

Entropy-driven Adaptive Fusion Network for Scene Classification of High-Resolution Remote Sensing Images
-
摘要: 高分辨遥感图像场景分类因复杂背景、多样成像条件及类内差异大等因素面临显著挑战,而传统卷积神经网络(CNN)方法在全局上下文建模方面存在局限,Swin Transformer在跨窗口特征交互、细粒度局部特征提取以及多层次特征自适应融合方面仍存在不足。针对上述问题,该文提出一种面向高分辨遥感图像场景分类的熵驱动自适应融合网络,主要创新与贡献概括如下:(1)设计注意力引导的区域筛选与特征优化模块(ASO),通过跨窗口稀疏注意力增强全局建模能力并筛选关键区域,结合递归优化强化局部特征表示,增强了模型跨窗口交互能力与细粒度局部特征判别性;(2)构建熵驱动门控融合模块(EGF),利用熵指导的门控机制对Swin特征、全局上下文与优化后的局部特征进行自适应融合,克服多层次特征简单融合易引入冗余的问题;(3)在AID与NWPU-RESISC45公开数据集上的实验表明,所提方法在分类精度上优于多种现有先进方法,展现出良好的鲁棒性与泛化能力。
-
关键词:
- 遥感图像场景分类 /
- 熵 /
- 特征融合 /
- Swin-Transformer网络
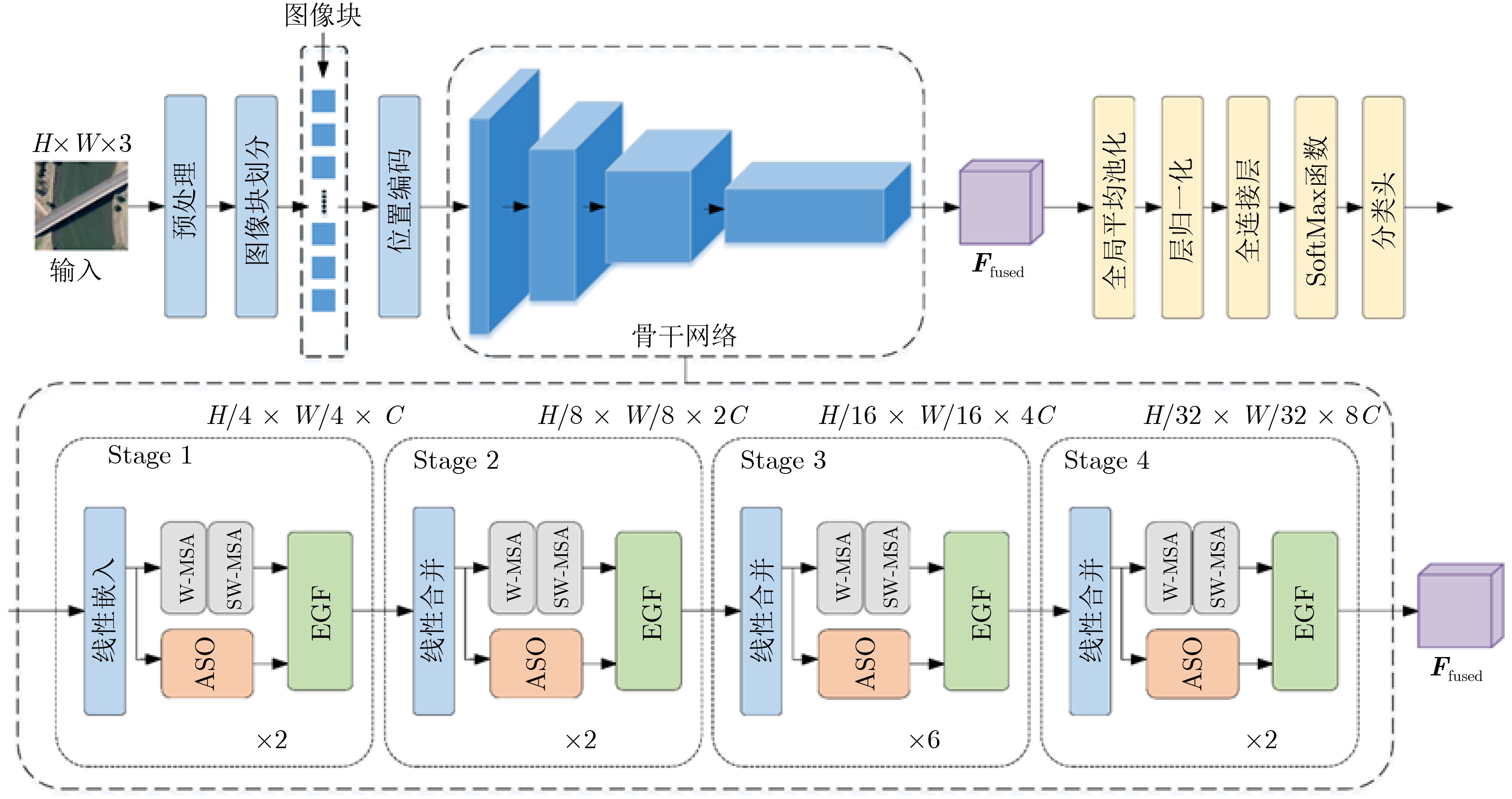
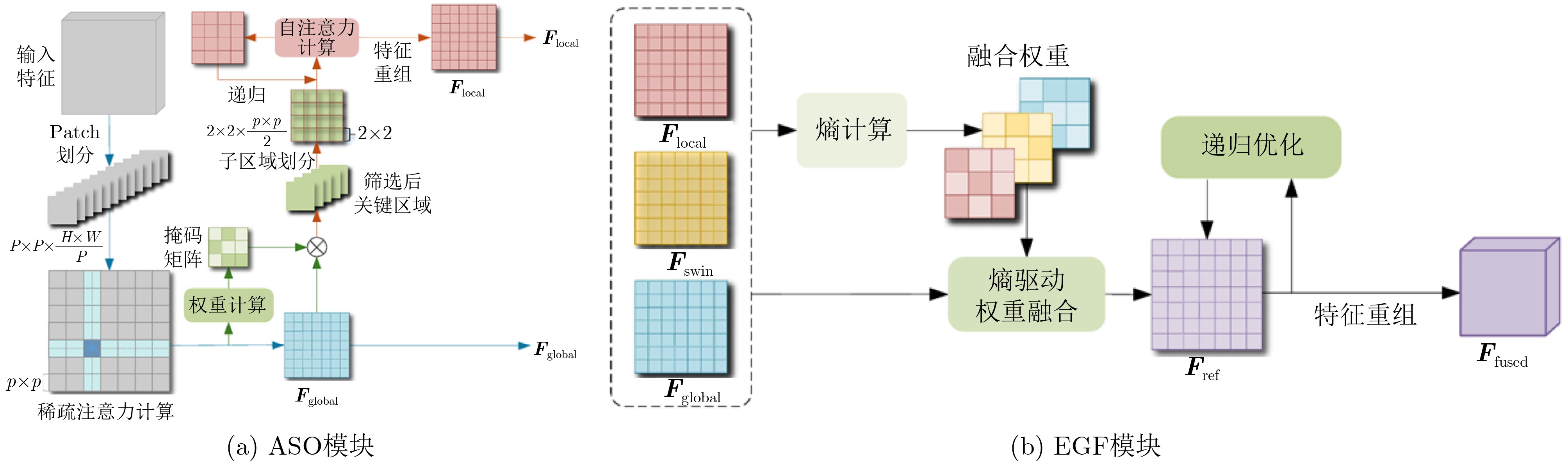
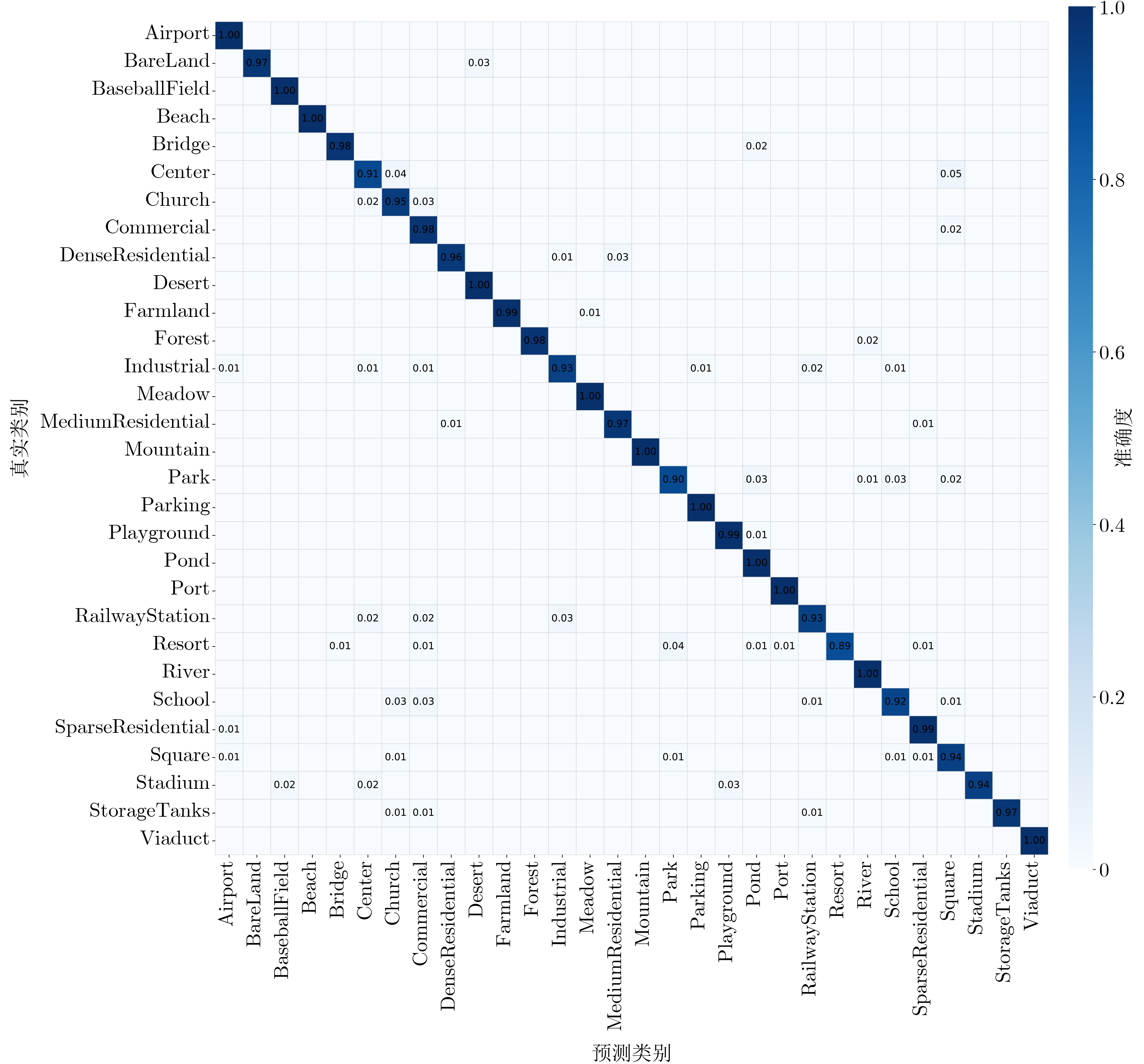
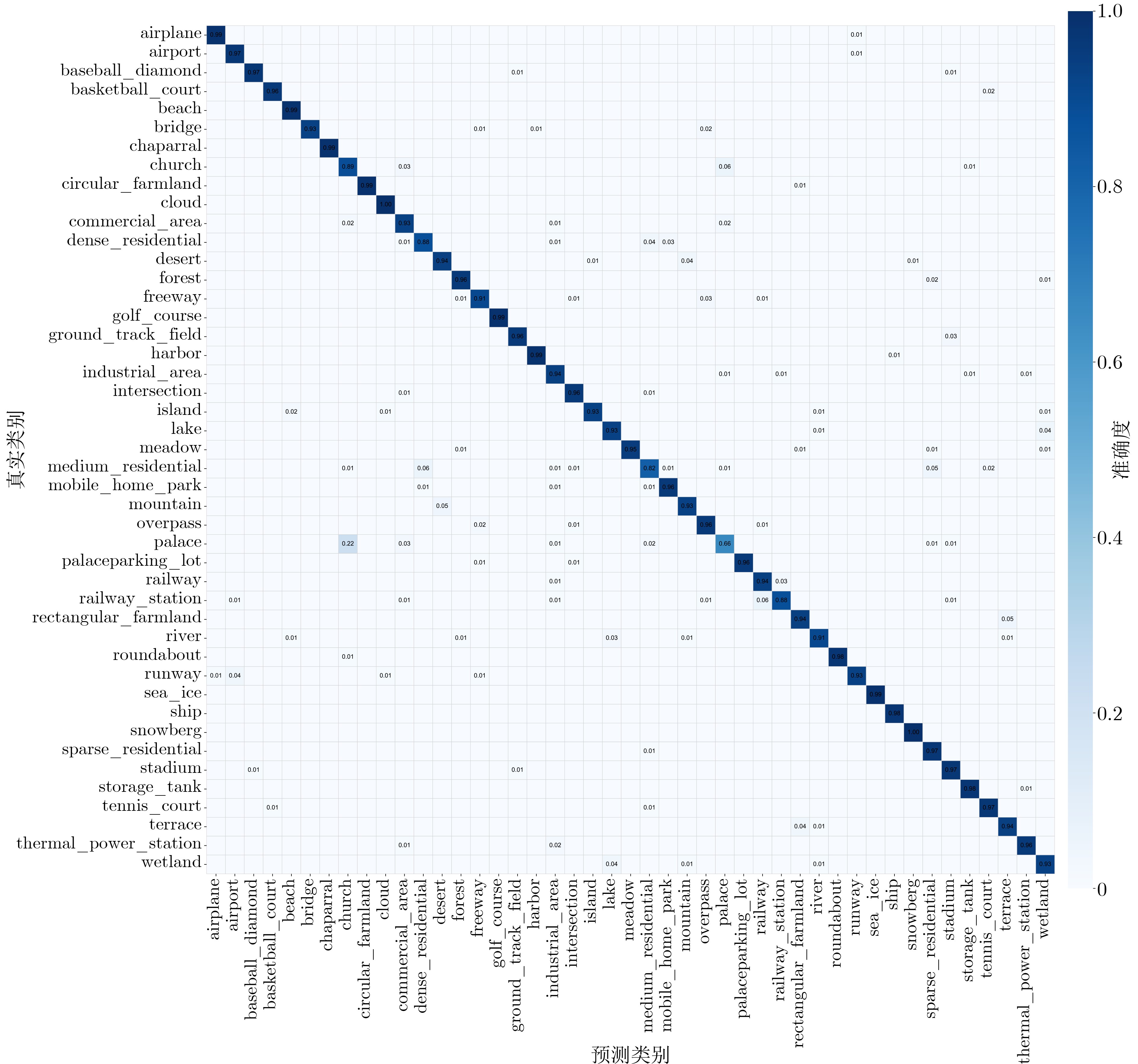
Abstract:Objective Remote sensing image scene classification is intended to assign semantic labels to aerial or satellite images. With the rapid development of Earth observation technologies, high-resolution remote sensing images provide abundant detail but also present major challenges, including complex spatial structures, large scale variations, high intra-class variance, and strong inter-class similarity. Traditional Convolutional Neural Networks (CNNs) have achieved notable success in local spatial modeling, but they cannot adequately capture long-range dependencies because of their fixed receptive fields. To address this limitation, CNN-Transformer hybrid architectures have been proposed to balance local detail and global semantics. However, these models usually adopt simple concatenation for multi-scale feature fusion, which introduces redundancy and reduces discriminability. In addition, although the Swin Transformer uses window-based self-attention to capture contextual information, it still shows clear limitations in the analysis of complex high-resolution images. Specifically, long-range dependency modeling across windows is constrained by the fixed window size. The extraction of fine-grained local features is also limited because deep networks tend to overlook crucial fine-texture information from low- and mid-level features. Moreover, existing multi-level feature fusion strategies lack semantic guidance and therefore readily introduce background noise. Therefore, a network that can balance global contextual modeling and local discriminability while enabling adaptive fusion is still needed. Methods To address limited cross-window interaction and the absence of semantic guidance in multi-level feature fusion, an Entropy-driven Adaptive Fusion Swin Transformer (E-AF-ST) network is proposed. The architecture uses a lightweight Swin-Tiny backbone and incorporates two key modules: the Attention-guided region Selection and feature Optimization module (ASO) and the Entropy-driven Gated Fusion module (EGF) ( Fig. 1 ). The ASO module addresses weak cross-window interaction and insufficient fine-grained feature extraction in the Swin Transformer through three consecutive stages (Fig. 2a ). First, cross-window sparse attention is computed to remove physical window boundaries. By enlarging the patch partition size, sparse attention is applied to the entire image sequence, allowing global contextual correlations across the whole image to be captured. Second, dynamic region selection is performed. On the basis of pixel-level entropy measurement, a multilayer perceptron maps entropy features to attention scores, and a Top-k masking strategy dynamically selects the most informative discriminative regions. Third, recursive feature optimization is performed. Multi-head self-attention and layer normalization are applied at the local scale to progressively enhance boundaries and microstructural information. The EGF module then integrates the Swin Transformer output features, the globally enhanced contextual features, and the locally optimized features to reduce semantic discrepancies (Fig. 2b ). First, energy normalization is performed using the Frobenius norm to obtain a probabilistic energy distribution. Next, an entropy-driven gated fusion mechanism calculates the Shannon entropy for each branch. A learnable soft-normalization gating function then maps the entropy information to normalized fusion weights, automatically reducing the weight of branches with high entropy caused by cluttered backgrounds. Finally, the fused representations undergo lightweight recursive optimization using depthwise separable convolutions and GELU activation functions with residual connections to suppress redundant information. The forward propagation process is systematically summarized in Algorithm 1.Results and Discussions To validate the discriminative capability of the proposed network, extensive experiments were conducted on two widely used public datasets, AID and NWPU-RESISC45. The proposed E-AF-ST network shows superior classification performance compared with existing advanced methods ( Table 1 ). On the AID dataset, the model achieves state-of-the-art overall accuracies of 95.56% and 97.21% at training ratios of 20% and 50%, respectively. On the challenging NWPU-RESISC45 dataset, it achieves the highest accuracies of 92.45% and 94.59% at training ratios of 10% and 20%, respectively. The confusion matrices show that the recognition accuracy of most categories exceeds 95% (Figs. 3 ,4 ), and the misclassification proportions for classes with complex backgrounds are significantly lower than those of the baseline model (Table 2). Visual analysis based on Grad-CAM further confirms the advantages of the E-AF-ST network in global contextual modeling and critical region selection. Compared with the Swin-Tiny baseline, the proposed network demonstrates more precise semantic focus (Fig. 5 ). In “airport” and “port” scenes, background noise is effectively suppressed and key targets are accurately highlighted. In structurally complex scenes such as “viaducts" and “railway stations”, extension directions and texture characteristics are comprehensively captured. Ablation experiments confirm that the cross-window sparse attention in the ASO module and the dynamic weight allocation in the EGF module are highly complementary. Furthermore, this performance gain is achieved with only a minimal increase in model complexity, with a total of 30.45M parameters and 4.72G- FLOPs.Conclusions An E-AF-ST network is proposed to address insufficient extraction of local discriminative information, cross-scale feature inconsistency, and semantic redundancy in high-resolution remote sensing image scene classification. With information entropy used as a guiding metric, the ASO module enables precise selection and recursive optimization of discriminative regions, whereas the EGF module achieves adaptive and redundancy-reduced integration of multi-source features. Experimental and visual results show that the proposed method effectively reduces interference from complex backgrounds and outperforms existing mainstream CNN-Transformer hybrid architectures. This study provides a new theoretical perspective and technical route for multi-scale target perception and feature semantic alignment. -
1 E-AF-ST网络前向传播过程
输入:高分辨遥感图像$ \boldsymbol{I}\in {{R}}^{{H}\times {W}\times {C}} $ 参数:ASO递归次数$ {T} $,EGF递归次数$ {K} $ 输出:场景分类概率分布$ \boldsymbol{P} $ 1://第1阶段:多层特征提取 2:$ {\boldsymbol{F}}_{{{\mathrm{swin}}}}\leftarrow \text{SwinTiny}\left(\boldsymbol{I}\right) $ 3://第2阶段:区域筛选与特征优化 4:$ {\boldsymbol{F}}_{{{\mathrm{global}}}}\leftarrow \text{SparseAttention}\left({\boldsymbol{F}}_{\rm{swin}}\right) $ 5:$ \boldsymbol{\alpha }\leftarrow \text{Sigmoid}\left(\text{MLP}\left(\text{Entropy}\left({\boldsymbol{F}}_{\rm{global}}\right)\right)\right) $ 6:$ \boldsymbol{M}\leftarrow {{\text{Top-}}k}\left(\boldsymbol{\alpha }\right) $ 7:$ {\boldsymbol{F}}_{\rm{sel}}\leftarrow {\boldsymbol{F}}_{\rm{global}}\odot \boldsymbol{M} $ 8:$ {\boldsymbol{S}}_{0}\leftarrow {\boldsymbol{F}}_{\rm{sel}} $ 9:For $ {t}={1} $ to $ {T} $ do 10: $ {\boldsymbol{S}}_{{t}}\leftarrow \text{LayerNorm}\left({\boldsymbol{S}}_{{t}-{1}}\right)+\text{MHSA}\left({\boldsymbol{S}}_{{t}-{1}}\right) $ 11:End For 12:$ {\boldsymbol{F}}_{\rm{local}}\leftarrow \text{Reshape}\left({\boldsymbol{S}}_{{T}}\right) $ 13://第3阶段:熵驱动门控融合 14:$ {\boldsymbol{P}}_{\rm{swin}},{\boldsymbol{P}}_{\rm{global}},{\boldsymbol{P}}_{\rm{local}}\leftarrow \text{EnergyNorm}\left({\boldsymbol{F}}_{\rm{swin}},\right. $
$\left. {\boldsymbol{F}}_{\rm{global}},{\boldsymbol{F}}_{\rm{local}}\right) $15:$ {\mathcal{H}}_{\mathrm{s}},{\mathcal{H}}_{\mathrm{g}},{\mathcal{H}}_{\mathrm{l}}\leftarrow \text{CalcEntropy}\left({\boldsymbol{P}}_{\rm{swin}},{\boldsymbol{P}}_{\rm{global}},{\boldsymbol{P}}_{\rm{local}}\right) $ 16:$ \boldsymbol{w}\leftarrow \text{Softmax}\left({\alpha }\cdot \left[{1}-{\mathcal{H}}_{\text{s}},{1}-{\mathcal{H}}_{\text{g}},{1}-{\mathcal{H}}_{\text{l}}\right]\right) $ 17:$ {\boldsymbol{F}}_{\rm{mix}}\leftarrow {\boldsymbol{w}}_{{1}}{\boldsymbol{F}}_{\rm{swin}}+{\boldsymbol{w}}_{{2}}{\boldsymbol{F}}_{\rm{global}}+{\boldsymbol{w}}_{{3}}{\boldsymbol{F}}_{\rm{local}} $ 18:$ \boldsymbol{F}_{\rm{ref}}^{0}\leftarrow {\boldsymbol{F}}_{\rm{mix}} $ 19:For $ {k}={1} $ to $ {K} $ do 20: $ \boldsymbol{F}_{\rm{ref}}^{{k}}\leftarrow \text{LayerNorm}\left(\text{Conv}\left(\text{GELU}\left(\boldsymbol{F}_{\rm{ref}}^{{k}-{1}}\right)\right)\right)+\boldsymbol{F}_{\rm{ref}}^{{k}-{1}} $ 21:End For 22:$ {\boldsymbol{F}}_{\rm{fused}}\leftarrow \boldsymbol{F}_{\rm{ref}}^{{K}}+{\boldsymbol{F}}_{\rm{mix}} $ 23://第4阶段:分类输出 24:$ \boldsymbol{y}\leftarrow \text{GlobalAvgPool}\left({\boldsymbol{F}}_{\rm{fused}}\right) $ 25:$ \boldsymbol{P}\leftarrow \text{Softmax}\left(\text{Classifier}\left(\boldsymbol{y}\right)\right) $ 26:Return $ \boldsymbol{P} $  下载: 导出CSV
下载: 导出CSV
表 1 不同训练比例下消融实验OA值(%)
方法 AID NWPU-RESISC45 20%训练集 50%训练集 10%训练集 20%训练集 Baseline 94.56 96.92 90.84 93.18 +ASO 95.12 97.05 91.52 93.97 +EGF 94.78 96.89 91.2 93.65 E-AF-ST 95.56 97.21 92.45 94.59
下载: 导出CSV
表 2 不同方法在AID与在NWPU-RESISC45数据集上的分类准确率对比(%)
方法 AID数据集 NWPU-RESISC45数据集 Params
(M)FLOPs
(G)20%训练集 50%训练集 10%训练集 20%训练集 Swin-Tiny[14] 94.56±0.14 96.92±0.12 90.84±0.09 93.18±0.15 29 4.5 ResNet101+EAM[18] 94.26±0.11 97.06±0.19 91.91±0.22 94.29±0.09 - - MGS-Net[19] 95.46±0.21 97.18±0.16 92.40±0.16 94.57±0.12 - - SAGN[20] 95.17±0.12 96.77±0.18 91.73±0.18 93.49±0.10 - - CSCA-Net[6] 94.67±0.20 96.83±0.14 91.27±0.11 93.72±0.10 - - MBAF-Net[7] 93.98±0.15 96.93±0.16 91.61±0.14 94.01±0.08 24.48 4.51 EMTCAL[21] 94.69±0.14 96.41±0.23 91.63±0.19 93.65±0.12 - - AC-Net[22] 93.33±0.29 95.38±0.29 91.09±0.13 92.42±0.16 - - E-AF-ST(本文) 95.56±0.19 97.21±0.16 92.45±0.15 94.59±0.11 30.45 4.72
下载: 导出CSV
-
[1] 李大湘, 南艺璇, 刘颖. 面向遥感图像场景分类的双知识蒸馏模型[J]. 电子与信息学报, 2023, 45(10): 3558–3567. doi: 10.11999/JEIT221017.LI Daxiang, NAN Yixuan, and LIU Ying. A double knowledge distillation model for remote sensing image scene classification[J]. Journal of Electronics & Information Technology, 2023, 45(10): 3558–3567. doi: 10.11999/JEIT221017. [2] 吴倩倩, 倪康, 郑志忠. 基于双阶段高阶Transformer的遥感图像场景分类[J]. 遥感学报, 2025, 29(3): 792–807. doi: 10.11834/jrs.20233332.WU Qianqian, NI Kang, and ZHENG Zhizhong. Remote sensing image scene classification on the basis of a two-stage high-order Transformer[J]. National Remote Sensing Bulletin, 2025, 29(3): 792–807. doi: 10.11834/jrs.20233332. [3] CHEN Jianlai, XIONG Rongqi, YU Hanwen, et al. Microwave photonic synthetic aperture radar: Systems, experiments, and imaging processing[J]. IEEE Geoscience and Remote Sensing Magazine, 2025, 13(2): 314–328. doi: 10.1109/MGRS.2024.3444777. [4] 尹文昕, 于海琛, 刁文辉, 等. 遥感场景理解中视觉Transformer的参数高效微调[J]. 电子与信息学报, 2024, 46(9): 3731–3738. doi: 10.11999/JEIT240218.YIN Wenxin, YU Haichen, DIAO Wenhui, et al. Parameter efficient fine-tuning of vision transformers for remote sensing scene understanding[J]. Journal of Electronics & Information Technology, 2024, 46(9): 3731–3738. doi: 10.11999/JEIT240218. [5] CHENG Gong, HAN Junwei, and LU Xiaoqiang. Remote sensing image scene classification: Benchmark and state of the art[J]. Proceedings of the IEEE, 2017, 105(10): 1865–1883. doi: 10.1109/JPROC.2017.2675998. [6] HOU Yan’e, YANG Kang, DANG Lanxue, et al. Contextual spatial-channel attention network for remote sensing scene classification[J]. IEEE Geoscience and Remote Sensing Letters, 2023, 20: 6008805. doi: 10.1109/LGRS.2023.3304645. [7] SHI Jiacheng, LIU Wei, SHAN Haoyu, et al. Remote sensing scene classification based on multibranch fusion attention network[J]. IEEE Geoscience and Remote Sensing Letters, 2023, 20: 3001505. doi: 10.1109/LGRS.2023.3262407. [8] PAN Wenwen, SUN Xiaofei, WANG Yilun, et al. Enhanced photovoltaic panel defect detection via adaptive complementary fusion in YOLO-ACF[J]. Scientific Reports, 2024, 14(1): 26425. doi: 10.1038/s41598-024-75772-9. [9] 徐从安, 吕亚飞, 张筱晗, 等. 基于双重注意力机制的遥感图像场景分类特征表示方法[J]. 电子与信息学报, 2021, 43(3): 683–691. doi: 10.11999/JEIT200568.XU Congan, LÜ Yafei, ZHANG Xiaohan, et al. A discriminative feature representation method based on dual attention mechanism for remote sensing image scene classification[J]. Journal of Electronics & Information Technology, 2021, 43(3): 683–691. doi: 10.11999/JEIT200568. [10] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. The 9th International Conference on Learning Representations (ICLR), 2021: 1–21. [11] SONG Jiayin, FAN Yiming, SONG Wenlong, et al. SwinHCST: A deep learning network architecture for scene classification of remote sensing images based on improved CNN and transformer[J]. International Journal of Remote Sensing, 2023, 44(23): 7439–7463. doi: 10.1080/01431161.2023.2285739. [12] HUANG Xinyan, LIU Fang, CUI Yuanhao, et al. Faster and better: A lightweight transformer network for remote sensing scene classification[J]. Remote Sensing, 2023, 15(14): 3645. doi: 10.3390/rs15143645. [13] LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. The 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 10012–10022. doi: 10.1109/ICCV48922.2021.00986. [14] JANNAT F E and WILLIS A R. Improving classification of remotely sensed images with the Swin transformer[C]. SoutheastCon 2022, Mobile, USA, 2022: 611–618. doi: 10.1109/SoutheastCon48659.2022.9764016. [15] CHANG Jing, HE Xiaohui, SONG Dingjun, et al. A multi-scale attention network for building extraction from high-resolution remote sensing images[J]. Scientific Reports, 2025, 15(1): 24938. doi: 10.1038/s41598-025-09086-9. [16] YE Zhipin, LIU Yingqian, JING Teng, et al. A high-resolution network with strip attention for retinal vessel segmentation[J]. Sensors, 2023, 23(21): 8899. doi: 10.3390/s23218899. [17] XIA Guisong, HU Jingwen, HU Fan, et al. AID: A benchmark data set for performance evaluation of aerial scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(7): 3965–3981. doi: 10.1109/TGRS.2017.2685945. [18] ZHAO Zhicheng, LI Jiaqi, LUO Ze, et al. Remote sensing image scene classification based on an enhanced attention module[J]. IEEE Geoscience and Remote Sensing Letters, 2021, 18(11): 1926–1930. doi: 10.1109/LGRS.2020.3011405. [19] WANG Junjie, LI Wei, ZHANG Mengmeng, et al. Remote-sensing scene classification via multistage self-guided separation network[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5615312. doi: 10.1109/TGRS.2023.3295797. [20] YANG Yuqun, TANG Xu, CHEUNG Y M, et al. SAGN: Semantic-aware graph network for remote sensing scene classification[J]. IEEE Transactions on Image Processing, 2023, 32: 1011–1025. doi: 10.1109/TIP.2023.3238310. [21] TANG Xu, LI Mingteng, MA Jingjing, et al. EMTCAL: Efficient multiscale transformer and cross-level attention learning for remote sensing scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5626915. doi: 10.1109/TGRS.2022.3194505. [22] TANG Xu, MA Qinshuo, ZHANG Xiangrong, et al. Attention consistent network for remote sensing scene classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 2030–2045. doi: 10.1109/JSTARS.2021.3051569. -

 下载:
下载:



图(5) / 表(3)
计量
- 文章访问数: 515
- HTML全文浏览量: 282
- PDF下载量: 64
- 被引次数: 0
