

Design of a CNN Accelerator Based on Systolic Array Collaboration with Inter-Layer Fusion
-
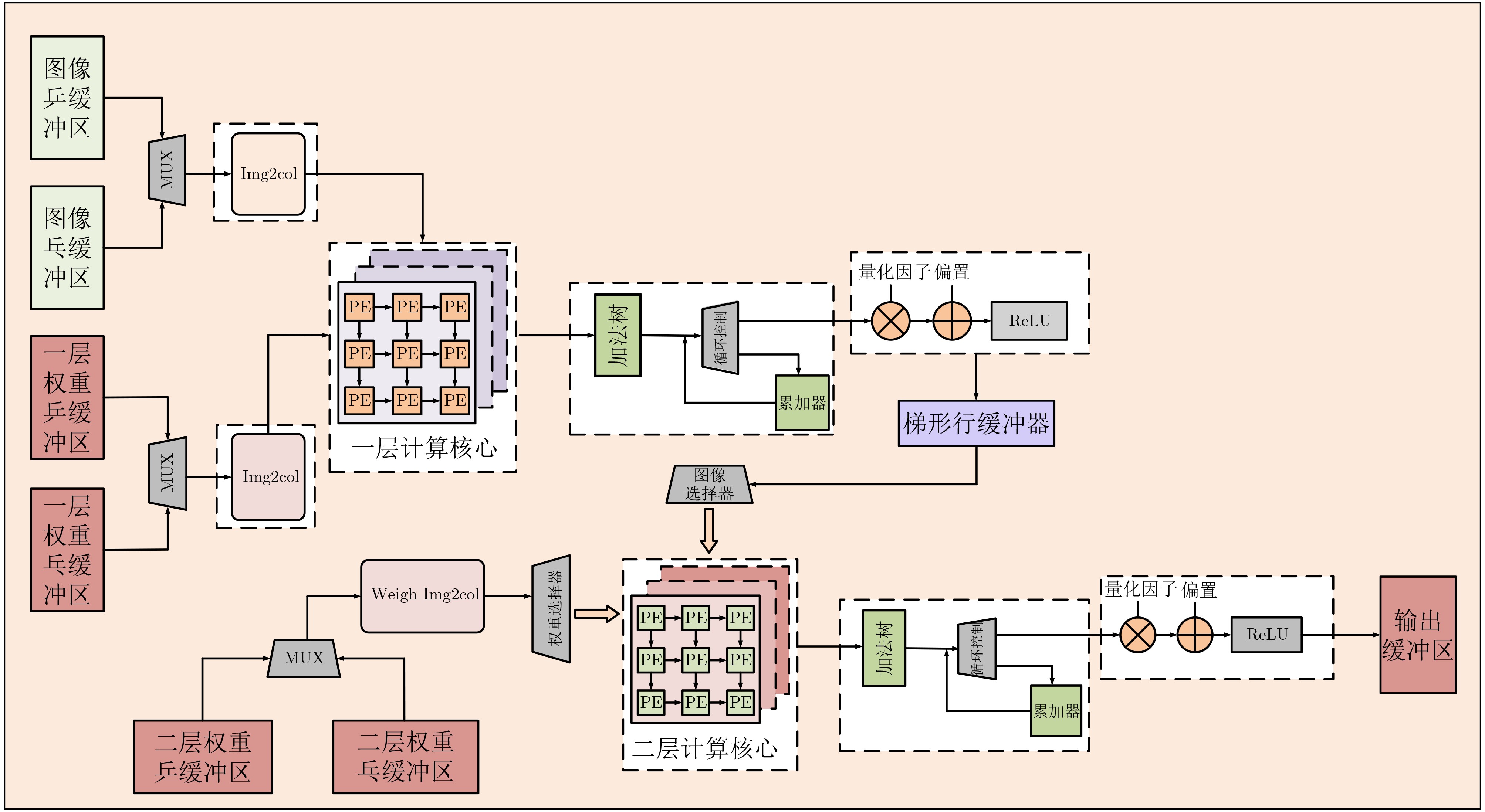
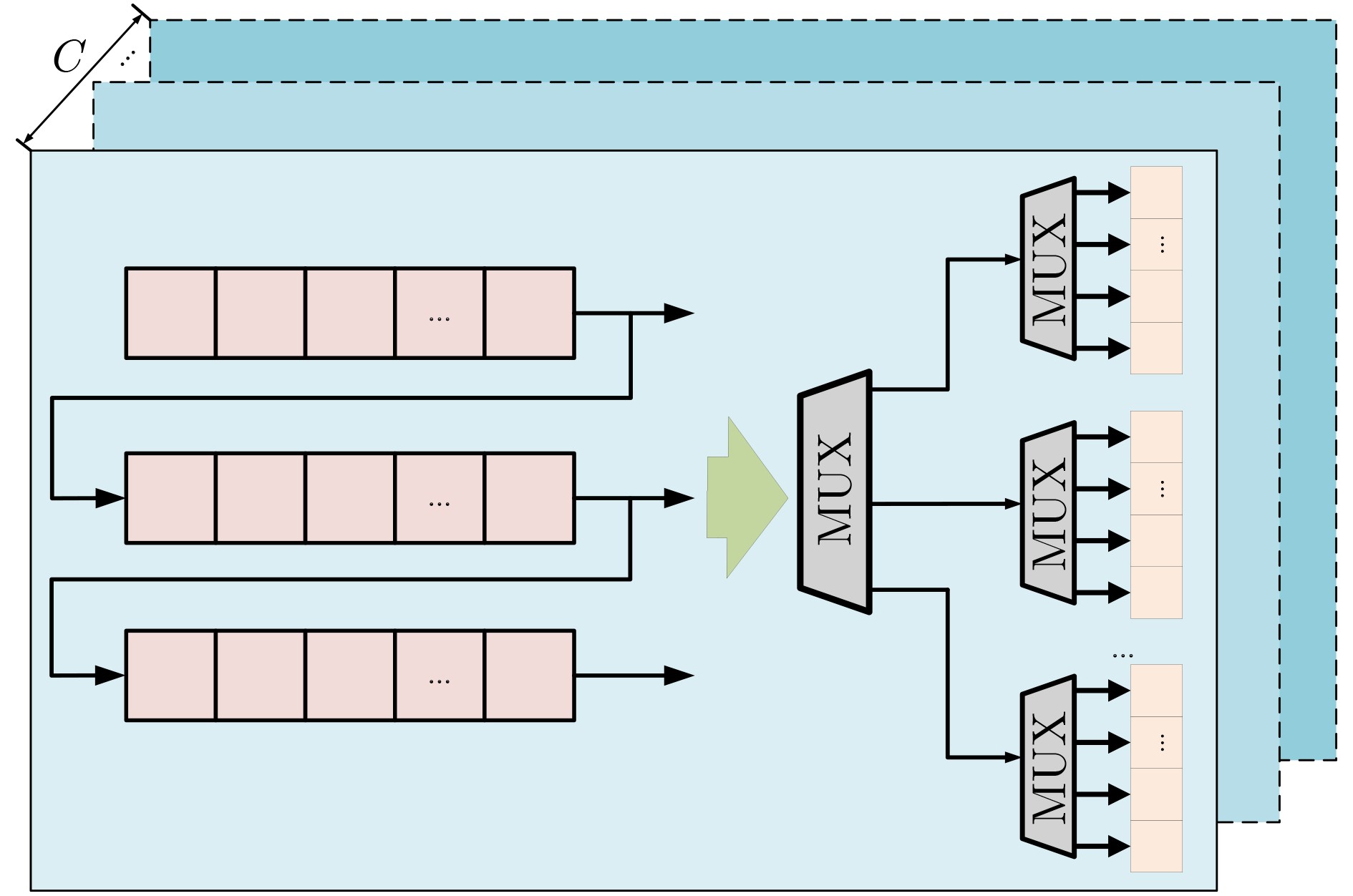
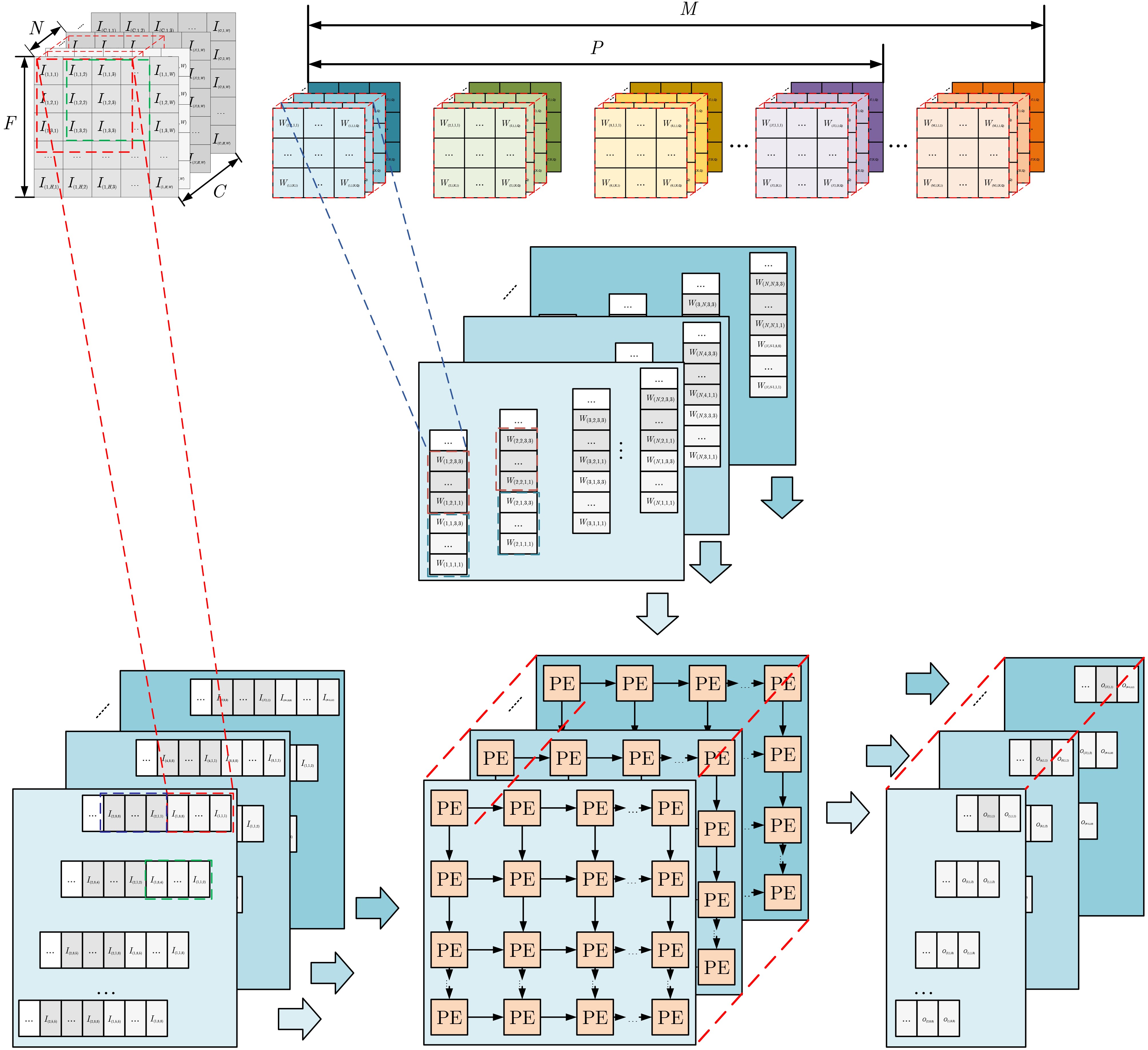
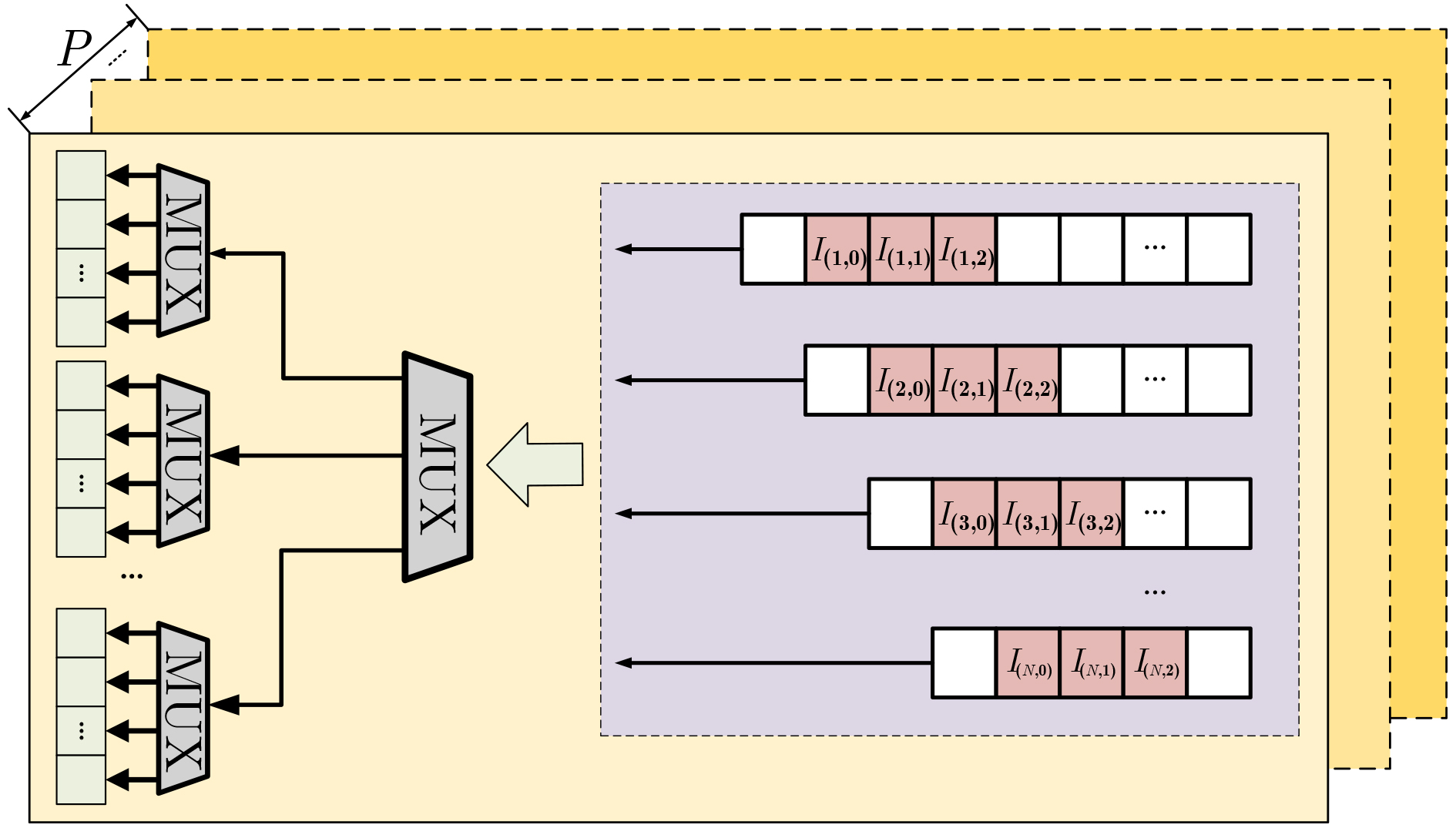
摘要: 卷积神经网络在边缘计算和嵌入式领域的实时应用对硬件加速器的性能和能效提出了严峻挑战。针对基于FPGA的卷积神经网络加速器中普遍存在的数据搬运瓶颈、资源利用率不足和计算单元效率低下等核心问题,该文提出一种脉动阵列协同层融合的混合卷积神经网络加速器架构,将计算密集型邻接层进行深度绑定,在同一级阵列内完成连续计算,减少中间结果向片外存储的频繁存取,降低数据搬运次数和功耗,提升计算速度和整体能效比;设计动态可配置脉动阵列方法,在硬件层面自适应支持多维度矩阵乘法计算,避免为不同规模运算分别部署专用硬件的资源浪费,降低整体FPGA逻辑资源的消耗,提升硬件资源的适应性与灵活性;通过精心规划计算流与控制逻辑,设计流式脉动阵列计算方法,确保脉动阵列计算单元始终保持在高效工作状态,数据在计算引擎中以高度流水化和并行方式持续流动,提升脉动阵列内部处理单元利用率,减少计算空洞期,提升整体吞吐率。实验结果表明,在Xilinx Zynq-
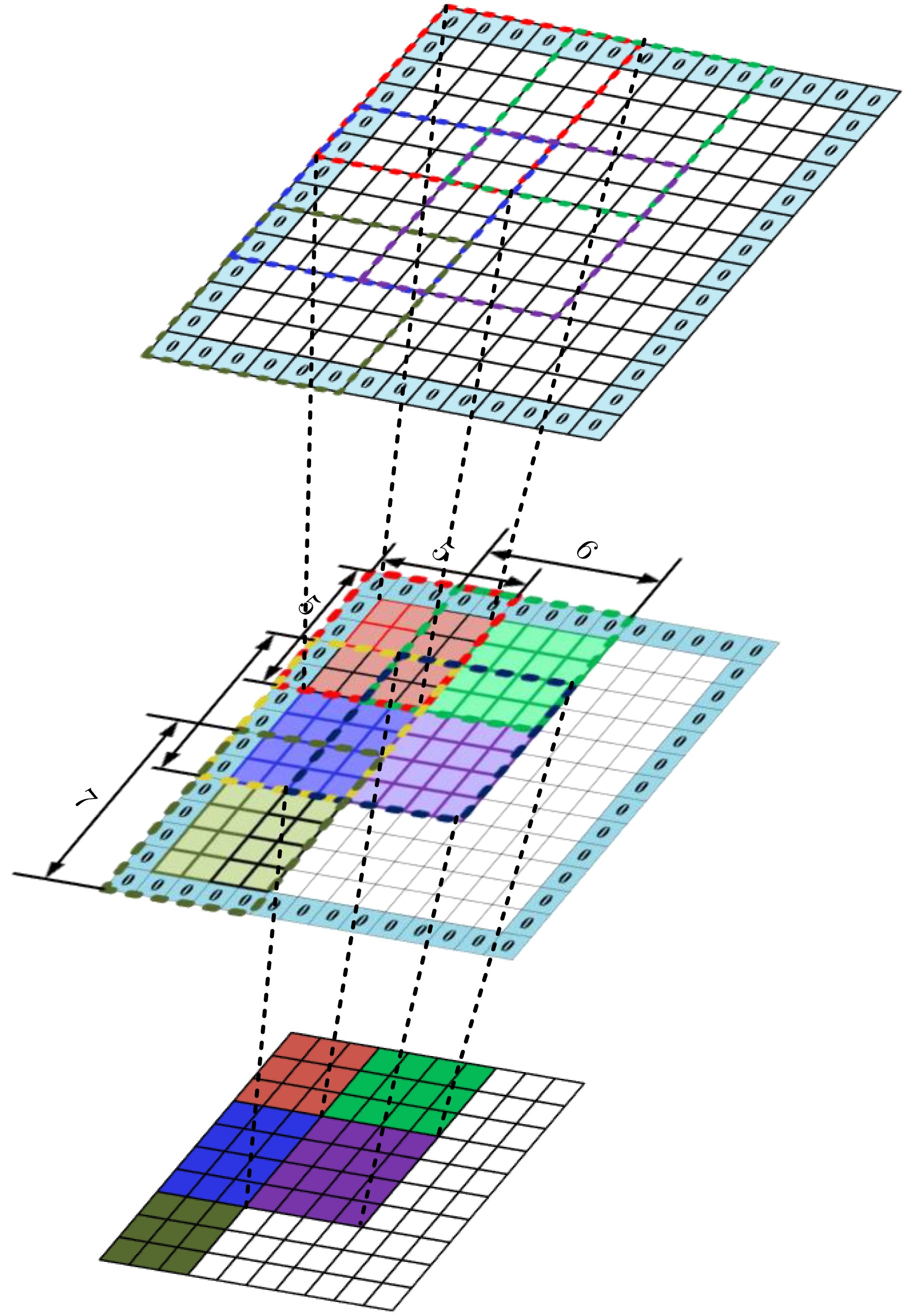
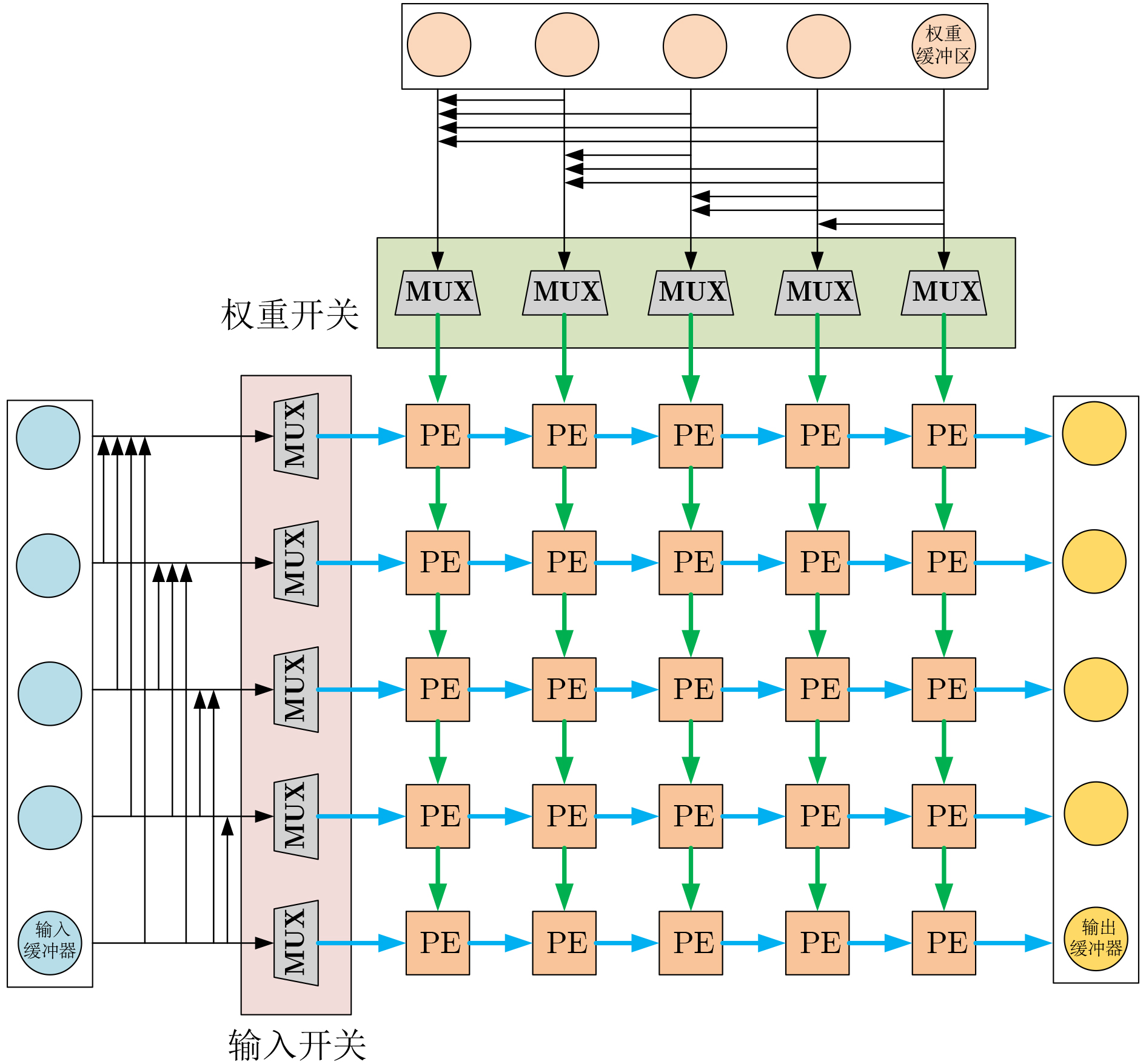
7100 平台上,VGG16, ResNet50以及Yolov8n在所提出加速器上的性能分别达到390.25GOPS, 360.27GOPS和348.08GOPS,为部署高性能、低功耗的CNN推理至资源受限的边缘设备提供了有效的FPGA实现途径。Abstract:Objective With the rapid deployment of deep learning in edge computing, the demand for efficient Convolutional Neural Network (CNN) accelerators continues to increase. Although traditional CPUs and GPUs provide strong computational capability, they incur high power consumption, long latency, and limited scalability in real-time embedded scenarios. FPGA-based accelerators, due to their reconfigurability and parallelism, provide a viable alternative. However, current designs often show low resource utilization, memory access bottlenecks, and difficulty in balancing throughput and energy efficiency. To address these issues, a systolic array–based CNN accelerator with inter-layer fusion optimization is proposed. The design integrates an enhanced memory hierarchy and optimized computation scheduling. Hardware-oriented convolution mapping and lightweight quantization are adopted to improve computational efficiency and reduce resource consumption, while meeting real-time inference requirements for applications such as intelligent surveillance and autonomous driving. Methods This study addresses core challenges in FPGA-based CNN accelerators, including data transfer overhead, insufficient resource utilization, and low processing unit efficiency. A hybrid accelerator architecture based on systolic array–assisted inter-layer fusion is proposed. Computation-intensive adjacent layers are tightly coupled and executed sequentially within a single systolic array, which reduces frequent off-chip memory accesses for intermediate results. This reduces data transfer overhead and power consumption and improves computation speed and overall energy efficiency. A dynamically reconfigurable systolic array is further developed to support multi-dimensional matrix multiplications with varying scales. This design avoids resource waste caused by fixed-function hardware and reduces FPGA logic consumption, thereby improving hardware adaptability and flexibility. A streaming systolic array computation scheme is also introduced through coordinated computation flow and control logic. Processing elements maintain a high-efficiency operating state, and data flows continuously through the computation engine in a pipelined and parallel manner. This improves processing unit utilization, reduces idle cycles, and increases overall throughput. Results and Discussions To determine appropriate quantization precision, experiments are conducted on the MNIST dataset using VGG16 and ResNet50 under fixed-point quantization with 12-bit, 10-bit, 8-bit, and 6-bit precision. As shown in Table 1, inference accuracy decreases significantly when precision falls below 8 bits, indicating that excessively low precision weakens model representational capacity. On the proposed accelerator, VGG16, ResNet50, and YOLOv8n achieve peak computational performances of 390.25 GOPS, 360.27 GOPS, and 348.08 GOPS, respectively. Performance comparisons with FPGA accelerators reported in the literature are summarized in Table 4. Table 5 presents comparisons with CPU and GPU platforms in terms of throughput and energy efficiency. For VGG16, ResNet50, and YOLOv8n, the proposed accelerator delivers throughput that is 1.76×, 3.99×, and 2.61× higher than the corresponding CPU platforms. Energy efficiency improves by 3.1× (VGG16), 2.64× (ResNet50), and 2.96× (YOLOv8n) compared with GPU platforms, demonstrating superior energy utilization. Conclusions A systolic array–assisted inter-layer fusion CNN accelerator architecture is proposed. A theoretical analysis of computational density confirms the performance advantages of the design. To address variation in convolution window sizes in the second layer, a dynamically reconfigurable systolic array method is developed. A streaming systolic array scheme is also implemented to sustain pipelined and parallel data flow within the computation engine. This design reduces idle cycles and improves throughput. Experimental results show that the accelerator achieves high computational performance with minimal loss in inference accuracy. Peak performances of 390.25 GOPS, 360.27 GOPS, and 348.08 GOPS are achieved for VGG16, ResNet50, and YOLOv8n, respectively. Compared with CPU and GPU platforms, the proposed accelerator shows superior energy efficiency and is suitable for resource-constrained and energy-sensitive edge computing scenarios. -
Key words:
- Convolutional Neural Network (CNN) /
- FPGA /
- Systolic array /
- Accelerator
-
表 1 CIFAR100, CIFAR10和MNIST数据集上VGG16和ResNet50网络不同量化位宽分析
数据集 网络模型 准确率 32 float 12 bit 10 bit 8 bit 6 bit CIFAR100 VGG16 70.44 70.45 70.44 69.99 53.33 ResNet50 74.98 74.94 74.91 73.98 40.43 CIFAR10 VGG16 93.78 92.45 91.88 91.23 85.33 ResNet50 94.98 93.94 92.91 92..35 86.43 MNIST VGG16 98.42 97.98 96.95 96.55 93.33 ResNet50 99.35 98.94 98.90 97.38 95.43  下载: 导出CSV
下载: 导出CSV
表 2 部署资源消耗
资源类别 消耗(个) 片内总计(个) 占比(%) LUT 245672 277400 88.56 FF 293028 554800 52.81 BRAM 297 755 39.33 DSP 2000 2020 99.00
下载: 导出CSV
表 4 各算子资源消耗(个)
算子类型 LUT FF BRAM DSP Conv 184293 229438 157.5 1824 Max_pool 12370 10698 20 0 Add 2256 2885 12 96 Cat 2120 2367 16 80 Upsample 1066 832 8 0
下载: 导出CSV
表 5 与相关FPGA加速器的比较结果
文献[6] 文献[7] 本文 文献[7] 文献[8] 文献[9] 本文 文献[14] 文献[15] 本文 模型 YOLOv2 YOLOv4-Tiny YOLOv8n VGG16 VGG16 VGG16 VGG16 ResNet50 ResNet50 ResNet50 计算平台 Pynq-z2 Zynq7020 Zynq7100 Zynq7020 ZC706 ZU15EG Zynq7100 ZC706 XCZU19EG Zynq7100 制程(nm) 28 28 28 28 28 16 28 28 16 28 频率(MHz) 125 200 200 150 150 300 200 200 100 200 数据类型 Int16 Int16 Int8 Int16 Int16 Int8 Int8 Int8 Int8 Int8 DSP(个) 153 220 2000 220 449 3528 2000 840 - 2000 GOP 29.47 6.95 9.16 15.52 15.52 15.52 15.52 4.13 4.13 4.13 算力(GOPS) 54.62 24.25 348.08 48.36 115.21 217.62 390.25 330.2 292 360.27 功耗(W) 2.7 4.58 7.1 3.75 3.8 3.72 7.1 - - 7.1 能效比(GOPS/W) 20.23 5.29 49.02 12.89 30.32 58.36 54.96 119.64 7.81 50.74
下载: 导出CSV
表 6 与CPU和GPU加速器实现对比
CPU GPU 本文 模型 VGG16 ResNet50 YOLOv8n VGG16 ResNet50 YOLOv8n VGG16 ResNet50 YOLOv8n 计算平台 Intel i5-12600kf Nvidia RTX 4060 Xilinx Zynq-7100 制程(nm) 7 5 28 频率 3.05 GHz 2.73 GHz 200 MHz 数据类型 Float32 Float32 Int8 GOP 15.52 4.13 9.16 15.52 4.13 9.16 15.52 4.13 9.16 GOPS 220.69 90.28 132.87 1974.60 2027.83 1832 390.25 360.27 348.08 功耗(W) 74.27 92.14 76.35 111.55 105.88 110.58 7.1 7.1 7.1 能效比(GOPS/W) 2.97 0.97 1.74 17.70 19.15 16.56 54.96 50.74 49.02
下载: 导出CSV
-
[1] SHAO Jie and CHENG Qiyu. E-FCNN for tiny facial expression recognition[J]. Applied Intelligence, 2021, 51(1): 549–559. doi: 10.1007/s10489-020-01855-5. [2] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[C]. The 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, USA, 2012: 1106–1114. [3] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. 3rd International Conference on Learning Representations, San Diego, USA, 2015: 236–238. [4] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Identity mappings in deep residual networks[C]. 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 630–645. doi: 10.1007/978-3-319-46493-0_38. [5] IOFFE S and SZEGEDY C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]. The 32nd International Conference on Machine Learning, Lille, France, 2015: 448–456. [6] BAO Chun, XIE Tao, FENG Wenbin, et al. A power-efficient optimizing framework FPGA accelerator based on Winograd for YOLO[J]. IEEE Access, 2020, 8: 94307–94317. doi: 10.1109/ACCESS.2020.2995330. [7] YE Jinlin, LIU Yuhan, CHEN Haiyong, et al. Edge computing accelerator for real-time defect detection of photovoltaic panel on lightweight FPGAs[J]. IEEE Transactions on Instrumentation and Measurement, 2025, 74: 3001815. doi: 10.1109/TIM.2025.3563001. [8] ZHANG Chen, WANG Xin’an, YONG Shanshan, et al. An energy-efficient convolutional neural network processor architecture based on a systolic array[J]. Applied Sciences, 2022, 12(24): 12633. doi: 10.3390/app122412633. [9] XU Yuhua, LUO Jie, and SUN Wei. Flare: An FPGA-based full precision low power CNN accelerator with reconfigurable structure[J]. Sensors, 2024, 24(7): 2239. doi: 10.3390/s24072239. [10] ZHANG Yonghua, WANG Haojie, and PAN Zhenhua. An efficient CNN accelerator for pattern-compressed sparse neural networks on FPGA[J]. Neurocomputing, 2025, 611: 128700. doi: 10.1016/j.neucom.2024.128700. [11] HU Xianghong, FU Shansen, LIN Yuanmiao, et al. An FPGA-based bit-level weight sparsity and mixed-bit accelerator for neural networks[J]. Journal of Systems Architecture, 2025, 166: 103463. doi: 10.1016/j.sysarc.2025.103463. [12] LI Gang, LIU Zejian, LI Fanrong, et al. Block convolution: Toward memory-efficient inference of large-scale CNNs on FPGA[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2022, 41(5): 1436–1447. doi: 10.1109/TCAD.2021.3082868. [13] PACINI T, RAPUANO E, DINELLI G, et al. A multi-cache system for on-chip memory optimization in FPGA-based CNN accelerators[J]. Electronics, 2021, 10(20): 2514. doi: 10.3390/electronics10202514. [14] OU Yaozhong, YU Weihan, UN K F, et al. A 119.64 GOPs/W FPGA-based ResNet50 mixed-precision accelerator using the dynamic DSP packing[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2024, 71(5): 2554–2558. doi: 10.1109/TCSII.2024.3377356. [15] FUKUSHIMA Y, IIZUKA K, and AMANO H. Parallel implementation of CNN on multi-FPGA cluster[J]. IEICE Transactions on Information and Systems, 2023, E106. D(7): 1198–1208. doi: 10.1587/transinf.2022EDP7175. [16] ALWANI M, CHEN Han, FERDMAN M, et al. Fused-layer CNN accelerators[C]. 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, China, 2016: 1–12. doi: 10.1109/MICRO.2016.7783725. [17] 陈云霁, 李玲, 赵永威, 等. 智能计算系统: 从深度学习到大模型[M]. 2版. 北京: 机械工业出版社, 2024: 256–257.CHEN Yunji, LI Ling, ZHAO Yongwei, et al. AI Computing Systems[M]. 2nd ed. Beijing: China Machine Press, 2024: 256–257. [18] LIU Yanyi, DU Hang, WU Yin, et al. FPGA accelerated deep learning for industrial and engineering applications: Optimal design under resource constraints[J]. Electronics, 2025, 14(4): 703. doi: 10.3390/electronics14040703. -

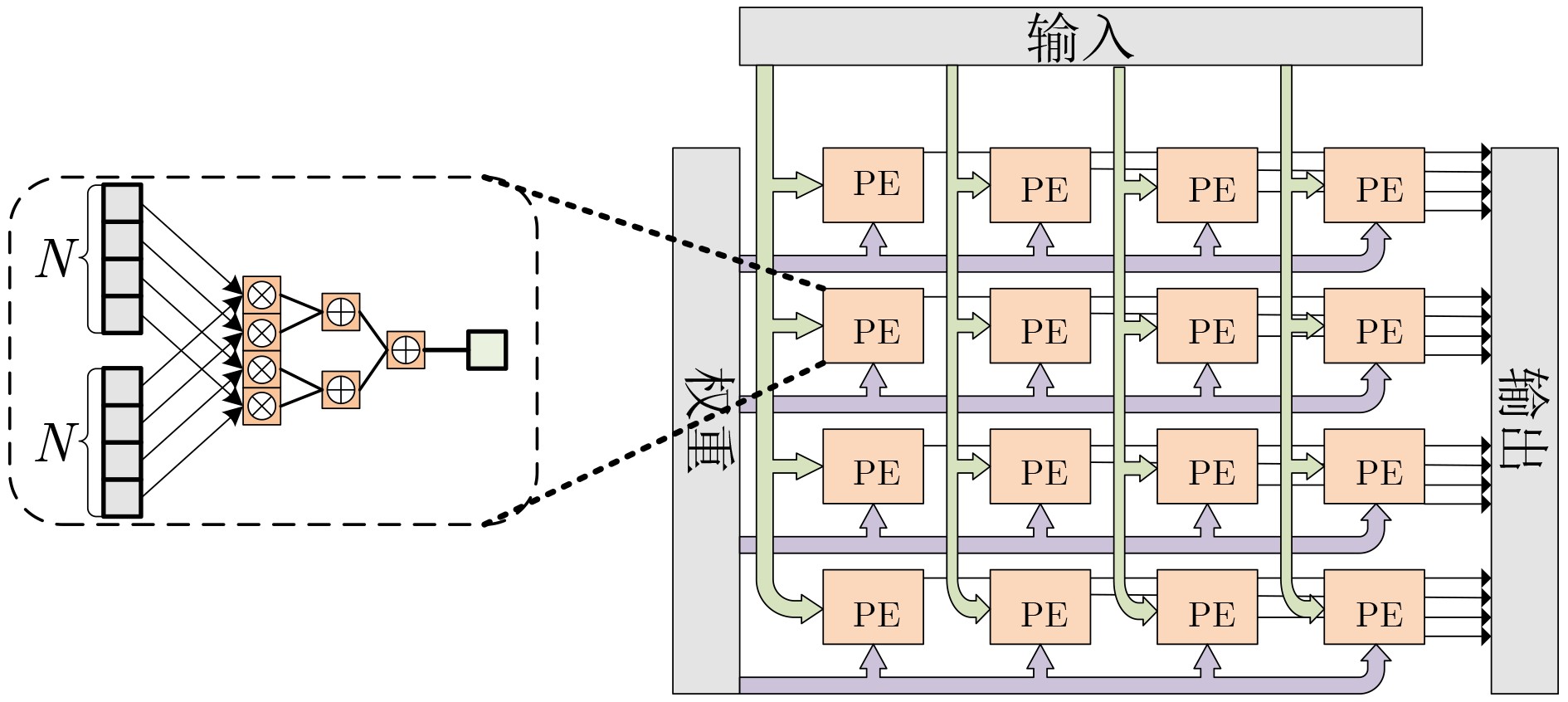
 下载:
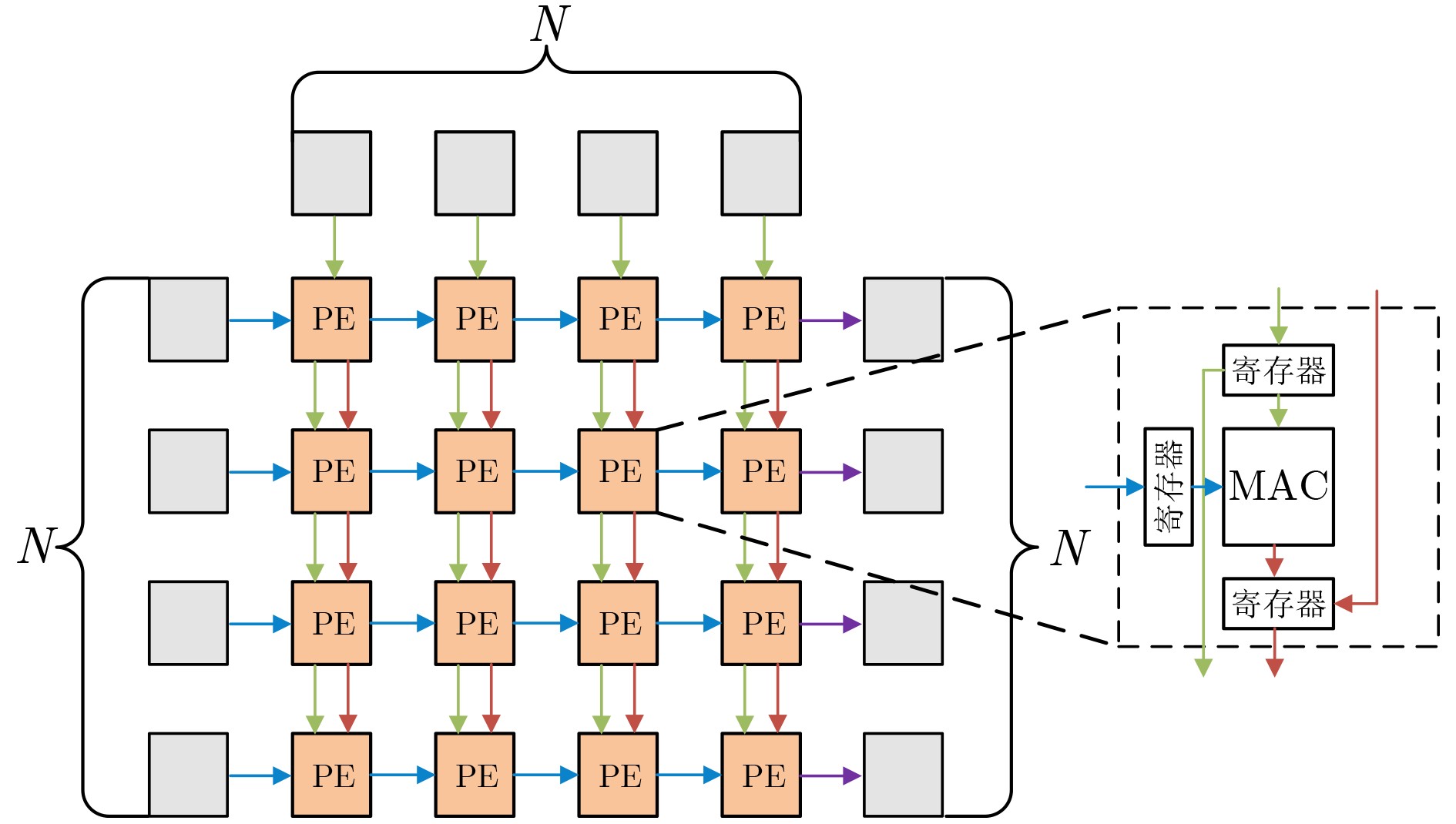
下载:
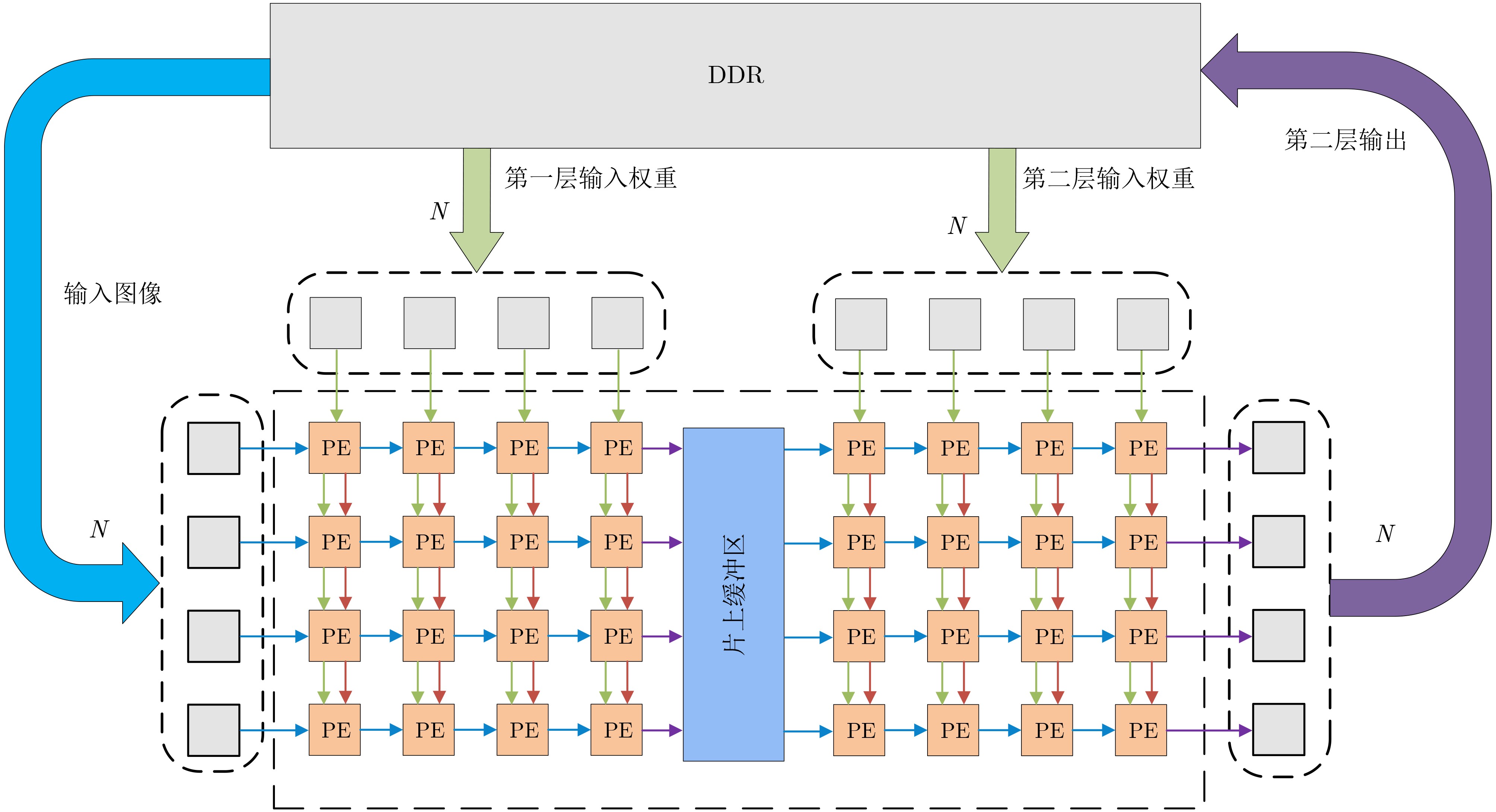
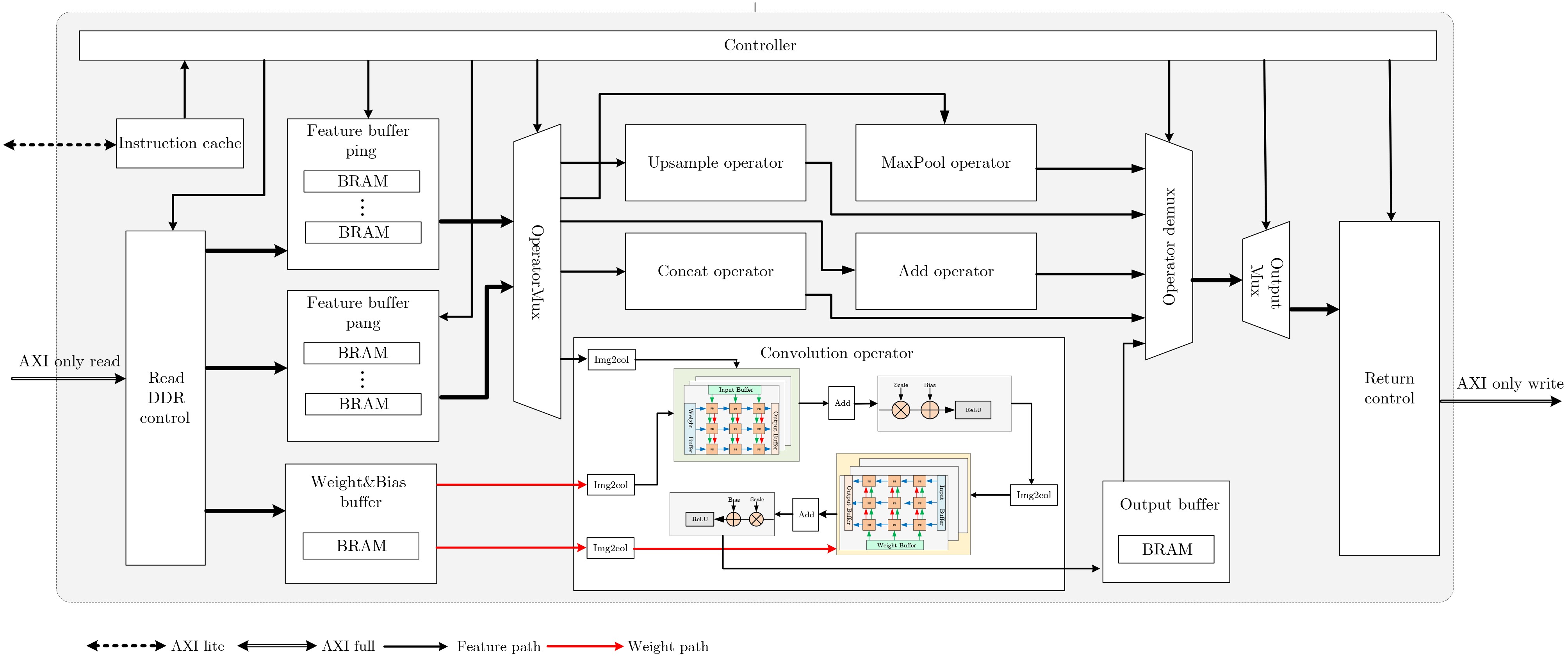



图(11) / 表(6)
计量
- 文章访问数: 739
- HTML全文浏览量: 587
- PDF下载量: 120
- 被引次数: 0
