

A Study on Lightweight Method of TCM Structured Large Model Based on Memory-Constrained Pruning
-
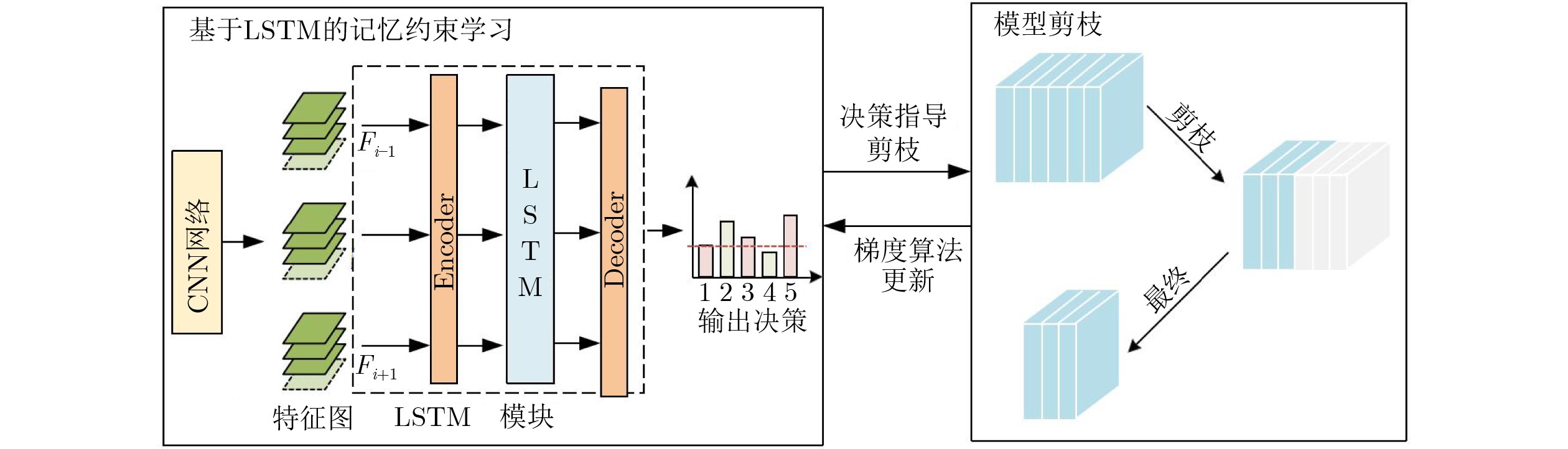
摘要: 随着人工智能技术的快速发展,大语言模型正在中医医疗领域广泛试点应用。但基层中医医院部署大模型面临GPU资源受限、中医非结构化病历利用率低的双重痛点。为此,该文提出一种轻量化的中医病历智能结构化模型。所提模型不仅借助知识蒸馏实现文本编码器轻量化,更重要的是在传统文本编码中引入多模态融合模块,实现轻量化舌诊图像表征。具体而言,该文提出了一种基于记忆约束的多模态表征轻量化方法。所提方法将长短时记忆网络作为剪枝决策器,分析历史信息中长时依赖关系,以此来学习并量化多模态表征中特征连接的重要性。在此基础上,引入增强学习方法对舌诊特征提取模型参数进行反向更新,进一步提升剪枝决策的准确性。实验采用多中心21家三甲医院的
10500 份脱敏中医电子病历及舌像图像关联文本进行训练与验证。实验结果证明,所提模型F1-score达91.7%,显存占用3.8 GB,推理速度22rec/s,较BERT-Large提升175%效率且显存降低75%。消融实验表明,动态批次裁剪相较于BERT-Large基准模型可节省75%显存,在模型自身消融对比中节省38.7%显存,中医术语增强词表使罕见实体F1-score提升6.2%。Abstract:Objective The structuring of Traditional Chinese Medicine (TCM) Electronic Medical Records (EMRs) is essential for knowledge discovery, clinical decision support, and intelligent diagnosis. However, two major barriers remain. First, TCM EMRs are primarily unstructured free text and often paired with tongue images, which complicates automated processing. Second, grassroots hospitals usually have limited GPU resources, which restricts the deployment of large pretrained models. This study aims to address these challenges by proposing a lightweight multimodal model based on memory-constrained pruning. The method is designed to preserve near-state-of-the-art accuracy while sharply reducing memory consumption and computation cost, ensuring practical use in resource-limited healthcare settings. Methods A three-stage architecture is used, comprising an encoder, a multimodal fusion module, and a decoder. For text, a distilled TinyBERT encoder is combined with a BiLSTM-CRF decoder to extract 23 categories of TCM clinical entities, including symptoms, syndromes, prescriptions, and herbs. For images, a ResNet-50 encoder processes tongue diagnosis photographs. A memory-constrained pruning strategy is introduced in which an LSTM decision network observes convolutional feature maps and adaptively prunes redundant channels while retaining key diagnostic information. Gradient reparameterization and dynamic channel grouping improve pruning flexibility, and a reinforcement-learning controller stabilizes training. INT8 mixed-precision quantization, gradient accumulation, and Dynamic Batch Pruning (DBP) further reduce memory usage. A TCM terminology-enhanced lexicon is integrated into the encoder embeddings to improve recognition of rare entities. The system is trained end-to-end on paired EMR-tongue datasets ( Fig. 1 ) to optimize multimodal information flow.Results and Discussions Experiments are performed on 10,500 de-identified EMRs paired with tongue images from 21 tertiary hospitals. On an RTX 3060 GPU, the model achieves an F1-score of 91.7%, reduces peak GPU memory to 3.8 GB, and reaches an inference speed of 22 records per second ( Table 1 ). Compared with BERT-Large, memory consumption decreases by 75%, throughput increases 1.75×, and accuracy remains comparable. Ablation studies confirm the contributions of each component. The adaptive attention gating mechanism increases F1 by 2.8% (Table 3 ). DBP reduces memory usage by 38.7% with minimal accuracy loss and improves performance on EMRs exceeding 5 000 characters. The terminology-enhanced lexicon improves recognition of rare entities such as “blood stasis” by 6.2%. Structured EMR fields also support association rule mining, and the confidence of syndrome-symptom relationships increases by 18%. These findings highlight three observations: (1) multimodal fusion with lightweight design provides clinical advantages over unimodal models; (2) memory-constrained pruning achieves stable channel reduction under strict hardware limits and outperforms magnitude-based pruning; and (3) pruning, quantization, and dynamic batching show strong synergy when jointly designed. The results support the feasibility of deploying high-performing TCM EMR structuring systems in real-world environments with limited computational capacity.Conclusions This study proposes a lightweight multimodal framework for structuring TCM EMRs. Memory-constrained pruning, combined with quantization and DBP, substantially compresses the visual encoder while maintaining text-image fusion accuracy. The approach reaches near-state-of-the-art performance with sharply reduced hardware requirements, enabling deployment in regional hospitals and clinics. Beyond efficiency gains, the structured multimodal outputs enhance TCM knowledge graphs and improve downstream tasks such as syndrome classification and treatment recommendation. The framework narrows the gap between powerful pretrained models and limited hardware resources in grassroots institutions and provides a scalable direction for lightweight multimodal NLP in medical informatics. Future work includes integrating modalities such as pulse-wave signals, extending pruning strategies with graph neural networks, and exploring adaptive cross-modal attention to strengthen clinical applicability. -
表 1 不同模型的性能对比
模型 F1-score
(%)显存占用
(GB)推理速度
(rec/s)BERT-Large 92.1 15.2 8 本文模型 91.7 3.8 22 CNN-BiLSTM 86.3 2.1 35 本文模型(-AG) 88.9 3.7 23 本文模型(-DBP) 91.5 6.2 20 T + EfficientNet-B0[18] 89.3 4.1 28 MobileBERT + MobileNet-V2 88.7 3.5 32 注:-AG表示移除自适应注意力门控,-DBP表示移除动态批次裁剪,动态批次裁剪的显存节省率62%指对比相同模型未启用该策略时的显存(6.2 GB)。  下载: 导出CSV
下载: 导出CSV
表 2 按实体类别细分的F1-score(测试集)
实体类别 具体实体名称 F1-score(%) 数据说明 肛肠科 刻下便血颜色 94.2 枚举型实体(淡红/鲜红/暗红),标签明确 刻下便后肛内肿物是否脱出 93.8 二元枚举(是/否),关键词规则清晰 骨科 患处VAS评分 95.6 数值型实体(整数),格式固定 健侧腕关节周径(cm) 95.1 decimal型数值,单位明确 呼吸内科 痰色 92.5 枚举型(黄/白/绿等),存在模糊描述(如“黄白相间”) 有无发热 93.3 二元枚举(有/无),时间范围明确 消化内科 刻下腹泻频次 91.8 范围枚举(每日<4次等),需处理模糊表述(如“5~8次”) 刻下有无黏液脓血便 92.1 三元枚举(有/无/未提及),文本表述直接 证候类 舌象(如“舌淡红”) 88.7 描述性文本,存在模糊性(如“淡红偏暗”) 脉象(如“脉细涩”) 87.5 术语嵌套(脉象+病机),表述抽象 注:数据来源于 2 100 份测试集(来自总数据集10 500 份),各类实体标注参照《中医诊断学术语》。
下载: 导出CSV
表 3 各模块对性能的影响
模块 F1-score 变化 显存变化 长文本处理稳定性 自适应注意力门控 +2.8% ±0% 无影响 动态批次裁剪 ±0.2% –38.7% 提升至99.6% 术语增强词表 +6.2% ±0% 无影响 注:显存节省率计算公式:$ \varDelta_{\rm{mem}}=\frac{M_{{\mathrm{base}}}-M_{{\text{opt}}}}{M_{{\mathrm{base}}}}\text{×}100\text{%} $。其中,$ {M}_\text{base} $为未使用优化策略时的显存(如无DBP时为6.2 GB),$ {M}_\text{opt} $为使用优化后的显存(3.8 GB)。
下载: 导出CSV
表 4 剪枝策略对比
剪枝策略 F1-score (%) 显存占用
(GB)推理速度
(rec/s)CNN-BiLSTM+无剪枝 91.7 6.2 18 CNN-BiLSTM+L1
范数剪枝91.2 4.8 20 CNN-BiLSTM+记忆
约束剪枝91.5 3.8 22
下载: 导出CSV
表 5 不同剪枝比例下的模型性能
剪枝比例 F1-score(%) 显存占用(GB) 推理速度(rec/s) 30% 91.2 4.5 19 40% 90.9 4.0 21 50% 90.1 3.5 24 60% 89.5 3.1 27 70% 87.1 2.7 30
下载: 导出CSV
表 6 不同LSTM隐藏层大小下的模型性能
LSTM隐藏层大小 F1-score(%) 模型参数量(M) 64 89.2 58.2 128 89.5 59.1 192 89.5 60.3 256 89.4 61.8
下载: 导出CSV
-
[1] MA Xinyin, FANG Gongfan, and WANG Xinchao. LLM-pruner: On the structural pruning of large language models[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 950. [2] 国家卫生健康委, 国家发展改革委, 教育部, 等. 2023年度全国三级公立中医医院绩效监测分析情况通报[EB/OL]. (2025-03-28) [2026-03-28]. http://www.natcm.gov.cn/yizhengsi/zhengcewenjian/2025-03-28/36079.html.National Health Commission, National Development and Reform Commission, Ministry of Education, et al. Circular on the Performance Monitoring and Analysis of National Tertiary Public Traditional Chinese Medicine Hospitals in 2023[EB/OL]. (2025-03-28) [2026-03-28]. http://www.natcm.gov.cn/yizhengsi/zhengcewenjian/2025-03-28/36079.html. [3] LE T D, JOUVET P, NOUMEIR R. Improving transformer performance for french clinical notes classification using mixture of experts on a limited dataset[J]. IEEE Journal of Translational Engineering in Health and Medicine, 2025, 13: 261–274. [4] WANG J, LI Y, and ZHANG Q. Lightweight BERT for TCM entity recognition in primary hospitals[C]. International Conference on Biomedical and Health Informatics (BHI), Pittsburgh, Pennsylvania, USA, 2023: 1–5. [5] GAO S, ZHANG Y, HUANG F, et al. Bilevelpruning: Unified dynamic and static channel pruning for convolutional neural networks[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), Seattle, Washington, USA, 2024: 16090–16100. [6] LIU Zhuang, SUN Mingjie, ZHOU Tinghui, et al. Rethinking the value of network pruning[C]. 7th International Conference on Learning Representations, New Orleans, USA, 2019. [7] KUNDU S, NAZEMI M, BEEREL P A, et al. DNR: A tunable robust pruning framework through dynamic network rewiring of DNNs[C]. The 26th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 2021: 344–350. doi: 10.1145/3394885.3431542. [8] JACOB B, KLIGYS S, CHEN Bo, et al. Quantization and training of neural networks for efficient integer-arithmetic-only inference[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 2704–2713. doi: 10.1109/CVPR.2018.00286. [9] HAN Song, MAO Huizi, and DALLY W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding[J]. arXiv preprint arXiv: 1510.00149, 2015. doi: 10.48550/arXiv.1510.00149. [10] JIA Q, ZHANG D, XU H, et al. Extraction of traditional Chinese medicine entity: design of a novel span-level named entity recognition method with distant supervision[J]. JMIR Medical Informatics, 2021, 9(6): e28219. [11] LIU X, HE P, CHEN W, et al. TinyBERT: Distilling BERT for natural language understanding[C]. EMNLP, Hong Kong, China, 2020: 4163-4174. [12] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [13] FU Zheren, ZHANG Lei, XIA Hou, et al. Linguistic-aware patch slimming framework for fine-grained cross-modal alignment[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 26297–26306. doi: 10.1109/CVPR52733.2024.02485. [14] PAN Zhengxin, WU Fangyu, and ZHANG Bailing. Fine-grained image-text matching by cross-modal hard aligning network[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 19275–19284. doi: 10.1109/CVPR52729.2023.01847. [15] BACK J, AHN N, and KIM J. Magnitude attention-based dynamic pruning[J]. Expert Systems with Applications, 2025, 276: 126957. doi: 10.1016/j.eswa.2025.126957. [16] LIU Jiaxin, LIU Wei, LI Yongming, et al. Attention-based adaptive structured continuous sparse network pruning[J]. Neurocomputing, 2024, 590: 127698. doi: 10.1016/j.neucom.2024.127698. [17] POUDEL P, CHHETRI A, GYAWALI P, et al. Multimodal federated learning with missing modalities through feature imputation network[C]. 29th Annual Conference on Medical Image Understanding and Analysis, Leeds, UK, 2026: 289–299. doi: 10.1007/978-3-031-98688-8_20. [18] TAN Mingxing and LE Q V. EfficientNet: Rethinking model scaling for convolutional neural networks[C]. 36th International Conference on Machine Learning, Long Beach, USA, 2019: 6105–6114. -


 下载:
下载:



图(3) / 表(7)
计量
- 文章访问数: 479
- HTML全文浏览量: 318
- PDF下载量: 40
- 被引次数: 0
