

LLM-based Data Compliance Checking for Internet of Things Scenarios
-
摘要: 随着《中华人民共和国数据安全法》、欧盟《通用数据保护条例》(GDPR)等国内外法规条例的逐步施行,数据合规检测成为规范数据处理活动、保障数据安全、保护个人与组织合法权益的重要手段。然而,物联网场景下异构设备数据冗长多变、非结构化、内容模糊等特点加剧了数据合规检测的难度,导致传统规则匹配方法容易产生大量的误报。针对上述挑战,该文提出一种新型面向物联网场景的大模型驱动数据合规检测方法:第1阶段,基于全量规则库,利用快速正则匹配算法高效筛查出所有潜在违规数据,并输出结构化初步检测结果;第2阶段,利用大语言模型进行语义级合规复核,设计差异化分类检测策略,针对不同违规类型构建基于思维链与少样本提示融合的增强提示词,用于减少规则差异性与语义模糊性带来的错误结果。该文采集了52种物联网设备的日志与流量数据,形成共计55 080条原始违规检测数据,并在8个主流大模型底座以及不同影响设置参数上开展对比实验。研究结果表明原有仅第1阶段基于规则匹配的检测方法在真实物联网环境下误报率为64.3%,而经第2阶段大模型驱动的复核检测后降至6.9%,且大模型自身引入的错误率控制在0.01%以下。Abstract:
Objective The implementation of regulations such as the Data Security Law of the People’s Republic of China, the Personal Information Protection Law of the People’s Republic of China, and the European Union General Data Protection Regulation (GDPR) has established data compliance checking as a central mechanism for regulating data processing activities, ensuring data security, and protecting the legitimate rights and interests of individuals and organizations. However, the characteristics of the Internet of Things (IoT), defined by large numbers of heterogeneous devices and the dynamic, extensive, and variable nature of transmitted data, increase the difficulty of compliance checking. Logs and traffic data generated by IoT devices are long, unstructured, and often ambiguous, which results in a high false-positive rate when traditional rule-matching methods are applied. In addition, the dynamic business environments and user-defined compliance requirements further increase the complexity of rule design, maintenance, and decision-making. Methods A large language model-driven data compliance checking method for IoT scenarios is proposed to address the identified challenges. In the first stage, a fast regular expression matching algorithm is employed to efficiently screen potential non-compliant data based on a comprehensive rule database. This process produces structured preliminary checking results that include the original non-compliant content and the corresponding violation type. The rule database incorporates current legislation and regulations, standard requirements, enterprise norms, and customized business requirements, and it maintains flexibility and expandability. By relying on the efficiency of regular expression matching and generating structured preliminary results, this stage addresses the difficulty of reviewing large volumes of long IoT text data and enhances the accuracy of the subsequent large language model review. In the second stage, a Large Language Model (LLM) is employed to evaluate the precision of the initial detection results. For different categories of violations, the LLM adaptively selects different prompt words to perform differentiated classification detection. Results and Discussions Data are collected from 52 IoT devices operating in a real environment, including log and traffic data ( Table 2 ). A compliance-checking rule library for IoT devices is established in accordance with the Cybersecurity Law, the Data Security Law, other relevant regulations, and internal enterprise information-security requirements. Based on this library, the collected data undergo a first-stage rule-matching process, yielding a false-positive rate of 64.3% and identifying 55 080 potential non-compliant data points. Three aspects are examined: benchmark models, prompt schemes, and role prompts. In the benchmark model comparison, eight mainstream large language models are used to evaluate detection performance (Table 5 ), including Qwen2.5-32B-Instruct, DeepSeek-R1-70B, and DeepSeek-R1-0528 with different parameter configurations. After review and testing by the large language model, the initial false-positive rate is reduced to 6.9%, which demonstrates a substantial improvement in the quality of compliance checking. The model’s own error rate remains below 0.01%. The prompt-engineering assessment shows that prompt design exerts a strong effect on review accuracy (Table 6 ). When general prompts are applied, the final false-positive rate remains high at 59%. When only chain-of-thought prompts or concise sample prompts are used, the false-positive rate is reduced to approximately 12% and 6%, respectively, and the model’s own error rate decreases to about 30% and 13%. Combining these strategies further reduces the error rate of the small-sample prompt approach to 0.01%. The effect of system-role prompt words on review accuracy is also evaluated (Table 7 ). Simple role prompts yield higher accuracy and F1 scores than the absence of role prompts, whereas detailed role prompts provide a clearer overall advantage than simple role prompts. Ablation experiments (Table 8 ) further examine the contribution of rule classification and prompt engineering to compliance checking. Knowledge supplementation is applied to reduce interference and misjudgment among rules, lower prompt redundancy, and decrease the false-alarm rate during large language model review.Conclusions A large language model-driven data compliance checking method for IoT scenarios is presented. The method is designed to address the challenge of assessing compliance in large-scale unstructured device data. Its feasibility is verified through rationality analysis experiments, and the results indicate that false-positive rates are effectively reduced during compliance checking. The initial rule-based method yields a false-positive rate of 64.3%, which is reduced to 6.9% after review by the large language model. Additionally, the error introduced by the model itself is maintained below 0.01%. -
表 1 可行性研究实验结果
实验 方法 误报率 1 仅基于规则匹配检测 0.643 2 仅利用LLM检测1(LogGPT) 0.512 3 仅利用LLM检测2(LogPrompt) 0.554 4 规则匹配与大模型协同检测 0.069  下载: 导出CSV
下载: 导出CSV
表 2 原始设备数据集包含的所有违规类型
编号 数据违规类别 数目(条) 模糊匹配 精准匹配 a 设备保护信息 4 900 √ b 弱口令安全风险 8 779 √ c 敏感关键字 9 881 √ d 证件护照数据 7 124 √ e 私有链路及邮箱 5 713 √ f 人权歧视违规 6 840 √ g 涉政违规 5 820 √ h 其他违规行为 6 023 √ 总计 55 080 26 339 28 741
下载: 导出CSV
表 3 基于类别误报率的分层次提示词分类结果
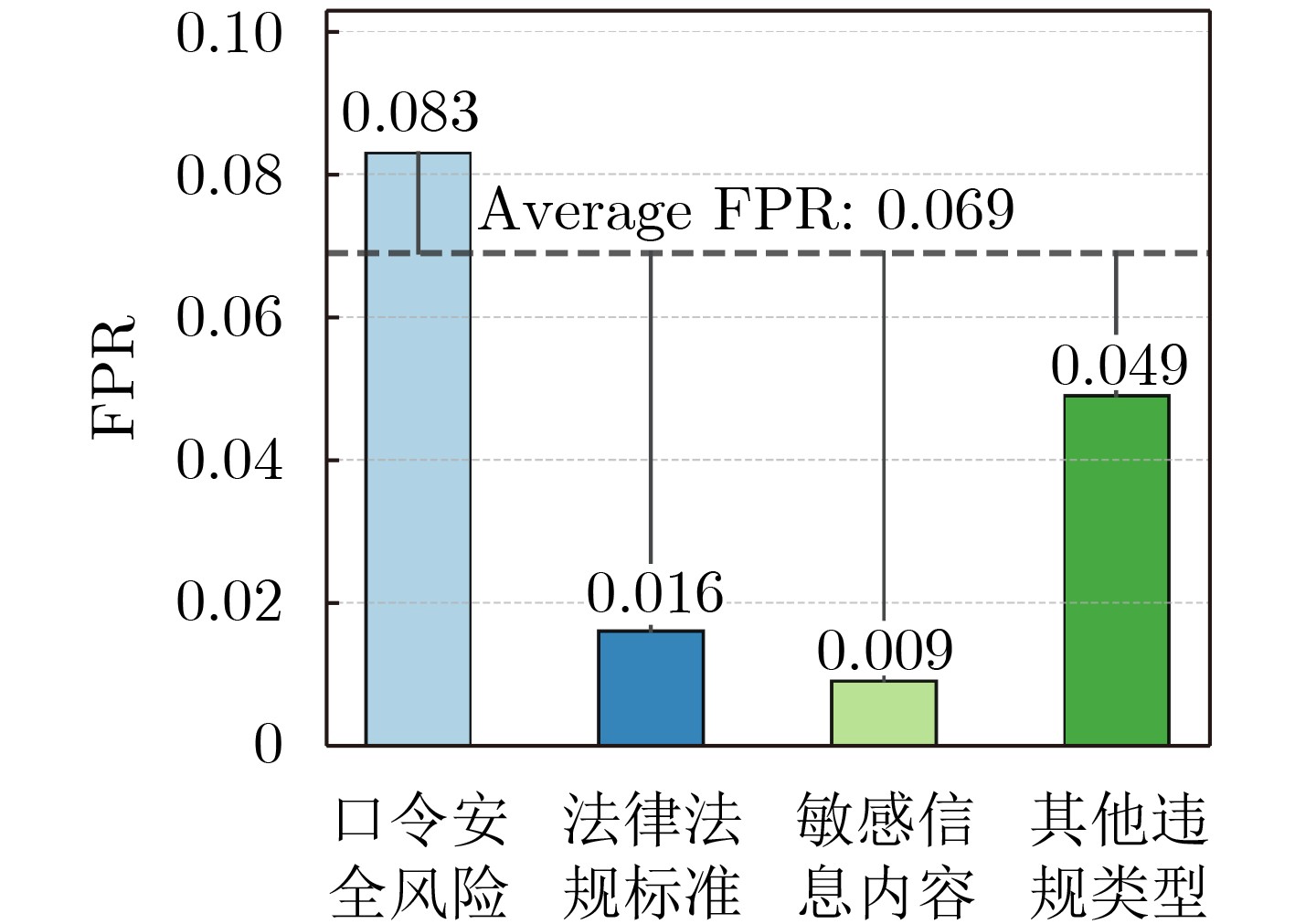
BCM归类 基于误报率的分类 知识补充 数目(条) 模糊匹配 口令安全风险b K1 8 779 法律法规标准f, g K2 17 560 精准匹配 敏感信息内容c K3 18 860 其他违规类型a, d, e, h K4 9 881
下载: 导出CSV
表 4 不同基准大模型的检测样本情况
数据
类型正则
匹配结果指标 Qw-7B Qw-32B DS-32B QwQ-32B DS-70B Qw-72B Qw3-235B DS-0528 违规(T) 19 695 TP 18 993 19 690 19 810 22 000 21 700 17 092 21 704 19 680 FN 1 177 5 550 215 317 3 263 520 492 合规(F) 35 385 TN 26 695 32 951 26 513 23 625 21 543 33 095 28 912 31 956 FP 8 215 2 434 8 207 9 240 11 520 1 630 3 944 2 952
下载: 导出CSV
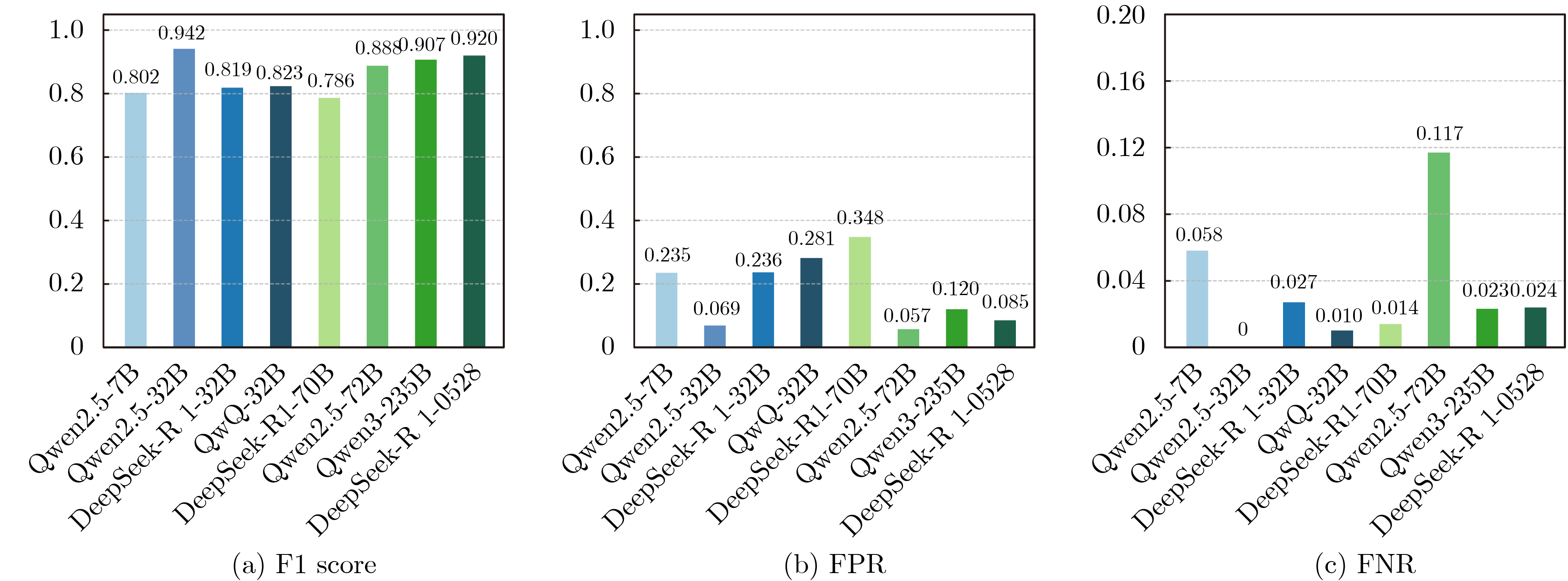
表 5 不同基准大模型的检测结果指标以及正则匹配错误率
指标 Qw-7B Qw-32B DS-32B QwQ-32B DS-70B Qw-72B Qw3-235B DS-0528 原始错误率:
0.643Acc. 0.829 0.956 0.841 0.828 0.785 0.922 0.919 0.937 Pre. 0.698 0.890 0.707 0.704 0.653 0.894 0.846 0.870 TPR 0.942 1.000 0.973 0.990 0.986 0.883 0.977 0.976 F1 0.802 0.942 0.819 0.823 0.786 0.888 0.907 0.920 FPR 0.235 0.069 0.236 0.281 0.348 0.057 0.120 0.085 FNR 0.058 0.01% 0.027 0.010 0.014 0.117 0.023 0.024
下载: 导出CSV
表 6 不同提示词方案的对比实验结果
提示词 方案 Acc. TPR FPR FNR F1 1 Common 0.68 0.83 0.59 0.17 0.77 2 CoT only 0.79 0.69 0.12 0.30 0.75 3 Few-Shot only 0.91 0.87 0.06 0.13 0.88 4 本文 0.96 1.00 0.06 0.01% 0.94
下载: 导出CSV
表 7 不同大模型系统角色提示词的影响
角色提示词 Acc. Pre. TPR FPR FNR F1 S1 0.79 0.60 0.94 0.27 0.06 0.74 S2 0.82 0.69 0.95 0.26 0.05 0.80 S3 0.82 0.70 0.99 0.28 0.01 0.82
下载: 导出CSV
表 8 分类提示词消融实验
模型 实验 Acc. Pre. TPR FPR FNR F1 Qwen2.5-32B None 0.91 0.79 0.99 0.12 0.01 0.88 Mix 0.88 0.79 0.97 0.18 0.03 0.87 Classification 0.95 0.89 1.00 0.06 0.01% 0.94 DS-R1-32B None 0.70 0.61 0.97 0.39 0.03 0.75 Mix 0.83 0.68 0.98 0.25 0.03 0.80 Classification 0.84 0.70 0.97 0.23 0.02 0.81
下载: 导出CSV
-
[1] 陈磊. 隐私合规视角下数据安全建设的思考与实践[J]. 保密科学技术, 2020(4): 39–46.CHEN Lei. Thoughts and practices on data security construction from a privacy compliance perspective[J]. Secrecy Science and Technology, 2020(4): 39–46. [2] 王融. 《欧盟数据保护通用条例》详解[J]. 大数据, 2016, 2(4): 93–101. doi: 10.11959/j.issn.2096-0271.2016045.WANG Rong. Deconstructing the EU general data protection regulation[J]. Big Data Research, 2016, 2(4): 93–101. doi: 10.11959/j.issn.2096-0271.2016045. [3] 安鹏, 喻波, 江为强, 等. 面向多样性数据安全合规检测系统的设计[J]. 信息安全研究, 2024, 10(7): 658–667. doi: 10.12379/j.issn.2096-1057.2024.07.09.AN Peng, YU Bo, JIANG Weiqiang, et al. Design of diversity data security compliance detection system[J]. Journal of Information Security Research, 2024, 10(7): 658–667. doi: 10.12379/j.issn.2096-1057.2024.07.09. [4] WANG Lun, KHAN U, NEAR J, et al. PrivGuard: Privacy regulation compliance made easier[C]. 31st USENIX Security Symposium (USENIX Security 22), Boston, USA, 2022: 3753–3770. [5] 李昕, 唐鹏, 张西珩, 等. 面向GDPR隐私政策合规性的智能化检测方法[J]. 网络与信息安全学报, 2023, 9(6): 127–139. doi: 10.11959/j.issn.2096-109x.2023088.LI Xin, TANG Peng, ZHANG Xiheng, et al. GDPR-oriented intelligent checking method of privacy policies compliance[J]. Chinese Journal of Network and Information Security, 2023, 9(6): 127–139. doi: 10.11959/j.issn.2096-109x.2023088. [6] 郭群, 张华熊, 王波, 等. 基于内容和上下文的敏感个人信息实体识别方法[J]. 软件工程, 2025, 28(2): 6–9,26. doi: 10.19644/j.cnki.issn2096-1472.2025.002.002.GUO Qun, ZHANG Huaxiong, WANG Bo, et al. Content and contextual sensitive personal information entity recognition method[J]. Software Engineering, 2025, 28(2): 6–9,26. doi: 10.19644/j.cnki.issn2096-1472.2025.002.002. [7] 张西珩, 李昕, 唐鹏, 等. 基于知识图谱的隐私政策合规性检测与分析[J]. 网络与信息安全学报, 2024, 10(6): 151–163. doi: 10.11959/j.issn.2096-109x.2024087.ZHANG Xiheng, LI Xin, TANG Peng, et al. Privacy policy compliance detection and analysis based on knowledge graph[J]. Chinese Journal of Network and Information Security, 2024, 10(6): 151–163. doi: 10.11959/j.issn.2096-109x.2024087. [8] MENG Weibin, LIU Ying, ZAITER F, et al. LogParse: Making log parsing adaptive through word classification[C]. 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, USA, 2020: 1–9. doi: 10.1109/ICCCN49398.2020.9209681. [9] HE Pinjia, ZHU Jieming, ZHENG Zibin, et al. Drain: An online log parsing approach with fixed depth tree[C]. 2017 IEEE International Conference on Web Services (ICWS), Honolulu, USA, 2017: 33–40. doi: 10.1109/ICWS.2017.13. [10] DU Min, LI Feifei, ZHENG Guineng, et al. DeepLog: Anomaly detection and diagnosis from system logs through deep learning[C]. The 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, USA, 2017: 1285–1298. doi: 10.1145/3133956.3134015. [11] MENG Weibin, LIU Ying, ZHU Yichen, et al. Loganomaly: Unsupervised detection of sequential and quantitative anomalies in unstructured logs[C]. The 28th International Joint Conference on Artificial Intelligence, Macao China, 2019: 4739–4745. [12] ZHANG Xu, XU Yong, LIN Qingwei, et al. Robust log-based anomaly detection on unstable log data[C]. The 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Tallinn Estonia, 2019: 807–817. doi: 10.1145/3338906.3338931. [13] 尹春勇, 张杨春. 基于CNN和Bi-LSTM的无监督日志异常检测模型[J]. 计算机应用, 2023, 43(11): 3510–3516 doi: 10.19678/j.issn.1000-3428.0061750.Yin C Y and Zhang Y C. Unsupervised log anomaly detection model based on CNN and Bi-LSTM[J]. J. Journal of Computer Applications, 2023, 43(11): 3510–3516 doi: 10.19678/j.issn.1000-3428.0061750. [14] QI Jiaxing, HUANG Shaohan, LUAN Zhongzhi, et al. LogGPT: Exploring ChatGPT for log-based anomaly detection[C]. 2023 IEEE International Conference on High Performance Computing & Communications, Data Science & Systems, Smart City & Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Melbourne, Australia, 2023: 273–280. doi: 10.1109/HPCC-DSS-SmartCity-DependSys60770.2023.00045. [15] LIU Yilun, TAO Shimin, MENG Weibin, et al. LogPrompt: Prompt engineering towards zero-shot and interpretable log analysis[C]. The 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings, Lisbon, Portugal, 2024: 364–365. doi: 10.1145/3639478.3643108. [16] XIANG Jinyu, ZHANG Jiayi, YU Zhaoyang, et al. Self-Supervised Prompt Optimization. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 9017–9041, Suzhou, China. Association for Computational Linguistics. doi: 10.18653/v1/2025.findings-emnlp.479. [17] GUAN Wei, CAO Jian, QIAN Shiyou, et al. LogLLM: Log-based anomaly detection using large language models[EB/OL]. arXiv preprint arXiv: 2411.08561, 2024. doi: 10.48550/arXiv.2411.08561. [18] ELHAFSI A, SINHA R, AGIA C, et al. Semantic anomaly detection with large language models[J]. Autonomous Robots, 2023, 47(8): 1035–1055. doi: 10.1007/s10514-023-10132-6. [19] YANG Tiankai, NIAN Yi, LI Li, et al. AD-LLM: Benchmarking large language models for anomaly detection[C]. Findings of the Association for Computational Linguistics: ACL 2025, Vienna, Austria, 2025: 1524–1547. doi: 10.18653/v1/2025.findings-acl.79. [20] OLINER A and STEARLEY J. What supercomputers say: A study of five system logs[C]. 37th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN'07), Edinburgh, UK, 2007: 575–584. doi: 10.1109/DSN.2007.103. [21] DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. The 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota, 2019: 4171–4186. doi: 10.18653/v1/N19-1423. [22] WEI J, WANG Xuezhi, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1800. [23] BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 159. [24] BAI Jinze, BAI Shuai, CHU Yunfei, et al. Qwen technical report[EB/OL]. arXiv preprint arXiv: 2309.16609, 2023. doi: https://doi.org/10.48550/arXiv.2412.15115 [25] Team Q. Qwq-32b: Embracing the power of reinforcement learning[EB/OL].(2025-3) [26] GUO Daya, YANG Dejian, ZHANG Haowei, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature 645, 633–638 (2025) doi: https://doi.org/10.1038/s41586-025-09422-z. [27] HOLTZMAN A, BUYS J, DU Li, et al. The curious case of neural text degeneration[J]. International Conference on Learning Representations, 2020. doi: https://doi.org/10.48550/arXiv.1904.09751. [28] XIAO Chaojun, CAI Jie, ZHAO Weilin, et al. Densing law of llms[J]. Nature Machine Intelligence, 2025: 1–11. doi: https://doi.org/10.48550/arXiv.2412.04315. [29] KAPLAN J, MCCANDLISH S, HENIGHAN T, et al. Scaling laws for neural language models[EB/OL]. arXiv preprint arXiv: 2001.08361, 2020. doi: https://doi.org/10.48550/arXiv.2001.08361. [30] WU Jun, WEN Jiangtao, and HAN Yuxing. BackSlash: Rate constrained optimized training of large language models[C]. Proceedings of the 42nd International Conference on Machine Learning, PMLR 267:67852-67863, 2025. doi: https://doi.org/10.48550/arXiv.2504.16968. -


 下载:
下载:
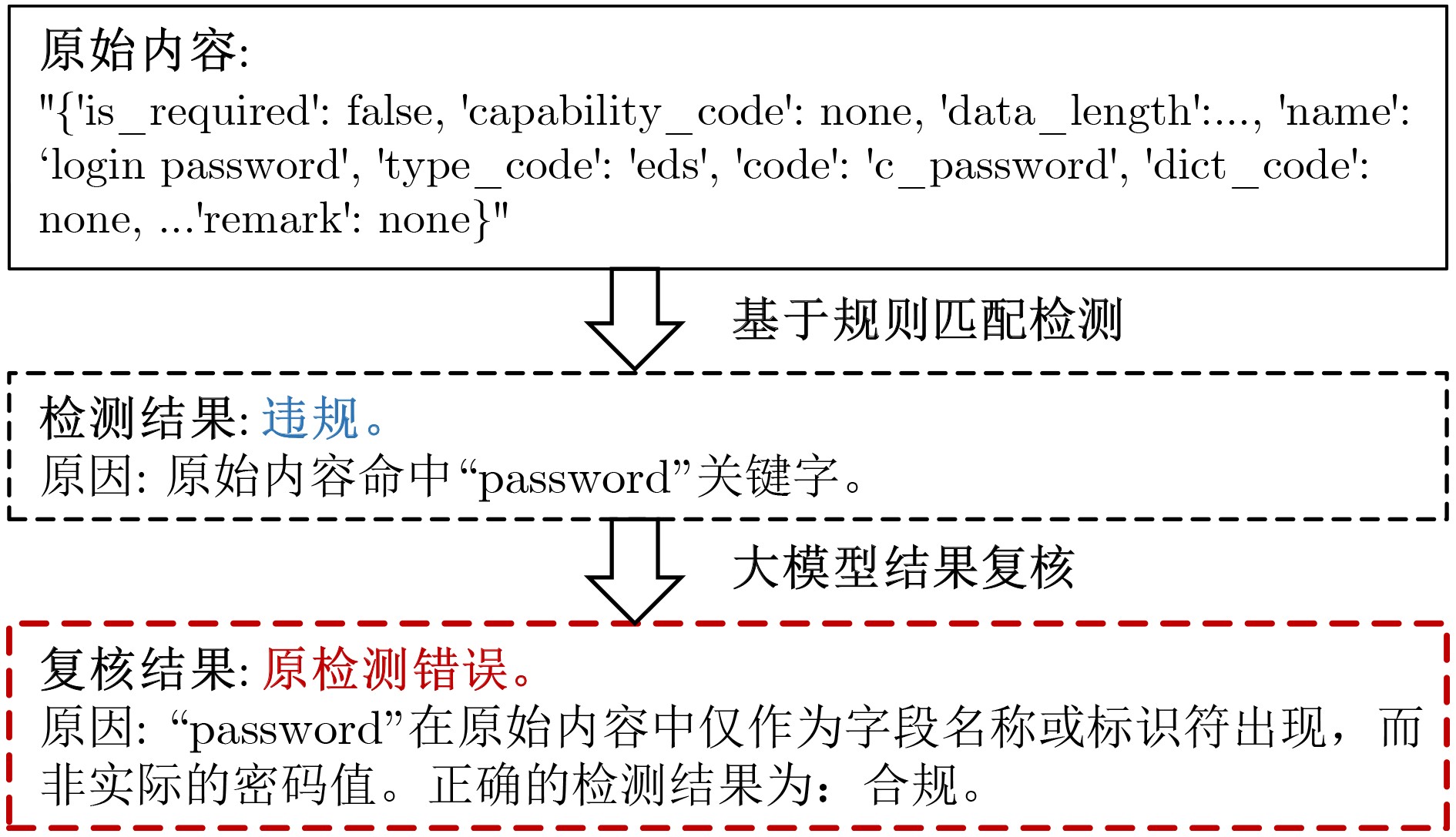
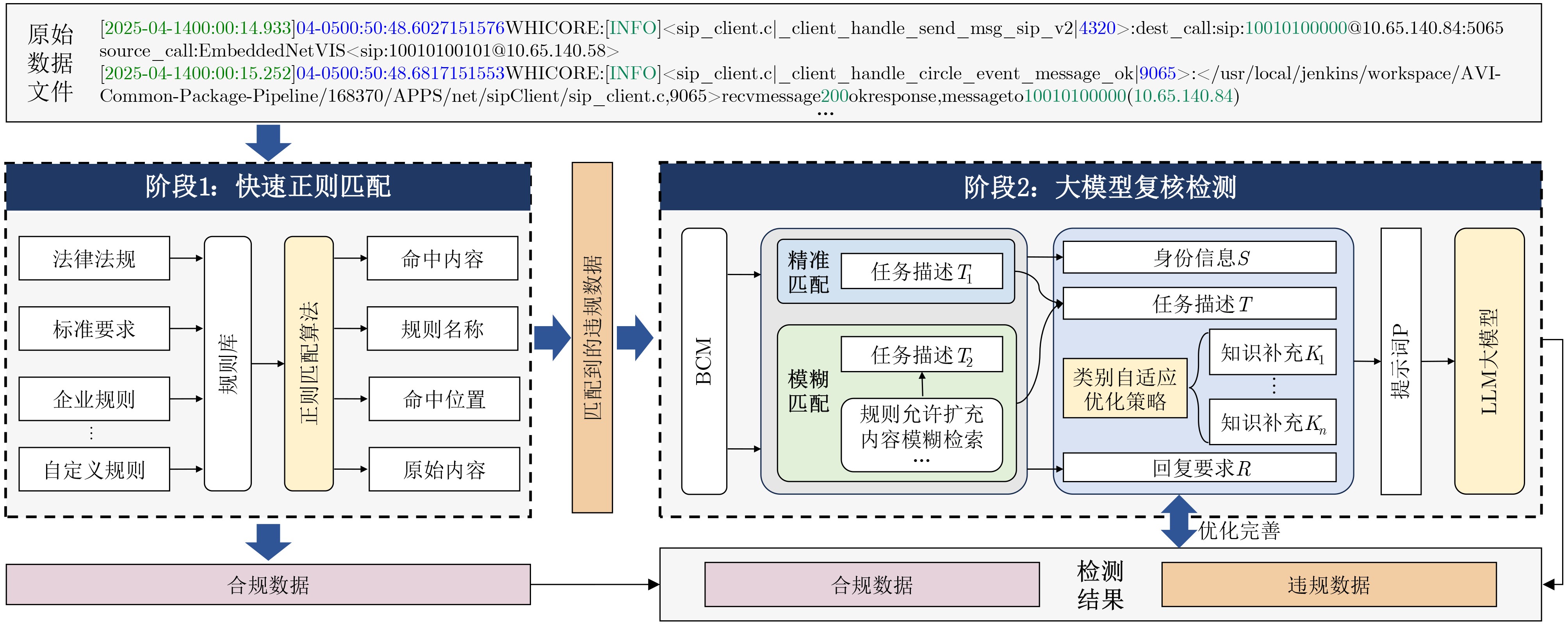

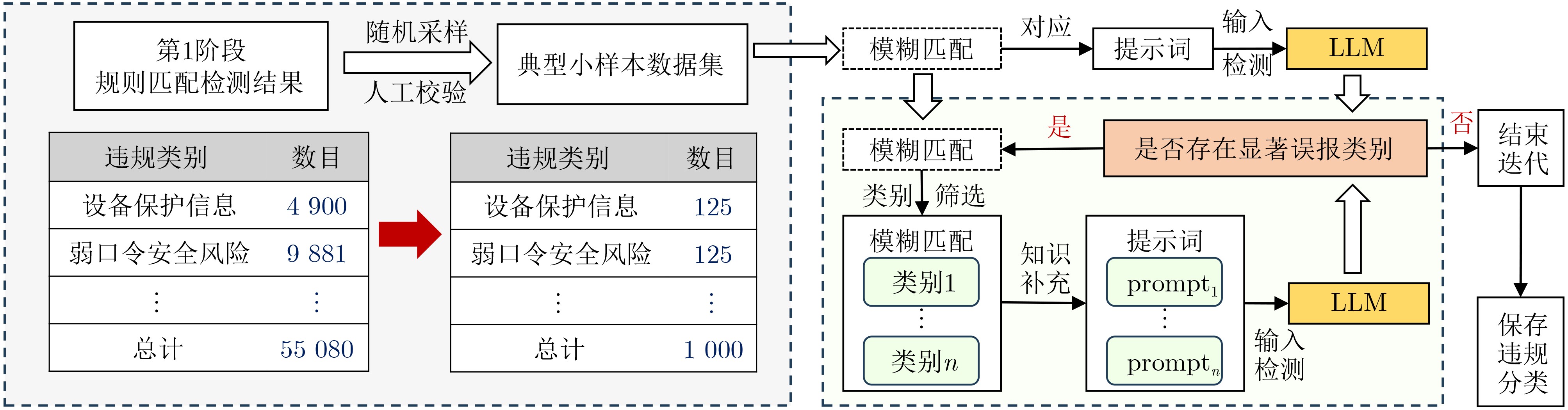



图(8) / 表(8)
计量
- 文章访问数: 784
- HTML全文浏览量: 423
- PDF下载量: 75
- 被引次数: 0
