

Secure Multi-Task Federated Panoptic Perception Algorithm for Connected Autonomous Vehicles
-
摘要: 随着车联网和深度学习技术的发展,智能网联汽车(Connected Autonomous Vehicles, CAV)能够收集驾驶场景中的图像数据,并借助卷积神经网进行特征提取和处理,以实现对驾驶环境的高效感知。然而,由于驾驶场景的复杂性,单任务模型难以处理多样化的感知需求。此外,深度学习模型的优异表现依赖于海量数据,而单车收集的数据不足以训练出具有泛化性的模型。联邦学习技术打破了车辆间的信息孤岛,使车辆在不上传本地数据的情况下共享模型,通过上传本地模型至中心服务器进行模型聚合,从而获得性能更优的全局模型。因此,本文提出一种安全多任务全景感知算法。首先,构建了一个全景感知模型,使车辆能够并行执行驾驶场景中的多个感知任务,实现全景感知。其次,设计了一种基于混合评分的CAV选择算法,以筛选高质量的本地模型,最后,提出一种基于Shamir秘密共享的全局模型聚合算法,在聚合过程中采用秘密共享方法,避免因服务器遭受攻击或宕机导致的数据泄露。仿真结果验证了所提算法的有效性。Abstract: With the rapid development of vehicular networks and deep learning, connected autonomous vehicles (CAV) are now capable of collecting image data from driving scenarios and leveraging Convolutional Neural Networks for feature extraction and processing, thereby enabling efficient perception of their surroundings. However, due to the inherent complexity of driving scenarios, single-task models struggle to address various perception demands. And the performance of deep learning models heavily relies on large-scale data, while the data collected by individual vehicles is insufficient for training models with generalization capabilities. Federated learning overcomes data silos by enabling CAV to upload local model gradients instead of raw data to a central server for aggregation, which can preserve data privacy. Therefore, we present a Secure Multi-Task Federated Panoptic Perception algorithm for vehicular network scenarios. Firstly, the panoptic perception model is constructed to allow CAV to execute multiple perception tasks simultaneously. Besides, a CAV selection strategy based on hybrid scoring is designed to select high-quality local models from vehicles. Finally, a global model aggregation scheme based on Shamir secret sharing is introduced to prevent data leakage in the event of server attacks or outages, which employs secret sharing during the aggregation process. Simulation results validate the effectiveness of the proposed algorithm.
-
Key words:
- panoptic perception /
- deep learning /
- federated learning /
- secret sharing
-
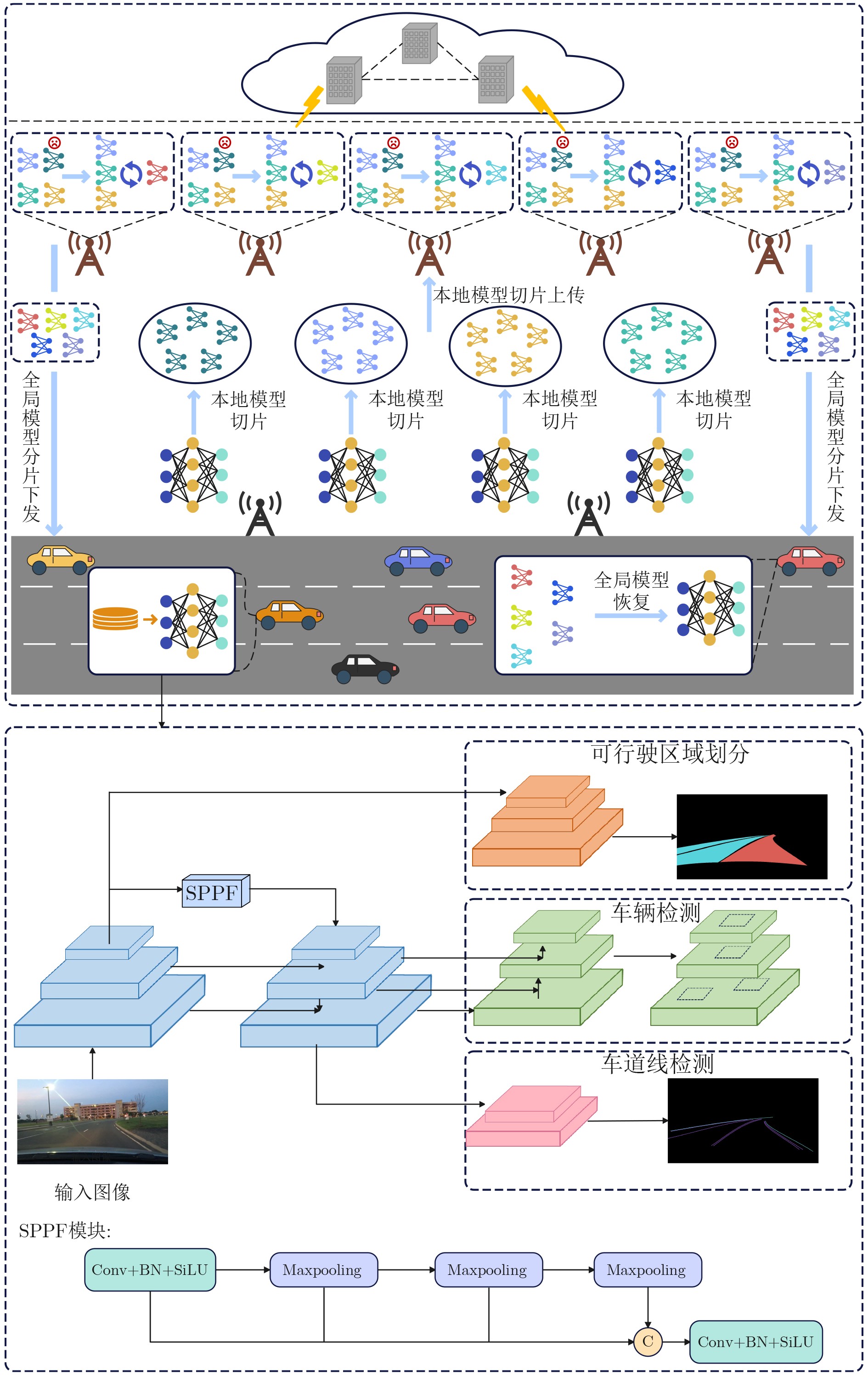
1 基于混合评分的CAV选择算法
输入:CAV本地模型,CAV信誉值 输出:参与全局模型聚合的CAV集合 1:所有CAV在本地生成一对公私钥,私钥保存在本地,公钥广
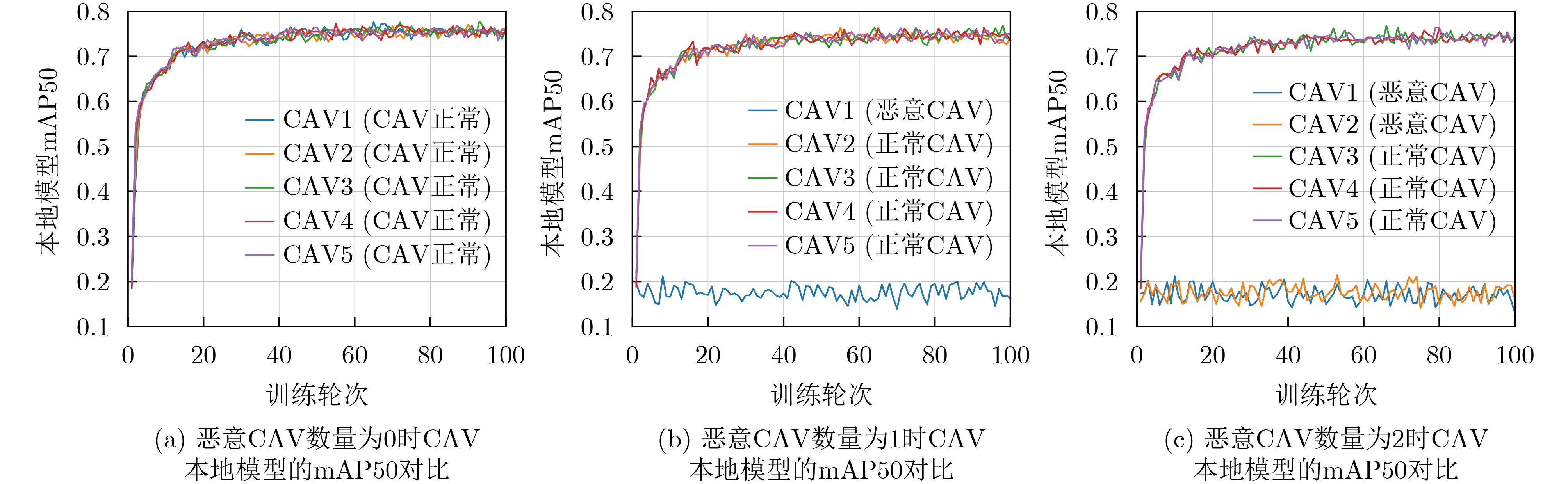
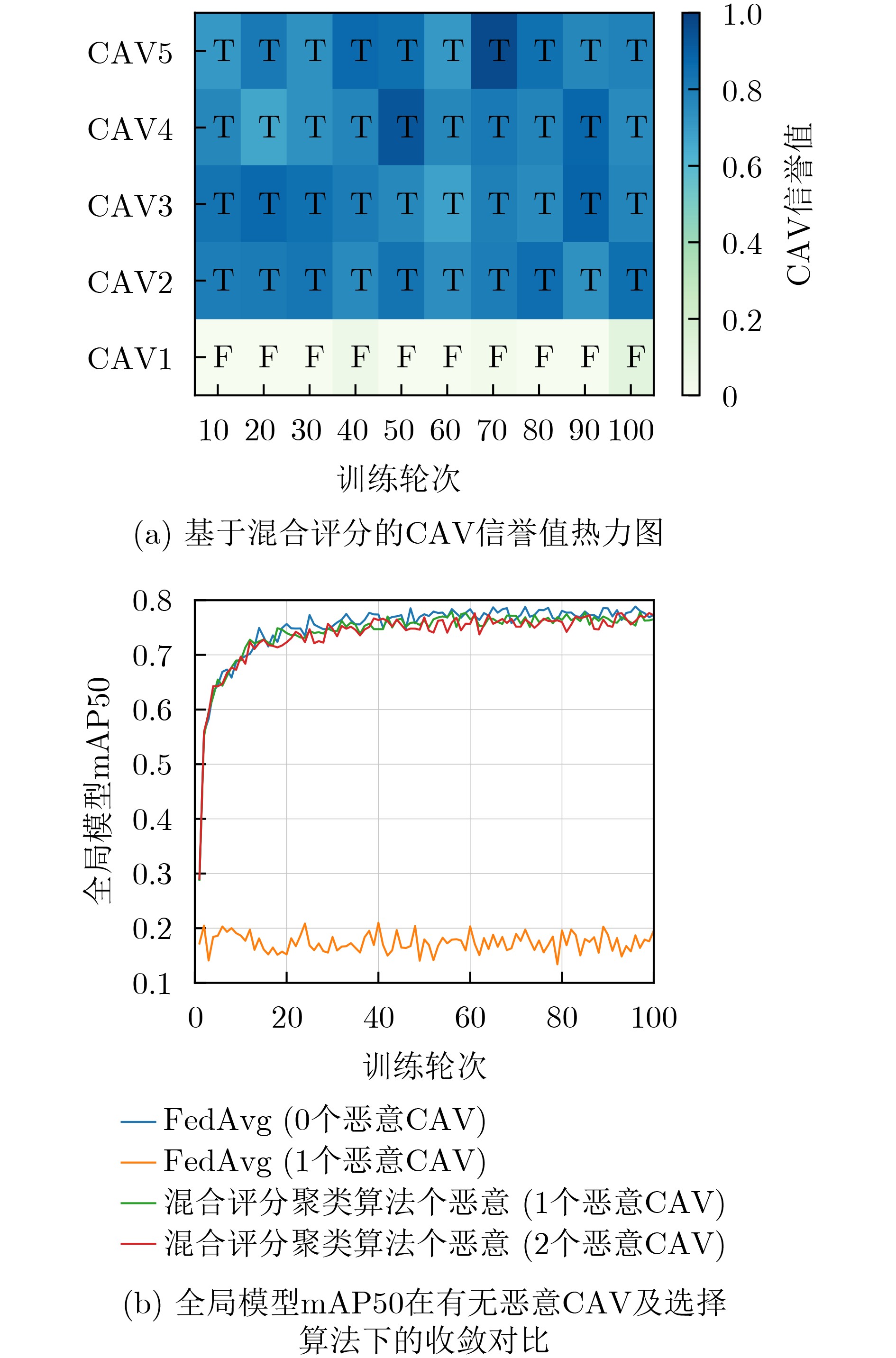
播发送给RSU2:for $ {\text{v}}_{i} $ in $ {\boldsymbol{V}}_{I} $ do 3: RSU选择高信誉值CAV集合$ {\boldsymbol{V}}_{K} $ 4: $ {\text{v}}_{i} $对本地模型加密并广播给RSU 5: $ {\boldsymbol{V}}_{K} $中的CAV获取该加密本地模型并使用解密 6: 使用本地数据测试解密后的本地模型 7: 计算$ {\text{v}}_{i} $本地模型的精度评分 8:end for 9:RSU计算所有CAV的间接评分 10:for $ {\text{v}}_{i} $ in $ {\boldsymbol{V}}_{I} $ do 11: 计算$ {\text{v}}_{i} $的本地模型年龄 12: 计算$ {\text{v}}_{i} $的本地模型与上一轮全局模型的相似度 13:end for 14:使用K-means聚类算法进行CAV选择 15:更新CAV的信誉值  下载: 导出CSV
下载: 导出CSV
2 基于Shamir秘密共享的全局模型聚合算法
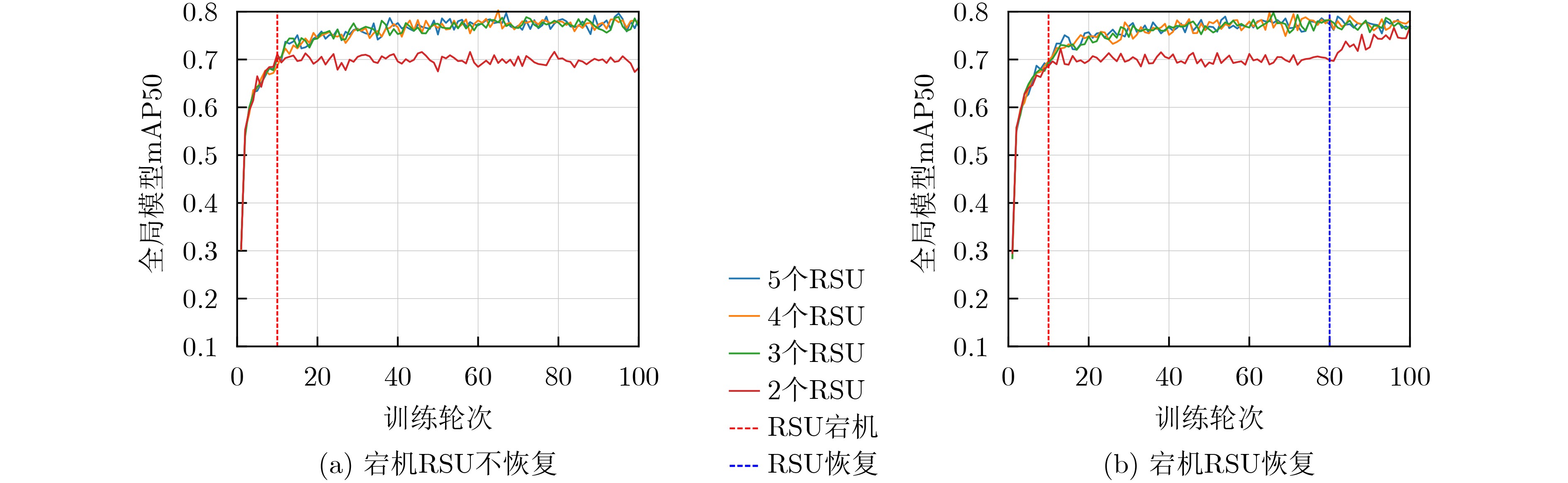
输入:CAV本地模型,RSU数量$ J $,CAV数量$ I $ 输出:全局模型 1:for $ {v}_{i} $ $ i $ = 1:$ I $ do 2: $ {v}_{i} $构建秘密多项式: 3: $ {f}_{i}(x)={a}_{1,i}x+{a}_{2,i}{x}^{2}+\cdots +{a}_{t-1,i}{x}^{t-1}+{\boldsymbol{M}}_{i} $ 4: $ {\text{v}}_{i} $计算$ {f}_{i}(1),{f}_{i}(2),\cdots ,{f}_{i}(J) $并发送给个$ J $RSU 5:end for 6:for $ {\text{r}}_{j} $ $ j $ = 1:$ J $ do 7: $ {\text{r}}_{j} $收到来自CAV的本地模型切片后,对其进行聚合 8: 聚合操作:$ {\boldsymbol{M}}_{j,\mathrm{mod}\text{el}}=\displaystyle\sum \nolimits_{i=1}^{I}\frac{1}{I}{f}_{i}(x) $ 9: $ {\text{r}}_{j} $将聚合结果发送给CAV 10:end for 11:CAV收到至少t个RSU的聚合结果后恢复出全局模型
下载: 导出CSV
表 2 全景感知模型在不同联邦学习框架下的性能
联邦学习框架 Recall(%) mAP50(%) mIoU(%) Accuracy(%) IoU(%) FedAvg 82.4 74.3 87.4 80.3 25.3 FedCS 84.5 73.7 88.3 81.3 26.4 FedAsync 84.7 76.8 88.2 81.5 26.8 SMFPP 86.4 77.7 89.6 82.4 27.2
下载: 导出CSV
表 4 交通目标检测结果
模型 Recall(%) mAP50(%) MultiNet 80.5 57.4 DLT-Net 88.3 64.8 Fast R-CNN 80.9 61.2 YOLOv8n(det) 81.6 73.4 YOLOP 86.1 74.5 A-YOLOM 85.3 77.5 YOLOMH 86.6 76.2 SMFPP 86.4 77.7
下载: 导出CSV
表 5 可行驶区域分割结果
模型 mIoU(%) MultiNet 69.4 DLT-Net 70.8 PSPNet 87.6 YOLOv8n(seg) 77.4 YOLOP 89.3 A-YOLOM 88.7 YOLOMH 89.2 SMFPP 89.6
下载: 导出CSV
表 6 车道线检测结果
模型 Accuracy(%) IoU(%) Enet 33.8 13.4 SCNN 34.6 14.9 Enet-SAD 35.3 15.2 YOLOv8n(seg) 80.7 20.4 YOLOP 81.8 24.9 A-YOLOM 82.0 26.5 YOLOMH 82.2 26.9 SMFPP 82.4 27.2
下载: 导出CSV
表 1 不同场景下模型性能
模型 场景 Recall(%) mAP50(%) mIoU(%) Accuracy(%) IoU(%) YOLOP 日间场景 87.5 76.4 90.4 82.7 25.3 SMFPP 日间场景 88.4 78.6 91.8 84.2 28.2 YOLOP 夜间场景 85.3 74.3 88.3 80.5 24.2 SMFPP 夜间场景 85.7 76.4 89.6 81.3 26.5
下载: 导出CSV
表 7 模型参数与推理速度比较结果
模型 参数量(M) 推理速度(FPS) YOLOP 7.9 26.0 HybridNests 12.83 11.7 A-YOLOM 4.43 39.9 YOLOPv2 38.9 91 SMFPP 3.45 52.4
下载: 导出CSV
表 3 不同CAV规模下全局模型性能
CAV数量 Recall(%) mAP50(%) mIoU(%) Accuracy(%) IoU(%) 5 86.4 77.7 89.6 82.4 27.2 10 87.8 79.2 89.8 84.1 27.5 20 88.6 79.5 90.4 85.2 28.4
下载: 导出CSV
-
[1] DHINESH KUMAR R and RAMMOHAN A. Revolutionizing intelligent transportation systems with cellular vehicle-to-everything (C-V2X) technology: Current trends, use cases, emerging technologies, standardization bodies, industry analytics and future directions[J]. Vehicular Communications, 2023, 43: 100638. doi: 10.1016/j.vehcom.2023.100638. [2] HUANG Xiaoge, YIN Hongbo, CHEN Qianbin, et al. DAG-based swarm learning: A secure asynchronous learning framework for Internet of Vehicles[J]. Digital Communications and Networks, 2024, 10(6): 1611–1621. doi: 10.1016/j.dcan.2023.10.004. [3] HUANG Xiaoge, LI Wenjing, LIANG Chengchao, et al. Environment-aware personalized heterogeneous federated distillation for dual-layer blockchain-enabled internet of vehicles[J]. IEEE Transactions on Vehicular Technology, 2025, 74(12): 19552–19567. doi: 10.1109/TVT.2025.3586538. [4] GUO Yu, LIU R W, LU Yuxu, et al. Haze visibility enhancement for promoting traffic situational awareness in vision-enabled intelligent transportation[J]. IEEE Transactions on Vehicular Technology, 2023, 72(12): 15421–15435. doi: 10.1109/TVT.2023.3298041. [5] GIRSHICK R. Fast R-CNN[C]. IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1440–1448. doi: 10.1109/ICCV.2015.169. [6] TERVEN J, CÓRDOVA-ESPARZA D M, and ROMERO-GONZÁLEZ J A. A comprehensive review of YOLO architectures in computer vision: From YOLOv1 to YOLOv8 and YOLO-NAS[J]. Machine Learning and Knowledge Extraction, 2023, 5(4): 1680–1716. doi: 10.3390/make5040083. [7] BADRINARAYANAN V, KENDALL A, and CIPOLLA R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481–2495. doi: 10.1109/TPAMI.2016.2644615. [8] ZHAO Hengshuang, SHI Jianping, QI Xiaojuan, et al. Pyramid scene parsing network[C]. IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 6230–6239. doi: 10.1109/CVPR.2017.660. [9] PAN Xingang, SHI Jianping, LUO Ping, et al. Spatial as deep: Spatial CNN for traffic scene understanding[C]. Proceedings of the 32th AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018: 7276–7283. doi: 10.1609/aaai.v32i1.12301. [10] NEVEN D, DE BRABANDERE B, GEORGOULIS S, et al. Towards end-to-end lane detection: An instance segmentation approach[C]. IEEE Intelligent Vehicles Symposium, Changshu, China, 2018: 286–291. doi: 10.1109/IVS.2018.8500547. [11] TEICHMANN M, WEBER M, ZÖLLNER M, et al. Multinet: Real-time joint semantic reasoning for autonomous driving[C]. IEEE Intelligent Vehicles Symposium, Changshu, China, 2018: 1013–1020. doi: 10.1109/IVS.2018.8500504. [12] WU Dong, LIAO Manwen, ZHANG Weitian, et al. Correction to: YOLOP: You only look once for panoptic driving perception[J]. Machine Intelligence Research, 2023, 20(6): 952. doi: 10.1007/s11633-023-1452-6. [13] DAT V T, BAO N V H, and HUNG P D. HybridNets: End-to-end perception network[J]. Pattern Recognition and Image Analysis, 2025, 35(2): 106–118. doi: 10.1134/S1054661825700038. [14] XIAO Sa, HUANG Xiaoge, DENG Xuesong, et al. DB-FL: DAG blockchain-enabled generalized federated dropout learning[J]. Digital Communications and Networks, 2025, 11(3): 886–897. doi: 10.1016/j.dcan.2024.09.005. [15] HU Xiaoya, LI Ruiqin, WANG Licheng, et al. A data sharing scheme based on federated learning in IoV[J]. IEEE Transactions on Vehicular Technology, 2023, 72(9): 11644–11656. doi: 10.1109/TVT.2023.3266100. -

 下载:
下载:



图(5) / 表(9)
计量
- 文章访问数: 214
- HTML全文浏览量: 110
- PDF下载量: 24
- 被引次数: 0
