

Multi-Scale Deformable Alignment-Aware Bidirectional Gated Feature Aggregation for Stereoscopic Image Generation from a Single Image
-
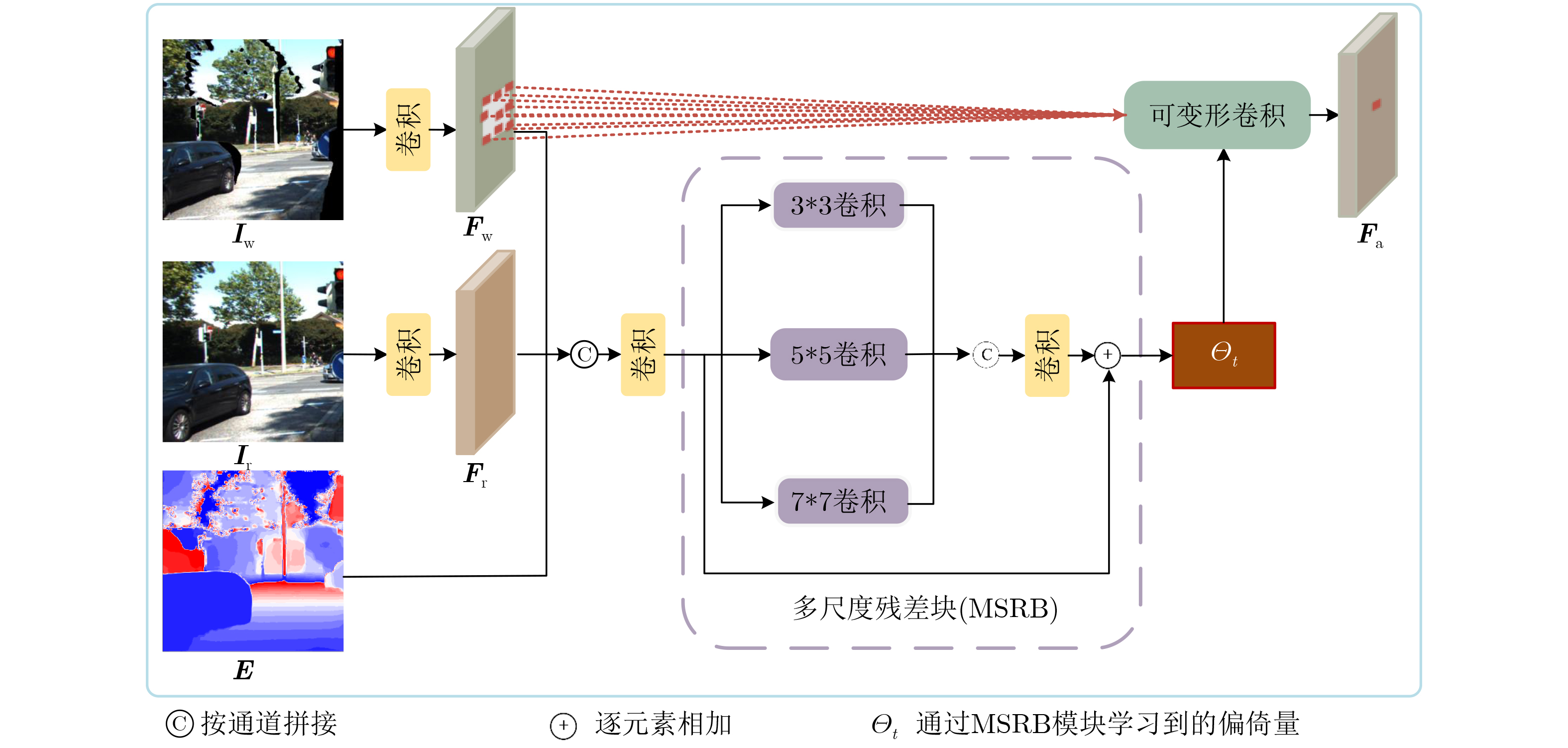
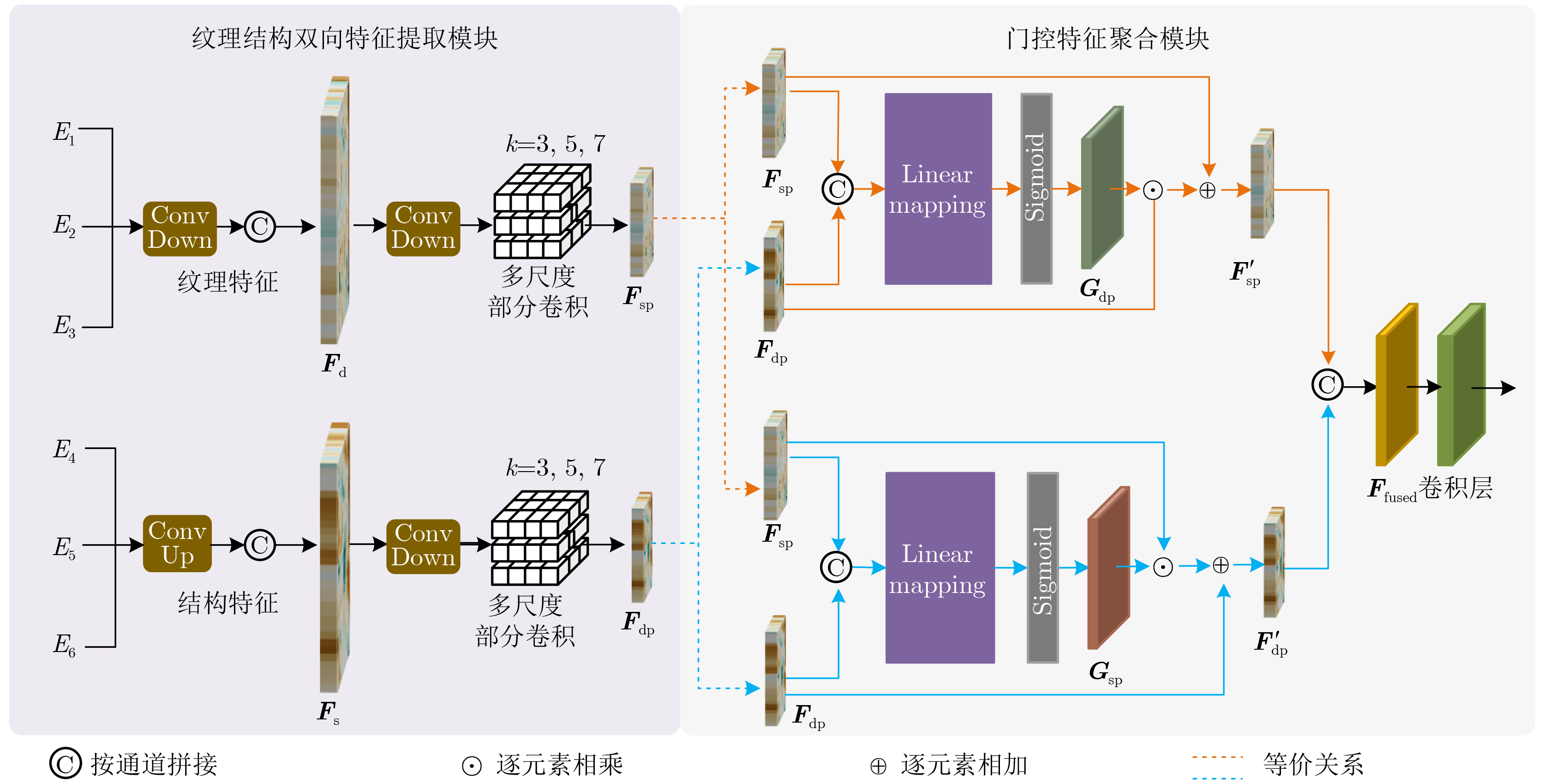
摘要: 单目视角下的立体图像生成通常依赖深度真值作为先验,易存在几何错位、遮挡伪影及纹理模糊等问题。为此,该文提出一种多尺度可变形对齐感知的双向门控特征聚合立体图像生成网络,在无需深度真值监督的条件下实现端到端训练。该方法引入多尺度可变形对齐模块(MSDA)根据内容自适应调整采样位置,在不同尺度上自适应对齐源特征与目标特征,缓解固定卷积难以适应几何变形和视差变化引起的错位问题;此外,构建纹理结构双向门控特征聚合模块(Bi-GFA),提出一种约束网络浅层学习纹理、深层建模结构的特征解耦策略,实现纹理与结构信息的动态互补与高效融合;同时,设计可学习的对齐引导损失(LAG),进一步提升特征对齐精度与语义一致性。在KITTI, MPEG-FTV及多视点深度视频序列数据集上的实验结果表明,所提方法在结构还原性、纹理质量及视角一致性等方面优于现有先进方法。Abstract:
Objective The generation of stereoscopic images from a single image usually relies on depth as a prior, which often leads to geometric misalignment, occlusion artifacts, and texture blurring. Recent studies have therefore shifted toward end-to-end learning of alignment transformation and rendering within the image or feature domain. By adopting a content-based feature transformation and alignment mechanism, high-quality novel images can be generated without explicit geometric information. However, three main challenges remain. First, fixed convolution has limited ability to model large-scale geometric and disparity changes, which restricts feature alignment performance. Second, texture and structural information are tightly coupled in network representations, and hierarchical modeling and dynamic fusion mechanisms are often absent. This limitation makes it difficult to preserve fine details while maintaining semantic consistency. Third, existing supervision strategies mainly focus on reconstruction errors and provide limited constraints on the intermediate alignment process, which reduces the efficiency of cross-view feature consistency learning. To address these challenges, a Multi-Scale Deformable Alignment-Aware Bidirectional Gated Feature Aggregation network is proposed for stereoscopic image generation from a single image. Methods First, to address image misalignment and distortion caused by the inability of fixed convolution to adapt to geometric deformation and disparity changes, a Multi-Scale Deformable Alignment (MSDA) module is proposed. This module employs multi-scale deformable convolution to adaptively adjust sampling positions based on image content, enabling effective alignment between source and target features across different scales. Second, to address texture blurring and structural distortion in synthesized images, a feature decoupling strategy is adopted to guide shallow layers to learn texture information and deeper layers to model structural information. A Texture-Structure Bidirectional Gating Feature Aggregation (Bi-GFA) module is designed to achieve dynamic complementarity and efficient fusion of texture and structural features. Third, to improve cross-view feature alignment accuracy, a Learnable Alignment-Guided Loss (LAG) function is proposed. This loss guides the alignment network to adaptively refine the offset field at the feature level, thereby improving the fidelity and semantic consistency of the synthesized images. Results and Discussions This study focuses on scene-level image synthesis from a single image. Quantitative results show that the proposed method performs better than all compared methods in terms of PSNR, SSIM, and LPIPS. The method also maintains stable performance across different dataset sizes and scene complexities, indicating strong generalization ability and robustness ( Tab. 1 andTab. 2 ). Qualitative comparisons indicate that the generated images are visually closest to the ground-truth images and exhibit high overall sharpness and detail fidelity. In the outdoor KITTI dataset, pixel alignment errors of foreground objects are effectively reduced (Fig. 4 ). In indoor scenes, facial and hair textures are clearly reconstructed. High-frequency regions, such as champagne towers and balloon edges, present sharp contours and accurate color reproduction without visible artifacts or blurring. Both global illumination and local structural details are well preserved, producing high perceptual quality (Fig. 5 ). Ablation experiments further confirm the effectiveness of the proposed MSDA, Bi-GFA, and LAG modules (Tab. 3 ).Conclusions A Multi-Scale Deformable Alignment-Aware Bidirectional Gated Feature Aggregation network is proposed to address strong dependence on ground-truth depth, geometric misalignment and distortion, texture blurring, and structural distortion in stereoscopic image generation from a monocular image. The MSDA module improves the flexibility and accuracy of cross-view feature alignment. The Texture-Structure Bi-GFA module enables complementary fusion of texture details and structural information. The LAG further refines offset field estimation and improves the fidelity and semantic consistency of the synthesized images. Experimental results show that the proposed method performs better than existing advanced methods in structural reconstruction, texture clarity, and viewpoint consistency, while maintaining strong generalization ability and robustness. Future work will examine the effect of different depth estimation strategies on system performance and investigate more efficient network architectures and model compression methods to reduce computational cost and support real-time stereoscopic image generation. -
表 2 在MPEG-FTV及多视点深度视频序列户内数据集设置下对比实验结果
对比方法 N MPEG-FTV-Dog MPEG-FTV-Champagne Akko & Kayo PSNR (dB) SSIM LPIPS PSNR (dB) SSIM LPIPS PSNR (dB) SSIM LPIPS Xie等人[7] NA 16.581 0.223 0.318 18.678 0.712 0.277 19.852 0.662 0.119 Tucker等人[11] 32 19.469 0.772 0.086 19.346 0.884 0.102 21.256 0.642 0.090 Zhang等人[6] NA 20.752 0.793 0.044 19.796 0.886 0.077 25.696 0.881 0.082 本文 NA 21.881 0.886 0.027 22.838 0.896 0.059 26.827 0.902 0.073 对比方法 N Rena MPEG-FTV-Kendo MPEG-FTV-Balloon PSNR (dB) SSIM LPIPS PSNR (dB) SSIM LPIPS PSNR (dB) SSIM LPIPS Xie等人[7] NA 27.109 0.875 0.099 22.008 0.803 0.177 21.146 0.705 0.213 Tucker等人[11] 32 19.147 0.380 0.221 23.783 0.882 0.042 24.539 0.794 0.066 Zhang等人[6] NA 30.426 0.956 0.092 22.869 0.910 0.063 23.685 0.871 0.095 本文 NA 31.259 0.961 0.080 25.828 0.952 0.019 25.371 0.941 0.018  下载: 导出CSV
下载: 导出CSV
表 3 在KTTTI户外数据集以及MPEG-FTV-Dog户内数据集下的消融实验结果
组件 MSDA Bi-GFA $ \mathcal{L}_{\mathrm{LAG}} $ KITTI MPEG-FTV-Dog PSNR (dB) SSIM LPIPS PSNR (dB) SSIM LPIPS w/o ALL 15.593 0.651 0.207 15.111 0.603 0.198 w/o MSDA √ √ 20.894 0.788 0.139 19.564 0.735 0.156 w/o Bi-GFA √ √ 21.698 0.809 0.123 20.555 0.791 0.132 w/o $ \mathcal{L}_{\mathrm{LAG}} $ √ √ 22.838 0.857 0.118 21.002 0.814 0.029 本文 √ √ √ 22.968 0.863 0.101 21.881 0.886 0.027
下载: 导出CSV
-
[1] SHEN Qiuhong, WU Zike, YI Xuanyu, et al. Gamba: Marry Gaussian splatting with mamba for single-view 3D reconstruction[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025: 1–14. doi: 10.1109/TPAMI.2025.3569596. [2] JIANG Lei, SCHAEFER G, and MENG Qinggang. Multi-scale feature fusion for single image novel view synthesis[J]. Neurocomputing, 2024, 599: 128081. doi: 10.1016/j.neucom.2024.128081. [3] WILES O, GKIOXARI G, SZELISKI R, et al. SynSin: End-to-end view synthesis from a single image[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 7465–7475. doi: 10.1109/CVPR42600.2020.00749. [4] 周洋, 蔡毛毛, 黄晓峰, 等. 结合上下文特征融合的虚拟视点图像空洞填充[J]. 电子与信息学报, 2024, 46(4): 1479–1487. doi: 10.11999/JEIT230181.ZHOU Yang, CAI Maomao, HUANG Xiaofeng, et al. Hole filling for virtual view synthesized image by combining with contextual feature fusion[J]. Journal of Electronics & Information Technology, 2024, 46(4): 1479–1487. doi: 10.11999/JEIT230181. [5] ZHENG Chuanxia, CHAM T J, and CAI Jianfei. Pluralistic image completion[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 1438–1447. doi: 10.1109/CVPR.2019.00153. [6] ZHANG Chunlan, LIN Chunyu, LIAO Kang, et al. As-deformable-as-possible single-image-based view synthesis without depth prior[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(8): 3989–4001. doi: 10.1109/TCSVT.2023.3237815. [7] XIE Junyuan, GIRSHICK R, and FARHADI A. Deep3D: Fully automatic 2D-to-3D video conversion with deep convolutional neural networks[C]. 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 842–857. doi: 10.1007/978-3-319-46493-0_51. [8] ZHOU Tinghui, TULSIANI S, SUN Weilun, et al. View synthesis by appearance flow[C]. 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 286–301. doi: 10.1007/978-3-319-46493-0_18. [9] ZHANG Chunlan, LIN Chunyu, LIAO Kang, et al. SivsFormer: Parallax-aware transformers for single-image-based view synthesis[C]. 2022 IEEE Conference on Virtual Reality and 3D User Interfaces, Christchurch, New Zealand, 2022: 47–56. doi: 10.1109/VR51125.2022.00022. [10] FLYNN J, NEULANDER I, PHILBIN J, et al. Deep stereo: Learning to predict new views from the world’s imagery[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 5515–5524. doi: 10.1109/CVPR.2016.595. [11] TUCKER R and SNAVELY N. Single-view view synthesis with multiplane images[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 548–557. doi: 10.1109/CVPR42600.2020.00063. [12] LI Jiaxin, FENG Zijian, SHE Qi, et al. MINE: Towards continuous depth MPI with NeRF for novel view synthesis[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 12558–12568. doi: 10.1109/ICCV48922.2021.01235. [13] TULSIANI S, TUCKER R, and SNAVELY N. Layer-structured 3D scene inference via view synthesis[C]. Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 2018: 311–327. doi: 10.1007/978-3-030-01234-2_19. [14] MILDENHALL B, SRINIVASAN P P, TANCIK M, et al. NeRF: Representing scenes as neural radiance fields for view synthesis[J]. Communications of the ACM, 2022, 65(1): 99–106. doi: 10.1145/3503250. [15] 孙文博, 高智, 张依晨, 等. 稀疏视角下基于几何一致性的神经辐射场卫星城市场景渲染与数字表面模型生成[J]. 电子与信息学报, 2025, 47(6): 1679–1689. doi: 10.11999/JEIT240898.SUN Wenbo, GAO Zhi, ZHANG Yichen, et al. Geometrically consistent based neural radiance field for satellite city scene rendering and digital surface model generation in sparse viewpoints[J]. Journal of Electronics & Information Technology, 2025, 47(6): 1679–1689. doi: 10.11999/JEIT240898. [16] LUO Dengyan, XIANG Yanping, WANG Hu, et al. Deformable Feature Alignment and Refinement for moving infrared small target detection[J]. Pattern Recognition, 2026, 169: 111894. doi: 10.1016/j.patcog.2025.111894. [17] 姚婷婷, 肇恒鑫, 冯子豪, 等. 上下文感知多感受野融合网络的定向遥感目标检测[J]. 电子与信息学报, 2025, 47(1): 233–243. doi: 10.11999/JEIT240560.YAO Tingting, ZHAO Hengxin, FENG Zihao, et al. A context-aware multiple receptive field fusion network for oriented object detection in remote sensing images[J]. Journal of Electronics & Information Technology, 2025, 47(1): 233–243. doi: 10.11999/JEIT240560. [18] FIAZ M, NOMAN M, CHOLAKKAL H, et al. Guided-attention and gated-aggregation network for medical image segmentation[J]. Pattern Recognition, 2024, 156: 110812. doi: 10.1016/j.patcog.2024.110812. [19] GUO Shuai, HU Jingchuan, ZHOU Kai, et al. Real-time free viewpoint video synthesis system based on DIBR and a depth estimation network[J]. IEEE Transactions on Multimedia, 2024, 26: 6701–6716. doi: 10.1109/TMM.2024.3355639. [20] NIKLAUS S, MAI Long, YANG Jimei, et al. 3D Ken Burns effect from a single image[J]. ACM Transactions on Graphics, 2019, 38(6): 184. doi: 10.1145/3355089.3356528. [21] YU Jiahui, LIN Zhe, YANG Jimei, et al. Generative image inpainting with contextual attention[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 5505–5514. doi: 10.1109/CVPR.2018.00577. [22] SZYMANOWICZ S, INSAFUTDINOV E, ZHENG Chuanxia, et al. Flash3D: Feed-forward generalisable 3D scene reconstruction from a single image[C]. 2025 International Conference on 3D Vision, Singapore, Singapore, 2025: 670–681. doi: 10.1109/3DV66043.2025.00067. [23] FANG Kun, ZHANG Qinghui, WAN Chenxia, et al. Single view generalizable 3D reconstruction based on 3D Gaussian splatting[J]. Scientific Reports, 2025, 15(1): 18468. doi: 10.1038/s41598-025-03200-7. -


 下载:
下载:




图(5) / 表(3)
计量
- 文章访问数: 424
- HTML全文浏览量: 297
- PDF下载量: 39
- 被引次数: 0
