

Cross Modal Hashing of Medical Image Semantic Mining for Large Language Model
-
摘要: 针对医学图像与文本深层语义关系建模不足的挑战,该文提出基于大语言模型(LLM)驱动的医学图像语义挖掘哈希方法。首先,联合大语言模型的语义泛化能力,设计了图像描述型、诊断报告总结型和联合模态推理型提示模板进行模态数据增强,从而实现了对医学图像和诊断报告数据的深层次语义挖掘。其次,设计了结构化编码层,以确保图像和文本的特征能够在统一的嵌入空间内进行精确匹配。然后,设计了提示指令模板,采用软提示和硬提示相结合的方式微调大语言模型,实现图像和文本特征的对齐。最后,引入高斯2元受限玻尔兹曼机进行概率化哈希映射,有效保留数据结构信息。实验验证,该方法与最近的经典跨模态哈希检索方法相比,在两个数据集上平均检索精度分别提升7.21%和7.72%。Abstract:
Objective A novel cross-modal hashing framework driven by Large Language Models (LLMs) is proposed to address the semantic misalignment between medical images and their corresponding textual reports. The objective is to enhance cross-modal semantic representation and improve retrieval accuracy by effectively mining and matching semantic associations between modalities. Methods The generative capacity of LLMs is first leveraged to produce high-quality textual descriptions of medical images. These descriptions are integrated with diagnostic reports and structured clinical data using a dual-stream semantic enhancement module, designed to reinforce inter-modality alignment and improve semantic comprehension. A structural similarity-guided hashing scheme is then developed to encode both visual and textual features into a unified Hamming space, ensuring semantic consistency and enabling efficient retrieval. To further enhance semantic alignment, a prompt-driven attention template is introduced to fuse image and text features through fine-tuned LLMs. Finally, a contrastive loss function with hard negative mining is employed to improve representation discrimination and retrieval accuracy. Results and Discussions Experiments are conducted on a multimodal medical dataset to compare the proposed method with existing cross-modal hashing baselines. The results indicate that the proposed method significantly outperforms baseline models in terms of precision and Mean Average Precision (MAP) ( Table 3 ;Table 4 ). On average, a 7.21% improvement in retrieval accuracy and a 7.72% increase in MAP are achieved across multiple data scales, confirming the effectiveness of the LLM-driven semantic mining and hashing approach.Conclusions Experiments are conducted on a multimodal medical dataset to compare the proposed method with existing cross-modal hashing baselines. The results indicate that the proposed method significantly outperforms baseline models in terms of precision and Mean Average Precision (MAP) ( Table 3 ;Table 4 ). On average, a 7.21% improvement in retrieval accuracy and a 7.72% increase in MAP are achieved across multiple data scales, confirming the effectiveness of the LLM-driven semantic mining and hashing approach.-
Key words:
- Cross-modal retrieval /
- Hashing /
- Large Language Models(LLM) /
- Semantic alignment /
- Data augmentation
-
表 1 本文术语和符号总结
符号 描述 ${\boldsymbol{Z}}$ 医学图像数据${\boldsymbol{I}}$通过ViT模块后的视觉特征矩阵 ${\boldsymbol{X}}$ 视觉特征矩阵${\boldsymbol{Z}}$通过结构化编码层得到的视觉语义嵌入矩阵 ${\boldsymbol{Y}}$ 诊断报告数据${\boldsymbol{T}}$通过大语言模型编码层得到的文本语义嵌入
矩阵${v^{\boldsymbol{x}}}$ 视觉语义嵌入向量${\boldsymbol{x}}$通过大语言模型后得到的特征表示 ${v^{\boldsymbol{y}}}$ 文本语义嵌入向量${\boldsymbol{y}}$通过大语言模型后得到的特征表示 ${h^{\boldsymbol{x}}}$ GBRBM的隐藏层输出,及医学图像对应的哈希码 ${h^{\boldsymbol{y}}}$ GBRBM的隐藏层输出,及诊断报告对应的哈希码 g(·) ViT模型网络函数 $w$ 可见层$v$和隐藏层$h$之间的权重 $ \sigma $ 可见单元$v$相关的标准差 $ b $ 可见层$v$的偏置 $a$ 隐藏层$h$的偏置 Sma 不同模态实例之间的流形相似度  下载: 导出CSV
下载: 导出CSV
表 2 MIMIC和URBN数据集划分
数据集名 数据集 训练集 查询集 检索集 MIMIC 116 282 58 141 10 000 106 282 URBN 2 261 1 831 226 2 035
下载: 导出CSV
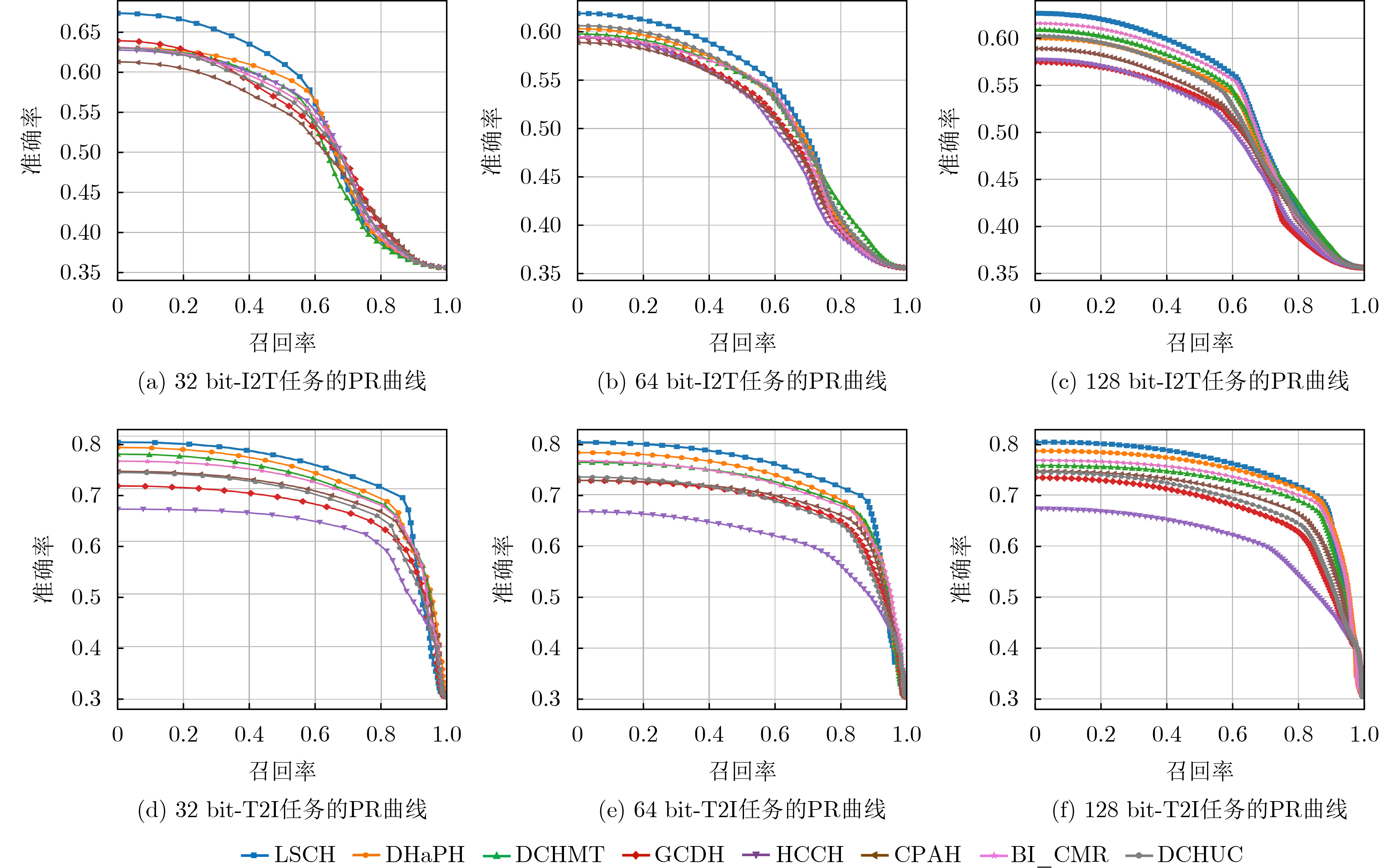
表 3 在MIMIC数据集上不同长度哈希码的MAP值表现
方法 I2T T2I 32 bit 64 bit 128 bit 32 bit 64 bit 128 bit DCHUC 0.655 0.677 0.683 0.682 0.696 0.705 BI_CMR 0.661 0.678 0.698 0.718 0.734 0.753 CPAH 0.640 0.657 0.673 0.696 0.703 0.715 HCCH 0.647 0.654 0.685 0.635 0.635 0.644 GCDH 0.652 0.663 0.661 0.664 0.685 0.691 DCHMT 0.672 0.683 0.691 0.732 0.741 0.742 DHaPH 0.681 0.674 0.682 0.752 0.765 0.776 LSCH 0.694 0.693 0.705 0.761 0.784 0.789
下载: 导出CSV
表 4 在URBN数据集上不同长度哈希码的MAP值表现
方法 I2T T2I 32 bit 64 bit 128 bit 32 bit 64 bit 128 bit DCHUC 0.676 0.674 0.682 0.763 0.772 0.792 BI_CMR 0.718 0.723 0.740 0.798 0.811 0.823 CPAH 0.663 0.679 0.664 0.757 0.782 0.786 HCCH 0.721 0.705 0.723 0.736 0.746 0.755 GCDH 0.726 0.731 0.736 0.778 0.806 0.817 DCHMT 0.741 0.748 0.756 0.806 0.825 0.845 DHaPH 0.751 0.759 0.750 0.812 0.834 0.838 LSCH 0.762 0.773 0.769 0.842 0.861 0.872
下载: 导出CSV
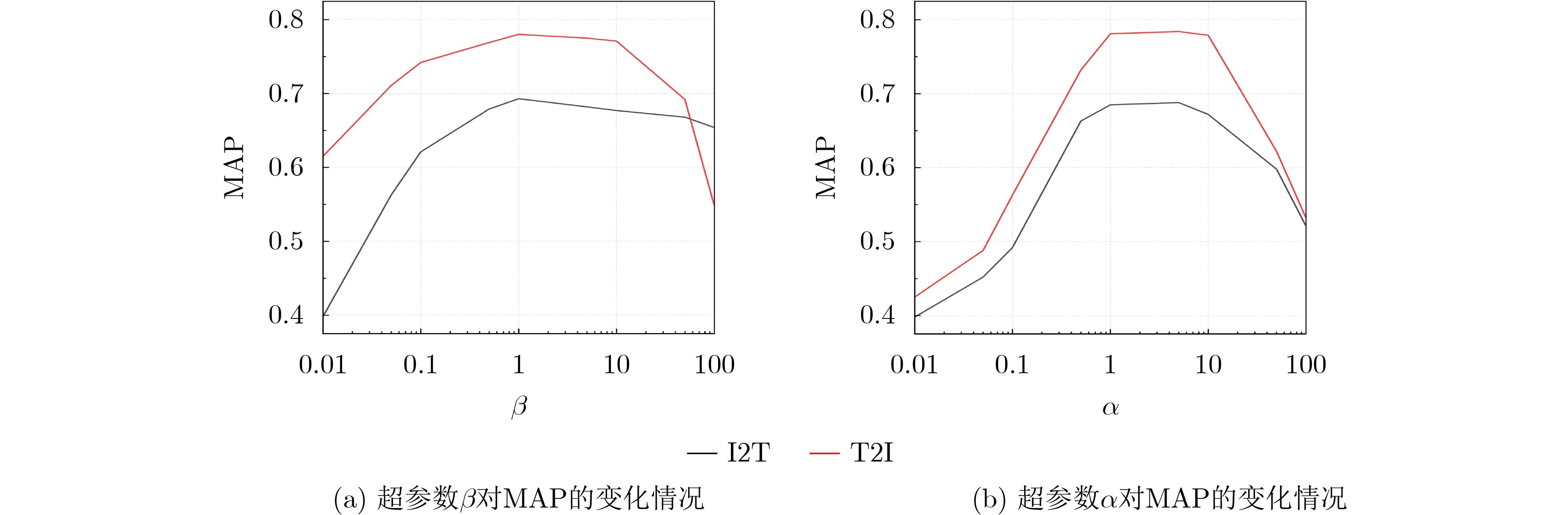
表 5 在两个基准数据集上不同任务的最优参数组合
数据集 任务 I2T T2I MIMIC $\alpha $=2, $\beta $=1 $\alpha $=5, $\beta $=2 URBN $\alpha $=0.5, $\beta $=0.8 $\alpha $=0.6, $\beta $=0.1
下载: 导出CSV
表 6 在MIMIC数据集上对LSCH及其变体进行MAP比较
方法 I2T T2I 32 bit 64 bit 128 bit 32 bit 64 bit 128 bit LSCH 0.694 0.693 0.705 0.761 0.784 0.789 LSCH-1 0.674 0.678 0.682 0.723 0.734 0.743 LSCH-2 0.681 0.685 0.692 0.743 0.762 0.758 LSCH-3 0.685 0.691 0.693 0.746 0.766 0.774 LSCH-4 0.688 0.691 0.698 0.756 0.772 0.783 LSCH-5 0.675 0.688 0.691 0.732 0.742 0.765 LSCH-6 0.682 0.685 0.689 0.719 0.718 0.733
下载: 导出CSV
-
[1] HUANG S C, PAREEK A, SEYYEDI S, et al. Fusion of medical imaging and electronic health records using deep learning: A systematic review and implementation guidelines[J]. NPJ Digital Medicine, 2020, 3: 136. doi: 10.1038/s41746-020-00341-z. [2] HOLSTE G, PARTRIDGE S C, RAHBAR H, et al. End-to-end learning of fused image and non-image features for improved breast cancer classification from MRI[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 3287–3296. doi: 10.1109/ICCVW54120.2021.00368. [3] FANG Shichao, HONG Shenda, LI Qing, et al. Cross-modal similar clinical case retrieval using a modular model based on contrastive learning and k-nearest neighbor search[J]. International Journal of Medical Informatics, 2025, 193: 105680. doi: 10.1016/j.ijmedinf.2024.105680. [4] ZHANG Yilin. Multi-modal medical image matching based on multi-task learning and semantic-enhanced cross-modal retrieval[J]. Traitement du Signal, 2023, 40(5): 2041–2049. doi: 10.18280/ts.400522. [5] ZHU Xiangru, LI Zhixu, WANG Xiaodan, et al. Multi-modal knowledge graph construction and application: A survey[J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(2): 715–735. doi: 10.1109/TKDE.2022.3224228. [6] XU Liming, ZENG Xianhua, ZHENG Bochuan, et al. Multi-manifold deep discriminative cross-modal hashing for medical image retrieval[J]. IEEE Transactions on Image Processing, 2022, 31: 3371–3385. doi: 10.1109/TIP.2022.3171081. [7] FANG Jiansheng, FU Huazhu, and LIU Jiang. Deep triplet hashing network for case-based medical image retrieval[J]. Medical Image Analysis, 2021, 69: 101981. doi: 10.1016/j.media.2021.101981. [8] LI Junnan, LI Dongxu, SAVARESE S, et al. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models[C]. 40th International Conference on Machine Learning, Honolulu, USA, 2023: 19730–19742. [9] ZHANG Pan, DONG Xiaoyi, WANG Bin, et al. InternLM-XComposer: A vision-language large model for advanced text-image comprehension and composition[EB/OL]. https://doi.org/10.48550/arXiv.2309.15112, 2023. [10] ZHU Hongyi, HUANG Jiahong, RUDINAC S, et al. Enhancing interactive image retrieval with query rewriting using large language models and vision language models[C]. 2024 International Conference on Multimedia Retrieval, Phuket, Thailand, 2024: 978–987. doi: 10.1145/3652583.3658032. [11] LEE J, YOON W, KIM S, et al. BioBERT: A pre-trained biomedical language representation model for biomedical text mining[J]. Bioinformatics, 2020, 36(4): 1234–1240. doi: 10.1093/bioinformatics/btz682. [12] SANDERSON K. GPT-4 is here: What scientists think[J]. Nature, 2023, 615(7954): 773. doi: 10.1038/d41586-023-00816-5. [13] JIANG Qingyuan and LI Wujun. Deep cross-modal hashing[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 3270–3278. doi: 10.1109/CVPR.2017.348. [14] WU Gengshen, LIN Zijia, HAN Jungong, et al. Unsupervised deep hashing via binary latent factor models for large-scale cross-modal retrieval[C]. 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 2018: 2854–2860. doi: 10.24963/ijcai.2018/396. [15] LI Chao, DENG Cheng, LI Ning, et al. Self-supervised adversarial hashing networks for cross-modal retrieval[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 4242–4251. doi: 10.1109/CVPR.2018.00446. [16] LI Tieying, YANG Xiaochun, WANG Bin, et al. Bi-CMR: Bidirectional reinforcement guided hashing for effective cross-modal retrieval[C]. 36th AAAI Conference on Artificial Intelligence, 2022: 10275–10282. doi: 10.1609/aaai.v36i9.21268. [17] BAO Hangbo, WANG Wenhui, DONG Li, et al. VLMo: Unified vision-language pre-training with mixture-of-modality-experts[C]. 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 2384. [18] MELCHIOR J, WANG Nan, and WISKOTT L. Gaussian-binary restricted boltzmann machines for modeling natural image statistics[J]. PLoS One, 2017, 12(2): e0171015. doi: 10.1371/journal.pone.0171015. [19] JOHNSON A E W, POLLARD T J, GREENBAUM N R, et al. MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs[EB/OL]. https://doi.org/10.48550/arXiv.1901.07042, 2023. [20] DEMNER-FUSHMAN D, KOHLI M D, ROSENMAN M B, et al. Preparing a collection of radiology examinations for distribution and retrieval[J]. Journal of the American Medical Informatics Association, 2016, 23(2): 304–310. doi: 10.1093/jamia/ocv080. [21] SHARMA P, DING Nan, GOODMAN S, et al. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning[C]. 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 2556–2565. doi: 10.18653/v1/P18-1238. [22] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]. 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248–255. doi: 10.1109/CVPR.2009.5206848. [23] GILARDI F, ALIZADEH M, and KUBLI M. ChatGPT outperforms crowd workers for text-annotation tasks[J]. Proceedings of the National Academy of Sciences of the United States of America, 2023, 120(30): e2305016120. doi: 10.1073/pnas.2305016120. [24] DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, USA, 2019: 4171–4186. doi: 10.18653/v1/N19-1423. [25] LESTER B, AL-RFOU R, and CONSTANT N. The power of scale for parameter-efficient prompt tuning[C]. 2021 Conference on Empirical Methods in Natural Language Processing, 2021: 3045–3059. doi: 10.18653/v1/2021. emnlp-main. 243. [26] LI X L and LIANG P. Prefix-tuning: Optimizing continuous prompts for generation[C]. 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 2024: 4582–4597. doi: 10.18653/v1/2021.acl-long.353. [27] 吴钱林, 唐伦, 刘青海, 等. 基于Transformer语义对齐的医学图像跨模态哈希检索[J]. 生物医学工程学杂志, 2025, 42(1): 156–163. doi: 10.7507/1001-5515.202407034.WU Qianlin, TANG Lun, LIU Qinghai, et al. Cross-modal hash retrieval of medical images based on Transformer semantic alignment[J]. Journal of Biomedical Engineering, 2005, 42(1): 156–163. doi: 10.7507/1001-5515.202407034. [28] TU Rongcheng, MAO Xianling, MA Bing, et al. Deep cross-modal hashing with hashing functions and unified hash codes jointly learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(2): 560–572. doi: 10.1109/TKDE.2020.2987312. [29] XIE De, DENG Cheng, LI Chao, et al. Multi-task consistency-preserving adversarial hashing for cross-modal retrieval[J]. IEEE Transactions on Image Processing, 2020, 29: 3626–3637. doi: 10.1109/TIP.2020.2963957. [30] SUN Yuan, REN Zhenwen, HU Peng, et al. Hierarchical consensus hashing for cross-modal retrieval[J]. IEEE Transactions on Multimedia, 2024, 26: 824–836. doi: 10.1109/TMM.2023.3272169. [31] BAI Cong, ZENG Chao, MA Qing, et al. Graph convolutional network discrete hashing for cross-modal retrieval[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(4): 4756–4767. doi: 10.1109/TNNLS.2022.3174970. [32] TU Junfeng, LIU Xueliang, LIN Zongxiang, et al. Differentiable cross-modal hashing via multimodal transformers[C]. 30th ACM International Conference on Multimedia, Lisboa, Portugal, 2022: 453–461. doi: 10.1145/3503161.3548187. [33] HUO Yadong, QIN Qibing, ZHANG Wenfeng, et al. Deep hierarchy-aware proxy hashing with self-paced learning for cross-modal retrieval[J]. IEEE Transactions on Knowledge and Data Engineering, 2024, 36(11): 5926–5939. doi: 10.1109/TKDE.2024.3401050. -


 下载:
下载:




图(6) / 表(6)
计量
- 文章访问数: 658
- HTML全文浏览量: 575
- PDF下载量: 80
- 被引次数: 0
