

Spherical Geometry-guided and Frequency-Enhanced Segment Anything Model for 360° Salient Object Detection
-
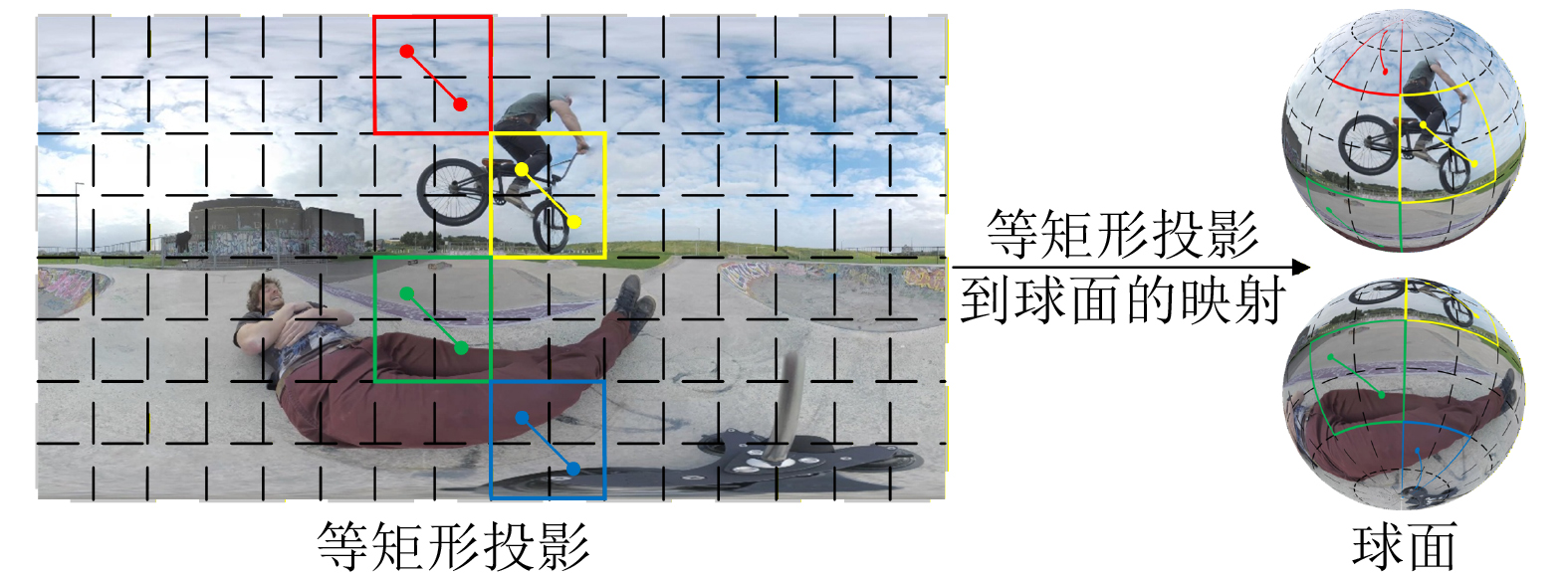
摘要: 分割一切模型(SAM)作为通用分割大模型,在多类二维视觉任务中展现出强大迁移能力,但原生SAM主要针对2D平面图像设计,缺乏对360°全景图像球面几何特性的建模能力,难以直接应用于360°全景图像显著目标检测(360° SOD)。为了将SAM应用于360° SOD并解决其不足,该文提出一种采用球面几何引导和频率增强SAM的360° SOD网络,具体包括多认知适配器(MCA),受人类视觉感知机制的启发,通过引入多尺度、多路径特征建模提升全景图像的上下文感知能力;球面几何引导注意力(SGGA),利用球面几何先验缓解等矩形投影中的畸变与边界不连续性;以及空频域联合感知模块(SFJPM),结合多尺度空洞卷积与频域注意力,增强全局与局部信息的协同建模,提升360° SOD性能。该文在现有的两个公开360° SOD数据集(360-SOD, 360-SSOD)上进行了大量实验,结果表明,所提方法在客观指标和主观结果上的表现均优于现有的7种代表性2D SOD方法和7种360° SOD方法。Abstract:
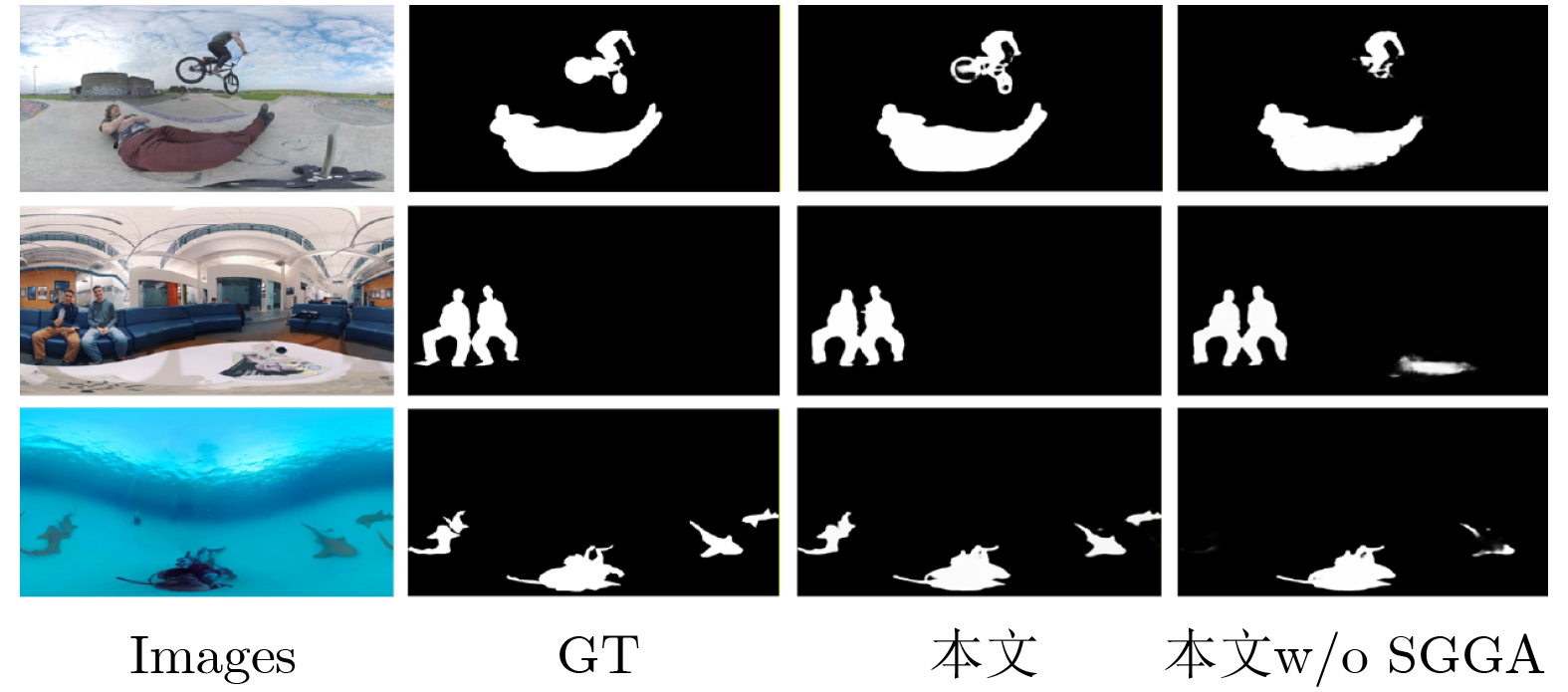
Objective With the rapid development of Virtual Reality (VR) and Augmented Reality (AR) technologies and the increasing demand for omnidirectional visual applications, accurate salient object detection in complex 360° scenes has become critical for system stability and intelligent decision-making. The Segment Anything Model (SAM) demonstrates strong transferability across two-dimensional vision tasks. However, it is primarily designed for planar images and lacks explicit modeling of spherical geometry, which limits its direct application to 360° Salient Object Detection (360° SOD). To address this limitation, this study integrates the generalization capability of SAM with spherical-aware multi-scale geometric modeling to improve 360° SOD. Specifically, a Multi-Cognitive Adapter (MCA), Spherical Geometry Guided Attention (SGGA), and Spatial-Frequency Joint Perception Module (SFJPM) are proposed to enhance multi-scale structural representation, mitigate projection-induced geometric distortions and boundary discontinuities, and strengthen joint global and local feature modeling. Methods The proposed 360° SOD framework is built on SAM and consists of an image encoder and a mask decoder. During encoding, spherical geometry modeling is incorporated into patch embedding by mapping image patches onto a unit sphere and explicitly modeling spatial relationships between patch centers. This strategy injects geometric priors into the attention mechanism, which improves sensitivity to non-uniform geometric characteristics and reduces information loss caused by omnidirectional projection distortion. The encoder adopts a partial freezing strategy and is organized into four stages, each containing three encoder blocks. Each block integrates the MCA for multi-scale contextual fusion and the SGGA to model long-range dependencies in spherical space. Multi-level features are concatenated along the channel dimension to form a unified representation. The representation is then refined by the SFJPM, which jointly captures spatial structures and frequency-domain global information. The fused features are subsequently fed into the SAM mask decoder. Saliency maps are optimized under ground-truth supervision to achieve accurate object localization and boundary refinement. Results and Discussions Experiments are conducted using the PyTorch framework on an RTX 3090 GPU with an input resolution of 512 × 512. Evaluations are performed on two public datasets, 360-SOD and 360-SSOD, and compared with 14 state-of-the-art methods. The proposed approach consistently achieves superior performance across six evaluation metrics. On the 360-SOD dataset, the model achieves a Mean Absolute Error (MAE) of 0.015 2 and a maximum F-measure of 0.849 2, outperforming representative methods such as MDSAM and DPNet. Qualitative results show that the proposed method produces saliency maps that are highly consistent with ground-truth annotations. The model handles challenging scenarios effectively, including projection distortion, boundary discontinuity, multi-object scenes, and complex backgrounds. Ablation studies further show that MCA, SGGA, and SFJPM each contribute to performance improvement and operate complementarily. Conclusions This study proposes an SAM-based framework for 360° salient object detection that jointly addresses multi-scale representation, spherical distortion awareness, and spatial-frequency feature modeling. The MCA improves multi-scale feature fusion, the SGGA compensates for Equirectangular Projection (ERP)-induced geometric distortion, and the SFJPM enhances long-range dependency modeling. Extensive experiments verify the effectiveness and feasibility of applying SAM to 360° SOD. Future research will extend this framework to omnidirectional video and multi-modal scenarios to further improve spatiotemporal modeling and scene understanding. -
表 1 360-SOD和360-SOD数据集上各模型客观指标对比
类型 方法 360-SOD 数据集 360-SSOD 数据集 MAE↓ maxF↑ meanF↑ maxE↑ meanE↑ Sm↑ MAE↓ maxF↑ meanF↑ maxE↑ meanE↑ Sm↑ 2D
SODLDF[4] 0.0234 0.7052 0.6892 0.8659 0.8557 0.8557 0.0315 0.6105 0.5942 0.8464 0.8222 0.7376 VST[5] 0.0260 0.6941 0.6332 0.8897 0.8361 0.7808 0.0343 0.5975 0.5282 0.8497 0.7681 0.7453 PGNet[8] 0.0254 0.7221 0.7144 0.8700 0.8440 0.8048 0.0316 0.5969 0.5519 0.8318 0.7404 0.6993 BBRF[9] 0.0258 0.6571 0.6532 0.8545 0.8510 0.7563 0.0430 0.5155 0.5014 0.8043 0.7991 0.6679 CeleNet[6] 0.0230 0.7399 0.7280 0.8914 0.8859 0.8095 0.0291 0.6587 0.6513 0.8632 0.8487 0.7592 MDSAM[2] 0.0163 0.8440 0.8009 0.9329 0.9214 0.8721 0.0266 0.6912 0.6650 0.8648 0.8444 0.7853 DC-Net-S[7] 0.0202 0.7539 0.7417 0.8964 0.8697 0.8332 0.0265 0.6342 0.6169 0.8456 0.8037 0.7509 360°
SODFANet[18] 0.0258 0.6874 0.6631 0.8807 0.8599 0.7778 0.0406 0.6371 0.5753 0.8579 0.7752 0.7330 MPFRNet[19] 0.0191 0.7653 0.7556 0.8854 0.8750 0.8416 - - - - - - LDNet[23] 0.0289 0.6562 0.6391 0.8655 0.8414 0.7679 0.0342 0.5862 0.5672 0.8390 0.8187 0.7245 DATFormer[24] 0.0179 0.7750 0.7614 0.8989 0.8857 0.8387 0.0287 0.6410 0.6056 0.8631 0.8168 0.7599 ACoNet[30] 0.0181 0.7893 0.7815 0.9141 0.9043 0.8493 0.0288 0.6641 0.6564 0.8695 0.8632 0.7796 DSANet[25] 0.0196 0.7843 0.7719 0.9080 0.9002 0.8463 0.0292 0.6743 0.6594 0.8664 0.8354 0.7804 DPNet[26] 0.0189 0.8035 0.7864 0.9206 0.9096 0.8487 0.0283 0.6690 0.6561 0.8715 0.8512 0.7677 本文 0.0152 0.8492 0.8334 0.9460 0.9393 0.8768 0.0252 0.6998 0.6800 0.8723 0.8555 0.7912  下载: 导出CSV
下载: 导出CSV
表 2 360-SOD数据集上不同模型组合的客观指标对比
Baseline MCA SGGA SFJPM MAE↓ maxF↑ meanF↑ maxE↑ meanE↑ Sm↑ √ 0.0189 0.8166 0.7840 0.9223 0.9121 0.8574 √ √ 0.0169 0.8293 0.7980 0.9213 0.9120 0.8614 √ √ 0.0175 0.8164 0.7905 0.9246 0.9154 0.8517 √ √ 0.0172 0.8207 0.7894 0.9252 0.9156 0.8583 √ √ √ 0.0161 0.8339 0.7988 0.9268 0.9082 0.8715 √ √ √ 0.0157 0.8359 0.8119 0.9372 0.9261 0.8730 √ √ √ 0.0162 0.8219 0.8008 0.9145 0.9052 0.8695 √ √ √ √ 0.0152 0.8493 0.8306 0.9460 0.9393 0.8768
下载: 导出CSV
表 4 360-SOD数据集上SFJPM模块的消融实验
模型组成 MAE↓ maxF↑ meanF↑ maxE↑ meanE↑ Sm↑ 本文 w/o FFT 0.0158 0.8265 0.8148 0.9297 0.9086 0.8683 本文 w/o DC 0.0157 0.8212 0.8051 0.9277 0.9112 0.8744 本文 0.0152 0.8492 0.8334 0.9460 0.9393 0.8768
下载: 导出CSV
表 5 各模型复杂度对比
复杂度指标 LDF[4] VST[5] PGNet[8] BBRF[9] CeleNet[6] MDSAM[2] DC-Net-S[7] 本文 FLOPs(G) 15.5724 31.0892 42.9705 67.1505 11.6932 124.6865 211.2706 248.3677 Params(M) 25.1501 83.0549 72.6664 74.4025 25.4528 100.2057 509.6138 105.6467 InferTime(ms) 218.1235 19.9368 98.0829 138.7012 14.2027 36.2441 42.5081 43.8720 复杂度指标 FANet[18] MPFRNet[19] LDNet*[23] DATFormer[24] ACoNet[30] DSANet[25] DPNet[26] 本文 FLOPs(G) 340.9447 - 3.4 38.1789 81.2432 66.4029 22.4106 248.3677 Params(M) 25.3993 - 2.9 29.5681 24.1538 24.5739 78.4854 105.6467 InferTime(ms) 180.5596 - - 24.4292 50.6232 45.4815 68.5605 43.8720 注:“-”表示因没有源代码而无法测试的值,“*”表示从原论文中获取的数值。
下载: 导出CSV
-
[1] CUI Ruikai, HE Siyuan, and QIU Shi. Adaptive low rank adaptation of segment anything to salient object detection[J]. arXiv preprint arXiv: 2308.05426, 2023. doi: 10.48550/arXiv.2308.05426. [2] GAO Shixuan, ZHANG Pingping, YAN Tianyu, et al. Multi-scale and detail-enhanced segment anything model for salient object detection[C]. The 32nd ACM International Conference on Multimedia, Melbourne, Australia, 2024: 9894–9903. doi: 10.1145/3664647.3680650. [3] LIU Zhengyi, DENG Sheng, WANG Xinrui, et al. SSFam: Scribble supervised salient object detection family[J]. IEEE Transactions on Multimedia, 2025, 27: 1988–2000. doi: 10.1109/TMM.2025.3543092. [4] WEI Jun, WANG Shuhui, WU Zhe, et al. Label decoupling framework for salient object detection[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 13022–13031. doi: 10.1109/CVPR42600.2020.01304. [5] LIU Nian, ZHANG Ni, WAN Kaiyuan, et al. Visual saliency transformer[C]. The IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 4702–4712. doi: 10.1109/ICCV48922.2021.00468. [6] LI Gongyang, BAI Zhen, LIU Zhi, et al. Salient object detection in optical remote sensing images driven by transformer[J]. IEEE Transactions on Image Processing, 2023, 32: 5257–5269. doi: 10.1109/TIP.2023.3314285. [7] ZHU Jiayi, QIN Xuebin, and ELSADDIK A. DC-Net: Divide-and-conquer for salient object detection[J]. Pattern Recognition, 2025, 157: 110903. doi: 10.1016/j.patcog.2024.110903. [8] XIE Chenxi, XIA Changqun, MA Mingcan, et al. Pyramid grafting network for one-stage high resolution saliency detection[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 11707–11716. doi: 10.1109/CVPR52688.2022.01142. [9] MA Mingcan, XIA Changqun, XIE Chenxi, et al. Boosting broader receptive fields for salient object detection[J]. IEEE Transactions on Image Processing, 2023, 32: 1026–1038. doi: 10.1109/TIP.2022.3232209. [10] KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[C]. The IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 3992–4003. doi: 10.1109/ICCV51070.2023.00371. [11] HOULSBY N, GIURGIU A, JASTRZEBSKI S, et al. Parameter-efficient transfer learning for NLP[C]. The 36th International Conference on Machine Learning, Long Beach, USA, 2019: 2790–2799. [12] HU E, Shen Yelong, WALLIS P, et al. LoRA: Low-rank adaptation of large language models[C]. 10th International Conference on Learning Representations, OpenReview. net, 2022. [13] ZHENG Linghao, PU Xinyang, ZHANG Su, et al. Tuning a SAM-based model with multicognitive visual adapter to remote sensing instance segmentation[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 2737–2748. doi: 10.1109/JSTARS.2024.3504409. [14] LI Jia, SU Jinming, XIA Changqun, et al. Distortion-adaptive salient object detection in 360° omnidirectional images[J]. IEEE Journal of Selected Topics in Signal Processing, 2020, 14(1): 38–48. doi: 10.1109/JSTSP.2019.2957982. [15] MA Guangxiao, LI Shuai, CHEN Chenglizhao, et al. Stage-wise salient object detection in 360° omnidirectional image via object-level semantical saliency ranking[J]. IEEE Transactions on Visualization and Computer Graphics, 2020, 26(12): 3535–3545. doi: 10.1109/TVCG.2020.3023636. [16] WEN Hongfa, ZHU Zunjie, ZHOU Xiaofei, et al. Consistency perception network for 360° omnidirectional salient object detection[J]. Neurocomputing, 2025, 620: 129243. doi: 10.1016/j.neucom.2024.129243. [17] ZHANG Yi, HAMIDOUCHE W, and DEFORGES O. Channel-spatial mutual attention network for 360° salient object detection[C]. 2022 26th International Conference on Pattern Recognition, Montreal, Canada, 2022: 3436–3442. doi: 10.1109/ICPR56361.2022.9956354. [18] HUANG Mengke, LIU Zhi, LI Gongyang, et al. FANet: Features adaptation network for 360° omnidirectional salient object detection[J]. IEEE Signal Processing Letters, 2020, 27: 1819–1823. doi: 10.1109/LSP.2020.3028192. [19] CONG Runmin, HUANG Ke, LEI Jianjun, et al. Multi-projection fusion and refinement network for salient object detection in 360° omnidirectional image[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(7): 9495–9507. doi: 10.1109/TNNLS.2022.3233883. [20] ZHANG Jie, ZHANG Qiudan, SHEN Xuelin, et al. Salient object detection on 360° omnidirectional image with bi-branch hybrid projection network[C]. 2023 IEEE 25th International Workshop on Multimedia Signal Processing (MMSP), Poitiers, France, 2023: 1–5. doi: 10.1109/MMSP59012.2023.10337695. [21] HE Zhentao, SHAO Feng, CHEN Gang, et al. SCFANet: Semantics and context feature aggregation network for 360° salient object detection[J]. IEEE Transactions on Multimedia, 2024, 26: 2276–2288. doi: 10.1109/TMM.2023.3293994. [22] HE Zhentao, SHAO Feng, XIE Zhengxuan, et al. SIHENet: Semantic interaction and hierarchical embedding network for 360° salient object detection[J]. IEEE Transactions on Instrumentation and Measurement, 2025, 74: 5003815. doi: 10.1109/TIM.2024.3507047. [23] HUANG Mengke, LI Gongyang, LIU Zhi, et al. Lightweight distortion-aware network for salient object detection in omnidirectional images[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(10): 6191–6197. doi: 10.1109/TCSVT.2023.3253685. [24] ZHAO Yinjie, ZHAO Lichen, YU Qian, et al. Distortion-aware transformer in 360° salient object detection[C]. The 31st ACM International Conference on Multimedia, Ottawa, Canada, 2023: 499–508. doi: 10.1145/3581783.3612025. [25] 陈晓雷, 张学功, 杜泽龙, 等. 面向360°全景图像显著目标检测的畸变语义聚合网络[J]. 中国图象图形学报, 2025, 30(7): 2451–2467. doi: 10.11834/jig.240371.CHEN Xiaolei, ZHANG Xuegong, DU Zelong, et al. Distortion semantic aggregation network for salient object detection in 360° omnidirectional images[J]. Journal of Image and Graphics, 2025, 30(7): 2451–2467. doi: 10.11834/jig.240371. [26] 陈晓雷, 杜泽龙, 张学功, 等. 畸变自适应与位置感知的360°全景图像显著目标检测网络[J]. 中国图象图形学报, 2025, 30(8): 2758–2774. doi: 10.11834/jig.240592.CHEN Xiaolei, DU Zelong, ZHANG Xuegong, et al. Distortion-adaptive and position-aware network for salient object detection in 360° omnidirectional image[J]. Journal of Image and Graphics, 2025, 30(8): 2758–2774. doi: 10.11834/jig.240592. [27] WU Junjie, XIA Changqun, YU Tianshu, et al. View-aware salient object detection for 360° omnidirectional image[J]. IEEE Transactions on Multimedia, 2023, 25: 6471–6484. doi: 10.1109/TMM.2022.3209015. [28] DAI Haowei, BAO Liuxin, SHEN Kunye, et al. 360° omnidirectional salient object detection with multi-scale interaction and densely-connected prediction[C]. 12th International Conference on Image and Graphics, Nanjing, China, 2023: 427–438. doi: 10.1007/978-3-031-46305-1_35. [29] CHEN Gang, SHAO Feng, CHAI Xiongli, et al. Multi-stage salient object detection in 360° omnidirectional image using complementary object-level semantic information[J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2024, 8(1): 776–789. doi: 10.1109/TETCI.2023.3259433. [30] 陈晓雷, 王兴, 张学功, 等. 面向360度全景图像显著目标检测的相邻协调网络[J]. 电子与信息学报, 2024, 46(12): 4529–4541. doi: 10.11999/JEIT240502.CHEN Xiaolei, WANG Xing, ZHANG Xuegong, et al. Adjacent coordination network for salient object detection in 360 degree omnidirectional images[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4529–4541. doi: 10.11999/JEIT240502. [31] YUN I, SHIN C, LEE H, et al. EGformer: Equirectangular geometry-biased transformer for 360 depth estimation[C]. The IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 6078–6089. doi: 10.1109/ICCV51070.2023.00561. -


 下载:
下载:









图(10) / 表(5)
计量
- 文章访问数: 649
- HTML全文浏览量: 308
- PDF下载量: 116
- 被引次数: 0
