

A Test-Time Adaptive Method for Nighttime Image-Aided Beam Prediction
-
摘要: 针对毫米波通信系统中传统波束管理方法在动态场景下面临的高时延问题以及视觉辅助波束预测技术在恶劣环境下性能显著退化的问题,该文提出一种基于测试时间自适应(TTA)的夜间图像辅助波束预测方法。毫米波通信依赖大规模多输入多输出(MIMO)技术实现高增益窄波束对准,但传统波束扫描机制存在指数级复杂度与时延瓶颈,难以满足车联网等高动态场景需求。现有视觉辅助方法通过深度学习模型提取图像特征并映射波束参数,但在低照度、雨雾等突发恶劣环境下,因训练数据与实时图像特征分布偏移导致预测精度急剧下降。该文创新性地引入测试时间自适应机制,突破传统静态推理模式,仅需在推理阶段对实时采集的低质量图像执行模型的单次梯度反向传播,即可实现跨域特征分布动态对齐,无须预先采集或标注恶劣场景数据。具体而言,设计基于熵最小化的一致性学习策略,通过对原始视图与数据增强视图的预测一致性约束,驱动模型参数向预测置信度最大化方向迭代更新,降低预测不确定性。实验表明,在真实夜间场景下,该文所提方法的top-3波束预测准确率达93.01%,较静态部署方案提升约20%,且显著优于传统低光照增强方法。该方法充分利用基站固定部署场景中背景语义的跨域一致性特性,通过轻量化在线自适应机制实现模型鲁棒性增强,为毫米波通信系统在复杂开放环境中的高效波束管理提供了新路径。Abstract:
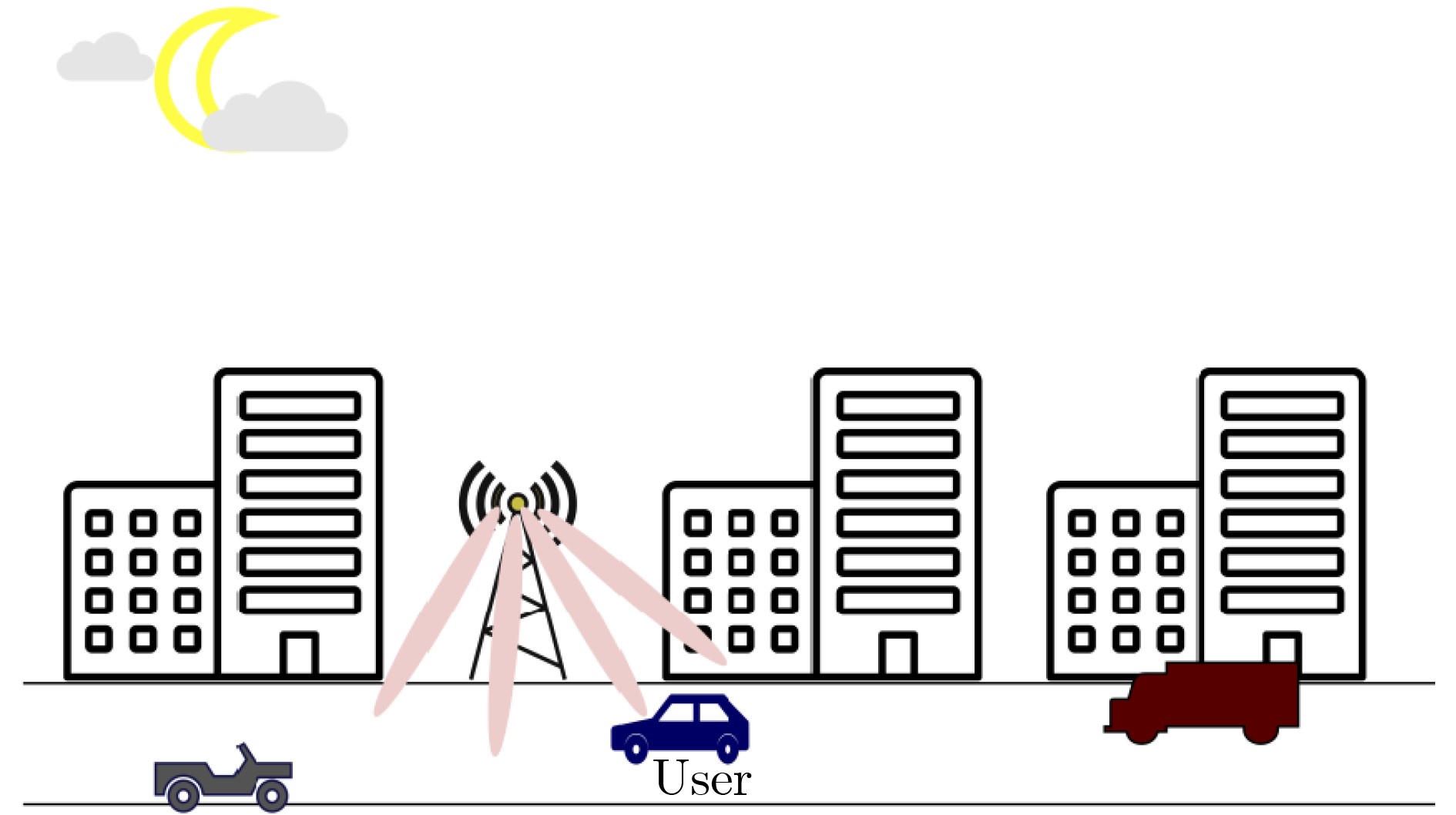
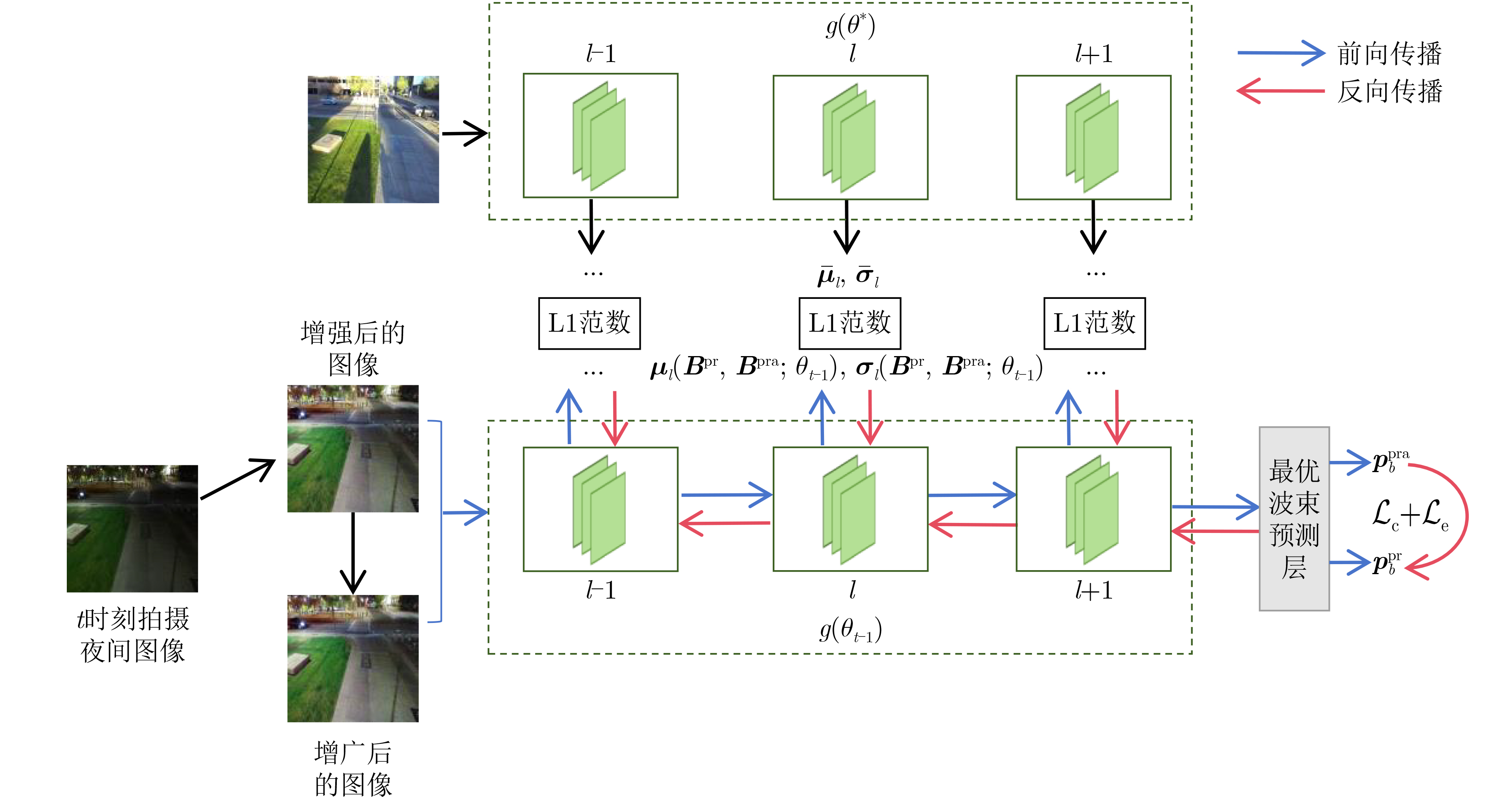
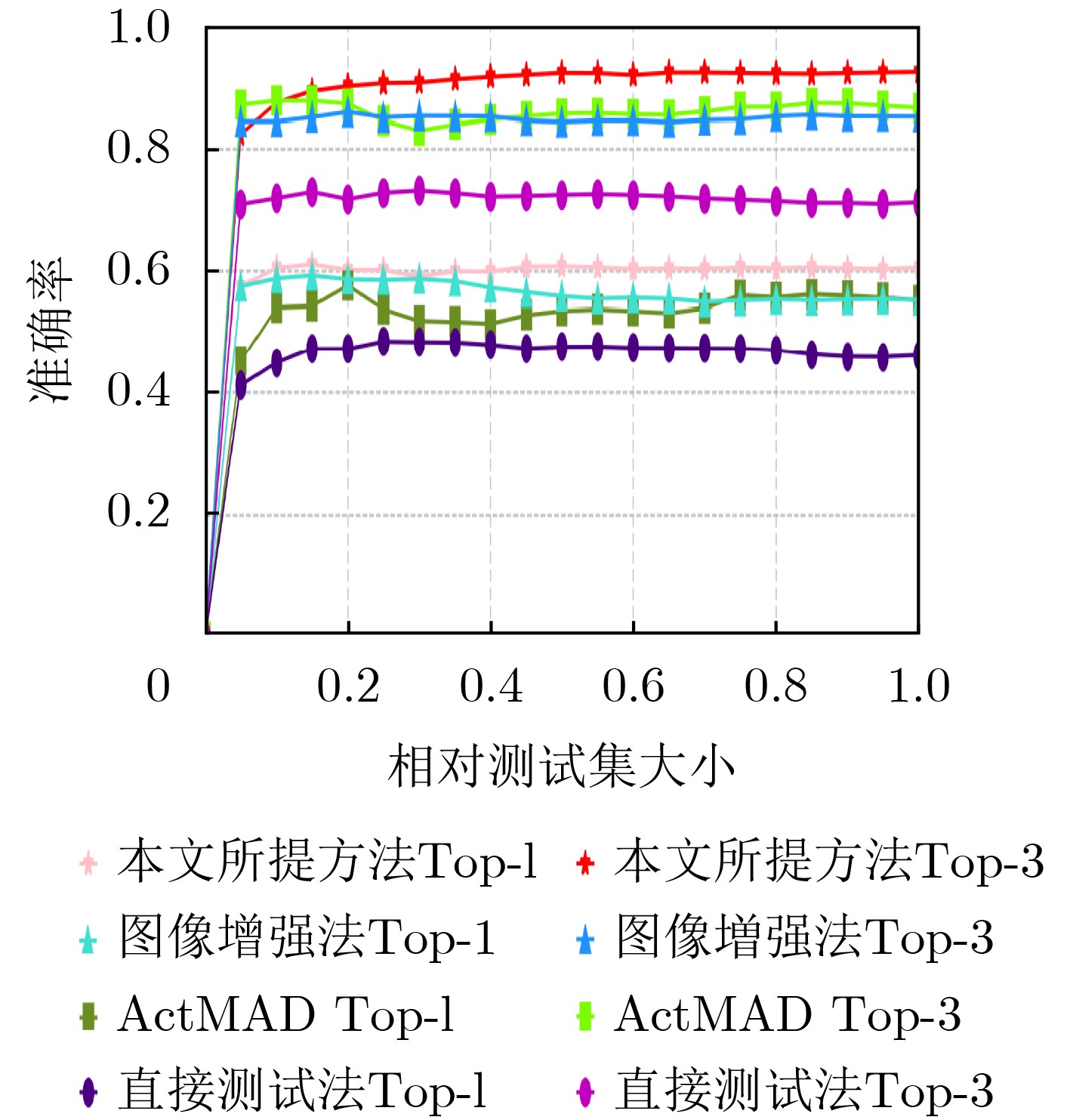
The latency of traditional beam management in dynamic scenarios and the severe degradation of vision-aided beam prediction under adverse environmental conditions in millimeter-wave (mmWave) systems are addressed by a nighttime image-assisted beam prediction method based on Test-Time Adaptation (TTA). mmWave communications rely on massive Multiple-Input Multiple-Output (MIMO) technology to achieve high-gain narrow beam alignment. However, conventional beam scanning suffers from exponential complexity and latency, limiting applicability in high-mobility settings such as vehicular networks. Vision-assisted schemes that employ deep learning to map image features to beam parameters experience sharp performance loss in low-light, rainy, or foggy environments because of distribution shifts between training data and real-time inputs. In the proposed framework, a TTA mechanism is introduced to overcome the limitations of static inference by performing a single gradient back propagation across model parameters during inference on degraded images. This adaptation dynamically aligns cross-domain feature distributions without the need for adverse-condition data collection or annotation. An entropy minimization-based consistency strategy is further designed to enforce agreement between original and augmented views, guiding parameter updates toward higher confidence and lower uncertainty. Experiments on real nighttime scenarios demonstrate that the framework achieves a top-3 beam prediction accuracy of 93.01%, improving performance by nearly 20% over static inference and outperforming conventional low-light enhancement. By leveraging the semantic consistency of fixed-base-station deployments, this lightweight online adaptation improves robustness, providing a promising solution for efficient beam management in mmWave systems operating in complex open environments. Objective mmWave communication, a cornerstone of 5G and beyond, relies on massive MIMO architectures to counter severe path loss through high-gain narrow beam alignment. Traditional beam management schemes, based on exhaustive beam scanning and channel measurement, incur exponential complexity and latency on the order of hundreds of milliseconds, making them unsuitable for high-mobility scenarios such as vehicular networks. Vision-aided beam prediction has recently emerged as a promising alternative, using deep learning to map visual features (e.g., user location and motion) to optimal beam parameters. Although this approach achieves high accuracy under daytime conditions (>90%), it experiences sharp performance degradation in low-light, rainy, or foggy environments because of domain shifts between training data (typically daylight images) and real-time degraded inputs. Existing countermeasures depend on offline data augmentation, which is costly and provides limited generalization to unseen adverse environments. To overcome these limitations, this work proposes a lightweight online adaptation framework that dynamically aligns cross-domain features during inference, eliminating the need for pre-collected adverse-condition data. The objective is to enable robust mmWave communications in unpredictable environments, a necessary step toward practical deployment in autonomous driving and industrial IoT. Methods The proposed TTA method operates in three stages. First, a pre-trained beam prediction model with a ResNet-18 backbone is initialized using daylight images and labeled beam indices. During inference, real-time low-quality nighttime images are processed through two parallel pipelines: (1) the original view and (2) a data-augmented view incorporating Gaussian noise. A consistency loss is applied to minimize the prediction distance between the two views, enforcing robustness against local feature perturbations. In parallel, an entropy minimization loss sharpens the output probability distribution by penalizing high prediction uncertainty. These combined losses drive a single-step gradient back propagation that updates all model parameters. Through this mechanism, feature distributions between the training (daylight) and testing (nighttime) domains are aligned without altering global semantic representations, as illustrated in Fig. 2 . The system architecture consists of a roadside base station equipped with an RGB camera and a N-element antenna array, which captures environmental data and executes real-time beam prediction.Results and Discussions Experiments on a real-world dataset demonstrate the effectiveness of the proposed method. Under nighttime conditions, the TTA framework achieves a Top-3 beam prediction accuracy of 93.01%, exceeding static inference (71.25%) and traditional low-light enhancement methods (85.27%) ( Table 3 ). Ablation studies further validate the contributions of each component: the online feature alignment mechanism, optimized for small-batch data, significantly improves accuracy (Table 4 ), and the entropy minimization strategy with multi-view consistency learning provides additional gains (Table 5 ). As shown inFigure 4 , the framework exhibits rapid convergence during online testing, enabling base stations to promptly recover performance when faced with new environmental disturbances.Conclusions This study addresses the limited robustness of existing vision-aided beam prediction methods in dynamically changing environments by introducing a TTA framework for nighttime image-assisted beam prediction. A small-batch adaptive feature alignment strategy is developed to mitigate feature mismatches in unseen domains while satisfying real-time communication constraints. Besides, a joint optimization framework integrates classical low-light image enhancement with multi-view consistency learning, thereby improving feature discrimination under complex lighting conditions. Experiments conducted on real-world data confirm the effectiveness of the proposed algorithm, achieving more than 20% higher Top-3 beam prediction accuracy compared with direct testing. These results demonstrate the framework’s robustness in dynamic environments and its potential to optimize vision-aided communication systems under non-ideal conditions. Future work will extend this approach to beam prediction under rain and fog, as well as to multi-modal perception-assisted communication systems. -
Key words:
- Vision aided beam prediction /
- Test-time adaptation /
- Consistency learning
-
表 2 测试时间自适应的超参数
超参数 描述 参数值 Lr_t 自适应的学习率 $ 1.25 \times {10^{ - 5}} $ Optimizer_t 自适应的优化器类型 SGD Bs 遍历训练集时的批输入大小 128 B 夜间图像的批输入大小 4  下载: 导出CSV
下载: 导出CSV
表 3 预测准确率对比(%)
方法 Top-1 Top-2 Top-3 直接测试法 46.17 63.58 71.25 图像增强法 55.14 77.74 85.27 ActMAD 55.14 78.61 86.68 本文方法 60.96 86.28 93.01
下载: 导出CSV
表 4 小批次在线异域特征对齐方法有效性(%)
方法 Top-1 Top-2 Top-3 图像增强法 55.14 77.74 85.27 ActMAD 55.14 78.61 86.68 小批次适用的方法 57.09 81.00 88.57
下载: 导出CSV
表 5 多视图在线一致性学习的有效性(%)
方法 Top-1 Top-2 Top-3 小批次适用的方法 57.09 81.00 88.57 增加$ {\mathcal{L}_{\text{e}}} $ 58.94 83.93 91.02 增加一致性学习 60.96 86.28 93.01
下载: 导出CSV
表 6 不同批处理大小下的预测准确率对比(%)
B Top-1 Top-2 Top-3 2 60.42 86.42 93.21 4 60.96 86.28 93.01 8 60.96 86.52 93.01
下载: 导出CSV
表 7 在线学习前后在验证集上的预测准确率(%)
模型参数 Top-1 Top-2 Top-3 $ {\theta ^{\text{*}}} $ 73.96 95.12 98.65 $ {\theta ^{{\text{tta}}}} $ 73.34 95.02 98.55
下载: 导出CSV
-
[1] JIANG Shuaifeng and ALKHATEEB A. Computer vision aided beam tracking in a real-world millimeter wave deployment[C]. 2022 IEEE Globecom Workshops, Rio de Janeiro, Brazil, 2022: 142–147. doi: 10.1109/GCWkshps56602.2022.10008648. [2] HUANG Wei, HUANG Xueqing, ZHANG Haiyang, et al. Vision image aided near-field beam training for internet of vehicle systems[C]. 2024 IEEE International Conference on Communications Workshops, Denver, USA, 2024: 390–395. doi: 10.1109/ICCWorkshops59551.2024.10615560. [3] CHARAN G, OSMAN T, HREDZAK A, et al. Vision-position multi-modal beam prediction using real millimeter wave datasets[C]. 2022 IEEE Wireless Communications and Networking Conference, Austin, USA, 21022: 2727–2731. doi: 10.1109/WCNC51071.2022.9771835. [4] LI Kehui, ZHOU Binggui, GUO Jiajia, et al. Vision-aided multi-user beam tracking for mmWave massive MIMO system: Prototyping and experimental results[C]. IEEE 99th Vehicular Technology Conference, Singapore, Singapore, 2024: 1–6. doi: 10.1109/VTC2024-Spring62846.2024.10683659. [5] OUYANG Ming, GAO Feifei, WANG Yucong, et al. Computer vision-aided reconfigurable intelligent surface-based beam tracking: Prototyping and experimental results[J]. IEEE Transactions on Wireless Communications, 2023, 22(12): 8681–8693. doi: 10.1109/TWC.2023.3264752. [6] WEN Feiyang, XU Weihua, GAO Feifei, et al. Vision aided environment semantics extraction and its application in mmWave beam selection[J]. IEEE Communications Letters, 2023, 27(7): 1894–1898. doi: 10.1109/LCOMM.2023.3270039. [7] DEMIRHAN U and ALKHATEEB A. Radar aided 6G beam prediction: Deep learning algorithms and real-world demonstration[C]. 2022 IEEE Wireless Communications and Networking Conference (WCNC). Austin, USA, 2022, 2655–2660. doi: 10.1109/WCNC51071.2022.9771564. [8] ZHANG Tengyu, LIU Jun, and GAO Feifei. Vision aided beam tracking and frequency handoff for mmWave communications[C]. IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS). New York, USA, 2022, 1–2. doi: 10.1109/INFOCOMWKSHPS54753.2022.9798197. [9] XU Weihua, GAO Fefei, TAO Xiaoming, et al. Computer vision aided mmWave beam alignment in V2X communications[J]. IEEE Transactions on Wireless Communications, 2023, 22(4): 2699–2714. doi: 10.1109/TWC.2022.3213541.doi:10.1109/twc.2022.3213541. [10] ALRABEIAH M, HREDZAK A, and ALKHATEEB A. Millimeter wave base stations with cameras: Vision-aided beam and blockage prediction[C]. 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 2020: 1–5. doi: 10.1109/VTC2020-Spring48590.2020.9129369. [11] WANG Heng, OU Binbao, XIE Xin, et al. Vision-aided mmWave beam and blockage prediction in low-light environment[J]. IEEE Wireless Communications Letters, 2025, 14(3): 791–795. doi: 10.1109/LWC.2024.3523400. [12] BASAK H and YIN Zhaozheng. Forget more to learn more: Domain-specific feature unlearning for semi-supervised and unsupervised domain adaptation[C]. 18th European Conference on Computer Vision, Milan, Italy, 2024: 130–148. doi: 10.1007/978-3-031-72920-1_8. [13] SCHNEIDER S, RUSAK E, ECK L, et al. Improving robustness against common corruptions by covariate shift adaptation[C]. Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 968. [14] MIRZA J M, SONEIRA P J, LIN Wei, et al. ActMAD: Activation matching to align distributions for test-time-training[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 24152–24161. doi: 10.1109/CVPR52729.2023.02313. [15] ZUIDERVELD K. Contrast limited adaptive histogram equalization[M]. HECKBERT P S. Graphics Gems IV. Amsterdam: Elsevier, 1994: 474–485. doi: 10.1016/B978-0-12-336156-1.50061-6. [16] ALKHATEEB A, CHARAN G, OSMAN T, et al. DeepSense 6G: A large-scale real-world multi-modal sensing and communication dataset[J]. IEEE Communications Magazine, 2023, 61(9): 122–128. doi: 10.1109/MCOM.006.2200730. [17] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [18] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]. 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248–255. doi: 10.1109/CVPR.2009.5206848. [19] WANG Dequan, SHELHAMER E, LIU Shaoteng, et al. Tent: Fully test-time adaptation by entropy minimization[C]. 9th International Conference on Learning Representations, 2021: 1–15. -

 下载:
下载:



图(4) / 表(7)
计量
- 文章访问数: 500
- HTML全文浏览量: 373
- PDF下载量: 27
- 被引次数: 0
