

A Vehicle-Infrastructure Cooperative 3D Object Detection Scheme Based on Adaptive Feature Selection
-
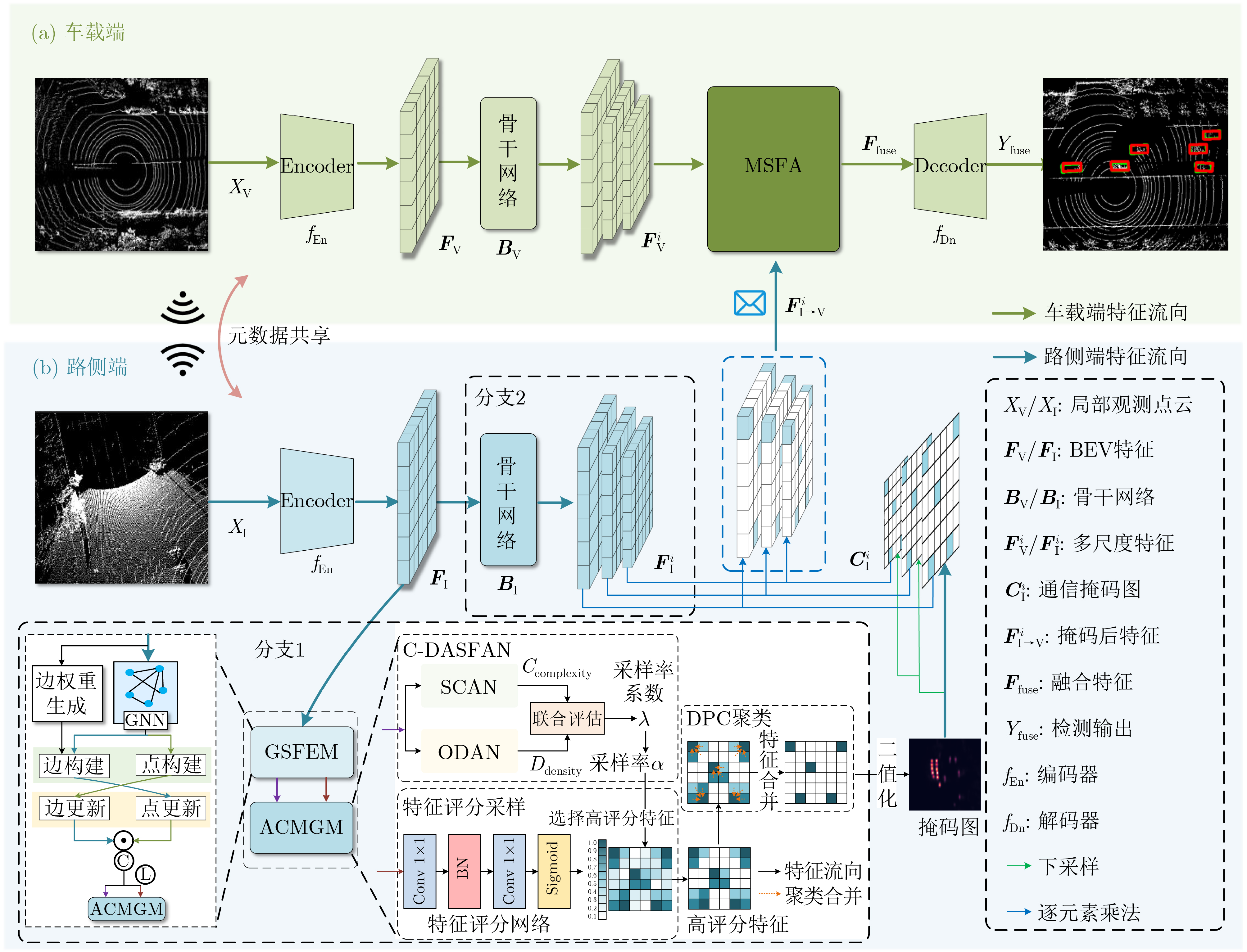
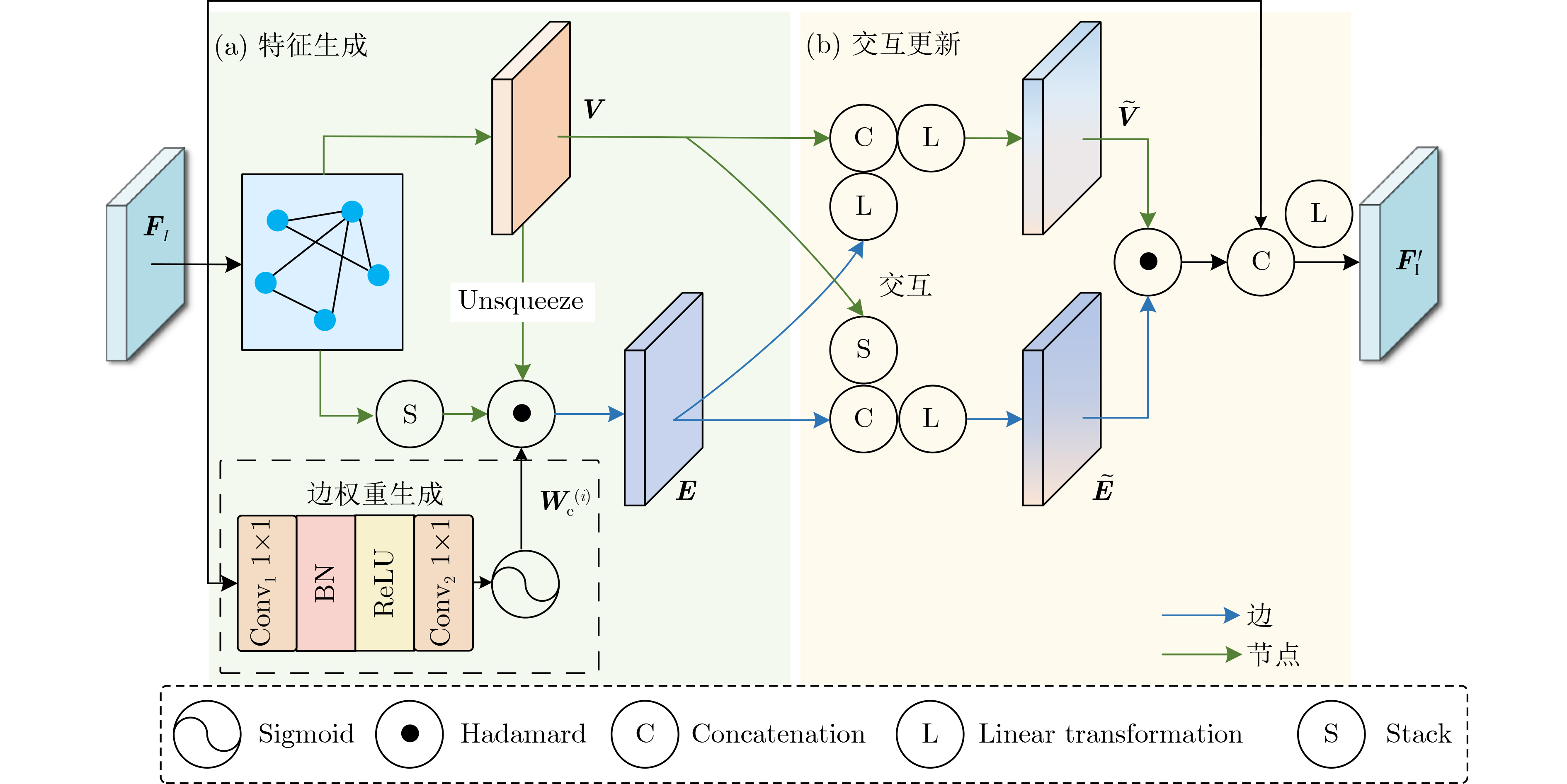
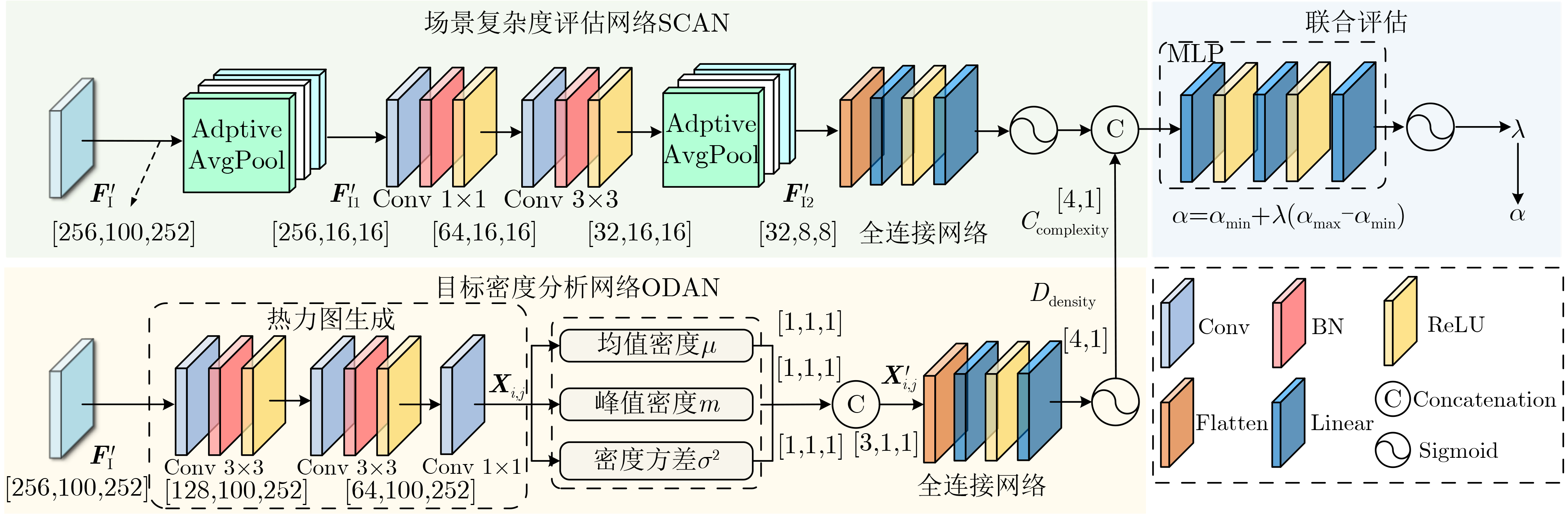
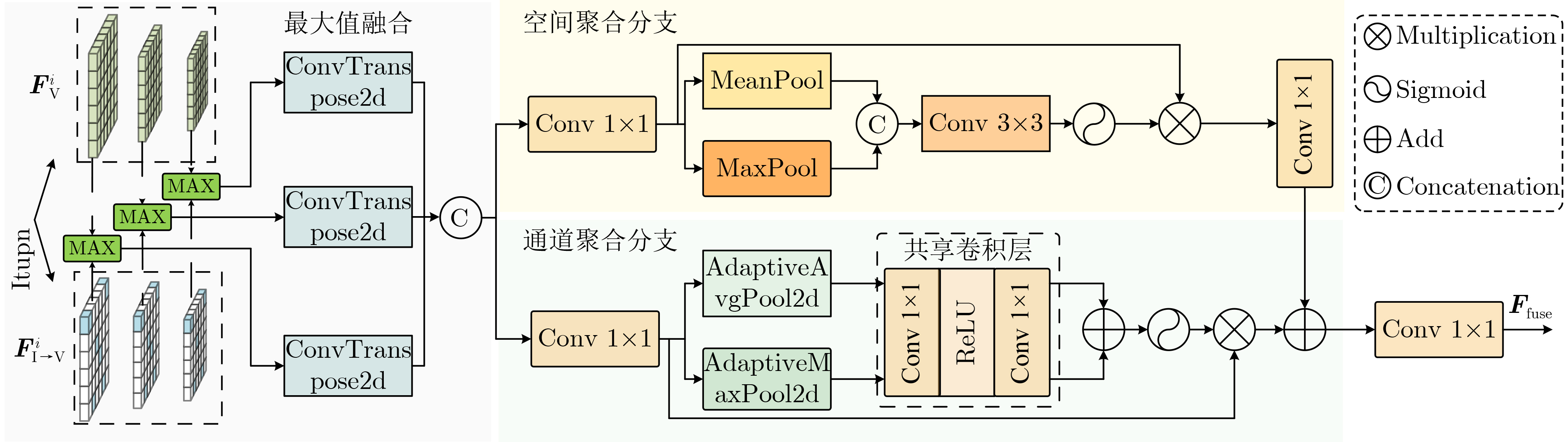
摘要: 车路协同场景完成三维目标检测需解决车载端和路侧端之间通信带宽受限和信息聚合能力有限两个问题。该文基于空间过滤理论,设计了自适应特征选择的车路协同3D目标检测方案(AFS-VIC3D)。首先,为解决通信带宽受限问题,在路侧端设计了包含两个基本模块的自适应特征选择方案:(1)图结构特征增强模块(GSFEM)利用图神经网络(GNN)通过交互更新节点和边的权重来增强前景目标区域特征响应,并减少背景区域特征响应,以提升目标区域特征判别性;(2)自适应特征通信掩码构建模块(ACMGM)通过动态分析特征重要性分布,自适应选择信息量高的特征以构建稀疏二维通信掩码图实现特征优化传输;其次,为了提升信息聚合能力,在车载端设计了多尺度特征聚合模块(MSFA),通过空间-通道聚合协同机制,在尺度、空间和通道层次上融合车载端和路侧端特征,提高目标检测精度和鲁棒性。所提AFS-VIC3D在公开数据集DAIR-V2X和V2XSet上进行验证,均以交互比(IoU)阈值分别为0.3/0.5/0.7时平均精度(AP)为指标。在DAIR-V2X数据集上,该方案以$ {2^{20.15}} $字节的通信量达到了83.65%/79.34%/64.45%的检测精度;在V2XSet数据集上,以$ {2^{20.16}} $字节的通信量达到了94.14%/93.08%/86.69%的检测精度。结果表明,所提AFS-VIC3D方案自适应选择并传输对目标检测起关键作用的特征,在降低通信带宽消耗的同时提升3D目标检测性能,能实现检测性能与通信带宽之间的最佳权衡。Abstract:
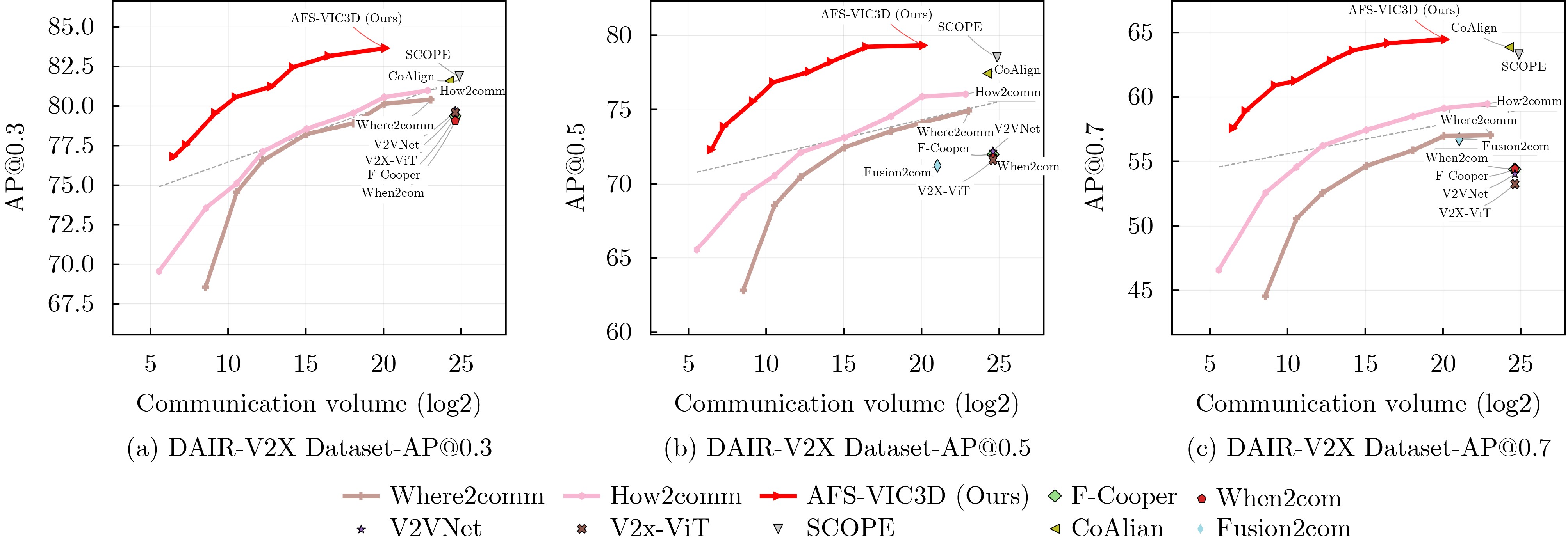
Objective Vehicle-infrastructure cooperative Three-Dimensional (3D) object detection is viewed as a core technology for intelligent transportation systems. As autonomous driving advances, the fusion of roadside and vehicle-mounted LiDAR data provides beyond-line-of-sight perception for vehicles, offering clear potential for improving traffic safety and efficiency. Conventional cooperative perception, however, is constrained by limited communication bandwidth and insufficient aggregation of heterogeneous data, which restricts the balance between detection performance and bandwidth usage. These constraints hinder the practical deployment of cooperative perception in complex traffic environments. This study proposes an Adaptive Feature Selection-based Vehicle-Infrastructure Cooperative 3D Object Detection Scheme (AFS-VIC3D) to address these challenges. Spatial filtering theory is used to identify and transmit the critical features required for detection, improving 3D perception performance while reducing bandwidth consumption. Methods AFS-VIC3D uses a coordinated design for roadside and vehicle-mounted terminals. Incoming point clouds are encoded into Bird’s-Eye View (BEV) features through PointPillar encoders, and metadata synchronization ensures spatiotemporal alignment. At the roadside terminal, key features are selected using two parallel branches: a Graph Structure Feature Enhancement Module (GSFEM) and an Adaptive Communication Mask Generation Module (ACMGM). Multi-scale features are then extracted hierarchically with a ResNet backbone. The outputs of both branches are fused through elementwise multiplication to generate optimized features for transmission. At the vehicle-mounted terminal, BEV features are processed using homogeneous backbones and fused through a Multi-Scale Feature Aggregation (MSFA) module across scale, spatial, and channel dimensions, reducing sensor heterogeneity and improving detection robustness. Results and Discussions The effectiveness and robustness of AFS-VIC3D are validated on both the DAIRV2X real-world dataset and the V2XSet simulation dataset. Comparative experiments ( Table 1 ,Fig. 5 ) show that the model attains higher detection accuracy with lower communication overhead and exhibits slower degradation under low-bandwidth conditions. Ablation studies (Table 2 ) demonstrate that each module (GSFEM, ACMGM, and MSFA) contributes to performance. GSFEM improves the discriminability of target features, and ACMGM used with GSFEM further reduces communication cost. A comparison of feature transmission methods (Table 3 ) shows that adaptive sampling based on scene complexity and target density (C-DASFAN) yields higher accuracy and lower bandwidth usage, confirming the advantage of ACMGM. BEV visualizations (Fig. 6 ) indicate that predicted bounding boxes align closely with ground truth with minimal redundancy. Analysis of complex scenarios (Fig. 7 ) shows fewer missed detections and false positives, demonstrating robustness in high-density and complex road environments. Feature-level visualization (Fig. 8 ) further verifies that GSFEM and ACMGM enhance target features and suppress background noise, improving overall detection performance.Conclusions This study presents an AFS-VIC3D that addresses the key challenges of limited communication bandwidth and heterogeneous data aggregation through a coordinated design combining roadside dual-branch feature optimization and vehicle-mounted MSFA. The GSFEM module uses graph neural networks to enhance the discriminability of target features, the ACMGM module optimizes communication resources through communication mask generation, and the MSFA module improves heterogeneous data aggregation between vehicle and infrastructure terminals through joint spatial and channel aggregation. Experiments on the DAIR-V2X and V2XSet datasets show that AFS-VIC3D improves 3D detection accuracy while lowering communication overhead, with clear advantages in complex traffic scenarios. The framework offers a practical and effective solution for vehicle-infrastructure cooperative 3D perception and demonstrates strong potential for deployment in bandwidth-constrained intelligent transportation systems. -
表 1 DAIR-V2X和V2XSet数据集上各算法对比实验结果
方法 阶段 DAIR-V2X V2XSet AP@0.3↑ AP@0.5↑ AP@0.7↑ Comm↓ AP@0.3↑ AP@0.5↑ AP@0.7↑ Comm↓ No Collaboration N 64.06 61.05 51.83 0 79.63 77.33 51.34 0 Early Fusion E 79.61 74.45 58.82 27.48 90.20 84.60 54.82 28.01 Late Fusion L 78.55 69.72 44.04 8.39 87.62 80.87 50.39 8.57 F-Cooper[7] Ⅰ 79.38 72.00 54.40 24.62 86.61 79.00 52.68 24.87 V2VNet[8] Ⅰ 79.70 72.19 54.04 24.62 90.70 85.43 61.40 24.87 V2X-ViT[9] Ⅰ 79.60 71.61 53.26 24.62 91.65 87.36 66.65 24.87 When2com[10] Ⅰ 79.08 71.84 54.43 24.62 84.16 79.55 56.12 24.87 Where2comm[11] Ⅰ 80.41 74.93 57.03 23.06 92.04 88.87 68.82 23.08 How2comm[12] Ⅰ 80.98 76.05 59.45 22.85 90.10 90.28 73.87 22.86 SCOPE[15] Ⅰ 81.88 78.52 63.29 24.88 91.64 91.27 82.19 24.88 CoAlign[16] Ⅰ 81.60 77.45 63.85 24.25 92.79 91.69 83.12 24.25 Fusion2comm[13] Ⅰ - 71.24 56.72 21.04 - - - - SparseComm[14] Ⅰ - - - - - 91.82 77.60 20.35 本文方法 Ⅰ 83.65↑ 79.34↑ 64.45↑ 20.15↓ 94.14 ↑ 93.08↑ 86.69↑ 20.16↓  下载: 导出CSV
下载: 导出CSV
表 2 DAIR-V2X和V2XSet数据集下的消融实验结果
Modules DAIR-V2X V2XSet GSFEM ACMGM MSFA AP@0.3↑(%) AP@0.5↑(%) AP@0.7↑(%) Comm↓ AP@0.3↑(%) AP@0.5↑(%) AP@0.7↑(%) Comm↓ × × × 80.41 74.93 57.03 23.06 92.04 88.87 68.82 23.08 √ × × 80.95 76.01 59.20 24.16 93.00 89.88 72.45 24.18 × √ × 81.92 77.15 62.86 21.15 93.30 90.04 71.72 21.16 × × √ 81.96 77.27 61.34 23.06 92.80 91.10 80.22 23.08 √ √ × 83.20 78.55 63.32 20.15 93.28 92.21 84.85 20.16 √ × √ 81.70 77.27 62.75 24.16 93.24 90.03 72.03 24.16 × √ √ 82.17 77.48 62.00 21.15 94.02 92.79 84.56 21.16 √ √ √ 83.65 79.34 64.45 20.15 94.14 93.08 86.69 20.16
下载: 导出CSV
表 3 不同特征选择方式对通信量以及目标检测性能的影响
采用方法 特征选
择方法DAIR-V2X V2XSet AP@0.3↑(%) AP@0.5↑(%) AP@0.7↑(%) Comm↓ AP@0.3↑(%) AP@0.5↑(%) AP@0.7↑(%) Comm↓ 基线 SF 80.41 74.93 57.03 23.06 92.04 88.87 68.82 23.08 方法(1) FC 79.32 71.38 54.59 24.06 88.76 85.46 67.46 24.50 方法(2) FC 78.59 70.63 56.46 22.70 87.25 84.35 66.82 22.80 方法(3) SF 80.56 76.46 57.45 22.60 91.56 88.06 69.63 22.62 方法(4) SF 81.05 76.16 58.49 21.60 92.51 88.74 69.13 21.80 方法(5) SF 80.86 77.02 59.46 20.70 93.01 88.76 70.52 20.80 方法(6) SF 81.92 77.15 62.86 20.15 93.30 90.04 71.72 20.16
下载: 导出CSV
-
[1] SHAO Shilin, ZHOU Yang, LI Zhenglin, et al. Frustum PointVoxel-RCNN: A high-performance framework for accurate 3D object detection in point clouds and images[C]. The 2024 4th International Conference on Computer, Control and Robotics (ICCCR), Shanghai, China, 2024: 56–60. doi: 10.1109/ICCCR61138.2024.10585339. [2] 邵凯, 吴广, 梁燕, 等. 基于局部特征编解码的自动驾驶3D目标检测[J]. 系统工程与电子技术, 2025, 47(10): 3168–3178. doi: 10.12305/j.issn.1001-506X.2025.10.05.SHAO Kai, WU Guang, LIANG Yan, et al. Local feature encode-decoding based 3D target detection of autonomous driving[J]. Systems Engineering and Electronics, 2025, 47(10): 3168–3178. doi: 10.12305/j.issn.1001-506X.2025.10.05. [3] ZHANG Yezheng, FAN Zhijie, HOU Jiawei, et al. Incentivizing point cloud-based accurate cooperative perception for connected vehicles[J]. IEEE Transactions on Vehicular Technology, 2025, 74(4): 5637–5648. doi: 10.1109/TVT.2024.3519626. [4] HU Senkang, FANG Zhengru, DENG Yiqin, et al. Collaborative perception for connected and autonomous driving: Challenges, possible solutions and opportunities[J]. IEEE Wireless Communications, 2025, 32(5): 228–234. doi: 10.1109/MWC.002.2400348. [5] LI Jing, NIU Yong, WU Hao, et al. Effective joint scheduling and power allocation for URLLC-oriented V2I communications[J]. IEEE Transactions on Vehicular Technology, 2024, 73(8): 11694–11705. doi: 10.1109/TVT.2024.3381924. [6] LIU Gang, HU Jiewen, MA Zheng, et al. Joint optimization of communication latency and platoon control based on uplink RSMA for future V2X networks[J]. IEEE Transactions on Vehicular Technology, 2025, 74(9): 13458–13470. doi: 10.1109/TVT.2025.3560709. [7] CHEN Qi, MA Xu, TANG Sihai, et al. F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3D point clouds[C]. The 4th ACM/IEEE Symposium on Edge Computing, Arlington, USA, 2019: 88–100. doi: 10.1145/3318216.3363300. [8] WANG T H, MANIVASAGAM S, LIANG Ming, et al. V2VNet: Vehicle-to-vehicle communication for joint perception and prediction[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 605–621. doi: 10.1007/978-3-030-58536-5_36. [9] XU Runsheng, XIANG Hao, TU Zhengzhong, et al. V2X-ViT: Vehicle-to-everything cooperative perception with vision transformer[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 107–124. doi: 10.1007/978-3-031-19842-7_7. [10] LIU Y C, TIAN Junjiao, GLASER N, et al. When2com: Multi-agent perception via communication graph grouping[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 4105–4114. doi: 10.1109/CVPR42600.2020.00416. [11] HU Yue, FANG Shaoheng, LEI Zixing, et al. Where2comm: Communication-efficient collaborative perception via spatial confidence maps[C]. The 36th International Conference on Neural Information Processing System, New Orleans, USA, 2022: 352. doi: 10.5555/3600270.3600622. [12] YANG Dingkang, YANG Kun, WANG Yuzheng, et al. How2comm: Communication-efficient and collaboration-pragmatic multi-agent perception[J]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 1093. [13] CHU Huazhen, LIU Haizhuang, ZHUO Junbao, et al. Occlusion-guided multi-modal fusion for vehicle-infrastructure cooperative 3D object detection[J]. Pattern Recognition, 2025, 157: 110939. doi: 10.1016/j.patcog.2024.110939. [14] LIU Haizhuang, CHU Huazhen, ZHUO Junbao, et al. SparseComm: An efficient sparse communication framework for vehicle-infrastructure cooperative 3D detection[J]. Pattern Recognition, 2025, 158: 110961. doi: 10.1016/j.patcog.2024.110961. [15] YANG Kun, YANG Dingkang, ZHANG Jingyu, et al. Spatio-temporal domain awareness for multi-agent collaborative perception[C]. The IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 23383–23392. doi: 10.1109/ICCV51070.2023.02137. [16] LU Yifan, LI Quanhao, LIU Baoan, et al. Robust collaborative 3D object detection in presence of pose errors[C]. The 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 2023: 4812–4818. doi: 10.1109/ICRA48891.2023.10160546. [17] LANG A H, VORA S, CAESAR H, et al. PointPillars: Fast encoders for object detection from point clouds[C]. The 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 12689–12697. doi: 10.1109/CVPR.2019.01298. [18] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [19] XUE Yuanliang, JIN Guodong, SHEN Tao, et al. SmallTrack: Wavelet pooling and graph enhanced classification for UAV small object tracking[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5618815. doi: 10.1109/TGRS.2023.3305728. [20] ZHANG Jingyu, YANG Kun, WANG Yilei, et al. ERMVP: Communication-efficient and collaboration-robust multi-vehicle perception in challenging environments[C]. The 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 12575–12584. doi: 10.1109/CVPR52733.2024.01195. [21] 陶新民, 李俊轩, 郭心悦, 等. 基于超球体密度聚类的自适应不均衡数据过采样算法[J]. 电子与信息学报, 2025, 47(7): 2347–2360. doi: 10.11999/JEIT241037.TAO Xinmin, LI Junxuan, GUO Xinyue, et al. Density clustering hypersphere-based self-adaptively oversampling algorithm for imbalanced datasets[J]. Journal of Electronics & Information Technology, 2025, 47(7): 2347–2360. doi: 10.11999/JEIT241037. [22] LIU Haisong, TENG Yao, LU Tao, et al. SparseBEV: High-performance sparse 3D object detection from multi-camera videos[C]. The 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 18534–18544. doi: 10.1109/ICCV51070.2023.01703. [23] LIU Mushui, DAN Jun, LU Ziqian, et al. CM-UNet: Hybrid CNN-mamba UNet for remote sensing image semantic segmentation[J]. arXiv preprint arXiv: 2405.10530, 2024. doi. org/10.48550/arXiv. 2405.10530. [24] YU Haibao, LUO Yizhen, SHU Mao, et al. DAIR-V2X: A large-scale dataset for vehicle-infrastructure cooperative 3D object detection[C]. The 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 21329–21338. doi: 10.1109/CVPR52688.2022.02067. -

 下载:
下载:





图(8) / 表(3)
计量
- 文章访问数: 813
- HTML全文浏览量: 488
- PDF下载量: 67
- 被引次数: 0
