

A One-Shot Object Detection Method Fusing Dual-Branch Optimized SAM and Global-Local Collaborative Matching
-
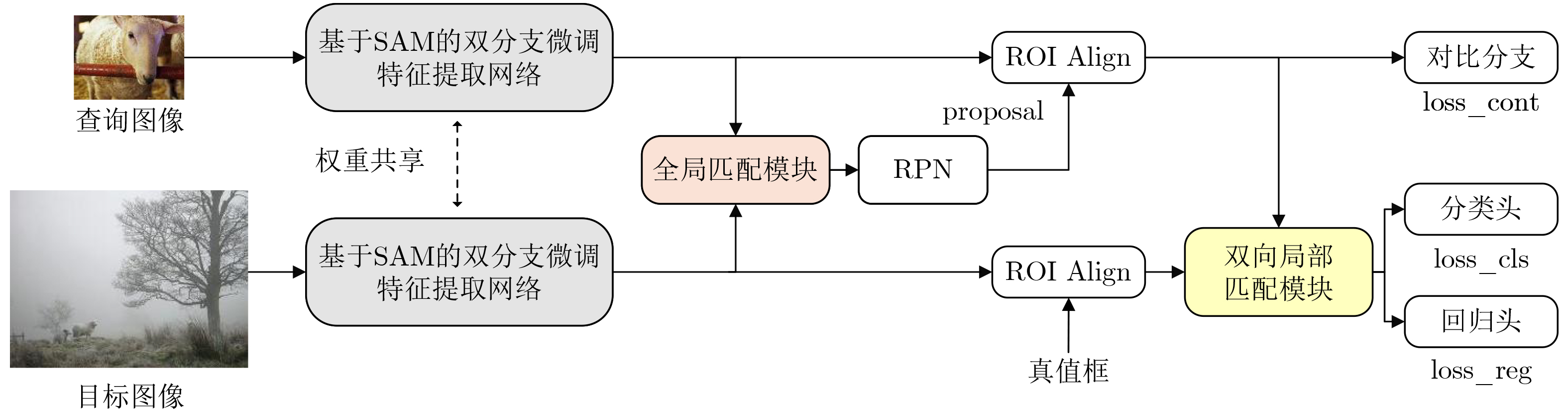
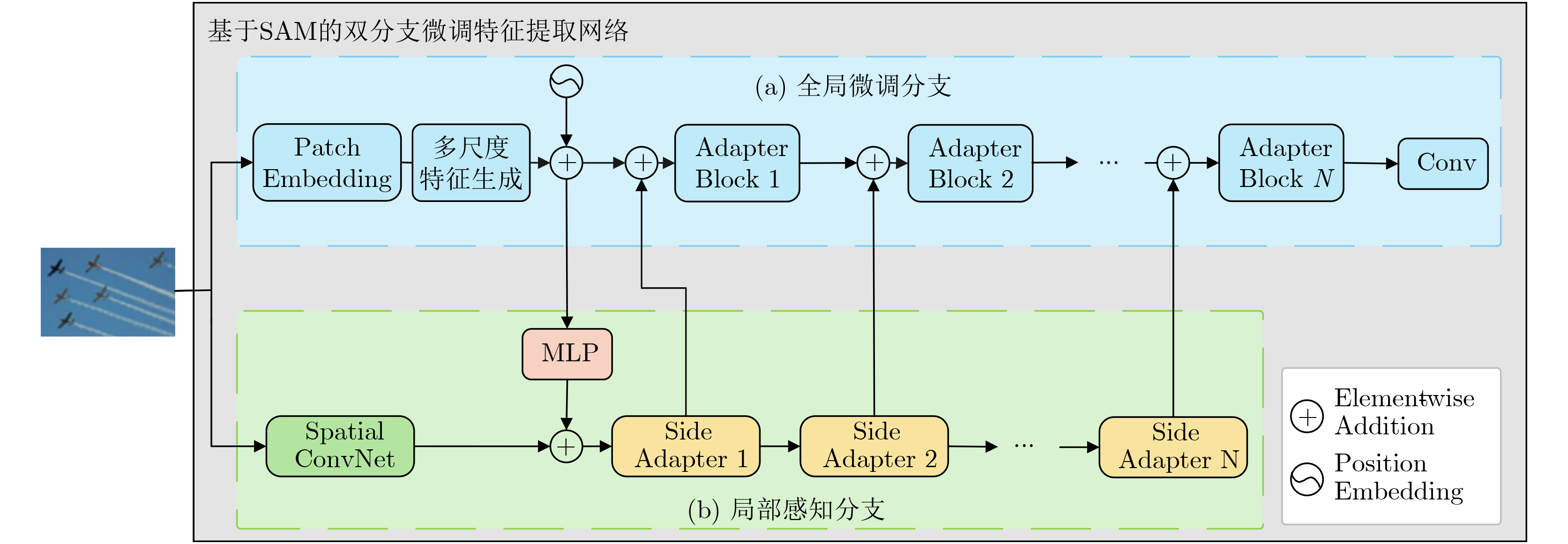
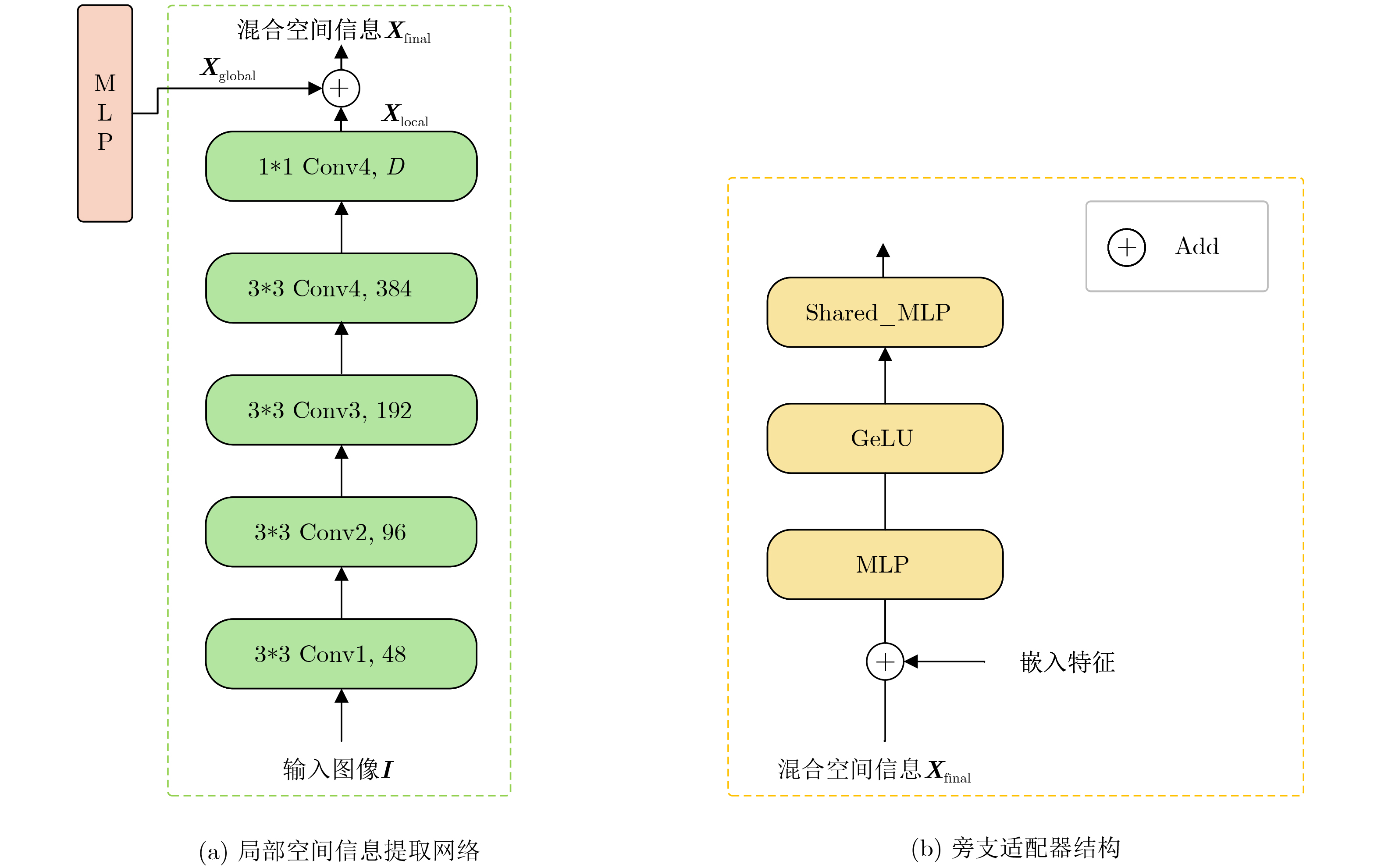
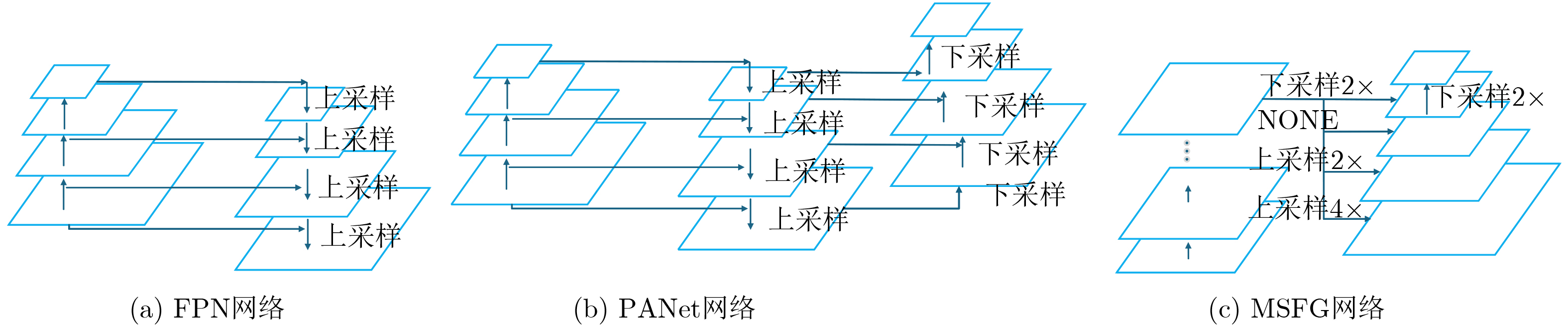
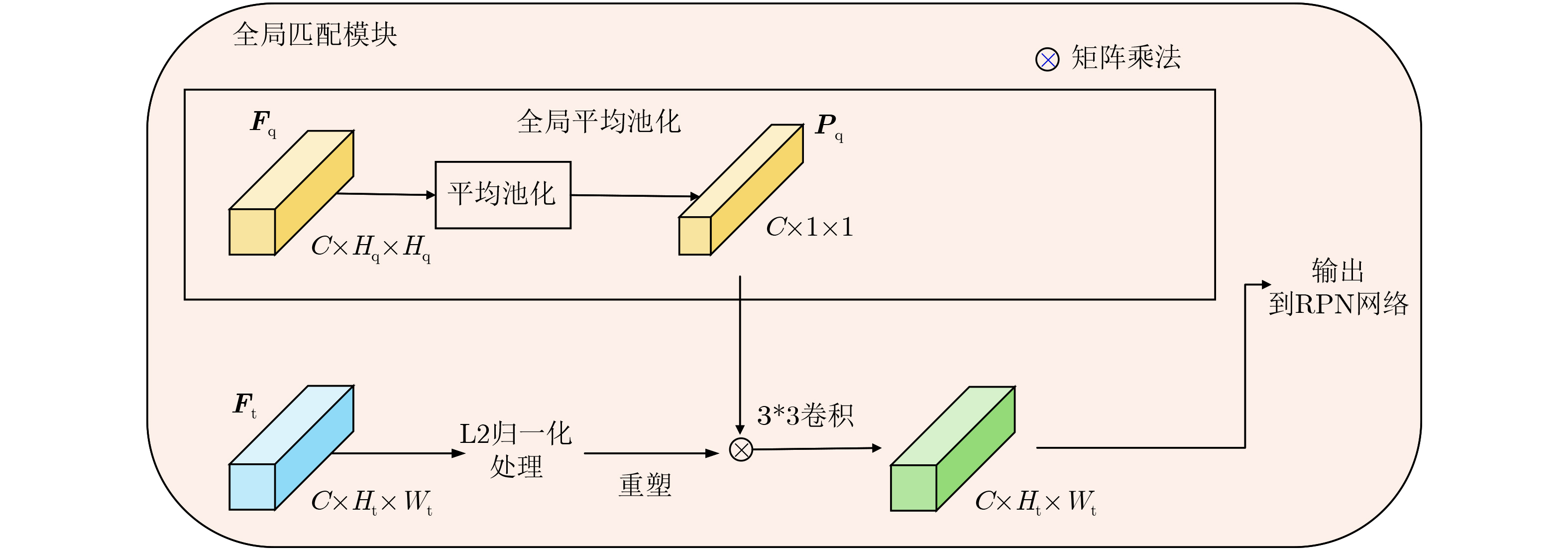
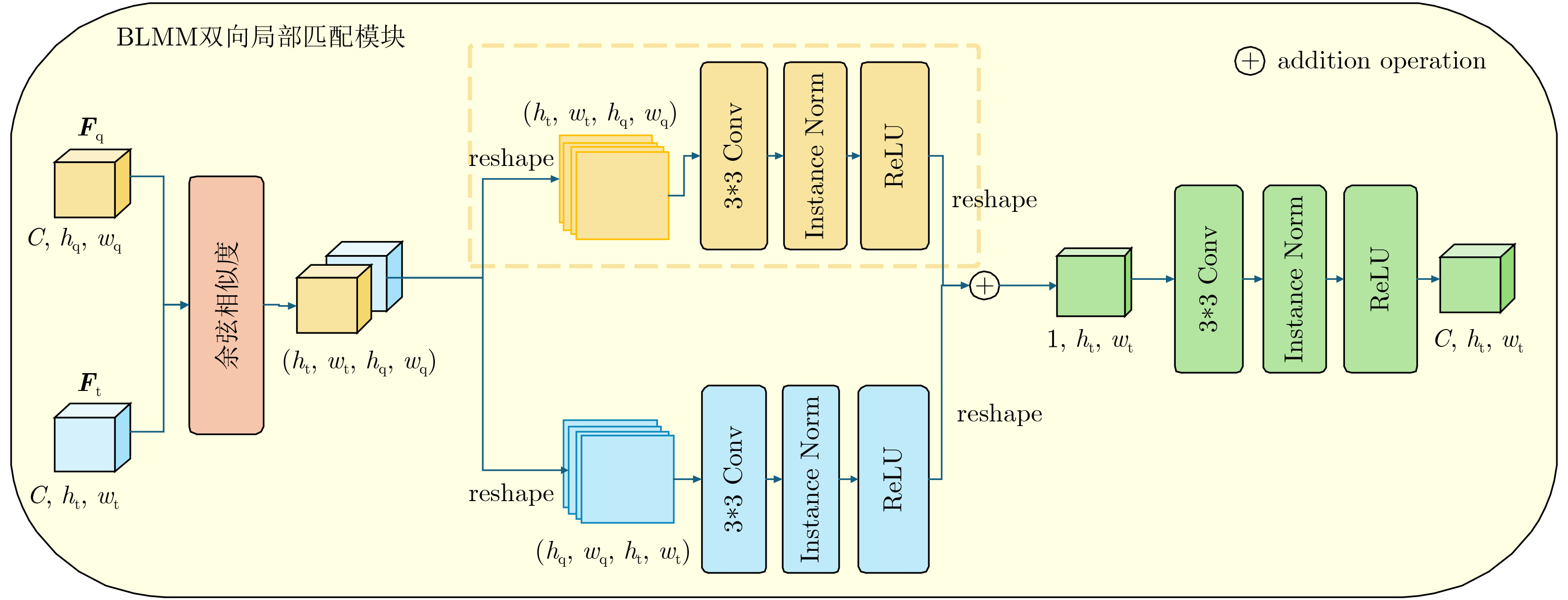
摘要: 单样本目标检测(OSOD)可有效缓解传统目标检测对大规模标注数据的依赖,但现有方法存在新类别特征表达不足、类间相似性高导致判别边界模糊等问题。为此,该文提出基于双分支优化SAM与全局-局部协同匹配的单样本目标检测算法DOS-GLNet。首先,设计基于SAM的双分支微调特征提取网络:全局微调分支通过在SAM的编码器中插入轻量级适配模块,在保留通用视觉表征能力的同时适配检测任务;局部感知分支通过卷积网络提取局部空间节并与全局特征跨层融合,弥补SAM局部信息缺失;结合多尺度特征生成模块,将SAM单尺度特征扩展为多尺度特征金字塔,适配不同尺寸目标检测需求。其次,构建全局-局部协同的两阶段匹配机制:全局匹配模块(GMM)通过余弦相似度度量查询与目标特征的全局相关性,引导区域提议网络生成高质量候选区域;双向局部匹配模块(BLMM)通过稠密4D相关性张量捕捉查询与目标的双向语义关系,实现细粒度特征对齐。在Pascal VOC与MS COCO数据集上的实验表明,DOS-GLNet相较于主流OSOD算法在检测精度上具有显著优势,消融实验验证了各创新模块对检测性能的有效增益,可降低深度学习目标检测网络对海量标注数据的依赖。Abstract:
Objective DOS-GLNet targets high-precision object recognition and localization through hierarchical collaboration of model components, using only a single query image with novel category prototypes and a target image. The method follows a two-layer architecture consisting of feature extraction and matching interaction. In the feature extraction layer, the Segment Anything Model (SAM) is adopted as the base extractor and is fine-tuned using a dual-branch strategy. This strategy preserves SAM’s general visual and category-agnostic perception while enhancing local spatial detail representation. A multi-scale module is further incorporated to construct a feature pyramid and address the single-scale limitation of SAM. In the matching interaction layer, a global-local collaborative two-stage matching mechanism is designed. The Global Matching Module (GMM) performs coarse-grained semantic alignment by suppressing background responses and guiding the Region Proposal Network (RPN) to generate high-quality candidate regions. The Bidirectional Local Matching Module (BLMM) then establishes fine-grained spatial correspondence between candidate regions and the query image to capture part-level associations. Methods A detection network based on Dual-Branch Optimized SAM and Global-Local Collaborative Matching, termed DOS-GLNet, is proposed. The main contributions are as follows. (1) In the feature matching stage, a two-stage global-local matching mechanism is constructed. A GMM is embedded before the RPN to achieve robust matching of overall target features using a large receptive field. (2) A BLMM is embedded before the detection head to capture pixel-level, bidirectional fine-grained semantic correlation through a four-dimensional correlation tensor. This progressive matching strategy establishes cross-sample correlations in the feature space, optimizes feature representation, and improves object localization accuracy. Results and Discussions On the Pascal VOC dataset, the proposed method is compared with SiamRPN, which was originally developed for one-shot tracking and is adapted for detection due to task similarity, as well as OSCD, CoAE, AIT, BHRL, and BSPG. The results show that the proposed method outperforms all baseline approaches and achieves stronger overall one-shot detection performance. On the MS COCO dataset, comparative methods include SiamMask, CoAE, AIT, BHRL, and BSPG. Although base and novel class performance varies across different data splits, consistent trends are observed. DOS-GLNet matches state-of-the-art performance on base classes while maintaining strong accuracy on fully trained categories. It further achieves state-of-the-art results on novel classes, with an average improvement of approximately 2%. These results indicate more effective feature alignment and relationship modeling based on one-shot samples, as well as improved representation of novel class features under limited prior information. Conclusions Conclusions To improve feature optimization in one-shot object detection, enhancements are introduced at both the backbone network and the matching mechanism levels. A DOS-GLNet framework based on dual-branch optimized SAM and global-local collaborative matching is proposed. For the backbone, an SAM-based dual-branch fine-tuning feature extraction network is constructed. Lightweight adapters are integrated into the SAM encoder to enable parameter-efficient fine-tuning, preserving generalization capability while improving task adaptability. In parallel, a convolutional local branch is designed to strengthen local feature perception, and cross-layer fusion is applied to enhance local detail representation. A multi-scale module further increases the scale diversity of the feature pyramid. For feature matching, a two-stage global-local collaborative strategy is adopted. Global matching focuses on target-level semantic alignment, whereas local matching refines instance-level detail discrimination. Together, these designs effectively improve one-shot object detection performance. -
表 2 不同算法在Pascal VOC数据集上的检测结果(%)
算法 基类 plant sofa tv car bottle boat chair person bus train horse bike SiamRPN[35] 1.90 15.70 4.50 12.80 1.00 1.10 6.10 8.70 7.90 6.90 17.40 17.80 OSCD[26] 28.40 41.50 65.00 66.40 37.10 49.80 16.20 31.70 69.70 73.10 75.60 71.60 CoAE[30] 30.00 54.90 64.10 66.70 40.10 54.10 14.70 60.900 77.50 78.30 77.90 73.20 AIT[36] 46.40 60.50 68.00 73.60 49.00 65.10 26.60 68.20 82.60 85.40 82.90 77.10 BHRL[37] 57.50 49.40 76.80 80.40 61.20 58.40 48.10 83.30 74.30 87.30 80.10 81.00 BSPG[15] 55.00 55.60 78.30 81.40 62.50 59.50 50.90 81.70 72.70 87.50 82.10 81.00 DOS-GLNet(本文方法) 58.20 48.60 73.10 84.80 62.90 62.80 46.30 86.60 74.30 87.10 84.60 79.70  下载: 导出CSV
下载: 导出CSV
续表2 不同算法在Pascal VOC数据集上的检测结果(%) 算法 基类 新类 平均AP50 bird motobike table 平均AP50 cow sheep cat Aeroplane 平均AP50 SiamRPN[35] 7.20 18.50 5.10 9.60 15.90 15.70 21.70 3.50 14.20 11.90 OSCD[26] 52.30 63.40 39.80 52.70 75.30 60.00 47.90 25.30 52.10 52.40 CoAE[30] 70.80 70.80 46.20 60.10 83.90 67.10 75.60 46.20 68.20 64.20 AIT[36] 71.80 75.10 60.00 67.20 85.50 72.80 80.40 50.20 72.20 69.70 BHRL[37] 730 78.80 38.80 69.70 81.00 67.90 85.40 59.30 72.60 71.20 BSPG[15] 73.90 79.10 39.50 70.50 80.60 67.40 84.60 61.40 73.50 72.00 DOS-GLNet(本文方法) 68.30 78.90 32.90 69.60 84.20 72.00 85.50 70.10 77.90 73.80
下载: 导出CSV
表 4 不同算法在MS COCO数据集上的检测结果(%)
算法名称 基类 新类 平均AP50 Split1 Split2 Split3 Split4 平均AP50 Split1 Split2 Split3 Split4 平均AP50 SiamMask[39] 38.90 37.10 37.80 36.60 37.60 15.30 17.60 17.40 17.00 16.80 27.20 CoAE[30] 42.20 40.20 39.90 41.30 40.90 23.40 23.60 20.50 20.40 22.00 31.20 AIT[36] 50.10 47.20 45.80 46.90 47.50 26.00 26.40 22.30 22.60 24.30 35.90 BHRL[37] 56.00 52.10 52.60 53.40 53.50 26.10 29.00 22.70 24.50 25.60 39.60 BSPG[15] 57.10 54.10 54.00 54.60 55.0 27.70 30.70 24.60 26.30 27.30 41.20 DOS-GLNet (本文方法) 57.00 54.60 55.10 54.90 55.4 30.30 32.90 26.10 27.80 29.30 42.40
下载: 导出CSV
表 6 不同主干网络和多尺度网络的实验结果(%)
实验组 主干网络 多尺度网络 基类AP50 新类AP50 - ResNet FPN 68.80 75.30 本文框架 SAM-ViT-B MSFG 69.60 77.90 本文框架 SAM-ViT-L MSFG 70.20 78.50 本文框架 SAM-ViT-H MSFG 70.80 79.10
下载: 导出CSV
表 7 全局-局部匹配模块消融实验结果(%)
RPN网络 检测头 基类AP50 新类AP50 SiamMask[39] BLMM 69.10 74.30 GMM (本文方法) Reweighting 67.40 73.20 GMM (本文方法) Depthwise Cross Correlation 68.70 76.80 GMM (本文方法) Non-local Attention 68.10 75.50 GMM (本文方法) BLMM 69.60 77.90
下载: 导出CSV
表 8 不同编码器在Pascal VOC和MS COCO数据集上的检测精度
编码器 Pascal VOC MS COCO fps 耗时(ms) ViT-B 69.60 55.40 28 35.70 ViT-L 70.20 56.10 18 55.60 ViT-H 70.80 56.80 10 100.00
下载: 导出CSV
-
[1] LIU Quanyong, PENG Jiangtao, ZHANG Genwei, et al. Deep contrastive learning network for small-sample hyperspectral image classification[J]. Journal of Remote Sensing, 2023, 3: 0025. doi: 10.34133/remotesensing.0025. [2] 邵延华, 张铎, 楚红雨, 等. 基于深度学习的YOLO目标检测综述[J]. 电子与信息学报, 2022, 44(10): 3697–3708. doi: 10.11999/JEIT210790.SHAO Yanhua, ZHANG Duo, CHU Hongyu, et al. A review of YOLO object detection based on deep learning[J]. Journal of Electronics & Information Technology, 2022, 44(10): 3697–3708. doi: 10.11999/JEIT210790. [3] MEI Shaohui, LIAN Jiawei, WANG Xiaofei, et al. A comprehensive study on the robustness of deep learning-based image classification and object detection in remote sensing: Surveying and benchmarking[J]. Journal of Remote Sensing, 2024, 4: 0219. doi: 10.34133/remotesensing.0219. [4] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 580–587. doi: 10.1109/CVPR.2014.81. [5] REDMON J and FARHADI A. YOLO9000: Better, faster, stronger[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 7263–7271. doi: 10.1109/CVPR.2017.690. [6] LAW H and DENG Jia. CornerNet: Detecting objects as paired keypoints[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 734–750. doi: 10.1007/978-3-030-01264-9_45. [7] CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 213–229. doi: 10.1007/978-3-030-58452-8_13. [8] HAN Guangxing and LIM S N. Few-shot object detection with foundation models[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 28608–28618. doi: 10.1109/cvpr52733.2024.02703. [9] NASEER A, ALZAHRANI H A, ALMUJALLY N A, et al. Efficient multi-object recognition using GMM segmentation feature fusion approach[J]. IEEE Access, 2024, 12: 37165–37178. doi: 10.1109/ACCESS.2024.3372190. [10] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]. 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248–255. doi: 10.1109/CVPR.2009.5206848. [11] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [12] KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 4015–4026. doi: 10.1109/ICCV51070.2023.00371. [13] LIU Shu, QI Lu, QIN Haifang, et al. Path aggregation network for instance segmentation[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8759–8768. doi: 10.1109/CVPR.2018.00913. [14] MILIOTO A, MANDTLER L, and STACHNISS C. Fast instance and semantic segmentation exploiting local connectivity, metric learning, and one-shot detection for robotics[C]. 2019 International Conference on Robotics and Automation, Montreal, Canada, 2019: 20–24. doi: 10.1109/ICRA.2019.8793593. [15] ZHANG Wenwen, HU Yun, SHAN Hangguan, et al. Exploring base-class suppression with prior guidance for bias-free one-shot object detection[C]. The 38th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 7314–7322. doi: 10.1609/aaai.v38i7.28561. [16] DALAL N and TRIGGS B. Histograms of oriented gradients for human detection[C]. 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, USA, 2005: 886–893. doi: 10.1109/CVPR.2005.177. [17] HE Kaiming, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2961–2969. doi: 10.1109/ICCV.2017.322. [18] 刘佳琳. 基于改进YOLOv8的行人和车辆检测算法的研究[D]. [硕士论文], 大连交通大学, 2025. doi: 10.26990/d.cnki.gsltc.2025.000813.LIU Jialin. Research on improved YOLOv8-based pedestrian and vehicle detection algorithm[D]. [Master dissertation], Dalian Jiaotong University, 2025. doi: 10.26990/d.cnki.gsltc.2025.000813. [19] LIU Shilong, LI Feng, ZHANG Hao, et al. DAB-DETR: Dynamic anchor boxes are better queries for DETR[C]. The 10th International Conference on Learning Representations, 2022. [20] ZHAO Yian, LÜ Wenyu, XU Shangliang, et al. DETRs beat YOLOs on real-time object detection[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 16965–16974. doi: 10.1109/CVPR52733.2024.01605. [21] WANG Yaqing, YAO Quanming, KWOK J T, et al. Generalizing from a few examples: A survey on few-shot learning[J]. ACM Computing Surveys (CSUR), 2021, 53(3): 63. doi: 10.1145/3386252. [22] SUN Bo, LI Banghuai, CAI Shengcai, et al. FSCE: Few-shot object detection via contrastive proposal encoding[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 7352–7362. doi: 10.1109/CVPR46437.2021.00727. [23] HU Hanzhe, BAI Shuai, LI Aoxue, et al. Dense relation distillation with context-aware aggregation for few-shot object detection[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 10185–10194. doi: 10.1109/CVPR46437.2021.01005. [24] KANG Bingyi, LIU Zhuang, WANG Xin, et al. Few-shot object detection via feature reweighting[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 8420–8429. doi: 10.1109/ICCV.2019.00851. [25] HAN Guangxing, MA Jiawei, HUANG Shiyuan, et al. Few-shot object detection with fully cross-transformer[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 5321–5330. doi: 10.1109/CVPR52688.2022.00525. [26] FU Kun, ZHANG Tengfei, ZHANG Yue, et al. OSCD: A one-shot conditional object detection framework[J]. Neurocomputing, 2021, 425: 243–255. doi: 10.1016/j.neucom.2020.04.092. [27] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. The 9th International Conference on Learning Representations, 2021. [28] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2117–2125. doi: 10.1109/CVPR.2017.106. [29] LI Bo, WU Wei, WANG Qiang, et al. SiamRPN++: Evolution of siamese visual tracking with very deep networks[C]. Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 4282–4291. doi: 10.1109/CVPR.2019.00441. [30] HSIEH T I, LO Y C, CHEN H T, et al. One-shot object detection with co-attention and co-excitation[C]. The 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 245. [31] CHEN T I, LIU Y C, SU H T, et al. Dual-awareness attention for few-shot object detection[J]. IEEE Transactions on Multimedia, 2023, 25: 291–301. doi: 10.1109/TMM.2021.3125195. [32] MELEKHOV I, TIULPIN A, SATTLER T, et al. DGC-Net: Dense geometric correspondence network[C]. 2019 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2019: 1034–1042. doi: 10.1109/WACV.2019.00115. [33] EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The PASCAL visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303–338. doi: 10.1007/s11263-009-0275-4. [34] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]. The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 740–755. doi: 10.1007/978-3-319-10602-1_48. [35] LI Bo, YAN Junjie, WU Wei, et al. High performance visual tracking with Siamese region proposal network[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8971–8980. doi: 10.1109/CVPR.2018.00935. [36] CHEN Dingjie, HSIEH H Y, and LIU T L. Adaptive image transformer for one-shot object detection[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville: IEEE, 2021: 12247–12256. doi: 10.1109/CVPR46437.2021.01207. [37] YANG Hanqing, CAI Sijia, SHENG Hualian, et al. Balanced and hierarchical relation learning for one-shot object detection[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 7591–7600. doi: 10.1109/CVPR52688.2022.00744. [38] INKAWHICH M, INKAWHICH N, YANG Hao, et al. OSR-ViT: A simple and modular framework for open-set object detection and discovery[C]. 2024 IEEE International Conference on Big Data, Washington, USA, 2024: 928–937. doi: 10.1109/BigData62323.2024.10826036. [39] HU Weiming, WANG Qiang, ZHANG Li, et al. SiamMask: A framework for fast online object tracking and segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(3): 3072–3089. doi: 10.1109/TPAMI.2022.3172932. -

 下载:
下载:





图(9) / 表(9)
计量
- 文章访问数: 744
- HTML全文浏览量: 418
- PDF下载量: 100
- 被引次数: 0
