

Context-Aware Fine-Grained Multimodal Emotion Recognition Based on Mamba
-
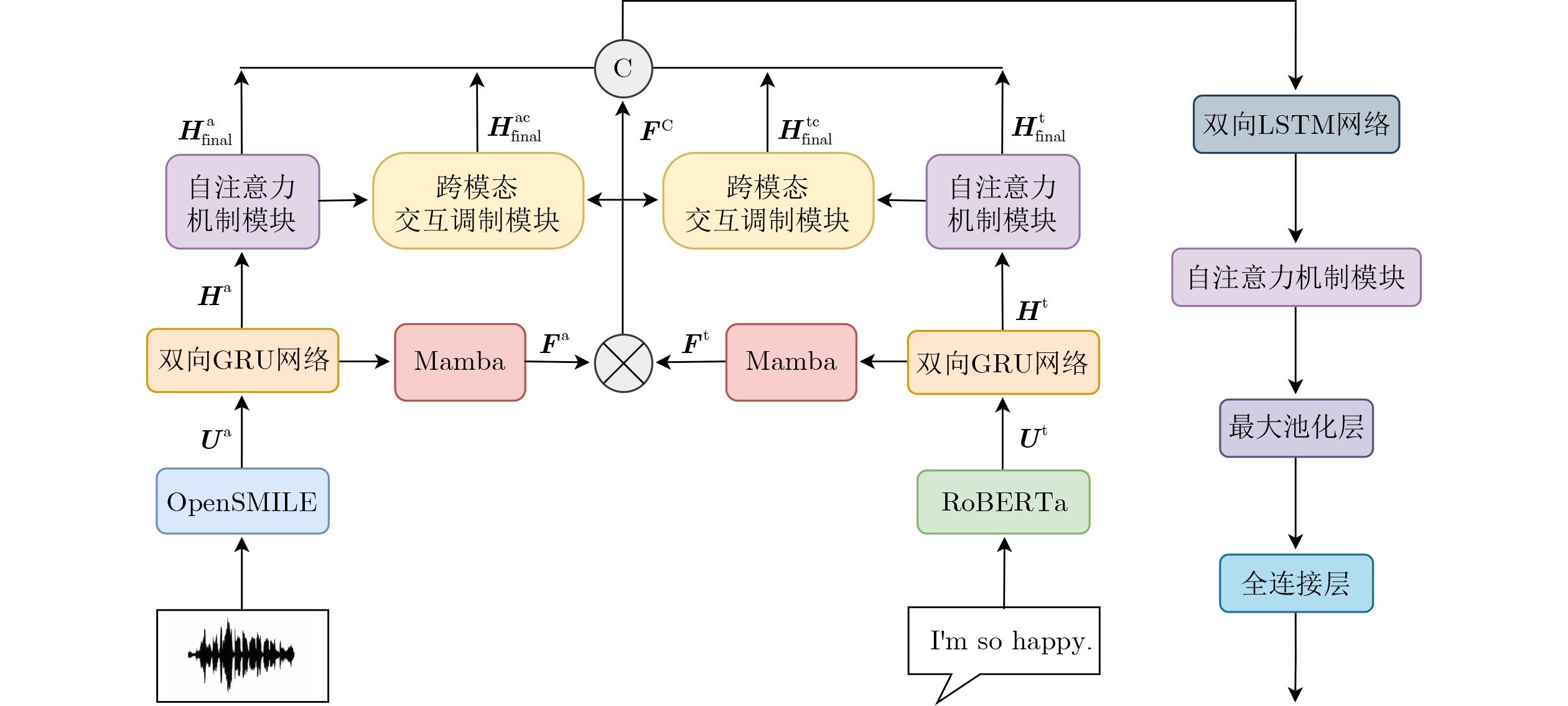
摘要: 当前多模态情感识别方法大多在多模态交互过程中未能充分利用上下文信息,导致对细粒度情感差异的识别不够精准,从而影响了模型在复杂情感分析任务中的表现。为此,该文提出基于Mamba上下文感知细粒度融合的多模态情感识别方法(CA-FGMER-Mamba),该方法通过上下文建模、模态内细粒度筛选和模态间细粒度融合获取高区分度情感分类特征,实现了高质量的情感分类。首先,采用RoBERTa预训练模型对文本模态进行深度编码,采用OpenSMILE工具包提取音频特征并进行特征降维;其次,利用Bi-GRU上下文感知模块有效整合语音和文本模态的时序上下文信息。接着,引入Mamba状态空间模块重新校准语音和文本特征,动态调整不同时间步的特征权重,以突出情感表达的关键信息。在特征融合阶段,设计了细粒度融合策略,通过自注意力机制、高阶外积融合和跨模态交互调制,精细建模模态内与模态间的协同关系。最终,将融合后的特征通过分类网络进行情感预测。在IEMOCAP数据集和MELD数据集上的实验结果表明,CA-FGMER-Mamba方法在情感识别性能方面取得了显著提升,具有优秀的泛化能力和有效性。Abstract:
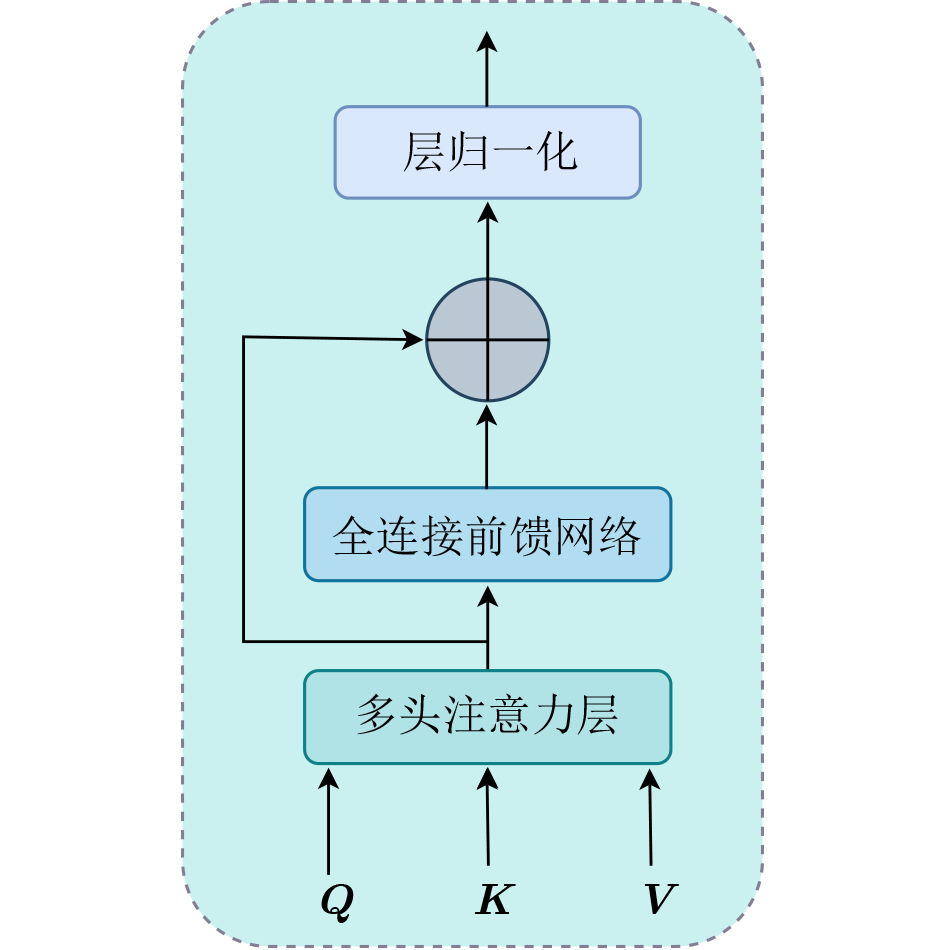
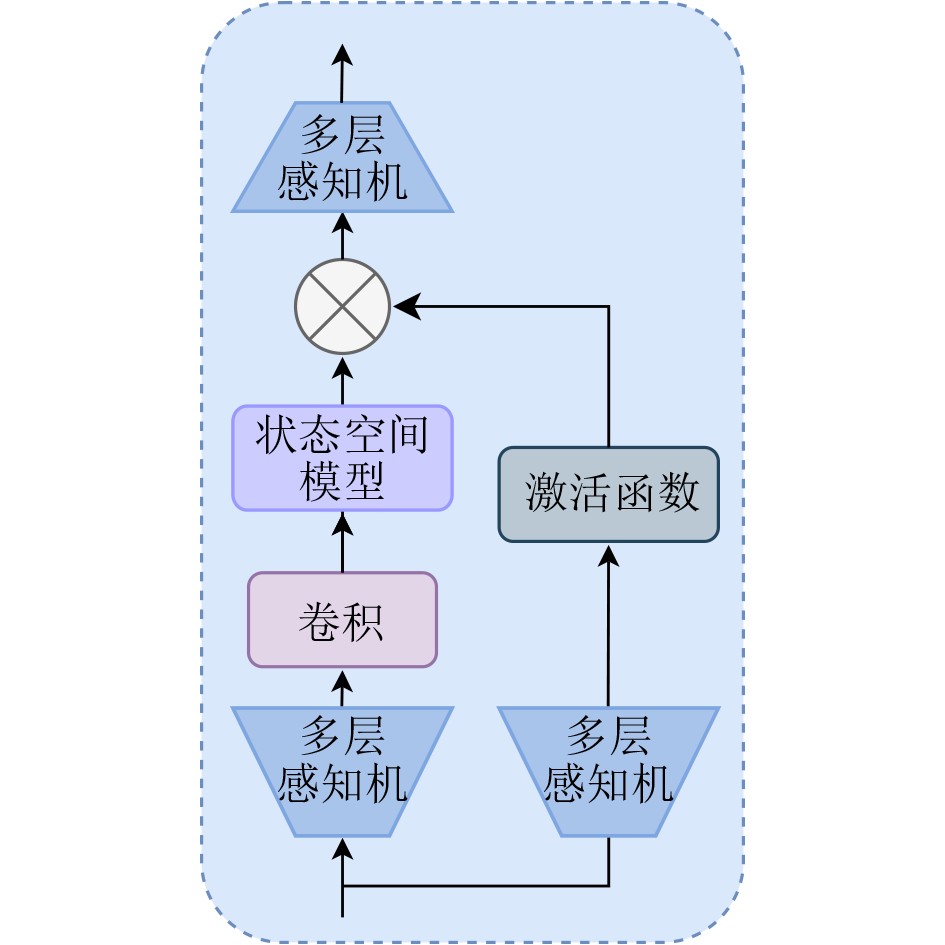
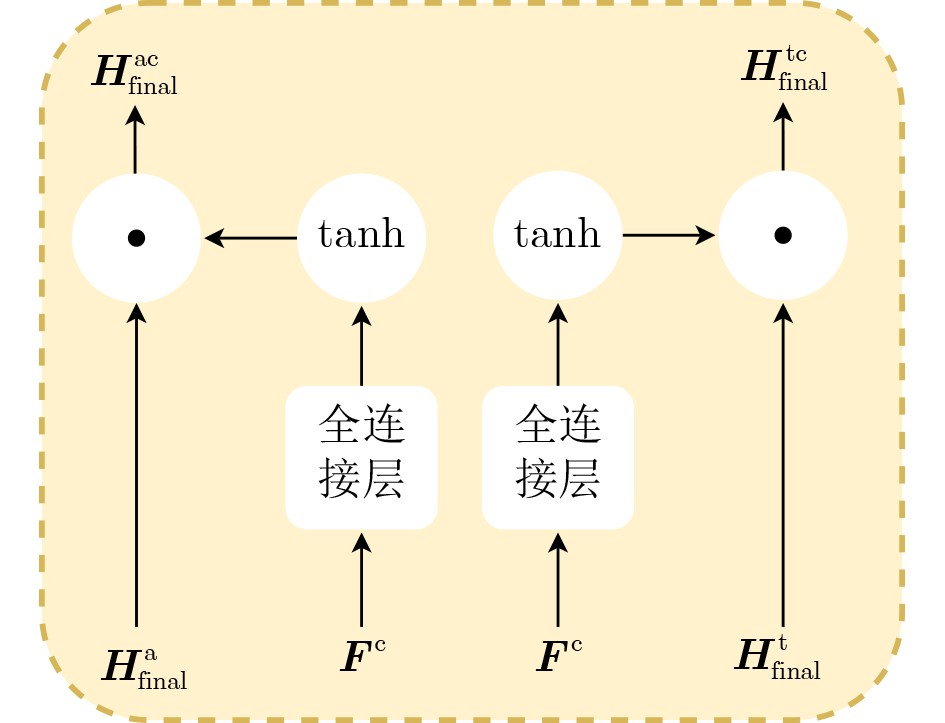
Objective Multimodal Emotion Recognition(MER) aims to infer human emotional states by integrating speech and text signals. Existing MER methods often fail to use temporal and speaker context effectively and lack fine-grained intra- and inter-modal interaction modeling. These limitations reduce the ability to distinguish similar emotions. This study proposes a Context-Aware Fine-Grained Multimodal Emotion Recognition model based on the Mamba State Space Model(SSM), termed CA-FGMER-Mamba, to improve recognition accuracy in complex scenarios. Methods The CA-FGMER-Mamba model consists of five modules. First, text features are encoded using RoBERTa with explicit speaker identity injection and a three-segment contextual input. Audio features are extracted using OpenSMILE and reduced to 512 dimensions. Second, a Bidirectional Gated Recurrent Unit(Bi-GRU) integrates historical and future contextual dependencies. Third, intra-modal fine-grained filtering applies multi-head self-attention to emphasize key emotional cues and suppress redundancy. Fourth, inter-modal fine-grained fusion uses a Mamba SSM module to recalibrate features across time steps. This stage includes higher-order outer-product fusion, mean pooling, and a cross-modal interaction modulation module to adaptively adjust modality contributions. Finally, fused features are processed by a Bi-LSTM, followed by a self-attention layer and a fully connected network for classification. The model is optimized using a joint triplet loss and cross-entropy loss. Results and Discussions Experiments are conducted on the IEMOCAP and MELD datasets. On the IEMOCAP four-class task, CA-FGMER-Mamba achieves a Weighted Accuracy(WA) of 0.781 and an Unweighted Accuracy(UA) of 0.790, outperforming seven representative methods. On the six-class task, the model achieves a Weighted F1-score of 0.703 and shows strong performance in distinguishing similar emotions such as “happy” (0.646) and “excited” (0.803). On the MELD dataset, the model achieves a Weighted F1-score of 0.665, indicating strong generalization. Ablation experiments confirm that combining intra-modal and inter-modal fusion improves performance. Conclusions The CA-FGMER-Mamba model addresses key limitations in existing MER methods by integrating context-aware modeling with fine-grained intra- and inter-modal fusion based on the Mamba SSM. The Bi-GRU with speaker identity enhances modeling of temporal and role-related context and alleviates recency bias. Intra-modal self-attention and Mamba-based inter-modal recalibration improve feature extraction and cross-modal interaction modeling, enabling accurate discrimination of similar emotions. The cross-modal interaction modulation module adaptively adjusts modality contributions and enhances robustness. Experimental results demonstrate strong performance in WA, UA, and Weighted F1-score, with good generalization. Future work will explore multi-scale interaction mechanisms, multi-task learning strategies, and noise-aware modeling to further improve fusion accuracy and robustness. -
Key words:
- Multimodal emotion recognition /
- Fine-grained fusion /
- Context-aware
-
表 1 在IEMOCAP四分类任务上指标值对比
方法 WA UA Shared-weights Transformer 0.768 0.771 Contrastive regularization 0.761 0.775 bc-LSTM+MCNN 0.750 0.751 MAFN 0.756 0.714 Bayesian co-attention 0.755 0.770 ASR Error Adaptation 0.764 0.769 ISSA-BiGRU-MHA 0.765 0.771 CA-FGMER-Mamba 0.781 0.790  下载: 导出CSV
下载: 导出CSV
表 2 在IEMOCAP六分类任务上指标值对比
方法 高兴 悲伤 中性 生气 激动 恐惧 Weighted-F1 SACCMA 0.386 0.865 0.649 0.646 0.745 0.630 0.671 COGMEN 0.519 0.817 0.686 0.660 0.753 0.582 0.676 MM-DFN 0.422 0.790 0.664 0.698 0.756 0.663 0.682 GraphCFC 0.431 0.850 0.647 0.714 0.789 0.637 0.689 MultiEMO(A+T) 0.616 0.802 0.640 0.733 0.664 0.692 0.692 DER-GCN 0.588 0.798 0.615 0.721 0.733 0.678 0.694 CA-FGMER-Mamba 0.646 0.828 0.679 0.673 0.803 0.626 0.703
下载: 导出CSV
表 3 在MELD数据集上指标值对比
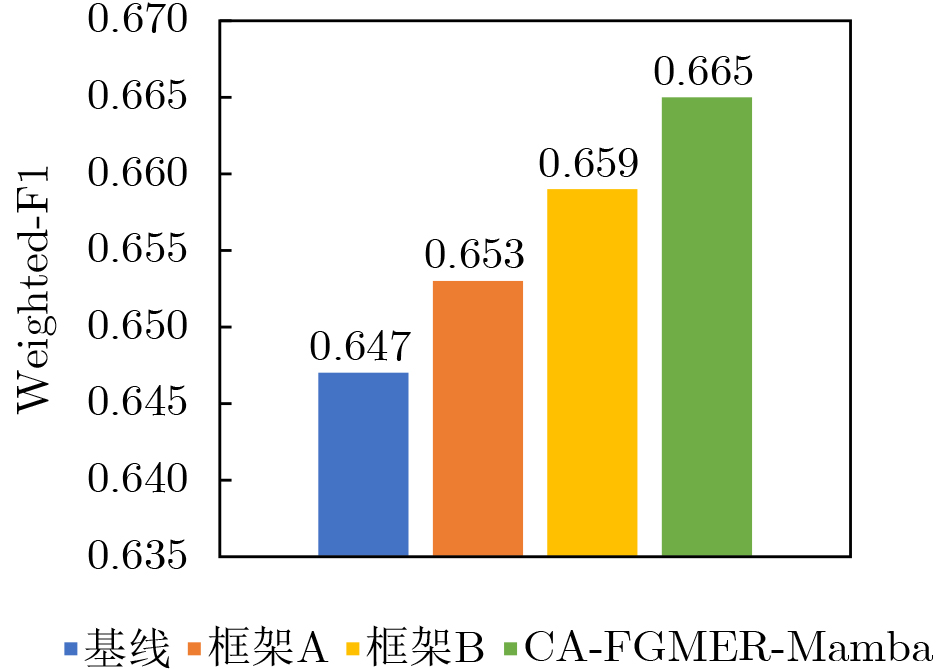
方法 Weighted-F1 年份 EmoCaps 0.640 2022 SMIN 0.645 2023 Prompt Learning 0.654 2023 HCAM 0.658 2023 BSSMPF(A+T) 0.656 2024 DEDNet(A+T) 0.653 2024 CA-FGMER-Mamba 0.665
下载: 导出CSV
表 4 IEMOCAP数据集六分类情感识别准确率及综合表现
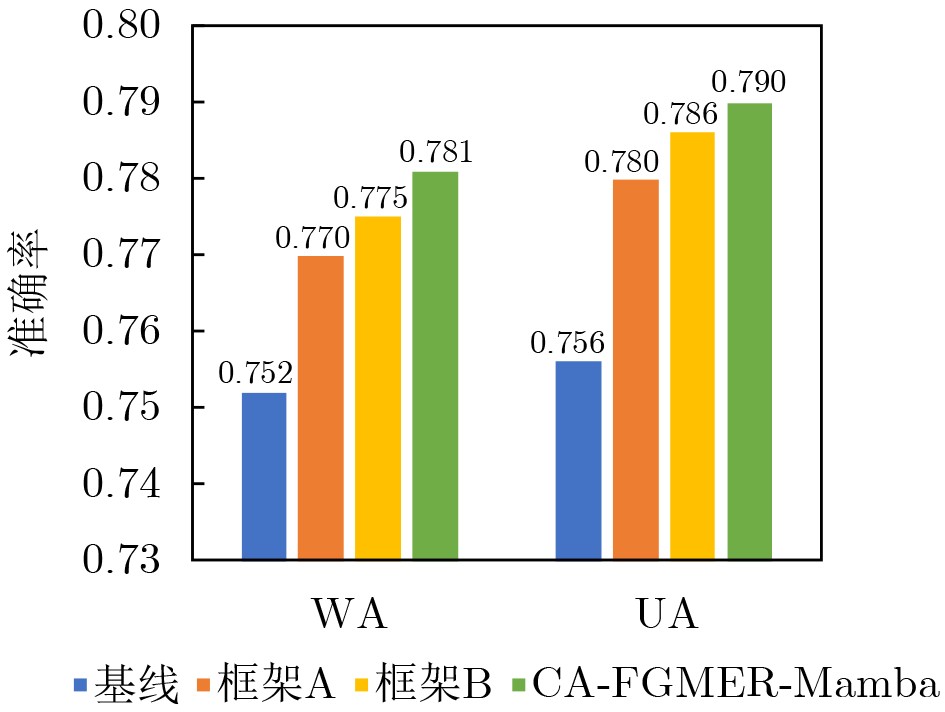
模型 高兴 悲伤 中性 生气 激动 恐惧 综合 基线 0.521 0.791 0.670 0.656 0.756 0.624 0.679 框架A 0.478 0.796 0.676 0.677 0.762 0.629 0.682 框架B 0.662 0.812 0.652 0.651 0.753 0.645 0.694 CA-FGMER-Mamba 0.646 0.828 0.679 0.673 0.803 0.626 0.703
下载: 导出CSV
-
[1] 孙强, 王姝玉. 结合时间注意力机制和单模态标签自动生成策略的自监督多模态情感识别[J]. 电子与信息学报, 2024, 46(2): 588–601. doi: 10.11999/JEIT231107.SUN Qiang and WANG Shuyu. Self-supervised multimodal emotion recognition combining temporal attention mechanism and unimodal label automatic generation strategy[J]. Journal of Electronics & Information Technology, 2024, 46(2): 588–601. doi: 10.11999/JEIT231107. [2] 刘佳, 宋泓, 陈大鹏, 等. 非语言信息增强和对比学习的多模态情感分析模型[J]. 电子与信息学报, 2024, 46(8): 3372–3381. doi: 10.11999/JEIT231274.LIU Jia, SONG Hong, CHEN Dapeng, et al. A multimodal sentiment analysis model enhanced with non-verbal information and contrastive learning[J]. Journal of Electronics & Information Technology, 2024, 46(8): 3372–3381. doi: 10.11999/JEIT231274. [3] 薛珮芸, 戴书涛, 白静, 等. 借助语音和面部图像的双模态情感识别[J]. 电子与信息学报, 2024, 46(12): 4542–4552. doi: 10.11999/JEIT240087.XUE Peiyun, DAI Shutao, BAI Jing, et al. Emotion recognition with speech and facial images[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4542–4552. doi: 10.11999/JEIT240087. [4] LIU Yuanyuan, WEI Lin, LIU Kejun, et al. Leveraging eye movement for instructing robust video-based facial expression recognition[J]. IEEE Transactions on Affective Computing, 2025, 16(4): 3404–3420. doi: 10.1109/TAFFC.2025.3599859. [5] LIU Yuanyuan, ZHANG Haoyu, ZHAN Yibing, et al. Noise-resistant multimodal Transformer for emotion recognition[J]. International Journal of Computer Vision, 2025, 133(5): 3020–3040. doi: 10.1007/s11263-024-02304-3. [6] LIU Yang, SUN Haoqin, GUAN Wenbo, et al. Multi-modal speech emotion recognition using self-attention mechanism and multi-scale fusion framework[J]. Speech Communication, 2022, 139: 1–9. doi: 10.1016/j.specom.2022.02.006. [7] SHANG Yanan and FU Tianqi. Multimodal fusion: A study on speech-text emotion recognition with the integration of deep learning[J]. Intelligent Systems with Applications, 2024, 24: 200436. doi: 10.1016/j.iswa.2024.200436. [8] QIAN Fan and HAN J. Contrastive regularization for multimodal emotion recognition using audio and text[EB/OL]. (2022-11-20). https://doi.org/10.48550/arXiv.2211.10885, 2022. [9] SHI Tao and HUANG Shaolun. MultiEMO: An attention-based correlation-aware multimodal fusion framework for emotion recognition in conversations[C]. The 61st Annual Meeting of the Association for Computational Linguistics, Toronto, Canada, 2023: 14752–14766. doi: 10.18653/v1/2023.acl-long.824. [10] ZHAO Zihan, WANG Yu, and WANG Yanfeng. Knowledge-aware Bayesian co-attention for multimodal emotion recognition[C]. The ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10095798. [11] LIN Binghuai and WANG Liyuan. Robust multi-modal speech emotion recognition with ASR error adaptation[C]. ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10094839. [12] GUO Lili, SONG Yikang, and DING Shifei. Speaker-aware cognitive network with cross-modal attention for multimodal emotion recognition in conversation[J]. Knowledge-Based Systems, 2024, 296: 111969. doi: 10.1016/j.knosys.2024.111969. [13] JOSHI A, BHAT A, JAIN A, et al. COGMEN: COntextualized GNN based multimodal emotion recognition[C]. The 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, USA, 2022: 4148–4164. doi: 10.18653/v1/2022.naacl-main.306. [14] GU A and DAO T. Mamba: Linear-time sequence modeling with selective state spaces[C]. The 1st Conference on Language Modeling, Philadelphia, USA, 2024. [15] CHO K, VAN MERRIËNBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]. The 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 2014: 1724–1734. doi: 10.3115/v1/D14-1179. [16] PORJAZOVSKI D, GROSZ T, and KURIMO M. Improved spoken emotion recognition with combined segment-based processing and triplet loss[C]. The 7th International Conference on Natural Language and Speech Processing (ICNLSP 2024), Trento, Italy, 2024: 47–54. [17] BUSSO C, BULUT M, LEE C C, et al. IEMOCAP: Interactive emotional dyadic motion capture database[J]. Language Resources and Evaluation, 2008, 42(4): 335–359. doi: 10.1007/s10579-008-9076-6. [18] PORIA S, HAZARIKA D, MAJUMDER N, et al. MELD: A multimodal multi-party dataset for emotion recognition in conversations[C]. The 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019: 527–536. doi: 10.18653/v1/P19-1050. [19] WANG Yuhua, SHEN Guang, XU Yuezhu, et al. Learning mutual correlation in multimodal transformer for speech emotion recognition[C]. The Interspeech 2021, Brno, Czechia, 2021: 4518–4522. doi: 10.21437/Interspeech.2021-2004. [20] ZHANG Junfeng, XING Lining, TAN Zhen, et al. Multi-head attention fusion networks for multi-modal speech emotion recognition[J]. Computers & Industrial Engineering, 2022, 168: 108078. doi: 10.1016/j.cie.2022.108078. [21] HU Dou, HOU Xiaolong, WEI Lingwei, et al. MM-DFN: Multimodal dynamic fusion network for emotion recognition in conversations[C]. ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, Singapore, 2022: 7037–7041. doi: 10.1109/ICASSP43922.2022.9747397. [22] LI Jiang, WANG Xiaoping, LV Guoqing, et al. GraphCFC: A directed graph based cross-modal feature complementation approach for multimodal conversational emotion recognition[J]. IEEE Transactions on Multimedia, 2024, 26: 77–89. doi: 10.1109/TMM.2023.3260635. [23] AI Wei, SHOU Yuntao, MENG Tao, et al. DER-GCN: Dialog and event relation-aware graph convolutional neural network for multimodal dialog emotion recognition[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(3): 4908–4921. doi: 10.1109/TNNLS.2024.3367940. [24] LI Zaijing, TANG Fengxiao, ZHAO Ming, et al. EmoCaps: Emotion capsule based model for conversational emotion recognition[C]. The Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 2022: 1610–1618. doi: 10.18653/v1/2022.findings-acl.126. [25] LIAN Zheng, LIU Bin, and TAO Jianhua. SMIN: Semi-supervised multi-modal interaction network for conversational emotion recognition[J]. IEEE Transactions on Affective Computing, 2023, 14(3): 2415–2429. doi: 10.1109/TAFFC.2022.3141237. [26] JEONG E, KIM G, and KANG S. Multimodal prompt learning in emotion recognition using context and audio information[J]. Mathematics, 2023, 11(13): 2908. doi: 10.3390/math11132908. [27] DUTTA S and GANAPATHY S. HCAM - hierarchical cross attention model for multi-modal emotion recognition[EB/OL]. (2023-04-14). https://doi.org/10.48550/arXiv.2304.06910, 2023. [28] SHOU Yuntao, MENG Tao, AI Wei, et al. Revisiting multi-modal emotion learning with broad state space models and probability-guidance fusion[C]. The European Conference on Machine Learning and Knowledge Discovery in Databases, Research Track, Porto, Portugal, 2025: 509–525. doi: 10.1007/978-3-032-06078-5_29. [29] WANG Ye, ZHANG Wei, LIU Ke, et al. Dynamic emotion-dependent network with relational subgraph interaction for multimodal emotion recognition[J]. IEEE Transactions on Affective Computing, 2025, 16(2): 712–725. doi: 10.1109/taffc.2024.3461148. -

 下载:
下载:


图(6) / 表(4)
计量
- 文章访问数: 596
- HTML全文浏览量: 246
- PDF下载量: 80
- 被引次数: 0
