

A Survey of Lightweight Techniques for Segment Anything Model
-
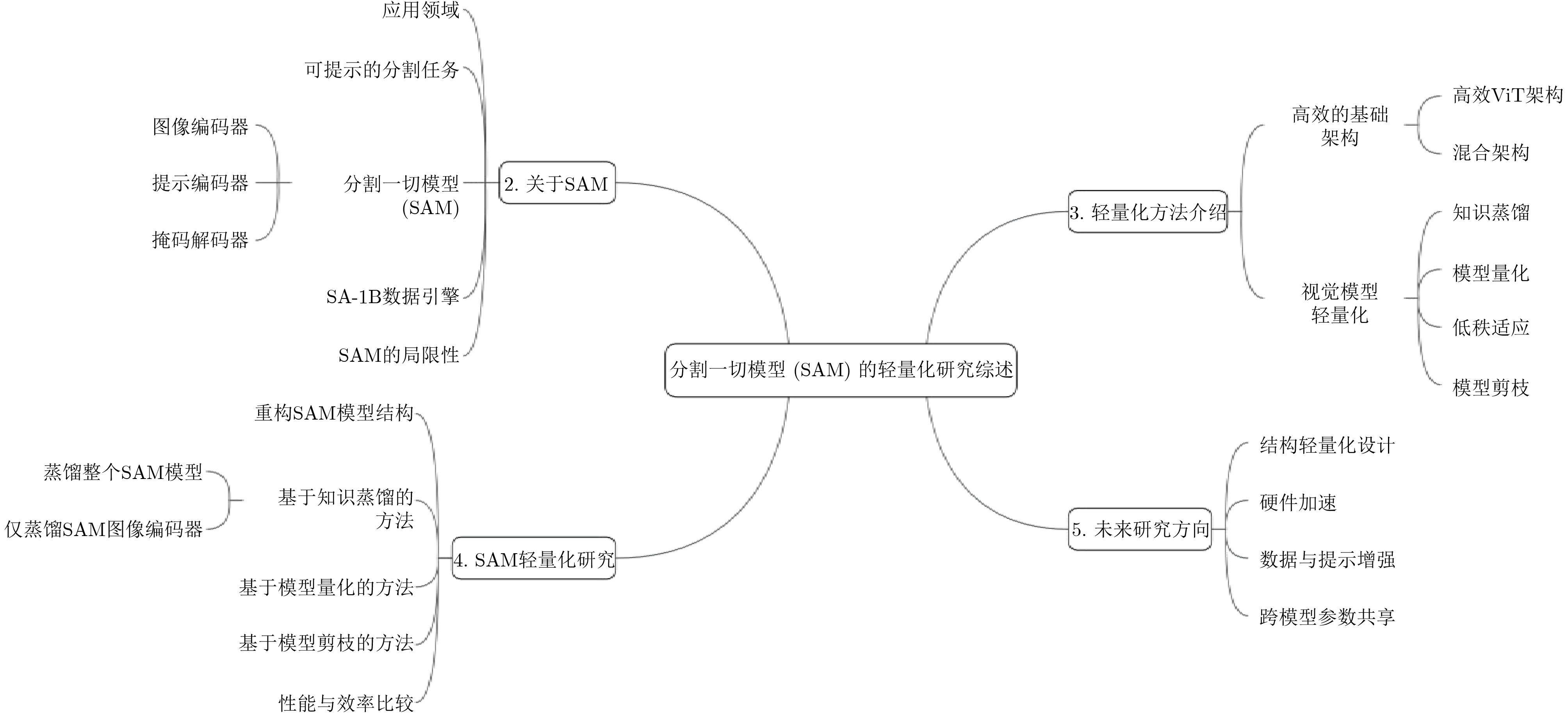
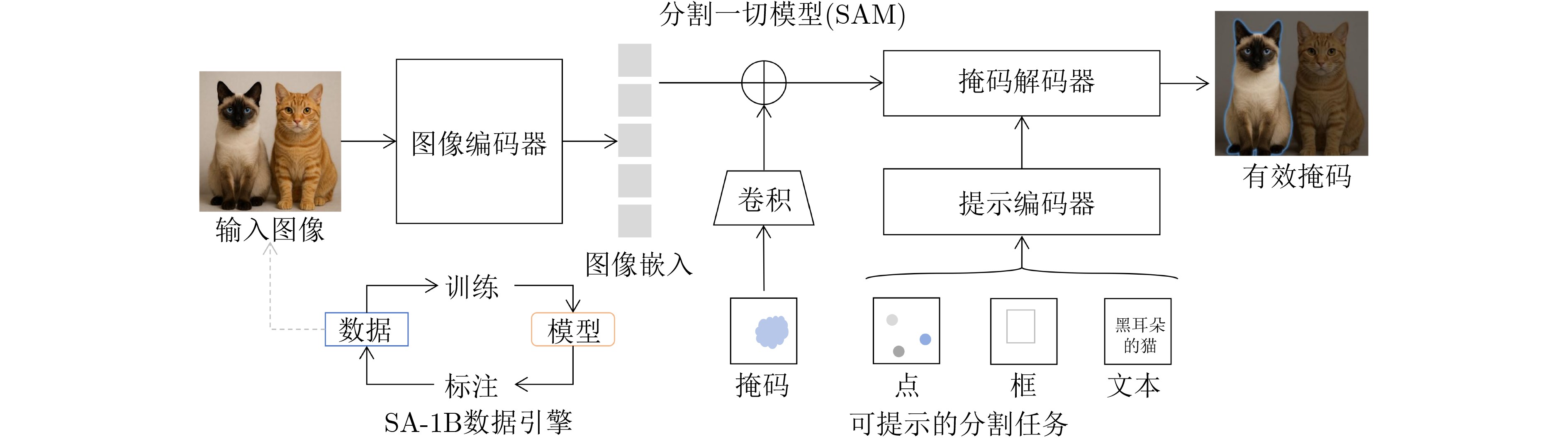
摘要: Meta公司提出的分割一切模型(SAM)作为计算机视觉领域的基础模型,在图像分割、目标检测与跟踪等任务中展现出强大的零样本泛化能力。然而,SAM模型依赖计算密集型的图像编码器(如ViT-H)和复杂的任务解码架构,导致高昂的计算资源消耗和存储需求,严重限制了其在边缘设备、移动终端等资源受限场景中的实际部署。为提升SAM的实用性,近年来研究者提出了多种轻量化方法。该文系统性综述了相关进展:首先,从任务范式、模型架构、数据引擎和应用领域等多方面简要介绍了SAM的基本情况。其次,回顾了高效基础架构替换、知识蒸馏、模型量化和模型剪枝等模型压缩方法。在此基础上,进一步概述了重构模型结构和轻量化网络替代等方法在当前SAM轻量化研究中的具体应用情况。最后,聚焦效率和精度上的平衡问题,对SAM轻量化模型未来的发展方向进行了深入分析和讨论。Abstract:
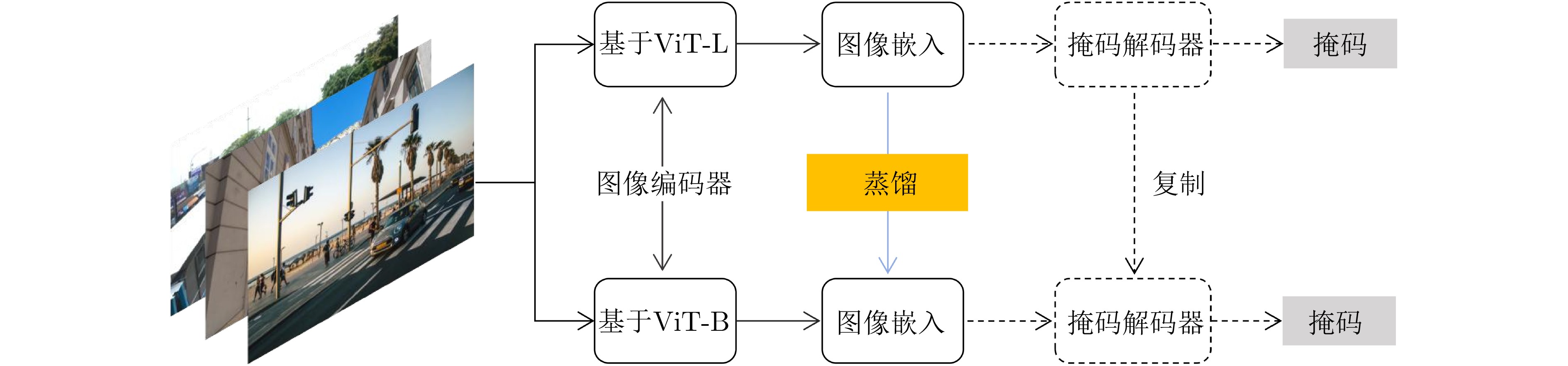
Objective The Segment Anything Model (SAM) demonstrates strong zero-shot generalization in image segmentation and sets a new direction for visual foundation models. The original SAM, especially the ViT-Huge version with about 637 million parameters, requires high computational resources and substantial memory. This restricts deployment in resource-limited settings such as mobile devices, embedded systems, and real-time tasks. Growing demand for efficient and deployable vision models has encouraged research on lightweight variants of SAM. Existing reviews describe applications of SAM, yet a structured summary of lightweight strategies across model compression, architectural redesign, and knowledge distillation is still absent. This review addresses this need by providing a systematic analysis of current SAM lightweight research, classifying major techniques, assessing performance, and identifying challenges and future research directions for efficient visual foundation models. Methods This review examines recent studies on SAM lightweight methods published in leading conferences and journals. The techniques are grouped into three categories based on their technical focus. The first category, Model Compression and Acceleration, covers knowledge distillation, network pruning, and quantization. The second category, Efficient Architecture Design, replaces the ViT backbone with lightweight structures or adjusts attention mechanisms. The third category, Efficient Feature Extraction and Fusion, refines the interaction between the image encoder and prompt encoder. A comparative assessment is conducted for representative studies, considering model size, computational cost, inference speed, and segmentation accuracy on standard benchmarks ( Table 3 ).Results and Discussions The reviewed models achieve clear gains in inference speed and parameter efficiency. MobileSAM reduces the model to 9.6 M parameters, and Lite-SAM reaches up to 16× acceleration while maintaining suitable segmentation accuracy. Approaches based on knowledge distillation and hybrid design support generalization across domains such as medical imaging, video segmentation, and embedded tasks. Although accuracy and speed still show a degree of tension, the selection of a lightweight strategy depends on the intended application. Challenges remain in prompt design, multi-scale feature fusion, and deployment on low-power hardware platforms. Conclusions This review provides an overview of the rapidly developing field of SAM lightweight research. The development of efficient SAM models is a multifaceted challenge that requires a combination of compression, architectural innovation, and optimization strategies. Current studies show that real-time performance on edge devices can be achieved with a small reduction in accuracy. Although progress is evident, challenges remain in handling complex scenarios, reducing the cost of distillation data, and establishing unified evaluation benchmarks. Future research is expected to emphasize more generalizable lightweight architectures, explore data-free or few-shot distillation approaches, and develop standardized evaluation protocols that consider both accuracy and efficiency. -
表 2 SAM轻量化研究工作总结
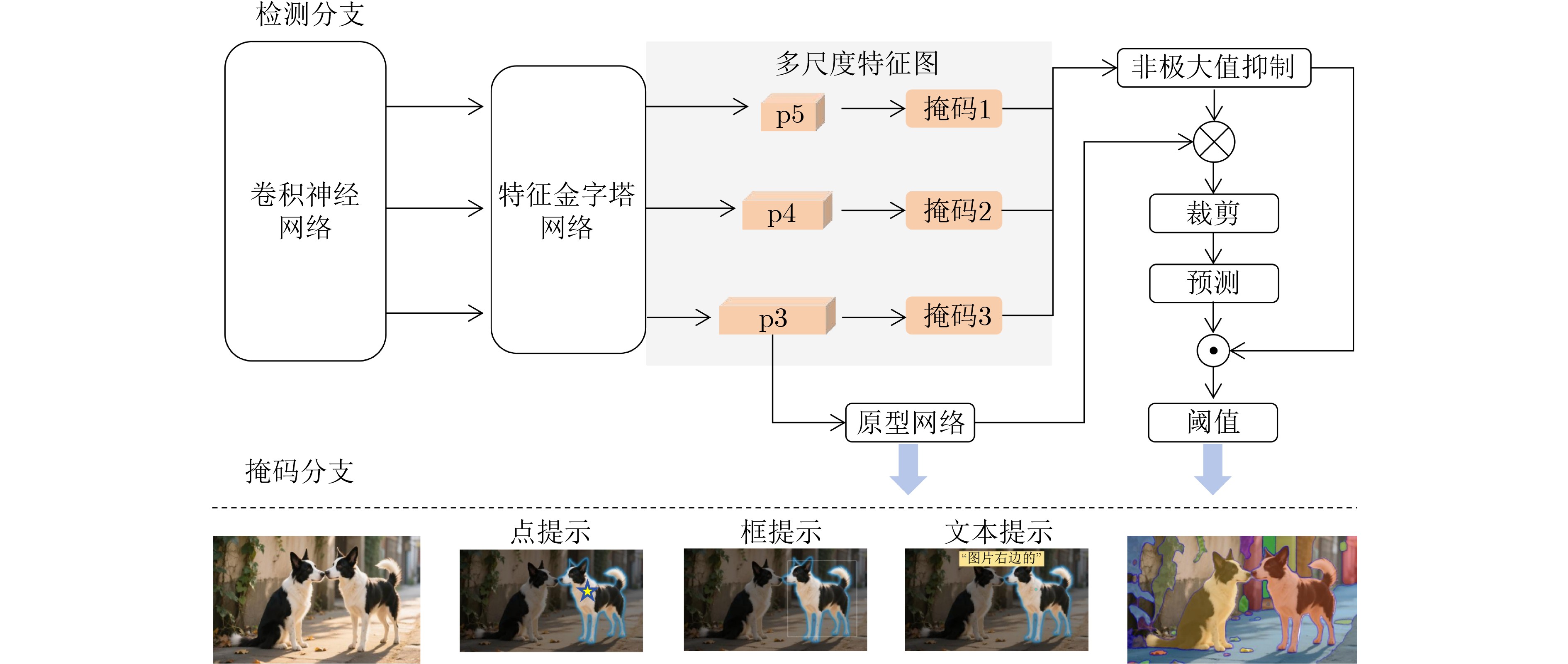
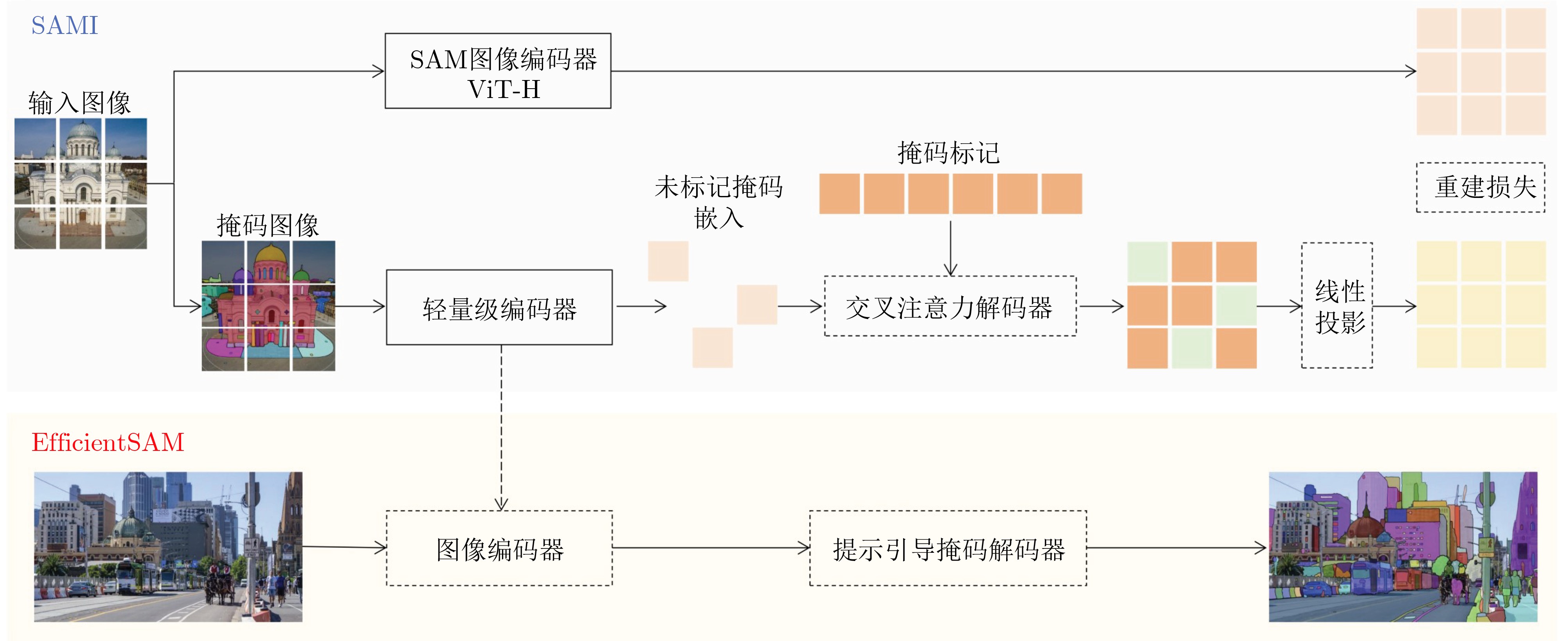
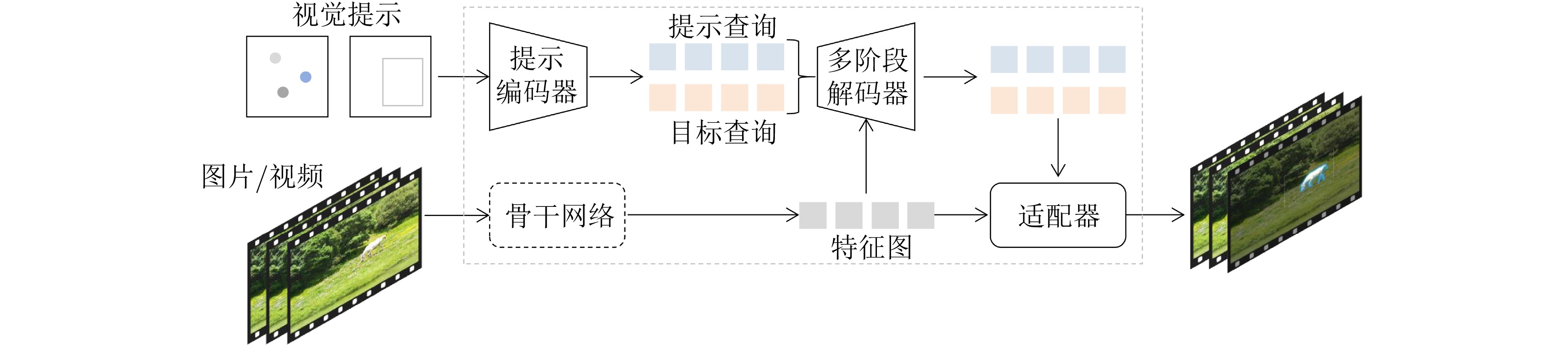
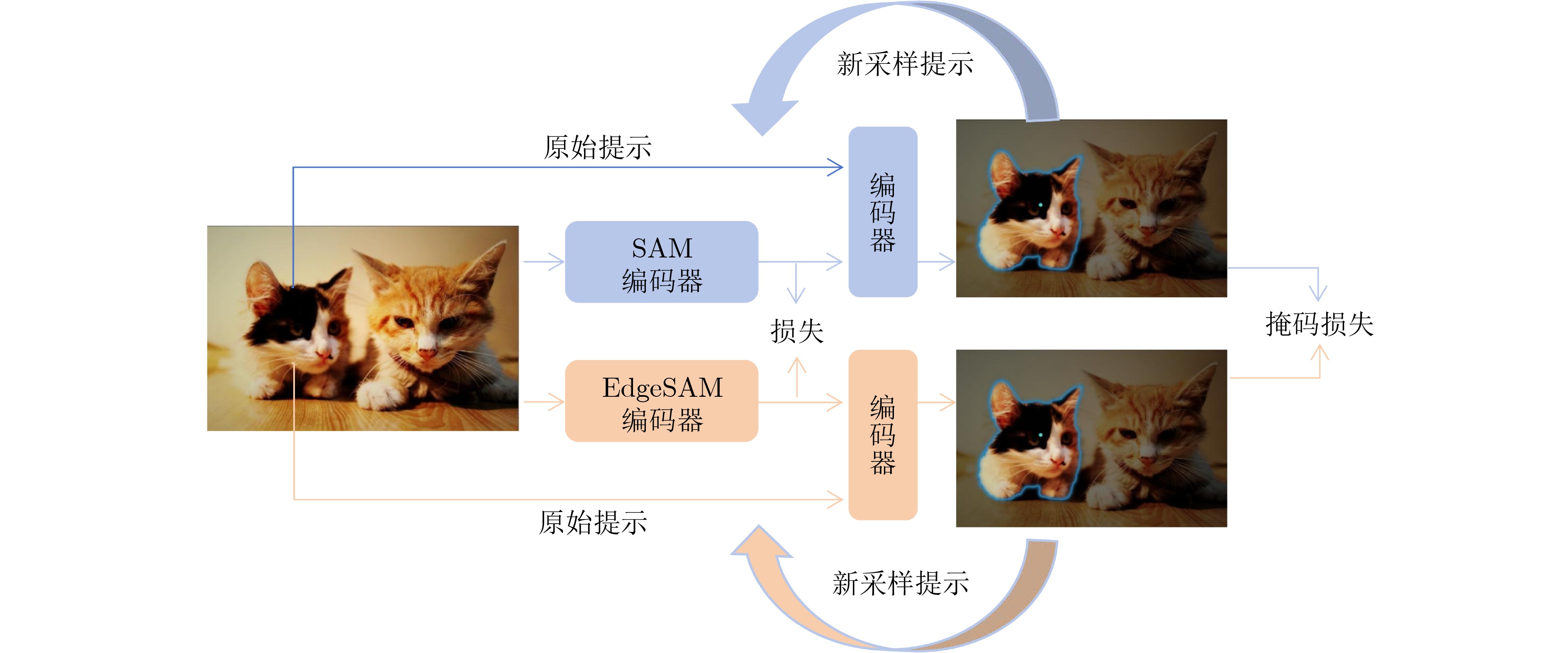
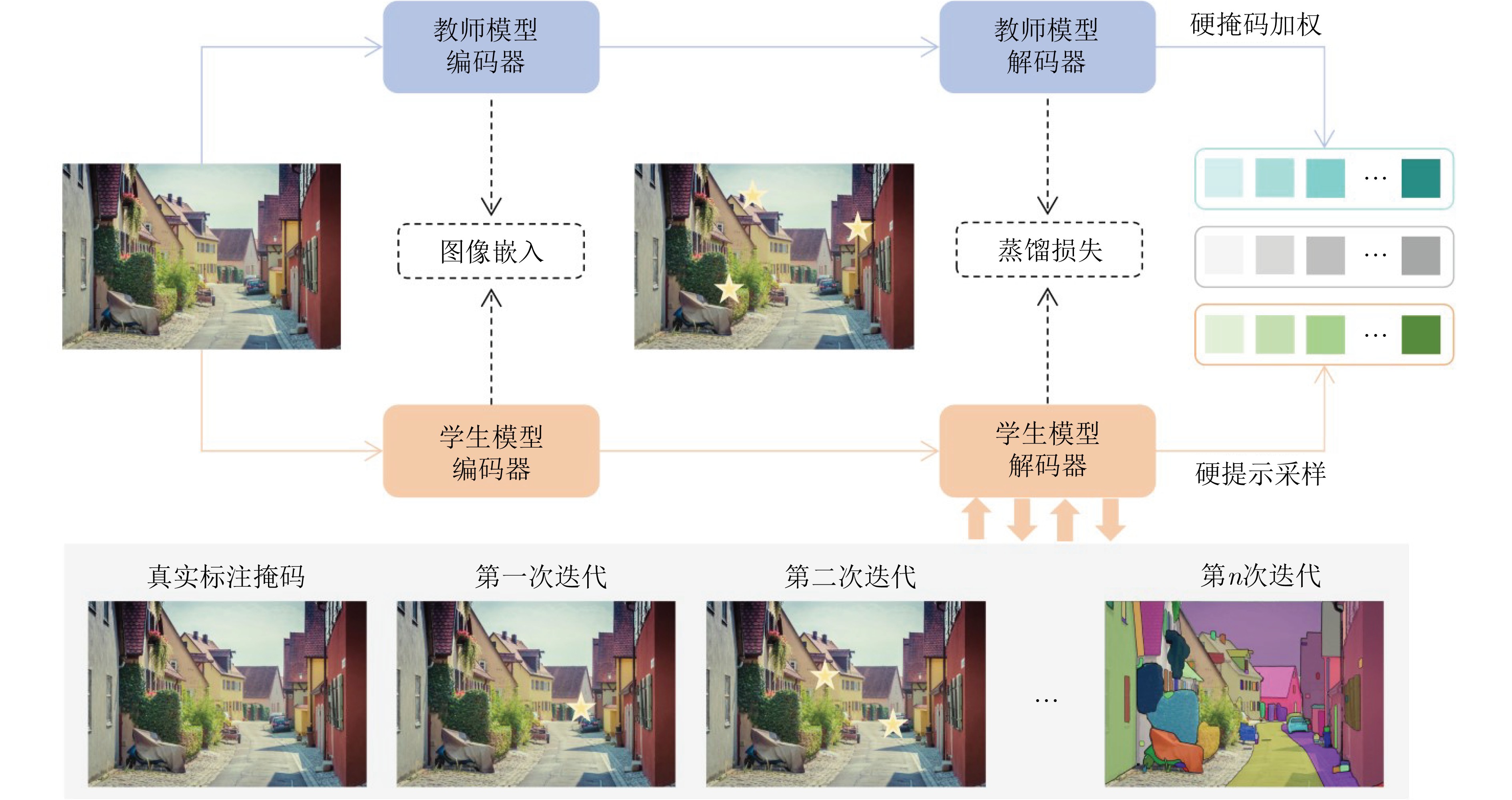
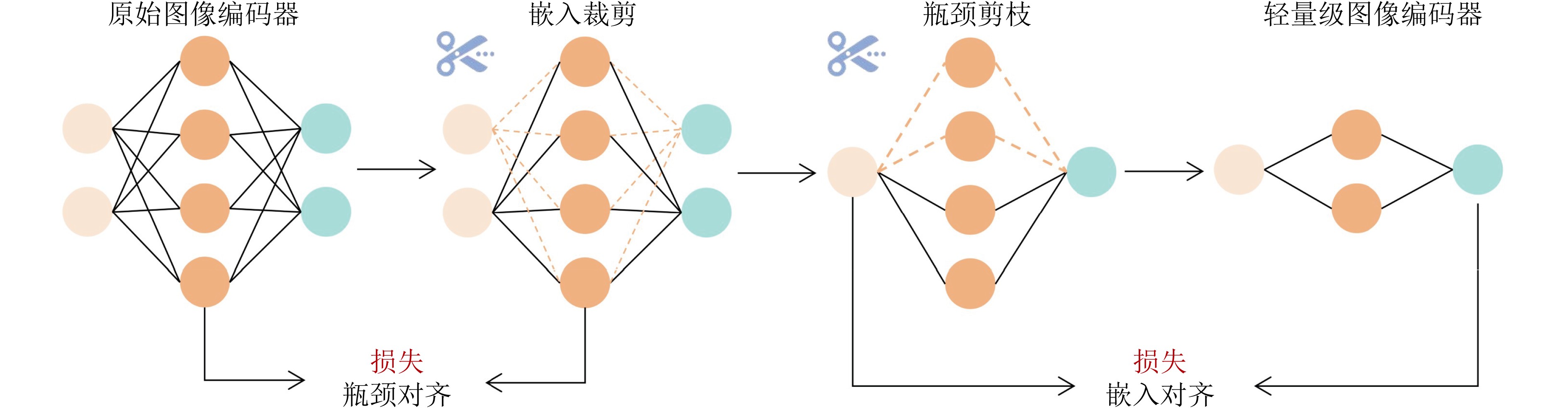
模型 发表时间(arxiv) 轻量化方法 网络结构 参数量(M) 应用领域 FastSAM[102] 2023.06 重构SAM YOLOv8-Seg(CNN) 68.00 轻量化通用分割模型 MobileSAM[50] 2023.06 知识蒸馏 TinyViT 9.66 轻量化通用分割模型 EdgeSAM[56] 2023.07 知识蒸馏 CNN 9.60 轻量化通用分割模型 nnSAM 2023.09 知识蒸馏 nnUNet(CNN) - 医学图像分割 EfficientSAM 2023.12 重构SAM ViT-Tiny/ViT-Small 25.00 轻量化通用分割模型 RepViT-SAM[55] 2023.12 知识蒸馏 RepViT(CNN) 48.90 轻量化通用分割模型 SlimSAM[101] 2023.12 模型剪枝 SAM 9.10 轻量化通用分割模型 SqueezeSAM 2023.12 重构SAM UNet(CNN) 19.00 交互式图像编辑工具 MobileSAMv2 2023.12 知识蒸馏 EfficientViT/TinyViT - 轻量化通用分割模型 TinySAM[52] 2023.12 知识蒸馏、模型量化 TinyViT - 轻量化通用分割模型 QMedSAM 2024.01 量化感知训练 ViT-Tiny 9.80 医学图像分割 EfficientViT-SAM 2024.02 知识蒸馏 EfficientViT 61.30 轻量化通用分割模型 FastSAM3D[69] 2024.03 知识蒸馏 ViT-Tiny - 3D医学影像分割 SAM-Lightening[70] 2024.03 知识蒸馏 Flash Attention(ViT) - 轻量化通用分割模型 PTQ4SAM[93] 2024.05 训练后量化 SAM - 嵌入式设备分割 Lite-SAM[65] 2024.07 重构SAM LiteViT(Hybrid) 4.20 轻量化通用分割模型 ESP-MedSAM 2024.07 知识蒸馏 TinyViT 28.46 医学图像分割 ESAM[51] 2024.08 重构SAM U-Net+ViT - 机器人操作、实时4D导航 KnowSAM 2024.12 知识蒸馏 UNet+SAM - 医学图像分割 KDSAM[86] 2025.01 知识蒸馏 ResNet-50(CNN) 26.40 医学图像分割 注:“-”表示原始论文中无相应的数据。  下载: 导出CSV
下载: 导出CSV
-
[1] BOMMASANI R, HUDSON D A, ADELI E, et al. On the opportunities and risks of foundation models[J]. arXiv preprint arXiv: 2108.07258, 2021. doi: 10.48550/arXiv.2108.07258. [2] HAN Kai, XIAO An, WU Enhua, et al. Transformer in transformer[C/OL]. The 35th International Conference on Neural Information Processing Systems, 2021: 1217. [3] OpenAI. GPT-4 technical report[J]. arXiv preprint arXiv: 2303.08774, 2023. doi: 10.48550/arXiv.2303.08774. [4] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[J]. 2018. [5] CHOWDHERY A, NARANG S, DEVLIN J, et al. PaLM: Scaling language modeling with pathways[J]. The Journal of Machine Learning Research, 2023, 24(1): 240. [6] TOUVRON H, LAVRIL T, IZACARD G, et al. LLaMA: Open and efficient foundation language models[J]. arXiv preprint arXiv: 2302.13971, 2023. doi: 10.48550/arXiv.2302.13971. [7] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[C/OL]. The 9th International Conference on Learning Representations, 2021. [8] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C/OL]. The 38th International Conference on Machine Learning, 2021: 8748–8763. [9] BAO Hangbo, DONG Li, PIAO Songhao, et al. BEiT: BERT pre-training of image transformers[C/OL]. The 10th International Conference on Learning Representations, 2022. [10] HE Kaiming, CHEN Xinlei, XIE Saining, et al. Masked autoencoders are scalable vision learners[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 16000–16009. doi: 10.1109/CVPR52688.2022.01553. [11] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. The 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, USA, 2019: 4171–4186. doi: 10.18653/v1/N19-1423. [12] ZHANG Hao, LI Feng, LIU Shilong, et al. DINO: DETR with improved denoising anchor boxes for end-to-end object detection[C]. The 11th International Conference on Learning Representations, Kigali, Rwanda, 2023. [13] KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 4015–4026. doi: 10.1109/ICCV51070.2023.00371. [14] ZHANG Chunhui, LIU Li, CUI Yawen, et al. A comprehensive survey on segment anything model for vision and beyond[J]. arXiv preprint arXiv: 2305.08196, 2023. doi: 10.48550/arXiv.2305.08196. [15] ZHANG Yichi, SHEN Zhenrong, and JIAO Rushi. Segment anything model for medical image segmentation: Current applications and future directions[J]. Computers in Biology and Medicine, 2024, 171: 108238. doi: 10.1016/j.compbiomed.2024.108238. [16] 王淼, 黄智忠, 何晖光, 等. 分割一切模型SAM的潜力与展望: 综述[J]. 中国图象图形学报, 2024, 29(6): 1479–1509. doi: 10.11834/jig.230792.WANG Miao, HUANG Zhizhong, HE Huiguang, et al. Potential and prospects of segment anything model: A survey[J]. Journal of Image and Graphics, 2024, 29(6): 1479–1509. doi: 10.11834/jig.230792. [17] LIU Pengfei, YUAN Weizhe, FU Jinlan, et al. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing[J]. ACM Computing Surveys, 2023, 55(9): 195. doi: 10.1145/3560815. [18] HU Chuanfei, XIA Tianyi, JU Shenghong, et al. When SAM meets medical images: An investigation of Segment Anything Model (SAM) on multi-phase liver tumor segmentation[J]. arXiv preprint arXiv: 2304.08506, 2023. doi: 10.48550/arXiv.2304.08506. [19] WANG Chong, WAN Yajie, Li Shuxin, et al. SegAnyPath: A foundation model for multi- resolution stain-variant and multi-task pathology image segmentation[J]. IEEE Transactions on Medical Imaging, 2025, 44(10): 3924-3937. doi: 10.1109/TMI.2024.3501352. [20] CHENG Junlong, YE Jin, DENG Zhongying, et al. SAM-Med2D[EB/OL]. http://arxiv.org/abs/2308.16184v1, 2023. [21] TANG Lv, XIAO Haoke, and LI Bo. Can SAM segment anything? When SAM meets camouflaged object detection[EB/OL]. http://arxiv.org/abs/2304.04709v2, 2023. [22] SHAHARABANY T, DAHAN A, GIRYES R, et al. AutoSAM: Adapting SAM to medical images by overloading the prompt encoder[EB/OL]. http://arxiv.org/abs/2306.06370v1, 2023. [23] DAI Haixing, MA Chong, YAN Zhiling, et al. SAMAug: Point prompt augmentation for segment anything model[EB/OL]. http://arxiv.org/abs/2307.01187v4, 2023. [24] ZHANG Yichi, CHENG Yuan, and QI Yuan. SemiSAM: Exploring SAM for enhancing semi-supervised medical image segmentation with extremely limited annotations[EB/OL]. http://arxiv.org/abs/2312.06316v1, 2023. [25] OpenMMLab. MMDet-SAM[EB/OL]. https://github.com/open-mmlab/playground/blob/main/mmdet_sam/README.md, 2023. [26] AHMADI M, LONBAR A G, NAEINI H K, et al. Application of segment anything model for civil infrastructure defect assessment[J]. Innovative Infrastructure Solutions, 2025, 10(7): 269. doi: 10.1007/s41062-025-02073-z. [27] LI Yaqin, WANG Dandan, YUAN Cao, et al. Enhancing agricultural image segmentation with an agricultural segment anything model adapter[J]. Sensors, 2023, 23(18): 7884. doi: 10.3390/s23187884. [28] 周洁, 方振宇. 基于SAM多尺度标签优化的半监督学习遥感目标检测[J]. 微电子学与计算机, 2026, 43(1): 65-74. doi: 10.19304/J.ISSN1000-7180.2024.0621.ZHOU Jie, FANG Zhenyu. Semi-supervised remote sensing object detection based on SAM multi-scale label optimization[J]. Microelectronics & Computer, 2026, 43(1): 65-74. doi: 10.19304/J.ISSN1000-7180.2024.0621. [29] YU Tao, FENG Runseng, FENG Ruoyu, et al. Inpaint anything: Segment anything meets image inpainting[J]. arXiv preprint arXiv: 2304.06790, 2023. doi: 10.48550/arXiv.2304.06790. [30] XIE Defeng, WANG Ruichen, MA Jian, et al. Edit everything: A text-guided generative system for images editing[J]. arXiv preprint arXiv: 2304.14006, 2023. doi: 10.48550/arXiv.2304.14006. [31] WANG Teng, ZHANG Jinrui, FEI Junjie, et al. Caption anything: Interactive image description with diverse multimodal controls[J]. arXiv preprint arXiv: 2305.02677, 2023. doi: 10.48550/arXiv.2305.02677. [32] YANG Jinyu, GAO Mingqi, LI Zhe, et al. Track anything: Segment anything meets videos[J]. arXiv preprint arXiv: 2304.11968, 2023. doi: 10.48550/arXiv.2304.11968. [33] CHENG H K and SCHWING A G. XMem: Long-term video object segmentation with an Atkinson-Shiffrin memory model[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 640–658. doi: 10.1007/978-3-031-19815-1_37. [34] LIU Youquan, KONG Lingdong, CEN Jun, et al. Segment any point cloud sequences by distilling vision foundation models[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 1617. [35] CEN Jiazhong, ZHOU Zanwei, FANG Jiemin, et al. Segment anything in 3D with NeRFs[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 1130. [36] 苏丽, 孙雨鑫, 苑守正. 基于深度学习的实例分割研究综述[J]. 智能系统学报, 2022, 17(1): 16–31. doi: 10.11992/tis.202109043.SU Li, SUN Yuxin, and YUAN Shouzheng. A survey of instance segmentation research based on deep learning[J]. CAAI Transactions on Intelligent Systems, 2022, 17(1): 16–31. doi: 10.11992/tis.202109043. [37] 王梓茏. 基于目标检测的遥感视觉场景理解算法研究[D]. [硕士论文], 中国矿业大学, 2024. doi: 10.27623/d.cnki.gzkyu.2024.003060.WANG Zilong. Research on remote sensing visual scene understanding algorithms based on object detection[D]. [Master dissertation], China University of Mining and Technology, 2024. doi: 10.27623/d.cnki.gzkyu.2024.003060. [38] GHIASI G, CUI Yin, SRINIVAS A, et al. Simple copy-paste is a strong data augmentation method for instance segmentation[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 2918–2928. doi: 10.1109/CVPR46437.2021.00294. [39] 刘思涌, 赵毅力. 微调SAM的遥感图像高效语义分割模型DP-SAM. 中国图象图形学报, 30(8):2884-2896. doi: 10.11834/jig.240540.LIU Siyong, ZHAO Yili. DP-SAM: Efficient semantic segmentation of remote sensing images by fine-tuning SAM. Journal of Image and Graphics, 30(8):2884-2896. doi: 10.11834/jig.240540. [40] 吴曈, 胡浩基, 冯洋, 等. 分割一切模型(SAM)在医学图像分割中的应用[J]. 中国激光, 2024, 51(21): 2107102. doi: 10.3788/CJL240614.WU Tong, HU Haoji, FENG Yang, et al. Application of segment anything model in medical image segmentation[J]. Chinese Journal of Lasers, 2024, 51(21): 2107102. doi: 10.3788/CJL240614. [41] HU Mingzhe, LI Yuheng, and YANG Xiaofeng. SkinSAM: Empowering skin cancer segmentation with segment anything model[J]. arXiv preprint arXiv: 2304.13973, 2023. doi: 10.48550/arXiv.2304.13973. [42] CHAI Shurong, JAIN R K, TENG Shiyu, et al. Ladder fine-tuning approach for SAM integrating complementary network[EB/OL]. http://arxiv.org/abs/2306.12737v1, 2023. [43] 孙兴, 蔡肖红, 李明, 等. 视觉大模型SAM在医学图像分割中的应用综述[J]. 计算机工程与应用, 2024, 60(17): 1–16. doi: 10.3778/j.issn.1002-8331.2401-0136.SUN Xing, CAI Xiaohong, LI Ming, et al. A review on the application of the vision large model SAM in medical image segmentation[J]. Computer Engineering and Applications, 2024, 60(17): 1–16. doi: 10.3778/j.issn.1002-8331.2401-0136. [44] GAO Yifan, XIA Wei, HU Dingdu, et al. DeSAM: Decoupling segment anything model for generalizable medical image segmentation[EB/OL]. http://arxiv.org/abs/2306.00499v1, 2023. [45] XU Yinsong, TANG Jiaqi, MEN Aidong, et al. EviPrompt: A training-free evidential prompt generation method for segment anything model in medical images[EB/OL]. http://arxiv.org/abs/2311.06400v1, 2023. [46] ZHANG Jie, LI Yunxin, YANG Xubing, et al. RSAM-Seg: A SAM-based model with prior knowledge integration for remote sensing image semantic segmentation[J]. Remote Sensing, 2025, 17(4): 590. doi: 10.3390/rs17040590. [47] WANG Di, ZHANG Jing, DU Bo, et al. SAMRS: Scaling-up remote sensing segmentation dataset with segment anything model[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 385. [48] HUANG You, LAI Wenbin, JI Jiayi, et al. HRSAM: Efficient interactive segmentation in high-resolution images[J]. arXiv preprint arXiv: 2407.02109, 2024. doi: 10.48550/arXiv.2407.02109. [49] CHEN Keyan, LIU Chenyang, CHEN Hao, et al. RSPrompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 4701117. doi: 10.1109/TGRS.2024.3356074. [50] ZHANG Chaoning, HAN Dongshen, QIAO Yu, et al. Faster segment anything: Towards lightweight SAM for mobile applications[J]. arXiv preprint arXiv: 2306.14289, 2023. doi: 10.48550/arXiv.2306.14289. [51] XU Xiuwei, CHEN Huangxing, ZHAO Linqing, et al. EmbodiedSAM: Online segment any 3D thing in real time[C]. The 13th International Conference on Learning Representations, Singapore, Singapore, 2025. [52] SHU Han, LI Wenshuo, TANG Yehui, et al. TinySAM: Pushing the envelope for efficient segment anything model[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025. doi: 10.1609/aaai.v39i19.34255. [53] TAN Daiqing, ZANG Hao, ZHANG Xinyue, et al. Tongue-LiteSAM: A lightweight model for tongue image segmentation with zero-shot.[J]. IEEE Access, 2025, 13: 11689–11703. doi: 10.1109/ACCESS.2025.3528658. [54] NVIDIA-AI-IoT. nanosam: Real-time 3D segmentation framework[EB/OL]. https://github.com/NVIDIA-AI-IOT/nanosam, 2023. [55] WANG Ao, CHEN Hui, LIN Zijia, et al. RepViT-SAM: Towards real-time segmenting anything[J]. arXiv preprint arXiv: 2312.05760, 2023. doi: 10.48550/arXiv.2312.05760. [56] ZHOU Chong, LI Xiangtai, LOY C C, et al. EdgeSAM: Prompt-in-the-loop distillation for SAM[J]. arXiv preprint arXiv: 2312.06660, 2023. doi: 10.48550/arXiv.2312.06660. [57] WANG Guodong, CAO Yu, HU Chuanyi, et al. Hierarchical Distillation of SAM for Lightweight Insulator Defect Segmentation[C]. 2024 6th International Conference on Robotics, Intelligent Control and Artificial Intelligence (RICAI), Nanjing, China, 2024: 1325–1329. doi: 10.1109/RICAI64321.2024.10911250. [58] 马依拉木·木斯得克, 高雨欣, 张思拓, 等. SAM及其改进模型在图像分割中的应用综述[J]. 计算机工程, 2025, 51(8): 16–38. doi: 10.19678/j.issn.1000-3428.0070619.MUSIDEKE M, GAO Yuxin, ZHANG Situo, et al. Review of application of SAM and its improved models in image segmentation[J]. Computer Engineering, 2025, 51(8): 16–38. doi: 10.19678/j.issn.1000-3428.0070619. [59] MA Jun, HE Yuting, LI Feifei, et al. Segment anything in medical images[J]. Nature Communications, 2024, 15(1): 654. doi: 10.1038/s41467-024-44824-z. [60] SHEN Qiuhong, YANG Xingyi, and WANG Xinchao. Anything-3D: Towards single-view anything reconstruction in the wild[J]. arXiv preprint arXiv: 2304.10261, 2023. doi: 10.48550/arXiv.2304.10261. [61] YU Weihao, LUO Mi, ZHOU Pan, et al. MetaFormer is actually what you need for vision[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 10819–10829. doi: 10.1109/CVPR52688.2022.01055. [62] YU Weihao, SI Chenyang, ZHOU Pan, et al. MetaFormer baselines for vision[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(2): 896–912. doi: 10.1109/TPAMI.2023.3329173. [63] WANG Xiaolong, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7794–7803. doi: 10.1109/CVPR.2018.00813. [64] WU Fengyi, ZHANG Tianfang, LI Lei, et al. RPCANet: Deep unfolding RPCA based infrared small target detection[C]. 2024 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2024: 4809–4818. doi: 10.1109/WACV57701.2024.00474. [65] FU Jianhai, YU Yuanjie, LI Ningchuan, et al. Lite-SAM is actually what you need for segment everything[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2025: 456–471. doi: 10.1007/978-3-031-72754-2_26. [66] LIU Jiaji, LUO Xiaonan, WANG Dong, et al. MobileVitV2-based fusion of vision transformers and convolutional neural networks for underwater image enhancement.[C]. 2023 13th International Conference on Information Science and Technology (ICIST), Cairo, Egypt, 2023: 195–204. doi: 10.1109/ICIST59754.2023.10367056. [67] ZHANG Tianfang, LI Lei, ZHOU Yang, et al. CAS-ViT: Convolutional additive self-attention vision transformers for efficient mobile applications[J]. arXiv preprint arXiv: 2408.03703, 2024. doi: 10.48550/arXiv.2408.03703. [68] DAO T, FU D Y, ERMON S, et al. FlashAttention: Fast and memory-efficient exact attention with IO-awareness[C]. The 36th Annual Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 16344–16359. [69] SHEN Yiqing, LI Jingxing, SHAO Xinyuan, et al. FastSAM3D: An efficient segment anything model for 3D volumetric medical images[C]. The 27th International Conference on Medical Image Computing and Computer Assisted Intervention, Marrakesh, Morocco, 2024: 542–552. doi: 10.1007/978-3-031-72390-2_51. [70] SONG Yanfei, PU Bangzheng, WANG Peng, et al. SAM-lightening: A lightweight segment anything model with dilated flash attention to achieve 30 times acceleration[J]. arXiv preprint arXiv: 2403.09195, 2024. doi: 10.48550/arXiv.2403.09195. [71] DAO T. FlashAttention-2: Faster attention with better parallelism and work partitioning[C]. The 12th International Conference on Learning Representations, Vienna, Austria, 2024. [72] GUO Jianyuan, HAN Kai, WU Han, et al. CMT: Convolutional neural networks meet vision transformers[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 12175–12185. doi: 10.1109/CVPR52688.2022.01186. [73] MEHTA S and RASTEGARI M. MobileViT: Light-weight, general-purpose, and mobile-friendly vision transformer[C]. The 10th International Conference on Learning Representations, 2022. [74] LEE S, CHOI J, and J. KIM H. EfficientViM: Efficient vision mamba with hidden state mixer based state space duality.[C] 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2025: 14923–14933. doi: 10.1109/CVPR52734.2025.01390. [75] WADEKAR S N and CHAURASIA A. MobileViTv3: Mobile-friendly vision transformer with simple and effective fusion of local, global and input features[J]. arXiv preprint arXiv: 2209.15159, 2022. doi: 10.48550/arXiv.2209.15159. [76] CAI Han, LI Junyan, HU Muyan, et al. EfficientViT: Lightweight multi-scale attention for high-resolution dense prediction[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023. doi: 10.1109/ICCV51070.2023.01587. [77] SCHMIDT T and NEWCOMBEE R. Segment This Thing: Foveated Tokenization for Efficient Point-Prompted Segmentation.[C] 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2025: 29428–29437. doi: 10.1109/CVPR52734.2025.02740. [78] LI Yanyu, HU Ju, WEN Yang, et al. Rethinking vision transformers for MobileNet size and speed[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023. doi: 10.1109/ICCV51070.2023.01549. [79] ZHAO Yingwei. Efficient SAM for medical image analysis[EB/OL]. https://www.researchgate.net/publication/375895620_Efficient_SAM_for_Medical_Image_Analysis, 2023. [80] WU Kan, ZHANG Jinnian, PENG Houwen, et al. TinyViT: Fast pretraining distillation for small vision transformers[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 68–85. doi: 10.1007/978-3-031-19803-8_5. [81] LI Pengyu, GUO Tianchu, WANG Biao, et al. Grid-attention: Enhancing computational efficiency of large vision models without fine-tuning[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2025: 54–70. doi: 10.1007/978-3-031-72973-7_4. [82] SHEN Yifan, LI Zhengyuan, and WANG Gang. Practical Region-level Attack against Segment Anything Models.[C] 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, USA, 2024: 194–203. doi: 10.1109/CVPRW63382.2024.00024. [83] CHEN Feiyang, LUO Ziqian, ZHOU Lisang, et al. Comprehensive survey of model compression and speed up for vision transformers[J]. arXiv preprint arXiv: 2404.10407, 2024. doi: 10.48550/arXiv.2404.10407. [84] HINTON G, VINYALS O, and DEAN J. Distilling the knowledge in a neural network[J]. arXiv preprint arXiv: 1503.02531, 2015. doi: 10.48550/arXiv.1503.02531. [85] 周涛, 黄凯雯. 基于SAM引导知识蒸馏的半监督医学图像分割方法及装置[P]. 中国, 202411166303.0, 2024.ZHOU Tao and HUANG Kaiwen. SAM-guided knowledge distillation-based semi-supervised medical image segmentation method and device[P]. CN, 202411166303.0, 2024. [86] PATIL K D, PALANI G, and KRISHNAMURTHI G. Efficient knowledge distillation of SAM for medical image segmentation[J]. arXiv preprint arXiv: 2501.16740, 2025. doi: 10.48550/arXiv.2501.16740. [87] ZHANG Quan, LIU Xiaoyu, LI Wei, et al. Distilling semantic priors from SAM to efficient image restoration models[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 25409–25419. doi: 10.1109/CVPR52733.2024.02401. [88] WU Jingqian, XU Rongtao, WOOD-DOUGHTY Z, et al. Segment anything model is a good teacher for local feature learning[J]. IEEE Transactions on Image Processing, 2025, 34: 2097–2111. doi: 10.1109/TIP.2025.3554033. [89] ISRAEL U, MARKS M, DILIP R, et al. A foundation model for cell segmentation[J]. arXiv preprint arXiv: 2011.11004, 2023. doi: 10.48550/arXiv.2311.11004. [90] YU Yang, XU Chen, and WANG Kai. TS-SAM: Fine-tuning segment-anything model for downstream tasks[C]. 2024 IEEE International Conference on Multimedia and Expo, Niagara Falls, Canada, 2024: 1–6. doi: 10.1109/ICME57554.2024.10688340. [91] 谢政. 高效深度迁移学习与模型压缩研究[D]. [硕士论文], 华南理工大学, 2021. doi: 10.27151/d.cnki.ghnlu.2021.003508.XIE Zheng. Research on efficient deep transfer learning and model compression[D]. [Master dissertation], South China University of Technology, 2021. doi: 10.27151/d.cnki.ghnlu.2021.003508. [92] PARK G, PARK B, KIM M, et al. LUT-GEMM: Quantized matrix multiplication based on LUTs for efficient inference in large-scale generative language models[J]. arXiv preprint arXiv: 2206.09557, 2022. doi: 10.48550/arXiv.2206.09557. [93] LV Chengtao, CHEN Hong, GUO Jinyang, et al. PTQ4SAM: Post-training quantization for segment anything[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024. doi: 10.1109/CVPR52733.2024.01509. [94] HU E J, SHEN Yelong, WALLIS P, et al. LoRA: Low-rank adaptation of large language models[J]. The 10th International Conference on Learning Representations, 2022. [95] 赵晓佳. 基于张量低秩学习的多视图聚类算法研究[D]. [硕士论文], 哈尔滨工业大学, 2024. doi: 10.27061/d.cnki.ghgdu.2024.000950.ZHAO Xiaojia. Research on multi-view clustering algorithm based on tensor low-rank learning[D]. [Master dissertation], Harbin Institute of Technology, 2024. doi: 10.27061/d.cnki.ghgdu.2024.000950. [96] ALEEM S, DIETLMEIER J, ARAZO E, et al. ConvLoRA and AdaBN based domain adaptation via self-training[J]. arXiv: 2402.04964, 2024. doi: 10.48550/arXiv.2402.04964. [97] ZHANG Kaidong and LIU Dong. Customized segment anything model for medical image segmentation[J]. arXiv preprint arXiv: 2304.13785, 2023. doi: 10.48550/arXiv.2304.13785. [98] YUE Wenxi, ZHANG Jing, HU Kun, et al. SurgicalSAM: Efficient class promptable surgical instrument segmentation[C]. The 38th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 6890–6898. doi: 10.1609/aaai.v38i7.28514. [99] 张云翔, 高圣溥. 边缘资源轻量化需求下深度神经网络双角度并行剪枝方法[J]. 沈阳工业大学学报, 2025, 47(2): 250–257. doi: 10.7688/j.issn.1000-1646.2025.02.15.ZHANG Yunxiang and GAO Shengpu. Dual-angle parallel pruning method for deep neural networks under requirement for lightweight edge resources[J]. Journal of Shenyang University of Technology, 2025, 47(2): 250–257. doi: 10.7688/j.issn.1000-1646.2025.02.15. [100] HAN Song, MAO Huizi, and DALLY W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding[J]. arXiv preprint arXiv: 1510.00149, 2015. doi: 10.48550/arXiv.1510.00149. [101] CHEN Zigeng, FANG Gongfan, MA Xinyin, et al. SlimSAM: 0.1% data makes segment anything slim[C]. The 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2024: 39434–39461. [102] ZHAO Xu, DING Wenchao, AN Yongqi, et al. Fast segment anything[J]. arXiv preprint arXiv: 2306.12156, 2023. doi: 10.48550/arXiv.2306.12156. [103] JOCHER G, CHAURASIA A, and QIU Jing. Yolo by ultralytics[EB/OL]. https://github.com/ultralytics/ultralytics, 2023. [104] BOLYA D, ZHOU Chong, XIAO Fanyi, et al. YOLACT: Real-time instance segmentation[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 9157–9166. doi: 10.1109/ICCV.2019.00925. [105] JI Shunping, WEI Shiqing, and LU Meng. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(1): 574–586. doi: 10.1109/TGRS.2018.2858817. [106] XIONG Yunyang, VARADARAJAN B, WU Lemeng, et al. EfficientSAM: Leveraged masked image pretraining for efficient segment anything[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 16111–16121. doi: 10.1109/CVPR52733.2024.01525. [107] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]. 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248–255. doi: 10.1109/CVPR.2009.5206848. [108] PATHAK D, KRÄHENBÜHL P, DONAHUE J, et al. Context encoders: Feature learning by inpainting[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2536–2544. doi: 10.1109/CVPR.2016.278. [109] VINCENT P, LAROCHELLE H, LAJOIE I, et al. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion[J]. The Journal of Machine Learning Research, 2010, 11: 3371–3408. [110] VARADARAJAN B, SORAN B, IANDOLA F, et al. SqueezeSAM: User friendly mobile interactive segmentation[J]. arXiv preprint arXiv: 2312.06736, 2023. doi: 10.48550/arXiv.2312.06736. [111] RONNEBERGER O, FISCHER P, and BROX T. U-net: Convolutional networks for biomedical image segmentation[C]. The 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 2015: 234–241. doi: 10.1007/978-3-319-24574-4_28. [112] XU Shilin, YUAN Haobo, SHI Qingyu, et al. RMP-SAM: Towards real-time multi-purpose segment anything[J]. arXiv preprint arXiv: 2401.10228, 2024. doi: 10.48550/arXiv.2401.10228. [113] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [114] HUANG Kaiwen, ZHOU Tao, FU Huazhu, et al. Learnable prompting SAM-induced knowledge distillation for semi-supervised medical image segmentation[J]. IEEE Transactions on Medical Imaging, 2025, 44(5): 2295–2306. doi: 10.1109/TMI.2025.3530097. [115] ZHONG Lanfeng, LIAO Xin, ZHANG Shaoting, et al. Semi-supervised pathological image segmentation via cross distillation of multiple attentions[C]. The 26th International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, Canada, 2023: 570–579. doi: 10.1007/978-3-031-43987-2_55. [116] YOU Chenyu, ZHOU Yuan, ZHAO Ruihan, et al. SimCVD: Simple Contrastive Voxel-Wise Representation Distillation for Semi-Supervised Medical Image Segmentation[J].IEEE Transactions on Medical Imaging, 2022, 41(9):2228-2237. doi: 10.1109/TMI.2022.3161829. [117] LI Yunxiang, JING Bowen, LI Zihan, et al. nnSAM: Plug-and-play segment anything model improves nnUNet performance[J]. arXiv preprint arXiv: 2309.16967, 2023. doi: 10.48550/arXiv.2309.16967. [118] ISENSEE F, JAEGER P F, KOHL S A A, et al. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation[J]. Nature Methods, 2021, 18(2): 203–211. doi: 10.1038/s41592-020-01008-z. [119] XU Qing, LI Jiaxuan, HE Xiangjian, et al. ESP-MedSAM: Efficient self-prompting SAM for universal medical image segmentation[J]. arXiv preprint arXiv: 2407.14153v1, 2024. [120] ZHANG Chaoning, HAN Dongshen, ZHENG Sheng, et al. MobileSAMv2: Faster segment anything to everything[J]. arXiv preprint arXiv: 2312.09579, 2023. doi: 10.48550/arXiv.2312.09579. [121] YU Lei. Efficient and robust medical image segmentation using lightweight ViT-tiny based SAM and model quantization[EB/OL]. https://openreview.net/forum?id=clVaaD4FgD, 2024. [122] LIU Zhenhua, WANG Yunhe, HAN Kai, et al. Post-training quantization for vision transformer[C/OL]. The 35th International Conference on Neural Information Processing Systems, 2021: 2152. [123] WANG Ao, CHEN Hui, LIN Zijia, et al. Rep ViT: Revisiting mobile CNN from ViT perspective[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 15909–15920. doi: 10.1109/CVPR52733.2024.01506. [124] ZHANG Zhuoyang, CAI Han, and HAN Song. EfficientViT-SAM: Accelerated segment anything model without performance loss[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, USA, 2024: 7859–7863. doi: 10.1109/CVPRW63382.2024.00782. [125] MIYASHITA D, LEE E H, and MURMANN B. Convolutional neural networks using logarithmic data representation[J]. arXiv preprint arXiv: 1603.01025, 2016. doi: 10.48550/arXiv.1603.01025. [126] LU Haisheng, FU Yujie, ZHANG Fan, et al. Efficient quantization-aware training on segment anything model in medical images and its deployment[M]. MA Jun, ZHOU Yuyin, and WANG Bo. Medical Image Segmentation Foundation Models. CVPR 2024 Challenge: Segment Anything in Medical Images on Laptop. Cham: Springer, 2025: 137–150. doi: 10.1007/978-3-031-81854-7_9. [127] LIU Zechun, CHENG K T, HUANG Dong, et al. Nonuniform-to-uniform quantization: Towards accurate quantization via generalized straight-through estimation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 4942–4952. doi: 10.1109/CVPR52688.2022.00489. [128] PENG Bo, ALCAIDE E, ANTHONY Q, et al. RWKV: Reinventing RNNs for the transformer era[C]. The Findings of the Association for Computational Linguistics, Singapore, 2023: 14048–14077. doi: 10.18653/v1/2023.findings-emnlp.936. [129] SUN Yutao, DONG Li, HUANG Shaohan, et al. Retentive network: A successor to transformer for large language models[J]. arXiv preprint arXiv: 2307.08621, 2023. doi: 10.48550/arXiv.2307.08621. [130] GU A and DAO T. Mamba: Linear-time sequence modeling with selective state spaces[J]. arXiv preprint arXiv: 2312.00752, 2023. doi: 10.48550/arXiv.2312.00752. [131] LIU Ziming, WANG Yixuan, VAIDYA S, et al. KAN: Kolmogorov-Arnold networks[J]. arXiv preprint arXiv: 2404.19756, 2024. doi: 10.48550/arXiv.2404.19756. -




图(10) / 表(3)
计量
- 文章访问数: 1429
- HTML全文浏览量: 1020
- PDF下载量: 157
- 被引次数: 0
 下载:
下载:
