

Collaborative Inference for Large Language Models Against Jamming Attacks
-
摘要: 大语言模型协同推断技术利用边缘服务器的算力增强推断性能,但在干扰攻击下由于数据卸载的时延和丢包大幅增加,导致推断任务完成率和速度等性能下降。为此,该文提出面向大语言模型的抗干扰协同推断方案,采用强化学习根据推断任务类型、多模态数据量大小、设备间信道增益和干扰强度等信息优化选择边缘服务器、大语言模型的稀疏率和量化精度、数据卸载的发射功率和传输信道。基于逐层无结构剪枝算法和参数量化技术部署不同稀疏率和量化精度的大语言模型,处理图片、文本、视频和温湿度等多模态数据的词元向量,以满足多样化任务的推断精度和速度需求。根据数据卸载的时延和丢包率评估推断性能下降的风险等级,避免选择可能使任务失败的抗干扰协同推断策略。最后,搭建移动无人车抗干扰协同推断系统,部署大语言模型LLaVA-1.5-7B以图片和文本数据为输入,支撑移动终端的人机问答和决策辅助等推断任务。实验结果表明,该方案可提升智能干扰攻击下的推断任务完成率、精度和速度。Abstract:
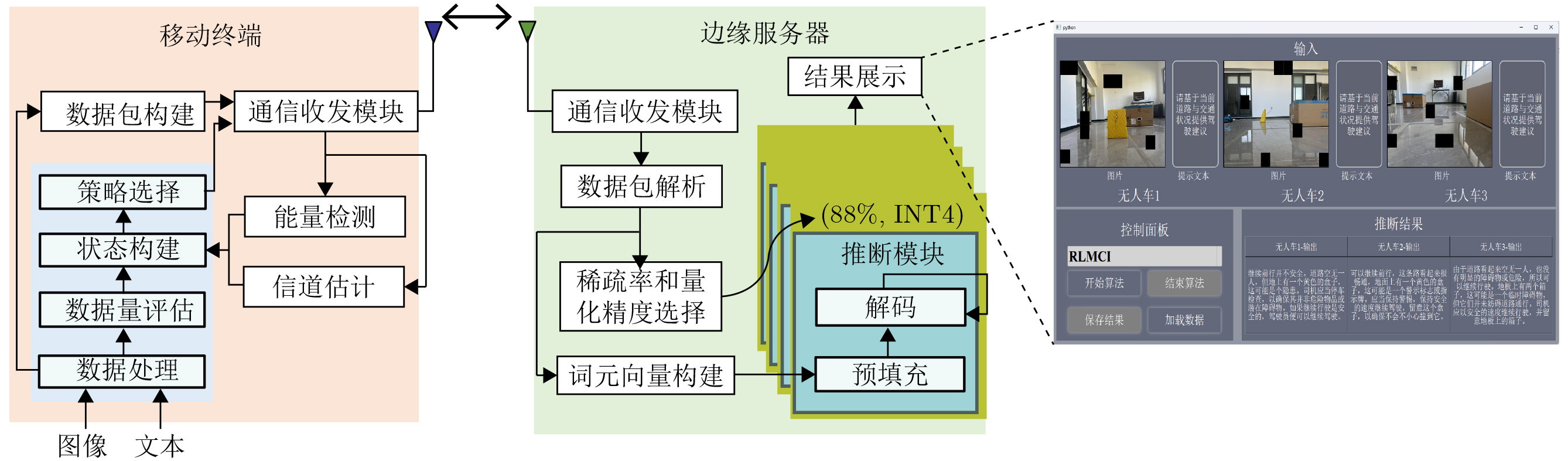
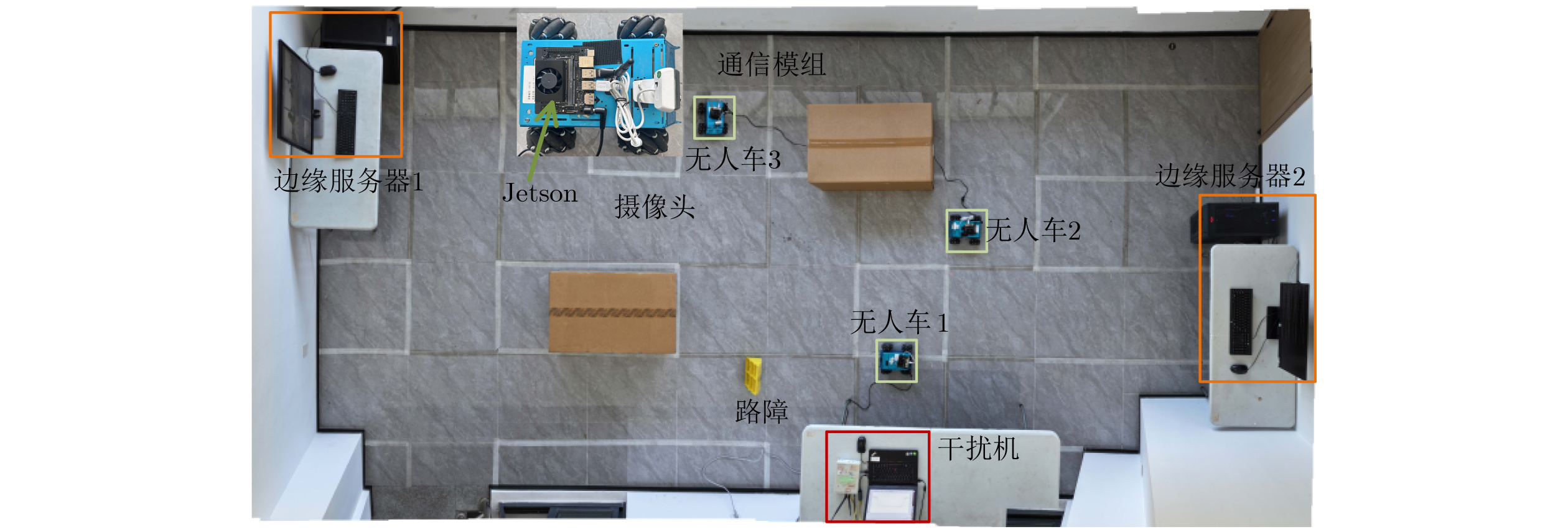
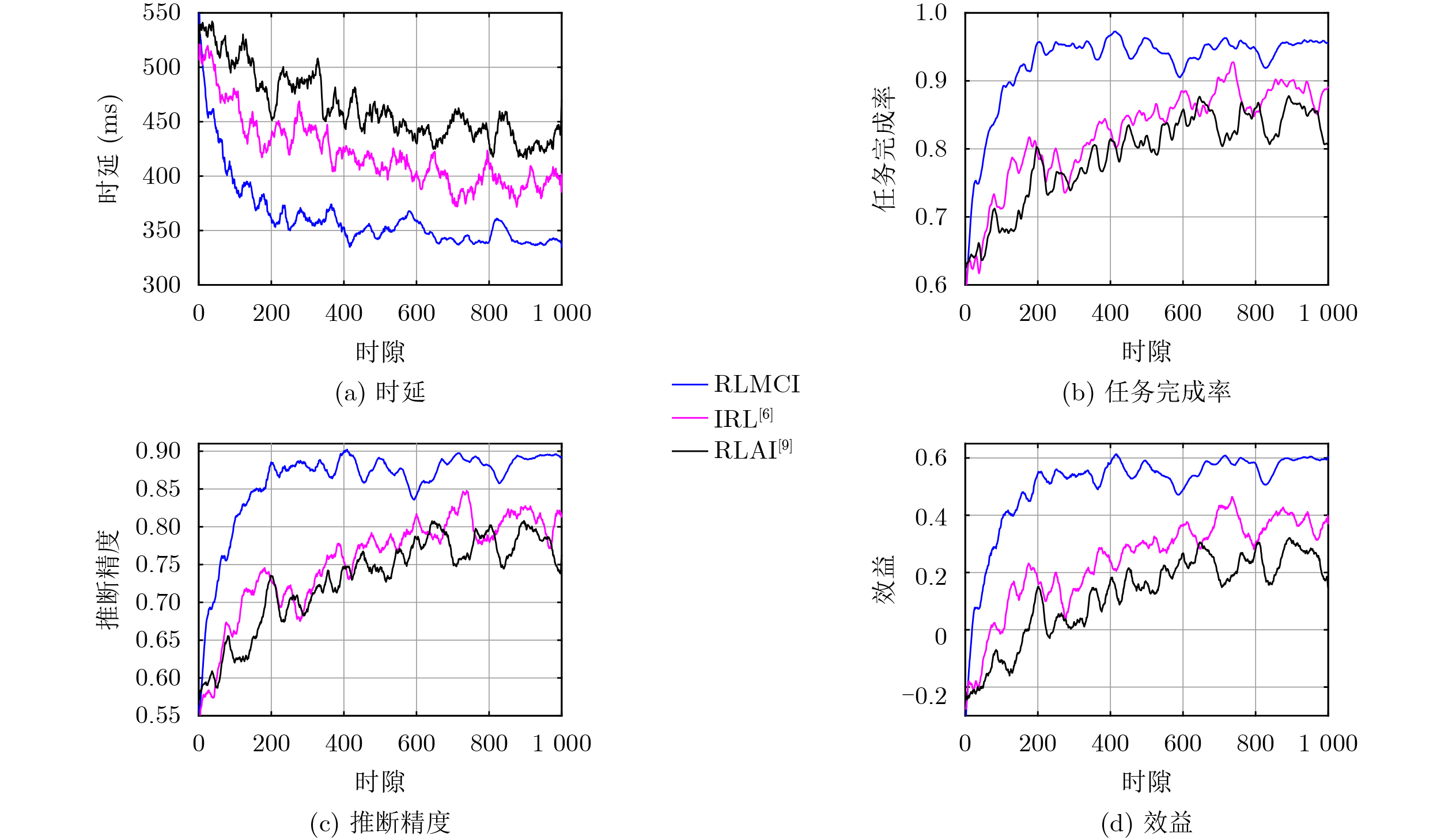
Objective Collaborative inference with Large Language Models (LLMs) is employed to enable mobile devices to offload multi-modal data, including images, text, video, and environmental information such as temperature and humidity, to edge servers. This offloading improves the performance of inference tasks such as human-computer question answering, logical reasoning, and decision support. Jamming attacks, however, increase transmission latency and packet loss, which reduces task completion rates and slows inference. A reinforcement learning-based collaborative inference scheme is proposed to enhance inference speed, accuracy, and task completion under jamming conditions. LLMs with different sparsity levels and quantization precisions are deployed on edge servers to meet heterogeneous inference requirements across tasks. Methods A reinforcement learning-based collaborative inference scheme is proposed to enhance inference accuracy, speed, and task completion under jamming attacks. The scheme jointly selects the edge servers, sparsity rates and quantization levels of LLMs, as well as the transmit power and channels for data offloading, based on task type, data volume, channel gains, and received jamming power. A policy risk function is formulated to quantify the probability of inference task failure given offloading latency and packet loss rate, thereby reducing the likelihood of unsafe policy exploration. Each edge server deploys LLMs with varying sparsity rates and quantization precisions, derived from layer-wise unstructured pruning and model parameter quantization, to process token vectors of multi-modal data including images, text, video, and environmental information such as temperature and humidity. This configuration is designed to meet diverse requirements for inference accuracy and speed across different tasks. The LLM inference system is implemented with mobile devices offloading images and text to edge servers for human-computer question answering and driving decision support. The edge servers employ a vision encoder and tokenizer to transform the received sensing data into token vectors, which serve as inputs to the LLMs. Pruning and parameter quantization are applied to the foundation model LLaVA-1.5-7B, generating nine LLM variants with different sparsity rates and quantization precisions to accommodate heterogeneous inference demands. Results and Discussions Experiments are conducted with three vehicles offloading images (i.e., captured traffic scenes) and texts (i.e., user prompts) using a maximum transmit power of 100 mW on 5.735~5.835 MHz frequency channels. The system is evaluated against a smart jammer that applies Q-learning to block one of the 20 MHz channels within this band. The results show consistent performance gains over benchmark schemes. Faster responses and more accurate driving advice are achieved, enabled by reduced offloading latency and lower packet loss in image transmission, which allow the construction of more complete traffic scenes. Over 20 repeated runs, inference speed is improved by 20.3%, task completion rate by 14.1%, and inference accuracy by 12.2%. These improvements are attributed to the safe exploration strategy, which prevents performance degradation and satisfies diverse inference requirements across tasks. Conclusions This paper proposed a reinforcement learning-based collaborative inference scheme that jointly selects the edge servers, sparsity rates and quantization levels of LLMs, as well as the transmit power and offloading channels, to counter jamming attacks. The inference system deploys nine LLM variants with different sparsity rates and quantization precisions for human-computer question answering and driving decision support, thereby meeting heterogeneous requirements for accuracy and speed. Experimental results demonstrate that the proposed scheme provides faster responses and more reliable driving advice. Specifically, it improves inference speed by 20.3%, task completion rate by 14.1%, and accuracy by 12.2%, achieved through reduced offloading latency and packet loss compared with benchmark approaches. -
表 1 重要符号列表
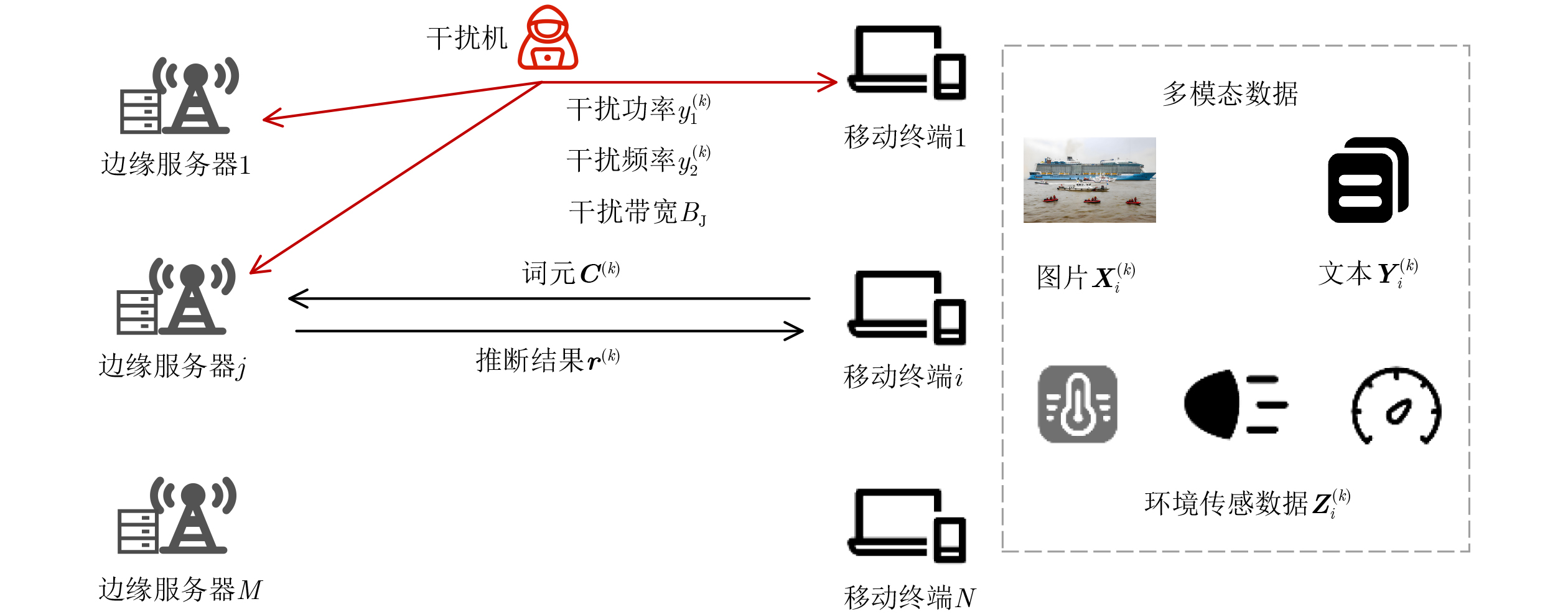
符号 含义 $N$ 移动设备数量 $M$ 边缘服务器数量 $F$ 信道数量 ${\varphi ^{(k)}}$ 推断业务类型 ${{\boldsymbol{X}}^{(k)}}$/${{\boldsymbol{Y}}^{(k)}}$/${{\boldsymbol{Z}}^{(k)}}$ 图片/文本/环境传感数据 ${\boldsymbol{{C}}^{(k)}}$ 多模态数据的词元向量 $T$ 词元向量最大长度 $b_i^{(k)}$ 数据量大小 $ {o^{\left( k \right)}} $ 大语言模型的稀疏率 ${g^{(k)}}$ 参数权重量化水平 $ h_{i,j}^{(k)} $ 终端$ i $和服务器$ j $间的信道增益 $f_i^{(k)}$ 传输信道 $p_i^{(k)}$ 发射功率 $y_1^{(k)}$ 干扰功率 $y_2^{(k)}$ 干扰频率 ${B_{\mathrm{J}}}$ 干扰带宽 ${\gamma ^{(k)}}$ 信干噪比 ${\chi ^{(k)}}$ 干扰信号强度 ${r^{(k)}}$ 推断结果 ${t_1}^{(k)}$ 传输时延 ${t_2}^{(k)}$ 推断时延 ${\beta ^{(k)}}$ 推断精度 ${\rho ^{(k)}}$ 任务完成率  下载: 导出CSV
下载: 导出CSV
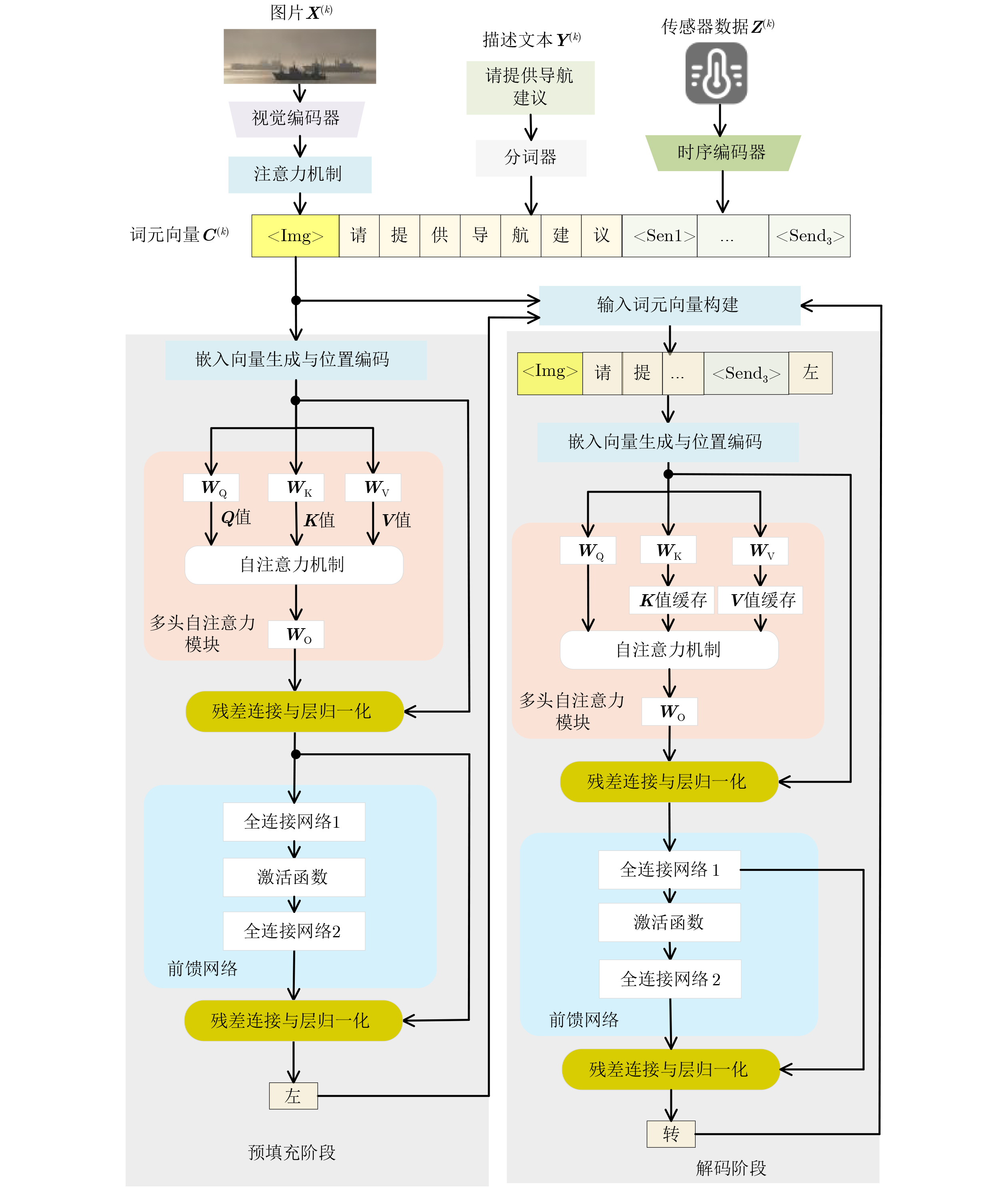
1 基于强化学习的大语言模型抗干扰协同推断
(1) 初始化$ {\mu _l}_{,1} $, $ {\mu _l}_{,2} $, $ {c_l}_{,1} $, $ {c_l}_{,2} $ (2) For k = 1, 2, … do (3) 评估数据量大小$ b $ (4) 估计与边缘服务器间的信道增益$ {\boldsymbol{h}} $ (5) 测量干扰信号强度$ {\boldsymbol{\chi}} $ (6) 根据式(3)构建状态$ {{\boldsymbol{s}}^{(k)}} $ (7) 输入$ {{\boldsymbol{s}}^{(k)}} $到策略网络获取协同推断策略的长期效益值和风险值 (8) 根据式(4)构建策略分布 (9) 选择发射功率$ p $在信道$ f $上将多模态数据卸载到边缘服务器$ x $ (10) 选择大语言模型的稀疏率$ o $和参数量化精度$ g $ (11) 接收推断结果$ {\boldsymbol{r }}$,任务完成率$ \rho $,精度$ \beta $和时延$ t $ (12) 根据式(5)计算效益$ u $ (13) 根据式(6)计算策略的风险值$ q $ (14) 构建经验并存入经验池 (15) 均匀随机采样$ Z $条经验样本$\mathcal{B}$ (16) 根据式(7)和式(8)更新神经网络参数${\boldsymbol{ \omega}} $和$ {\boldsymbol{\theta}} $ (17) End For
下载: 导出CSV
-
[1] 任磊, 王海腾, 董家宝, 等. 工业大模型: 体系架构、关键技术与典型应用[J]. 中国科学: 信息科学, 2024, 54(11): 2606–2622. doi: 10.1360/SSI-2024-0185.REN Lei, WANG Haiteng, DONG Jiabao, et al. Industrial foundation model: Architecture, key technologies, and typical applications[J]. SCIENTIA SINICA Informationis, 2024, 54(11): 2606–2622. doi: 10.1360/SSI-2024-0185. [2] 张青龙, 韩锐, 刘驰. 云边协同大模型块粒度重训方法[J]. 电子学报, 2025, 53(2): 287–300. doi: 10.12263/DZXB.20240518.ZHANG Qinglong, HAN Rui, and LIU Chi. Cloud-edge collaborative retraining of foundation models at the block granularity[J]. Acta Electronica Sinica, 2025, 53(2): 287–300. doi: 10.12263/DZXB.20240518. [3] WU Shengqiong, FEI Hao, QU Lweiji, et al. NExT-GPT: Any-to-any multimodal LLM[C]. The 41st International Conference on Machine Learning (ICML), Vienna, Austria, 2024: 1–37. [4] ZHOU Zixuan, NING Xuefei, HONG Ke, et al. A survey on efficient inference for large language models[EB/OL]. https://arxiv.org/abs/2404.14294, 2024. [5] DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning[EB/OL]. https://arxiv.org/abs/2501.12948, 2025. [6] REN Yuzheng, ZHANG Haijun, YU F R, et al. Industrial internet of things with large language models (LLMs): An intelligence-based reinforcement learning approach[J]. IEEE Transactions on Mobile Computing, 2025, 24(5): 4136–4152. doi: 10.1109/TMC.2024.3522130. [7] ZHANG Xinyuan, NIE Jiangtian, HUANG Yudong, et al. Beyond the cloud: Edge inference for generative large language models in wireless networks[J]. IEEE Transactions on Wireless Communications, 2025, 24(1): 643–658. doi: 10.1109/TWC.2024.3497923. [8] MOHAMMED T, JOE-WONG C, BABBAR R, et al. Distributed inference acceleration with adaptive DNN partitioning and offloading[C]. The IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, Canada, 2020: 854–863. doi: 10.1109/INFOCOM41043.2020.9155237. [9] HE Ying, FANG Jingcheng, YU F R, et al. Large language models (LLMs) inference offloading and resource allocation in cloud-edge computing: An active inference approach[J]. IEEE Transactions on Mobile Computing, 2024, 23(12): 11253–11264. doi: 10.1109/TMC.2024.3415661. [10] BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 159. [11] ALAYRAC J B, DONAHUE J, LUC P, et al. Flamingo: A visual language model for few-shot learning[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1723. [12] KOH J Y, FRIED D, and SALAKHUTDINOV R R. Generating images with multimodal language models[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 939. [13] LIU Shilong, ZENG Zhaoyang, REN Tianhe, et al. Grounding DINO: Marrying dino with grounded pre-training for open-set object detection[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2024: 38–55. DOI: 10.1007/978-3-031-72970-6_3. [14] XIE Gaochang, XIONG Zehui, ZHANG Xinyuan, et al. GAI-IOV: Bridging generative AI and vehicular networks for ubiquitous edge intelligence[J]. IEEE Transactions on Wireless Communications, 2024, 23(10): 12799–12814. doi: 10.1109/TWC.2024.3396276. [15] YU Zhongzhi, WANG Zheng, LI Yuhan, et al. EDGE-LLM: Enabling efficient large language model adaptation on edge devices via unified compression and adaptive layer voting[C]. Proceedings of the 61st ACM/IEEE Design Automation Conference, San Francisco, USA, 2024: 1–6. DOI: 10.1145/3649329.3658473. [16] FRANTAR E and ALISTARH D. SparseGPT: Massive language models can be accurately pruned in one-shot[C]. The 40th International Conference on Machine Learning, Honolulu, USA, 2023: 414. [17] FRANTAR E, ASHKBOOS S, HOEFLER T, et al. OPTQ: Accurate post-training quantization for generative pre-trained transformers[C]. The 40th International Conference on Machine Learning, Kigali, Rwanda, 2023: 1–16. [18] FRANTAR E, KURTIC E, and ALISTARH D. M-FAC: Efficient matrix-free approximations of second-order information[C]. The 35th International Conference on Neural Information Processing Systems, 2021: 1140. [19] MA Xinyin, FANG Gongfan, and WANG Xiachao. LLM-pruner: On the structural pruning of large language models[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 950. [20] CHEN M H, LIANG Ben, and DONG Min. Multi-user multi-task offloading and resource allocation in mobile cloud systems[J]. IEEE Transactions on Wireless Communications, 2018, 17(10): 6790–6805. doi: 10.1109/TWC.2018.2864559. [21] NGUYEN M D, AJIB W, ZHU Weiping, et al. Integrated user association, computation offloading, resource allocation, and UAV trajectory control against jamming for UAV-based wireless networks[J]. IEEE Transactions on Wireless Communications, 2025, 24(7): 5588–5604. doi: 10.1109/TWC.2025.3547975. [22] LV Zefang, XIAO Liang, DU Yousong, et al. Multi-agent reinforcement learning based UAV swarm communications against jamming[J]. IEEE Transactions on Wireless Communications, 2023, 22(12): 9063–9075. doi: 10.1109/TWC.2023.3268082. [23] LIN Zhiping, XIAO Liang, CHEN Hongyi, et al. Edge-assisted collaborative perception against jamming and interference in vehicular networks[J]. IEEE Transactions on Wireless Communications, 2025, 24(1): 860–874. doi: 10.1109/TWC.2024.3510601. [24] XIAO Liang, LU Xiaozhen, XU Tangwei, et al. Reinforcement learning-based mobile offloading for edge computing against jamming and interference[J]. IEEE Transactions on Communications, 2020, 68(10): 6114–6126. doi: 10.1109/TCOMM.2020.3007742. [25] QU Guanqiao, CHEN Qiyuan, WEI Wei, et al. Mobile edge intelligence for large language models: A contemporary survey[J]. IEEE Communications Surveys & Tutorials, 2025. doi: 10.1109/COMST.2025.3527641. [26] AGRAWAL A, KEDIA N, PANWAR A, et al. Taming throughput-latency tradeoff in LLM inference with Sarathi-Serve[C]. The 18th USENIX Symposium on Operating Systems Design and Implementation, Santa Clara, USA, 2024: 117–134. [27] GIRDHAR R, EL-NOUBY A, LIU Zhuang, et al. ImageBind one embedding space to bind them all[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 15180–15190. doi: 10.1109/CVPR52729.2023.01457. [28] SHANKAR S, ZAMFIRESCU-PEREIRA J D, HARTMANN B, et al. Who validates the validators? aligning LLM-assisted evaluation of LLM outputs with human preferences[C]. Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, Pittsburgh, USA, 2024: 131. doi: 10.1145/3654777.3676450. -

 下载:
下载:



图(6) / 表(2)
计量
- 文章访问数: 842
- HTML全文浏览量: 466
- PDF下载量: 98
- 被引次数: 0
