

CaRS-Align: Channel Relation Spectra Alignment for Cross-Modal Vehicle Re-identification
-
摘要: 可见光与红外光作为智能交通场景中常用的两种图像模态,在长时间、广范围的车辆再辨识中具有重要应用价值。但是,由于成像机制与光谱响应的差异,两种模态的视觉表现特性并不一致,干扰身份表征学习,制约跨模态车辆再辨识。为此,该文提出通道关系谱对齐(CaRS-Align)方法,以通道关系谱而非通道特征作为对齐目标,从关系结构层面削弱成像风格差异的干扰。具体地,首先在模态内构建通道关系谱,通过稳定的相关建模获取语义协同的通道—通道关系谱;随后,在跨模态层面最大化两模态对应通道关系谱的相关性,实现通道关系谱一致性对齐。CaRS-Align 对齐的是关系结构而非强度幅值,对光照、对比度与成像条件变化更不敏感,有效提升跨模态再辨识性能。实验表明,在公开的MSVR310和RGBN300数据集上,所提CaRS-Align方法优于现有先进方法,例如,在MSVR310数据集上,红外光-可见光检索模式下,CaRS-Align的Rank-1识别率达到64.35%,较之现有先进方法提升了2.58%。Abstract:
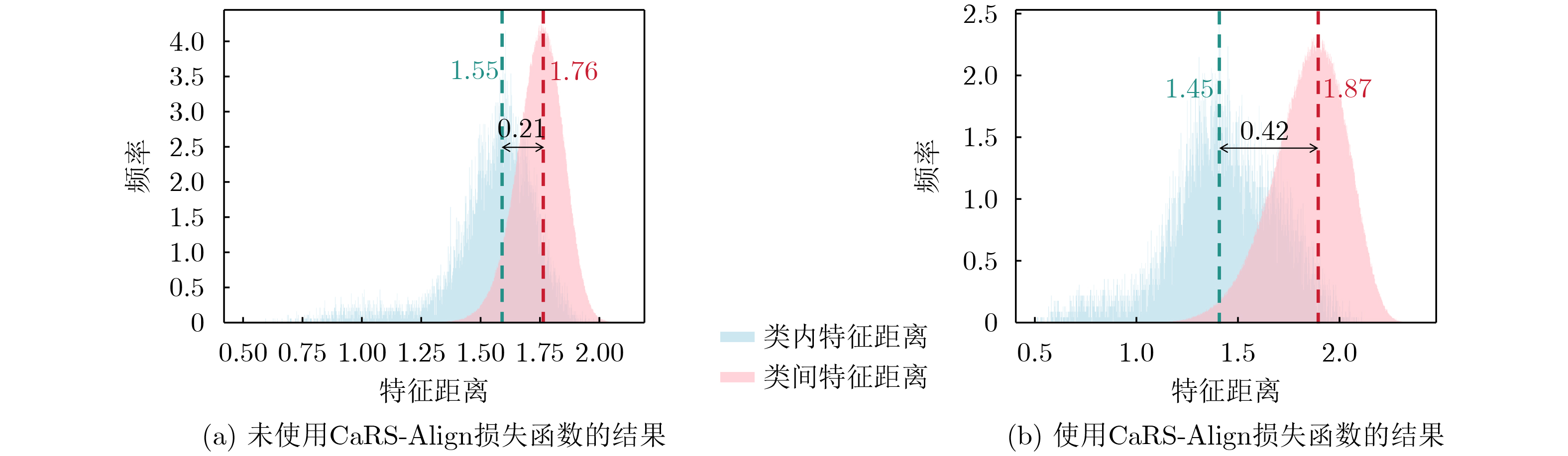
Objective Visible and infrared images are two commonly used modalities in intelligent transportation scenarios and play a key role in vehicle re-identification. However, differences in imaging mechanisms and spectral responses lead to inconsistent visual characteristics between these modalities, which limits cross-modal vehicle re-identification. To address this problem, this paper proposes a Channel Relation Spectra Alignment (CaRS-Align) method that uses channel relation spectra, rather than channel-wise features, as the alignment target. This strategy reduces interference caused by imaging style differences at the relational-structure level. Within each modality, a channel relation spectrum is constructed to capture stable and semantically coordinated channel-to-channel relationships through correlation modeling. At the cross-modal level, the correlation between the corresponding channel relation spectra of the two modalities is maximized to achieve consistent alignment of relational structures. Experiments on the public MSVR310 and RGBN300 datasets show that CaRS-Align outperforms existing state-of-the-art methods. For example, on MSVR310, under infrared-to-visible retrieval, CaRS-Align achieves a Rank-1 accuracy of 64.35%, which is 2.58% higher than advanced existing methods. Methods CaRS-Align adopts a hierarchical optimization paradigm: (1) for each modality, a channel-channel relation spectrum is constructed by mining inter-channel dependencies, yielding a semantically coordinated relation matrix that preserves the organizational structure of semantic cues; (2) cross-modal consistency is achieved by maximizing the correlation between the relation spectra of the two modalities, enabling progressive optimization from intra-modal construction to cross-modal alignment; and (3) relation spectrum alignment is integrated with standard classification and retrieval objectives commonly used in re-identification to supervise backbone training for the vehicle re-identification model. Results and Discussions Compared with several state-of-the-art cross-modal re-identification methods on the RGBN300 and MSVR310 datasets, CaRS-Align demonstrates strong performance and achieves best or second-best results across both retrieval modes. As shown in ( Table 1 ), on RGBN300 it attains 75.09% Rank-1 accuracy and 55.45% mean Average Precision (mAP) in the infrared-to-visible mode, and 76.60% Rank-1 accuracy and 56.12% mAP in the visible-to-infrared mode. As shown in (Table 2 ), similar advantages are observed on MSVR310, with 64.54% Rank-1 accuracy and 41.25% mAP in the visible-to-infrared mode, and 64.35% Rank-1 accuracy and 40.99% mAP in the infrared-to-visible mode. (Fig. 4 ) presents Top-10 retrieval results, where CaRS-Align reduces identity mismatches in both directions (Fig. 5 ) illustrates feature distance distributions, showing substantial overlap between intra-class and inter-class distances without CaRS-Align (Fig. 5(a) ), whereas clearer separation is observed with CaRS-Align (Fig. 5(b) ), confirming improved feature discrimination. These results indicate that modeling channel-level relational structures improves both retrieval modes, increases adaptability to modality shifts, and effectively reduces mismatches caused by cross-modal differences.Conclusions This paper proposes a visible-infrared cross-modal vehicle re-identification method based on CaRS-Align. Within each modality, a channel relation spectrum is constructed to preserve semantic co-occurrence structures. A CaRS-Align function is then designed to maximize the correlation between modalities, thereby achieving consistent alignment and improving cross-modal performance. Experiments on the MSVR310 and RGBN300 datasets demonstrate that CaRS-Align outperforms existing state-of-the-art methods in key metrics, including Rank-1 accuracy and mAP. -
[1] LIU Feng, HUANG Kaiwen, and LI Qin. Knowledge-driven multi-branch interaction network for vehicle re-identification[J]. IEEE Transactions on Intelligent Transportation Systems, 2025, 26(10): 17000–17012. doi: 10.1109/TITS.2025.3573396. [2] SHEN Fei, XIE Yi, ZHU Jianqing, et al. GiT: Graph interactive transformer for vehicle re-identification[J]. IEEE Transactions on Image Processing, 2023, 32: 1039–1051. doi: 10.1109/TIP.2023.3238642. [3] 王博文, 郑建, 孙彦景, 等. 应急场景无人机自组网部分重叠信道动态分配方法[J]. 电子与信息学报, 2024, 46(12): 4373–4382. doi: 10.11999/JEIT240377.WANG Bowen, ZHENG Jian, SUN Yanjing, et al. Partially overlapping channels dynamic allocation method for UAV Ad-hoc networks in emergency scenario[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4373–4382. doi: 10.11999/JEIT240377. [4] 钱志鸿, 田春生, 郭银景, 等. 智能网联交通系统的关键技术与发展[J]. 电子与信息学报, 2020, 42(1): 2–19. doi: 10.11999/JEIT190787.QIAN Zhihong, TIAN Chunsheng, GUO Yinjing, et al. The key technology and development of intelligent and connected transportation system[J]. Journal of Electronics & Information Technology, 2020, 42(1): 2–19. doi: 10.11999/JEIT190787. [5] HE Wenying, WANG Feiyu, BAI Yude, et al. PEFN: A patches enhancement and hierarchical fusion network for robust vehicle re-identification[J]. IEEE Internet of Things Journal, 2025, 12(14): 26898–26910. doi: 10.1109/JIOT.2025.3561186. [6] LI Hongchao, CHEN Jingong, ZHENG Aihua, et al. Day-night cross-domain vehicle re-identification[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 12626–12635. doi: 10.1109/cvpr52733.2024.01200. [7] GUO Jinbo, ZHANG Xiaojing, LIU Zhengyi, et al. Generative and attentive fusion for multi-spectral vehicle re-identification[C]. The 7th International Conference on Intelligent Computing and Signal Processing, Xi'an, China, 2022: 1565–1572. doi: 10.1109/icsp54964.2022.9778769. [8] LI Hongchao, LI Chenglong, ZHU Xianpeng, et al. Multi-spectral vehicle re-identification: A challenge[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 11345–11353. doi: 10.1609/aaai.v34i07.6796. [9] ZHENG Aihua, ZHU Xianpeng, MA Zhiqi, et al. Cross-directional consistency network with adaptive layer normalization for multi-spectral vehicle re-identification and a high-quality benchmark[J]. Information Fusion, 2023, 100: 101901. doi: 10.1016/j.inffus.2023.101901. [10] ZHANG Hongyang, KUANG Zhenyu, CHENG Lidong, et al. Aivr-net: Attribute-based invariant visual representation learning for vehicle re-identification[J]. Knowledge-Based Systems, 2024, 289: 111455. doi: 10.1016/j.knosys.2024.111455. [11] BAU D, ZHOU Bolei, KHOSLA A, et al. Network dissection: Quantifying interpretability of deep visual representations[C]. IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 3319–3327. doi: 10.1109/cvpr.2017.354. [12] ZEILER M D and FERGUS R. Visualizing and understanding convolutional networks[C]. The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 818–833. doi: 10.1007/978-3-319-10590-1_53. [13] HU Jie, SHEN Li, and SUN Gang. Squeeze-and-excitation networks[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7132–7141. doi: 10.1109/cvpr.2018.00745. [14] LU Zefeng, LIN Ronghao, and HU Haifeng, Modality and camera factors bi-disentanglement for NIR-VIS object re-identification[J]. IEEE Transactions on Information Forensics and Security, 2023, 18: 1989–2004. doi: 10.1109/tifs.2023.3262130. [15] YE Mang, RUAN Weijian, DU Bo, et al. Channel augmented joint learning for visible-infrared recognition[C]. IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 13547–13556. doi: 10.1109/iccv48922.2021.01331. [16] 霍东东, 杜海顺. 基于通道重组和注意力机制的跨模态行人重识别[J]. 激光与光电子学进展, 2023, 60(14): 1410007. doi: 10.3788/LOP221850.HUO Dongdong and DU Haishun. Cross-modal person re-identification based on channel reorganization and attention mechanism[J]. Laser & Optoelectronics Progress, 2023, 60(14): 14100007. doi: 10.3788/LOP221850. [17] QIN Wencheng, HUANG Baojin, HUANG Zhiyong, et al. Deep constraints space via channel alignment for visible-infrared person re-identification[J]. IEEE Signal Processing Letters, 2022, 29: 2672–2676. doi: 10.1109/LSP.2022.3233002. [18] LIU Jiachang, SONG Wanru, CHEN Changhong, et al. Cross-modality person re-identification via channel-based partition network[J]. Applied Intelligence, 2022, 52(3): 2423–2435. doi: 10.1007/s10489-021-02548-3. [19] 伍邦谷, 张苏林, 石红, 等. 基于多分支结构的不确定性局部通道注意力机制[J]. 电子学报, 2022, 50(2): 374–382. doi: 10.12263/DZXB.20201204.WU Banggu, ZHANG Sulin, SHI Hong, et al. Multi-branch structure based local channel attention with uncertainty[J]. Acta Electronica Sinica, 2022, 50(2): 374–382. doi: 10.12263/DZXB.20201204. [20] SI Yunzhong, XU Huiying, ZHU Xinzhong, et al. SCSA: Exploring the synergistic effects between spatial and channel attention[J]. Neurocomputing, 2025, 634: 129866. doi: 10.1016/j.neucom.2025.129866. [21] HONG C, KIM H, BAIK S, et al. DAQ: Channel-wise distribution-aware quantization for deep image super-resolution networks[C]. IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2022: 913–922. doi: 10.1109/wacv51458.2022.00099. [22] WANG Yang, PENG Jinjia, WANG Huibing, et al. Progressive learning with multi-scale attention network for cross-domain vehicle re-identification[J]. Science China Information Sciences, 2022, 65(6): 160103. doi: 10.1007/s11432-021-3383-y. [23] LIU Xinchen, LIU Wu, ZHENG Jinkai, et al. Beyond the parts: Learning multi-view cross-part correlation for vehicle re-identification[C]. The 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 907–915. doi: 10.1145/3394171.3413578. [24] QIAN Jiuchao, PAN Minting, TONG Wei, et al. URRNet: A unified relational reasoning network for vehicle re-identification[J]. IEEE Transactions on Vehicular Technology, 2023, 72(9): 11156–11168. doi: 10.1109/TVT.2023.3262983. [25] HUA Xuecheng, CHENG Ke, LU Hu, et al. MSCMNet: Multi-scale semantic correlation mining for visible-infrared person re-identification[J]. Pattern Recognition, 2025, 159: 111090. doi: 10.1016/j.patcog.2024.111090. [26] LI Jiarui, ZHEN Qiu, YANG Yilin, et al. Prototype-driven multi-feature generation for visible-infrared person re-identification[C]. IEEE International Conference on Acoustics, Speech and Signal Processing, Hyderabad, India, 2025: 1–5. doi: 10.1109/ICASSP49660.2025.10889917. [27] HUANG Linhan, CHEN Yutao, LIU Liu, et al. Harmonizing metric discrepancy for cross-modal object re-identification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2025, 35(11): 11129–11143. doi: 10.1109/TCSVT.2025.3576091. [28] YANG Mouxing, HUANG Zhenyu, and PENG Xi. Robust object re-identification with coupled noisy labels[J]. International Journal of Computer Vision, 2024, 132(7): 2511–2529. doi: 10.1007/s11263-024-01997-w. [29] YU Hao, CHENG Xu, PENG Wei, et al. Modality unifying network for visible-infrared person re-identification[C]. IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 11151–11161. doi: 10.1109/iccv51070.2023.01027. [30] KIM M, KIM S, PARK J, et al. PartMix: Regularization strategy to learn part discovery for visible-infrared person re-identification[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 18621–18632. doi: 10.1109/cvpr52729.2023.01786. [31] WEI Xianbin, SONG Kechen, YANG Wenkang, et al. A visible-infrared clothes-changing dataset for person re-identification in natural scene[J]. Neurocomputing, 2024, 569: 127110. doi: 10.1016/j.neucom.2023.127110. [32] LI Guanzhi, ZHANG Aining, ZHANG Qizhi, et al. Pearson correlation coefficient-based performance enhancement of broad learning system for stock price prediction[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2022, 69(5): 2413–2417. doi: 10.1109/TCSII.2022.3160266. [33] LIU Gaqiong, HUANG Shucheng, WANG Gang, et al. Emrnet: Enhanced micro-expression recognition network with attention and distance correlation[J]. Artificial Intelligence Review, 2025, 58(6): 176. doi: 10.1007/s10462-025-11159-0. [34] CHUNG F R K. Spectral Graph Theory[M]. Providence: American Mathematical Society, 1997: 12–16. [35] YE Mang, SHEN Jianbing, LIN Gaojie, et al. Deep learning for person re-identification: A survey and outlook[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(6): 2872–2893. doi: 10.1109/TPAMI.2021.3054775. [36] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84–90. doi: 10.1145/3065386. [37] 周玉, 赵小锋, 汪一, 等. 关键细粒度信息指导的多尺度遮挡行人重识别[J]. 电子与信息学报, 2024, 46(6): 2578–2586. doi: 10.11999/JEIT230686.ZHOU Yu, ZHAO Xiaofeng, WANG Yi, et al. Multi-scale occluded person re-identification guided by key fine-grained information[J]. Journal of Electronics & Information Technology, 2024, 46(6): 2578–2586. doi: 10.11999/JEIT230686. [38] ZHAO Qianqian, SU Jiajun, ZHU Jianqing, et al. Modality-consistent attention for visible-infrared vehicle re-identification[J]. IEEE Signal Processing Letters, 2024, 31: 1910–1914. doi: 10.1109/LSP.2024.3431920. [39] YU Mingxin, GE Yiyuan, CHEN Zhihao, et al. No escape: Towards suggestive clues guidance for cross-modality person re-identification[J]. Information Fusion, 2025, 122: 103185. doi: 10.1016/j.inffus.2025.103185. [40] ZHANG Yukang and WANG Hanzi. Diverse embedding expansion network and low-light cross-modality benchmark for visible-infrared person re-identification[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 2153–2162. doi: 10.1109/cvpr52729.2023.00214. -


 下载:
下载:






图(6) / 表(2)
计量
- 文章访问数: 350
- HTML全文浏览量: 255
- PDF下载量: 50
- 被引次数: 0
