

High-Performance Hardware Design of Arithmetic Coding for Deep Neural Network-Based Image Compression
-
摘要: 随着深度学习驱动的图像压缩技术迅速发展,面向深度神经网络(DNN)的图像压缩亟需一种高性能熵编码架构,以满足对高速压缩的实际需求。针对传统熵编码在硬件实现中面临的运算延迟与资源开销瓶颈,该文提出并实现了一种基于现场可编程逻辑门阵列(FPGA)的高效Range Asymmetric Numeral Systems (RANS)算术编码架构。在设计优化方面,首先引入硬件友好的除法变乘法策略降低除法与取模运算的延迟;其次结合细粒度量化与精度校准机制,在减少资源消耗的同时保证计算精度;最后,基于交织并行设计思想实现可调多通道高速压缩路径,大幅提升系统吞吐率。该架构部署于Xilinx Kintex-7 XC7K325T FPGA平台,在可控压缩率损失下,实现了高达191.97 MSymbol/s的吞吐性能,与现有最新熵编码硬件方案齐平,同时在资源利用率与系统扩展性方面也展现出显著优势,具备良好的工程应用潜力。
-
关键词:
- 熵编码 /
- 图像压缩 /
- FPGA /
- 区间非对称数值系统(RANS)
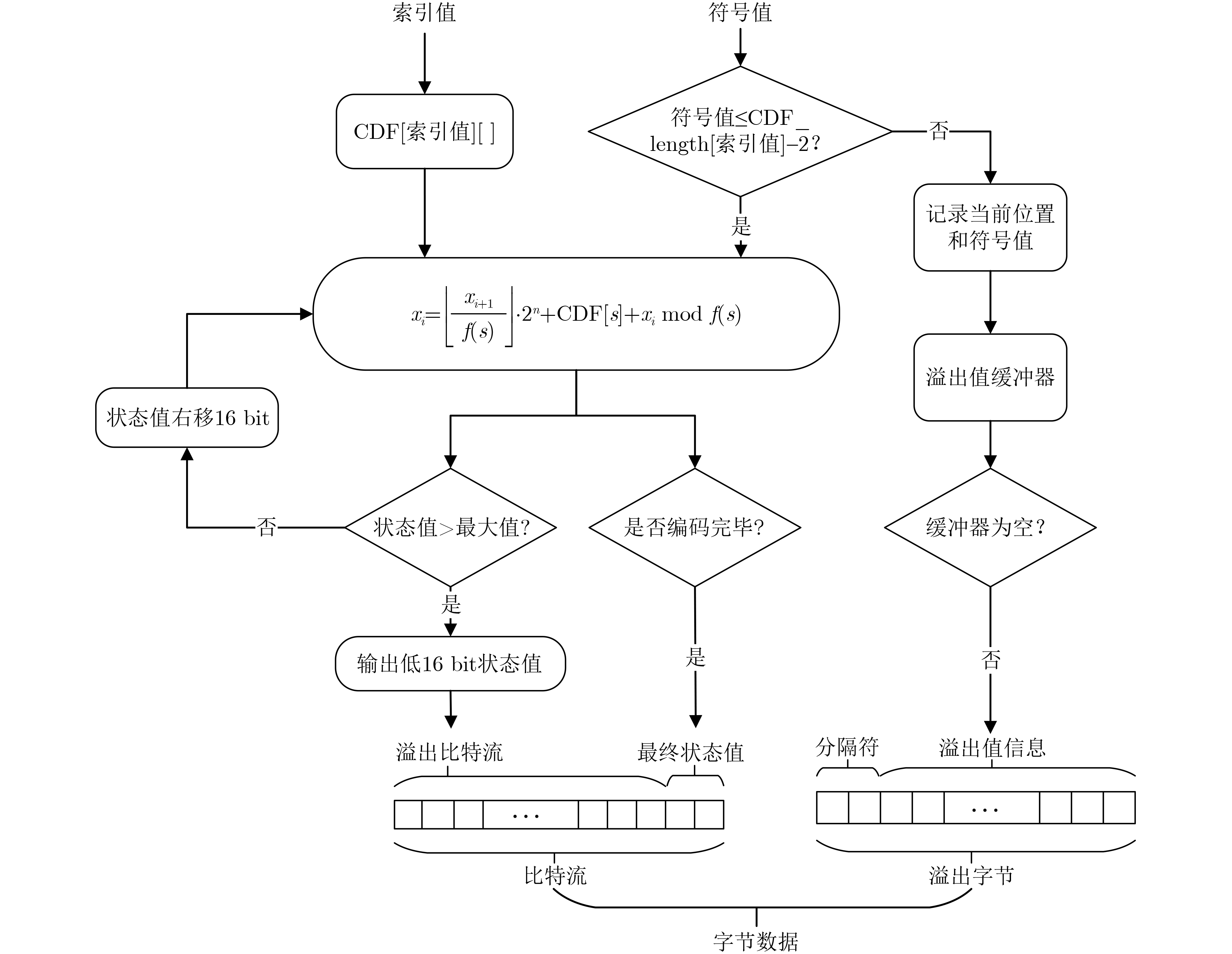
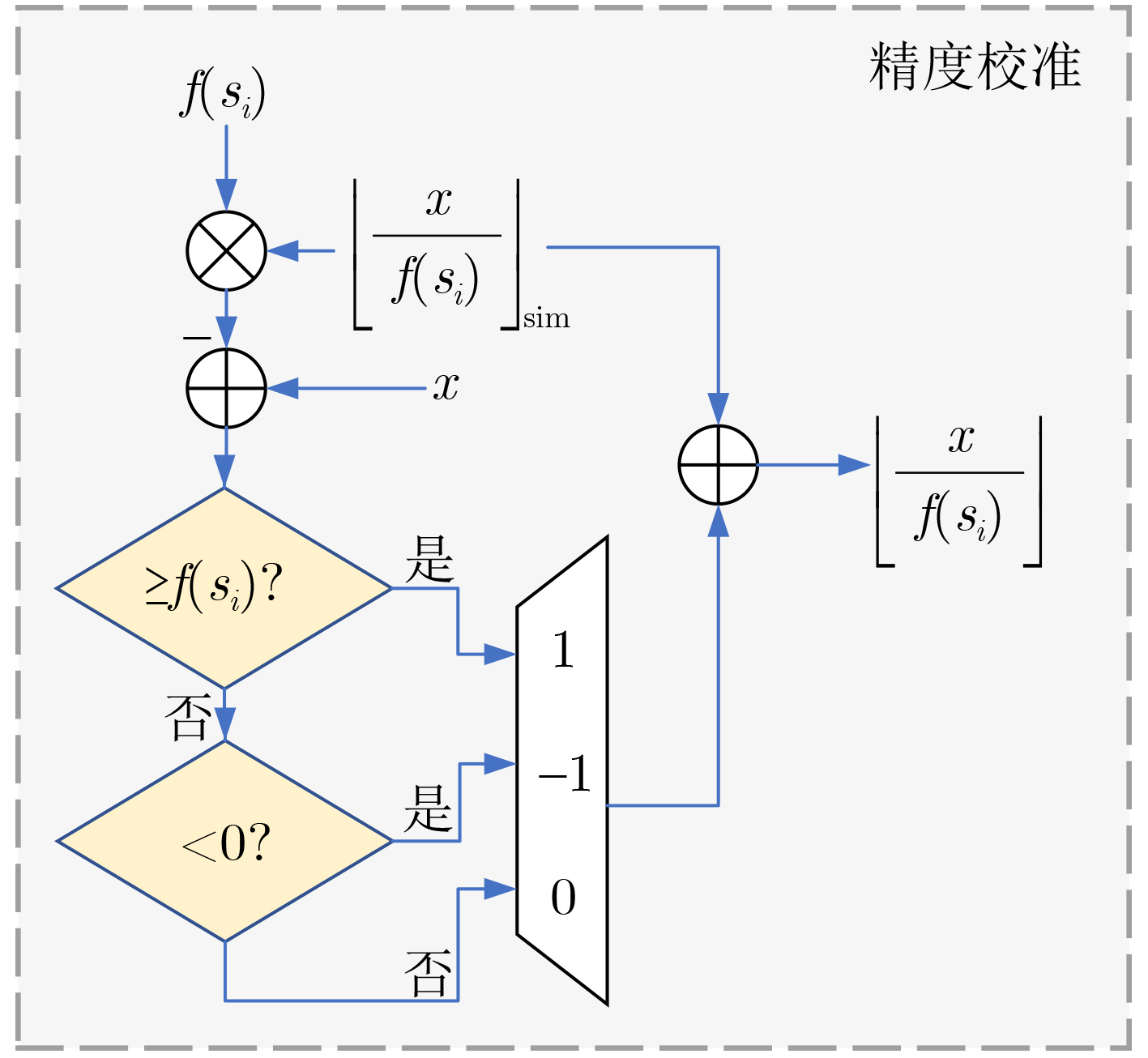
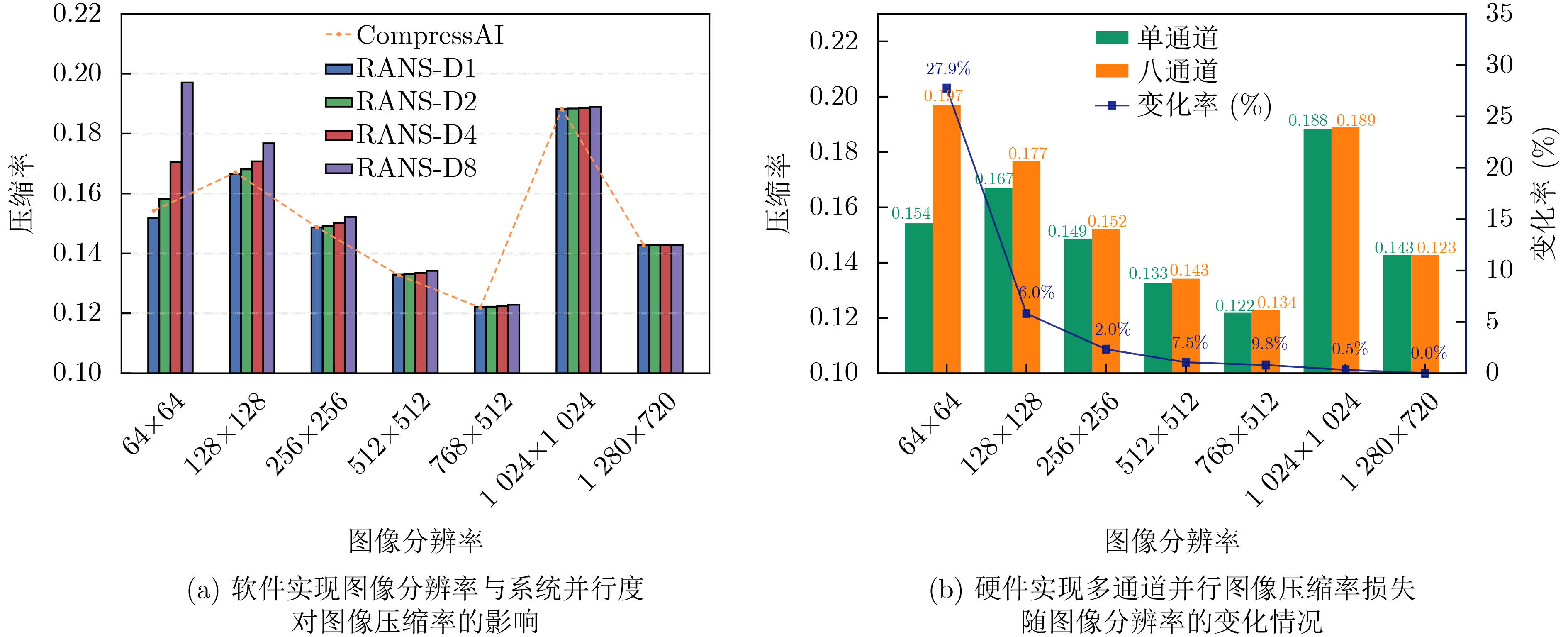
Abstract:Objective Deep Neural Network (DNN)-based image compression has gained increasing importance in real-time applications such as intelligent driving, where an efficient balance between compression ratio and encoding speed is essential. This study proposes a hardware implementation of entropy coding, realized on a Field-Programmable Gate Array (FPGA) platform based on Range Asymmetric Numeral Systems (RANS) arithmetic coding. The design seeks to achieve an optimal trade-off between compression efficiency and hardware resource utilization, while maximizing data throughput to meet the requirements of real-time environments. The main objectives are to enhance image encoding throughput, reduce hardware resource consumption, and sustain high data throughput with only minor losses in compression ratio. The proposed hardware architecture demonstrates strong scalability and practical deployment potential, offering significant value for DNN-based image compression in high-performance systems. Methods To enable practical FPGA deployment of RANS arithmetic coding, several hardware-oriented optimizations are applied. Division and modulus operations in the state update are replaced with precomputed reciprocals combined with fixed-point multiply-and-shift sequences. A precision-calibration stage based on remainder-boundary checks corrects substitution errors to ensure exact quotient-remainder equivalence with full-precision division. This calibration is implemented synchronously in the encoder datapath with minimal control overhead to preserve lossless decoding. Parameter storage and lookup overheads are reduced through fine-grained quantization and a compact, flattened Cumulative Distribution Function (CDF) layout, CDF values are linearly scaled and quantized to fixed-width integers, while contiguous storage of valid entries together with stored effective lengths eliminated padding. Tailored bit-width assignments for different parameter types balance precision against resource usage. These measures reduce the CDF table size from 31.125 kB to 6.369 kB while simplifying lookup logic and shortening critical memory-access paths. Throughput is further increased by using an interleaved multi-channel architecture in which the input stream is partitioned into independent substreams processed concurrently by separate RANS encoder instances. Each instances maintain its own local state, parameter memory, and renormalization buffer. Local handling of renormalization and escape conditions preserves channel continuity, enabling the decoder to perform symmetric decoding without global synchronization. Finally, the entire design is organized as a pipeline-friendly datapath. Reciprocal multiplications are mapped to DSP blocks, while lookups and calibration checks occupy adjacent pipeline stages. Renormalized bytes are emitted to an output FIFO to avoid stalls. This eliminates multi-cycle divide units, reduces latency and memory footprint, and provide a scalable path to high-frequency, high-throughput operation. Results and Discussions The proposed model is deployed on a Xilinx Kintex-7 XC7K325T FPGA platform, synthesized using Vivado v2018.2 and functionally verified on ModelSim SE-64 10.4. Data throughput, resource utilization, and compression efficiency are emphasized in the evaluation. Simulation results indicate that the implemented encoder achieves an identical compression ratio to the PyTorch-based open-source CompressAI library. Any degradation in compression efficiency caused by high parallelism is negligible for high-resolution images (≥768 × 512) ( Fig. 5 ). The FPGA implementation further shows that timing closure is met at a 140 MHz clock frequency. In single-channel mode, the design consumes only 540 LUTs, 336 FFs, and 9.5 BRAMs. Under high-parallelism configurations, resource utilization scales linearly with the number of channels. In eight-channel parallel mode, the encoder attains a symbol throughput of 191.97 MSymbols/s and a data throughput of 4.607 Gbps, representing an improvement of approximately 766% over single-channel operation (Table 3 ). To quantitatively evaluate the trade-off between resource usage and encoding efficiency, the metric Area Efficiency (AE) is introduced. When compared with FPGA implementations of other entropy coding schemes, the proposed architecture demonstrates clear advantages in both resource efficiency and throughput, achieving an AE of 85.97 kSymbol/(s·Slice), which exceeds most existing high-throughput models. Relative to comparable entropy coding schemes, the proposed design provides a significant increase in throughput (Table 4 ). Moreover, the scalability and adaptability of the architecture are validated across different degrees of parallelism, enabling flexible adjustment of channel count while maintaining superior performance in diverse application scenarios.Conclusions This work proposes a high-throughput RANS arithmetic coding hardware architecture for DNN-based image compression and demonstrates its implementation on an FPGA platform. By integrating hardware-friendly division substitution, fine-grained parameter quantization, and continuous-output interleaved parallelism, the design overcomes key bottlenecks related to computational latency and resource overhead. Experimental results confirm that the proposed model achieves a peak throughput of 191.97 Msymbols/s with negligible compression loss, while also demonstrating outstanding AE and linear scalability. The architecture provides significant advantages over existing entropy coding implementations in both resource-constrained and high-performance scenarios, offering strong practical potential for real-time neural network image compression systems. Overall, this research delivers a pragmatic and extensible solution for the hardware realization of DNN-based image compression, with the capability to accelerate large-scale deployment in high-efficiency environments such as intelligent driving. -
Key words:
- Entropy coding /
- Image compression /
- FPGA /
- Range Asymmetric Numeral System(RANS)
-
表 1 神经网络训练下的CDF表各组部分参数值
索引 CDF长度 边界方差 偏移量 0 5 0.1100 –1 1 5 0.1195 –1 2 5 0.1298 –1 ··· 23 13 0.7351 –5 ··· 47 69 5.3352 –33 ··· 63 249 20.0000 –123  下载: 导出CSV
下载: 导出CSV
表 2 重要变量与参数量化后位宽(皆采用定点数方式存储)
名称 类型 位宽 Scale_table 参数 24 Valid_CDF 参数 16 Freq_length 参数 8 Accu_freq_length 参数 12 Valid_freq 参数 16 Valid_freq_inv 参数 32 Offset 参数 8 pm,pv,qm 变量 24 Index 变量 6 Symbol 变量 8 Escape_information 变量 32 Data_out 变量 16
下载: 导出CSV
1 穷搜法确定定点数移位乘法替代除法所带来的误差
输入:state ∈ [0, 232–1], freq ∈ [1, 65533] 输出:Error[] 误差值统计 (1) for freq ← 1 to 65533 do (2) freq_inv ← round(231 / freq) (3) for state ← 0 to 232–1 do (4) exact ← $\left\lfloor {{\mathrm{state}} / {\mathrm{freq}}} \right\rfloor $ (5) approx ← (state × freq_inv) >> num (6) diff ← approx - exact (7) if diff ≠ 0 then (8) Error.append(diff) (9) return Error
下载: 导出CSV
表 3 模型整体性能在FPGA实现下的结果
测试平台:Xilinx Kintex-7 XC7K325T 并行度 1 4 8 最大频率(MHz) 150.42 145.24 143.98 LUT资源 540 2174 4327 FF资源 336 1541 3109 DSP资源 6 24 48 BRAM资源 9.5 36 68 Slice资源 286 1085 2233 符号吞吐量
(MSymbol/s)25.07 96.82 191.97 数据吞吐量(Gbps) 0.601 2.323 4.607 静态功耗(W) 0.061 0.084 0.087 动态功耗(W) 0.082 0.247 0.482 总功耗(W) 0.143 0.331 0.569 能效比(Gbps/W) 4.203 7.018 8.097
下载: 导出CSV
表 4 与其他文献FPGA熵编码图像压缩器的比较结果
测试平台 基础
算法最大
频率(MHz)Slice资源 BRAM资源 吞吐量
(MSymbol/s)面积效率
(kSymbol/(s·Slice))Belyaev等人[12] Altera Stratix ABRC 54.25 1296 0 54.25 41.86 Shcherbakov等人[22] XC5VFX70T RC 90.98 2025 45 90.98 44.93 Shcherbakov等人[22] XC5VFX70T HC 100.50 846 43 100.50 118.79 Mahapatra等人[21] SPARTAN3-3S4000 AC 90.60 7862 0 90.60 11.52 Li等人[23] Zynq- 7000 XC7Z045混合 300 8437 - 480.00 56.89 王旭升[24] TUL PYNQ-Z2 RANS 115.20 758 32 28.80 37.99 本文
(单通道)Kintex-7 XC7K325T RANS 150.42 286 9.5 25.07 87.66 本文
(8通道)Kintex-7 XC7K325T RANS 143.98 2233 68 191.97 85.97
下载: 导出CSV
-
[1] IWAI S, MIYAZAKI T, and OMACHI S. Semantically-guided image compression for enhanced perceptual quality at extremely low bitrates[J]. IEEE Access, 2024, 12: 100057–100072. doi: 10.1109/ACCESS.2024.3430322. [2] FU Haisheng, LIANG Feng, LIANG Jie, et al. Fast and high-performance learned image compression with improved checkerboard context model, deformable residual module, and knowledge distillation[J]. IEEE Transactions on Image Processing, 2024, 33: 4702–4715. doi: 10.1109/TIP.2024.3445737. [3] SHANNON C E. A mathematical theory of communication[J]. The Bell System Technical Journal, 1948, 27(3): 379–423. doi: 10.1002/j.1538-7305.1948.tb01338.x. [4] HUFFMAN D A. A method for the construction of minimum-redundancy codes[J]. Proceedings of the IRE, 1952, 40(9): 1098–1101. doi: 10.1109/JRPROC.1952.273898. [5] GAGIE T. Dynamic Shannon coding[J]. Information Processing Letters, 2007, 102(2/3): 113–117. doi: 10.1016/j.ipl.2006.09.015. [6] WITTEN I H, NEAL R M, and CLEARY J G. Arithmetic coding for data compression[J]. Communications of the ACM, 1987, 30(6): 520–540. doi: 10.1145/214762.214771. [7] BELYAEV E, TURLIKOV A, EGIAZARIAN K, et al. An efficient multiplication-free and look-up table-free adaptive binary arithmetic coder[C]. Proceedings of the 19th IEEE International Conference on Image Processing, Orlando, USA, 2012, 701–704. doi: 10.1109/ICIP.2012.6466956. [8] GUO Zongyu, FU Jun, FENG Rusen, et al. Accelerate neural image compression with channel-adaptive arithmetic coding[C]. 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Korea, 2021: 1–5. doi: 10.1109/ISCAS51556.2021.9401277. [9] LI Mingyin, LIU Yue, and WANG Na. A novel ANS coding with low computational complexity[C]. 2023 IEEE/CIC International Conference on Communications in China (ICCC Workshops), Dalian, China, 2023: 1–6. doi: 10.1109/ICCCWorkshops57813.2023.10233773. [10] WANG Jian and LING Qiang. Learned image compression with adaptive channel and window-based spatial entropy models[J]. IEEE Transactions on Consumer Electronics, 2024, 70(4): 6430–6441. doi: 10.1109/TCE.2024.3485179. [11] DUBÉ D and YOKOO H. Fast construction of almost optimal symbol distributions for asymmetric numeral systems[C]. 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 2019: 1682–1686. doi: 10.1109/ISIT.2019.8849430. [12] BELYAEV E, LIU Kai, GABBOUJ M, et al. An efficient adaptive binary range coder and its VLSI architecture[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2015, 25(8): 1435–1446. doi: 10.1109/TCSVT.2014.2372291. [13] 林志坚, 黄萍, 郑明魁, 等. 基于FPGA的HEVC熵编码语法元素硬件加速设计[J]. 华南理工大学学报: 自然科学版, 2023, 51(8): 110–117. doi: 10.12141/j.issn.1000-565X.220350.LIN Zhijian, HUANG Ping, ZHENG Mingkui, et al. Hardware acceleration design of HEVC entropy encoding syntax elements based on FPGA[J]. Journal of South China University of Technology: Natural Science Edition, 2023, 51(8): 110–117. doi: 10.12141/j.issn.1000-565X.220350. [14] 黄海, 邢琳, 那宁, 等. 有限状态熵编码的VLSI设计与实现[J]. 计算机辅助设计与图形学学报, 2021, 33(4): 640–648. doi: 10.3724/SP.J.1089.2021.18575.HUANG Hai, XING Lin, NA Ning, et al. Design and implementation of VLSI for finite state entropy encoding[J]. Journal of Computer-Aided Design & Computer Graphics, 2021, 33(4): 640–648. doi: 10.3724/SP.J.1089.2021.18575. [15] 李天阳, 张帆, 王松, 等. 基于FPGA的卷积神经网络和视觉Transformer通用加速器[J]. 电子与信息学报, 2024, 46(6): 2663–2672. doi: 10.11999/JEIT230713.LI Tianyang, ZHANG Fan, WANG Song, et al. FPGA-based unified accelerator for convolutional neural network and vision transformer[J]. Journal of Electronics & Information Technology, 2024, 46(6): 2663–2672. doi: 10.11999/JEIT230713. [16] 杨海钢, 孙嘉斌, 王慰. FPGA器件设计技术发展综述[J]. 电子与信息学报, 2010, 32(3): 714–727. doi: 10.3724/SP.J.1146.2009.00751.YANG Haigang, SUN Jiabin, and WANG Wei. An overview to FPGA device design technologies[J]. Journal of Electronics & Information Technology, 2010, 32(3): 714–727. doi: 10.3724/SP.J.1146.2009.00751. [17] HOWARD P G. Interleaving entropy codes[C]. Proceedings of Compression and Complexity of SEQUENCES 1997 (Cat. No. 97TB100171), Salerno, Italy, 1997: 45–55. doi: 10.1109/SEQUEN.1997.666902. [18] LIN Fangzheng, ARUNRUANGSIRILERT K, SUN Heming, et al. Recoil: Parallel rANS decoding with decoder-adaptive scalability[C]. Proceedings of the 52nd International Conference on Parallel Processing, Salt Lake City, USA, 2023: 31–40. doi: 10.1145/3605573.3605588. [19] DUAN Zhihao, LU Ming, MA J, et al. QARV: Quantization-aware ResNet VAE for lossy image compression[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(1): 436–450. doi: 10.1109/TPAMI.2023.3322904. [20] 袁瑞佳, 白宝明, 童胜. 10 Gbps LDPC编码器的FPGA设计[J]. 电子与信息学报, 2011, 33(12): 2942–2947. doi: 10.3724/SP.J.1146.2010.01338.YUAN Ruijia, BAI Baoming, and TONG Sheng. FPGA-based design of LDPC encoder with throughput over 10 Gbps[J]. Journal of Electronics & Information Technology, 2011, 33(12): 2942–2947. doi: 10.3724/SP.J.1146.2010.01338. [21] MAHAPATRA S and SINGH K. An FPGA-based implementation of multi-alphabet arithmetic coding[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2007, 54(8): 1678–1686. doi: 10.1109/TCSI.2007.902527. [22] SHCHERBAKOV I and WEHN N. A parallel adaptive range coding compressor: Algorithm, FPGA prototype, evaluation[C]. 2012 Data Compression Conference, Snowbird, USA, 2012: 119–128. doi: 10.1109/DCC.2012.20. [23] LI Xufeng, ZHOU Li, and ZHU Yan. A tile-based multi-core hardware architecture for lossless image compression and decompression[J]. Applied Sciences, 2025, 15(11): 6017. doi: 10.3390/app15116017. [24] 王旭升. 基于JPEG-XL的无损图像编码算法及其硬件实现[D]. [硕士论文], 西安电子科技大学, 2023. doi: 10.27389/d.cnki.gxadu.2023.001821.WANG Xusheng. Hardware implementation of lossless image compression algorithm based on JPEG-XL[D]. [Master dissertation], Xidian University, 2023. doi: 10.27389/d.cnki.gxadu.2023.001821. -

 下载:
下载:




图(5) / 表(5)
计量
- 文章访问数: 709
- HTML全文浏览量: 472
- PDF下载量: 69
- 被引次数: 0
