Agent Deep Reinforcement Learning Strategy for Multi-Spacecraft Long-Distance Orbital Game
-
摘要: 针对多航天器轨道追逃博弈问题,本文介绍了一个新颖的研究场景,该场景尚未得到系统研究。为了增强航天器的决策能力,使其在复杂的多智能体博弈中制定更加稳健的策略,本文提出一种基于渐进式对抗训练框架的多智能体深度强化学习算法求解各航天器的博弈策略。并且设定两组不同轨道特性的算例和多种不同的仿真条件进行模拟验证,以及通过行为偏差分析验证策略的鲁棒性。分析不同轨道特性、仿真条件和行为偏差对各航天器的博弈策略的影响。仿真结果表明,本文所提出的方法可以使每个航天器都能制定出有效的博弈策略,策略满足所有设定的约束条件和具有良好的鲁棒性。
-
关键词:
- 多航天器追逃博弈 /
- 多智能体深度强化学习 /
- 渐进式对抗训练框架 /
- 行为偏差分析
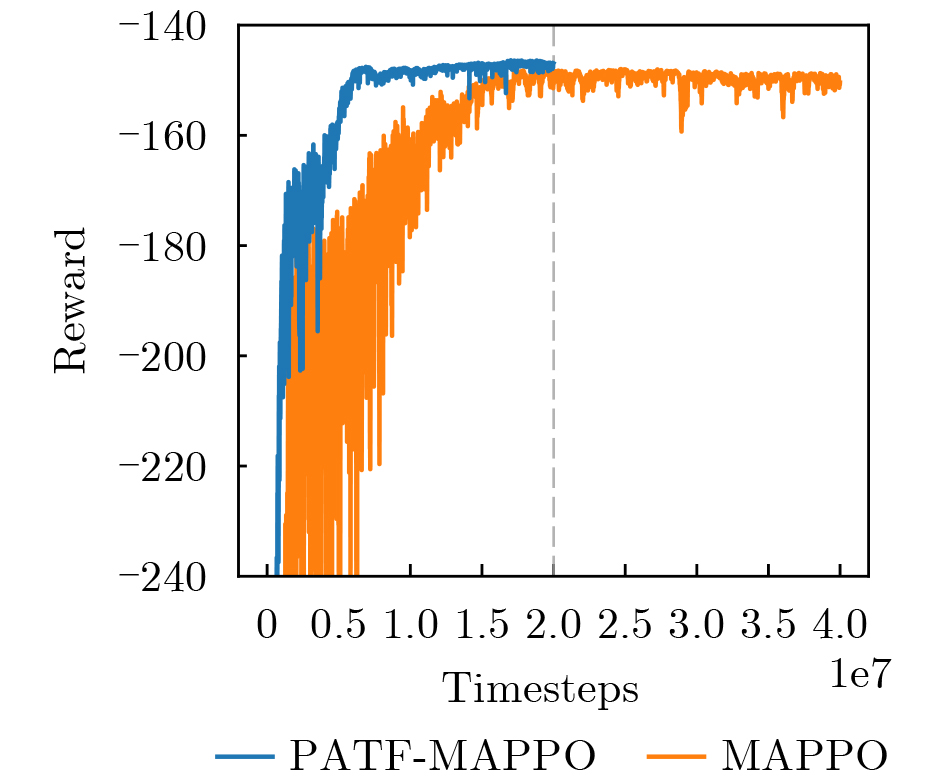
Abstract:This paper introduces a novel research scenario for multi-spacecraft Orbital Pursuit-Evasion Game (OPEG), which has not yet been systematically studied. To enhance the decision-making capabilities of spacecraft and enable them to formulate more robust policies in complex multi-agent games, this paper proposes a multi-agent deep reinforcement learning algorithm based on a progressive adversarial training framework to solve the game policies of each spacecraft. Two sets of examples with different orbital characteristics and various simulation conditions were set up for simulation verification, and behavioral deviation analysis is conducted to verify the robustness of the policy. The impact of different orbital characteristics, simulation conditions, and behavioral deviations on the game policy was analyzed. Simulation results show that the proposed method enables each spacecraft to formulate an effective game policy that satisfies all set constraints and has good robustness. Objective As the space environment becomes increasingly complex, space security has become a hot research area. The existence of a large amount of space debris and failed spacecraft poses a serious threat to high-value spacecraft in orbit. Therefore, the study of Orbital Pursuit-Evasion Game (OPEG) for non-cooperative target spacecraft has attracted widespread attention. Existing research focuses on OPEG for two spacecraft, but less on OPEG for multiple spacecraft. When there are more than two players in the game, zero-sum game design is not feasible, and it is difficult to solve using traditional methods. Furthermore, existing research ignores engineering dynamic constraints and simplifies or defines the dynamics as a two-dimensional scene when modeling the problem, which can cause considerable errors. To overcome the limitations of existing spacecraft game scenarios, this paper proposes a novel multi-spacecraft OPEG research scenario. The aim is to investigate the application of the MADRL algorithm in solving the approximate steady-state policies of each spacecraft in long-distance multi-spacecraft OPEG, highlighting the significant advantages of the MADRL algorithm in solving multi-spacecraft OPEG, and providing a feasible solution for truly realizing autonomous multi-spacecraft game play in the future. Methods The Multi-Agent Proximal Policy Optimization (MAPPO) algorithm based on the Progressive Adversarial Training Framework (PATF) is used to solve the optimal game policy for each spacecraft in the Multi-Spacecraft OPEG. First, a multi-constrained multi-spacecraft OPEG model is established based on actual engineering constraints, and the problem is transformed into a Decentralized Partially Observable Markov Decision Process (Dec-POMDPs). Secondly, in order to improve the decision-making ability of agents in complex multi-agent game environments and formulate more robust game policies, a novel PATF is introduced, with different reward functions designed for the specific missions of each spacecraft. Finally, two sets of simulation examples with different orbital characteristics were set up, and four different simulation conditions were set up for simulation and behavioral deviation analysis was performed. Results and Discussions The MAPPO algorithm based on the PATF proposed in this paper is compared with the original MAPPO ( Fig. 3 ). The results show that the proposed method can learn effective policies more quickly, reduce ineffective exploration, and achieve a higher final convergence reward value with less fluctuation in the reward curve. This also demonstrates that the PATF can significantly enhance the decision-making ability of agents, enabling them to formulate robust policies more effectively. Simulation verification was performed using two sets of examples in four different settings (Figs. 4 ,5 , 6, and 7). Simulation results (Tables 3 and4 ) show that the proposed method performs well in both sets of examples. Furthermore, it was verified that when the pursuer and the interceptor are on the same orbital plane, the pursuer is more likely to be intercepted. When the interceptor and the target are not on the same orbital plane, the interceptor has a relatively easier time carrying out the interception mission. This paper also analyzes the situation where both sides of the game have behavioral biases, and models this by adding control noise. Simulation results (Tables 5 and6 ) show that both sides adopt relatively conservative policies to counter the control noise. The game policy formulated by the method in this paper is an approximate steady-state policy. Behavioral deviations will lead to a decrease in one’s own payoff and an increase in the opponent's payoff, and the game policy has good robustness.Conclusions The method proposed in this paper can be well applied to solving the long-distance OPEG problem involving multiple spacecraft in non-coplanar elliptical orbits, enabling each spacecraft to formulate excellent game policies. The PATF facilitates better decision-making by the spacecraft in complex multi-spacecraft dynamic systems, with robust control policies developed by the pursuer and interceptors. The results also demonstrate the accuracy and effectiveness of the reward function design. Through two sets of examples and simulation results with different settings, the impact on the policies of both parties when the pursuer and interceptor have different orbital characteristics is analyzed. When interceptors have different maximum thrusts, the decision-making of each spacecraft changes accordingly. The behavior deviation analysis proves that the game policies of each spacecraft have good robustness. When one party’s behavior deviates, the approximate steady-state policy balance will change, resulting in a decrease in its own benefits and an increase in the other party’s benefits. The research scenario formulated in this paper expands the scope of existing research on multi-spacecraft game problems. -
表 1 算例1和算例2中航天器的轨道根数
轨道根数 算例 1 算例 2 追击者 拦截者1 拦截者2 追击者 拦截者1 拦截者2 $ a $[km] 16000 16200 16200 15900 16200 16200 $ e $ 0.2 0.2 0.2 0.2 0.2 0.2 $ i $ [°] 35 36 35 35.5 35.5 35 $ {\varOmega } $ [°] 30 30 30 30 30 30 $ \omega $ [°] 91 89 90 89 89 89.7 $ f $ [°] 0 0 0 0 0.735 0  下载: 导出CSV
下载: 导出CSV
表 2 多航天器OPEG模型的参数设置
参数 $ N $ $ \Delta t $ $ {T}_{\mathrm{P},\max } $ $ {T}_{\mathrm{I},\max } $ $ \Delta {r}_{\mathrm{P},\max } $ $ \Delta {r}_{\mathrm{td},\max } $ $ \Delta {r}_{\mathrm{I},\max } $ $ \Delta {r}_{\mathrm{sd},\min } $ $ \Delta {r}_{\mathrm{sd},\max } $ 值 50 60 s 100 N 60 N, 75 N 3 km 20 km 5 km 2 km 5 km
下载: 导出CSV
表 3 算例1的数值结果
Setup 追击者 拦截者1 拦截者2 步数 胜利者 $ \Delta {r}_{\text{PT}} $ [km] $ \Delta {r}_{\text{PI}} $ [km] $ {\Delta m}_{\mathrm{P}} $ [kg] $ \Delta {r}_{{{\mathrm{I}}_{1}}\mathrm{P}} $ [km] $ \Delta {r}_{{{\mathrm{I}}_{1}}\mathrm{T}} $ [km] $ \Delta {m}_{{{\mathrm{I}}_{1}}} $ [kg] $ \Delta {r}_{{{\mathrm{I}}_{2}}\mathrm{P}} $ [km] $ \Delta {r}_{{{\mathrm{I}}_{2}}\mathrm{T}} $ [km] $ {\Delta m}_{{{\mathrm{I}}_{2}}} $ [kg] 1 1.23 16.32 15.85 201.79 202.94 14.86 16.32 16.38 17.38 38 P 2 41.42 0.74 17.44 235.39 268.26 14.54 0.74 41.21 17.27 32 $ {\mathrm{I}}_{2} $ 3 1.12 12.13 22.44 106.07 105.73 21.35 12.13 12.49 15.99 38 P 4 41.41 0.76 17.45 183.42 218.56 18.22 0.76 41.41 17.26 32 $ {\mathrm{I}}_{2} $
下载: 导出CSV
表 4 算例2的数值结果
Setup 追击者 拦截者1 拦截者2 步数 胜利者 $ \Delta {r}_{\text{PT}} $ [km] $ \Delta {r}_{\text{PI}} $ [km] $ {\Delta m}_{\mathrm{P}} $ [kg] $ \Delta {r}_{{{\mathrm{I}}_{1}}\mathrm{P}} $ [km] $ \Delta {r}_{{{\mathrm{I}}_{1}}\mathrm{T}} $ [km] $ \Delta {m}_{{{\mathrm{I}}_{1}}} $ [kg] $ \Delta {r}_{{{\mathrm{I}}_{2}}\mathrm{P}} $ [km] $ \Delta {r}_{{{\mathrm{I}}_{2}}\mathrm{T}} $ [km] $ {\Delta m}_{{{\mathrm{I}}_{2}}} $ [kg] 1 0.14 26.15 10.98 35.63 35.72 18.32 26.15 26.20 18.32 40 P 2 0.26 22.24 13.62 55.58 55.49 16.48 22.24 22.37 17.50 36 P 3 76.01 0.49 18.24 0.49 75.84 19.81 103.14 82.06 14.09 36 $ {\mathrm{I}}_{1} $ 4 51.66 1.15 18.64 1.15 52.23 20.29 31.62 34.70 20.40 36 $ {\mathrm{I}}_{1} $
下载: 导出CSV
表 5 追击者具有控制噪声的仿真数值结果
Setup $ {\Delta m}_{\mathrm{P}} $ [kg] $ \Delta {m}_{{{\mathrm{I}}_{1}}} $ [kg] $ {\Delta m}_{{{\mathrm{I}}_{2}}} $ [kg] Steps MSR [%] Winner mean std mean std mean std mean std 1 16.59 0.55 15.44 0.089 16.65 0.16 39.17 1.34 98.5 P 2 15.20 0.051 12.55 9.7e-5 14.86 1.8e-4 31 0 100 I 3 21.09 1.34 21.55 0.56 15.16 0.85 41.41 1.87 95.5 P 4 15.35 0.058 14.93 2.4e-4 15.00 6.7e-5 29 0 100 I
下载: 导出CSV
表 6 拦截者具有控制噪声的仿真数值结果
Setup $ {\Delta m}_{\mathrm{P}} $ [kg] $ \Delta {m}_{{{\mathrm{I}}_{1}}} $ [kg] $ {\Delta m}_{{{\mathrm{I}}_{2}}} $ [kg] Steps MSR [%] Winner mean std mean std mean std mean std 1 14.02 7.8e-5 14.50 0.043 14.84 0.040 39 0 100 P 2 19.98 9.7e-5 16.72 0.051 18.43 0.037 40 0 100 P 3 18.77 1.2e-4 18.42 0.059 15.43 0.051 38 0 100 P 4 22.03 7.2e-5 19.91 0.063 20.89 0.034 38 0 100 P
下载: 导出CSV
-
[1] SUN Qilong, QI Naiming, XIAO Longxu, et al. Differential game strategy in three-player evasion and pursuit scenarios[J]. Journal of Systems Engineering and Electronics, 2018, 29(2): 352–366. doi: 10.21629/JSEE.2018.02.16. [2] CUI Jianfeng, LI Dongchang, LIU Peng, et al. Game-model prediction hybrid path planning algorithm for multiple mobile robots in pursuit evasion game[C]. 2021 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 2021: 925–930. doi: 10.1109/ICUS52573.2021.9641362. [3] ZHANG Yiqun, ZHANG Pengfei, WANG Xiaodong, et al. An open loop Stackelberg solution to optimal strategy for UAV pursuit-evasion game[J]. Aerospace Science and Technology, 2022, 129: 107840. doi: 10.1016/j.ast.2022.107840. [4] 高思华, 刘宝煜, 惠康华, 等. 信息年龄约束下的无人机数据采集能耗优化路径规划算法[J]. 电子与信息学报, 2024, 46(10): 4024–4034. doi: 10.11999/JEIT240075.GAO Sihua, LIU Baoyu, HUI Kanghua, et al. Energy-efficient UAV trajectory planning algorithm for AoI-constrained data collection[J]. Journal of Electronics & Information Technology, 2024, 46(10): 4024–4034. doi: 10.11999/JEIT240075. [5] 颜志, 陆元媛, 丁聪, 等. 面向用户移动场景的无人机中继功率分配与轨迹设计[J]. 电子与信息学报, 2024, 46(5): 1896–1907. doi: 10.11999/JEIT231337.YAN Zhi, LU Yuanyuan, DING Cong, et al. Power allocation and trajectory design for unmanned aerial vehicle relay network with mobile users[J]. Journal of Electronics & Information Technology, 2024, 46(5): 1896–1907. doi: 10.11999/JEIT231337. [6] LOWE R, WU Yi, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach California, USA, 2017: 6382–6393. [7] LUO Yuelin, GANG Tieqiang, and CHEN Lijie. Research on target defense strategy based on deep reinforcement learning[J]. IEEE Access, 2022, 10: 82329–82335. doi: 10.1109/ACCESS.2022.3179373. [8] WANG Xin, WANG Yueying, ZHOU Weixiang, et al. Pursuit-evasion game of unmanded surface vehicles based on deep reinforcement learning[C]. 2023 4th International Conference on Electronic Communication and Artificial Intelligence (ICECAI), Guangzhou, China, 2023: 358–363. doi: 10.1109/ICECAI58670.2023.10176487. [9] JI Mengda, XU Genjiu, DUAN Zekun, et al. Cooperative pursuit with multiple pursuers based on deep minimax Q-learning[J]. Aerospace Science and Technology, 2024, 146: 108919. doi: 10.1016/j.ast.2024.108919. [10] JAGAT A and SINCLAIR A J. Nonlinear control for spacecraft pursuit-evasion game using the state-dependent Riccati equation method[J]. IEEE Transactions on Aerospace and Electronic Systems, 2017, 53(6): 3032–3042. doi: 10.1109/TAES.2017.2725498. [11] MA Huidong and ZHANG Gang. Delta-V analysis for impulsive orbital pursuit-evasion based on reachable domain coverage[J]. Aerospace Science and Technology, 2024, 150: 109243. doi: 10.1016/j.ast.2024.109243. [12] SHI Mingming, YE Dong, SUN Zhaowei, et al. Spacecraft orbital pursuit–evasion games with J2 perturbations and direction-constrained thrust[J]. Acta Astronautica, 2023, 202: 139–150. doi: 10.1016/j.actaastro.2022.10.004. [13] ZHANG Jingrui, ZHANG Kunpeng, ZHANG Yao, et al. Near-optimal interception strategy for orbital pursuit-evasion using deep reinforcement learning[J]. Acta Astronautica, 2022, 198: 9–25. doi: 10.1016/j.actaastro.2022.05.057. [14] ZHAO Liran, ZHANG Yulin, and DANG Zhaohui. PRD-MADDPG: An efficient learning-based algorithm for orbital pursuit-evasion game with impulsive maneuvers[J]. Advances in Space Research, 2023, 72(2): 211–230. doi: 10.1016/j.asr.2023.03.014. [15] TANG Xu, YE Dong, LOW K S, et al. Multi-spacecraft pursuit-evasion-defense strategy based on game theory for on-orbit spacecraft servicing[C]. 2023 IEEE Aerospace Conference, Big Sky, USA, 2023: 1–9. doi: 10.1109/AERO55745.2023.10115953. [16] XU Sihan, ZHAO Liran, ZHANG Weichen, et al. Delta-V-based cooperative strategies for orbital two-pursuer one-evader pursuit–evasion games[J]. Space: Science & Technology, 2025, 5: 0222. doi: 10.34133/space.0222. [17] LIANG Haizhao, WANG Jianying, LIU Jiaqi, et al. Guidance strategies for interceptor against active defense spacecraft in two-on-two engagement[J]. Aerospace Science and Technology, 2020, 96: 105529. doi: 10.1016/j.ast.2019.105529. [18] DI Peng, YAO Ye, LIN Zheng, et al. Trajectory optimization of spacecraft autonomous far-distance rapid rendezvous based on deep reinforcement learning[J]. Advances in Space Research, 2025, 75(1): 790–806. doi: 10.1016/j.asr.2024.09.066. [19] 魏普远, 何磊. 基于深度强化学习的自适应大邻域搜索算法在成像卫星调度问题中的应用[J]. 电子与信息学报, 2025, 47(12): 5005–5015. doi: 10.11999/JEIT251009.WEI Puyuan and HE Lei. A deep reinforcement learning enhanced adaptive large neighborhood search for imaging satellite scheduling[J]. Journal of Electronics & Information Technology, 2025, 47(12): 5005–5015. doi: 10.11999/JEIT251009. [20] MU Chaoxu, LIU Shuo, LU Ming, et al. Autonomous spacecraft collision avoidance with a variable number of space debris based on safe reinforcement learning[J]. Aerospace Science and Technology, 2024, 149: 109131. doi: 10.1016/j.ast.2024.109131. [21] YU Chao, VELU A, VINITSKY E, et al. The surprising effectiveness of PPO in cooperative multi-agent games[C]. Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1787. [22] BATE R R, MUELLER D D, WHITE J E, et al. Fundamentals of Astrodynamics[M]. 2nd ed. Dover Publications, 2020. (查阅网上资料, 未找到对应的出版地信息, 请确认补充). [23] HANSEN E A, BERNSTEIN D S, and ZILBERSTEIN S. Dynamic programming for partially observable stochastic games[C]. Proceedings of the 19th National Conference on Artifical Intelligence, San Jose, USA, 2004: 709–715. [24] SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv: 1707.06347, 2017. doi: 10.48550/arXiv.1707.06347. (查阅网上资料,不确定文献类型及格式是否正确,请确认). -


 下载:
下载:







图(7) / 表(6)
计量
- 文章访问数: 449
- HTML全文浏览量: 170
- PDF下载量: 82
- 被引次数: 0
