

Evaluation of Domestic Large Language Models as Educational Tools for Cancer Patients
-
摘要: 癌症发病率和死亡率持续攀升,有效的患者教育是降低疾病负担的重要手段。近年来,大语言模型在医学领域中展现出潜力,但其在癌症患者教育中的应用效果尚缺乏系统评估。该研究旨在比较3种国产大模型(豆包、Kimi和DeepSeek)在癌症患者健康教育中的表现。 通过肿瘤内科护士小组讨论收集常见教育问题,筛选出10个高频问题,涵盖饮食、营养、治疗及预后。分别输入3种模型进行回答,并采用盲法评价。13名住院癌症患者从“易理解性、有效性”两方面评分,6名资深肿瘤医生从准确性、全面性和专业性三方面评分。评分采用Likert 5级量表,并应用单因素方差分析、Welch方差分析及多重比较方法进行统计学处理。结果表明3种模型总体得分均在4分左右,总体差异有统计学意义(P=0.004)。患者维度评价中,Kimi在易理解性(4.615±0.534)和有效性(4.476±0.560)方面表现最佳;医生维度评价中,DeepSeek在准确性(4.117±0.846)、全面性(4.100±0.681)和专业性(3.917±0.645)方面表现最佳。豆包整体表现中等。综上所述, 国产大模型在癌症患者教育中展现出显著潜力。Kimi适合患者视角的信息传递,DeepSeek的信息输出更符合专业医学要求。研究提示患者评分与医生评分存在差异错位,未来可探索分层呈现或双重验证机制的文本生成策略,兼顾可理解性与专业性,并通过检索增强、微调等技术进一步优化,以推动建立智能化、精准化的癌症健康教育体系。Abstract:
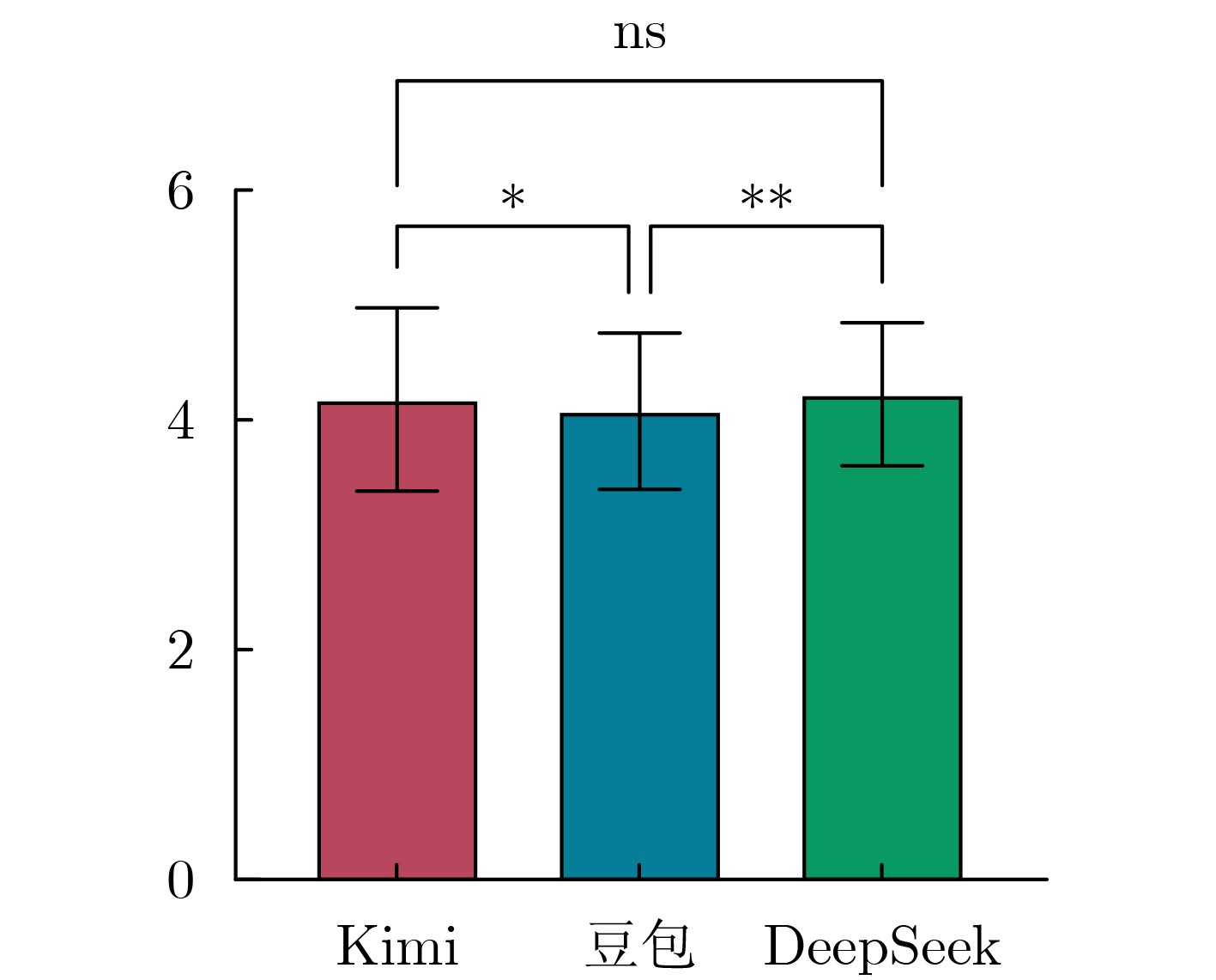
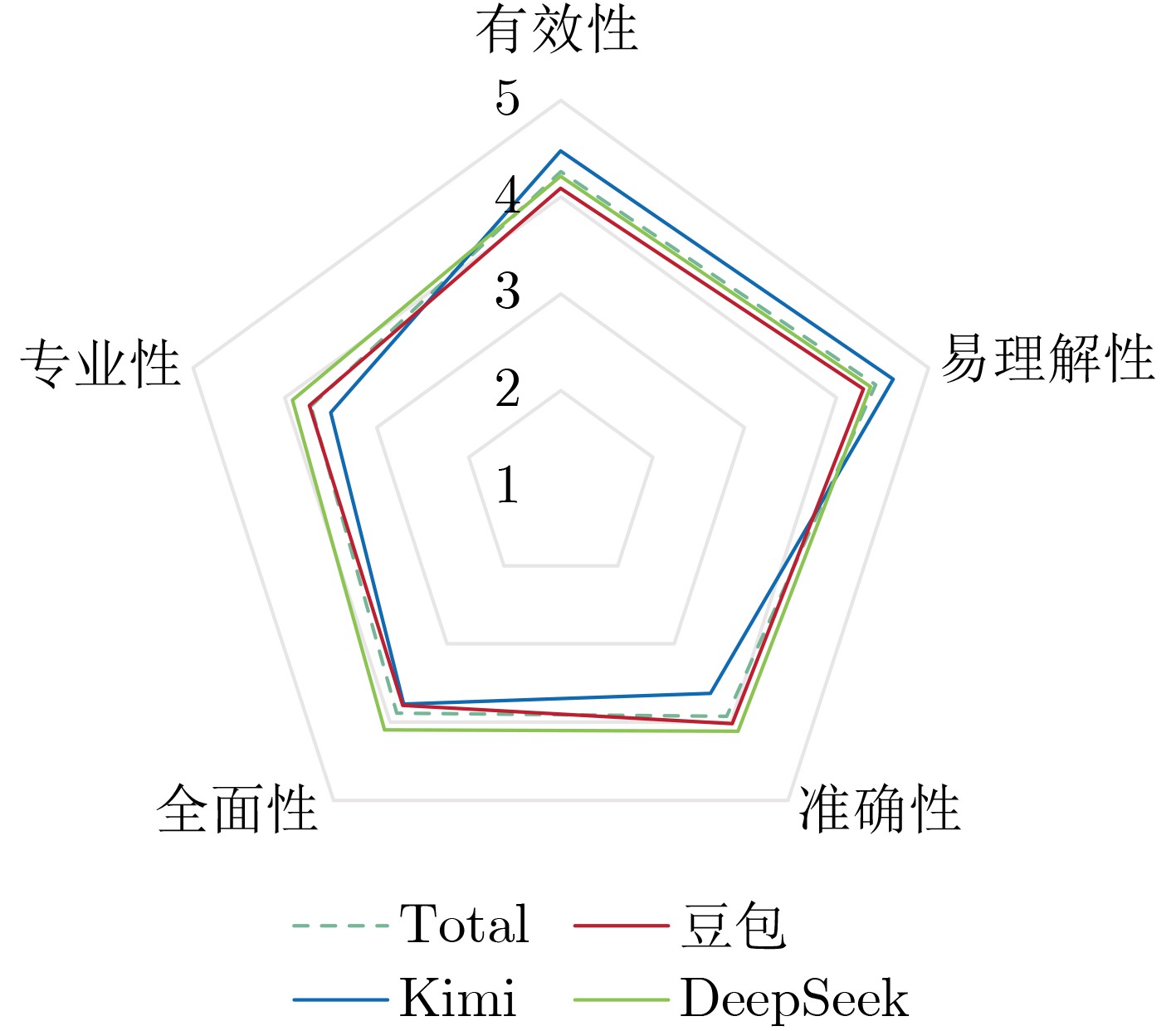
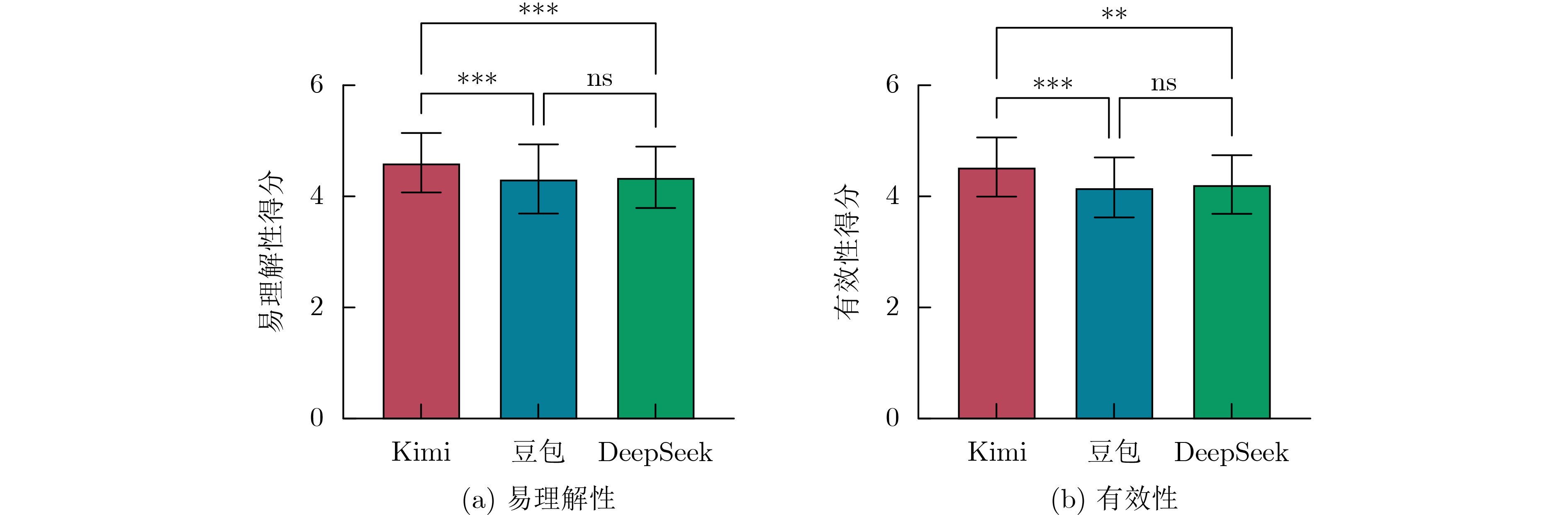
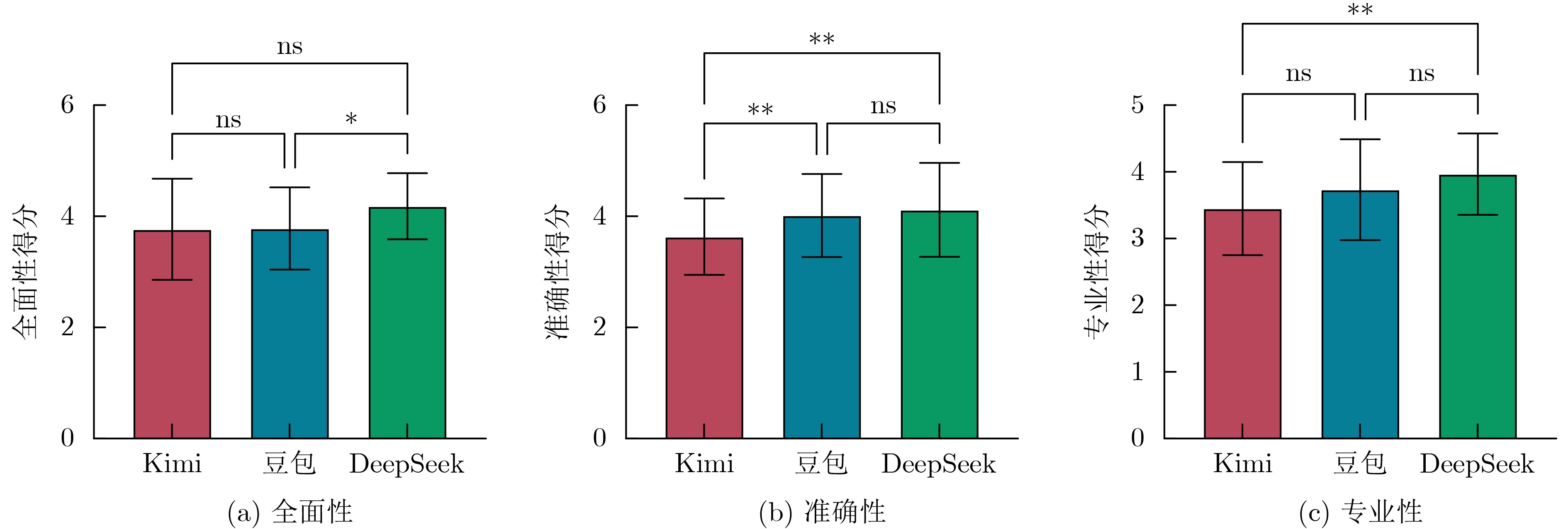
Objective With the rapid increase in cancer incidence and mortality worldwide, patient education has become a critical strategy for reducing the disease burden and improving patient outcomes. However, traditional education methods, such as paper-based materials or face-to-face consultations, are limited by time, space, and personalization constraints. The emergence of large language models (LLMs) has opened new opportunities for delivering intelligent, scalable, and personalized health education. Although domestic LLMs, such as Doubao, Kimi, and DeepSeek have been widely applied in general scenarios, their utility in oncology education remains underexplored. This study aimed to systematically evaluate the performance of three domestic LLMs in cancer patient education across multiple dimensions, providing empirical evidence for their potential clinical application and optimization. Methods Frequently asked patient education questions were collected through group discussions with oncology nurses from a tertiary hospital. Nineteen oncology nurses with ≥1 year of clinical experience participated in item selection, and the ten most common questions were chosen, covering domains such as diet, nutrition, treatment, adverse drug reactions, and prognosis. Each question was independently input into Doubao (Pro, ByteDance, May 2024), Kimi (V1.1, Moonshot AI, Nov 2023), and DeepSeek (R1, DeepSeek AI, Jan 2025) under “new chat” conditions to avoid contextual interference. Responses were standardized to remove model identifiers and randomly coded. Quality evaluation followed a blinded design. Thirteen inpatients with cancer assessed responses for readability and effectiveness, while six senior oncologists rated responses for accuracy, comprehensiveness, and professionalism. A self-designed five-point Likert scale was used for each dimension. Statistical analyses were conducted using GraphPad Prism 9.5.1. One-way ANOVA with Bonferroni correction was applied for dimensional comparisons, while Welch’s ANOVA and Games-Howell post hoc tests were used for overall score analysis. Results were visualized with tables and radar plots. Results and Discussions Overall, the three models achieved mean total scores of 4.05±0.687 (Doubao), 4.17±0.791 (Kimi), and 4.19±0.640 (DeepSeek). Welch’s ANOVA showed significant overall differences (F=5.537, P=0.004). Games-Howell analysis revealed that Doubao performed significantly worse than Kimi and DeepSeek (P=0.005 and 0.042, respectively), while Kimi and DeepSeek did not differ significantly (P=0.975). From the patient perspective, Kimi outperformed its peers, achieving the highest scores in readability (4.615±0.534) and effectiveness (4.476±0.560), with statistically significant differences (P<0.05). Patients rated Kimi’s responses to lifestyle-related queries, such as managing nausea or loss of appetite during chemotherapy, as particularly clear and actionable. From the expert perspective, DeepSeek demonstrated superiority in accuracy (4.117±0.846), comprehensiveness (4.100±0.681), and professionalism (3.917±0.645), with significant advantages over Kimi (P<0.01) and moderate superiority over Doubao (P<0.05). DeepSeek was favored for handling technical and evidence-based questions, such as drug metabolism or integrative therapy evaluation. The divergence between patient and expert assessments highlighted a mismatch: the “most understandable”responses (Kimi) were not always the “most professional” (DeepSeek). This complementarity suggests that future research should explore layered output formats or dual verification mechanisms. Such approaches would balance readability with professional rigor, minimizing the risks of misinformation while improving accessibility. Despite promising findings, limitations exist. This single-center study involved a relatively small sample size, and only patients with lung and breast cancer were included. The evaluation simulated static Q&A interactions rather than dynamic multi-turn dialogues, which are more representative of real-world consultations. Additionally, technical enhancements such as retrieval-augmented generation (RAG), fine-tuning with oncology-specific corpora, and multi-agent collaboration were not implemented. Future studies should expand to multi-center designs, diverse cancer populations, and advanced LLM optimization methods. Conclusions Domestic LLMs demonstrated significant potential as tools for cancer patient education. Kimi excelled in communication and patient-centered knowledge translation, while DeepSeek showed strength in professional accuracy and comprehensiveness. Doubao, although moderate across all dimensions, lagged behind in overall performance. The results indicate that LLMs can complement traditional health education by bridging the gap between patient comprehension and clinical expertise. -
Key words:
- Large Language Models (LLMs) /
- Cancer /
- Patient education /
- Readability /
- Professional accuracy
-
表 1 参与评价的10个化疗相关问题
编 号 内 容 1 化疗出现恶心呕吐怎么办 2 长效升白针有哪些副作用 3 化疗药物的毒性多久可以排出体外 4 化疗次数是由什么决定的 5 化疗期间不想吃东西怎么办 6 化疗后白细胞低怎么办 7 化疗后血小板低怎么办 8 化疗周期为什么定21天 9 化疗不良反应太大,中医药能否用于治疗肿瘤 10 化疗后癌细胞还会转移吗  下载: 导出CSV
下载: 导出CSV
表 2 模型层面的对比
平均分 DeepSeek Kimi 豆包 P 患者评价(N=130) 有效性 4.262± 0.55845 4.215± 0.52804 4.476± 0.55984 4.092± 0.52008 < 0.0001 易理解性 4.426± 0.59851 4.369± 0.55877 4.615± 0.53389 4.292± 0.65232 < 0.0001 医生评价(N=60) 准确性 3.922± 0.78716 4.117± 0.84560 3.633± 0.68807 4.017± 0.74769 0.0016 全面性 3.883± 0.79295 4.100± 0.68147 3.767± 0.90884 3.783± 0.73857 0.0336 专业性 3.717± 0.71905 3.917± 0.6455 3.500± 0.70109 3.733± 0.75614 0.0058
下载: 导出CSV
-
[1] BRAY F, LAVERSANNE M, SUNG H, et al. Global cancer statistics 2022: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries[J]. CA: A Cancer Journal for Clinicians, 2024, 74(3): 229–263. doi: 10.3322/caac.21834. [2] HAN Bingfeng, ZHENG Rongshou, ZENG Hongmei, et al. Cancer incidence and mortality in China, 2022[J]. Journal of the National Cancer Center, 2024, 4(1): 47–53. doi: 10.1016/j.jncc.2024.01.006. [3] 陈润生. 医疗大数据结合大语言模型的应用展望[J]. 四川大学学报: 医学版, 2023, 54(5): 855–856. doi: 10.12182/20230960301.CHEN Runsheng. Prospects for the application of healthcare big data combined with large language models[J]. Journal of Sichuan University: Medical Sciences, 2023, 54(5): 855–856. doi: 10.12182/20230960301. [4] LI Lulu, DU Pengqiang, HUANG Xiaojing, et al. Comparative analysis of generative artificial intelligence systems in solving clinical pharmacy problems: Mixed methods study[J]. JMIR Medical Informatics, 2025, 13: e76128. doi: 10.2196/76128. [5] MOONS P and VAN BULCK L. Using ChatGPT and Google bard to improve the readability of written patient information: A proof of concept[J]. European Journal of Cardiovascular Nursing, 2024, 23(2): 122–126. doi: 10.1093/eurjcn/zvad087. [6] 陈洁, 孟庆童, 刘惊今, 等. 基于指南的慢性心力衰竭患者运动康复科普手册研制[J]. 护理学报, 2024, 31(9): 36–41. doi: 10.16460/j.issn1008-9969.2024.09.036.CHEN Jie, MENG Qingtong, LIU Jingjin, et al. Development of guideline-based exercise rehabilitation handbook for patients with chronic heart failure[J]. Journal of Nursing (China), 2024, 31(9): 36–41. doi: 10.16460/j.issn1008-9969.2024.09.036. [7] 曹广文. 我国癌症的流行特点、防控现状及未来应对策略[J]. 海军军医大学学报, 2025, 46(3): 279–290. doi: 10.16781/j.CN31-2187/R.20250050.CAO Guangwen. Cancer in China: Epidemiological characteristics, current prophylaxis and treatment, and future strategy[J]. Academic Journal of Naval Medical University, 2025, 46(3): 279–290. doi: 10.16781/j.CN31-2187/R.20250050. [8] 司国金, 吕章艳, 李文轩, 等. 天津市肿瘤筛查人群的癌症防治核心知识及健康素养调查分析[J]. 中华肿瘤防治杂志, 2025, 32(1): 1–9. doi: 10.16073/j.cnki.cjcpt.2025.01.01.SI Guojin, LV Zhangyan, LI Wenxuan, et al. Investigation and analysis of cancer prevention and treatment core knowledge awareness and health literacy among the tumor screening population in Tianjin[J]. Chinese Journal of Cancer Prevention and Treatment, 2025, 32(1): 1–9. doi: 10.16073/j.cnki.cjcpt.2025.01.01. [9] GIBSON D, JACKSON S, SHANMUGASUNDARAM R, et al. Evaluating the efficacy of ChatGPT as a patient education tool in prostate cancer: Multimetric assessment[J]. Journal of Medical Internet Research, 2024, 26: e55939. doi: 10.2196/55939. [10] CHEN D, PARSA R, SWANSON K, et al. Large language models in oncology: A review[J]. BMJ Oncology, 2025, 4(1): e000759. doi: 10.1136/bmjonc-2025-000759. [11] MOONS P and VAN BULCK L. ChatGPT: Can artificial intelligence language models be of value for cardiovascular nurses and allied health professionals[J]. European Journal of Cardiovascular Nursing, 2023, 22(7): e55–e59. doi: 10.1093/eurjcn/zvad022. [12] AMMO T, GUILLAUME V G J, HOFMANN U K, et al. Evaluating ChatGPT-4o as a decision support tool in multidisciplinary sarcoma tumor boards: Heterogeneous performance across various specialties[J]. Frontiers in Oncology, 2025, 14: 1526288. doi: 10.3389/fonc.2024.1526288. [13] RYDZEWSKI N R, DINAKARAN D, ZHAO S G, et al. Comparative evaluation of LLMs in clinical oncology[J]. NEJM AI, 2024, 1(5): AIoa2300151. doi: 10.1056/AIoa2300151. [14] XIE Yaojue, ZHAI Yuansheng, and LU Guihua. Evolution of artificial intelligence in healthcare: A 30-year bibliometric study[J]. Frontiers in Medicine, 2025, 11: 1505692. doi: 10.3389/fmed.2024.1505692. [15] BEDI S, LIU Yutong, ORR-EWING L, et al. Testing and evaluation of health care applications of large language models: A systematic review[J]. JAMA, 2025, 333(4): 319–328. doi: 10.1001/jama.2024.21700. [16] SORIN V, KLANG E, SKLAIR-LEVY M, et al. Large language model (ChatGPT) as a support tool for breast tumor board[J]. npj Breast Cancer, 2023, 9(1): 44. doi: 10.1038/s41523-023-00557-8. [17] CHAVEZ M R, BUTLER T S, REKAWEK P, et al. Chat generative pre-trained transformer: Why we should embrace this technology[J]. American Journal of Obstetrics and Gynecology, 2023, 228(6): 706–711. doi: 10.1016/j.ajog.2023.03.010. [18] 王晨琪, 肖洪玲, 吴亚轩, 等. 大语言模型在护理领域的应用及展望——以ChatGPT为代表[J]. 护士进修杂志, 2024, 39(12): 1296–1300. doi: 10.16821/j.cnki.hsjx.2024.12.012.WANG Chenqi, XIAO Hongling, WU Yaxuan, et al. Application and perspectives of large language model in the field of nursing: Represented by ChatGPT[J]. Journal of Nurses Training, 2024, 39(12): 1296–1300. doi: 10.16821/j.cnki.hsjx.2024.12.012. -

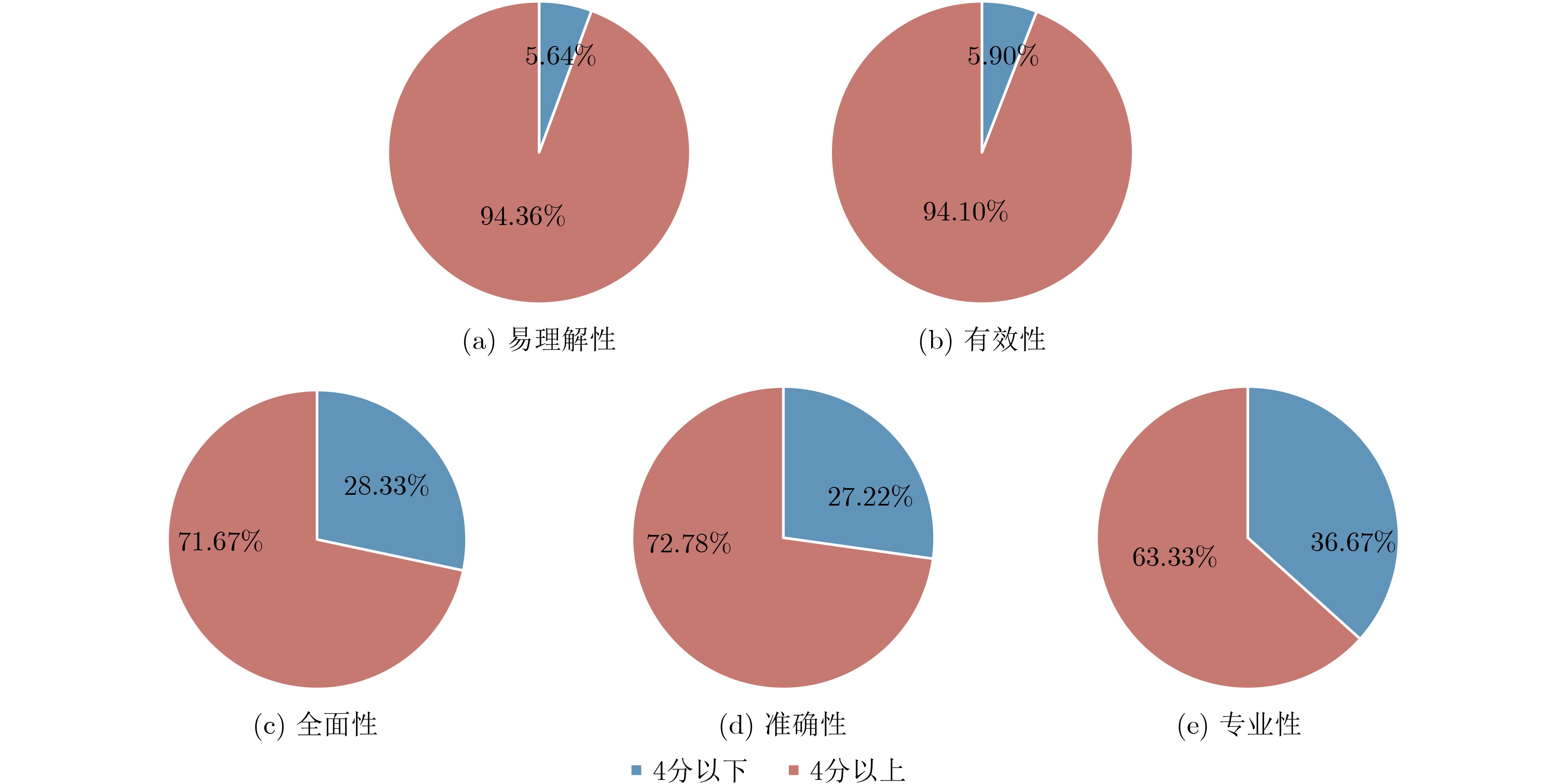
 下载:
下载:


图(5) / 表(2)
计量
- 文章访问数: 586
- HTML全文浏览量: 315
- PDF下载量: 44
- 被引次数: 0
