

Defeating Voice Conversion Forgery by Active Defense with Diffusion Reconstruction
-
摘要: 语音深度生成技术已经能够生成逼真的语音。其在丰富人们娱乐和生活的同时,也易被不法分子滥用进行语音伪造,从而对个人隐私与社会安全带来巨大隐患。作为语音伪造的主流防御手段,现有的主动防御技术虽然已取得了一定成效,但在防御能力与防御样本不可感知性的平衡以及鲁棒性上仍然一般。为此,该文提出一种抵抗语音转换伪造的扩散重构式主动防御方法。该方法利用扩散声码器PriorGrad作为生成器,借助基于待保护语音的扩散先验指导逐步去噪过程,从而重构待保护语音直接得到防御语音样本。而且,该方法还设计了多尺度人耳感知损失,重点抑制人耳敏感频段的扰动幅度,进一步提升防御样本不可感知性。针对4个先进的语音转换模型的实验表明:该方法在兼顾语音防御样本不可感知性的前提下,基于说话人验证精度客观评价指标,防御能力相比次优方法在白盒场景下平均提升约32%,在黑盒场景下平均提升约16%,实现了防御能力与样本不可感知性之间更好的平衡;而且,针对3种不同有损压缩和高斯滤波攻击,该方法均取得了比现有方法更好的鲁棒性。Abstract:
Objective Voice deep generation technology is able to produce speech that is perceptually realistic. Although it enriches entertainment and everyday applications, it is also exploited for voice forgery, creating risks to personal privacy and social security. Existing active defense techniques serve as a major line of protection against such forgery, yet their performance remains limited in balancing defensive strength with the imperceptibility of defensive speech examples, and in maintaining robustness. Methods An active defense method against voice conversion forgery is proposed on the basis of diffusion reconstruction. The diffusion vocoder PriorGrad is used as the generator, and the gradual denoising process is guided by the diffusion prior of the target speech so that the protected speech is reconstructed and defensive speech examples are obtained directly. A multi-scale auditory perceptual loss is further introduced to suppress perturbation amplitudes in frequency bands sensitive to the human auditory system, which improves the imperceptibility of the defensive examples. Results and Discussions Defense experiments conducted on four leading voice conversion models show that the proposed method maintains the imperceptibility of defensive speech examples and, when speaker verification accuracy is used as the evaluation metric, improves defense ability by about 32% on average in white-box scenarios and about 16% in black-box scenarios compared with the second-best method, achieving a stronger balance between defense ability and imperceptibility ( Table 2 ). In robustness experiments, the proposed method yields an average improvement of about 29% in white-box scenarios and about 18% in black-box scenarios under three compression attacks (Table 3 ), and an average improvement of about 35% in the white-box scenario and about 17% in the black-box scenario under Gaussian filtering attack (Table 4 ). Ablation experiments further show that the use of multi-scale auditory perceptual loss improves defense ability by 5% to 10% compared with the use of single-scale auditory perceptual loss (Table 5 ).Conclusions An active defense method against voice conversion forgery based on diffusion reconstruction is proposed. Defensive speech examples are reconstructed directly through a diffusion vocoder so that the generated audio better approximates the distribution of the original target speech, and a multi-scale auditory perceptual loss is integrated to improve the imperceptibility of the defensive speech. Experimental results show that the proposed method achieves stronger defense performance than existing approaches in both white-box and black-box scenarios and remains robust under compression coding and smoothing filtering. Although the method demonstrates clear advantages in defense performance and robustness, its computational efficiency requires further improvement. Future work is directed toward diffusion generators that operate with a single time step or fewer time steps to enhance computational efficiency while maintaining defense performance. -
Key words:
- Voice conversion /
- Deepfake /
- Active defense /
- Diffusion model
-
表 2 防御性能对比
代理模型 方法 SVAdefense↓ SVAquality↑ MCD↓ 推理时间(s)↓ M1 M2 M3 M4 黑盒平均 M1 FGSM[24] 0.86 0.78 0.84 0.89 0.84 0.98 6.27 0.76 PGD[25] 0.71 0.69 0.71 0.82 0.74 0.92 6.56 7.11 Huang等人[8] 0.66 0.68 0.68 0.86 0.74 0.96 5.80 64.03 Dong等人[10] 0.59 0.52 0.62 0.72 0.62 0.97 6.47 0.27 本文* 0.46 0.47 0.43 0.87 0.59 1.00 5.58 0.21 本文 0.31 0.43 0.44 0.76 0.54 1.00 5.68 0.20 M2 FGSM[25] 0.83 0.63 0.80 0.88 0.84 0.99 6.17 0.13 PGD[25] 0.61 0.50 0.60 0.74 0.65 0.92 6.75 2.21 Huang等人[8] 0.68 0.49 0.67 0.80 0.72 0.99 6.43 92.60 Dong等人[10] 0.62 0.46 0.54 0.69 0.62 0.96 7.43 0.26 本文* 0.46 0.40 0.60 0.72 0.59 0.99 5.85 0.20 本文 0.38 0.30 0.51 0.71 0.53 0.99 5.53 0.20 M3 FGSM[24] 0.92 0.79 0.79 0.95 0.89 0.99 8.06 0.09 PGD[25] 0.68 0.67 0.59 0.78 0.71 0.94 7.11 1.39 Huang等人[8] 0.74 0.79 0.59 0.89 0.81 0.98 6.23 66.90 Dong等人[10] 0.63 0.63 0.61 0.70 0.65 0.96 7.28 0.25 本文* 0.48 0.52 0.50 0.86 0.62 0.99 6.02 0.22 本文 0.39 0.44 0.40 0.80 0.54 0.99 5.83 0.21 M4 FGSM[24] 0.95 0.76 0.87 0.95 0.86 0.98 7.70 0.45 PGD[25] 0.91 0.74 0.79 0.89 0.81 1.0 7.48 3.13 Huang等人[8] 0.90 0.83 0.86 0.95 0.86 0.99 7.53 169.62 Dong等人[10] 0.64 0.46 0.60 0.64 0.57 0.96 7.46 0.27 本文* 0.50 0.57 0.55 0.62 0.54 0.99 6.97 0.22 本文 0.41 0.42 0.52 0.56 0.45 0.99 6.72 0.22  下载: 导出CSV
下载: 导出CSV
表 3 3种压缩攻击(MP3,AAC,OPUS)对防御能力的影响(SVAdefense↓)
压缩方法 代理模型 方法 128 kbit/(s·Hz) 64 kbit/(s·Hz) M1 M2 M3 M4 黑盒平均 M1 M2 M3 M4 黑盒平均 MP3 M1 Dong等人[10] 0.60 0.58 0.60 0.80 0.66 0.62 0.60 0.63 0.73 0.65 本文 0.33 0.44 0.44 0.80 0.56 0.32 0.45 0.44 0.79 0.56 M2 Dong等人[10] 0.60 0.48 0.62 0.73 0.65 0.70 0.51 0.58 0.68 0.65 本文 0.42 0.32 0.51 0.73 0.55 0.40 0.34 0.52 0.76 0.56 M3 Dong等人[10] 0.57 0.62 0.64 0.84 0.68 0.66 0.62 0.65 0.76 0.68 本文 0.39 0.46 0.44 0.81 0.55 0.38 0.46 0.42 0.80 0.55 M4 Dong等人[10] 0.67 0.51 0.62 0.60 0.60 0.71 0.44 0.71 0.64 0.62 本文 0.41 0.46 0.55 0.58 0.47 0.46 0.47 0.50 0.56 0.48 AAC M1 Dong等人[10] 0.62 0.55 0.65 0.82 0.67 0.61 0.56 0.67 0.73 0.65 本文 0.35 0.40 0.44 0.85 0.56 0.33 0.45 0.38 0.83 0.55 M2 Dong等人[10] 0.69 0.47 0.66 0.76 0.70 0.62 0.55 0.58 0.80 0.67 本文 0.47 0.34 0.58 0.70 0.58 0.48 0.33 0.62 0.75 0.62 M3 Dong等人[10] 0.62 0.65 0.60 0.79 0.68 0.63 0.65 0.68 0.82 0.70 本文 0.38 0.48 0.44 0.86 0.57 0.37 0.46 0.43 0.77 0.53 M4 Dong等人[10] 0.62 0.54 0.61 0.66 0.59 0.78 0.47 0.73 0.67 0.66 本文 0.43 0.46 0.53 0.59 0.47 0.45 0.52 0.48 0.56 0.48 OPUS M1 Dong等人[10] 0.68 0.52 0.72 0.86 0.70 0.67 0.54 0.76 0.78 0.69 本文 0.40 0.45 0.43 0.82 0.57 0.39 0.45 0.46 0.80 0.57 M2 Dong等人[10] 0.71 0.55 0.68 0.79 0.70 0.63 0.58 0.60 0.83 0.69 本文 0.44 0.32 0.60 0.72 0.59 0.42 0.35 0.58 0.78 0.59 M3 Dong等人[10] 0.62 0.68 0.57 0.82 0.71 0.68 0.62 0.59 0.82 0.71 本文 0.38 0.46 0.43 0.82 0.55 0.44 0.47 0.41 0.81 0.57 M4 Dong等人[10] 0.60 0.57 0.68 0.69 0.62 0.78 0.49 0.79 0.65 0.69 本文 0.45 0.48 0.63 0.63 0.52 0.48 0.56 0.52 0.57 0.52
下载: 导出CSV
表 4 滤波攻击对防御能力的影响(SVAdefense↓)
代理模型 方法 M1 M2 M3 M4 黑盒平均 M1 Dong等人[10]($ \mathrm{\sigma } $=0.01) 0.65 0.65 0.60 0.80 0.68 本文($ \mathrm{\sigma } $=0.04) 0.34 0.36 0.47 0.78 0.54 M2 Dong等人[10]($ \mathrm{\sigma } $=0.02) 0.54 0.53 0.71 0.72 0.66 本文($ \mathrm{\sigma } $=0.04) 0.41 0.32 0.61 0.73 0.58 M3 Dong等人[10]($ \mathrm{\sigma } $=0.01) 0.70 0.56 0.68 0.74 0.67 本文($ \mathrm{\sigma } $=0.03) 0.40 0.46 0.42 0.85 0.57 M4 Dong等人[10]($ \mathrm{\sigma } $=0.01) 0.60 0.64 0.55 0.72 0.60 本文($ \mathrm{\sigma } $=0.04) 0.36 0.50 0.54 0.59 0.47
下载: 导出CSV
表 5 不同尺度感知损失下本文方法的防御性能
代理
模型尺度 SVAdefense↓ SVAquality↑ MCD↓ M1 M2 M3 M4 黑盒
平均M1 无(本文*) 0.46 0.47 0.43 0.87 0.59 1.0 5.58 (512, 128) 0.35 0.42 0.45 0.82 0.56 1.0 6.16 ( 1024 , 256)0.33 0.38 0.45 0.84 0.56 1.0 5.46 (2 048, 512) 0.38 0.43 0.50 0.82 0.58 1.0 6.03 3尺度(本文) 0.31 0.43 0.44 0.76 0.54 1.0 5.68 M2 无(本文*) 0.46 0.40 0.60 0.72 0.59 0.99 5.85 (512, 128) 0.32 0.37 0.56 0.80 0.56 0.99 6.79 ( 1024 , 256)0.37 0.33 0.54 0.78 0.56 0.99 6.15 (2 048, 512) 0.42 0.38 0.57 0.76 0.58 0.99 5.87 3尺度(本文) 0.38 0.30 0.51 0.71 0.53 0.99 5.53 M3 无(本文*) 0.48 0.52 0.50 0.86 0.62 0.99 6.02 (512, 128) 0.46 0.44 0.46 0.84 0.58 0.99 6.10 ( 1024 , 256)0.51 0.40 0.48 0.84 0.58 0.99 6.08 (2 048, 512) 0.53 0.44 0.47 0.81 0.59 0.99 6.25 3尺度(本文) 0.39 0.44 0.40 0.80 0.54 0.99 5.83 M4 无(本文*) 0.50 0.57 0.55 0.62 0.54 0.99 6.97 (512, 128) 0.38 0.46 0.60 0.61 0.48 0.98 6.88 ( 1024 , 256)0.40 0.56 0.51 0.60 0.49 0.99 7.02 (2 048, 512) 0.39 0.55 0.56 0.58 0.50 0.98 7.15 3尺度(本文) 0.41 0.42 0.52 0.56 0.44 0.99 6.72
下载: 导出CSV
-
[1] KIM J, KIM J H, CHOI Y, et al. AdaptVC: High quality voice conversion with adaptive learning[C]. 2025 IEEE International Conference on Acoustics, Speech and Signal Processing, Hyderabad, India, 2025: 1–5. doi: 10.1109/ICASSP49660.2025.10889396. [2] 李旭嵘, 纪守领, 吴春明, 等. 深度伪造与检测技术综述[J]. 软件学报, 2021, 32(2): 496–518. doi: 10.13328/j.cnki.jos.006140.LI Xurong, JI Shouling, WU Chunming, et al. Survey on deepfakes and detection techniques[J]. Journal of Software, 2021, 32(2): 496–518. doi: 10.13328/j.cnki.jos.006140. [3] ZHANG Bowen, CUI Hui, NGUYEN V, et al. Audio deepfake detection: What has been achieved and what lies ahead[J]. Sensors, 2025, 25(7): 1989. doi: 10.3390/s25071989. [4] FAN Cunhang, DING Mingming, TAO Jianhua, et al. Dual-branch knowledge distillation for noise-robust synthetic speech detection[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024, 32: 2453–2466. doi: 10.1109/TASLP.2024.3389643. [5] 钱亚冠, 张锡敏, 王滨, 等. 基于二阶对抗样本的对抗训练防御[J]. 电子与信息学报, 2021, 43(11): 3367–3373. doi: 10.11999/JEIT200723.QIAN Yaguan, ZHANG Ximin, WANG Bin, et al. Adversarial training defense based on second-order adversarial examples[J]. Journal of Electronics & Information Technology, 2021, 43(11): 3367–3373. doi: 10.11999/JEIT200723. [6] 胡军, 石艺杰. 基于动量增强特征图的对抗防御算法[J]. 电子与信息学报, 2023, 45(12): 4548–4555. doi: 10.11999/JEIT221414.HU Jun and SHI Yijie. Adversarial defense algorithm based on momentum enhanced future map[J]. Journal of Electronics & Information Technology, 2023, 45(12): 4548–4555. doi: 10.11999/JEIT221414. [7] 张思思, 左信, 刘建伟. 深度学习中的对抗样本问题[J]. 计算机学报, 2019, 42(8): 1886–1904. doi: 10.11897/SP.J.1016.2019.01886.ZHANG Sisi, ZUO Xin, and LIU Jianwei. The problem of the adversarial examples in deep learning[J]. Chinese Journal of Computers, 2019, 42(8): 1886–1904. doi: 10.11897/SP.J.1016.2019.01886. [8] HUANG C Y, LIN Y Y, LEE H Y, et al. Defending your voice: Adversarial attack on voice conversion[C]. 2021 IEEE Spoken Language Technology Workshop, Shenzhen, China, 2021: 552–559. doi: 10.1109/SLT48900.2021.9383529. [9] LI Jingyang, YE Dengpan, TANG Long, et al. Voice Guard: Protecting voice privacy with strong and imperceptible adversarial perturbation in the time domain[C]. The Thirty-Second International Joint Conference on Artificial Intelligence, Macao, China, 2023: 4812–4820. doi: 10.24963/ijcai.2023/535. [10] DONG Shihang, CHEN Beijing, MA Kaijie, et al. Active defense against voice conversion through generative adversarial network[J]. IEEE Signal Processing Letters, 2024, 31: 706–710. doi: 10.1109/LSP.2024.3365034. [11] QIAN Kaizhi, ZHANG Yang, CHANG Shiyu, et al. AutoVC: Zero-shot voice style transfer with only autoencoder loss[C]. The 36th International Conference on Machine Learning, Long Beach, USA, 2019: 5210–5219. [12] CHOU J C and LEE H Y. One-shot voice conversion by separating speaker and content representations with instance normalization[C]. The 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 2019: 664–668. doi: 10.21437/Interspeech.2019-2663. [13] WU Dayi, CHEN Yenhao, and LEE H Y. VQVC+: One-shot voice conversion by vector quantization and U-Net architecture[C]. The 21st Annual Conference of the International Speech Communication Association, Shanghai, China, 2020: 4691–4695. doi: 10.21437/INTERSPEECH.2020-1443. [14] PARK H J, YANG S W, KIM J S, et al. TriAAN-VC: Triple adaptive attention normalization for any-to-any voice conversion[C]. 2023 IEEE International Conference on Acoustics, Speech and Signal Processing, Rhodes Island, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10096642. [15] HUANG Fan, ZENG Kun, and ZHU Wei. DiffVC+: Improving diffusion-based voice conversion for speaker anonymization[C]. The 25th Annual Conference of the International Speech Communication Association, Kos Island, Greece, 2024: 4453–4457. doi: 10.21437/Interspeech.2024-502. [16] MENG Dongyu and CHEN Hao. MagNet: A two-pronged defense against adversarial examples[C]. Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. New York, USA, 2017: 135–147. doi: 10.1145/3133956.3134057. [17] HO J, JAIN A, and ABBEEL P. Denoising diffusion probabilistic models[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 574. [18] LEE S G, KIM H, SHIN C, et al. PriorGrad: Improving conditional denoising diffusion models with data-dependent adaptive prior[C]. The 10th International Conference on Learning Representations, 2022: 1–18. [19] SUZUKI Y and TAKESHIMA H. Equal-loudness-level contours for pure tones[J]. The Journal of the Acoustical Society of America, 2004, 116(2): 918–933. doi: 10.1121/1.1763601. [20] YAMAMOTO R, SONG E, and KIM J M. Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram[C]. 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 2020: 6199–6203. doi: 10.1109/ICASSP40776.2020.9053795. [21] WANG Yulong and ZHANG Xueliang. MFT-CRN: Multi-scale Fourier transform for monaural speech enhancement[C]. The 24th Annual Conference of the International Speech Communication Association, Dublin, Ireland, 2023: 1060–1064. doi: 10.21437/Interspeech.2023-865. [22] YAMAGISHI J, VEAUX C, and MACDONALD K. CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92)[EB/OL]. https://datashare.ed.ac.uk/handle/10283/3443, 2019. [23] CHEN Y H, WU Dayi, WU T H, et al. Again-VC: A one-shot voice conversion using activation guidance and adaptive instance normalization[C]. 2021 IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, Canada, 2021: 5954–5958. doi: 10.1109/ICASSP39728.2021.9414257. [24] GOODFELLOW I J, SHLENS J, and SZEGEDY C. Explaining and harnessing adversarial examples[C]. The 3rd International Conference on Learning Representations, San Diegoa, USA, 2015. [25] WANG Run, HUANG Ziheng, CHEN Zhikai, et al. Anti-forgery: Towards a stealthy and robust DeepFake disruption attack via adversarial perceptual-aware perturbations[C]. The Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 2022: 761–767. doi: 10.24963/ijcai.2022/107. -

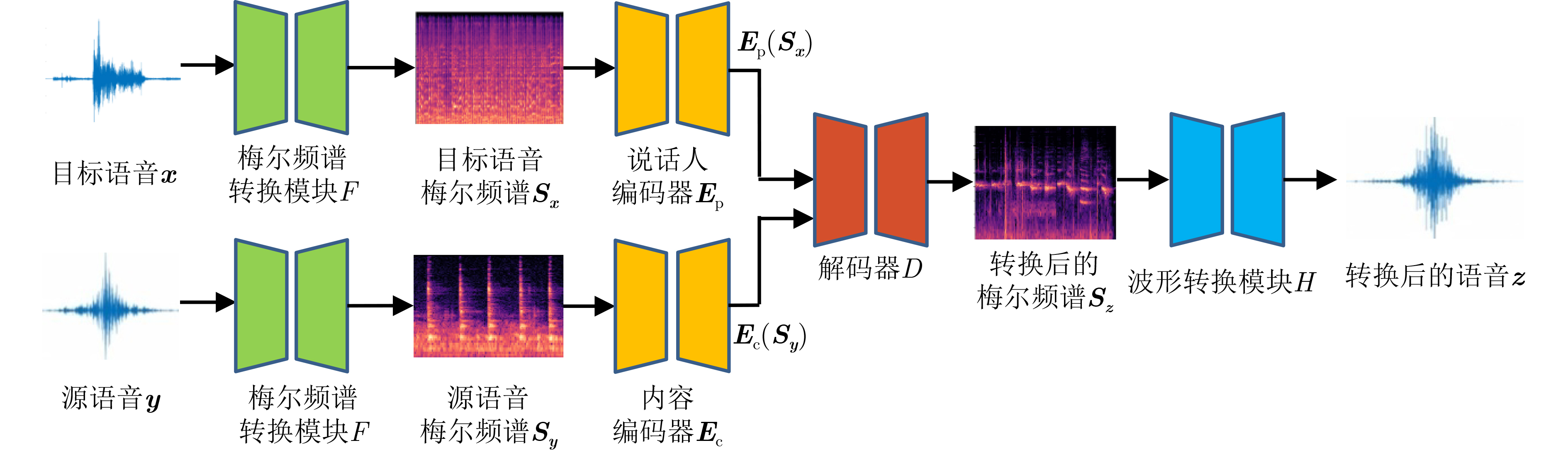
 下载:
下载:
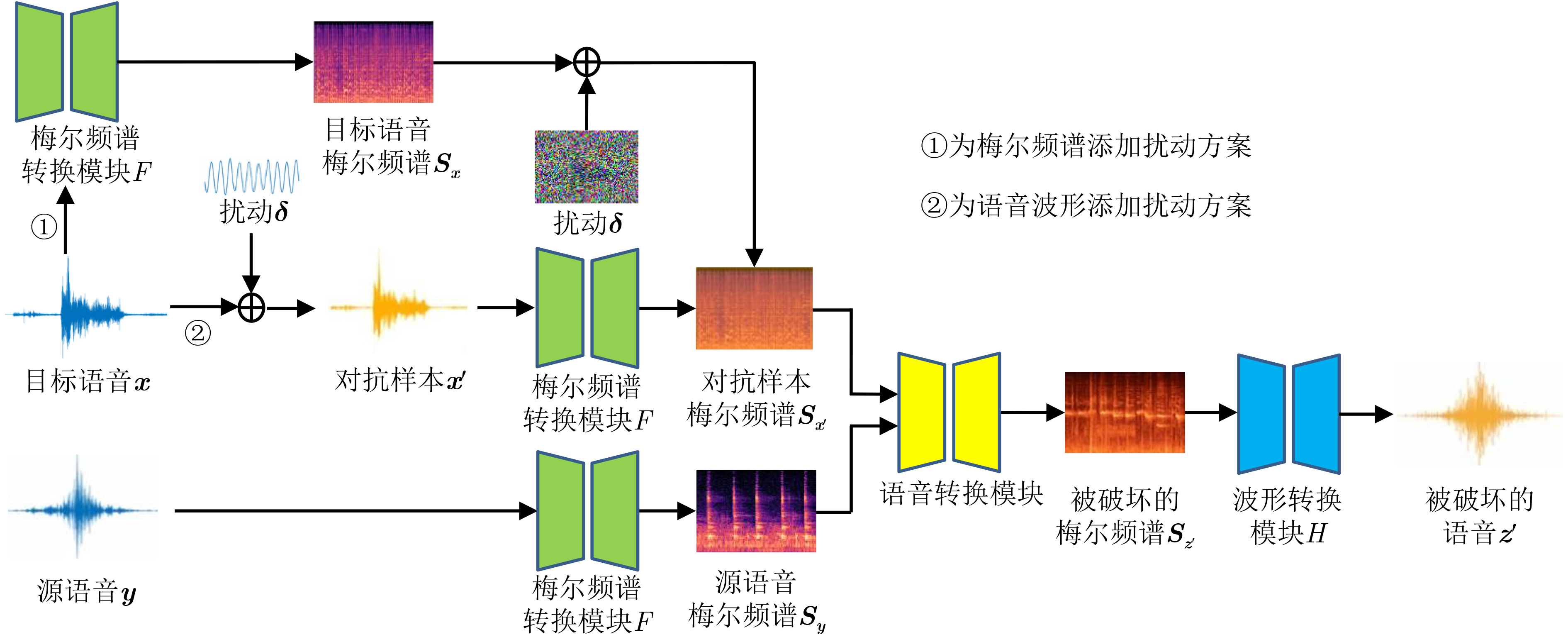

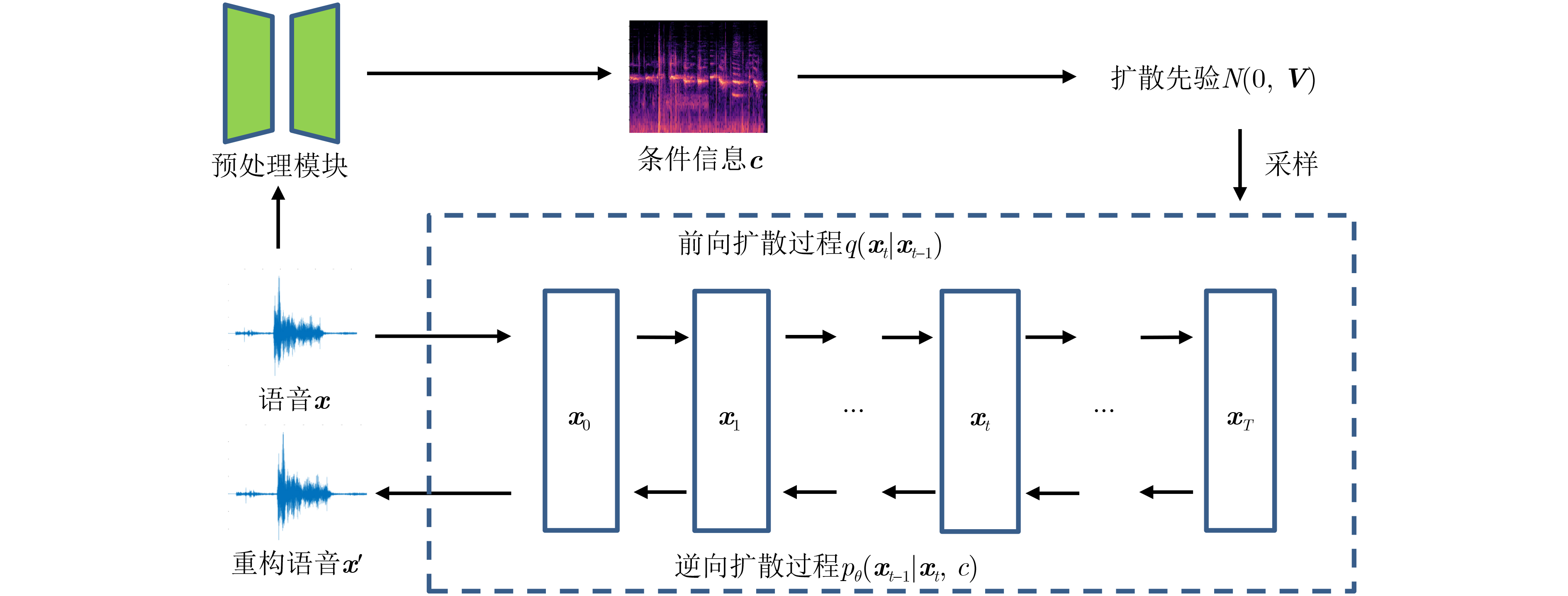


图(4) / 表(5)
计量
- 文章访问数: 771
- HTML全文浏览量: 448
- PDF下载量: 97
- 被引次数: 0
