

Graph Representation Learning Driven Adaptive Streaming for Point Cloud Video
-
摘要: 针对点云视频流在带宽受限网络下面临的用户体验质量(QoE)保障难题,该文提出一种融合视区预测与动态质量分配的QoE优化框架。为提升预测精度,设计一种基于图表示学习的视区预测方案,通过显式建模用户在三维场景中的空间上下文与移动模式,并将学习到的空间先验知识与用户历史轨迹相融合,以提升六自由度(6DoF)视区预测的长期准确性。为实现智能分配,该文提出一种基于上下文赌博机的动态质量分配方案。该方案根据实时上下文信息,在带宽约束下为各空间切块自适应地分配质量等级,旨在提升长期累积QoE,保障用户体验。在公开数据集上的仿真实验结果表明,该文方案在视区预测精度和综合QoE上均显著优于多种基线方案,展现了优异的适应性与稳定性。Abstract:
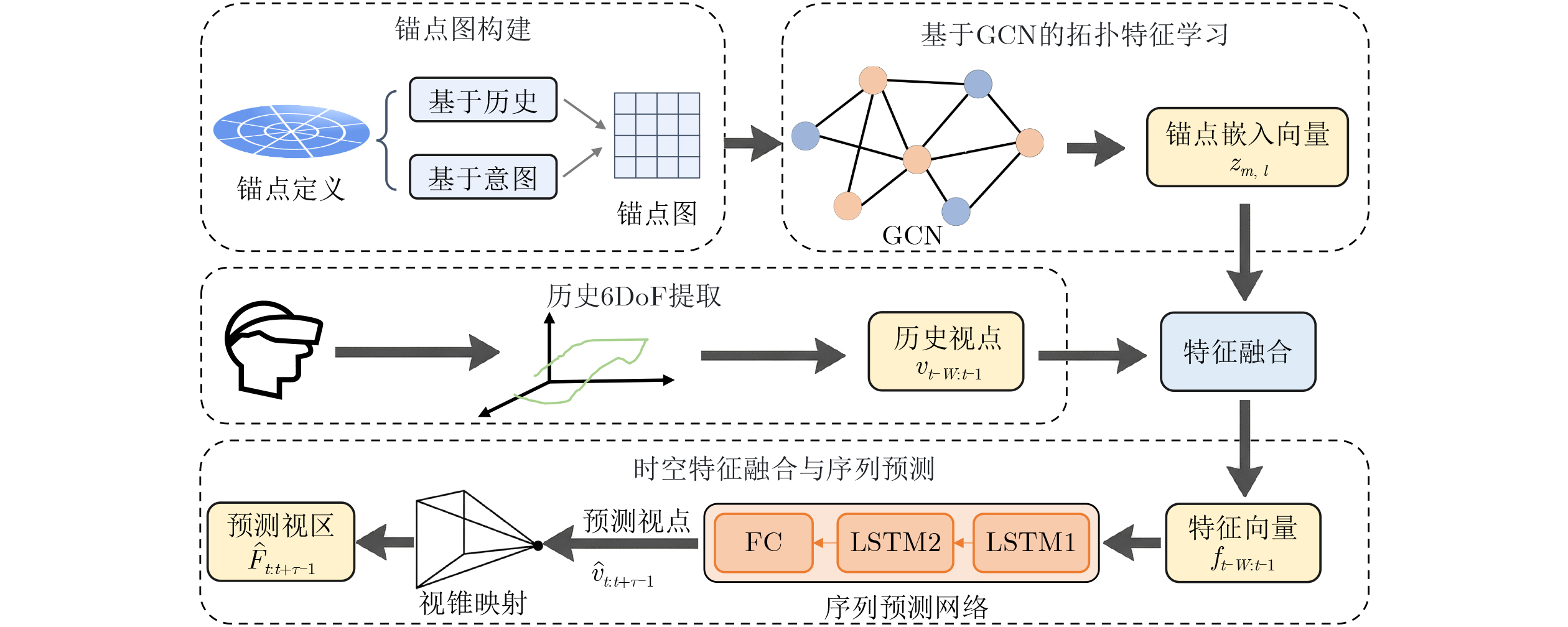
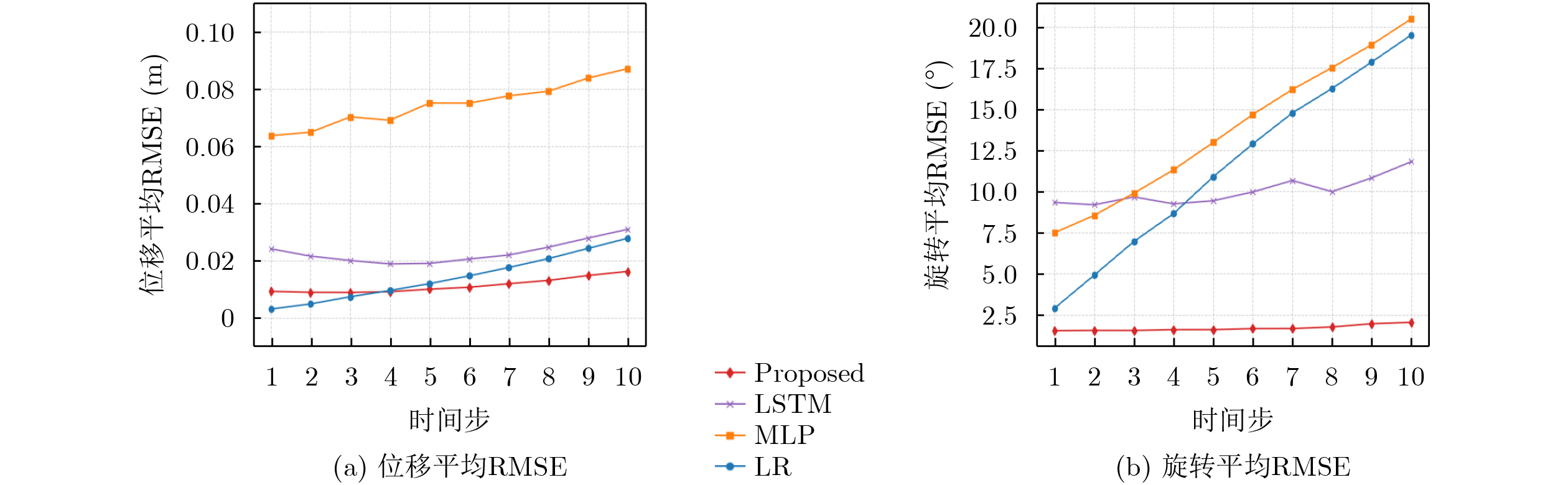
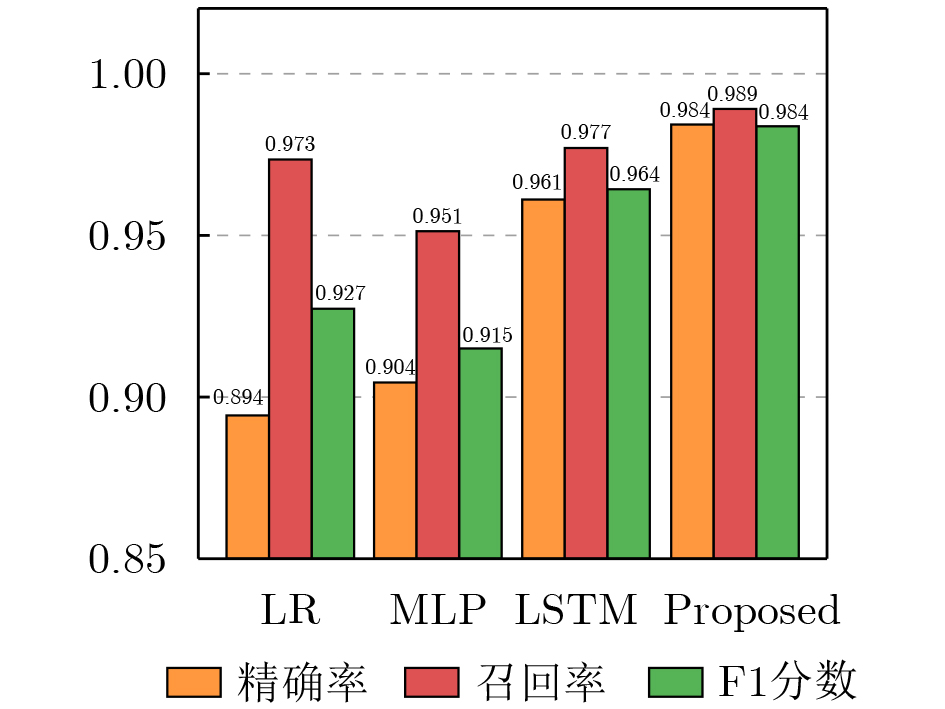
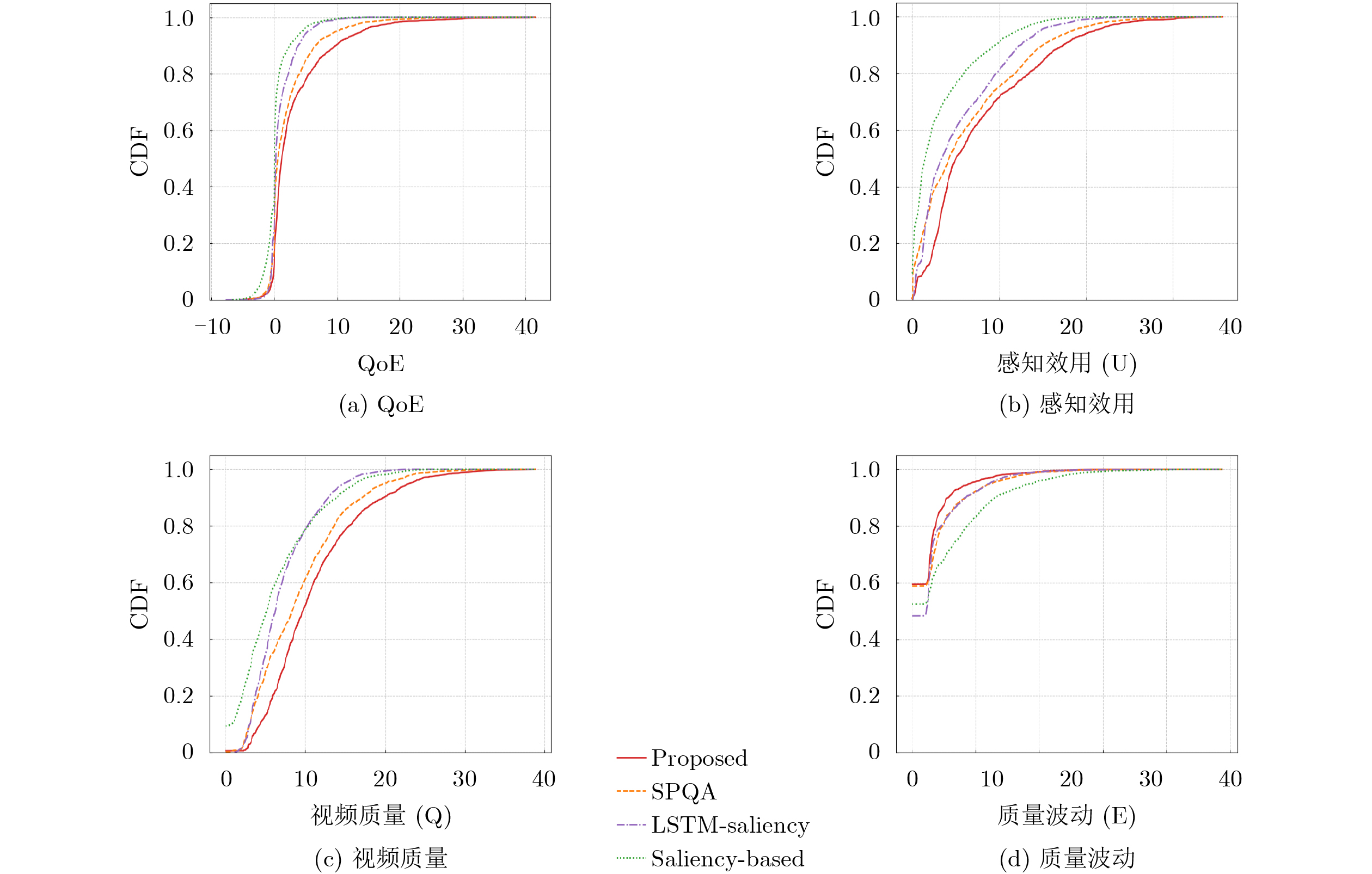
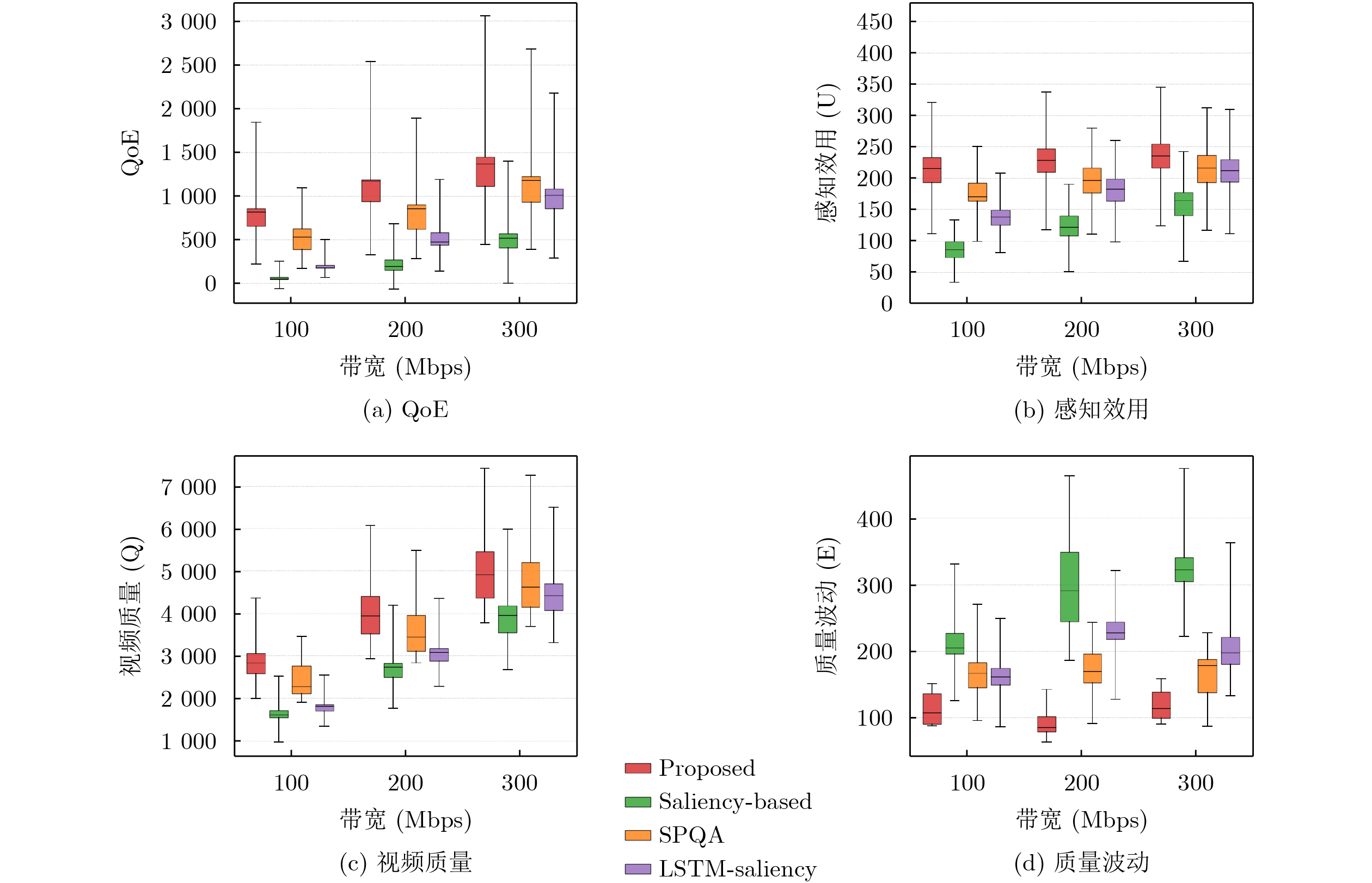
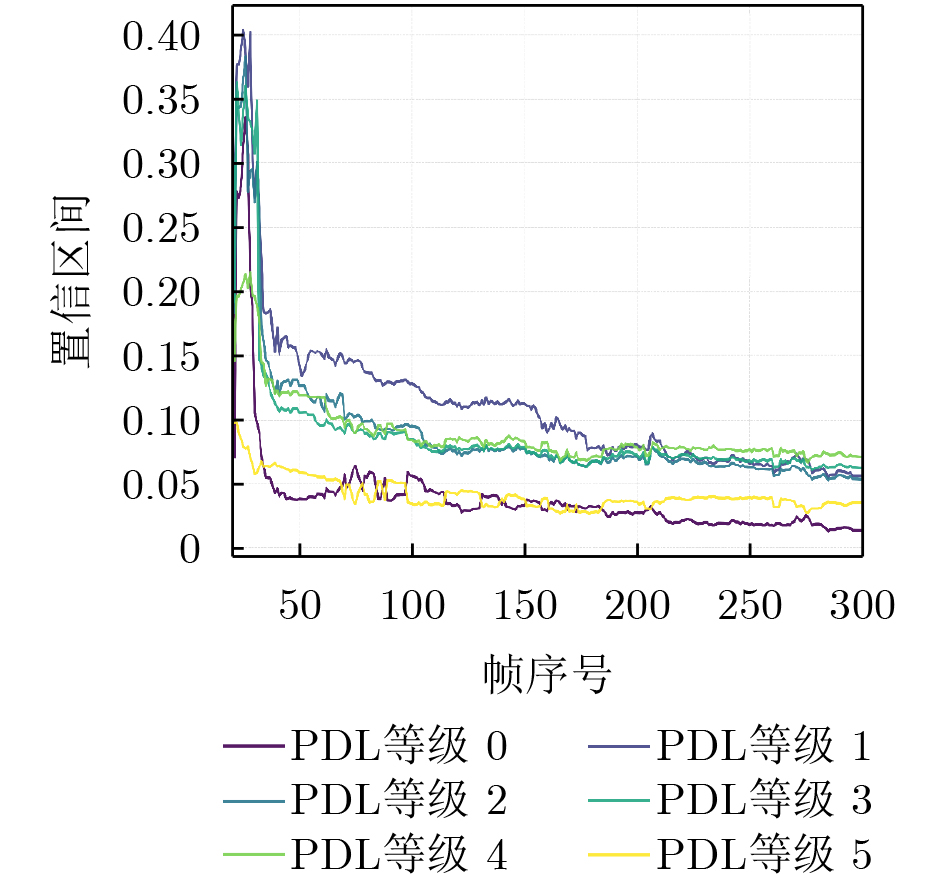
Objective The increasing demand for immersive media propels point cloud video into the spotlight for applications such as virtual and augmented reality. However, the massive data volume of point cloud streams poses a significant challenge to current network infrastructures, jeopardizing the user’s Quality of Experience (QoE) under limited bandwidth. Existing Adaptive BitRate (ABR) streaming solutions are hindered by two primary limitations. Viewport prediction models often focus solely on temporal features, leading to insufficient accuracy for long-term predictions in complex Six-Degrees-of-Freedom (6DoF) movement. Concurrently, dynamic quality allocation strategies struggle to make optimal online decisions under the uncertainties of prediction errors and network fluctuations, failing to effectively balance conflicting QoE metrics. This research addresses these challenges by proposing an integrated framework that combines high-precision viewport prediction with intelligent, context-aware quality allocation to enhance QoE for point cloud video streaming. Methods The proposed method integrates a graph-based viewport prediction scheme with a context-aware quality allocation mechanism. For viewport prediction, an “anchor point graph” is constructed to explicitly model the user’s spatial movement patterns. This graph is processed using representation learning to generate low-dimensional embeddings for each anchor point, which encapsulate rich spatial context. These learned spatial features are concatenated with real-time 6DoF viewport data to form a fused feature sequence. A stacked Long Short-Term Memory (LSTM) network processes this sequence to accurately predict the user’s future viewport trajectory. For quality allocation, the sequential decision-making process is modeled as a contextual bandit problem, adopting the LinUCB algorithm as the decision engine. At each decision epoch, a context vector is constructed for each spatial tile, incorporating critical information such as its predicted utility, historical quality level, and location relative to the predicted viewport. The LinUCB algorithm utilizes this context to select an optimal action for each tile, thereby maximizing cumulative QoE under the bandwidth budget, as detailed in Algorithm 1. Results and Discussions Extensive simulations validate the framework’s performance using the public 8i Voxelized Full Bodies dataset, real-world user viewport traces, and 5G network bandwidth profiles. In the viewport prediction task, the proposed model significantly outperforms baselines, achieving a stable average F1-score of 0.984 ( Fig. 4 ) and maintaining a consistently low Root-Mean-Square Error (RMSE) over long prediction horizons (Fig. 3 ). In the end-to-end streaming evaluation, the integrated framework demonstrates remarkable improvements in overall QoE. Cumulative Distribution Function (CDF) plots reveal that the proposed scheme consistently delivers higher QoE, user-perceived utility, and video quality, while incurring the lowest quality fluctuation (Fig. 5 ). Notably, under fluctuating network conditions, the solution improves the mean QoE by 54.82% compared to the next-best baseline at an average bandwidth of 100 Mbps (Fig. 6 ), highlighting its efficiency in resource-constrained environments.Conclusions This paper presents a complete adaptive streaming framework to address the QoE optimization challenge for point cloud video. By developing a novel 6DoF viewport prediction model that leverages graph representation learning, long-term prediction accuracy is significantly enhanced. Furthermore, by framing dynamic quality allocation as a contextual bandit problem, the system makes intelligent, online decisions that adapt to both prediction outcomes and dynamic network conditions. Comprehensive experimental results validate the effectiveness of this integrated approach, which consistently outperforms existing solutions in both prediction accuracy and overall user QoE. -
1 上下文感知的动态质量分配算法
输入:预测视区$ {\hat{F}}_{t} $,上下文列表$ {\{{\boldsymbol{x}}}_{t,k}\}_{k=1}^{K} $,带宽$ {B}_{t} $ 输出:切块质量分配列表$ \{{a}_{t,k}\}_{k=1}^{K} $ 1: 划分切块: $ {\mathcal{P}}_{{\mathrm{out}}},\;{\mathcal{P}}_{{\mathrm{pred}}} $ 2: $ {b}_{{\mathrm{in}}}\leftarrow g_{1}^{t}\cdot {B}_{t} $, $ {b}_{{\mathrm{out}}}\leftarrow {B}_{t}-{b}_{{\mathrm{in}}} $ 3: Function Allocate$ (\mathcal{K},{b}_{{\mathrm{budget}}}) $ 4: 按 $ {u}_{t,k,{\mathrm{maxlevel}}} $对切块列表$ \mathcal{K} $进行降序排序 5: for 所有切块$ {c}_{t,k}\in \mathcal{K} $ do 6: $ {a}_{t,k}\leftarrow \max\{a\mid {\mathrm{size}}({c}_{t,k},a)\leq {b}_{{\mathrm{budget}}}\} $ 7: $ {b}_{{\mathrm{budget}}}\leftarrow {b}_{{\mathrm{budget}}}-\text{size}({c}_{t,k},{a}_{t,k}) $ 8: 使用($ {x}_{t,k},{a}_{t,k},{\mathrm{rewar}}{d}_{t,k} $)更新LinUCB 9: end for 10: end Function 11: $ \text{Allocate}(\{k\mid k\in {\hat{F}}_{t}\},{b}_{{\mathrm{in}}}) $ 12: $ \text{Allocate}(\{k\mid k\notin {\hat{F}}_{t}\},{b}_{{\mathrm{out}}}) $ 13: return $ \{{a}_{t,k}\}_{k=1}^{K} $  下载: 导出CSV
下载: 导出CSV
表 1 实验参数设置
参数 值 输入/输出窗口(W/$ \tau $) 20/10 frame LSTM隐藏层结构 (128,64) 最大质量等级maxlevel 5 LinUCB探索参数$ \lambda $ 0.15 QoE权重因子$ \gamma $ (0.3,1,1)
下载: 导出CSV
-
[1] 王旭, 刘琼, 彭宗举, 等. 6DoF视频技术研究进展[J]. 中国图象图形学报, 2023, 28(6): 1863–1890. doi: 10.11834/jig.230025.WANG Xu, LIU Qiong, PENG Zongju, et al. Research progress of six degree of freedom (6DoF) video technology[J]. Journal of Image and Graphics, 2023, 28(6): 1863–1890. doi: 10.11834/jig.230025. [2] LIU Zhi, LI Qiyue, CHEN Xianfu, et al. Point cloud video streaming: challenges and solutions[J]. IEEE Network, 2021, 35(5): 202–209. doi: 10.1109/MNET.101.2000364. [3] 陈晓雷, 王兴, 张学功, 等. 面向360度全景图像显著目标检测的相邻协调网络[J]. 电子与信息学报, 2024, 46(12): 4529–4541. doi: 10.11999/JEIT240502.CHEN Xiaolei, WANG Xing, ZHANG Xuegong, et al. Adjacent coordination network for salient object detection in 360 degree omnidirectional images[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4529–4541. doi: 10.11999/JEIT240502. [4] BENTALEB A, LIM M, HAMMOUDI S, et al. Solutions, challenges, and opportunities in volumetric video streaming: An architectural perspective[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2025, 21(7): 187. doi: 10.1145/3705321. [5] D'EON E, HARRISON B, MYERS T, et al. 8i voxelized full bodies - a voxelized point cloud dataset[R]. ISO/IEC JTC1/SC29 Joint WG11/WG1 (MPEG/JPEG) input document WG11M40059/WG1M74006, 2017. [6] VAN DER HOOFT J, VEGA M T, WAUTERS T, et al. From capturing to rendering: Volumetric media delivery with six degrees of freedom[J]. IEEE Communications Magazine, 2020, 58(10): 49–55. doi: 10.1109/MCOM.001.2000242. [7] HU Qiang, ZHONG Houqiang, ZHENG Zihan, et al. VRVVC: Variable-rate NeRF-based volumetric video compression[C]. The Thirty-Ninth AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 3563–3571. doi: 10.1609/aaai.v39i4.32370. [8] 曾焕强, 孔庆玮, 陈婧, 等. 沉浸式视频编码技术综述[J]. 电子与信息学报, 2024, 46(2): 602–614. doi: 10.11999/JEIT230097.ZENG Huanqiang, KONG Qingwei, CHEN Jing, et al. Overview of immersive video coding[J]. Journal of Electronics & Information Technology, 2024, 46(2): 602–614. doi: 10.11999/JEIT230097. [9] 朱原玮, 黄亚坤, 乔秀全. 面向全息视频通信的自适应分块传输方法[J]. 电子学报, 2024, 52(4): 1144–1154. doi: 10.12263/DZXB.20230788.ZHU Yuanwei, HUANG Yakun, and QIAO Xiuquan. Towards holographic video communications: An adaptive tiling solution[J]. Acta Electronica Sinica, 2024, 52(4): 1144–1154. doi: 10.12263/DZXB.20230788. [10] LIU Junhua, ZHU Boxiang, WANG Fangxin, et al. CaV3: Cache-assisted viewport adaptive volumetric video streaming[C]. The 2023 IEEE Conference Virtual Reality and 3D User Interfaces (VR), Shanghai, China, 2023: 173–183. doi: 10.1109/VR55154.2023.00033. [11] LIU Shuquan, ZHANG Guanghui, XIAO Mengbai, et al. An intelligent prefetch strategy with multi-round cell enhancement in volumetric video streaming[C]. The 2024 21st Annual IEEE International Conference on Sensing, Communication, and Networking, Phoenix, USA, 2024: 1–9. doi: 10.1109/SECON64284.2024.10934826. [12] HAN Bo, LIU Yu, and QIAN Feng. ViVo: Visibility-aware mobile volumetric video streaming[C]. The 26th Annual International Conference on Mobile Computing and Networking, London, United Kingdom, 2020: 11. doi: 10.1145/3372224.3380888. [13] LI Jie, ZHANG Cong, LIU Zhi, et al. Optimal volumetric video streaming with hybrid saliency based tiling[J]. IEEE Transactions on Multimedia, 2023, 25: 2939–2953. doi: 10.1109/TMM.2022.3153208. [14] WANG Xi, LIU Wei, LIU Huitong, et al. Spatial perceptual quality aware adaptive volumetric video streaming[C]. IEEE Global Communications Conference (GLOBECOM), Kuala Lumpur, Malaysia, 2023: 1000–1005. doi: 10.1109/GLOBECOM54140.2023.10437209. [15] GÜL S, PODBORSKI D, BUCHHOLZ T, et al. Low-latency cloud-based volumetric video streaming using head motion prediction[C]. The 30th ACM Workshop on Network and Operating Systems Support for Digital Audio and Video, Istanbul, Turkey, 2020: 27–33. doi: 10.1145/3386290.3396933. [16] GÜL S, BOSSE S, PODBORSKI D, et al. Kalman filter-based head motion prediction for cloud-based mixed reality[C]. The 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 3632–3641. doi: 10.1145/3394171.3413699. [17] YU Yong, SI Xiaosheng, HU Changhua, et al. A review of recurrent neural networks: LSTM cells and network architectures[J]. Neural Computation, 2019, 31(7): 1235–1270. doi: 10.1162/neco_a_01199. [18] LI Jie, WANG Huiyu, LIU Zhi, et al. Toward optimal real-time volumetric video streaming: A rolling optimization and deep reinforcement learning based approach[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(12): 7870–7883. doi: 10.1109/TCSVT.2023.3277893. [19] HU Kaiyuan, YANG Haowen, JIN Yili, et al. Understanding user behavior in volumetric video watching: Dataset, analysis and prediction[C]. The 31st ACM International Conference on Multimedia, Ottawa, Canada, 2023: 1108–1116. doi: 10.1145/3581783.3613810. [20] WANG Lisha, LI Chenglin, DAI Wenrui, et al. QoE-driven and tile-based adaptive streaming for point clouds[C]. IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, Canada, 2021: 1930–1934. doi: 10.1109/ICASSP39728.2021.9414121. [21] SHI Yuang, CLEMENT B, and OOI W T. QV4: QoE-based viewpoint-aware V-PCC-encoded volumetric video streaming[C]. The 15th ACM Multimedia Systems Conference, Bari, Italy, 2024: 144–154. doi: 10.1145/3625468.3647619. [22] ZHANG Si, TONG Hanghang, XU Jiejun, et al. Graph convolutional networks: A comprehensive review[J]. Computational Social Networks, 2019, 6(1): 11. doi: 10.1186/s40649-019-0069-y. [23] LI Lihong, CHU Wei, LANGFORD J, et al. A contextual-bandit approach to personalized news article recommendation[C]. The 19th International Conference on World Wide Web, Raleigh, USA, 2010: 661–670. doi: 10.1145/1772690.1772758. [24] RACA D, LEAHY D, SREENAN C J, et al. Beyond throughput, the next generation: A 5G dataset with channel and context metrics[C]. The 11th ACM Multimedia Systems Conference, Istanbul, Turkey, 2020: 303–308. doi: 10.1145/3339825.3394938. [25] LU Yiyun, ZHU Yifei, and WANG Zhi. Personalized 360-degree video streaming: A meta-learning approach[C]. ACM Multimedia, Lisbon, Portugal, 2022: 1–10. doi: 10.1145/3503161.3548047. [26] WU Duo, WU Panlong, ZHANG Miao, et al. MANSY: Generalizing neural adaptive immersive video streaming with ensemble and representation learning[J]. IEEE Transactions on Mobile Computing, 2025, 24(3): 1654–1668. doi: 10.1109/TMC.2024.3487175. -

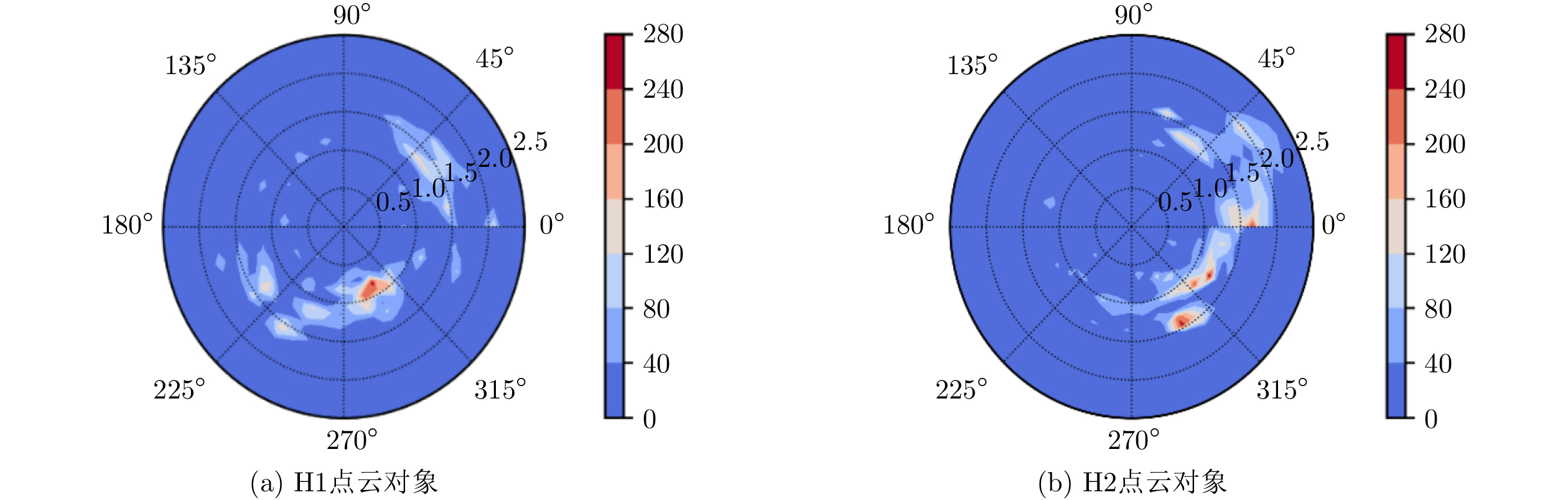
 下载:
下载:


图(7) / 表(2)
计量
- 文章访问数: 227
- HTML全文浏览量: 103
- PDF下载量: 7
- 被引次数: 0
