

Weakly Supervised Recognition of Aerial Adversarial Maneuvers via Contrastive Learning
-
摘要: 针对空中对抗场景中飞行机动标注数据获取困难、时序特征提取不充分等问题,该文提出一种基于对比学习的弱监督机动识别方法,旨在提升机动识别性能。通过将视觉表征对比学习的简单框架(SimCLR)创新性地扩展至时间序列分析,设计针对时间序列的数据增强策略,构建具有时序不变性的特征空间。进而结合对比学习机制,在特征空间内形成正负样本组的竞争关系,有效抑制伪标签噪声干扰。最后结合微调技术,在DCS World飞行模拟数据上进行实验验证。结果表明,该方法能有效利用时间序列数据潜在信息,在缺乏标注数据情况下展现出良好性能,为空中对抗机动识别及时间序列分析领域提供了新的思路与方法。Abstract:
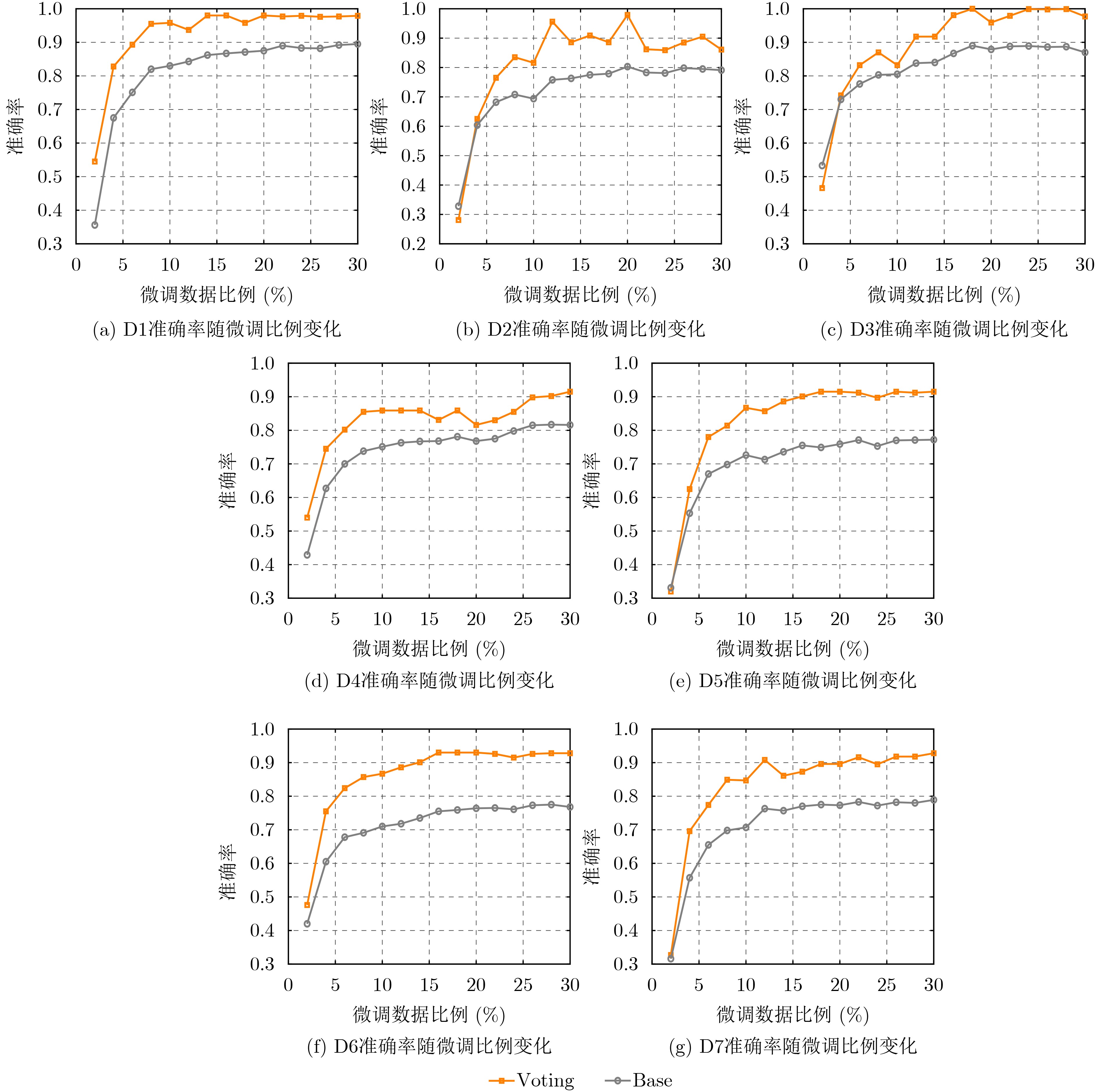
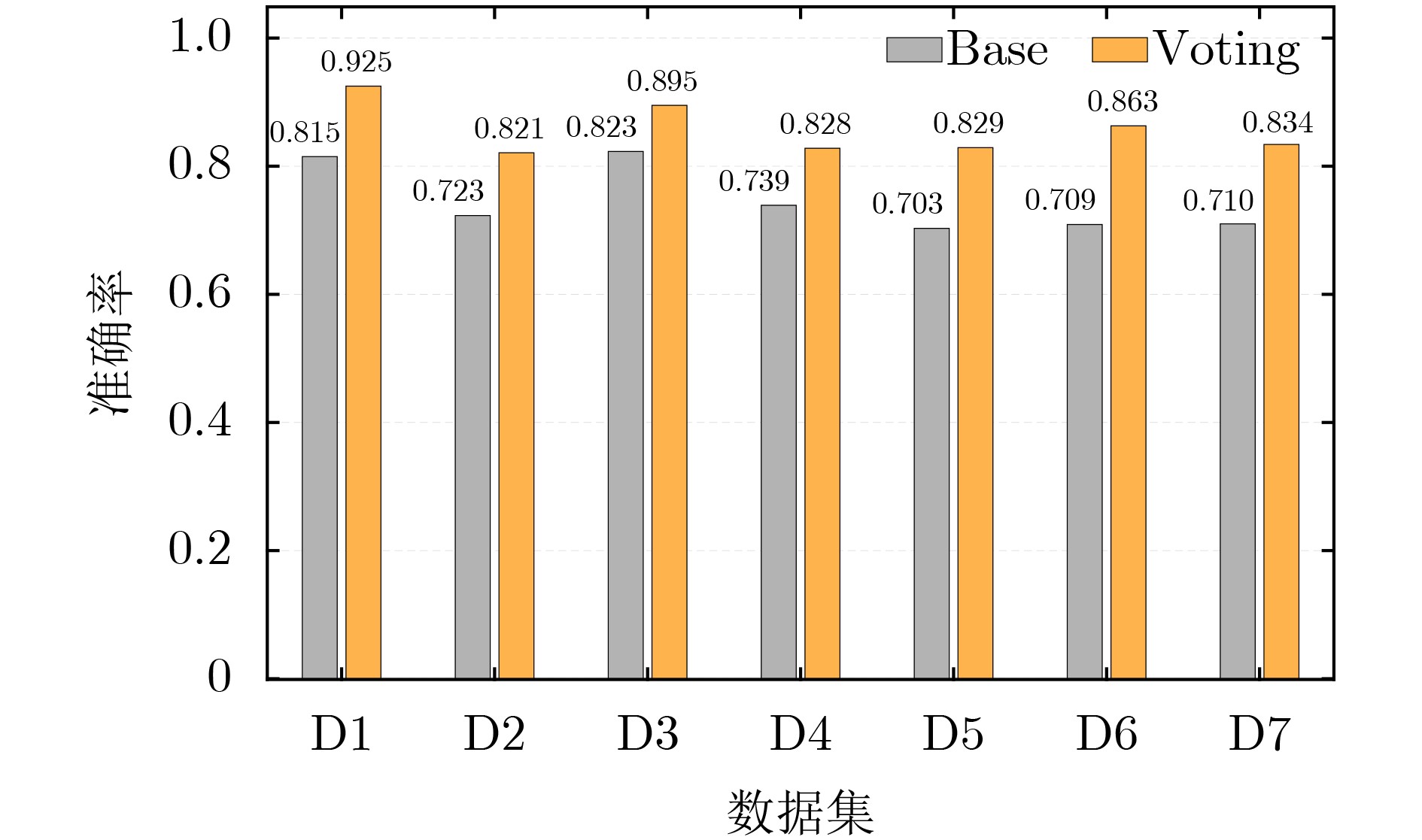
Objective Accurate recognition of aerial adversarial maneuvers is essential for situational awareness and tactical decision-making in modern air warfare. Conventional supervised approaches face major challenges: obtaining labeled flight data is costly due to the intensive human effort required for collection and annotation, and these methods are limited in capturing temporal dependencies inherent in sequential flight parameters. Temporal dynamics are crucial for describing the evolution of maneuvers, yet existing models fail to fully exploit this information. To address these challenges, this study proposes a weakly supervised maneuver recognition framework based on contrastive learning. The method leverages a small proportion of labeled data to learn discriminative representations, thereby reducing reliance on extensive manual annotations. The proposed framework enhances recognition accuracy in data-scarce scenarios and provides a robust solution for maneuver analysis in dynamic adversarial aerial environments. Methods The proposed framework extends the Simple framework for Contrastive Learning of visual Representations (SimCLR) into the time-series domain by incorporating five temporal-specific data augmentation strategies: time compression, masking, permutation, scaling, and flipping. These augmentations generate multi-view samples that form positive pairs for contrastive learning, thereby ensuring temporal invariance in the feature space. A customized ResNet-18 encoder is employed to extract hierarchical features from the augmented time-series data, and a Multi-Layer Perceptron (MLP) projection head maps these features into a contrastive space. The Normalized Temperature-scaled cross-entropy (NT-Xent) loss is adopted to maximize similarity between positive pairs and minimize it between negative pairs, which effectively mitigates pseudo-label noise. To further improve recognition performance, a fine-tuning strategy is introduced in which pre-trained features are combined with a task-specific classification head using a limited amount of labeled data to adapt to downstream recognition tasks. This contrastive learning framework enables efficient analysis of time-series flight data, achieves accurate recognition of fighter aircraft maneuvers, and reduces dependence on large-scale labeled datasets. Results and Discussions Experiments are conducted on flight simulation data obtained from DCS World. To address the class imbalance issue, hybrid datasets ( Table 1 ) are constructed, and training data ratios ranging from 2% to 30% are employed to evaluate the effectiveness of the weakly supervised framework. The results demonstrate that contrastive learning effectively captures the temporal patterns within flight data. For example, on the D1 dataset, accuracy with the base method increases from 35.6% with 2% labeled data to 89.5% when the fine-tuning ratio reaches 30% (Tables 3 ~5 ,Fig. 2(a) ). To improve recognition of long maneuver sequences, a linear classifier and a voting strategy are introduced. The voting strategy markedly enhances few-shot learning performance. On the D1 dataset, accuracy reaches 54.5% with 2% labeled data and rises to 97.9% at a 30% fine-tuning ratio, representing a substantial improvement over the base method. On the D6 dataset, which simulates multi-source data fusion scenarios in air combat, the accuracy of the voting method increases from 0.476 with 2% labeled data to 0.928 with 30% labeled data (Fig. 2(f) ), with a growth rate in the low-data phase 53% higher than that of the base method. Additionally, on the comprehensive D7 dataset, the accuracy standard deviation of the voting method is only 0.011 (Fig. 2(g) ,Fig. 3 ), significantly lower than the 0.015 observed for the base method. The superiority of the proposed framework can be attributed to two factors: the suppression of noise through integration of multiple prediction results using the voting strategy and the extraction of robust features from unlabeled data via contrastive learning pre-training. Together, these techniques enhance generalization and stability in complex scenarios, confirming the effectiveness of the method in leveraging unlabeled data and managing multi-source information.Conclusions This study applies the SimCLR framework to maneuver recognition and proposes a weakly supervised approach based on contrastive learning. By incorporating targeted data augmentation strategies and combining self-supervised learning with fine-tuning, the method exploits the latent information in time-series data, yielding substantial improvements in recognition performance under limited labeled data conditions. Experiments on simulated air combat datasets demonstrate that the framework achieves stable recognition across different data categories, offering practical insights for feature learning and model optimization in time-series classification tasks. Future research will focus on three directions: first, integrating real flight data to evaluate the model’s generalization capability in practical scenarios; second, developing dynamically adaptive data augmentation strategies to enhance performance in complex environments; and third, combining reinforcement learning and related techniques to improve autonomous decision-making in dynamic aerial missions, thereby expanding opportunities for intelligent flight operations. -
表 1 机动数据集构成
数据集
层级数据集
标识包含的机动类型 基础层 D1 半舵翻滚、俯冲、横滚、盘旋、爬升 D2 半舵翻滚、横滚、急转、爬升、旋降 D3 半舵翻滚、俯冲、爬升、尾冲、旋降 融合层 D4 半舵翻滚、俯冲、横滚、急转、盘旋、爬升、旋降 D5 半舵翻滚、俯冲、横滚、盘旋、爬升、尾冲、旋降 D6 半舵翻滚、俯冲、横滚、急转、爬升、尾冲、旋降 全量层 D7 半舵翻滚、俯冲、横滚、急转、盘旋、
爬升、尾冲、旋降 下载: 导出CSV
下载: 导出CSV
表 2 微调比例划分情况
场景 数据范围(%) 间隔(%) 总测试点个数 极低数据场景 2,4,6,8,10 2 5 中低数据场景 12,14,16,18,20 2 5 低数据场景 22,24,26,28,30 2 5
下载: 导出CSV
表 3 极低数据场景识别准确率
微调比例(%) D1 D2 D3 D4 D5 D6 D7 BM VM BM VM BM VM BM VM BM VM BM VM BM VM 2 0.356 0.545 0.328 0.281 0.533 0.466 0.429 0.540 0.331 0.320 0.420 0.476 0.316 0.327 4 0.675 0.828 0.604 0.625 0.730 0.742 0.627 0.745 0.553 0.625 0.605 0.755 0.557 0.696 6 0.751 0.893 0.682 0.765 0.776 0.832 0.700 0.802 0.670 0.780 0.678 0.824 0.655 0.774 8 0.820 0.955 0.708 0.835 0.803 0.870 0.738 0.855 0.698 0.814 0.691 0.857 0.698 0.849 10 0.830 0.958 0.694 0.816 0.805 0.832 0.751 0.859 0.726 0.867 0.710 0.867 0.707 0.847
下载: 导出CSV
表 4 中低数据场景识别准确率
微调比例(%) D1 D2 D3 D4 D5 D6 D7 BM VM BM VM BM VM BM VM BM VM BM VM BM VM 12 0.843 0.937 0.758 0.956 0.838 0.917 0.763 0.859 0.713 0.857 0.718 0.886 0.763 0.908 14 0.862 0.980 0.763 0.886 0.840 0.917 0.767 0.859 0.736 0.886 0.735 0.901 0.757 0.861 16 0.867 0.980 0.775 0.909 0.867 0.981 0.768 0.831 0.755 0.901 0.755 0.930 0.770 0.873 18 0.871 0.958 0.779 0.886 0.890 0.999 0.781 0.859 0.749 0.915 0.759 0.930 0.775 0.896 20 0.875 0.980 0.803 0.979 0.879 0.959 0.768 0.816 0.759 0.915 0.764 0.930 0.773 0.896
下载: 导出CSV
表 5 低数据场景识别准确率
微调比例(%) D1 D2 D3 D4 D5 D6 D7 BM VM BM VM BM VM BM VM BM VM BM VM BM VM 22 0.890 0.977 0.783 0.862 0.888 0.979 0.775 0.830 0.771 0.912 0.765 0.926 0.783 0.916 24 0.883 0.979 0.781 0.859 0.889 0.999 0.798 0.855 0.753 0.897 0.761 0.915 0.772 0.895 26 0.882 0.976 0.798 0.885 0.886 0.998 0.815 0.898 0.770 0.915 0.773 0.926 0.782 0.918 28 0.892 0.977 0.795 0.905 0.887 0.999 0.817 0.902 0.771 0.912 0.775 0.928 0.780 0.918 30 0.895 0.979 0.791 0.861 0.870 0.977 0.816 0.915 0.772 0.915 0.768 0.928 0.789 0.928
下载: 导出CSV
表 6 不同数据增强策略在各数据集上的识别准确率对比
数据集 时间压缩 缩放 排列 掩蔽 翻转 随机组合 D1 0.900 0.905 0.890 0.910 0.895 0.925 D2 0.805 0.800 0.790 0.808 0.795 0.821 D3 0.875 0.880 0.865 0.883 0.870 0.895
下载: 导出CSV
表 7 Voting方案与各基线模型的机动识别平均准确率对比
数据集 LSTM GRU T-Rep XGBoost Rocket MLP TimesNet Voting D1 0.900 0.924 0.915 0.898 0.876 0.912 0.899 0.925 D2 0.813 0.800 0.815 0.699 0.781 0.789 0.820 0.821 D3 0.859 0.851 0.888 0.758 0.802 0.851 0.885 0.895 D4 0.782 0.775 0.751 0.764 0.736 0.774 0.802 0.828 D5 0.752 0.776 0.731 0.860 0.742 0.781 0.794 0.829 D6 0.764 0.763 0.761 0.808 0.682 0.775 0.808 0.863 D7 0.782 0.794 0.738 0.803 0.730 0.761 0.766 0.834
下载: 导出CSV
-
[1] TIAN Yonglong, SUN Chen, POOLE B, et al. What makes for good views for contrastive learning?[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 573. [2] CHUANG C Y, ROBINSON J, LIN Y C, et al. Debiased contrastive learning[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 735. [3] ZHENG Mingkai, WANG Fei, YOU Shan, et al. Weakly supervised contrastive learning[C]. IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 10022–10031. doi: 10.1109/ICCV48922.2021.00989. [4] KHOSLA P, TETERWAK P, WANG Chen, et al. Supervised contrastive learning[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1567. [5] WU Linshan, ZHUANG Jiaxin, and CHEN Hao. VoCo: A simple-yet-effective volume contrastive learning framework for 3D medical image analysis[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 22873–22882. doi: 10.1109/CVPR52733.2024.02158. [6] CHEN Ting, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]. The 37th International Conference on Machine Learning, 2020: 149. [7] KUANG Haofei, ZHU Yi, ZHANG Zhi, et al. Video contrastive learning with global context[C]. IEEE/CVF International Conference on Computer Vision Workshops, Montreal, Canada, 2021: 3188. doi: 10.1109/ICCVW54120.2021.00358. [8] SUNG C, KIM W, AN J, et al. Contextrast: Contextual contrastive learning for semantic segmentation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 3732–3742. doi: 10.1109/CVPR52733.2024.00358. [9] WU Zhuofeng, WANG Sinong, GU Jiatao, et al. CLEAR: Contrastive learning for sentence representation[J]. arXiv preprint arXiv: 2012.15466, 2020. doi: 10.48550/arXiv.2012.15466. [10] SPIJKERVET J and BURGOYNE J A. Contrastive learning of musical representations[C/OL]. The 22nd International Society for Music Information Retrieval Conference, 2021: 673–681. [11] 倪世宏, 史忠科, 谢川, 等. 军用战机机动飞行动作识别知识库的建立[J]. 计算机仿真, 2005, 22(4): 23–26. doi: 10.3969/j.issn.1006-9348.2005.04.007.NI Shihong, SHI Zhongke, XIE Chuan, et al. Establishment of avion inflight maneuver action recognizing knowledge base[J]. Computer Simulation, 2005, 22(4): 23–26. doi: 10.3969/j.issn.1006-9348.2005.04.007. [12] 孟光磊, 陈振, 罗元强. 基于动态贝叶斯网络的机动动作识别方法[J]. 系统仿真学报, 2017, 29(S1): 140–145. doi: 10.16182/j.issn1004731x.joss.2017S1020.MENG Guanglei, CHEN Zhen, and LUO Yuanqiang. Maneuvering action identify method based on dynamic Bayesian network[J]. Journal of System Simulation, 2017, 29(S1): 140–145. doi: 10.16182/j.issn1004731x.joss.2017S1020. [13] WANG Yongjun, DONG Jiang, LIU Xiaodong, et al. Identification and standardization of maneuvers based upon operational flight data[J]. Chinese Journal of Aeronautics, 2015, 28(1): 133–140. doi: 10.1016/j.cja.2014.12.026. [14] LI Xiaokang, ZHU Tianyi, BIAN Zimu, et al. An improved algorithm for flight maneuver recognition and evaluation based on support vector machines[C]. 2024 International Conference on Cyber-Physical Social Intelligence (ICCSI), Doha, Qatar, 2024: 1–6. doi: 10.1109/ICCSI62669.2024.10799254. [15] XI Zhifei, LYU Yue, KOU Yingxin, et al. An online ensemble semi-supervised classification framework for air combat target maneuver recognition[J]. Chinese Journal of Aeronautics, 2023, 36(6): 340–360. doi: 10.1016/j.cja.2023.04.020. [16] WEI Zhenglei, DING Dali, ZHOU Huan, et al. A flight maneuver recognition method based on multi-strategy affine canonical time warping[J]. Applied Soft Computing, 2020, 95: 106527. doi: 10.1016/j.asoc.2020.106527. [17] LU Jing, CHAI Hongjun, and JIA Ruchun. A general framework for flight maneuvers automatic recognition[J]. Mathematics, 2022, 10(7): 1196. doi: 10.3390/math10071196. [18] WANG Can, TU Jingqi, YANG Xizhong, et al. Explainable basic-fighter-maneuver decision support scheme for piloting within-visual-range air combat[J]. Journal of Aerospace Information Systems, 2024, 21(6): 500–514. doi: 10.2514/1.I011388. [19] LEI Xie, SHILIN D, SHANGQIN T, et al. Beyond visual range maneuver intention recognition based on attention enhanced tuna swarm optimization parallel BiGRU[J]. Complex & Intelligent Systems, 2024, 10(2): 2151–2172. doi: 10.1007/s40747-023-01257-3. [20] TIAN Wei, ZHANG Hong, LI Hui, et al. Flight maneuver intelligent recognition based on deep variational autoencoder network[J]. EURASIP Journal on Advances in Signal Processing, 2022, 2022(1): 21. doi: 10.1186/s13634-022-00850-x. [21] LUO Dongsheng, CHENG Wei, WANG Yingheng, et al. Time series contrastive learning with information-aware augmentations[C]. The 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 4534–4542. doi: 10.1609/aaai.v37i4.25575. [22] CHEN Muxi, XU Zhijian, ZENG Ailing, et al. FrAug: Frequency domain augmentation for time series forecasting[J]. arXiv preprint arXiv: 2302.09292, 2023. doi: 10.48550/arXiv.2302.09292. [23] HADSELL R, CHOPRA S, and LECUN Y. Dimensionality reduction by learning an invariant mapping[C]. 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, USA, 2006: 1735–1742. doi: 10.1109/CVPR.2006.100. [24] SCHROFF F, KALENICHENKO D, and PHILBIN J. FaceNet: A unified embedding for face recognition and clustering[C]. IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 815–823. doi: 10.1109/CVPR.2015.7298682. [25] SOHN K. Improved deep metric learning with multi-class n-pair loss objective[C]. The 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 2016: 1857–1865. -


 下载:
下载:


图(3) / 表(7)
计量
- 文章访问数: 895
- HTML全文浏览量: 400
- PDF下载量: 61
- 被引次数: 0
