

DeepSeek-V3.1和ChatGPT-5在结直肠癌肝转移多学科团队诊疗中的应用比较
doi: 10.11999/JEIT250849 cstr: 32379.14.JEIT250849
Comparison of DeepSeek-V3.1 and ChatGPT-5 in Multidisciplinary Team Decision-making for Colorectal Liver Metastases
-
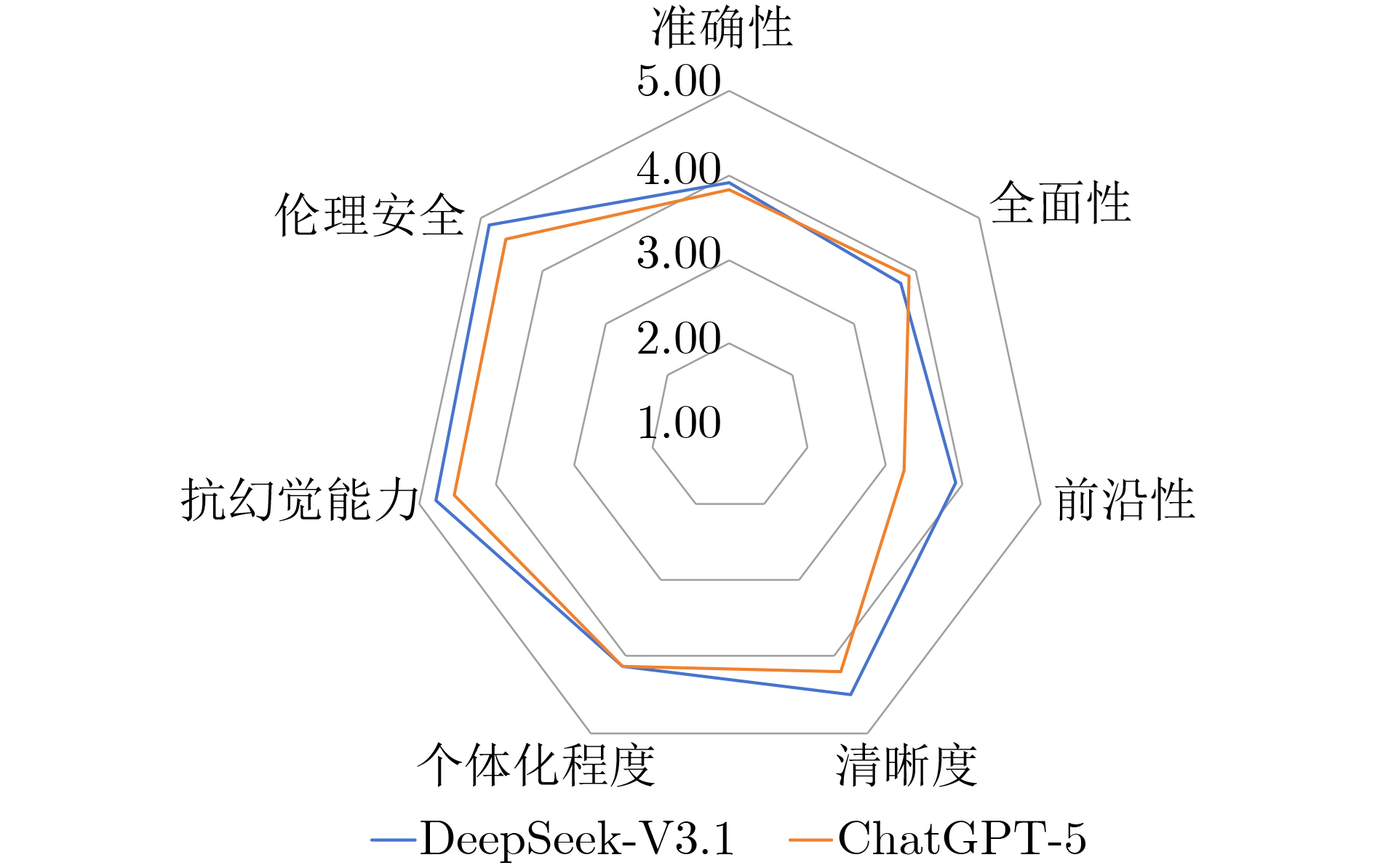
摘要: 该文旨在比较DeepSeek-V3.1与ChatGPT-5在结直肠癌肝转移(CRLM)多学科团队(MDT)决策中的应用表现,评估其与MDT专家意见的一致性,为大语言模型(LLMs)的临床实践提供循证依据与优化方向。该文基于真实世界数据与最新指南,设计了6例涵盖不同肿瘤负荷、基因突变谱和体能状态的虚拟CRLM病例,通过结构化的提示策略,在DeepSeek-V3.1与ChatGPT-5模型中分别生成MDT治疗建议。由4名MDT专家采用7维度5级李克特量表对模型输出进行独立评审。并通过统计学分析对两款模型在各个病例、各项维度和各个学科的表现分别进行比较。2款大语言模型在所有病例中的综合得分均≥ 4.0分(满分5分),表明其在复杂的MDT决策场景下具备可接受的临床效能。在跨维度分析中,两者在清晰度、个体化程度、抗幻觉能力和伦理安全4项上得分较高,而在准确性、全面性和前沿性方面仍有一定提升空间。DeepSeek-V3.1在整体表现(4.27±0.77 vs 4.08±0.86)、前沿性(3.90±0.65 vs 3.24±0.72)与伦理安全(4.87±0.34 vs 4.58±0.65)方面显著优于ChatGPT-5(P<0.05);在放疗领域亦明显领先(4.55±0.67 vs 3.38±0.91, P<0.01)。ChatGPT-5则在胃肠外科领域表现优于DeepSeek-V3.1(4.48±0.67 vs 4.17±0.85, P =0.02)。DeepSeek-V3.1与ChatGPT-5均表现出为CRLM-MDT决策提供可靠建议的良好能力。其中,DeepSeek-V3.1在前沿知识整合、伦理安全性及放射肿瘤学领域展现出显著优势,而ChatGPT-5则在胃肠外科方面表现更优,二者形成优势互补。该文证实了大型语言模型作为“MDT协作者”的可行性,为缩小地域间诊疗水平差距、提升临床决策效率提供了一项便捷可靠的技术方案。
-
关键词:
- 大语言模型 /
- DeepSeek-V3.1 /
- ChatGPT-5 /
- 结直肠癌肝转移 /
- 多学科团队
Abstract:Objective ColoRectal Cancer (CRC) is the third most commonly diagnosed malignancy worldwide. Approximately 25~50% of patients with CRC develop liver metastases during the course of their disease, which increases the disease burden. Although the MultiDisciplinary Team (MDT) model improves survival in ColoRectal Liver Metastases (CRLM), its broader implementation is limited by delayed knowledge updates and regional differences in medical standards. Large Language Models (LLMs) can integrate multimodal data, clinical guidelines, and recent research findings, and can generate structured diagnostic and therapeutic recommendations. These features suggest potential to support MDT-based care. However, the actual effectiveness of LLMs in MDT decision-making for CRLM has not been systematically evaluated. This study assesses the performance of DeepSeek-V3.1 and ChatGPT-5 in supporting MDT decisions for CRLM and examines the consistency of their recommendations with MDT expert consensus. The findings provide evidence-based guidance and identify directions for optimizing LLM applications in clinical practice. Methods Six representative virtual CRLM cases are designed to capture key clinical dimensions, including colorectal tumor recurrence risk, resectability of liver metastases, genetic mutation profiles (e.g., KRAS/BRAF mutations, HER2 amplification status, and microsatellite instability), and patient functional status. Using a structured prompt strategy, MDT treatment recommendations are generated separately by the DeepSeek-V3.1 and ChatGPT-5 models. Independent evaluations are conducted by four MDT specialists from gastrointestinal oncology, gastrointestinal surgery, hepatobiliary surgery, and radiation oncology. The model outputs are scored using a 5-point Likert scale across seven dimensions: accuracy, comprehensiveness, frontier relevance, clarity, individualization, hallucination risk, and ethical safety. Statistical analysis is performed to compare the performance of DeepSeek-V3.1 and ChatGPT-5 across individual cases, evaluation dimensions, and clinical disciplines. Results and Discussions Both LLMs, DeepSeek-V3.1 and ChatGPT-5, show robust performance across all six virtual CRLM cases, with an average overall score of ≥ 4.0 on a 5-point scale. This performance indicates that clinically acceptable decision support is provided within a complex MDT framework. DeepSeek-V3.1 shows superior overall performance compared with ChatGPT-5 (4.27±0.77 vs. 4.08±0.86, P=0.03). Case-by-case analysis shows that DeepSeek-V3.1 performs significantly better in Cases 1, 4, and 6 (P=0.04, P<0.01, and P =0.01, respectively), whereas ChatGPT-5 receives higher scores in Case 2 (P<0.01). No significant differences are observed in Cases 3 and 5 (P=0.12 and P=1.00, respectively), suggesting complementary strengths across clinical scenarios ( Table 3 ). In the multidimensional assessment, both models receive high scores (range: 4.12$ \sim $4.87) in clarity, individualization, hallucination risk, and ethical safety, confirming that readable, patient-tailored, reliable, and ethically sound recommendations are generated. Improvements are still needed in accuracy, comprehensiveness, and frontier relevance (Fig. 1 ). DeepSeek-V3.1 shows a significant advantage in frontier relevance (3.90±0.65 vs. 3.24±0.72, P=0.03) and ethical safety (4.87±0.34 vs. 4.58±0.65, P= 0.03) (Table 4), indicating more effective incorporation of recent evidence and more consistent delivery of ethically robust guidance. For the case with concomitant BRAF V600E and KRAS G12D mutations, DeepSeek-V3.1 accurately references a phase III randomized controlled study published in the New England Journal of Medicine in 2025 and recommends a triple regimen consisting of a BRAF inhibitor + EGFR monoclonal antibody + FOLFOX. By contrast, ChatGPT-5 follows conventional recommendations for RAS/BRAF mutant populations-FOLFOXIRI+bevacizumab-without integrating recent evidence on targeted combination therapy. This difference shows the effect of timely knowledge updates on the clinical value of LLM-generated recommendations. For MSI-H CRLM, ChatGPT-5’s recommendation of “postoperative immunotherapy” is not supported by phase III evidence or existing guidelines. Direct use of such recommendations may lead to overtreatment or ineffective therapy, representing a clear ethical concern and illustrating hallucination risks in LLMs. Discipline-specific analysis shows notable variation. In radiation oncology, DeepSeek-V3.1 provides significantly more precise guidance on treatment timing, dosage, and techniques than ChatGPT-5 (4.55±0.67 vs. 3.38±0.91, P<0.01), demonstrating closer alignment with clinical guidelines. In contrast, ChatGPT-5 performs better in gastrointestinal surgery (4.48±0.67 vs. 4.17 ±0.85, P=0.02), with experts rating its recommendations on surgical timing and resectability as more concise and accurate. No significant differences are identified in gastrointestinal oncology and hepatobiliary surgery (P=0.89 and P=0.14, respectively), indicating comparable performance in these areas (Table 5 ). These findings show a performance bias across medical sub-specialties, demonstrating that LLM effectiveness depends on the distribution and quality of training data.Conclusions Both DeepSeek-V3.1 and ChatGPT-5 demonstrated strong capabilities in providing reliable recommendations for CRLM-MDT decision-making. Specifically, DeepSeek-V3.1 showed notable advantages in integrating cutting-edge knowledge, ensuring ethical safety, and performing in the field of radiation oncology, whereas ChatGPT-5 excelled in gastrointestinal surgery, reflecting a complementary strength between the two models. This study confirms the feasibility of leveraging LLMs as “MDT collaborators”, offering a readily applicable and robust technical solution to bridge regional disparities in clinical expertise and enhance the efficiency of decision-making. However, model hallucination and insufficient evidence grading remain key limitations. Moving forward, mechanisms such as real-world clinical validation, evidence traceability, and reinforcement learning from human feedback are expected to further advance LLMs into more powerful auxiliary tools for CRLM-MDT decision support. -
表 1 病例列表
1 60岁男性,ECOG 1分。1年来间断便血,肠镜示距肛缘4~7 cm溃疡隆起型占位,病理为中分化腺癌。盆腔核磁提示直肠下段占位,累及左侧肛提肌、前列腺,直肠系膜内、直肠上动脉区淋巴结转移,数量≥ 7枚,MRF(+),EMVI 3分。腹部核磁提示肝脏S7, S8可见2枚转移灶,最大2 cm×1.5 cm。胸CT未见转移。基因检测提示KRAS, NRAS, BRAF均为野生型,MSS, HER2无扩增。CEA 12 ng/ml。血常规提示血红蛋白 90 g/L,肝肾功能未见异常。既往有高血压病史。 2
56岁男性,ECOG 2分,1年来排便困难,2天来腹胀伴停止排气排便,肠镜示距肛缘10 cm肿物,环3/4周,肠腔狭窄,取病理活检为低分化腺癌伴印戒细胞癌。基因检测提示KRAS G12c突变,NRAS, BRAF野生型,MSS, HER2无扩增。腹盆CT:直肠上段至乙状结肠可见占位性病变,长约10 cm,病变以上小肠及结肠扩张伴气液平形成;病变旁、肠系膜下动脉根部可见多发肿大淋巴结,数量≥7枚;肝脏可见多发转移灶,数量>10个,较大6 cm×5 cm,侵犯门脉左干。CEA 205 ng/ml。血常规、肝肾功能未见明显异常。3
43岁男性,ECOG 1分,腹痛2个月,肠镜示升结肠占位,约3 cm×4 cm,病理为粘液腺癌。基因检测提示MSI-H, KRAS, NRAS, BRAF均为野生型,HER2无扩增。腹盆CT提示升结肠占位,肠周可见肿大淋巴结,数量约4枚,较大短径1 cm;肝S6可见1枚转移瘤,1.5 cm×1.2 cm。胸CT未见转移。CEA 20 ng/ml。血常规、肝肾功能未见异常。父亲50岁因患直肠癌去世。4
65岁男性,ECOG 2分,3月来大便不畅,肠镜示距肛缘4~10 cm溃疡隆起型占位,病理为中分化腺癌。盆腔核磁:直肠中下段占位,肿瘤累及直肠周围脂肪,直肠系膜区、直肠上动脉走形区、左侧髂内区可见多发枚肿大淋巴结,数量约7枚,MRF(+),EMVI 4分。腹盆CT:左侧髂总血管旁可见转移淋巴结,肝内多发低强化占位。肝脏核磁:肝左叶、右叶见多发转移灶,数量约4枚,较大病灶2.3 cm×1.8 cm。基因检测提示BRAF V600E突变,KRAS G12D突变,NRAS野生型,MSS, HER2无扩增。血常规、肝肾功能无异常。5
56岁女性,ECOG 3分,2个月来肛门坠胀伴便血,2周来皮肤巩膜黄染。血常规无异常,谷丙转氨酶 107 IU/L, 谷草转氨酶120 IU/L,总胆红素 115 umol/L, 直接胆红素 86 umol/L, CEA 106 ng/ml。肠镜示距肛门3~6 cm占位,病理为低分化腺癌,HER2(3+)。盆腔核磁示直肠下段占位,病变累及肛门内、外括约肌,直肠周围系膜内可见肿大淋巴结,数量约4枚,MRF(+),EMVI 1分。腹部CT:肝内弥漫多发转移灶,数量> 10枚,较大5 cm×4.5 cm,肝内胆管扩张。胸CT提示双肺转移。基因检测提示HER2扩增,NRAS, BRAF野生型,MSS。6
35岁男性,ECOG 1分,大便习惯改变8个月,肠镜示距肛缘8~12 cm溃疡型肿物,病理为中分化腺癌。盆腔核磁提示直肠中上段占位,直肠周围系膜内可见条索影,直肠系膜区、直肠上动脉走形区可见肿大淋巴结,数量3枚,MRF(-), EMVI(-)。腹部核磁提示肝S8段可见1枚转移灶,1.7 cm×1.4 cm。胸CT未见转移征象。CEA 6 ng/ml。基因检测提示KRAS, NRAS, BRAF均为野生型,MSS, HER2无扩增。血常规、肝肾功能正常。 下载: 导出CSV
下载: 导出CSV
表 2 李克特量表的7个维度问题和评分标准
编号 维度 问题 评分标准 1 准确性 模型提出的治疗决策是否符合当前的临床指南或最佳实践? 1 = 完全不符合,5 = 完全符合 2 全面性 模型的最终建议是否合理整合了肿瘤内科、胃肠外科、肝胆外科、
放疗科的意见,且看起来符合您所在领域的最佳实践?1 = 完全不符合,5 = 完全符合 3 前沿性 模型的决策是否充分结合了您所在领域的最新的临床研究成果,
体现了循证医学的理念?1 = 完全未体现,5 = 完全体现 4 清晰度 模型关于您专业的治疗建议在整体上是否清晰易懂,并且能够通过有效的
解释向患者或其他临床医生进行传达?1 = 非常不清晰,5 = 非常清晰 5 个体化程度 模型关于您专业的治疗决策是否考虑了患者的具体情况
(如年龄、分子特征、体能状态、合并症、患者意愿等)?1 = 完全未考虑,5 = 完全考虑 6 抗幻觉能力 在模型提出的关于您专业的治疗方案中,是否存在可能导致患者或医生产生
幻觉的建议?例如,是否提出了不切实际或不符合当前医学认知的治疗方案?1 = 存在严重幻觉风险,
5 = 完全不存在幻觉风险7 伦理安全 模型提供的关于您专业的治疗建议是否会违反伦理标准,
有可能提供对患者有害的信息或建议?1 = 存在严重伦理风险,
5 = 完全符合伦理标准
下载: 导出CSV
表 3 2个大语言模型在6个病例中的评分比较
病例 DeepSeek-V3.1
(N = 28)ChatGPT-5
(N = 28)P值 1 4.46 ± 0.64 4.00 ± 0.94 0.04* 2 3.36 ± 0.87 4.43 ± 0.50 < 0.01* 3 4.25 ± 0.80 3.79 ± 1.10 0.12 4 4.39 ± 0.69 3.75 ± 0.93 < 0.01* 5 4.36 ± 0.49 4.36 ± 0.68 1.00 6 4.50 ± 0.79 4.18 ± 0.72 0.01* 6个病例的平均值 4.27 ± 0.77 4.08 ± 0.86 0.03* * P < 0.05
下载: 导出CSV
表 4 2个大语言模型在7个维度中的评分比较
维度 DeepSeek-V3.1(N=24) ChatGPT-5(N=24) P值 准确性 3.92 ± 0.83 3.83 ± 0.87 0.78 全面性 3.75 ± 0.74 3.88 ± 0.85 0.62 前沿性 3.90 ± 0.65 3.24 ± 0.72 0.03* 清晰度 4.50 ± 0.66 4.21 ± 0.72 0.13 个体化程度 4.12 ± 0.80 4.12 ± 0.74 1.00 抗幻觉能力 4.79 ± 0.41 4.54 ± 0.93 0.27 伦理安全 4.87 ± 0.34 4.58 ± 0.65 0.03* * P < 0.05
下载: 导出CSV
表 5 2个大语言模型在4个不同学科中的评分比较
学科 DeepSeek-V3.1
(N = 42)ChatGPT-5
(N = 42)P值 消化肿瘤内科 4.24 ± 0.79 4.21 ± 0.81 0.89 胃肠外科 4.17 ± 0.85 4.48 ± 0.67 0.02* 肝胆外科 4.12 ± 0.71 4.26 ± 0.63 0.14 放疗科 4.55 ± 0.67 3.38 ± 0.91 < 0.01* * P < 0.05
下载: 导出CSV
-
[1] SUNG H, FERLAY J, SIEGEL R L, et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries[J]. CA: A Cancer Journal for Clinicians, 2021, 71(3): 209–249. doi: 10.3322/caac.21660. [2] MARTIN J, PETRILLO A, SMYTH E C, et al. Colorectal liver metastases: Current management and future perspectives[J]. World Journal of Clinical Oncology, 2020, 11(10): 761–808. doi: 10.5306/wjco.v11.i10.761. [3] REBOUX N, JOOSTE V, GOUNGOUNGA J, et al. Incidence and survival in synchronous and metachronous liver metastases from colorectal cancer[J]. JAMA Network Open, 2022, 5(10): e2236666. doi: 10.1001/jamanetworkopen.2022.36666. [4] VALDERRAMA-TREVIÑO A I, BARRERA-MERA B, CEBALLOS-VILLALVA J C, et al. Hepatic metastasis from colorectal cancer[J]. Euroasian Journal of Hepato-Gastroenterology, 2017, 7(2): 166–175. doi: 10.5005/jp-journals-10018-1241. [5] ZEINEDDINE F A, ZEINEDDINE M A, YOUSEF A, et al. Survival improvement for patients with metastatic colorectal cancer over twenty years[J]. npj Precision Oncology, 2023, 7(1): 16. doi: 10.1038/s41698-023-00353-4. [6] LAN Y T, JIANG J K, CHANG S C, et al. Improved outcomes of colorectal cancer patients with liver metastases in the era of the multidisciplinary teams[J]. International Journal of Colorectal Disease, 2016, 31(2): 403–411. doi: 10.1007/s00384-015-2459-4. [7] TOPOL E J. High-performance medicine: The convergence of human and artificial intelligence[J]. Nature Medicine, 2019, 25(1): 44–56. doi: 10.1038/s41591-018-0300-7. [8] THIRUNAVUKARASU A J, TING D S J, ELANGOVAN K, et al. Large language models in medicine[J]. Nature Medicine, 2023, 29(8): 1930–1940. doi: 10.1038/s41591-023-02448-8. [9] SINGHAL K, AZIZI S, TU Tao, et al. Large language models encode clinical knowledge[J]. Nature, 2023, 620(7972): 172–180. doi: 10.1038/s41586-023-06291-2. [10] MESKÓ B and GÖRÖG M. A short guide for medical professionals in the era of artificial intelligence[J]. npj Digital Medicine, 2020, 3: 126. doi: 10.1038/s41746-020-00333-z. [11] PARK Y E and CHAE H. The fidelity of artificial intelligence to multidisciplinary tumor board recommendations for patients with gastric cancer: A retrospective study[J]. Journal of Gastrointestinal Cancer, 2024, 55(1): 365–372. doi: 10.1007/s12029-023-00967-8. [12] HORESH N, EMILE S H, GUPTA S, et al. Comparing the management recommendations of large language model and colorectal cancer multidisciplinary team: A pilot study[J]. Diseases of the Colon & Rectum, 2025, 68(1): 41–47. doi: 10.1097/DCR.0000000000003504. [13] CHOO J M, RYU H S, KIM J S, et al. Conversational artificial intelligence (chatGPT™) in the management of complex colorectal cancer patients: Early experience[J]. ANZ Journal of Surgery, 2024, 94(3): 356–361. doi: 10.1111/ans.18749. [14] UMIHANIC S, OSMANOVIC H, SELAK N, et al. Evaluating the concordance between ChatGPT and multidisciplinary teams in breast cancer treatment planning: A study from Bosnia and Herzegovina[J]. Journal of Clinical Medicine, 2025, 14(18): 6460. doi: 10.3390/jcm14186460. [15] AMMO T, GUILLAUME V G J, HOFMANN U K, et al. Evaluating ChatGPT-4o as a decision support tool in multidisciplinary sarcoma tumor boards: Heterogeneous performance across various specialties[J]. Frontiers in Oncology, 2025, 14: 1526288. doi: 10.3389/fonc.2024.1526288. [16] LEE J T, LI V C S, WU J J, et al. Evaluation of performance of generative large language models for stroke care[J]. npj Digital Medicine, 2025, 8(1): 481. doi: 10.1038/s41746-025-01830-9. [17] ELEZ E, YOSHINO T, SHEN Lin, et al. Encorafenib, cetuximab, and mFOLFOX6 in BRAF-mutated colorectal cancer[J]. New England Journal of Medicine, 2025, 392(24): 2425–2437. doi: 10.1056/NEJMoa2501912. [18] OMAR M, SORIN V, COLLINS J D, et al. Multi-model assurance analysis showing large language models are highly vulnerable to adversarial hallucination attacks during clinical decision support[J]. Communications Medicine, 2025, 5(1): 330. doi: 10.1038/s43856-025-01021-3. [19] AHN S. A guide to evade hallucinations and maintain reliability when using large language models for medical research: A narrative review[J]. Annals of Pediatric Endocrinology & Metabolism, 2025, 30(3): 115–118. doi: 10.6065/apem.2448278.139. [20] LIU Jiaxi. ChatGPT: Perspectives from human-computer interaction and psychology[J]. Frontiers in Artificial Intelligence, 2024, 7: 1418869. doi: 10.3389/frai.2024.1418869. [21] RAJARAM A, LI H, HOLODINSKY J K, et al. Opening the black box: Challenges and opportunities regarding interpretability of artificial intelligence in emergency medicine[J]. Canadian Journal of Emergency Medicine, 2025, 27(2): 83–86. doi: 10.1007/s43678-024-00827-9. -

 下载:
下载:


图(1) / 表(5)
计量
- 文章访问数: 521
- HTML全文浏览量: 305
- PDF下载量: 54
- 被引次数: 0
