

Multi-modal Joint Distillation Optimization for Source Code Vulnerability Detection
-
摘要: 针对现有基于深度学习的源代码漏洞检测方法在特征利用不充分、易学习虚假特征及跨模态一致性优化不足的问题,该文提出一种深度蒸馏与多模态一致性提升的漏洞检测框架mVulD-DO。该方法通过程序依赖图和代码切片技术,从源代码中提取函数名、变量名、Token_type及局部代码片段等多个语义模态以提升代码语义的刻画精度,并结合异构邻接矩阵与图注意力网络构建结构模态;接着,引入多层特征蒸馏层对各语义模态进行深层蒸馏以提炼特征主峰,利用BLSTM捕获时序依赖,并通过自适应动态Sinkhorn正则化在全局范围内对齐语义与结构特征分布;最终,经过对齐的模态输入全局注意力层进行融合,融合特征经过softmax分类器实现二分类检测。大量对比与消融实验表明,mVulD-DO在准确率、F1-score和Recall等指标上达到87.11%, 86.37%, 83.59%,均优于主流方法,验证了多模态表征、深度蒸馏及联合优化在漏洞检测中的协同优势和泛化能力。Abstract:
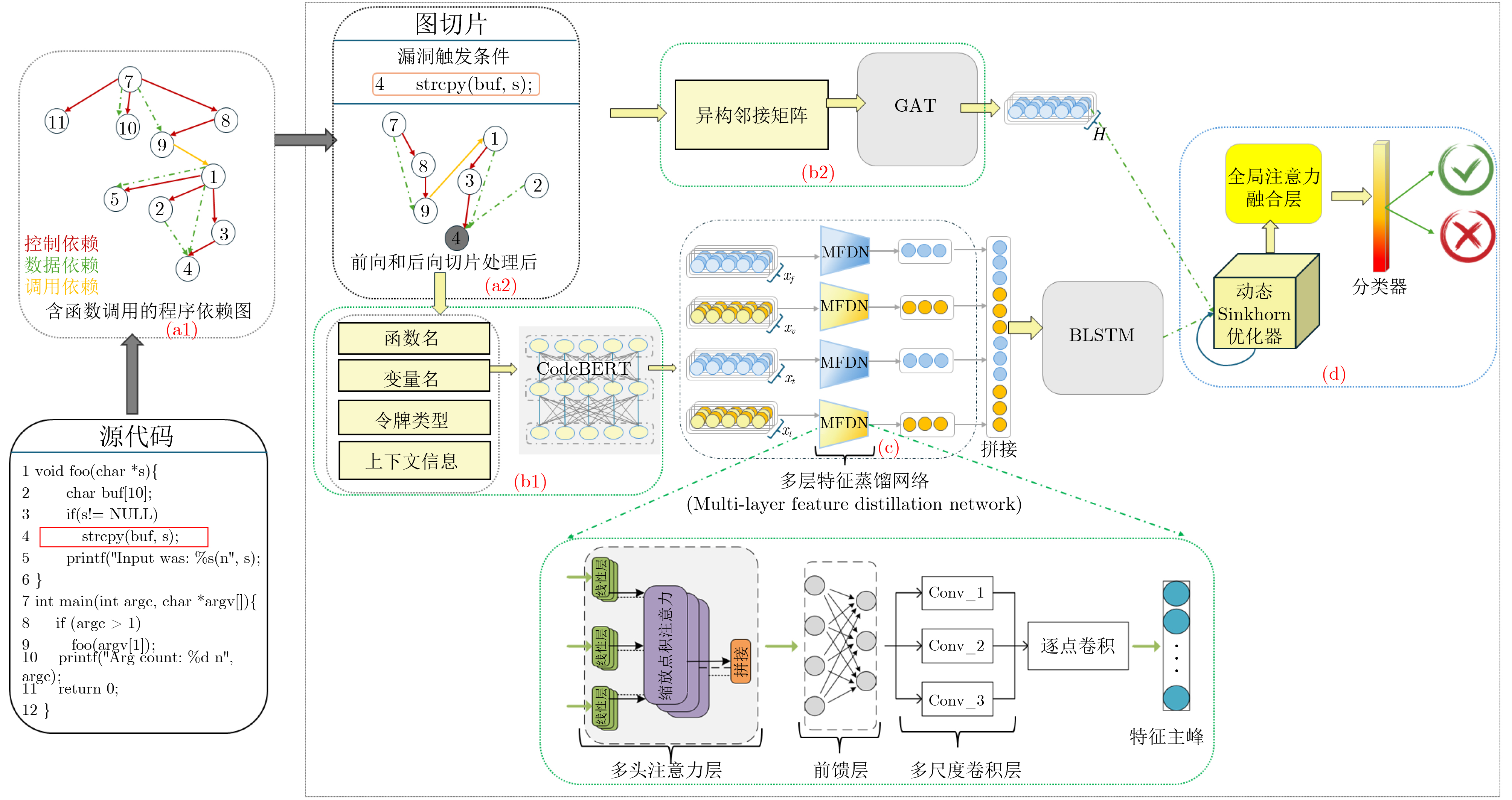
Objective As software systems increase in scale and complexity, the frequency of security vulnerabilities in source code rises accordingly, threatening system reliability, data integrity, and user privacy. Conventional automated vulnerability detection methods typically depend on a narrow set of shallow features—such as API call sequences, opcode patterns, or syntactic heuristics—rendering them susceptible to learning spurious correlations and unable to capture the rich semantic and structural information essential for accurate detection. Moreover, most existing approaches either rely on single-modal representations or weakly integrate multiple modalities without explicitly addressing distribution mismatches across them. This often results in overfitting to seen datasets and limited generalization to unseen codebases, particularly across different projects or programming languages. Although recent advances in machine learning and deep learning have improved source code analysis, effectively modeling the complex interactions between code semantics and execution structures remains a major challenge. To overcome these limitations, this paper proposes a multi-modal joint Distillation Optimization for Vulnerability Detection (mVulD-DO), a multimodal framework that combines deep feature distillation with dynamic global feature alignment. The proposed method aims to enhance semantic comprehension, structural reasoning, and cross-modal consistency, which are critical for robust vulnerability detection. By enforcing both intra-modality refinement and inter-modality alignment, mVulD-DO addresses the semantic-structural gap that constrains traditional methods. Methods The mVulD-DO framework begins by extracting multiple semantic modalities from raw source code—function names, variable names, token_type attributes, and local code slices—using program slicing and syntactic parsing techniques. In parallel, a Program Dependency Graph (PDG) is constructed to capture both control-flow and data-flow relationships, generating a heterogeneous graph that represents explicit and implicit program behaviors. Each semantic modality is embedded using pretrained encoders and subsequently refined via a deep feature distillation module, which integrates multi-head self-attention and multi-scale convolutional layers to emphasize salient patterns and suppress redundant noise. To model the sequential dependencies intrinsic to program execution, a Bidirectional Long Short-Term Memory (BLSTM) network captures long-range contextual interactions. For structural representation, a Graph Attention Network (GAT) processes the PDG-C to produce topology-aware embeddings. To bridge the gap between modalities, adaptive dynamic Sinkhorn regularization is applied to globally align the distributions of semantic and structural embeddings. This approach mitigates modality mismatches while preserving flexibility by avoiding rigid one-to-one correspondences. Finally, the distilled and aligned multimodal features are fused and passed through a lightweight fully connected classifier for binary vulnerability prediction. The model is jointly optimized using both classification and alignment objectives, improving its ability to generalize across unseen codebases. Results and Discussions Comprehensive comparisons conducted on the mixed CVE-fixes+SARD dataset—covering 25 common CWE vulnerability types with an 8:1:1 train:validation:test split—demonstrate that traditional source code detectors, which directly map code to labels, often rely on superficial patterns and show limited generalization, particularly for out-of-distribution samples. These methods achieve accuracies ranging from 55.41% to 85.84%, with recall typically below 80% ( Table 1 ). In contrast, mVulD-DO leverages multi-layer feature distillation to purify and enhance core representations, while dynamic Sinkhorn alignment mitigates cross-modal inconsistencies. This results in accuracy of 87.11% and recall of 83.59%, representing absolute improvements of 1.27% and 6.26%, respectively, over the strongest baseline method (ReGVD). Although mVulD-DO reports a slightly higher False Positive Rate (FPR) 10.98%—2.92% above that of ReGVD—it remains lower than that of most traditional detectors. This modest increase is considered acceptable in practice, given that failing to detect a critical vulnerability typically incurs greater cost than issuing additional alerts. Compared with instruction-tuned large language models (e.g., VulLLM), which maintain low FPRs below 10% but suffer from recall below 75%, mVulD-DO offers a more favorable trade-off between false alarms and coverage of true vulnerabilities. Ablation studies (Table 2 ) further validate the contribution of each component. Removing function name embeddings (unfunc) results in a 1.3% decrease in F1 score; removing variable name embeddings (unvar) causes a 1.3% drop; and omitting token_type attributes (untype) leads to a 3.35% reduction. The most substantial performance degradation—9.11% in F1—occurs when the deep feature distillation module is disabled (undis), highlighting the critical role of multi-scale semantic refinement and noise suppression. Additional evaluations on vulnerability-sensitive subsets—Call, OPS, Array, and Ptr—demonstrate consistent benefits from Sinkhorn alignment. F1 score improvements over unaligned variants are observed as follows: 1.45% for Call, 4.22% for OPS, 1.38% for Array, and 0.36% for Ptr (Table 3 ), confirming the generalization advantage across a broad spectrum of vulnerability types.Conclusions Experimental results demonstrate that the proposed mVulD-DO framework consistently outperforms existing vulnerability detection methods in recall, F1-score, and accuracy, while maintaining a low FPR The effectiveness of deep feature distillation, multi-scale semantic extraction, and dynamic Sinkhorn alignment is validated through extensive ablation and visualization analyses. Despite these improvements, the model incurs additional computational overhead due to multimodal distillation and Sinkhorn alignment, and shows sensitivity to hyperparameter settings, which may limit its suitability for real-time applications. Moreover, while strong performance is achieved on the mixed dataset, the model’s generalization across unseen projects and programming languages remains an open challenge. Future work will focus on developing lightweight training strategies—such as knowledge distillation and model pruning—to reduce computational costs. Additionally, incorporating unsupervised domain adaptation and incremental alignment mechanisms will be critical to support dynamic code evolution and enhance cross-domain robustness. These directions aim to improve the scalability, adaptability, and practical deployment of multimodal vulnerability detection systems in diverse software environments. -
Key words:
- Vulnerability detection /
- Deep distillation /
- Multimodal /
- Joint optimization
-
1 PDG-C子图切片过程
输入:G=(V,E),关键节点集合K 输出:子图G_S 1. 初始化节点集S←K2. 重复以下步骤,直至S不再变化: a. 正向切片:对每个v∈S,遍历所有(v,u)∈E,将u加入临时
集合Newb. 反向切片:对每个v∈S,遍历所有(u,v)∈E,将u加入New c. 合并:S←S∪Newd. 清空New 3. 子图提取:G_S←G[S]  下载: 导出CSV
下载: 导出CSV
表 1 与基线方法对比实验结果(%)
数据集 方法 Recall FPR F1 ACC CVE-fixes
+
SARDmVulD-DO 83.59 10.98 86.37 87.11 VulDeePecker 55.41 44.68 58.18 55.41 SlicedLocator 59.75 16.59 78.26 82.04 SySeVR 77.39 22.61 79.33 77.39 ReGVD 77.33 8.06 82.01 85.84 Devign 58.10 35.00 62.60 63.11 VulLLM-CL-7b 67.51 49.96 56.71 57.28 Codebert-FT 57.71 2.01 71.91 81.17 UniXcoder-FT 72.76 5.51 80.65 85.42 GraphCodeBERT-FT 23.64 8.68 34.83 63.06
下载: 导出CSV
表 2 不同表征的消融实验结果(%)
方法 Recall FPR F1 ACC P mVulD-DO (var+type+tokens) 87.99 16.75 85.07 85.25 79.28 mVulD-DO (func+type+tokens) 87.60 16.43 85.07 85.27 79.51 mVulD-DO (func+var+tokens) 83.78 17.06 83.02 83.30 78.15 mVulD-DO (type+tokens) 91.85 25.18 81.96 82.00 72.65 mVulD-DO (var+tokens) 90.92 19.67 84.69 84.79 77.09 mVulD-DO (func+tokens) 82.38 17.85 81.95 82.24 77.06 mVulD-DO (tokens) 89.19 26.09 80.28 80.42 71.23 mVulD-DO (undis) 68.49 12.19 77.26 77.27 87.09 mVulD-DO 83.59 10.98 86.37 87.11 83.93
下载: 导出CSV
表 3 不同数据集下进行联合学习的对比实验(%)
数据集 是否联合优化 ACC Recall FPR P F1 Call mVulD-DO (unsinkhorn) 85.66 89.88 17.47 79.82 85.58 mVulD-DO 87.12 90.46 15.47 81.93 87.03 Array mVulD-DO (unsinkhorn) 90.70 94.03 11.60 84.88 90.52 mVulD-DO 92.03 96.65 11.17 85.70 91.90 Ptr mVulD-DO (unsinkhorn) 70.90 62.53 21.71 71.76 70.45 mVulD-DO 71.22 63.43 21.91 71.87 70.81 OPS mVulD-DO (unsinkhorn) 88.37 85.95 10.42 80.43 87.12 mVulD-DO 92.17 91.83 7.65 85.67 91.34 Total mVulD-DO (unsinkhorn) 82.54 77.04 13.45 80.65 81.98 mVulD-DO 87.11 83.59 10.98 83.93 86.37
下载: 导出CSV
-
[1] Skybox Security. Vulnerability and threat trends report 2024[EB/OL]. https://www.skyboxsecurity.com/resources/report/vulnera-bility-threat-trends-report-2024, 2025. [2] Coverity Scan. Coverity scan static analysis[EB/OL]. https://scan.coverity.com/, 2024. [3] AYEWAH N, PUGH W, HOVEMEYER D, et al. Using static analysis to find bugs[J]. IEEE Software, 2008, 25(5): 22–29. doi: 10.1109/MS.2008.130. [4] PERL H, DECHAND S, SMITH M, et al. VCCFinder: Finding potential vulnerabilities in open-source projects to assist code audits[C]. The 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, USA, 2015: 426–437. doi: 10.1145/2810103.2813604. [5] LI Zhen, ZOU Deqing, XU Shouhuai, et al. VulDeePecker: A deep learning-based system for vulnerability detection[C]. The 25th Annual Network and Distributed System Security Symposium, San Diego, USA, 2018. [6] LI Zhen, ZOU Deqing, XU Shouhuai, et al. SySeVR: A framework for using deep learning to detect software vulnerabilities[J]. IEEE Transactions on Dependable and Secure Computing, 2022, 19(4): 2244–2258. doi: 10.1109/TDSC.2021.3051525. [7] JIANG Yuan, ZHANG Yujian, SU Xiaohong, et al. StagedVulBERT: Multigranular vulnerability detection with a novel pretrained code model[J]. IEEE Transactions on Software Engineering, 2024, 50(12): 3454–3471. doi: 10.1109/TSE.2024.3493245. [8] 杨宏宇, 马建辉, 侯旻, 等. 基于多模态对比学习的代码表征增强预训练方法[J]. 软件学报, 2024, 35(4): 1601–1617. doi: 10.13328/j.cnki.jos.007016.YANG Hongyu, MA Jianhui, HOU Min, et al. Pre-training method for enhanced code representation based on multimodal contrastive learning[J]. Journal of Software, 2024, 35(4): 1601–1617. doi: 10.13328/j.cnki.jos.007016. [9] ZHANG Kechi, LI Jia, LI Zhuo, et al. Transformer-based code model with compressed hierarchy representation[J]. Empirical Software Engineering, 2025, 30(2): 60. doi: 10.1007/s10664-025-10612-6. [10] YAMAGUCHI F, LINDNER F, and RIECK K. Vulnerability extrapolation: Assisted discovery of vulnerabilities using machine learning[C]. The 5th USENIX Conference on Offensive Technologies, San Francisco, USA, 2011. [11] DAM H K, PHAM T, NG S W, et al. Lessons learned from using a deep tree-based model for software defect prediction in practice[C]. 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), Montreal, Canada, 2019: 46–57. doi: 10.1109/MSR.2019.00017. [12] 李韵, 黄辰林, 王中锋, 等. 基于机器学习的软件漏洞挖掘方法综述[J]. 软件学报, 2020, 31(7): 2040–2061. doi: 10.13328/j.cnki.jos.006055.LI Yun, HUANG Chenlin, WANG Zhongfeng, et al. Survey of software vulnerability mining methods based on machine learning[J]. Journal of Software, 2020, 31(7): 2040–2061. doi: 10.13328/j.cnki.jos.006055. [13] FENG Qi, FENG Chendong, and HONG Weijiang. Graph neural network-based vulnerability predication[C]. 2020 IEEE International Conference on Software Maintenance and Evolution (ICSME), Adelaide, Australia, 2020: 800–801. doi: 10.1109/ICSME46990.2020.00096. [14] GHAFFARIAN S M and SHAHRIARI H R. Neural software vulnerability analysis using rich intermediate graph representations of programs[J]. Information Sciences, 2021, 553: 189–207. doi: 10.1016/j.ins.2020.11.053. [15] WU Bolun, ZOU Futai, YI Ping, et al. SlicedLocator: Code vulnerability locator based on sliced dependence graph[J]. Computers & Security, 2023, 134: 103469. doi: 10.1016/j.cose.2023.103469. [16] GUO Xiaobao, KONG A W K, and KOT A. Deep multimodal sequence fusion by regularized expressive representation distillation[J]. IEEE Transactions on Multimedia, 2023, 25: 2085–2096. doi: 10.1109/TMM.2022.3142448. [17] FENG Zhangyin, GUO Daya, TANG Duyu, et al. CodeBERT: A pre-trained model for programming and natural languages[C/OL]. Findings of the Association for Computational Linguistics: EMNLP 2020, 2020: 1536–1547. doi: 10.18653/v1/2020.findings-emnlp.139. [18] GUO Daya, REN Shuo, LU Shuai, et al. GraphCodeBERT: Pre-training code representations with data flow[C/OL]. The 9th International Conference on Learning Representations, 2021. [19] GUO Daya, LU Shuai, DUAN Nan, et al. UniXcoder: Unified cross-modal pre-training for code representation[C]. The 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 2022: 7212–7225. doi: 10.18653/v1/2022.acl-long.499. [20] 邓枭, 叶蔚, 谢睿, 等. 基于深度学习的源代码缺陷检测研究综述[J]. 软件学报, 2023, 34(2): 625–654. doi: 10.13328/j.cnki.jos.006696.DENG Xiao, YE Wei, XIE Rui, et al. Survey of source code bug detection based on deep learning[J]. Journal of Software, 2023, 34(2): 625–654. doi: 10.13328/j.cnki.jos.006696. [21] 张学军, 张奉鹤, 盖继扬, 等. mVulSniffer: 一种多类型源代码漏洞检测方法[J]. 通信学报, 2023, 44(9): 149–160. doi: 10.11959/j.issn.1000-436x.2023184.ZHANG Xuejun, ZHANG Fenghe, GAI Jiyang, et al. mVulSniffer: A multi-type source code vulnerability sniffer method[J]. Journal on Communications, 2023, 44(9): 149–160. doi: 10.11959/j.issn.1000-436x.2023184. [22] XU Xiangzhe, ZHANG Zhuo, SU Zian, et al. Symbol preference aware generative models for recovering variable names from stripped binary[EB/OL]. https://arxiv.org/abs/2306.02546, 2023. [23] WANG Yue, WANG Weishi, JOTY S, et al. CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation[C]. The 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 2021: 8696–8708. doi: 10.18653/v1/2021.emnlp-main.685. [24] WU Xinyi, AJORLOU A, WU Zihui, et al. Demystifying oversmoothing in attention-based graph neural networks[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 1524. [25] TANG Wensi, LONG Guodong, LIU Lu, et al. Omni-scale CNNs: A simple and effective kernel size configuration for time series classification[C/OL]. The 10th International Conference on Learning Representations, 2022. [26] MITRE. Common Vulnerabilities and Exposures (CVE)[EB/OL]. https://cve.mitre.org/, 2024. [27] NIST. Software assurance reference dataset[EB/OL]. https://samate.nist.gov/SARD/test-suites, 2024. [28] ZHOU Yaqin, LIU Shangqing, SIOW Jingkai, et al. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks[C]. The 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 915. [29] NGUYEN VA, NGUYEN DQ, NGUYEN V, et al. ReGVD: Revisiting graph neural networks for vulnerability detection[C]. The ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings, Pittsburgh, USA, 2022: 178–182. doi: 10.1145/3510454.3516865. [30] DU Xiaohu, WEN Ming, ZHU Jiahao, et al. Generalization-enhanced code vulnerability detection via multi-task instruction fine-tuning[C]. Findings of the Association for Computational Linguistics: ACL, Bangkok, Thailand, 2024: 10507–10521. doi: 10.18653/v1/2024.findings-acl.625. [31] ESPOSITO M, FALASCHI V, and FALESSI D. An extensive comparison of static application security testing tools[C]. The 28th International Conference on Evaluation and Assessment in Software Engineering, Salerno, Italy, 2024: 69–78. doi: 10.1145/3661167.3661199. -

 下载:
下载:


图(1) / 表(4)
计量
- 文章访问数: 697
- HTML全文浏览量: 535
- PDF下载量: 59
- 被引次数: 0
