

PSAQNet: A Perceptual Structure Adaptive Quality Network for Authentic Distortion Oriented No-reference Image Quality Assessment
-
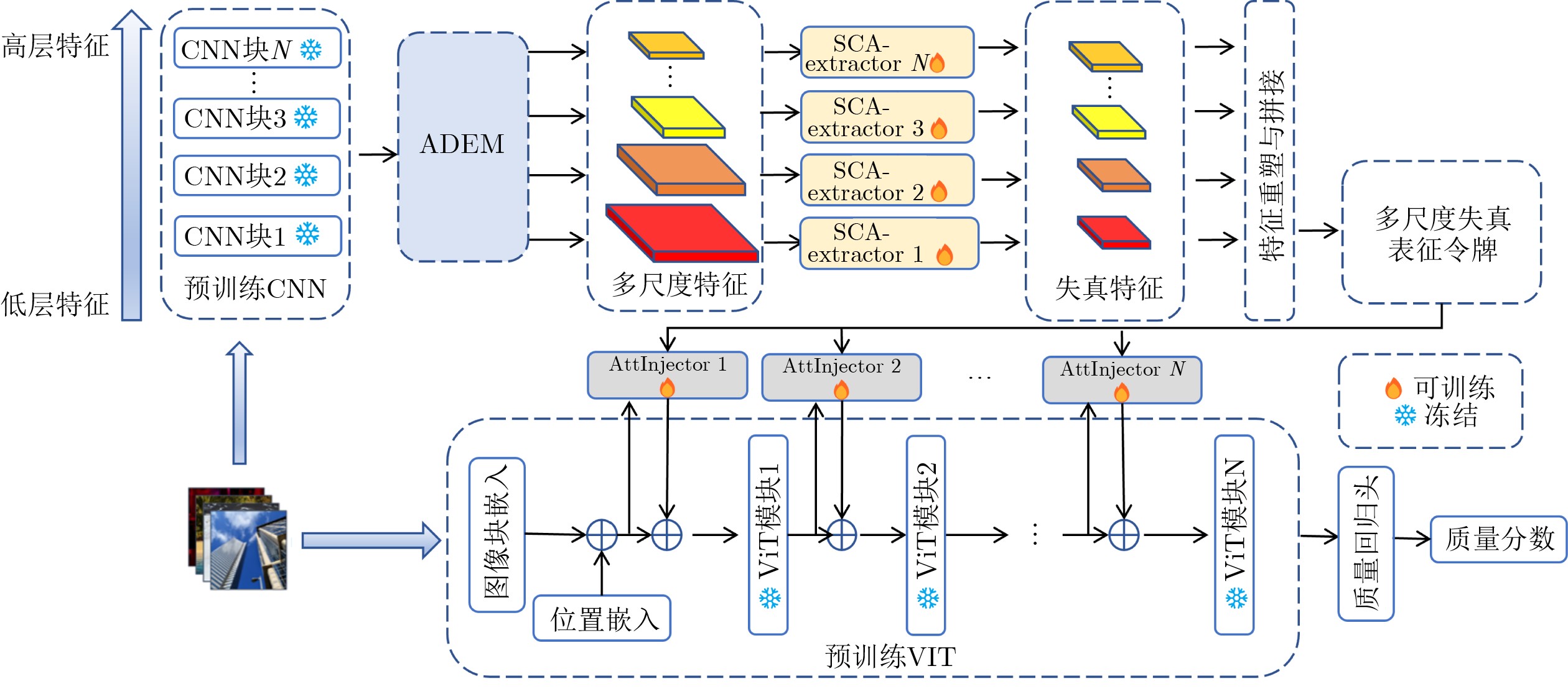
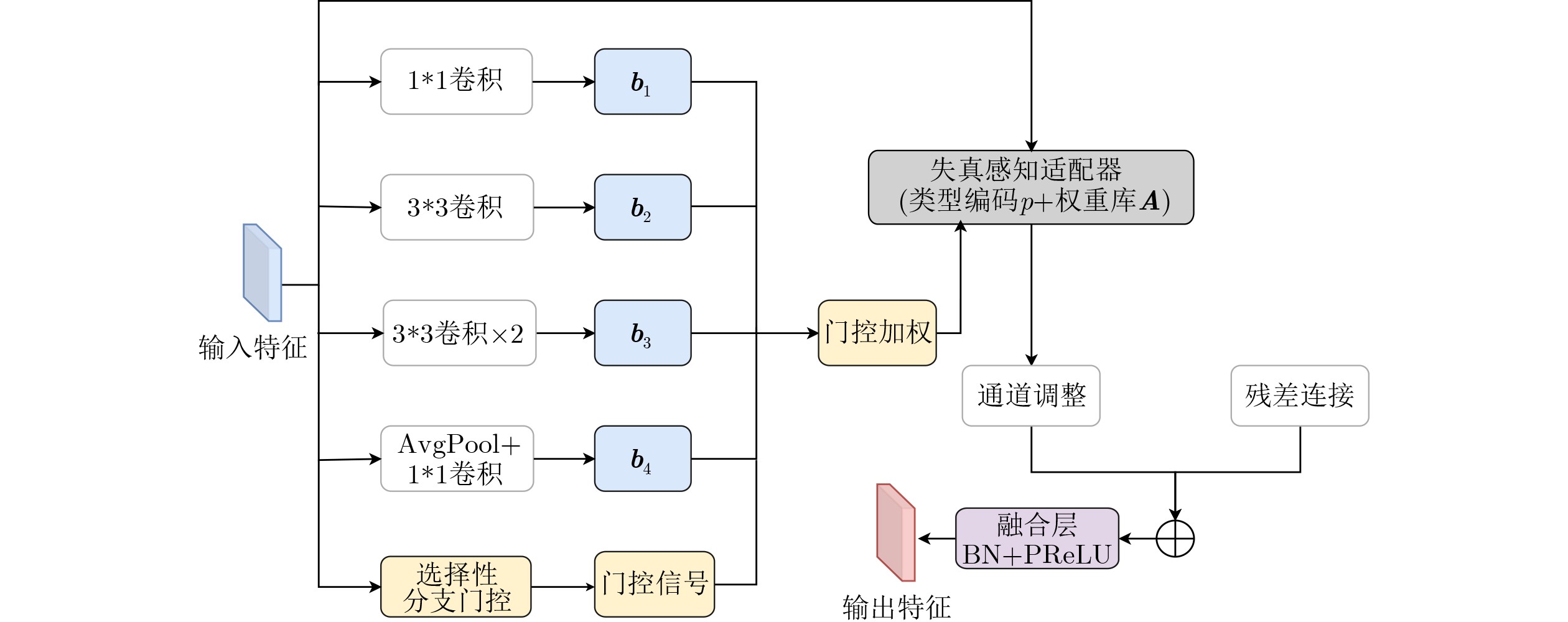
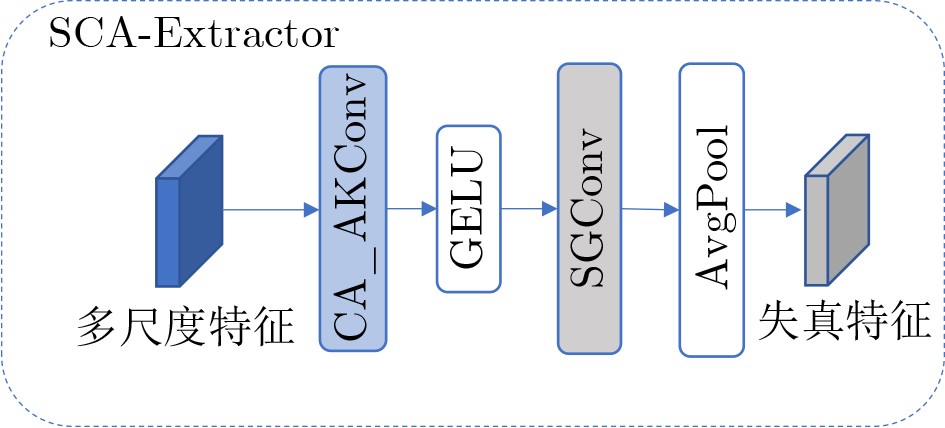
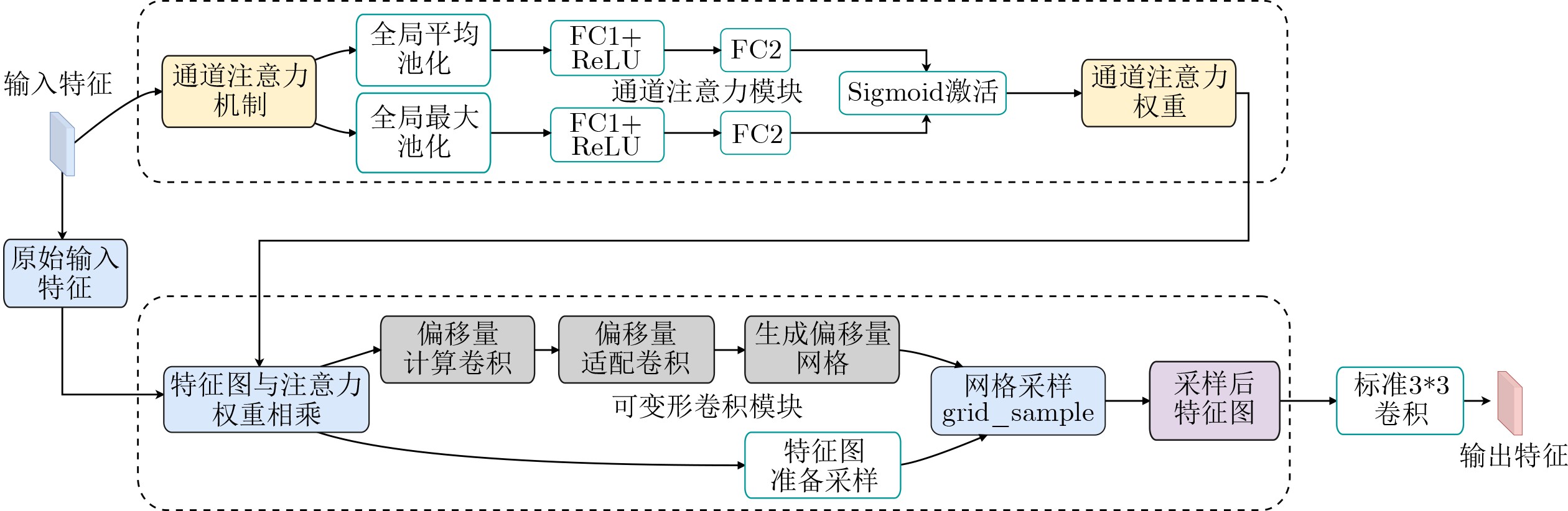
摘要: 针对无参考图像质量评价方法在真实场景中存在鲁棒性不够、泛化能力不足、几何结构建模欠缺的问题,该文提出一种基于感知结构自适应质量网络(PSAQNet)方法。首先,利用预训练卷积神经网络(CNN)提取多尺度特征,并通过高级失真增强模块对多分支特征进行门控筛选与适配,突出与失真相关的区域、抑制无关干扰;其次,引入通道感知自适应核卷积与空间引导卷积,从通道重标定、自适应采样以及空间引导调制等角度增强对旋转、扭曲等几何退化的建模与对齐能力;接着,将增强后的多尺度卷积特征经自适应池化与投影转换为token序列,并通过交叉注意力机制与Transformer全局表示进行选择性交互,实现局部细节与全局语义的有效融合;最后,在融合过程中结合分组卷积注意力进一步强调失真显著区域,通过预测头回归得到图像质量分数。在6个经典的数据库上进行实验结果显示,PSAQNet在皮尔逊线性相关系数(PLCC)/斯皮尔曼秩相关系数(SRCC)等相关性指标上优于多种代表性无参考图像质量评价方法。尤其在复杂失真和跨数据库测试中展现出更强的鲁棒性与泛化能力。Abstract:
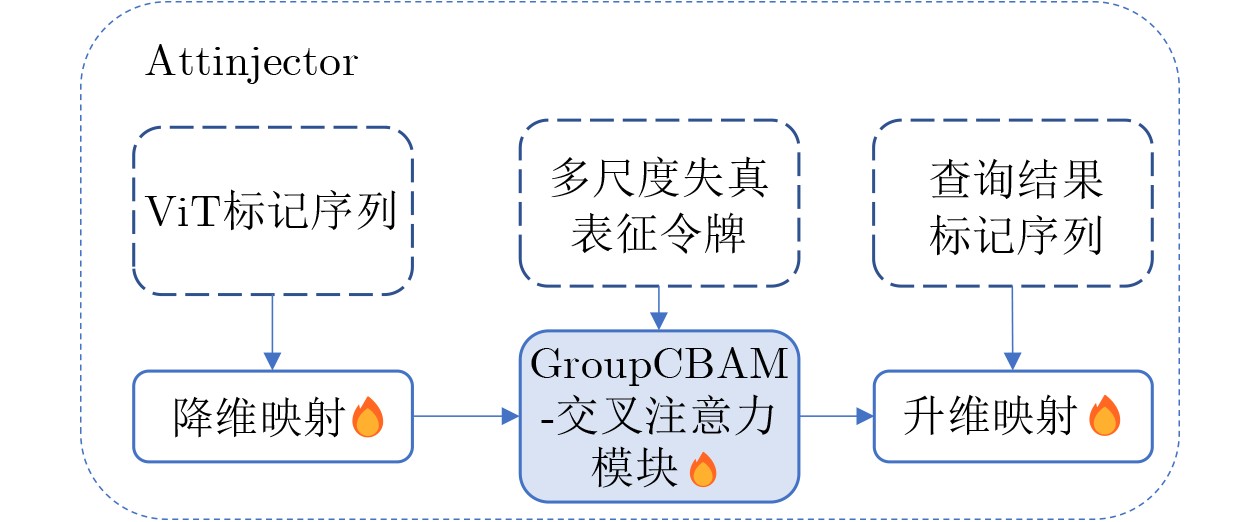
Objective No-Reference Image Quality Assessment (NR-IQA) is critical for practical imaging systems when pristine reference images are unavailable. However, many existing methods face three major challenges: limited robustness under complex distortions, weak generalization when distortion distributions shift (e.g., from synthetic to real-world settings), and insufficient modeling of geometric or structural degradations such as spatially varying blur, misalignment, and texture-structure coupling. These limitations cause models to rely excessively on dataset-specific statistics and reduce their effectiveness when applied to diverse scenes with mixed degradations. To address these issues, the Perceptual Structure Adaptive Quality Network (PSAQNet) is proposed to improve the accuracy and adaptability of NR-IQA under complex distortion conditions. Methods PSAQNet is designed as a unified CNN-Transformer framework that preserves hierarchical perceptual cues and supports global context reasoning. Instead of relying on late-stage pooling, distortion evidence is progressively enhanced throughout the network. The architecture contains several key components. The Advanced Distortion Enhanced Module (ADEM) operates on multi-scale features extracted from a pre-trained backbone. It adopts multi-branch gating and a distortion-aware adapter to emphasize degradation-related signals and reduce interference from dominant image content. This mechanism dynamically selects feature branches that correspond to perceptual degradation patterns, which is beneficial for spatially non-uniform or mixed distortions. To model geometric degradations, PSAQNet integrates Spatial-Guided Convolution (SGC) and Channel-Aware Adaptive Kernel convolution (CA_AK). SGC improves spatial sensitivity by guiding convolutional responses with structure-aware cues and focusing on regions where geometric distortions are prominent. CA_AK further improves geometric modeling by adaptively adjusting receptive behavior and recalibrating channels to preserve distortion-sensitive components. Additionally, PSAQNet incorporates efficient feature fusion strategies. Group Convolutional Block Attention Module (GroupCBAM) enables lightweight attention-based fusion of multi-level CNN features, whereas AttInjector selectively injects local distortion cues into global Transformer representations. This design allows global semantic reasoning to be guided by localized degradation evidence without introducing redundancy or instability. Results and Discussions Extensive experiments on six benchmark datasets containing both synthetic and real-world distortions demonstrate that PSAQNet achieves strong performance and stable agreement with human subjective judgments. The proposed method outperforms several recent approaches, particularly on real-world distortion datasets. These results indicate that PSAQNet effectively enhances distortion evidence, models geometric degradation, and integrates local distortion cues with global semantic representations. Such capabilities improve robustness under distribution shifts and reduce reliance on narrow distortion priors. Ablation studies confirm the contribution of each module. ADEM increases distortion saliency, SGC and CA_AK improve sensitivity to geometric degradations, and GroupCBAM and AttInjector strengthen the interaction between local and global features. Cross-dataset evaluations further demonstrate the generalization capability of PSAQNet across different content categories and distortion types. Scalability experiments also show that the framework benefits from stronger pretrained backbones without compromising its modular design. Conclusions PSAQNet addresses several key limitations in NR-IQA by integrating local distortion enhancement, geometric-aware feature modeling, and global semantic fusion within a unified framework. The modular architecture improves robustness and generalization across diverse distortion conditions and supports practical deployment in real-world scenarios. Future work will explore vision–language pre-training to improve cross-scene adaptability. -
表 1 本实验使用的6个数据集
数据集 失真图像数 失真类型数 数据集类型 LIVE 779 5 合成失真 CSIQ 866 6 合成失真 TID2013 3000 24 合成失真 KADID-10k 10125 25 合成失真 LIVEC 1162 - 真实失真 KonIQ-10k 10073 - 真实失真  下载: 导出CSV
下载: 导出CSV
表 2 与经典和最新的模型的对比结果
方法 CSIQ TID2013 LIVE KADID-10k LIVEC KonIQ-10k PLCC SRCC PLCC SRCC PLCC SRCC PLCC SRCC PLCC SRCC PLCC SRCC TReS 0.942 0.922 0.883 0.863 0.968 0.969 0.858 0.859 0.877 0.846 0.928 0.915 LoDa 0.968 0.961 0.901 0.869 0.979 0.975 0.936 0.931 0.887 0.871 0.934 0.920 SaTQA 0.972 0.965 0.931 0.948 0.983 0.983 0.949 0.946 0.899 0.877 0.941 0.930 MDM-GFIQA 0.973 0.965 0.936 0.929 0.976 0.976 0.921 0.918 0.908 0.887 0.942 0.930 本文 0.979 0.974 0.938 0.929 0.988 0.987 0.942 0.937 0.908 0.887 0.943 0.935
下载: 导出CSV
表 3 消融实验结果
方法 KonIQ-10k TID2013 PLCC SRCC PLCC SRCC baseline 0.934 0.920 0.901 0.869 baseline+DEM+CA_AK 0.936 0.925 0.924 0.922 baseline+DEM+SGC 0.934 0.927 0.925 0.920 baseline+CA_AK+SGC 0.936 0.924 0.922 0.919 baseline+DEM+CA_AK+SGC 0.938 0.927 0.932 0.925 baseline+DEM+CA_AK+
GroupCBAM0.936 0.930 0.933 0.923 baseline+DEM+SGC+
GroupCBAM0.939 0.931 0.930 0.926 PSAQNet 0.943 0.935 0.938 0.929
下载: 导出CSV
表 4 泛化性能测评
方法 KonIQ-10k KADID-10k LIVE LIVEC KonIQ-10k CSIQ TID2013 HyperIQA 0.785 0.648 0.744 0.551 TReS 0.786 0.606 0.761 0.562 LoDa 0.794 0.654 0.823 0.621 SaTQA 0.791 0.661 0.831 0.627 MDM-GFIQA 0.813 0.670 0.840 0.641 本文 0.817 0.677 0.842 0.659
下载: 导出CSV
-
[1] 韩玉兰, 崔玉杰, 罗轶宏, 等. 基于密集残差和质量评估引导的频率分离生成对抗超分辨率重构网络[J]. 电子与信息学报, 2024, 46(12): 4563–4574. doi: 10.11999/JEIT240388.HAN Yulan, CUI Yujie, LUO Yihong, et al. Frequency separation generative adversarial super-resolution reconstruction network based on dense residual and quality assessment[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4563–4574. doi: 10.11999/JEIT240388. [2] 柏园超, 刘文昌, 江俊君, 等. 深度神经网络图像压缩方法进展综述[J]. 电子与信息学报, 2025, 47(11): 4112–4128. doi: 10.11999/JEIT250567.BAI Yuanchao, LIU Wenchang, JIANG Junjun, et al. Advances in deep neural network based image compression: A survey[J]. Journal of Electronics & Information Technology, 2025, 47(11): 4112–4128. doi: 10.11999/JEIT250567. [3] WANG Zhou, BOVIK A C, SHEIKH H R, et al. Image quality assessment: From error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600–612. doi: 10.1109/TIP.2003.819861. [4] WANG Zhou, SIMONCELLI E P, BOVIK A C. Multiscale structural similarity for image quality assessment[C]. The 37th Asilomar Conference on Signals, Systems & Computers, Pacific Grove, USA, 2003: 1398–1402. doi: 10.1109/ACSSC.2003.1292216. [5] YANG Jie, LYU Mengjin, QI Zhiquan, et al. Deep learning based image quality assessment: A survey[J]. Procedia Computer Science, 2023, 221: 1000–1005. doi: 10.1016/j.procs.2023.08.080. [6] MOORTHY A K and BOVIK A C. Blind image quality assessment: From natural scene statistics to perceptual quality[J]. IEEE Transactions on Image Processing, 2011, 20(12): 3350–3364. doi: 10.1109/TIP.2011.2147325. [7] MITTAL A, MOORTHY A K, and BOVIK A C. No-reference image quality assessment in the spatial domain[J]. IEEE Transactions on Image Processing, 2012, 21(12): 4695–4708. doi: 10.1109/TIP.2012.2214050. [8] BOSSE S, MANIRY D, MÜLLER K R, et al. Deep neural networks for no-reference and full-reference image quality assessment[J]. IEEE Transactions on Image Processing, 2018, 27(1): 206–219. doi: 10.1109/TIP.2017.2760518. [9] ZHANG Lin, ZHANG Lei, and BOVIK A C. A feature-enriched completely blind image quality evaluator[J]. IEEE Transactions on Image Processing, 2015, 24(8): 2579–2591. doi: 10.1109/TIP.2015.2426416. [10] ZHANG Weixia, MA Kede, YAN Jia, et al. Blind image quality assessment using a deep bilinear convolutional neural network[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 30(1): 36–47. doi: 10.1109/TCSVT.2018.2886771. [11] KE Junjie, WANG Qifei, WANG Yilin, et al. MUSIQ: Multi-scale image quality transformer[C]. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 5128–5137. doi: 10.1109/ICCV48922.2021.00510. [12] CHEON M, YOON S J, KANG B, et al. Perceptual image quality assessment with transformers[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, USA, 2021: 433–442. doi: 10.1109/CVPRW53098.2021.00054. [13] CHEN Zewen, QIN Haina, WANG Juan, et al. PromptIQA: Boosting the performance and generalization for no-reference image quality assessment via prompts[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2024: 247–264. doi: 10.1007/978-3-031-73232-4_14. [14] ZHANG Bo, WANG Luoxi, ZHANG Cheng, et al. No-reference image quality assessment based on improved vision transformer and transfer learning[J]. Signal Processing: Image Communication, 2025, 135: 117282. doi: 10.1016/j.image.2025.117282. [15] 郭颖聪, 唐天航, 刘怡光. 基于Transformer与权重令牌引导的双分支无参考图像质量评价网络[J]. 四川大学学报: 自然科学版, 2025, 62(4): 847–856. doi: 10.19907/j.0490-6756.240396.GUO Yingcong, TANG Tianhang, and LIU Yiguang. A dual-branch no-reference image quality assessment network guided by Transformer and a weight token[J]. Journal of Sichuan University: Natural Science Edition, 2025, 62(4): 847–856. doi: 10.19907/j.0490-6756.240396. [16] 陈勇, 朱凯欣, 房昊, 等. 基于空间分布分析的混合失真无参考图像质量评价[J]. 电子与信息学报, 2020, 42(10): 2533–2540. doi: 10.11999/JEIT190721.CHEN Yong, ZHU Kaixin, FANG Hao, et al. No-reference image quality evaluation for multiply-distorted images based on spatial domain coding[J]. Journal of Electronics & Information Technology, 2020, 42(10): 2533–2540. doi: 10.11999/JEIT190721. [17] XU Kangmin, LIAO Liang, XIAO Jing, et al. Boosting image quality assessment through efficient transformer adaptation with local feature enhancement[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 2662–2672. doi: 10.1109/CVPR52733.2024.00257. [18] SHI Jinsong, GAO Pan, and QIN Jie. Transformer-based no-reference image quality assessment via supervised contrastive learning[C]. The 38th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 4829–4837. doi: 10.1609/aaai.v38i5.28285. [19] SU Shaolin, YAN Qingsen, ZHU Yu, et al. Blindly assess image quality in the wild guided by a self-adaptive hyper network[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 3664–3673. doi: 10.1109/CVPR42600.2020.00372. [20] HOSU V, LIN Hanhe, SZIRANYI T, et al. KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment[J]. IEEE Transactions on Image Processing, 2020, 29: 4041–4056. doi: 10.1109/TIP.2020.2967829. [21] LI Aobo, WU Jinjian, LIU Yongxu, et al. Bridging the synthetic-to-authentic gap: Distortion-guided unsupervised domain adaptation for blind image quality assessment[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 28422–28431. doi: 10.1109/CVPR52733.2024.02685. [22] GU Liping, LI Tongyan, and HE Jiyong. Classification of diabetic retinopathy grade based on G-ENet convolutional neural network model: Convolutional neural networks are used to solve the problem of diabetic retinopathy grade classification[C]. 2023 7th International Conference on Electronic Information Technology and Computer Engineering, Xiamen, China, 2023: 1590–1594. doi: 10.1145/3650400.3650666. [23] LI Yuhao and ZHANG Aihua. AKA-MobileNet: A cloud-noise-robust lightweight convolution neural network[C]. 2024 39th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Dalian, China, 2024: 188–193. doi: 10.1109/YAC63405.2024.10598582. [24] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]. The 15th European Conference on Computer Vision, Munich: Springer, 2018: 3–19. doi: 10.1007/978-3-030-01234-2_1. [25] SHEIKH H R, BOVIK A C, and DE VECIANA G. An information fidelity criterion for image quality assessment using natural scene statistics[J]. IEEE Transactions on Image Processing, 2005, 14(12): 2117–2128. doi: 10.1109/TIP.2005.859389. [26] LARSON E C and CHANDLER D M. Most apparent distortion: Full-reference image quality assessment and the role of strategy[J]. Journal of Electronic Imaging, 2010, 19(1): 011006. doi: 10.1117/1.3267105. [27] PONOMARENKO N, JIN Lina, IEREMEIEV O, et al. Image database TID2013: Peculiarities, results and perspectives[J]. Signal Processing: Image Communication, 2015, 30: 57–77. doi: 10.1016/j.image.2014.10.009. [28] LIN Hanhe, HOSU V, and SAUPE D. KADID-10k: A large-scale artificially distorted IQA database[C]. 2019 11th International Conference on Quality of Multimedia Experience (QoMEX), Berlin, Germany, 2019: 1–3. doi: 10.1109/QoMEX.2019.8743252. [29] GHADIYARAM D and BOVIK A C. Massive online crowdsourced study of subjective and objective picture quality[J]. IEEE Transactions on Image Processing, 2016, 25(1): 372–387. doi: 10.1109/TIP.2015.2500021. [30] ZHAO Yongcan, ZHANG Yinghao, XIA Tianfeng, et al. No-reference image quality assessment based on multi-scale dynamic modulation and degradation information[J]. Displays, 2026, 91: 103207. doi: 10.1016/j.displa.2025.103207. -

 下载:
下载:




图(7) / 表(4)
计量
- 文章访问数: 467
- HTML全文浏览量: 239
- PDF下载量: 45
- 被引次数: 0
