

Joint Focus Measure and Context-Guided Filtering for Depth From Focus
-
摘要: 聚焦深度估计(DFF)通过分析图像中各像素的焦点变化来推断场景深度,任务的关键在于定位焦堆栈中的最佳聚焦像素点。然而弱纹理区域中焦点变化通常较为细微,导致聚焦区域检测困难,影响深度估计的准确性。因此,该文提出了一种结合聚焦度量与上下文信息的焦堆栈深度估计网络,方法能够精确识别焦堆栈中最佳聚焦像素,并推断出可靠的深度图。文中将聚焦度量算子概念融入深度学习框架,通过增强聚焦区域的特征表达,提升网络对弱纹理区域细微焦点变化的感知能力。此外,文章引入语义上下文引导机制,利用整合的场景语义信息,指导焦点体积的滤波优化。这使网络能同时捕获局部焦点细节与全局上下文信息,实现对弱纹理区域焦点状态的全面推断。综合实验结果,所提出的模型在主观质量和客观指标相比其他算法都有明显提升,具有良好的泛化能力。Abstract:
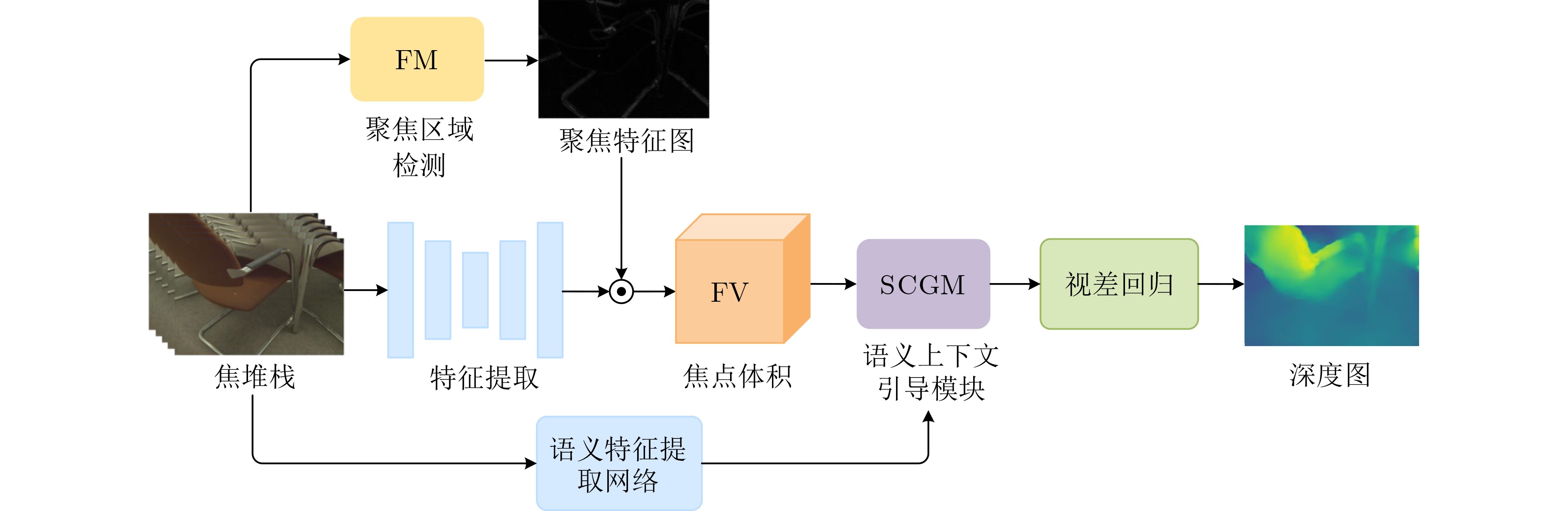
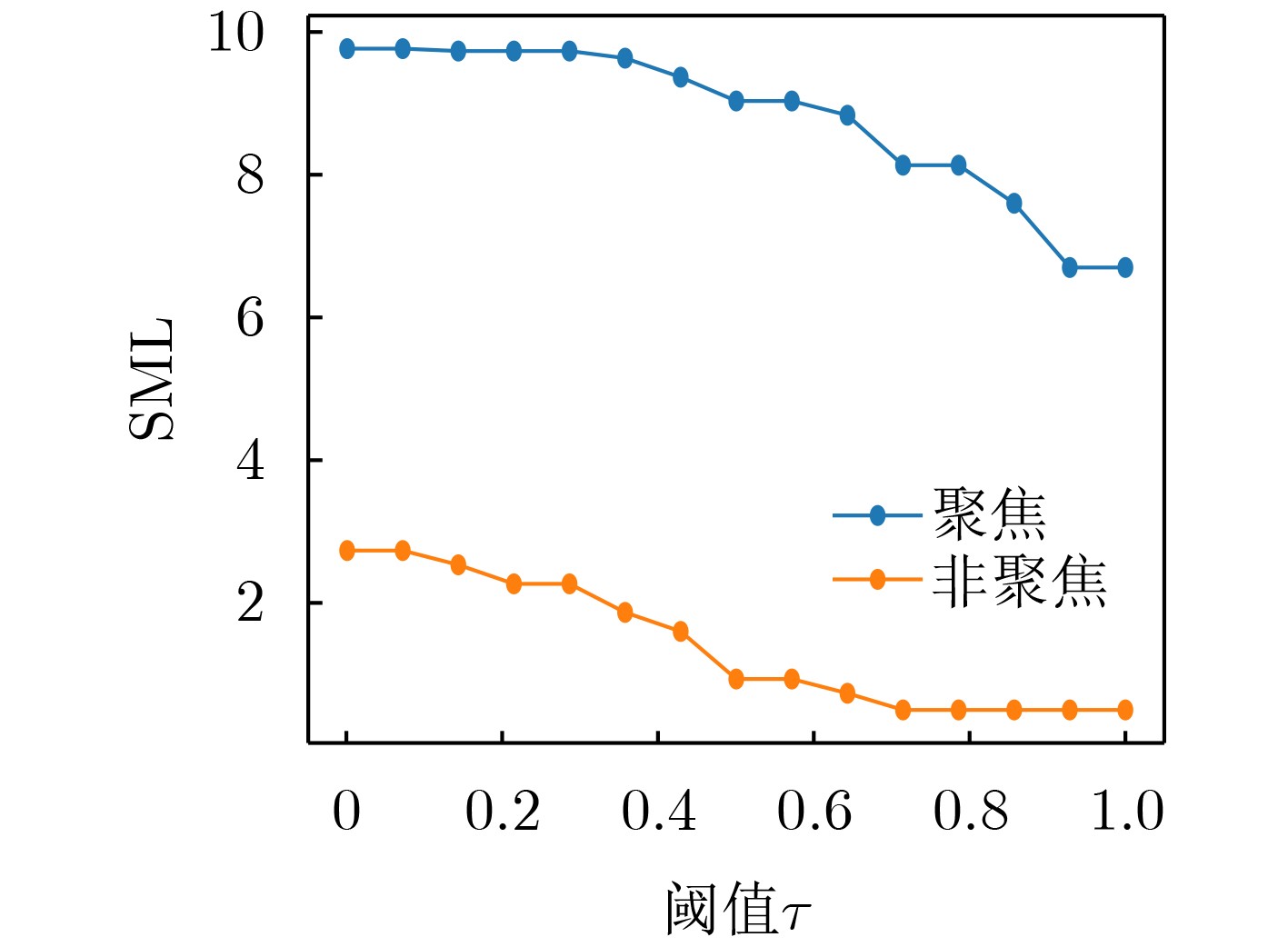
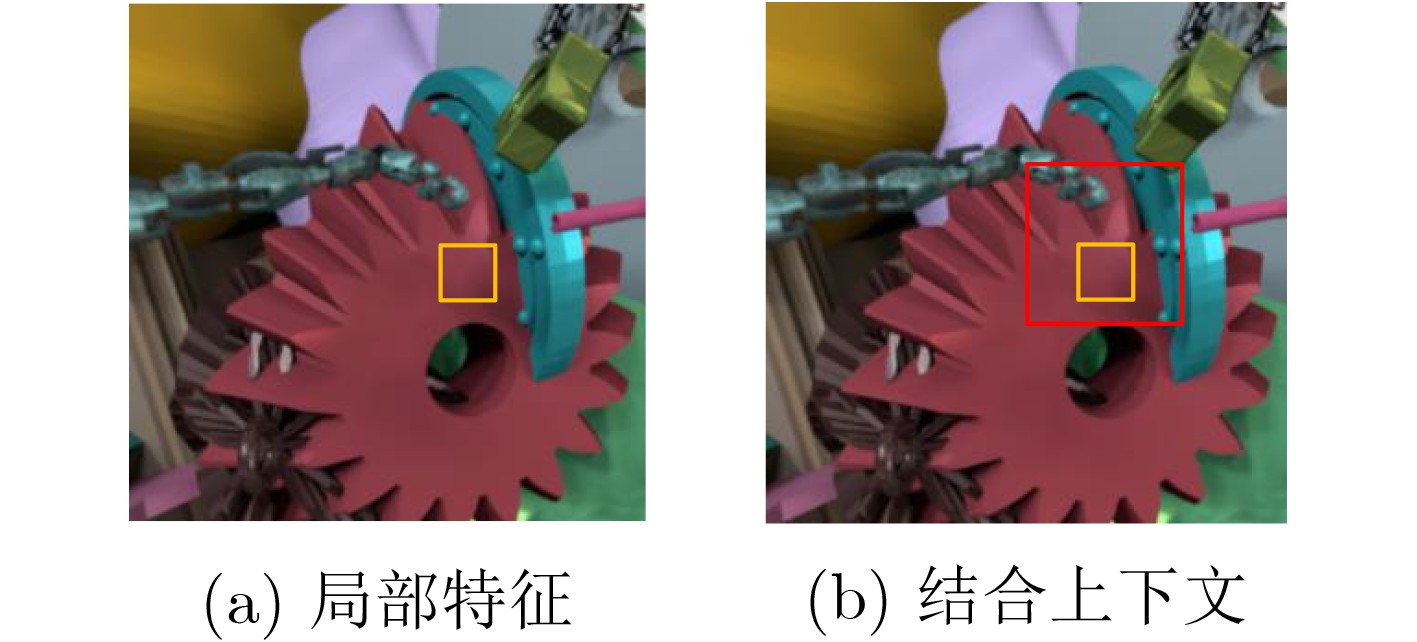
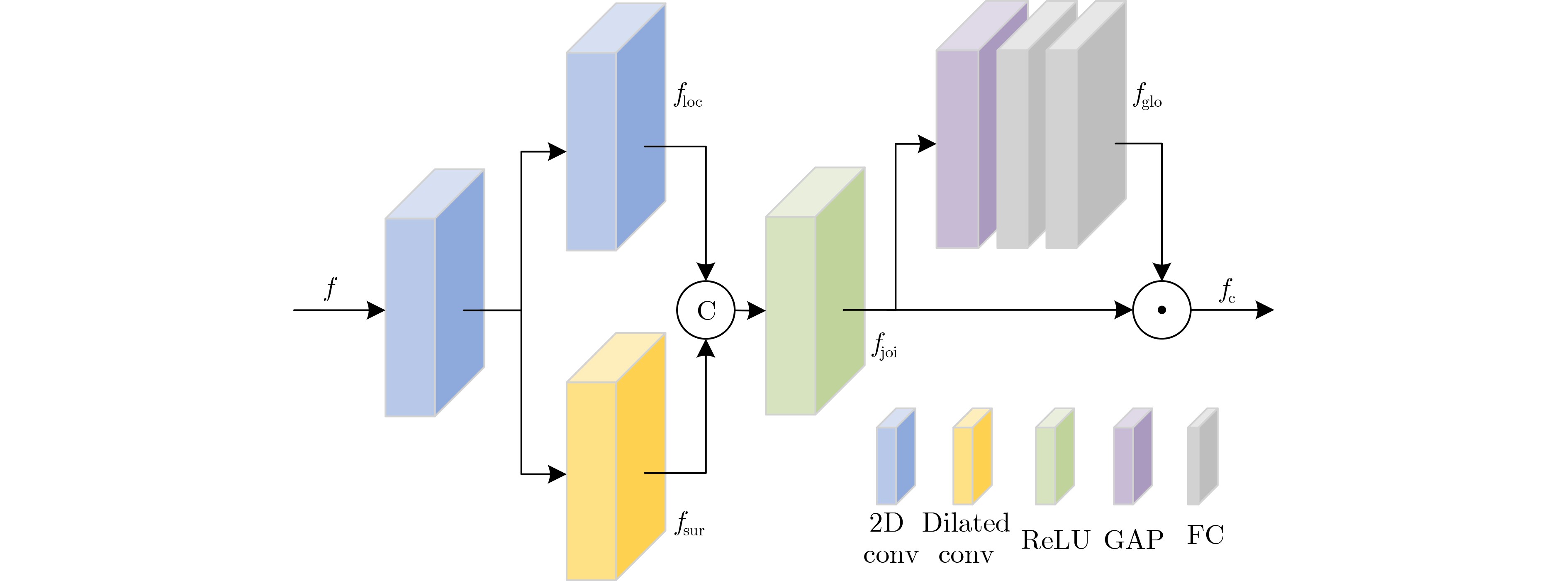
Objective Depth from Focus (DFF) seeks to determine scene depth by analyzing the focus variation of each pixel in an image. A key challenge in DFF is identifying the best-focused slice within the focal stack. However, focus variation in weakly textured regions is often subtle, making it difficult to detect focused areas, which adversely affects the accuracy of depth maps. To address this issue, this study proposes a depth estimation network that integrates focus measures and contextual information from the focal stack. The network accurately locates the best-focused pixels and generates a reliable depth map. By explicitly incorporating focus cues into a Convolutional Neural Network (CNN) and thoroughly considering spatial correlations within the scene, the approach facilitates comprehensive inference of focus states in weakly textured regions. This enables the network to capture both local focus-related details and global contextual information, thereby enhancing the accuracy and efficiency of depth estimation in challenging regions. Methods The proposed network consists of two main components. The first is focus region detection, which extracts focus-related features from the focal stack. A focus measure operator is introduced into the network during learning, yielding the maximum response when an image region is in sharp focus. After identifying the best-focused slices within the stack, the detected focus features are fused with those extracted by a 2D CNN. Because focus variations in weakly textured regions are often subtle, the representation of focus regions is enhanced to improve sensitivity to such changes. The second component comprises a semantic network and a semantic context module. A semantic context network is used to extract semantic cues, and semantic-guided filtering is then applied to the focus volume, integrating target features (focus volume) with guiding features (semantic context features). When local focus cues are indistinguishable, the global semantic context allows reliable inference of the focus state. This framework combines the strengths of deep learning and traditional methods while accounting for the specific characteristics of DFF and CNN architectures. Therefore, it produces robust and accurate depth maps, even in challenging regions. Results and Discussions The proposed architecture is evaluated through quantitative and qualitative comparisons on two public datasets. Prediction reliability is assessed using multiple evaluation metrics, including Mean Squared Error (MSE) and squared relative error (Sqr.rel.). Quantitative results ( Tables 1 and2 ) show that the proposed method consistently outperforms existing approaches on both datasets. The small discrepancy between predicted and ground-truth depths indicates precise depth estimation with reduced prediction errors. In addition, higher accuracy is achieved while computational cost remains within a practical range. Qualitative analysis (Figures 8 and9 ) further demonstrates superior depth reconstruction and detail preservation, even when a limited number of focal stack slices is used. The generalization ability of the network is further examined on the unlabeled Mobile Depth dataset (Figure 10 ). The results confirm that depth can be reliably recovered in diverse unseen scenes, indicating effectiveness for real-world applications. Ablation studies (Table 3 ) validate the contribution of each proposed module. Optimal performance is obtained when both the Focus Measure (FM) and the Semantic Context-Guided Module (SCGM) are applied. Parameter count comparisons further indicate that the proposed approach achieves a balance between performance and complexity, delivering robust accuracy without excessive computational burden.Conclusions This study proposes a CNN-based DFF framework to address the challenge of depth estimation in weakly textured regions. By embedding focus measure operators into the deep learning architecture, the representation of focused regions is enhanced, improving focus detection sensitivity and enabling precise capture of focus variations. In addition, the introduction of semantic context information enables effective integration of local and global focus cues, further increasing estimation accuracy. Experimental results across multiple datasets show that the proposed model achieves competitive performance compared with existing methods. Visual results on the Mobile Depth dataset further demonstrate its generalization ability. Nonetheless, the model shows limitations in extremely distant regions. Future work could incorporate multimodal information or frequency-domain features to further improve depth accuracy in weakly textured scenes. -
Key words:
- Depth from focus /
- Focus measure /
- Contextual information
-
表 1 FoD500数据集各算法指标评估
方法 MSE↓ RMS↓ logRMS↓ Abs.rel.↓ Sqr.rel.↓ δ↑ δ2↑ δ3↑ Bump.↓ avgUnc.↓ 时间(ms)↓ VDFF(2015) 29.66×10–2 5.05×10–1 0.87 1.18 85.62×10–2 17.92 32.66 50.31 1.12 - - RDF(2017) 11.15×10–2 3.22×10–1 0.71 0.46 23.95×10–2 39.48 64.65 76.13 1.54 - - DDFF(2019) 3.34×10–2 1.67×10–1 0.27 0.17 3.56×10–2 72.82 89.96 96.26 1.74 - 50.6 DefousNet(2020) 2.18×10–2 1.34×10–1 0.24 0.15 3.59×10–2 81.14 93.31 96.62 2.52 - 24.7 FV(2022) 1.88×10–2 1.25×10–1 0.21 0.14 2.43×10–2 81.16 94.97 98.08 1.45 0.24 18.1 DFV(2022) 2.05×10–2 1.29×10–1 0.21 0.13 2.39×10–2 81.90 94.68 98.05 1.43 0.17 18.2 DDFS(2024) 3.08×10–2 1.49×10–1 0.22 0.11 2.55×10–2 87.02 94.38 96.99 - - 22.8 Ours 1.79×10–2 1.20×10–1 0.20 0.13 2.29×10–2 83.24 95.44 98.21 1.42 0.16 29.2  下载: 导出CSV
下载: 导出CSV
表 2 DDFF-12数据集各算法指标评估
方法 MSE↓ RMS↓ logRMS↓ Abs.rel.↓ Sqr.rel.↓ δ↑ δ2↑ δ3↑ Bump.↓ avgUnc.↓ 时间(ms)↓ VDFF(2015) 156.55×10–4 12.14×10–2 0.98 1.38 241.2×10–3 15.26 29.46 44.89 0.43 - - RDF(2017) 91.18×10–4 9.41×10–2 0.91 1.00 139.4×10–3 15.65 33.08 47.48 1.33 - - DDFF(2019) 8.97×10–4 2.76×10–2 0.28 0.24 9.47×10–3 61.26 88.70 96.49 0.52 - 191.7 DefousNet(2020) 8.61×10–4 2.55×10–2 0.23 0.17 6.00×10–3 72.56 94.15 97.92 0.46 - 34.3 FV(2022) 6.49×10–4 2.28×10–2 0.23 0.18 7.10×10–3 71.93 92.80 97.86 0.42 5.20×10–2 33.2 DFV(2022) 5.70×10–4 2.13×10–2 0.21 0.17 6.26×10–3 76.74 94.23 98.14 0.42 4.99×10–2 33.3 Ours 5.28×10–4 2.05×10–2 0.20 0.16 5.53×10–3 77.95 95.59 98.36 0.41 4.47×10–2 39.7
下载: 导出CSV
表 3 消融实验
模型 FM SCGM DDFF-12 FoD500 MSE↓ Sqr.rel.↓ δ↑ MSE↓ Sqr.rel.↓ δ↑ Baseline 5.70×10–4 6.26×10–3 76.74 2.05×10–2 2.39×10–2 81.90 w/o FM √ 5.31×10–4 5.98×10–3 80.01 2.01×10–2 2.29×10–2 82.36 w/o SCGM √ 5.65×10–4 6.21×10–3 76.95 1.85×10–2 2.26×10–2 82.98 w/ all √ √ 5.28×10–4 5.53×10–3 77.95 1.79×10–2 2.29×10–2 83.24
下载: 导出CSV
表 4 各算法参数量比较
方法 参数量(M)↓ DefocusNet 3.728 DFV 19.522 DDFS 32.528 Baseline 20.826 Baseline+FM+SCGM 22.094
下载: 导出CSV
表 5 不同通道扩展数量的影响
扩张率 DDFF-12 FoD500 MSE↓ Sqr.rel.↓ MSE↓ Sqr.rel.↓ 1 5.40×10–4 6.06×10–3 2.01×10–2 2.28×10–2 2 5.38×10–4 5.56×10–3 1.85×10–2 2.26×10–2 3 5.28×10–4 5.53×10–3 1.79×10–2 2.29×10–2
下载: 导出CSV
-
[1] XIONG Haolin, MUTTUKURU S, XIAO Hanyuan, et al. Sparsegs: Sparse view synthesis using 3D Gaussian splatting[C]. 2025 International Conference on 3D Vision, Singapore, Singapore, 2025: 1032–1041. doi: 10.1109/3DV66043.2025.00100. [2] WESTERMEIER F, BRÜBACH L, WIENRICH C, et al. Assessing depth perception in VR and video see-through AR: A comparison on distance judgment, performance, and preference[J]. IEEE Transactions on Visualization and Computer Graphics, 2024, 30(5): 2140–2150. doi: 10.1109/TVCG.2024.3372061. [3] ZHOU Xiaoyu, LIN Zhiwei, SHAN Xiaojun, et al. DrivingGaussian: Composite Gaussian splatting for surrounding dynamic autonomous driving scenes[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 21634–21643. doi: 10.1109/CVPR52733.2024.02044. [4] 姜文涛, 刘晓璇, 涂潮, 等. 自适应空间异常的目标跟踪[J]. 电子与信息学报, 2022, 44(2): 523–533. doi: 10.11999/JEIT201025.JIANG Wentao, LIU Xiaoxuan, TU Chao, et al. Adaptive spatial and anomaly target tracking[J]. Journal of Electronics & Information Technology, 2022, 44(2): 523–533. doi: 10.11999/JEIT201025. [5] CHEN Rongshan, SHENG Hao, YANG Da, et al. Pixel-wise matching cost function for robust light field depth estimation[J]. Expert Systems with Applications, 2025, 262: 125560. doi: 10.1016/j.eswa.2024.125560. [6] WANG Yingqian, WANG Longguang, LIANG Zhengyu, et al. Occlusion-aware cost constructor for light field depth estimation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 19777–19786. doi: 10.1109/CVPR52688.2022.01919. [7] KE Bingxin, OBUKHOV A, HUANG Shengyu, et al. Repurposing diffusion-based image generators for monocular depth estimation[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 9492–9502. doi: 10.1109/CVPR52733.2024.00907. [8] PATNI S, AGARWAL A, and ARORA C. ECoDepth: Effective conditioning of diffusion models for monocular depth estimation[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 28285–28295. doi: 10.1109/CVPR52733.2024.02672. [9] SI Haozhe, ZHAO Bin, WANG Dong, et al. Fully self-supervised depth estimation from defocus clue[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 9140–9149. doi: 10.1109/CVPR52729.2023.00882. [10] YANG Xinge, FU Qiang, ELHOSEINY M, et al. Aberration-aware depth-from-focus[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(9): 7268–7278. doi: 10.1109/TPAMI.2023.3301931. [11] JEON H G, SURH J, IM S, et al. Ring difference filter for fast and noise robust depth from focus[J]. IEEE Transactions on Image Processing, 2020, 29: 1045–1060. doi: 10.1109/TIP.2019.2937064. [12] FAN Tiantian and YU Hongbin. A novel shape from focus method based on 3D steerable filters for improved performance on treating textureless region[J]. Optics Communications, 2018, 410: 254–261. doi: 10.1016/j.optcom.2017.10.019. [13] SURH J, JEON H G, PARK Y, et al. Noise robust depth from focus using a ring difference filter[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2444–2453. doi: 10.1109/CVPR.2017.262. [14] THELEN A, FREY S, HIRSCH S, et al. Improvements in shape-from-focus for holographic reconstructions with regard to focus operators, neighborhood-size, and height value interpolation[J]. IEEE Transactions on Image Processing, 2009, 18(1): 151–157. doi: 10.1109/TIP.2008.2007049. [15] MAHMOOD M T and CHOI T S. Nonlinear approach for enhancement of image focus volume in shape from focus[J]. IEEE Transactions on Image Processing, 2012, 21(5): 2866–2873. doi: 10.1109/TIP.2012.2186144. [16] MAHMOOD M T. Shape from focus by total variation[C]. IVMSP 2013, Seoul, Korea (South), 2013: 1–4. doi: 10.1109/IVMSPW.2013.6611940. [17] MOELLER M, BENNING M, SCHÖNLIEB C, et al. Variational depth from focus reconstruction[J]. IEEE Transactions on Image Processing, 2015, 24(12): 5369–5378. doi: 10.1109/TIP.2015.2479469. [18] HAZIRBAS C, SOYER S G, STAAB M C, et al. Deep depth from focus[C]. 14th Asian Conference on Computer Vision, Perth, Australia, 2019: 525–541. doi: 10.1007/978-3-030-20893-6_33. [19] CHEN Zhang, GUO Xinqing, LI Siyuan, et al. Deep eyes: Joint depth inference using monocular and binocular cues[J]. Neurocomputing, 2021, 453: 812–824. doi: 10.1016/j.neucom.2020.06.132. [20] MAXIMOV M, GALIM K, and LEAL-TAIXÉ L. Focus on defocus: Bridging the synthetic to real domain gap for depth estimation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 1068–1077. doi: 10.1109/CVPR42600.2020.00115. [21] WON C and JEON H G. Learning depth from focus in the wild[C]. 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 1–18. doi: 10.1007/978-3-031-19769-7_1. [22] WANG N H, WANG Ren, LIU Yulun, et al. Bridging unsupervised and supervised depth from focus via all-in-focus supervision[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 12601–12611. doi: 10.1109/ICCV48922.2021.01239. [23] YANG Fengting, HUANG Xiaolei, and ZHOU Zihan. Deep depth from focus with differential focus volume[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 12632–12641. doi: 10.1109/CVPR52688.2022.01231. [24] 邓慧萍, 盛志超, 向森, 等. 基于语义导向的光场图像深度估计[J]. 电子与信息学报, 2022, 44(8): 2940–2948. doi: 10.11999/JEIT210545.DENG Huiping, SHENG Zhichao, XIANG Sen, et al. Depth estimation based on semantic guidance for light field image[J]. Journal of Electronics & Information Technology, 2022, 44(8): 2940–2948. doi: 10.11999/JEIT210545. [25] HE Mengfei, YANG Zhiyou, ZHANG Guangben, et al. IIMT-net: Poly-1 weights balanced multi-task network for semantic segmentation and depth estimation using interactive information[J]. Image and Vision Computing, 2024, 148: 105109. doi: 10.1016/j.imavis.2024.105109. [26] PERTUZ S, PUIG D, and GARCIA M A. Analysis of focus measure operators for shape-from-focus[J]. Pattern Recognition, 2013, 46(5): 1415–1432. doi: 10.1016/j.patcog.2012.11.011. [27] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 936–944. doi: 10.1109/CVPR.2017.106. [28] WU Tianyi, TANG Sheng, ZHANG Rui, et al. CGNet: A light-weight context guided network for semantic segmentation[J]. IEEE Transactions on Image Processing, 2021: 1169–1179. doi: 10.1109/TIP.2020.3042065. [29] SUWAJANAKORN S, HERNANDEZ C, and SEITZ S M. Depth from focus with your mobile phone[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 3497–3506. doi: 10.1109/CVPR.2015.7298972. [30] FUJIMURA Y, IIYAMA M, FUNATOMI T, et al. Deep depth from focal stack with defocus model for camera-setting invariance[J]. International Journal of Computer Vision, 2024, 132(6): 1970–1985. doi: 10.1007/s11263-023-01964-x. -

 下载:
下载:








图(10) / 表(5)
计量
- 文章访问数: 503
- HTML全文浏览量: 286
- PDF下载量: 22
- 被引次数: 0
