

NAS4CIM: Tailored Neural Network Architecture Search for RRAM-Based Compute-in-Memory Chips
-
摘要: 基于忆阻器(RRAM)的存算一体(CIM)芯片被认为是解决卫星任务在轨智能处理过程中功耗受限与效率瓶颈的一条重要出路,在提升深度神经网络推理效率方面展现出巨大潜力。然而面向星上处理任务的复杂性,RRAM-CIM架构需要探索匹配的神经网络结构来发挥其能效优势。在 RRAM-CIM 场景下,现有方法在任务性能搜索中多采用基于随机采样的一次性训练,容易导致训练过程不稳定;在硬件性能建模上则常依赖预测器或算子级建模,前者需要高昂的初始成本,后者则忽视了网络整体的硬件表现。为此,该文提出NAS4CIM搜索框架,并引入半解耦式蒸馏增强的梯度系数超网训练方法(DDE-GSCST),有效缓解候选算子间的干扰问题,提高搜索过程的稳定性和鲁棒性。同时,该文采用基于Top-K统计的算子选择策略,在保证任务精度的同时显著优化了硬件性能。在CIFAR-10与ImageNet数据集上的实验表明,该方法在相同硬件架构下较现有方法提升2.2%的最优精度,并降低33.3%的能耗-延迟积(EDP)。此外,基于真实RRAM宏单元的实片测试结果与仿真结果一致,进一步验证了方法的有效性。Abstract:
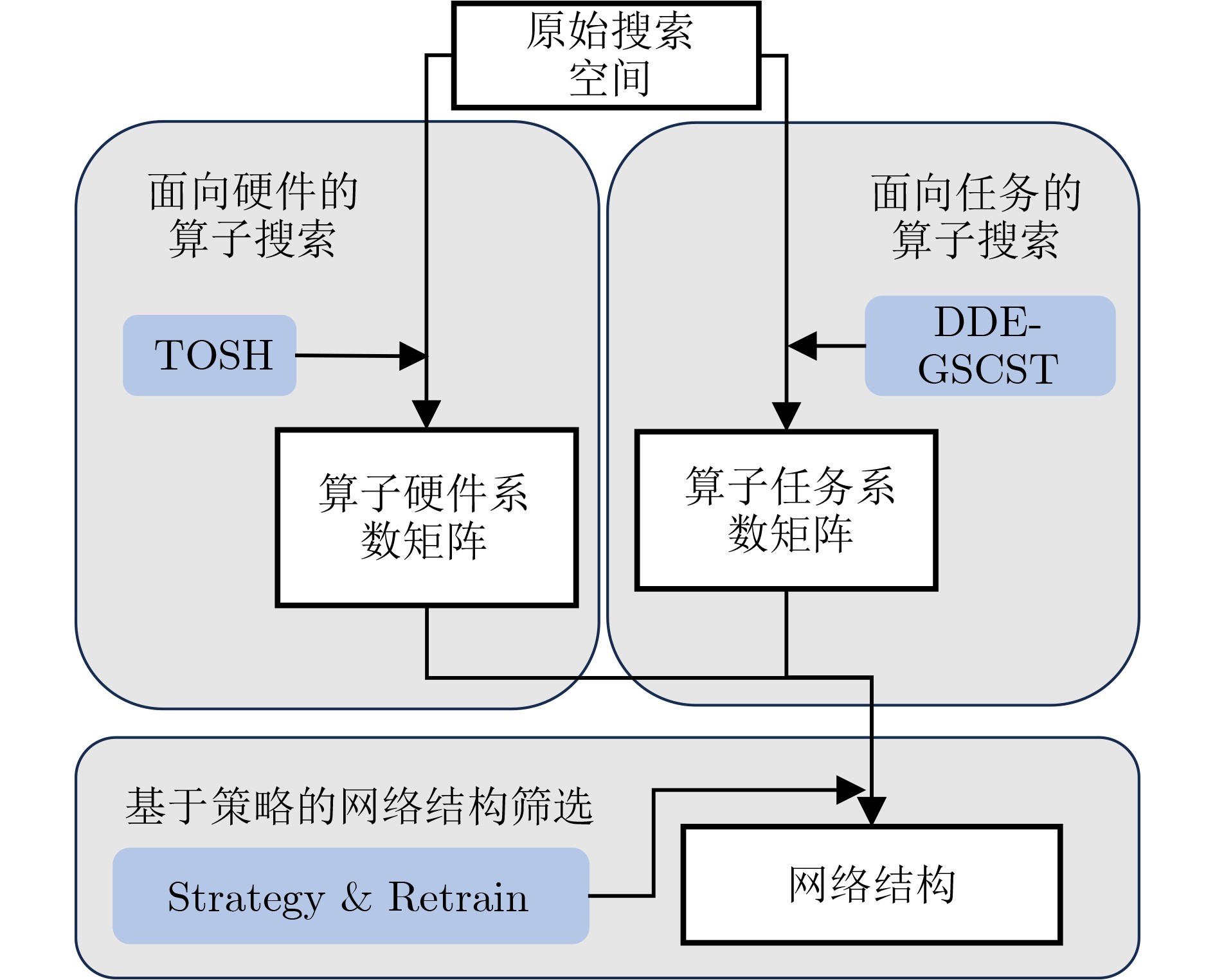
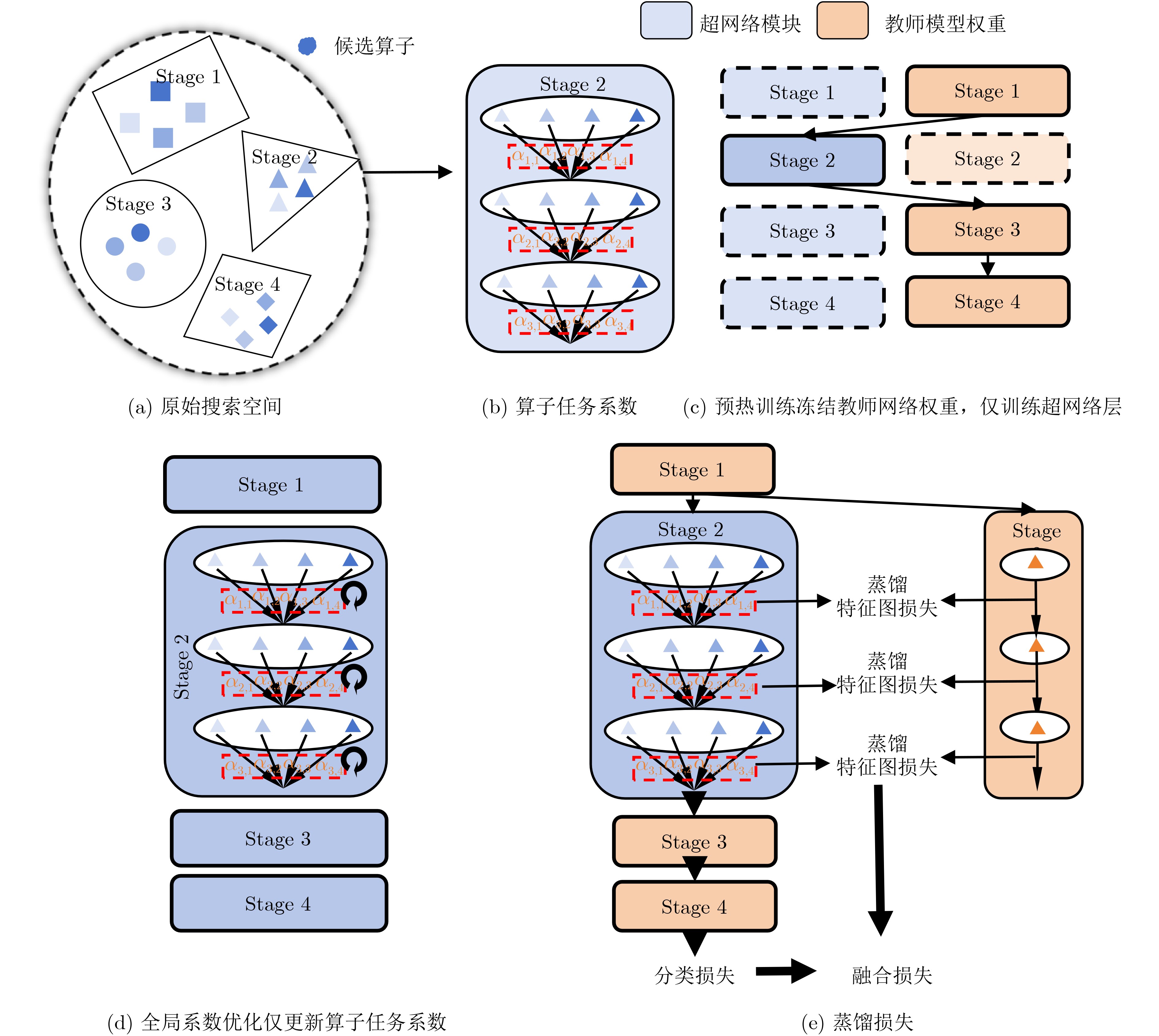
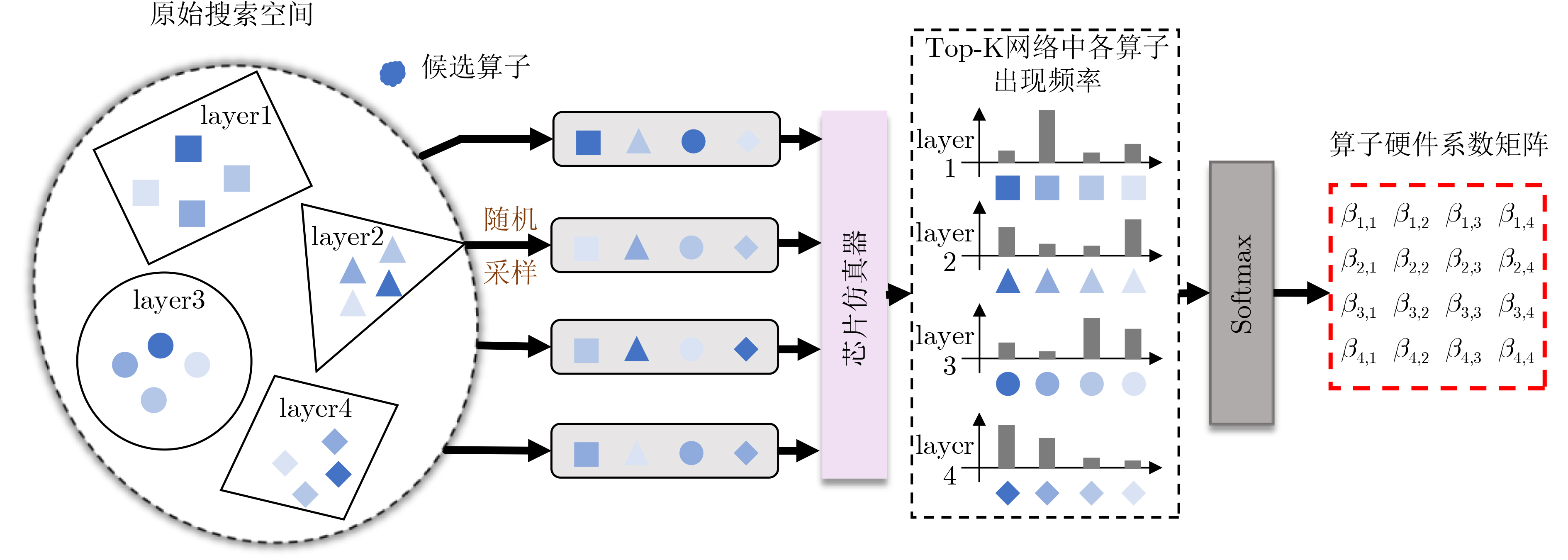
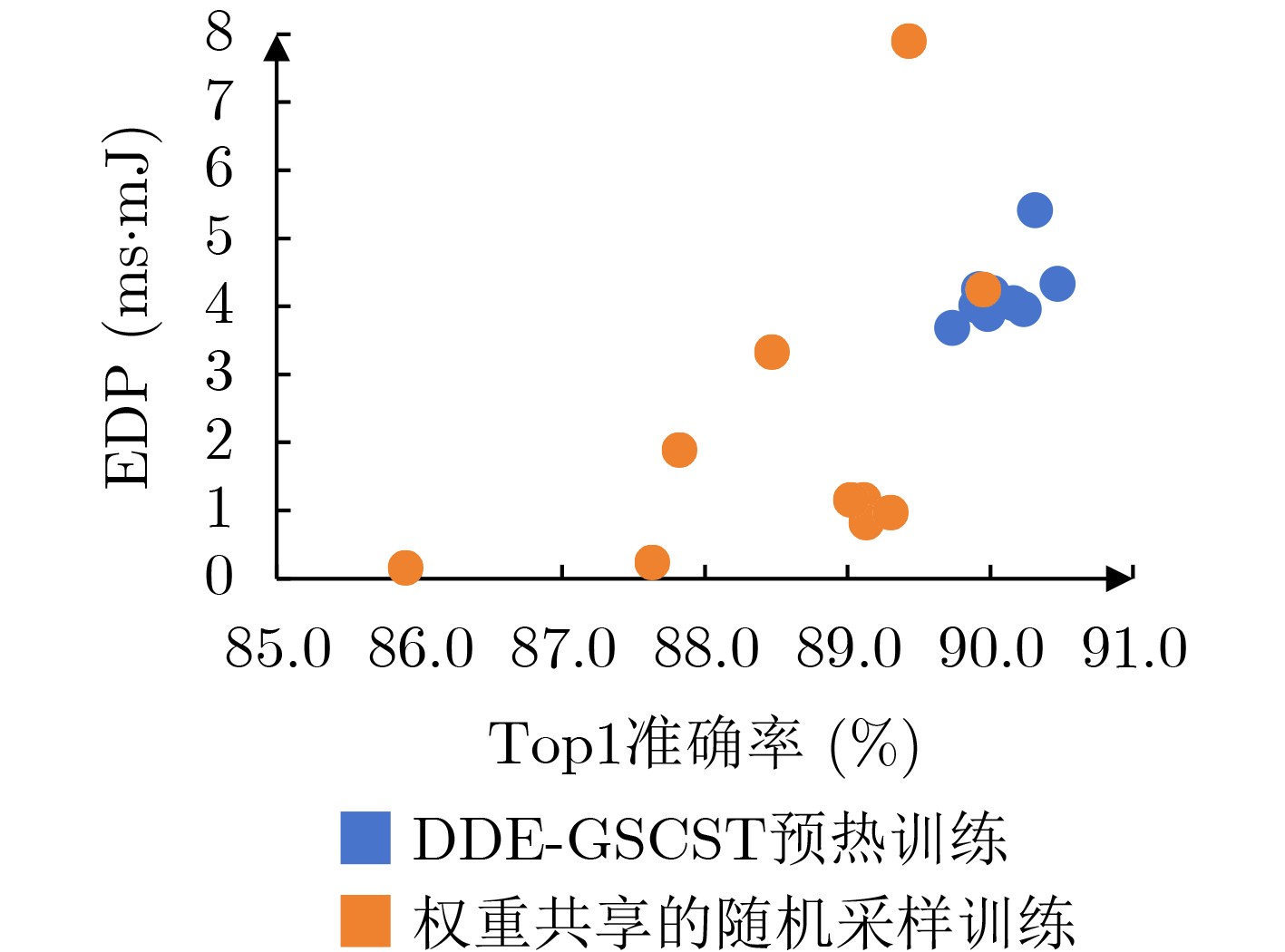
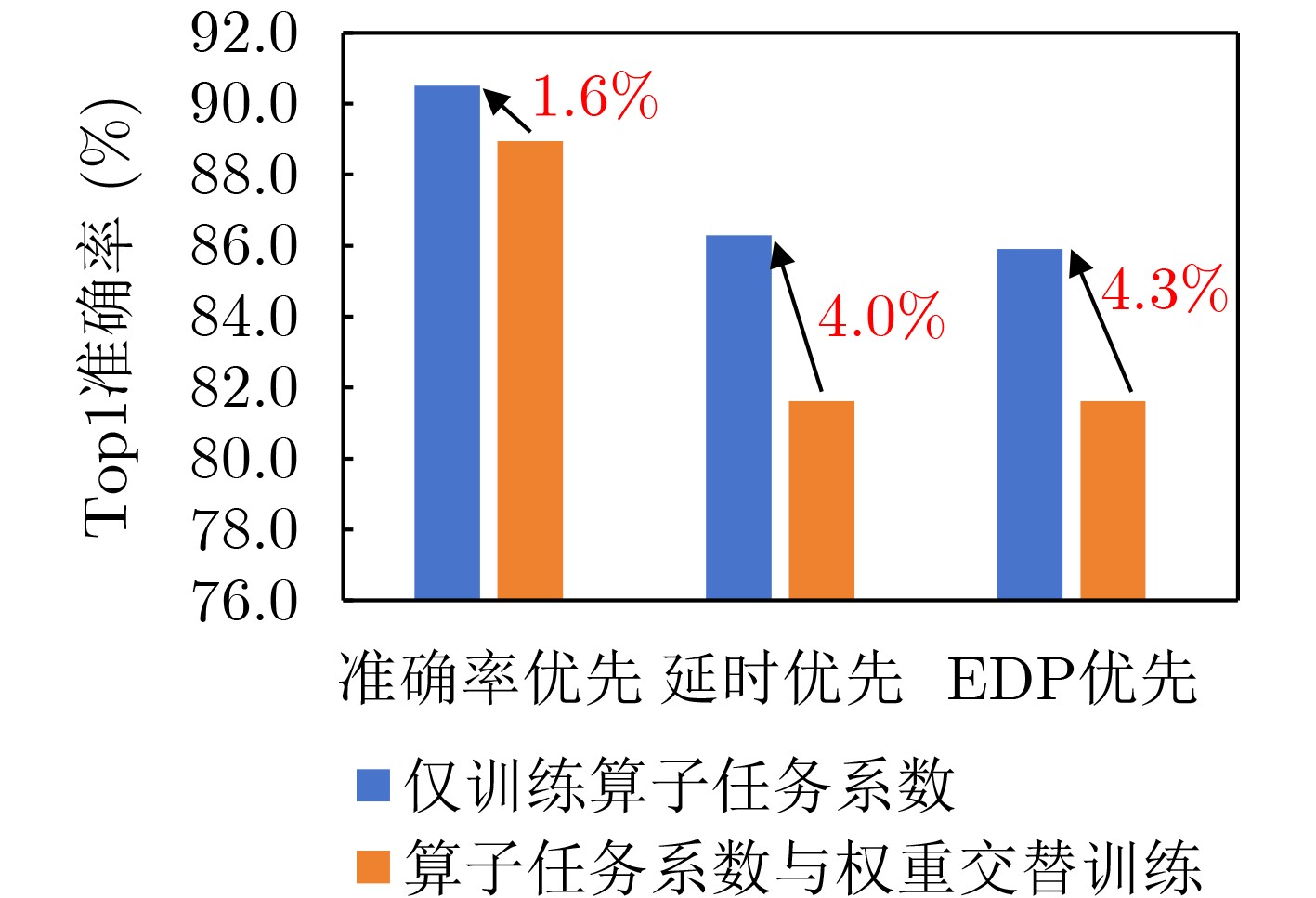
Objective With the growing demand for on-orbit information processing in satellite missions, efficient deployment of neural networks under strict power and latency constraints remains a major challenge. Resistive Random Access Memory (RRAM)-based Compute-in-Memory (CIM) architectures provide a promising solution for low power consumption and high throughput at the edge. To bridge the gap between conventional neural architectures and CIM hardware, this paper proposes NAS4CIM, a Neural Architecture Search (NAS) framework tailored for RRAM-based CIM chips. The framework proposes a decoupled distillation-enhanced training strategy and a Top-k-based operator selection method, enabling balanced optimization of task accuracy and hardware efficiency. This study presents a practical approach for algorithm-architecture co-optimization in CIM systems with potential application in satellite edge intelligence. Methods NAS4CIM is designed as a multi-stage architecture search framework that explicitly considers task performance and CIM hardware characteristics. The search process consists of three stages: task-driven operator evaluation, hardware-driven operator evaluation, and final architecture selection with retraining. In the task-driven stage, NAS4CIM employs the Decoupled Distillation-Enhanced Gradient-based Significance Coefficient Supernet Training (DDE-GSCST) method. Rather than jointly training all candidate operators in a fully coupled supernet, DDE-GSCST applies a semi-decoupled training strategy across different network stages. A high-accuracy teacher network is used to guide training. For each stage, the teacher network provides stable feature representations, whereas the remaining stages remain fixed, which reduces interference among candidate operators. Knowledge distillation is critical under CIM constraints. RRAM-based CIM systems typically rely on low-bit quantization and are affected by device-level noise, under which conventional weight-sharing NAS methods show unstable convergence. Feature distillation from a strong teacher network ensures clear optimization signals for candidate operators and supports reliable convergence. After training, each operator is assigned a task significance coefficient that quantitatively reflects its contribution to task accuracy. Following the task-driven stage, a hardware-driven search stage is performed. Candidate network structures are constructed by combining operators according to task significance rankings and are evaluated using an RRAM-based CIM hardware simulator. System-level hardware metrics, including inference latency and energy consumption, are measured. Complete network structures are evaluated directly, capturing realistic effects such as array partitioning, inter-array communication, and Analog-to-Digital Converter (ADC) overhead. From hardware-efficient networks with superior performance, the selection frequency of each operator is analyzed. Operators that appear more frequently in low-latency and low-energy designs are assigned higher hardware significance coefficients. This data-driven evaluation avoids inaccurate operator-level hardware modeling and reflects system-level behavior. In the final stage, task significance and hardware significance matrices are integrated. By adjusting weighting factors, the framework prioritizes accuracy, efficiency, or a balanced trade-off. Based on the combined evaluation, an optimal operator set is selected to construct the final network architecture, which is then retrained from scratch to refine weights and further improve accuracy while maintaining high hardware efficiency on CIM platforms. Results and Discussions NAS4CIM is evaluated on FashionMNIST, CIFAR-10, and ImageNet to demonstrate effectiveness across tasks of different scales. On FashionMNIST, the framework achieves 90.1% Top-1 accuracy in the accuracy-oriented search and an Energy-Delay Product (EDP) of 0.16 in the efficiency-oriented search ( Table 4 ). Real-chip experiments on fabricated RRAM macros show close agreement between measured accuracy and simulation results, confirming practical feasibility. On CIFAR-10, NAS4CIM reaches 90.5% Top-1 accuracy in the accuracy-oriented mode and an EDP of 0.16 in the efficiency-oriented mode, exceeding state-of-the-art methods under the same hardware configuration. Under a balanced accuracy-efficiency setting, the framework produces a network with 89.3% accuracy and an EDP of 0.97 (Table 3 ). On ImageNet, which represents a large-scale and more complex classification task, NAS4CIM achieves 70.0% Top-1 accuracy in the accuracy-oriented mode, whereas the efficiency-oriented search yields an EDP of 504.74 (Table 5 ). These results indicate effective scalability from simple to complex datasets while maintaining a favorable balance between accuracy and energy efficiency across optimization settings.Conclusions This study proposes NAS4CIM, a NAS framework for RRAM-based CIM chips. Through a decoupled distillation-enhanced training method and a Top-k-based operator selection strategy, the framework addresses instability in random sampling approaches and inaccuracies in operator-level performance modeling. NAS4CIM provides a unified strategy to balance task accuracy and hardware efficiency and demonstrates generality across tasks of different complexity. Simulation and real-chip experiments confirm stable performance and consistency between algorithmic and hardware evaluations. NAS4CIM presents a practical pathway for algorithm–hardware co-optimization in CIM systems and supports energy-efficient, real-time information processing for satellite edge intelligence. -
1 DDE-GSCST 预热训练阶段伪代码
输入: 训练数据集D 含有L个stage的教师网络T={T1, T2, ···, T3} 超网络模块集合S={S1, S2, ···, S3},每个Si含候选权重参数
θi和算子系数αi1. for i = 1, 2, ···, L do 2. 将教师网络第i个stage替换为超网络模Si 3. 冻结教师网络其余stage的参数 4. repeat直到收敛do 5. 从D取一个batch,得到教师中间特征图fT = T{1, 2, ···, i}(x) 6. 超网络模块输出特征图fs = (T{1, 2, ···, L}$\circ $Si)(x) 7. 学生网络输出$ y_\mathrm{s}=\left(T{_{{\left\{1,2,\cdots,{i}-1\right\}}}\circ}S_i\circ T_{\left\{i+1,\cdots,L\right\}}\right)\left(x\right) $ 8. 计算任务损失$ \mathrm{\mathit{L}_{task}}=\mathrm{CE}(y_{\mathrm{s}},y\mathrm{_{label}}) $ 9. 计算蒸馏损失$ \mathrm{\mathit{L}_{distll}}=\mathrm{MSE}(f_{\mathrm{s}},f_{\mathrm{T}}) $ 10. 总损失$ L=L_{\mathrm{task}}+\lambda\times L\mathrm{_{distll}} $ 11. 根据L计算梯度,固定算子系数αi,更新权重参数θi 12. 重新前向并计算L 13. 根据Ltask计算梯度,固定权重参数θi,更新算子系数αi 14. end repeat 15. 保存该stage的训练参数与算子系数 16. end for 输出: 预热后的超网络权重{θi}与算子系数{αi}  下载: 导出CSV
下载: 导出CSV
表 1 各任务网络搜索设置
指标 FashionMNIST搜索空间 CIFAR-10搜索空间 ImageNet搜索空间 卷积核大小 3, 5 1, 3 1, 3, 5 算子种类 空算子,标准卷积、残差卷积 空算子,标准卷积、标准残差块 空算子,标准残差块、瓶颈残差块 通道数 16, 32, 64 16, 32, 48, 64 16, 32, 48, 64, 80, 96 最大层数 3 9 8
下载: 导出CSV
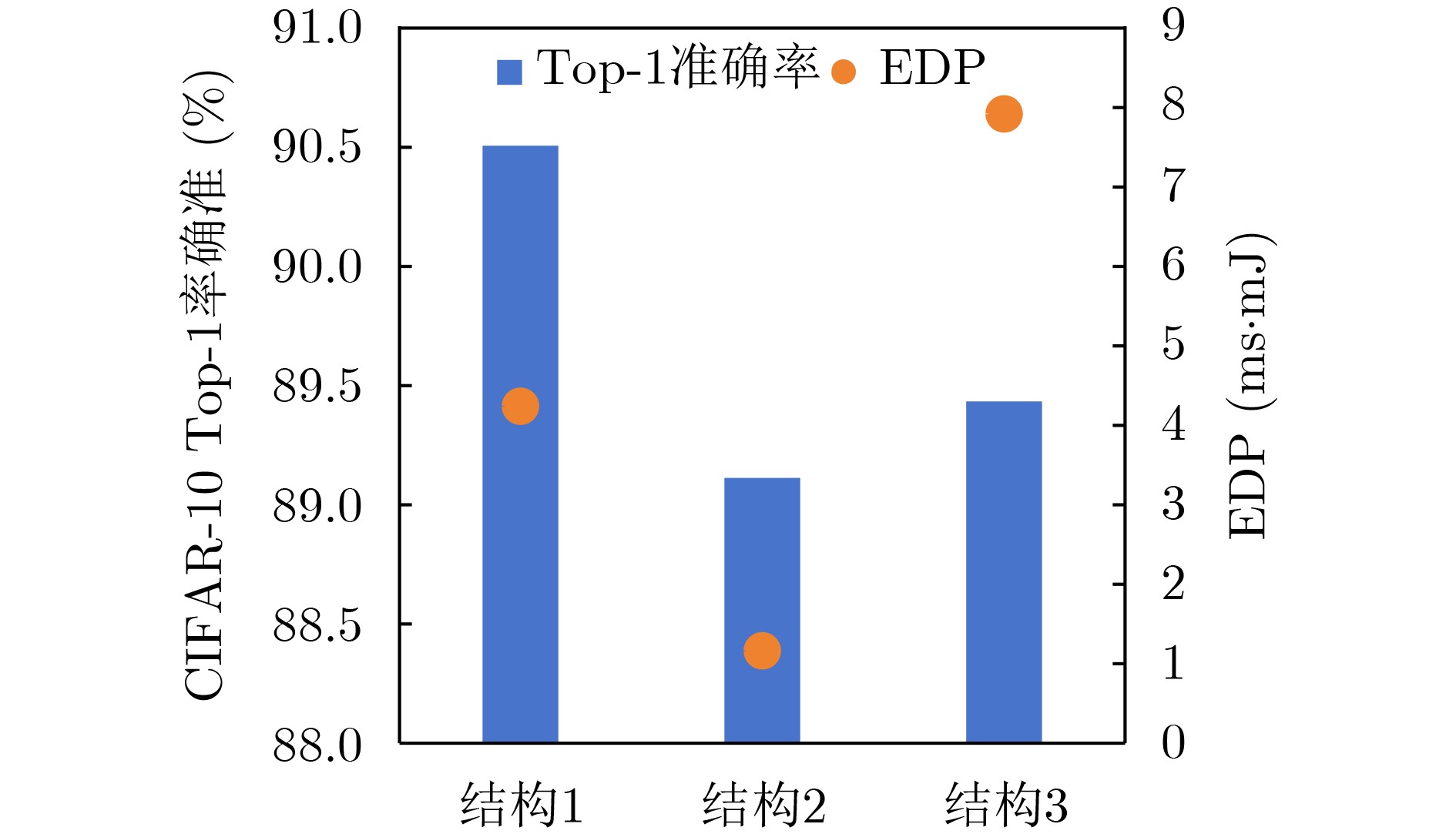
表 3 CIFAR-10数据集上的搜索结果对比
方法 准确率(%) EDP
(ms·mJ)参数量
(k)计算量
(MOPs)搜索
时长(h)NACIM 73.9 1.55 - - 59 UAE 83.0 - - - 154 NAS4RRAM 84.4 - - - 289 CARS(准确率优先) 88.0 11.03 - - 72 Gibbon(准确率优先) 88.3 14.33 - - 6 Gibbon(EDP优先) 84.6 0.24 - - 6 NAS4CIM(准确率优先) 90.5 4.23 268.35 81.10 6 NAS4CIM(EDP优先) 85.9 0.16 65.59 19.76 6 NAS4CIM(平衡) 89.3 0.97 135.23 49.12 6
下载: 导出CSV
表 4 FashionMNIST 数据集上的搜索结果与实片测试结果
方法 仿真准确率(%) 实片准确率(%) EDP(ms·mJ) 参数量(k) 计算量(MOPs) 教师网络 92.8 - - 270.90 81.63 NAS4CIM(准确率优先) 90.1 89.8 0.21 65.85 15.57 NAS4CIM(EDP优先) 88.7 88.3 0.16 65.08 13.99
下载: 导出CSV
表 5 ImageNet 数据集上的搜索结果
方法 准确率(%) EDP
(ms·mJ)参数量(M) 计算量
(GOPs)教师网络 71.6 - 11.50 3.59 NAS4CIM(准确率优先) 70.0 629.58 3.84 2.78 NAS4CIM(EDP优先) 66.6 504.74 3.64 1.94
下载: 导出CSV
-
[1] SANTORO G, TURVANI G, and GRAZIANO M. New logic-in-memory paradigms: An architectural and technological perspective[J]. Micromachines, 2019, 10(6): 368. doi: 10.3390/mi10060368. [2] 蔺海荣, 段晨星, 邓晓衡, 等. 双忆阻类脑混沌神经网络及其在IoMT数据隐私保护中应用[J]. 电子与信息学报, 2025, 47(7): 2194–2210. doi: 10.11999/JEIT241133.LIN Hairong, DUAN Chenxing, DENG Xiaoheng, et al. Dual-memristor brain-like chaotic neural network and its application in IoMT data privacy protection[J]. Journal of Electronics & Information Technology, 2025, 47(7): 2194–2210. doi: 10.11999/JEIT241133. [3] 江之行, 席悦, 唐建石, 等. 忆阻器及其存算一体应用研究进展[J]. 科技导报, 2024, 42(2): 31–49. doi: 10.3981/j.issn.1000-7857.2024.02.004.JIANG Zhixing, XI Yue, TANG Jianshi, et al. Review of recent research on memristors and computing-in-memory applications[J]. Science & Technology Review, 2024, 42(2): 31–49. doi: 10.3981/j.issn.1000-7857.2024.02.004. [4] 李冰, 午康俊, 王晶, 等. 基于忆阻器的图卷积神经网络加速器设计[J]. 电子与信息学报, 2023, 45(1): 106–115. doi: 10.11999/JEIT211435.LI Bing, WU Kangjun, WANG Jing, et al. Design of graph convolutional network accelerator based on resistive random access memory[J]. Journal of Electronics & Information Technology, 2023, 45(1): 106–115. doi: 10.11999/JEIT211435. [5] WAN W, KUBENDRAN R, SCHAEFER C, et al. A compute-in-memory chip based on resistive random-access memory[J]. Nature, 2022, 608(7923): 504–512. doi: 10.1038/s41586-022-04992-8. [6] 邝先验, 桓湘澜, 肖鸿彪, 等. 基于多端忆阻器的组合逻辑电路设计[J]. 电子元件与材料, 2024, 43(8): 1024–1030. doi: 10.14106/j.cnki.1001-2028.2024.1567.KUANG Xianyan, HUAN Xianglan, XIAO Hongbiao, et al. Design of combinational logic circuit using multi-terminal memristor[J]. Electronic Components and Materials, 2024, 43(8): 1024–1030. doi: 10.14106/j.cnki.1001-2028.2024.1567. [7] 陈长林, 骆畅航, 刘森, 等. 忆阻器类脑计算芯片研究现状综述[J]. 国防科技大学学报, 2023, 45(1): 1–14. doi: 10.11887/j.cn.202301001.CHEN Changlin, LUO Changhang, LIU Sen, et al. Review on the memristor based neuromorphic chips[J]. Journal of National University of Defense Technology, 2023, 45(1): 1–14. doi: 10.11887/j.cn.202301001. [8] PANDAY D K, SUMAN S, KHAN S, et al. Fabrication and characterization of alumina based resistive RAM for space applications[C]. The IEEE 24th International Conference on Nanotechnology (NANO), Gijon, Spain, 2024: 253–257. doi: 10.1109/NANO61778.2024.10628609. [9] YAO Peng, WU Huaqiang, GAO Bin, et al. Fully hardware-implemented memristor convolutional neural network[J]. Nature, 2020, 577(7792): 641–646. doi: 10.1038/s41586-020-1942-4. [10] CAI Han, ZHU Ligeng, and HAN Song. ProxylessNAS: Direct neural architecture search on target task and hardware[C]. The 7th International Conference on Learning Representations (ICLR), New Orleans, USA, 2019. [11] NEGI S, CHAKRABORTY I, ANKIT A, et al. NAX: Neural architecture and memristive xbar based accelerator co-design[C]. The 59th ACM/IEEE Design Automation Conference (DAC), San Francisco, USA, 2022: 451–456. doi: 10.1145/3489517.3530476. [12] JIANG Weiwen, LOU Qiuwen, YAN Zheyu, et al. Device-circuit-architecture co-exploration for computing-in-memory neural accelerators[J]. IEEE Transactions on Computers, 2021, 70(4): 595–605. doi: 10.1109/TC.2020.2991575. [13] YUAN Zhihang, LIU Jingze, LI Xingchen, et al. NAS4RRAM: Neural network architecture search for inference on RRAM-based accelerators[J]. Science China Information Sciences, 2021, 64(6): 160407. doi: 10.1007/s11432-020-3245-7. [14] SUN Hanbo, ZHU Zhenhua, WANG Chenyu, et al. Gibbon: An efficient co-exploration framework of NN model and processing-in-memory architecture[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2023, 42(11): 4075–4089. doi: 10.1109/TCAD.2023.3262201. [15] KRIZHEVSKY A. Learning multiple layers of features from tiny images[EB/OL]. https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf, 2009. [16] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]. The 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248–255. doi: 10.1109/CVPR.2009.5206848. [17] XIAO Han, RASUL K, and VOLLGRAF R. Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms[EB/OL]. arXiv preprint arXiv: 1708.07747, 2017. doi: 10.48550/arXiv.1708.07747. [18] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [19] LIU Hanxiao, SIMONYAN K, and YANG Yiming. DARTS: Differentiable architecture search[C]. The 7th International Conference on Learning Representations, New Orleans, USA, 2019. [20] ESSER S K, MCKINSTRY J L, BABLANI D, et al. Learned step size quantization[C]. The 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 2020. [21] ZHANG Yibei, ZHANG Qingtian, QIN Qi, et al. An RRAM retention prediction framework using a convolutional neural network based on relaxation behavior[J]. Neuromorphic Computing and Engineering, 2023, 3(1): 014011. doi: 10.1088/2634-4386/acb965. [22] ZHU Zhenhua, SUN Hanbo, XIE Tongxin, et al. MNSIM 2.0: A behavior-level modeling tool for processing-in-memory architectures[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2023, 42(11): 4112–4125. doi: 10.1109/TCAD.2023.3251696. [23] SHI Yuanming, ZHU Jingyang, JIANG Chunxiao, et al. Satellite edge artificial intelligence with large models: Architectures and technologies[J]. Science China Information Sciences, 2025, 68(7): 170302. doi: 10.1007/s11432-024-4425-y. -

 下载:
下载:


图(6) / 表(6)
计量
- 文章访问数: 756
- HTML全文浏览量: 449
- PDF下载量: 56
- 被引次数: 0
