

Prior-guided Temporal Fusion Method for Multi-UAV Cooperative Obstacle-avoidance Route Planning
-
摘要: 针对多无人机自主协同避障航路规划任务中,传统多智能体强化学习算法存在的收敛速度慢,无人机协同性不足等问题,该文提出一种先验引导的时序融合价值分解算法(PGL-QMIX)。该方法在离线阶段利用A星(A*)算法生成全局参考路径,并在在线决策中仅提取智能体感知范围内的局部路径片段与几何评分作为弱先验,引导个体策略在部分可观测环境下实现稳定探索与协同避障。同时,设计了双重长短期记忆网络(LSTM)架构,用于建模先验知识与实时状态的时序依赖关系。并对各无人机的动作价值函数进行动态加权融合与自适应优化,提升系统的环境适应性与多无人机协同的稳定性。实验结果表明,所提方法在三维栅格场景中,相较于同场景下次优结果,所提方法的收敛步数分别减少3.0%, 7.2%和7.4%,稳态任务成功率分别提升1.26, 4.41和8.12个百分点,平均航路长度分别缩短6.2%, 8.5%和10.0%,验证了该方法在多无人机自主协同避障航路规划中的有效性与稳定性。Abstract:
Objective Traditional multi-agent reinforcement learning methods for multi-Unmanned Aerial Vehicle(UAV) cooperative obstacle-avoidance route planning in cluttered 3D environments often suffer from slow convergence, weak coordination, and limited global awareness under partial observability. To address these limitations, this paper proposes a prior-guided temporal fusion value-decomposition framework, termed Prior-Guided-LSTM-QMIX (PGL-QMIX). The method uses local heuristic scores derived from offline A* reference paths to guide decision-making under partial observability. The aim is to reduce route length, avoid collisions, and preserve real-time planning capability. Methods The multi-UAV cooperative obstacle-avoidance route-planning task is formulated as a Partially Observable Markov Decision Process (POMDP). In the offline stage, A* is used to generate a reference path for each UAV. During online execution, only the locally visible path segment is extracted, and heuristic scores are constructed from this local prior information and fused with each UAV’s local observation. An individual-level Long Short-Term Memory (LSTM) network is used to capture temporal dependencies in local perception and prior guidance, whereas a system-level LSTM-based mixing network dynamically generates the mixing weights and bias for value decomposition, thereby enabling coordinated joint action-value estimation. Potential-based reward shaping is further adopted to improve training stability. Results and Discussions Simulation results in 3D grid environments show that PGL-QMIX converges faster and more stably than QMIX, VDN, and MAPPO. Compared with the corresponding second-best result in each scenario, PGL-QMIX reduces the number of convergence steps by 3.0%, 7.2%, and 7.4%, improves the steady-state task success rate by 1.26, 4.41, and 8.12 percentage points, and shortens the average route length by 6.2%, 8.5%, and 10.0%, respectively. In addition, the generated trajectories are shorter and more efficient across different map sizes. Conclusions PGL-QMIX improves coordination, safety, and route efficiency for multi-UAV cooperative obstacle avoidance in cluttered 3D environments. By integrating heuristic prior guidance, recurrent temporal fusion, and value decomposition, the proposed method achieves faster convergence, higher success rates, and better generalization than existing baselines. Future work will incorporate real UAV dynamic constraints and communication-aware cooperative obstacle avoidance. -
1 PGL-QMIX训练流程
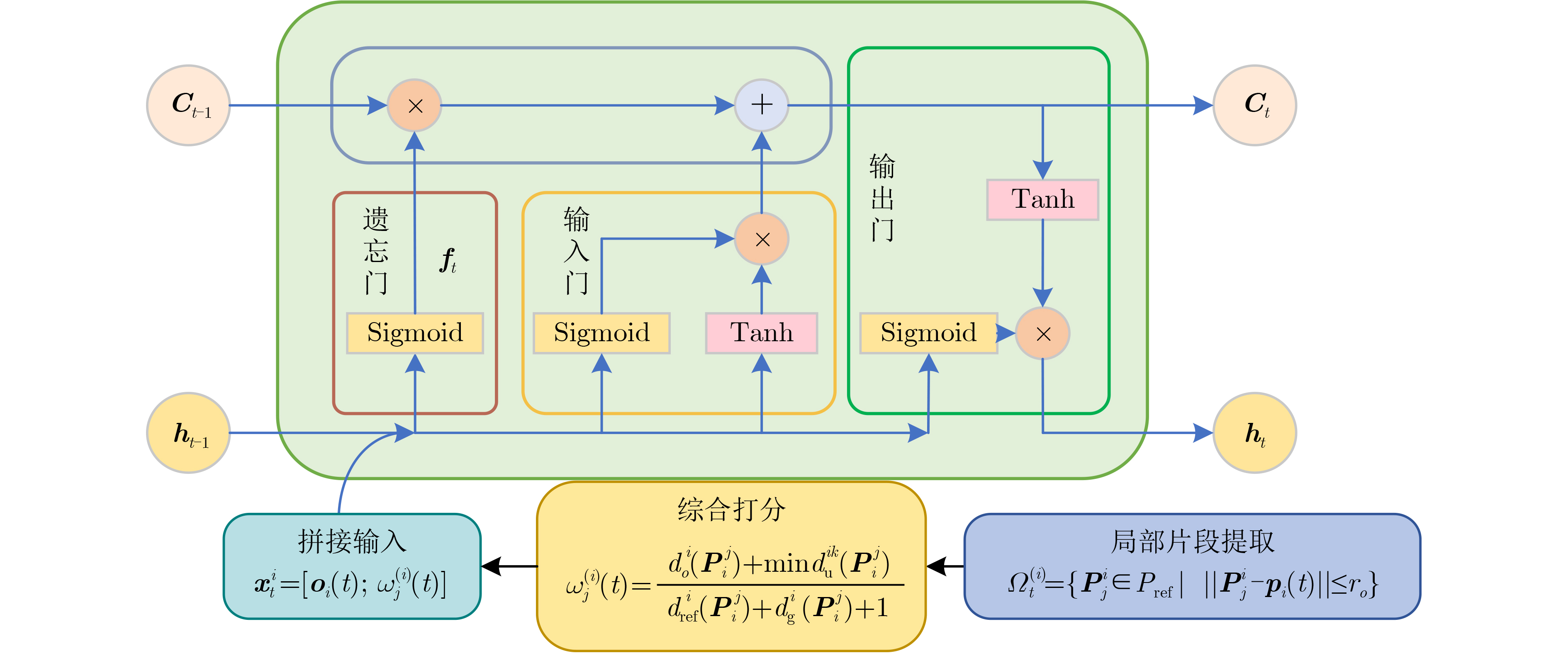
输入:回放池容量$ \mathcal{B} $,单回合长度$ T $;个体网络参数$ \left\{{\theta }_{i}\right\}_{i=1}^{N} $,系统层LSTM Mixer参数$ {\theta }_{m} $,目标网络参数$ \theta _{}^{-} $。 输出: 分散执行策略$ \pi_i(\boldsymbol{a}\mid\boldsymbol{o}_i) $ 1: 离线先验生成(每次reset后执行1次) 2: 从环境获得静态栅格grid,对每个无人机i 生成参考路径$ P_{i}^{{\mathrm{ref}}} $ 3: 初始化: 回放池$ D\leftarrow \varnothing $;同步目标网络$ {\theta }^{-}\leftarrow \theta $ 4: for 训练迭代 5: 环境reset,清零各智能体RNN隐状态$ \boldsymbol{h}_i $,系统层隐状态$ z $ 6: for t=0,1,···, $ T-1 $do 7: 获取每个智能体局部观测$ \boldsymbol{o}_i(t) $与位置$ \boldsymbol{p}_i(t) $ 8: 先验局部片段提取:$ \varOmega _{t}^{(i)}=\{\mathbf{P}_{j}^{i}\in P_{\text{ref}}^{i}\mid \| \mathbf{P}_{j}^{i}-\mathbf{p}_{i}(t)\| \leq {r}_{o}\} $ 9: 对$ \varOmega _{t}^{(i)} $内节点基于式(13)计算评分$ \omega _{j}^{(i)}(t) $ 10: 个体层时序编码,构造个体层输入:$ \mathbf{x}_t^i = [{\mkern 1mu} {{\mathbf{o}}_i}(t);\;\omega _j^{(i)}(t)] $ 11: 前向传播个体层LSTM得到时序特征$ h_{t}^{i} $ 12: 基于式(15)计算个体Q值$ \boldsymbol{h}_i(t),Q_i(t,\cdot)\leftarrow\mathrm{AgentLSTM}(\boldsymbol{x}_i(t),\boldsymbol{h}_i(t-1);\theta_i) $ 13: 系统层LSTM前向传播,生成隐藏状态$ \boldsymbol{z}_t $; 14: 由输出层生成时间相关权重$ \boldsymbol{W}_i(t) $与偏置$ \boldsymbol{b}(t) $ 15: 计算联合动作价值$ Q_{\text{tot}}(\boldsymbol{h}_t,\boldsymbol{a}_t;\theta) $ 16: 依据贪心策略选择联合动作$ \mathbf{a}_{t}=\{a_{t}^{1},a_{t}^{2},\cdots ,a_{t}^{N}\} $ 17: 执行联合动作$ \boldsymbol{a}_t $,获得团队回报$ {r}_{t} $和下一时刻观测 18: 将样本$ (\boldsymbol{h}_t,\boldsymbol{a}_t,r_t,\boldsymbol{h}_{t+1}) $存入经验池$ \mathcal{B} $ 19: if done break 20: end for 21: 参数更新(每若干步或每回合更新1次): 22:从$ \mathcal{B} $中随机采样小批量; 23: 基于式(20)计算TD目标值:${Y_t} = R(t) + \gamma {Q_{{\text{tot}},t + {1 }}}\left( {{\mathbf{h}_{t + 1}},{\mkern 1mu} \mathbf{a}_{t + 1}^*;{\mkern 1mu} {\theta ^ - }} \right)$ 24: 基于式(19)计算损失$ {L}_{\theta }=\displaystyle\sum \nolimits_{t=0}^{T}{\left[{Y}_{t}-{Q}_{{{\mathrm{tot}},t}}(\mathbf{h}_{t},\mathbf{a}_{t};\varTheta )\right]}^{2} $ 25: 反向传播并更新参数$ \theta \leftarrow \theta -\alpha {\nabla}_{\theta }\mathcal{L}(\theta ) $ 26: 目标网络同步:软更新目标网络$ {\theta }^{-}\leftarrow \tau \theta +(1-\tau ){\theta }^{-} $; 27: end for 28: return 训练好的网络参数$ \theta $  下载: 导出CSV
下载: 导出CSV
表 1 仿真超参数设置
实验参数 设置值 折扣因子$ \gamma $ 0.99 经验回放池大小$ \mathcal{B} $ 10000 批量大小 128 总训练步数 150000 单回合最大步数 200 最小探索率 0.01 学习率初值 $ 5\times {10}^{-4} $ 优化器 Adam 激活函数 Relu LSTM层 128单元 全连接层 128单元
下载: 导出CSV
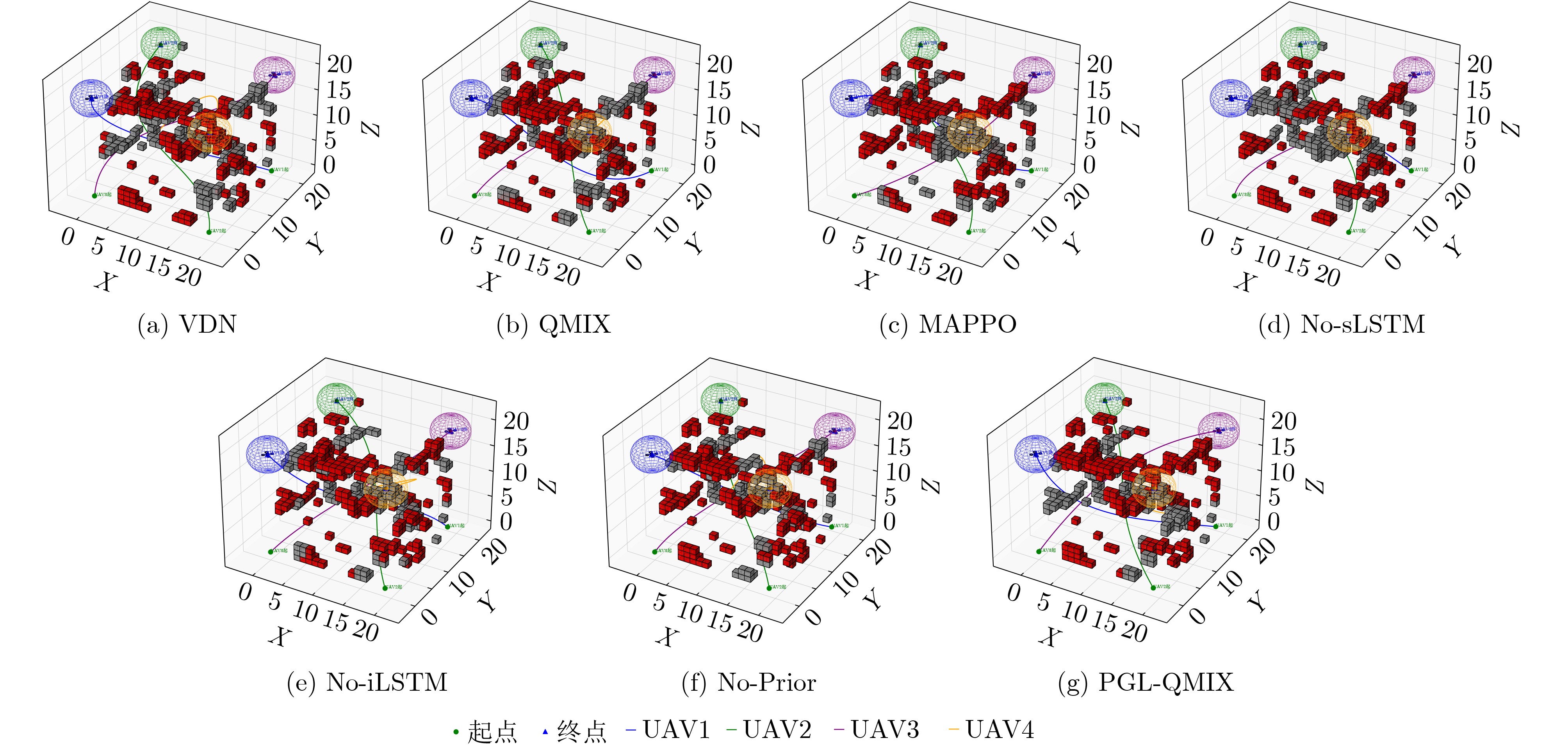
表 2 不同场景下收敛性能比较
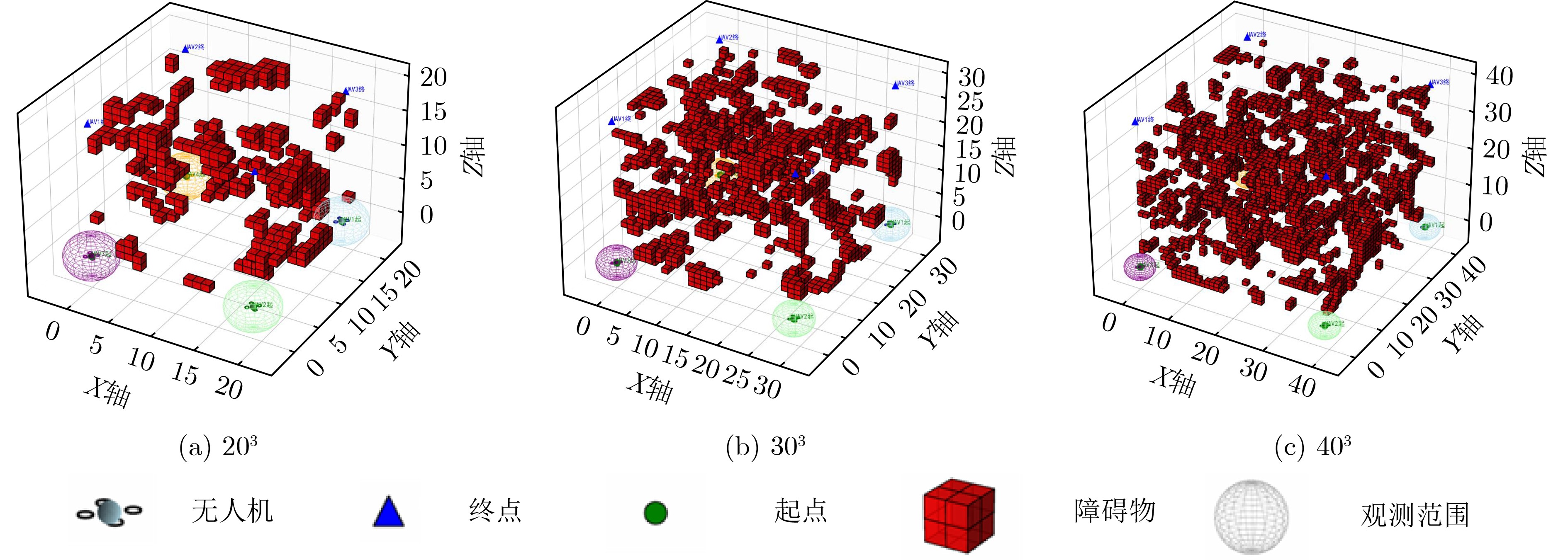
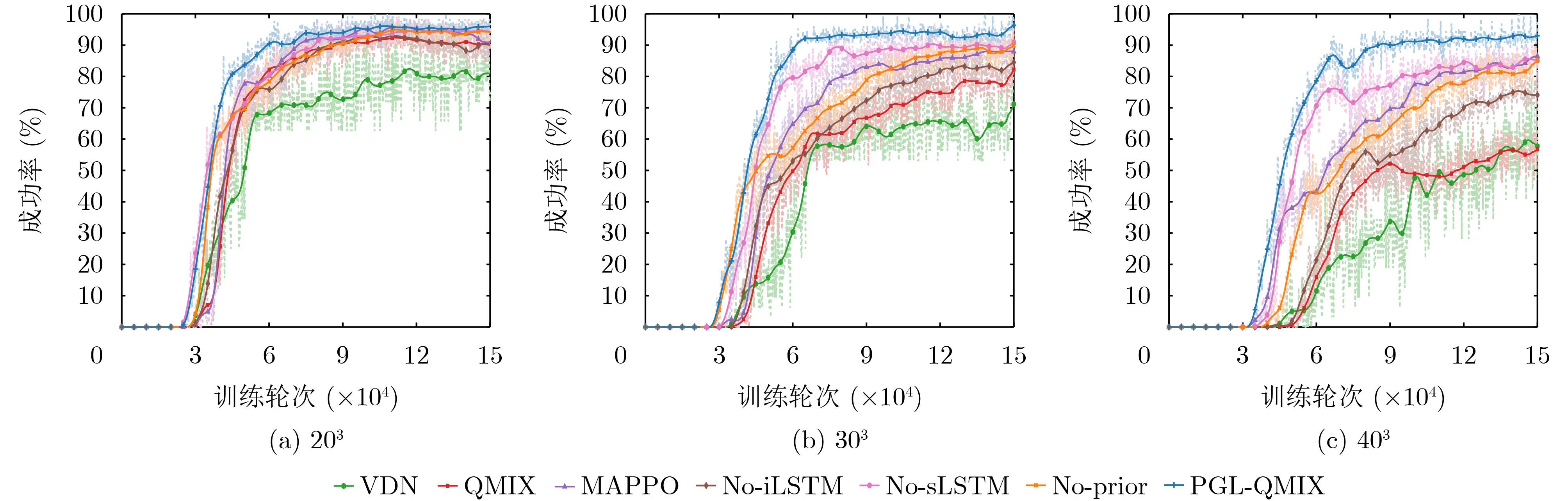
实验场景 算法 AUC 稳态平均奖励(%) 收敛步数($ \times10^4 $) 203 PGL-QMIX 16.911 137.57 3.24 No-Prior 16.321 134.25 3.74 No-iLSTM 15.705 130.87 4.06 No-sLSTM 16.125 130.89 3.34 MAPPO 16.028 131.16 3.58 QMIX 15.512 127.67 4.27 VDN 14.356 127.46 4.62 303 PGL-QMIX 25.406 209.87 3.36 No-Prior 24.329 201.88 3.90 No-iLSTM 23.887 197.42 3.96 No-sLSTM 24.023 198.90 3.62 MAPPO 23.922 199.37 3.92 QMIX 23.032 198.46 4.64 VDN 22.350 192.91 4.88 403 PGL-QMIX 33.139 273.59 3.74 No-Prior 32.127 269.02 4.24 No-iLSTM 29.474 262.21 4.32 No-sLSTM 32.017 267.05 4.04 MAPPO 30.461 265.40 4.22 QMIX 28.281 261.32 4.82 VDN 26.819 253.85 6.08
下载: 导出CSV
表 3 场景下任务成功率比较
实验场景 算法 首次80%
成功率步数($ \times10^4 $)平均成
功率(%)最高
成功率(%)203 PGL-QMIX 4.14 95.73 100.0 No-Prior 5.44 94.18 98.4 No-iLSTM 5.28 89.10 98.4 No-sLSTM 4.90 94.47 99.2 MAPPO 4.88 93.23 99.2 QMIX 5.14 90.50 98.4 VDN 6.08 79.93 96.9 303 PGL-QMIX 5.06 94.03 100.0 No-Prior 8.50 87.92 96.9 No-iLSTM 9.48 84.72 93.8 No-sLSTM 5.72 89.62 96.9 MAPPO 6.78 88.27 93.8 QMIX 11.22 79.04 92.2 VDN 8.98 66.47 84.4 403 PGL-QMIX 5.64 92.92 100.0 No-Prior 10.94 82.30 89.8 No-iLSTM 14.08 74.76 82.0 No-sLSTM 6.24 84.80 91.2 MAPPO 9.88 84.73 89.8 QMIX - 57.67 65.6 VDN - 55.94 78.1
下载: 导出CSV
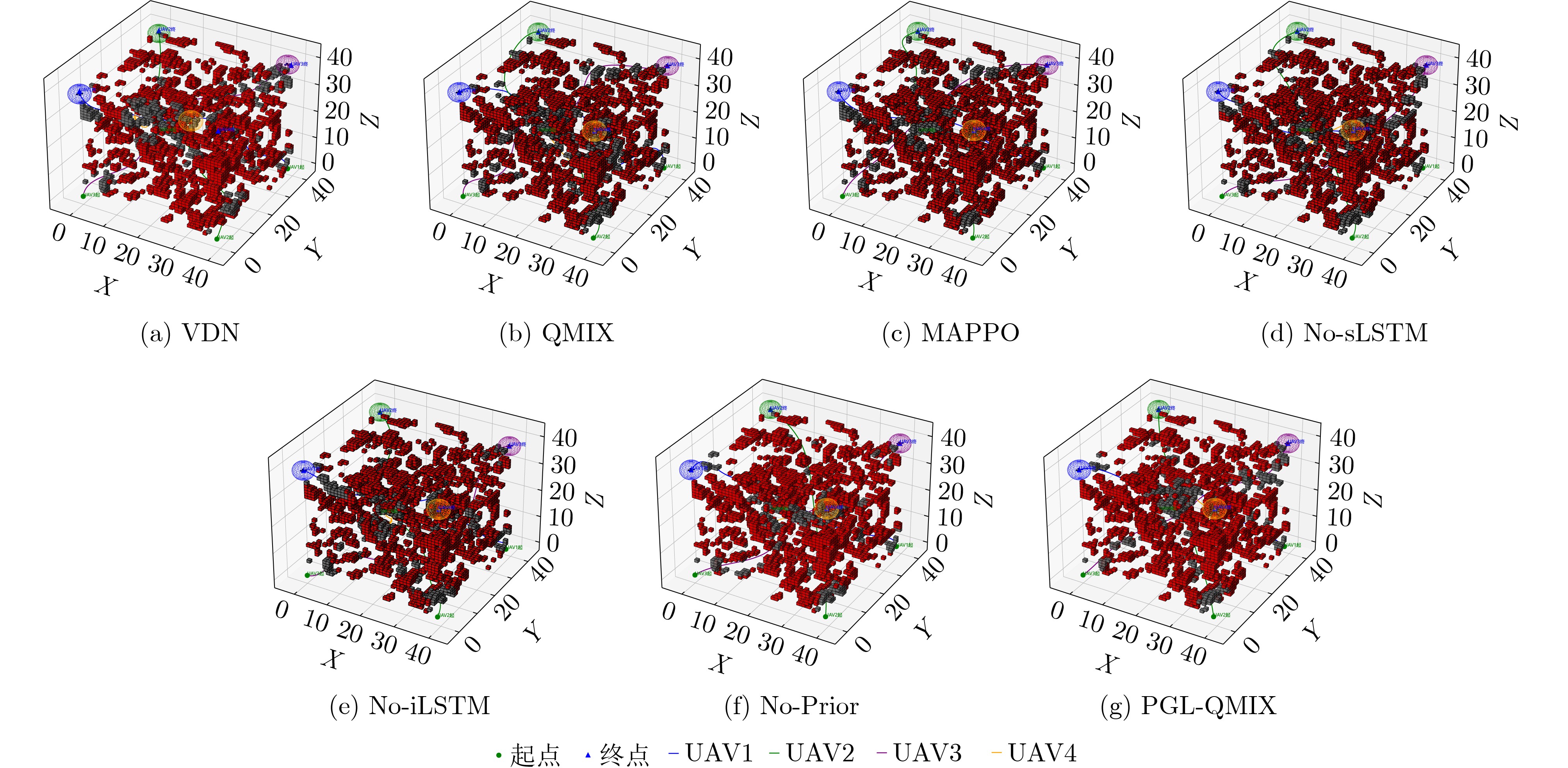
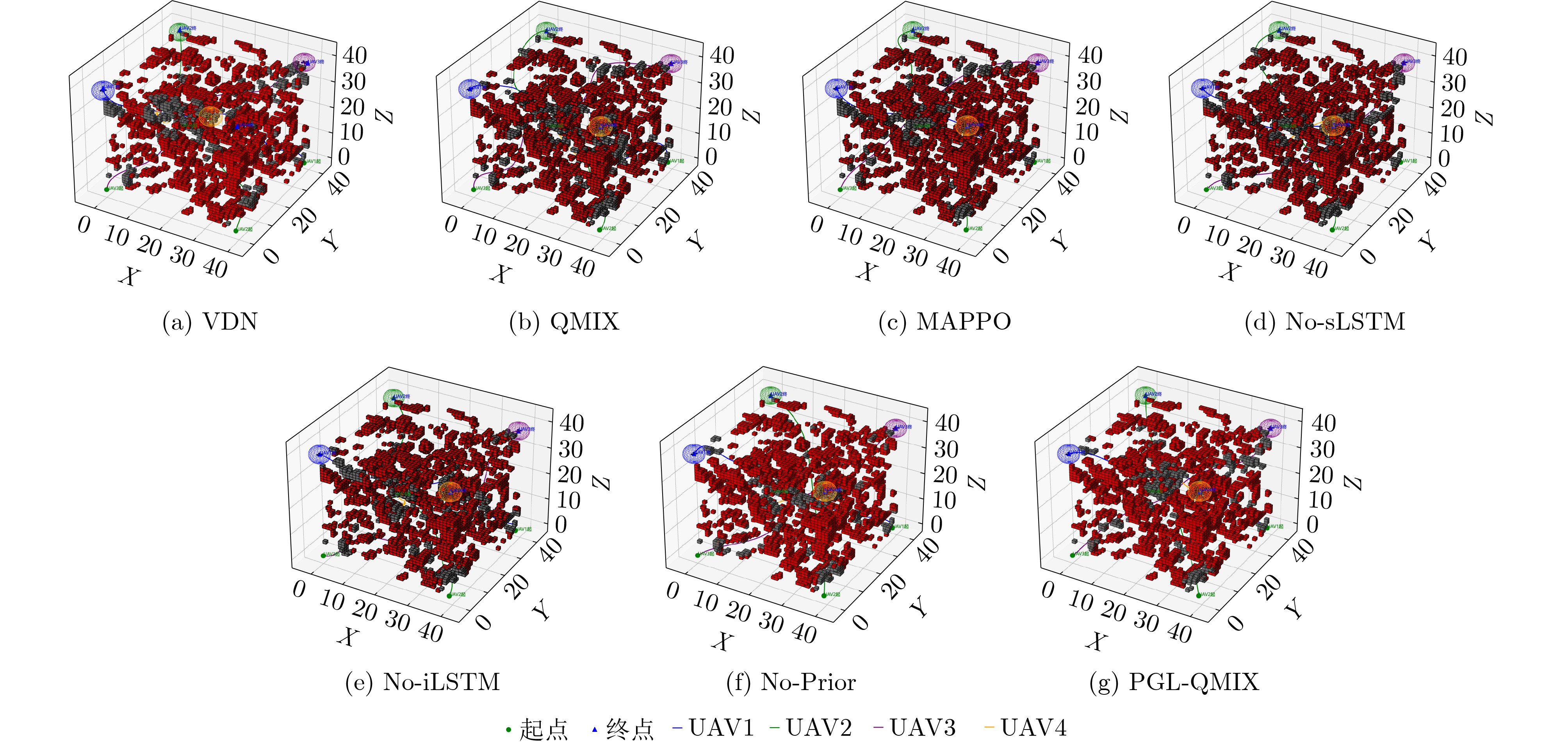
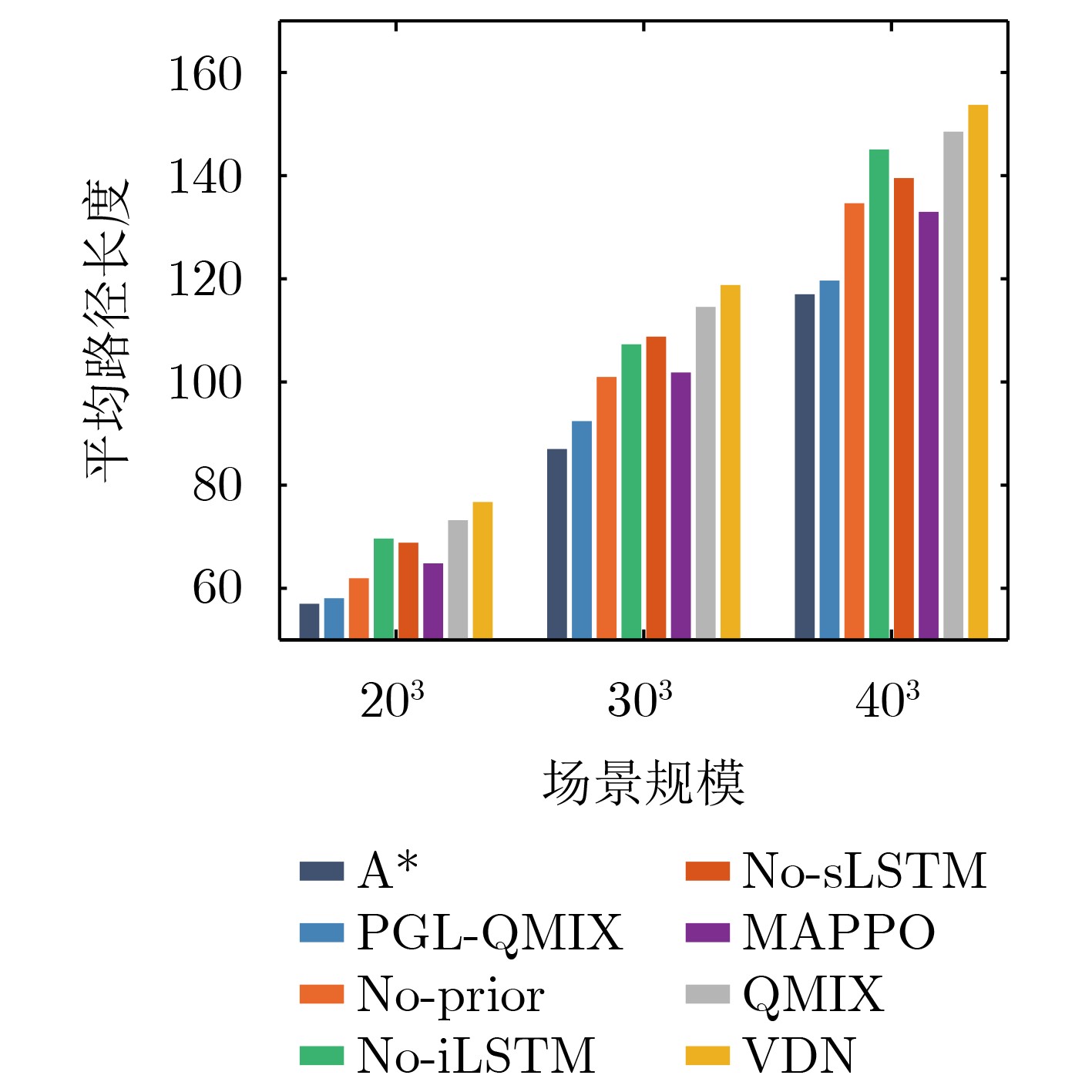
表 4 不同场景下算法路径比较
实验
场景算法 最小障碍
距离平均障碍
距离机间最近
距离平均路径
距离最长路径
距离203 PGL-QMIX 2.73 6.03 14.04 58.08 73.25 No-Prior 2.41 5.93 12.71 61.95 94.75 No-iLSTM 2.24 5.84 11.09 69.65 99.75 No-sLSTM 2.24 5.51 11.46 68.84 97.25 MAPPO 2.41 5.97 11.47 64.84 93.75 QMIX 2.00 5.22 8.06 73.20 100.75 VDN 1.71 5.11 6.20 76.73 108.25 303 PGL-QMIX 2.41 6.54 17.26 92.41 119.25 No-Prior 2.00 6.32 15.81 100.97 137.00 No-iLSTM 1.41 5.62 13.85 107.30 156.50 No-sLSTM 1.73 6.11 12.17 108.79 148.50 MAPPO 2.00 6.21 16.14 101.84 141.50 QMIX 1.41 5.41 11.52 114.56 156.25 VDN 1.41 5.22 10.47 118.79 163.00 403 PGL-QMIX 2.24 5.86 29.27 119.65 139.25 No-Prior 1.73 5.08 20.35 134.65 147.25 No-iLSTM 1.00 4.48 18.15 145.07 170.25 No-sLSTM 1.41 4.88 17.46 139.07 159.25 MAPPO 1.73 5.12 19.79 132.98 149.50 QMIX 1.00 4.50 13.42 148.52 187.50 VDN 1.00 3.80 12.17 153.71 200.00
下载: 导出CSV
-
[1] 高思华, 刘宝煜, 惠康华, 等. 信息年龄约束下的无人机数据采集能耗优化路径规划算法[J]. 电子与信息学报, 2024, 46(10): 4024–4034. doi: 10.11999/JEIT240075.GAO Sihua, LIU Baoyu, HUI Kanghua, et al. Energy-efficient UAV trajectory planning algorithm for AoI-constrained data collection[J]. Journal of Electronics & Information Technology, 2024, 46(10): 4024–4034. doi: 10.11999/JEIT240075. [2] 潘钰, 胡航, 金虎, 等. 非授权频段下无人机辅助通信的轨迹与资源分配优化[J]. 电子与信息学报, 2024, 46(11): 4287–4294. doi: 10.11999/JEIT240275.PAN Yu, HU Hang, JIN Hu, et al. Trajectory and resource allocation optimization for unmanned aerial vehicles assisted communications in unlicensed bands[J]. Journal of Electronics & Information Technology, 2024, 46(11): 4287–4294. doi: 10.11999/JEIT240275. [3] 薛健, 赵琳, 向贤财, 等. 非完全信息下无人机集群对抗研究综述[J]. 电子与信息学报, 2024, 46(4): 1157–1172. doi: 10.11999/JEIT230544.XUE Jian, ZHAO Lin, XIANG Xiancai, et al. A review of the research on UAV swarm confrontation under incomplete information[J]. Journal of Electronics & Information Technology, 2024, 46(4): 1157–1172. doi: 10.11999/JEIT230544. [4] DUCHOŇ F, BABINEC A, KAJAN M, et al. Path planning with modified a star algorithm for a mobile robot[J]. Procedia Engineering, 2014, 96: 59–69. doi: 10.1016/j.proeng.2014.12.098. [5] OSBAND I, BLUNDELL C, PRITZEL A, et al. Deep exploration via bootstrapped DQN[C]. The 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 2016: 4033–4041. [6] 周治国, 余思雨, 于家宝, 等. 面向无人艇的T-DQN智能避障算法研究[J]. 自动化学报, 2023, 49(8): 1645–1655. doi: 10.16383/j.aas.c210080.ZHOU Zhiguo, YU Siyu, YU Jiabao, et al. Research on T-DQN intelligent obstacle avoidance algorithm of unmanned surface vehicle[J]. Acta Automatica Sinica, 2023, 49(8): 1645–1655. doi: 10.16383/j.aas.c210080. [7] 赵静, 裴子楠, 姜斌, 等. 基于深度强化学习的无人机虚拟管道视觉避障[J]. 自动化学报, 2024, 50(11): 2245–2258. doi: 10.16383/j.aas.c230728.ZHAO Jing, PEI Zinan, JIANG Bin, et al. Virtual tube visual obstacle avoidance for UAV based on deep reinforcement learning[J]. Acta Automatica Sinica, 2024, 50(11): 2245–2258. doi: 10.16383/j.aas.c230728. [8] GREFF K, SRIVASTAVA R K, KOUTNÍK J, et al. LSTM: A search space odyssey[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(10): 2222–2232. doi: 10.1109/TNNLS.2016.2582924. [9] SUNEHAG P, LEVER G, GRUSLYS A, et al. Value-decomposition networks for cooperative multi-agent learning based on team reward[C]. The 17th International Conference on Autonomous Agents and MultiAgent Systems, Stockholm, Sweden, 2018: 2085–2087. [10] RASHID T, SAMVELYAN M, DE WITT C S, et al. Monotonic value function factorisation for deep multi-agent reinforcement learning[J]. The Journal of Machine Learning Research, 2020, 21(1): 178. [11] 冯斯梦, 张云弈, 刘凯, 等. 低空混合障碍下无人机协同多智能体航迹规划[J]. 电子与信息学报, 2025, 47(5): 1291–1300. doi: 10.11999/JEIT250012.FENG Simeng, ZHANG Yunyi, LIU Kai, et al. Collaborative multi-agent trajectory optimization for unmanned aerial vehicles under low-altitude mixed-obstacle airspace[J]. Journal of Electronics & Information Technology, 2025, 47(5): 1291–1300. doi: 10.11999/JEIT250012. [12] GUAN Yue, ZOU Sai, PENG Haixia, et al. Cooperative UAV trajectory design for disaster area emergency communications: A multiagent PPO method[J]. IEEE Internet of Things Journal, 2024, 11(5): 8848–8859. doi: 10.1109/jiot.2023.3320796. [13] YANG Yang, LI Juntao, and PENG Lingling. Multi-robot path planning based on a deep reinforcement learning DQN algorithm[J]. CAAI Transactions on Intelligence Technology, 2020, 5(3): 177–183. doi: 10.1049/trit.2020.0024. [14] WANG Binyu, LIU Zhe, LI Qingbiao, et al. Mobile robot path planning in dynamic environments through globally guided reinforcement learning[J]. IEEE Robotics and Automation Letters, 2020, 5(4): 6932–6939. doi: 10.1109/LRA.2020.3026638. [15] BEYNIER A, CHARPILLET F, SZER D, et al. DEC-MDP/POMDP[M]. SIGAUD O and BUFFET O. Markov Decision Processes in Artificial Intelligence. Hoboken: John Wiley & Sons, Inc. , 2013: 277–318. doi: 10.1002/9781118557426.ch9. [16] 邢娜, 邸昊天, 尹文杰, 等. 基于自适应多态蚁群优化的智能体路径规划[J]. 北京航空航天大学学报, 2025, 51(7): 2330–2337. doi: 10.13700/j.bh.1001-5965.2023.0432.XING Na, DI Haotian, YIN Wenjie, et al. Path planning for agents based on adaptive polymorphic ant colony optimization[J]. Journal of Beijing University of Aeronautics and Astronautics, 2025, 51(7): 2330–2337. doi: 10.13700/j.bh.1001-5965.2023.0432. -

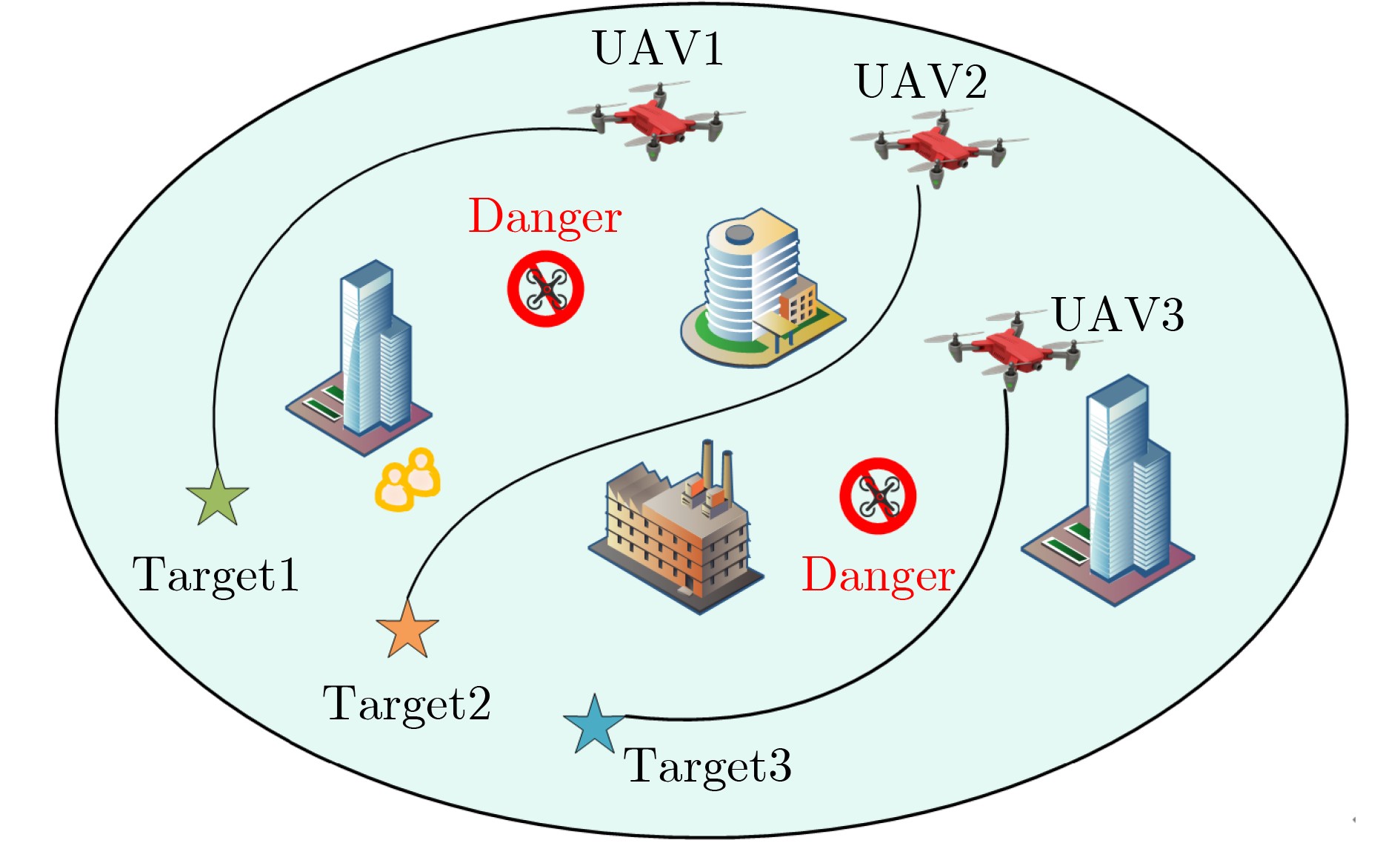
 下载:
下载:




图(10) / 表(5)
计量
- 文章访问数: 481
- HTML全文浏览量: 154
- PDF下载量: 64
- 被引次数: 0
