

Research on Segmentation Algorithm of Oral and Maxillofacial Panoramic X-ray Images under Dual-domain Multiscale State Space Network
-
摘要: 针对口腔颌面全景X射线图像中存在的形态变异显著、牙体-牙龈边界模糊以及牙周组织灰度值重叠等问题,该研究提出基于双域多尺度状态空间网络的口腔颌面全景X射线图像分割算法。空间域利用视觉状态空间块建立牙弓动态传播模型,并利用微分方程实现跨象限长程关联捕捉。特征域构建可变形多尺度注意力金字塔,并利用通道-空间注意力动态加权关键解剖标志的灰度渐变特征,解析牙体-牙龈模糊边界。双域特征进一步通过三重注意力融合机制,强化解剖标注的语义表达。实验表明,该算法在颌面全景X射线图像分割任务中取得显著效果,戴斯系数(Dice)达93.8%,豪斯多夫距离(HD95)为18.73像素,充分验证了算法的有效性。
-
关键词:
- 口腔颌面全景X射线图像分割 /
- 视觉状态空间块 /
- 可变形多尺度注意力金字塔 /
- 三重注意力融合
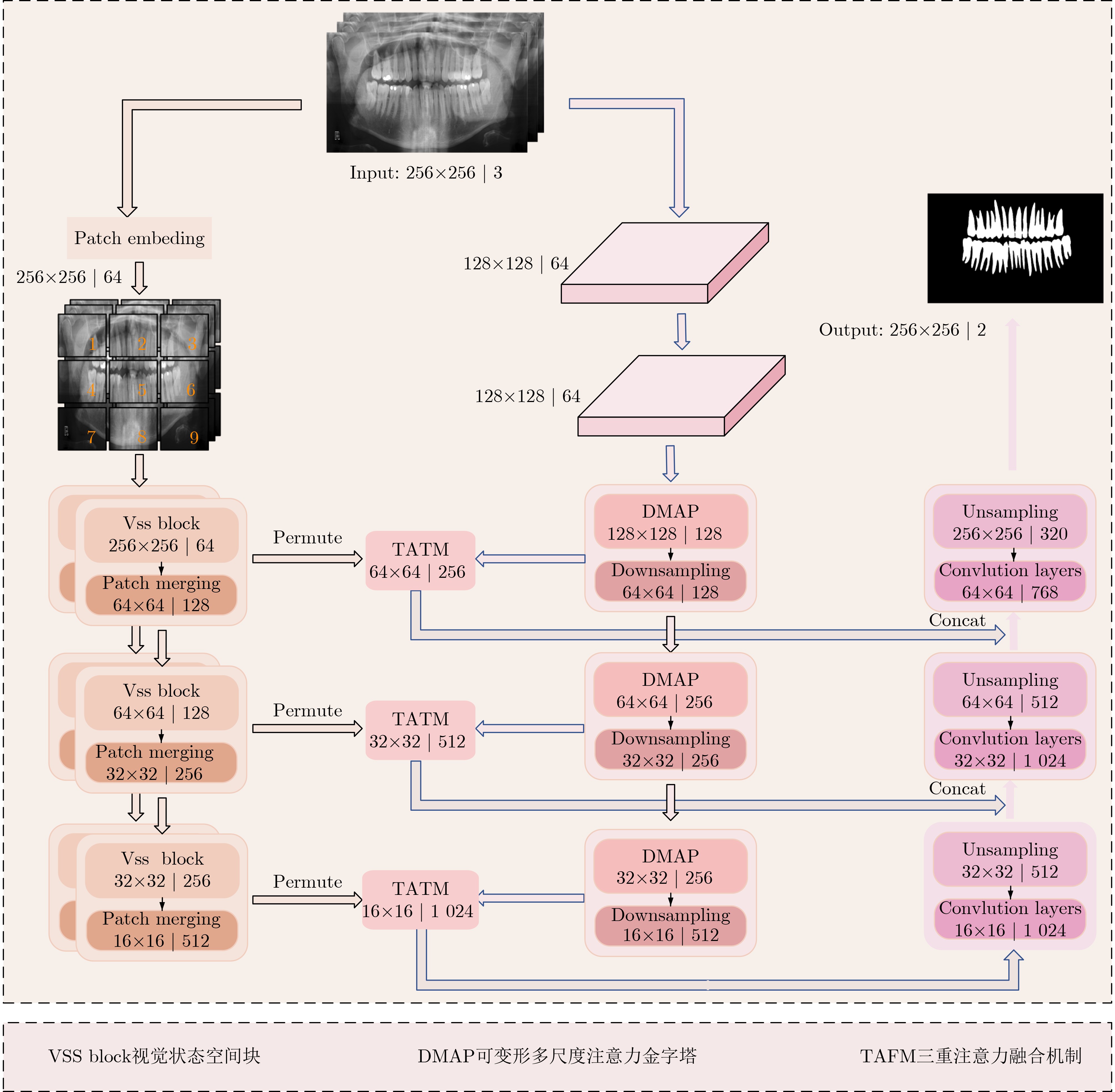
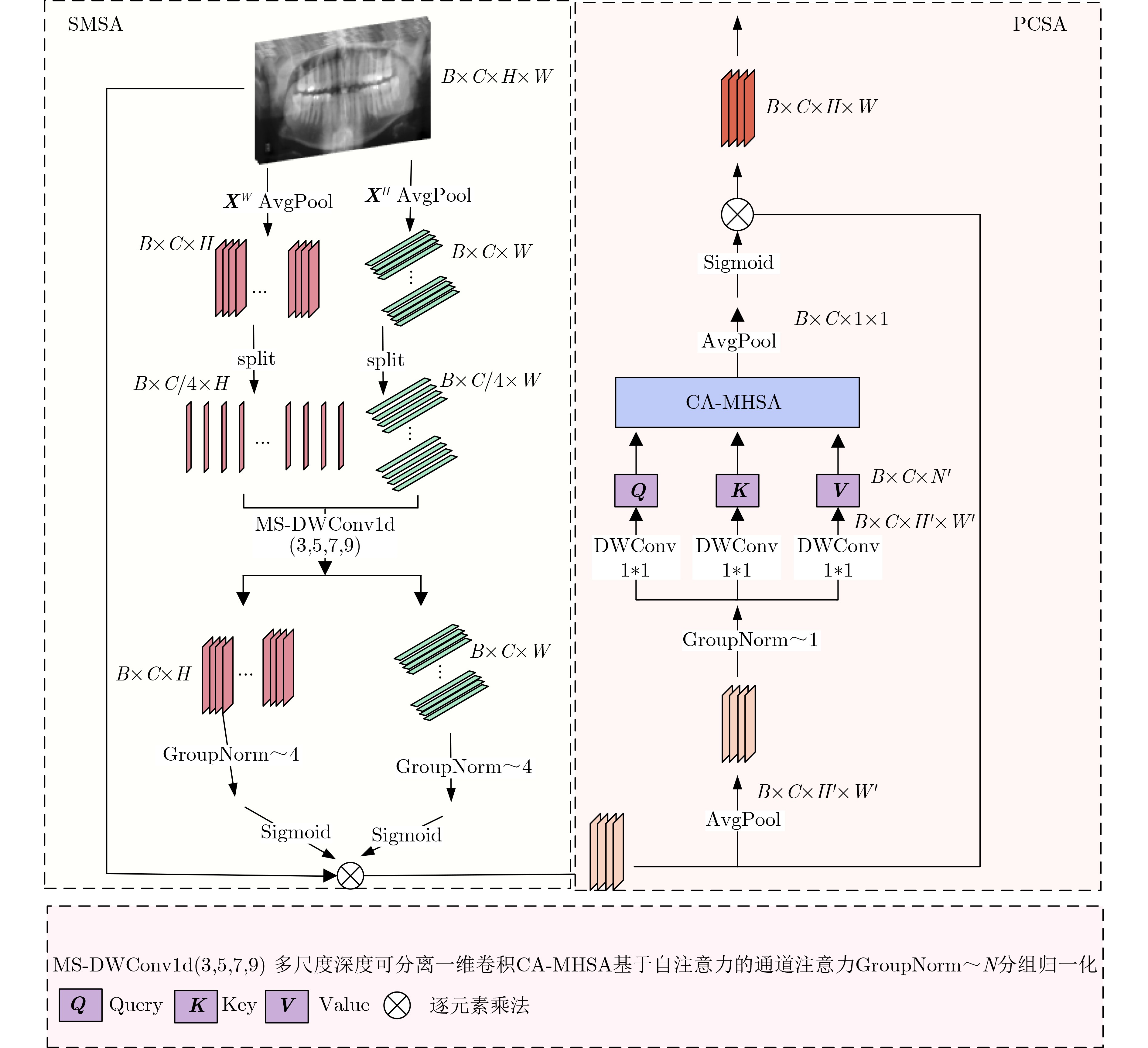
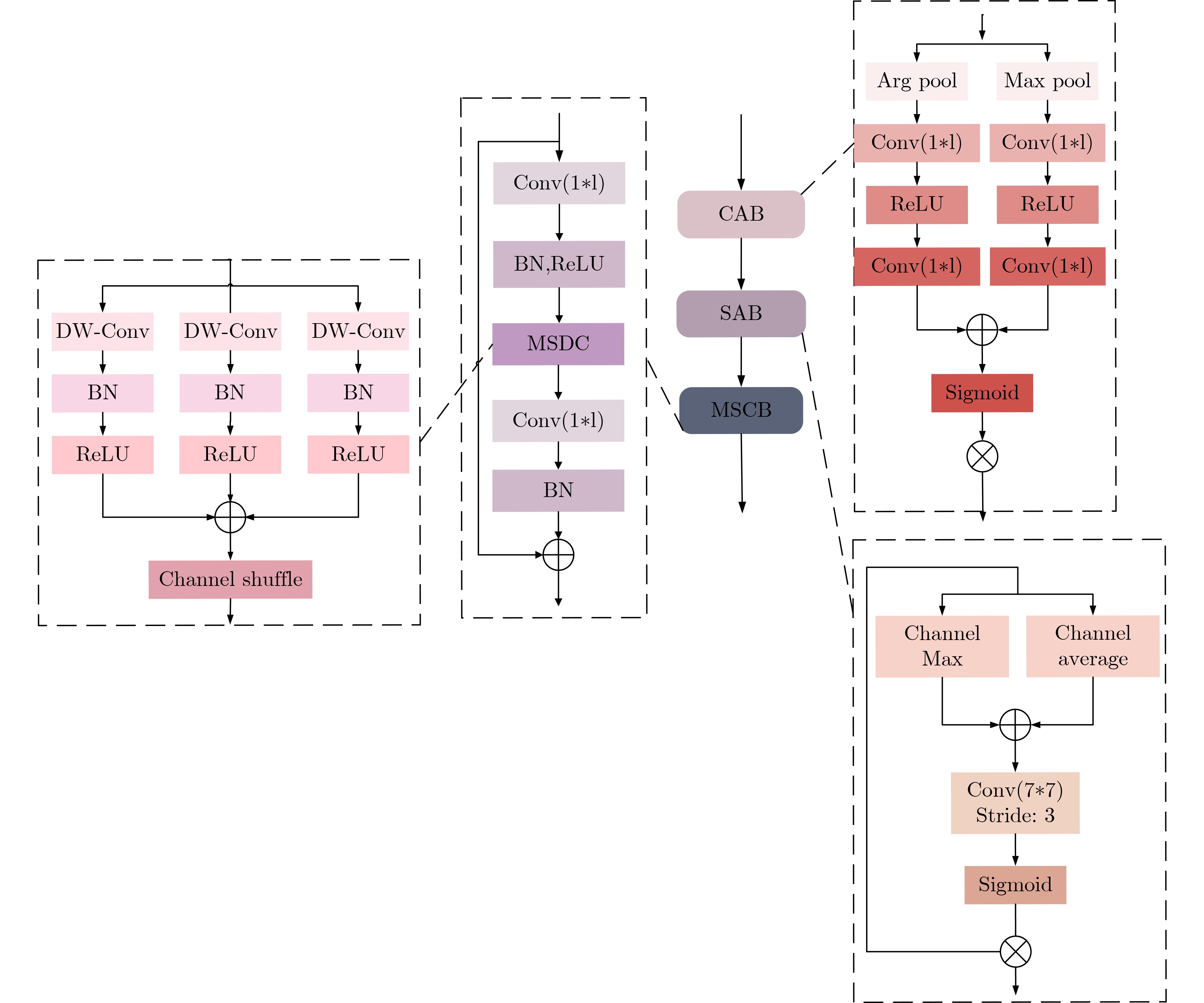
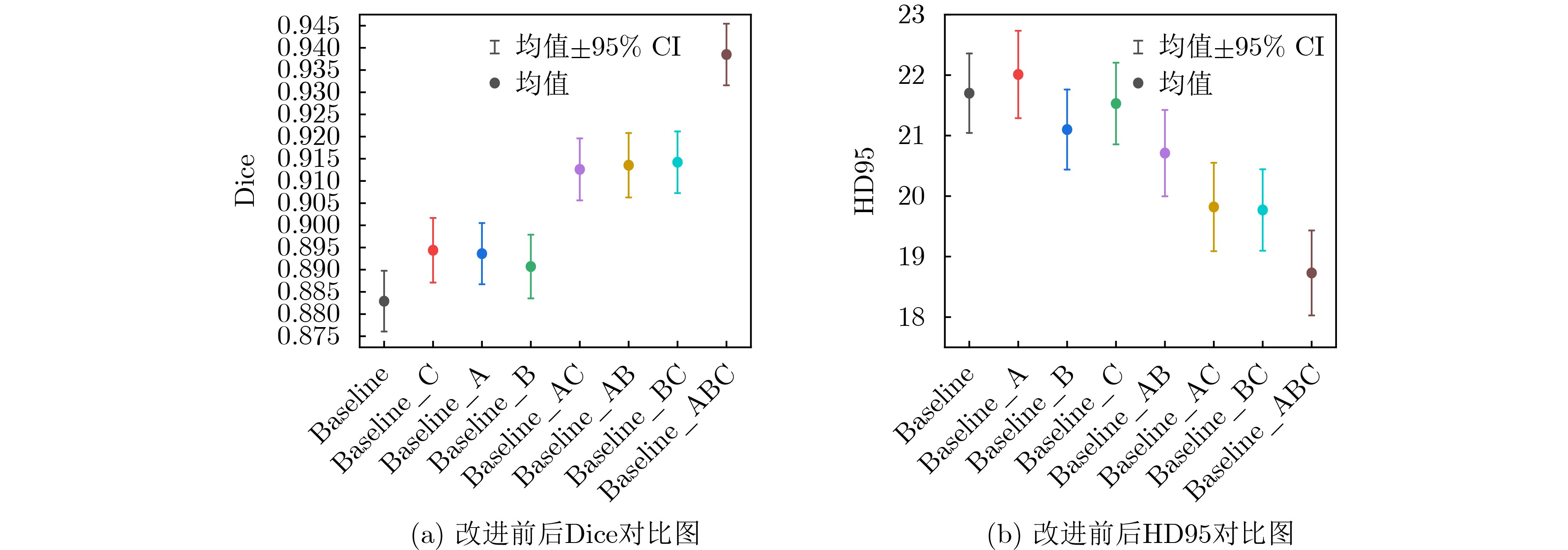
Abstract:Objective To address significant morphological variability, blurred boundaries between teeth and gingival tissues, and overlapping grayscale distributions in periodontal regions of oral and maxillofacial panoramic X-ray images, a state space model based on Mamba, a recently proposed neural network architecture, is adopted. The model preserves the advantage of Convolutional Neural Networks (CNNs) in local feature extraction while avoiding the high computational cost associated with Transformer-based methods. On this basis, a Dual-Domain Multiscale State Space Network (DMSS-Net)-based segmentation algorithm for oral and maxillofacial panoramic X-ray images is proposed, resulting in notable improvements in segmentation accuracy and computational efficiency. Methods An encoder-decoder architecture is adopted. The encoder consists of dual branches to capture global contextual information and local structural features, whereas the decoder progressively restores spatial resolution. Skip connections are used to transmit fused feature maps from the encoding path to the decoding path. During decoding, fused features gradually recover spatial resolution and reduce channel dimensionality through deconvolution combined with upsampling modules, finally producing a two-channel segmentation map. Results and Discussions Ablation experiments are conducted to validate the contribution of each module to overall performance, as shown in Table 1 . The proposed model demonstrates clear performance gains. The Dice score increases by 5.69 percentage points to 93.86%, and the 95th percentile Hausdorff distance (HD95) decreases by 2.97 mm to 18.73 mm, with an overall accuracy of 94.57%. In terms of efficiency, the model size is 81.23 MB with 90.1 million parameters, which is substantially smaller than that of the baseline model, enabling simultaneous improvement in segmentation accuracy and reduction in parameter count. Comparative experiments with seven representative medical image segmentation models under identical conditions, as reported inTable 2 , show that the DMSS-Net achieves superior segmentation accuracy while maintaining a model size comparable to, or smaller than, Transformer-based models of similar scale.Conclusions A DMSS-Net-based segmentation algorithm for oral and maxillofacial panoramic X-ray images is proposed. The algorithm is built on a dual-domain fusion framework that strengthens long-range dependency modeling in dental images and improves segmentation performance in regions with indistinct boundaries. The spatial-domain design effectively supports long-range contextual representation under dynamically varying dental arch morphology. Moreover, enhancement in the feature domain improves sensitivity to low-contrast structures and increases robustness against image interference. -
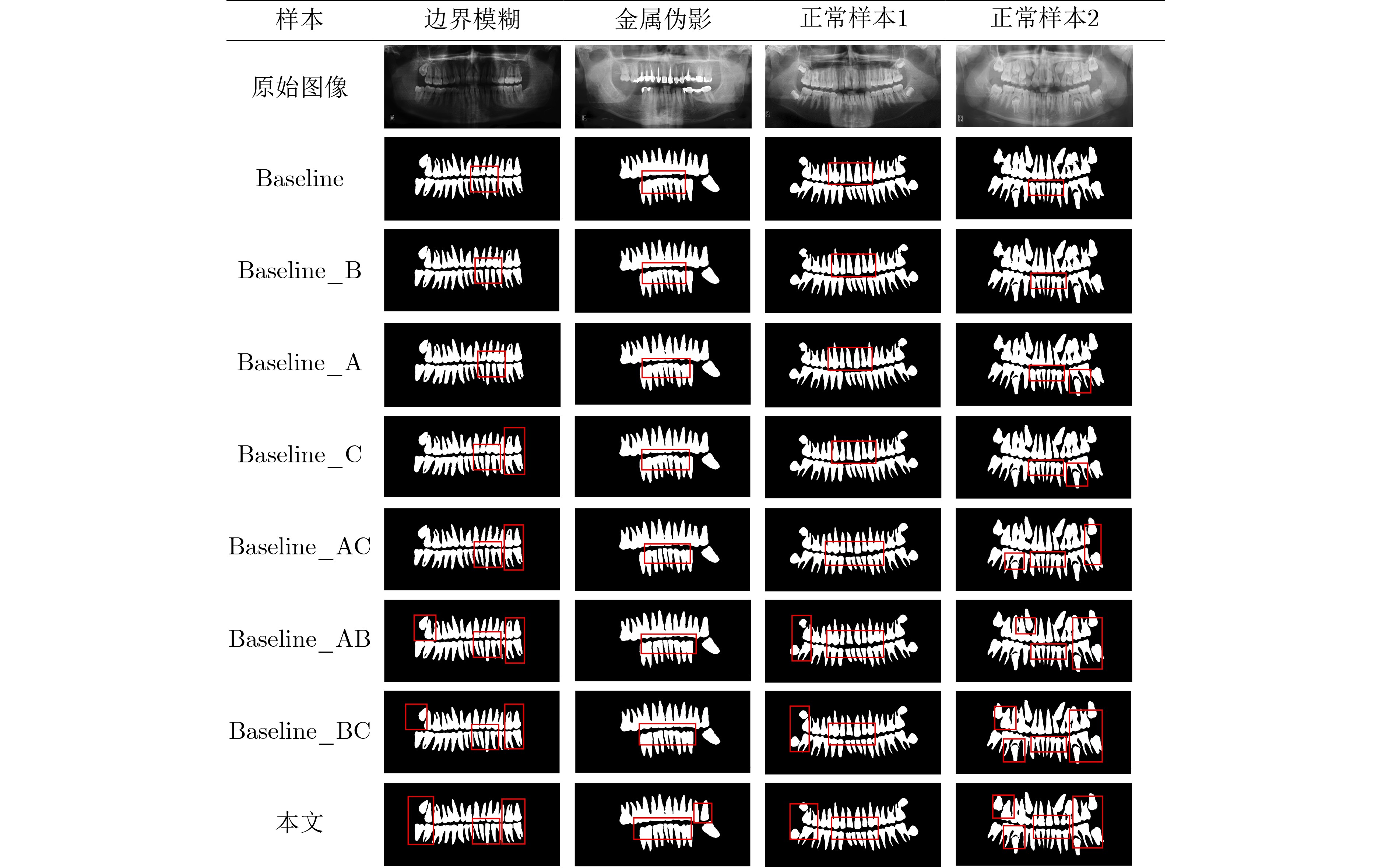
表 1 消融实验指标对比
Dice(%) HD95 Accuracy(%) Recall(%) Precision(%) 模型大小(MB) 参数量(M) baseline 88.17 21.70 93.03 87.97 86.73 84.24 93.19 baseline_A 89.41 22.01 93.67 88.24 87.07 79.23 88.43 baseline_B 89.16 22.10 93.74 88.32 87.42 81.15 89.16 baseline_C 89.73 21.53 93.86 88.87 87.13 78.59 85.63 baseline_AB 91.32 20.71 94.07 89.03 87.26 82.15 91.52 baseline_AC 91.24 19.82 94.20 89.24 87.34 83.41 92.31 baseline_BC 91.53 19.77 94.13 89.37 87.42 81.68 90.74 本文 93.86 18.73 94.57 90.46 88.03 81.23 90.10  下载: 导出CSV
下载: 导出CSV
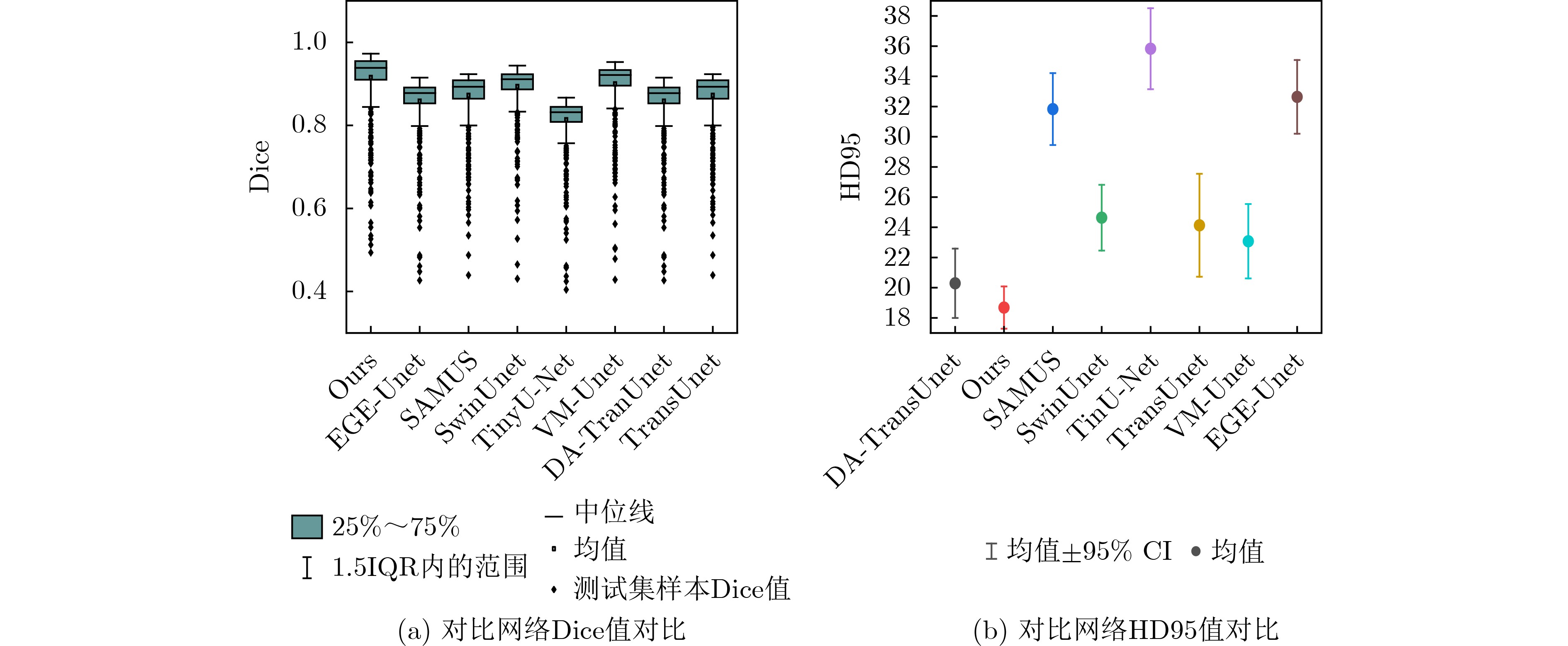
表 2 对比实验指标对比
模型名称 Dice (%) HD95 (mm) Accuracy (%) Recall (%) Precision (%) 模型大小 (MB) 参数量 (M) GFLOPs (G) fps TransUnet 91.43 24.13 92.02 88.76 86.31 82.14 88.52 29.34 18.24 Swin-Unet 89.03 24.63 92.63 89.13 86.81 84.61 92.31 40.93 11.47 VM-Unet 89.63 23.07 93.08 89.47 87.23 83.15 90.74 6.87 34.71 DA-TransUnet 91.25 20.29 93.24 89.73 87.78 87.78 80.63 31.42 16.87 Ege-Unet 88.18 32.64 92.57 86.93 86.04 52.87 61.91 13.73 27.38 TinyU-Net 86.27 35.83 91.74 86.02 85.94 48.65 58.31 4.18 45.63 SAMUS 88.51 31.83 95.02 88.83 86. 57 162.17 183.19 51.62 4.53 本文 93.86 18.73 94.30 90.46 88.03 81.23 90.10 24.93 22.14
下载: 导出CSV
-
[1] RUAN Jiacheng, XIE Mingye, GAO Jingsheng, et al. EGE-UNet: An efficient group enhanced UNet for skin lesion segmentation[C]. Proceedings of the 26th International Conference on Medical Image Computing and Computer Assisted Intervention, Vancouver, Canada: Springer, 2023: 481–490. doi: 10.1007/978-3-031-43901-8_46. [2] CHEN Junren, CHEN Rui, WANG Wei, et al. TinyU-Net: Lighter yet better U-Net with cascaded multi-receptive fields[C]. Proceedings of the 27th International Conference on Medical Image Computing and Computer Assisted Intervention, Marrakesh, Morocco: Springer, 2024: 626–635. doi: 10.1007/978-3-031-72114-4_60. [3] CAO Hu, WANG Yueyue, CHEN J, et al. Swin-Unet: Unet-like pure transformer for medical image segmentation[C]. Proceedings of the 17th European Conference on Computer Vision, Tel Aviv, Israel: Springer, 2023: 205–218. doi: 10.1007/978-3-031-25066-8_9. [4] CHEN Jieneng, LU Yongyi, YU Qihang, et al. TransUNet: Transformers make strong encoders for medical image segmentation[J]. arXiv preprint arXiv: 2102.04306, 2021. doi: 10.48550/arXiv.2102.04306. [5] SUN Guanqun, PAN Yizhi, KONG Weikun, et al. DA-TransUNet: Integrating spatial and channel dual attention with transformer U-Net for medical image segmentation[J]. Frontiers in Bioengineering and Biotechnology, 2024, 12: 1398237. doi: 10.3389/fbioe.2024.1398237. [6] LEE H H, BAO Shunxing, HUO Yuankai, et al. 3D UX-Net: A large kernel volumetric convnet modernizing hierarchical transformer for medical image segmentation[C]. Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda: ICLR, 2023. [7] ZHOU Hongyu, GUO Jiansen, ZHANG Yinghao, et al. nnFormer: Volumetric medical image segmentation via a 3D transformer[J]. IEEE Transactions on Image Processing, 2023, 32: 4036–4045. doi: 10.1109/TIP.2023.3293771. [8] HATAMIZADEH A, NATH V, TANG Yucheng, et al. Swin UNETR: Swin transformers for semantic segmentation of brain tumors in MRI images[C]. Proceedings of the 7th International Workshop on Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, Springer, 2021: 272–284. doi: 10.1007/978-3-031-08999-2_22. [9] GU A and DAO T. Mamba: Linear-time sequence modeling with selective state spaces[J]. arXiv preprint arXiv: 2312.00752, 2023. doi: 10.48550/arXiv.2312.00752. [10] RUAN Jiacheng, LI Jincheng, and XIANG Suncheng. VM-UNet: Vision mamba UNet for medical image segmentation[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2025. doi: 10.1145/3767748. [11] HAO Jing, ZHU Yonghui, HE Lei, et al. T-Mamba: A unified framework with long-range dependency in dual-domain for 2D & 3D tooth segmentation[J]. arXiv preprint arXiv: 2404.01065, 2024. doi: 10.48550/arXiv.2404.01065. [12] LIN Xian, XIANG Yangyang, YU Li, et al. Beyond adapting SAM: Towards end-to-end ultrasound image segmentation via auto prompting[C]. Proceedings of the 27th International Conference on Medical Image Computing and Computer Assisted Intervention, Marrakesh, Morocco: Springer, 2024: 24–34. doi: 10.1007/978-3-031-72111-3_3. [13] LIN P L, HUANG P Y, HUANG P W, et al. Teeth segmentation of dental periapical radiographs based on local singularity analysis[J]. Computer Methods and Programs in Biomedicine, 2014, 113(2): 433–445. doi: 10.1016/j.cmpb.2013.10.015. [14] MAHDI F P and KOBASHI S. Quantum particle swarm optimization for multilevel thresholding-based image segmentation on dental X-ray images[C]. Proceedings of the Joint 10th International Conference on Soft Computing and Intelligent Systems and 19th International Symposium on Advanced Intelligent Systems, Toyama, Japan: IEEE, 2018: 1148–1153. doi: 10.1109/SCIS-ISIS.2018.00181. [15] SON L H and TUAN T M. A cooperative semi-supervised fuzzy clustering framework for dental X-ray image segmentation[J]. Expert Systems with Applications, 2016, 46: 380–393. doi: 10.1016/j.eswa.2015.11.001. [16] PUSHPARAJ V, GURUNATHAN U, ARUMUGAM B, et al. An effective numbering and classification system for dental panoramic radiographs[C]. Proceedings of the 4th International Conference on Computing, Communications and Networking Technologies, Tiruchengode, India: IEEE, 2013: 1–8. doi: 10.1109/ICCCNT.2013.6726480. [17] ALSMADI M K. A hybrid Fuzzy C-Means and Neutrosophic for jaw lesions segmentation[J]. Ain Shams Engineering Journal, 2018, 9(4): 697–706. doi: 10.1016/j.asej.2016.03.016. [18] KOCH T L, PERSLEV M, IGEL C, et al. Accurate segmentation of dental panoramic radiographs with U-NETS[C]. Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging, Venice, Italy: IEEE, 2019: 15–19. doi: 10.1109/ISBI.2019.8759563. [19] ZANNAH R, BASHAR M, MUSHFIQ R B, et al. Semantic segmentation on panoramic dental X-ray images using U-Net architectures[J]. IEEE Access, 2024, 12: 44598–44612. doi: 10.1109/ACCESS.2024.3380027. [20] IMAK A, ÇELEBI A, POLAT O, et al. ResMIBCU-Net: An encoder–decoder network with residual blocks, modified inverted residual block, and bi-directional ConvLSTM for impacted tooth segmentation in panoramic X-ray images[J]. Oral Radiology, 2023, 39(4): 614–628. doi: 10.1007/s11282-023-00677-8. [21] LI Yunxiang, WANG Shuai, WANG Jun, et al. GT U-Net: A U-net like group transformer network for tooth root segmentation[C]. Proceedings of the Machine Learning in Medical Imaging: 12th International Workshop, Strasbourg, France: Springer, 2021: 386–395. doi: 10.1007/978-3-030-87589-3_40. [22] SHENG Chen, WANG Lin, HUANG Zhenhuan, et al. Transformer-based deep learning network for tooth segmentation on panoramic radiographs[J]. Journal of Systems Science and Complexity, 2023, 36(1): 257–272. doi: 10.1007/s11424-022-2057-9. [23] LI Pengcheng, GAO Chenqiang, LIAN Chunfeng, et al. Spatial prior-guided bi-directional cross-attention transformers for tooth instance segmentation[J]. IEEE Transactions on Medical Imaging, 2024, 43(11): 3936–3948. doi: 10.1109/TMI.2024.3406015. [24] LIU Yue, TIAN Yunjie, ZHAO Yuzhong, et al. VMamba: Visual state space model[C]. Proceedings of the 38th International Conference on Neural Information Processing Systems, Vancouver, Canada: Curran Associates Inc. , 2024: 3273. [25] HOWARD A G, ZHU Menglong, CHEN Bo, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint arXiv: 1704.04861, 2017. doi: 10.48550/arXiv.1704.04861. [26] SI Yunzhong, XU Huiying, ZHU Xinzhong, et al. SCSA: Exploring the synergistic effects between spatial and channel attention[J]. Neurocomputing, 2025, 634: 129866. doi: 10.1016/j.neucom.2025.129866. [27] SUN Hongkun, XU Jing, and DUAN Yuping. ParaTransCNN: Parallelized transcnn encoder for medical image segmentation[J]. arXiv preprint arXiv: 2401.15307, 2024. doi: 10.48550/arXiv.2401.15307. -

 下载:
下载:







图(11) / 表(2)
计量
- 文章访问数: 502
- HTML全文浏览量: 360
- PDF下载量: 64
- 被引次数: 0
