

Dynamic Scale Perception-Driven Multi-UAV Collaborative 3D Object Detection Method
-
摘要: 多无人机协同三维目标检测是低空智能感知领域的核心技术,鸟瞰图(BEV)特征表征范式为该任务提供了全局空间一致性支撑。但在实际应用中,受遥感图像目标尺度小、分布稀疏等特性影响,现有基于Transformer的BEV感知方法因采用全图同质化特征处理策略,会造成大量计算资源浪费,或者容易丢失小目标的精细特征,难以实现计算效率与检测精度的平衡。针对上述问题,该文提出一种适用于多无人机协同场景的动态尺度感知检测网络,核心思路是通过尺度差异化特征处理机制,实现计算效率与检测精度的协同优化。为此,设计两个核心创新模块:动态尺度感知BEV生成模块(DSBG)与自适应BEV特征协同聚合模块(ACFA)。其中,DSBG模块基于各无人机的特征图目标分布情况动态感知生成多分辨率BEV特征;ACFA模块对多分辨率BEV特征进行自适应加权融合,生成全局一致的协同BEV特征,再输入检测解码器完成目标预测。实验结果表明,所提网络在AeroCollab3D和Air-Co-Pred两个多无人机协同仿真数据集上均表现优异,平均预测精度(mAP)分别达到64.0%和80.6%,相较于其他先进方法分别提升1.5%和7.2%;同时计算成本最大降低41.6%,实现了计算效率与检测精度的高效平衡。Abstract:
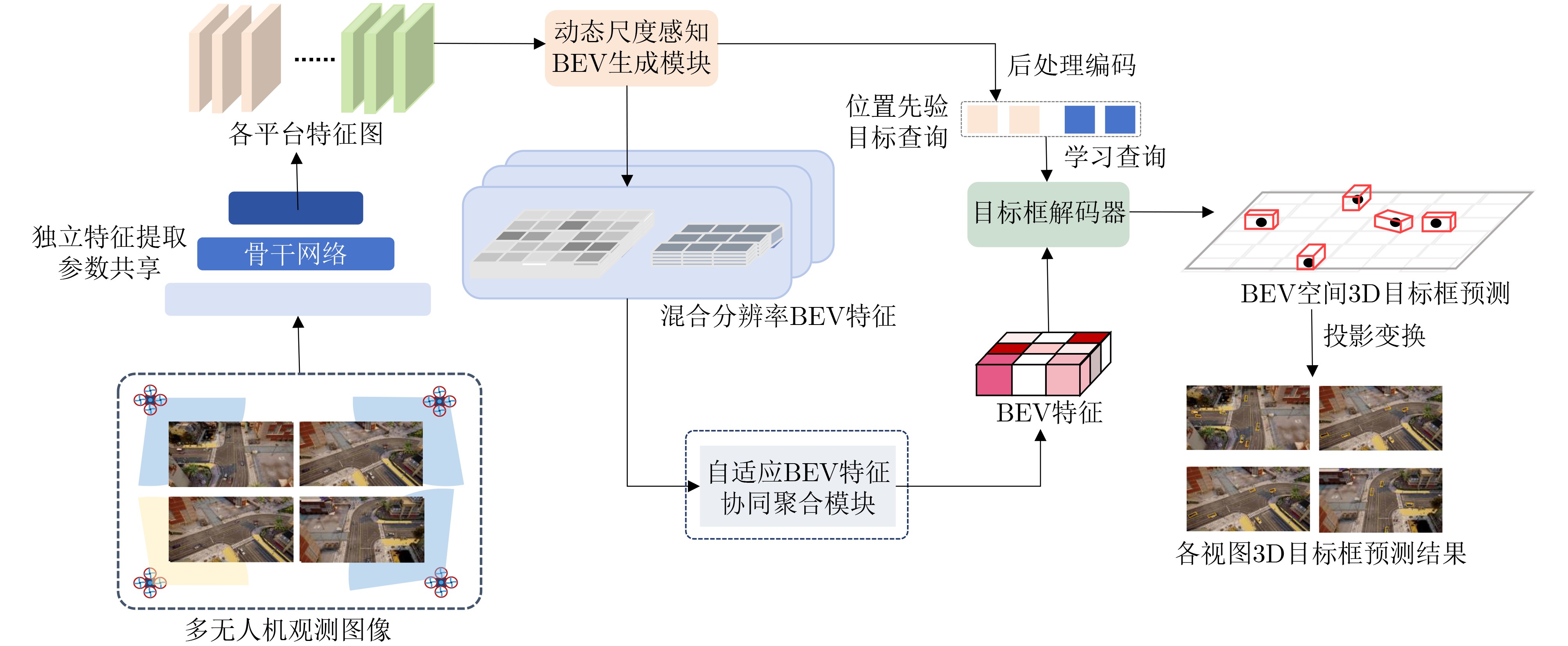
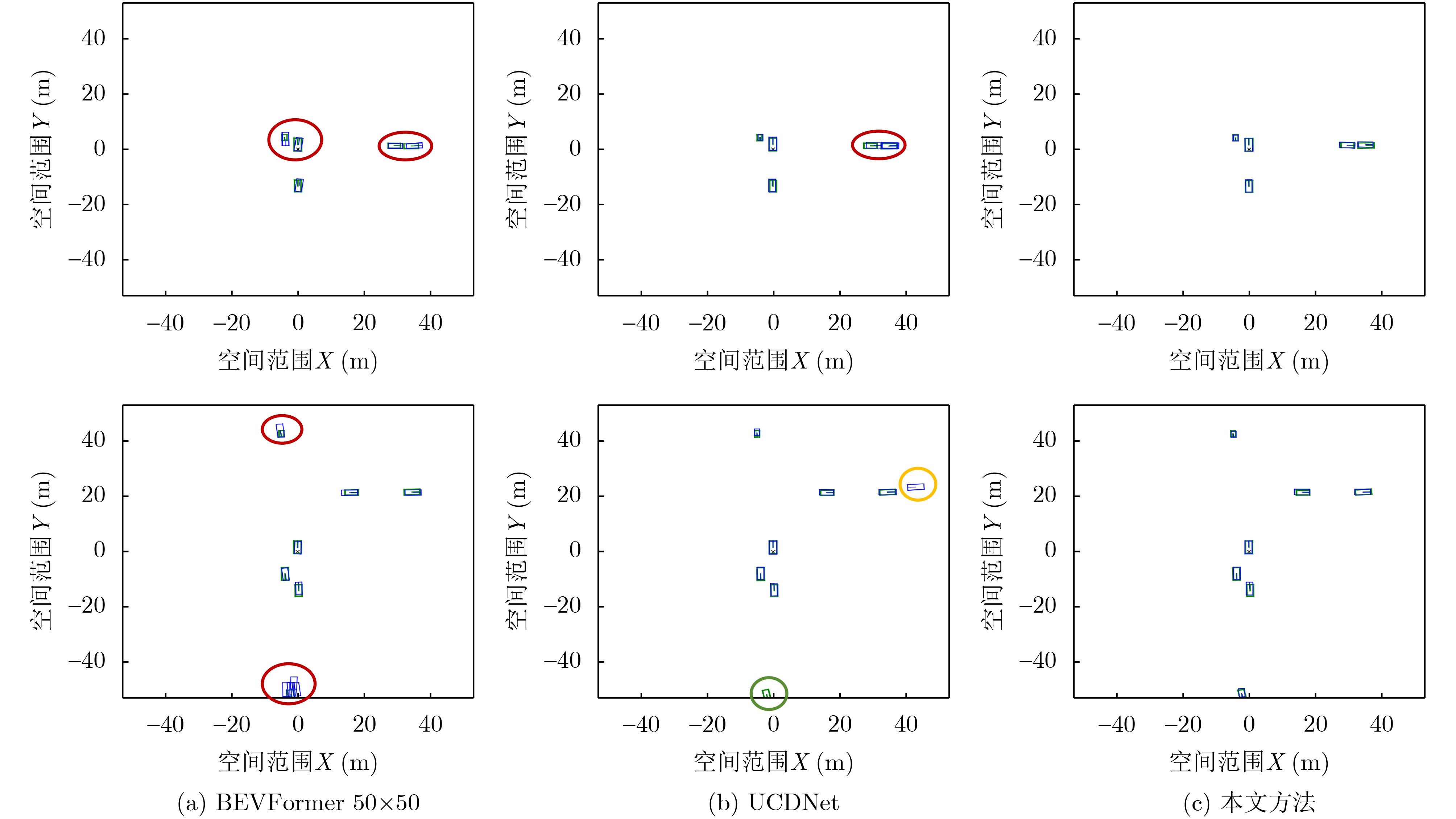
Objective Multi-UAV collaborative 3D object detection is a core technology for low-altitude intelligent perception, and the Bird’s-Eye View (BEV) feature representation paradigm provides support for global spatial consistency. However, in practical UAV remote-sensing scenarios, targets are extremely small, sparsely distributed, and embedded in a large proportion of background regions. Existing Transformer-based BEV perception methods adopt a homogeneous full-image feature-processing strategy. This strategy not only wastes computing resources because of excessive computation in large background areas, but also tends to dilute small-target features with background noise, making it difficult to balance computational efficiency and detection accuracy. Meanwhile, multi-UAV collaboration requires cross-device information interaction to achieve view complementarity and information gain, but this process is prone to redundant information and even feature conflicts. Traditional fixed-weight aggregation methods cannot accurately identify effective information or suppress redundancy, resulting in poor consistency of global BEV features and reduced collaborative detection accuracy. Therefore, the development of a detection network that is adaptive to multi-UAV aerial scenarios is of clear practical value. Methods A dynamic scale-aware detection network is proposed for efficient and accurate 3D object detection through two core modules: the Dynamic Scale-aware BEV Generation (DSBG) module and the Adaptive Collaborative BEV-Feature Aggregation (ACFA) module. The network establishes an end-to-end pipeline of “multi-view image input-dynamic scale adaptive feature encoding-BEV space 3D detection” ( Fig. 1 ). First, the observed images collected by each UAV are processed independently by a parameter-sharing ResNet-50 backbone network to generate feature maps with a consistent structure. The DSBG module then takes these feature maps as input, calculates the amplitude of feature responses in each spatial region through the Local Scale-Aware Unit, and estimates the target distribution. On this basis, differentiated BEV grid encoding is dynamically allocated: high-resolution dense grids are assigned to high-response target regions to preserve fine-grained features, whereas low-resolution sparse grids are assigned to low-response background regions to reduce invalid computation. At the same time, target query vectors with spatial position priors are generated. The ACFA module receives the multi-resolution BEV features generated by the DSBG module, concatenates the dual-resolution features from different UAVs in the channel dimension, upsamples the low-resolution features to align them with the high-resolution features, models the local correlations of two-scale features through 3*3 convolution, and obtains a globally consistent BEV feature map through element-wise weighted summation. Finally, the global BEV features are fed into the DETR decoder for 3D target prediction, with Focal Loss used for classification and Smooth L1 Loss used for regression (Eqs. 5$ \sim $6).Results and Discussions Extensive experiments are conducted on two public multi-UAV collaborative simulation datasets, AeroCollab3D and Air-Co-Pred. The results show that the proposed method achieves strong performance on both datasets. Compared with current state-of-the-art methods and baseline models, it not only improves mean Average Precision (mAP) by up to 7.2 percentage points, but also substantially reduces key evaluation metrics, including mean size error by more than 48%, mean localization error, and mean orientation error. In particular, clear advantages are observed in small-target detection and fine-grained category recognition, with pedestrian detection accuracy improved by nearly 10 percentage points. Ablation experiments verify the effectiveness of both the DSBG and ACFA modules. The proposed method steadily improves detection accuracy while significantly reducing computational cost by up to 41.6%, thereby achieving coordinated optimization of accuracy and efficiency. Visualization results ( Fig. 3 ) show that the predicted bounding boxes have higher spatial alignment with the ground truth, effectively alleviating the common problems of target overlap and missed detection in traditional methods.Fig. 4 further illustrates the technical advantages of multi-UAV collaborative detection. Even for targets occluded by obstacles, the proposed method achieves efficient detection, thereby enhancing the comprehensive perception capability of the global region.Conclusions A dynamic scale-aware detection network is proposed for multi-UAV collaborative 3D object detection to address the core challenges of the efficiency-accuracy tradeoff and poor feature consistency in traditional methods. The DSBG module achieves dynamic matching between the BEV encoding scale and target distribution, thereby reducing redundant computation, whereas the ACFA module improves multi-scale and multi-view feature aggregation to ensure global feature consistency and accuracy. Experimental results on two datasets confirm that the proposed method outperforms existing advanced methods in detection accuracy, computational efficiency, and robustness. Future work will focus on optimizing dynamic scale-adjustment strategies with temporal information and exploring multi-sensor fusion with lightweight LiDAR data to improve detection stability in complex scenarios. -
表 1 AeroCollab3D数据集对比实验结果
方法 BEV网格大小 mAP↑(%) mATE↓(m) mASE↓ mAOE↓ Cost↓ BEVDet[10] 128×128 55.4 0.512 0.196 0.498 4.712 BEVDet4D[11] 58.7 0.499 0.102 0.317 4.712 BEVLongTerm[10] 33.5 0.527 0.298 0.515 4.712 BEVDepth[12] 59.9 0.489 0.106 0.495 4.712 Where2comm[25] 52.3 0.473 0.199 0.415 4.712 C2F-Net[21] 62.5 0.487 0.188 0.399 4.712 本文方法 − 64.0 0.460 0.086 0.288 3.505  下载: 导出CSV
下载: 导出CSV
表 2 AeroCollab3D数据集细粒度检测结果
目标类别 mAP↑(%) mATE↓(m) mASE↓ mAOE↓ 小轿车 79.7 0.300 0.096 0.043 卡车 64.2 0.515 0.089 0.049 公交车 57.6 0.493 0.070 0.050 行人 54.7 0.536 0.093 1.011
下载: 导出CSV
表 4 AeroCollab3D数据集细粒度基线对比实验结果
方法 BEV网格大小 car_AP(%) truck_AP(%) bus_AP(%) pedestrian_AP(%) mAP↑(%) 交互传输比 Cost↓ 基线模型 50×50 71.4 57.4 55.0 36.4 55.0 0.0625 2.000 200×200 74.6 63.3 56.2 45.5 58.5 1.0000 6.000 +DSBG − 72.7 62.3 54.8 35.3 56.2 0.1775 3.317 +DSBG+ACFA − 79.7 64.2 57.6 54.7 64.0 0.1787 3.505
下载: 导出CSV
-
[1] ZONG Zhuofan, JIANG Dongzhi, SONG Guanglu, et al. Temporal enhanced training of multi-view 3D object detector via historical object prediction[C]. The 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 3758–3767. doi: 10.1109/ICCV51070.2023.00350. [2] 何江, 喻莞芯, 黄浩, 等. 多无人机分布式感知任务分配-通信基站关联与飞行策略联合优化设计[J]. 电子与信息学报, 2025, 47(5): 1402–1417. doi: 10.11999/JEIT240738.HE Jiang, YU Wanxin, HUANG Hao, et al. Joint task allocation, communication base station association and flight strategy optimization design for distributed sensing unmanned aerial vehicles[J]. Journal of Electronics & Information Technology, 2025, 47(5): 1402–1417. doi: 10.11999/JEIT240738. [3] YANG Dingkang, YANG Kun, WANG Yuzheng, et al. How2comm: Communication-efficient and collaboration-pragmatic multi-agent perception[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 1093. [4] HU Senkang, FANG Zhengru, DENG Yiqin, et al. Collaborative perception for connected and autonomous driving: Challenges, possible solutions and opportunities[J]. IEEE Wireless Communications, 2025, 32(5): 228–234. doi: 10.1109/MWC.002.2400348. [5] LI Xueping, TUPAYACHI J, SHARMIN A, et al. Drone-aided delivery methods, challenge, and the future: A methodological review[J]. Drones, 2023, 7(3): 191. doi: 10.3390/drones7030191. [6] LI Zhenxin, LAN Shiyi, ALVAREZ J M, et al. BEVNeXt: Reviving dense BEV frameworks for 3D object detection[C]. The 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 20113–20123. doi: 10.1109/CVPR52733.2024.01901. [7] WANG Xiaoming, CHEN Hao, CHU Xiangxiang, et al. AODet: Aerial object detection using transformers for foreground regions[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 4106711. doi: 10.1109/TGRS.2024.3407815. [8] WANG Yuchao, WANG Zhirui, CHENG Peirui, et al. AVCPNet: An AAV-vehicle collaborative perception network for 3-D object detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5615916. doi: 10.1109/TGRS.2025.3546669. [9] PHILION J and FIDLER S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3D[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 194–210. doi: 10.1007/978-3-030-58568-6_12. [10] HUANG Junjie, HUANG Guan, ZHU Zheng, et al. BEVDet: High-performance multi-camera 3D object detection in bird-eye-view[EB/OL]. https://arxiv.org/abs/2112.11790, 2021. [11] HUANG Junjie and HUANG Guan. BEVDet4D: Exploit temporal cues in multi-camera 3D object detection[EB/OL]. https://arxiv.org/abs/2203.17054, 2022. [12] LI Yinhao, GE Zheng, YU Guanyi, et al. BEVDepth: Acquisition of reliable depth for multi-view 3D object detection[C]. The 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 1477–1485. doi: 10.1609/aaai.v37i2.25233. [13] WANG Yue, GUIZILINI V C, ZHANG Tianyuan, et al. DETR3D: 3D object detection from multi-view images via 3D-to-2D queries[C]. The 5th Conference on Robot Learning, London, UK, 2022: 180–191. [14] LI Zhiqi, WANG Wenhai, LI Hongyang, et al. BEVFormer: Learning bird's-eye-view representation from LiDAR-camera via spatiotemporal transformers[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(3): 2020–2036. doi: 10.1109/TPAMI.2024.3515454. [15] ZHU Pengfei, ZHENG Jiayu, DU Dawei, et al. Multi-drone-based single object tracking with agent sharing network[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(10): 4058–4070. doi: 10.1109/TCSVT.2020.3045747. [16] CAO Yaru, HE Zhijian, WANG Lujia, et al. VisDrone-DET2021: The vision meets drone object detection challenge results[C]. The 2021 IEEE/CVF International Conference on Computer Vision Workshops, Montreal, Canada, 2021: 2847–2854. doi: 10.1109/ICCVW54120.2021.00319. [17] 姚婷婷, 肇恒鑫, 冯子豪, 等. 上下文感知多感受野融合网络的定向遥感目标检测[J]. 电子与信息学报, 2025, 47(1): 233–243. doi: 10.11999/JEIT240560.YAO Tingting, ZHAO Hengxin, FENG Zihao, et al. A context-aware multiple receptive field fusion network for oriented object detection in remote sensing images[J]. Journal of Electronics & Information Technology, 2025, 47(1): 233–243. doi: 10.11999/JEIT240560. [18] ZHU Xizhou, SU Weijie, LU Lewei, et al. Deformable DETR: Deformable transformers for end-to-end object detection[C]. 9th International Conference on Learning Representations, Vienna, Austria, 2021. [19] KINGMA D P and BA J. Adam: A method for stochastic optimization[C]. 3rd International Conference on Learning Representations, San Diego, USA, 2015. [20] WANG Zhechao, CHENG Peirui, CHEN Mingxin, et al. Drones help drones: A collaborative framework for multi-drone object trajectory prediction and beyond[C]. The 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2024: 2061. [21] CHEN Mingxin, WANG Zhirui, WANG Zhechao, et al. C2F-Net: Coarse-to-fine multidrone collaborative perception network for object trajectory prediction[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 6314–6328. doi: 10.1109/JSTARS.2025.3541249. [22] TIAN Pengju, WANG Zhirui, CHENG Peirui, et al. UCDNet: Multi-UAV collaborative 3-D object detection network by reliable feature mapping[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5602016. doi: 10.1109/TGRS.2024.3517594. [23] CAESAR H, BANKIT V, LANG A H, et al. nuScenes: A multimodal dataset for autonomous driving[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 11618–11628. doi: 10.1109/CVPR42600.2020.01164. [24] 梁燕, 杨会林, 邵凯. 自适应特征选择的车路协同3D目标检测方案[J]. 电子与信息学报, 2025, 47(12): 5214–5225. doi: 10.11999/JEIT250601.LIANG Yan, YANG Huilin, and SHAO Kai. A vehicle-infrastructure cooperative 3D object detection scheme based on adaptive feature selection[J]. Journal of Electronics & Information Technology, 2025, 47(12): 5214–5225. doi: 10.11999/JEIT250601. [25] HU Yue, FANG Shaoheng, LEI Zixing X, et al. Where2comm: Communication-efficient collaborative perception via spatial confidence maps[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 352. doi: 10.5555/3600270.3600622. -

 下载:
下载:




图(4) / 表(4)
计量
- 文章访问数: 847
- HTML全文浏览量: 418
- PDF下载量: 93
- 被引次数: 0
