

VCodePPA: A Large-scale Verilog Dataset with PPA Annotations
-
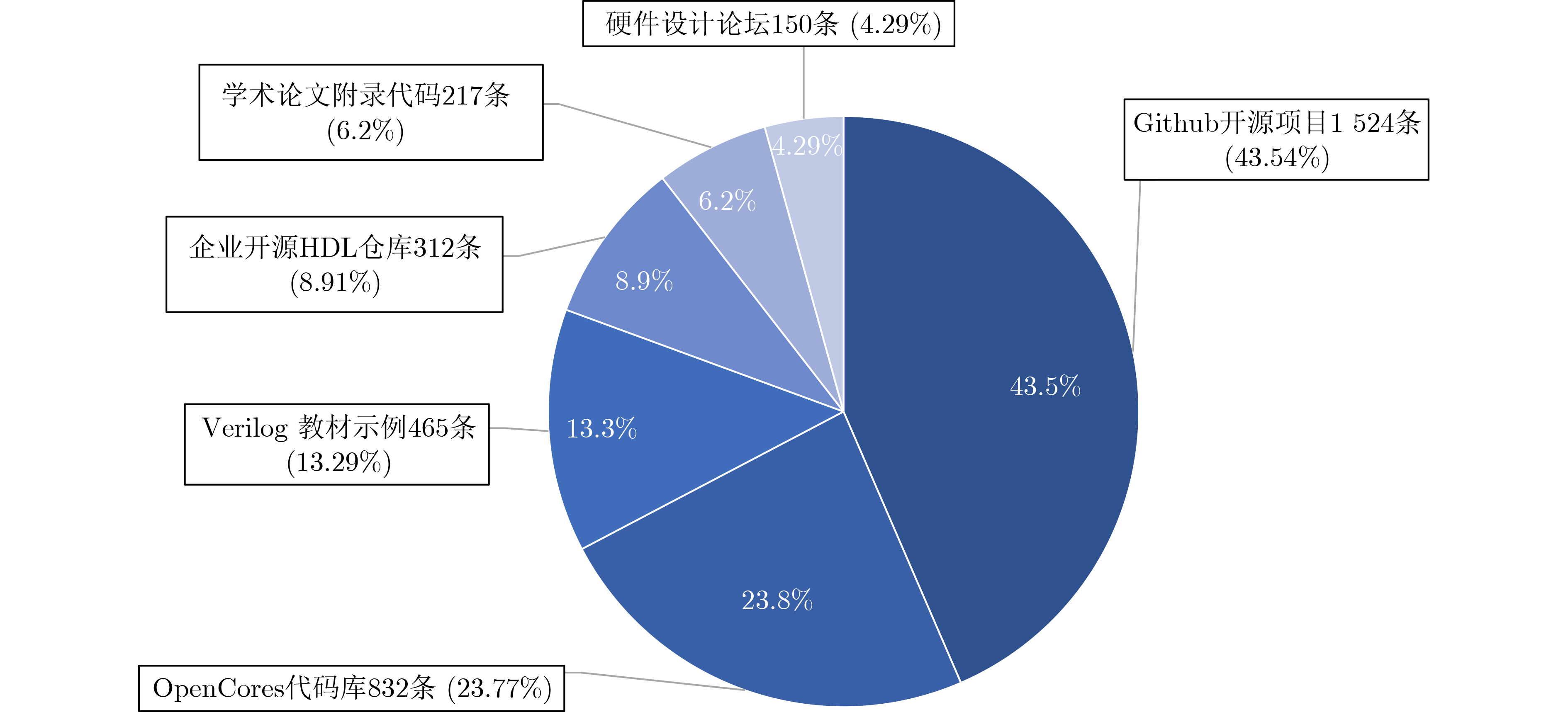
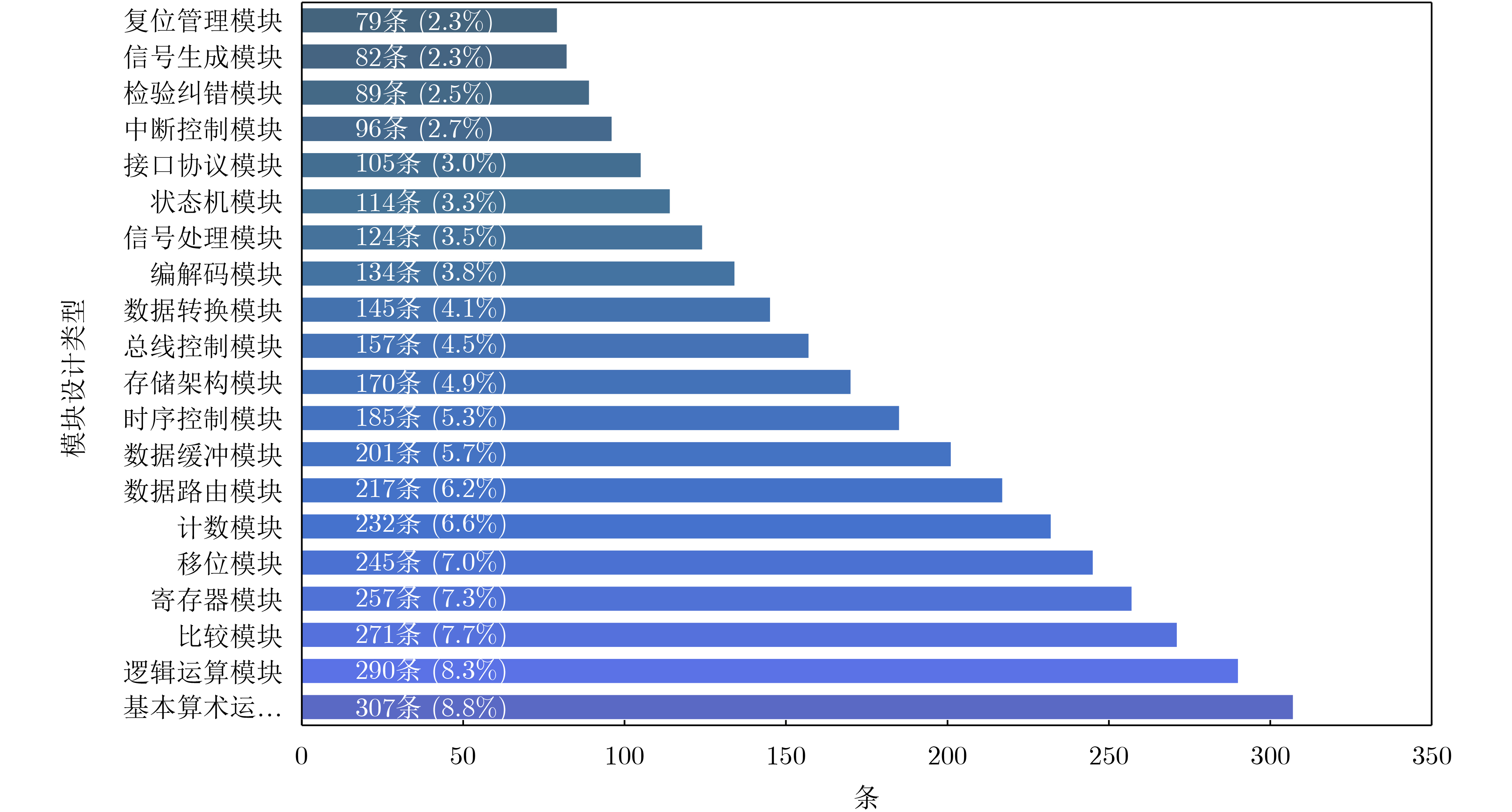
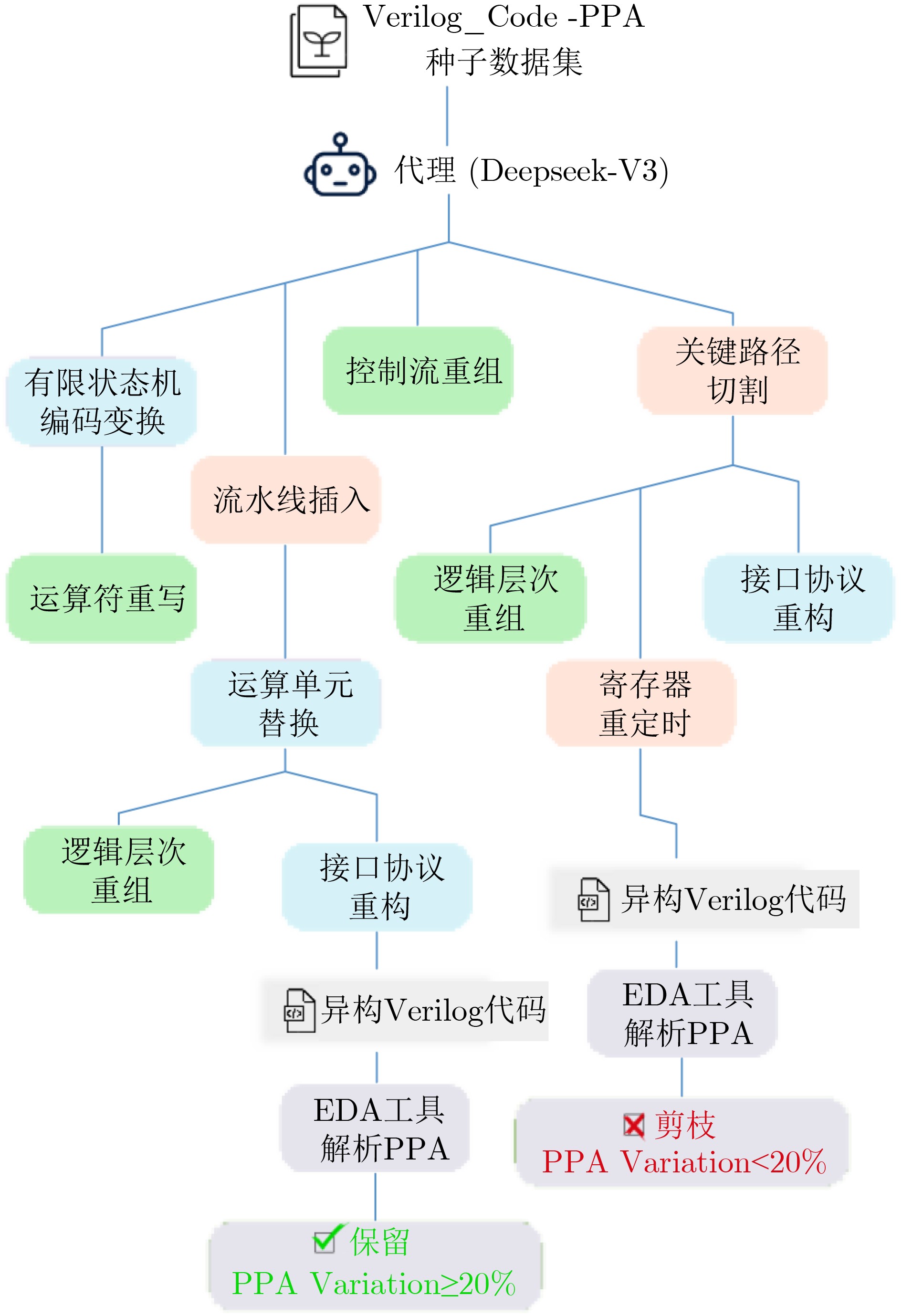
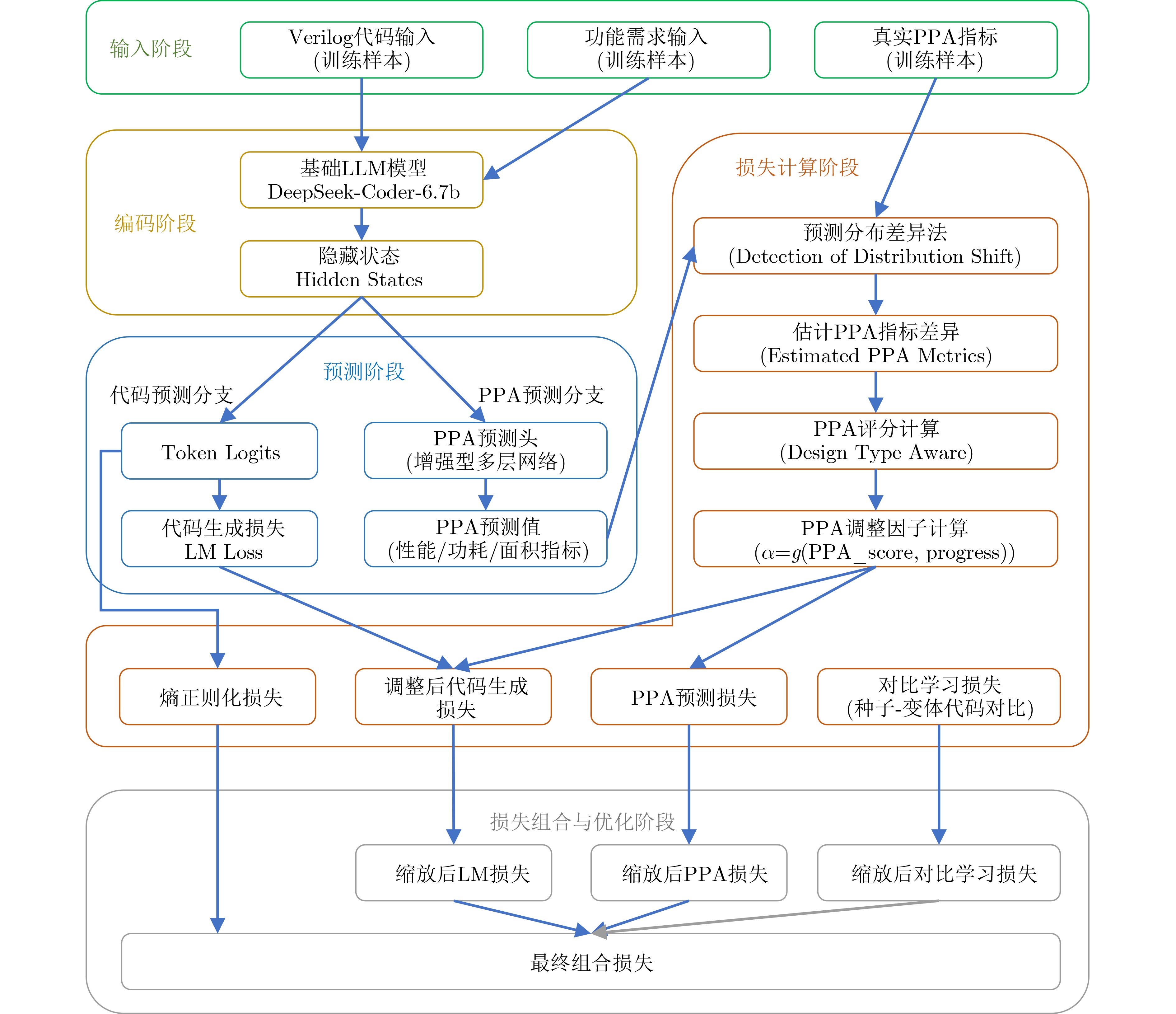
摘要: Verilog作为主流硬件描述语言之一,其代码质量直接影响电路的功耗、性能和面积(PPA)。当前,基于大语言模型(LLM)生成硬件描述语言的应用面临一个关键挑战:如何引入基于PPA指标的设计反馈机制,以有效指导模型优化,而不仅停留在Verilog语法和功能正确性层面。针对这一问题,该文公开了名为VCodePPA的数据集,该数据集将Verilog代码结构与功耗、性能、面积指标进行了精准关联,共包含17 342条高质量样本数据。该文所做工作为:构建了包含基本算术运算模块、存储架构模块等20种功能分类的3 500条规模的种子数据集;设计了基于蒙特卡罗搜索(MCTS)的多维代码数据增强方案,通过架构层、逻辑层和时序层3个维度的9种变换器对种子数据集进行代码变化,生成大规模功能等同但PPA指标差异显著的Verilog代码集。每条数据均包含如板上资源占用量、关键路径延迟、最大工作频率等多种硬件设计指标,用于训练模型在硬件设计PPA指标的冲突-平衡规律知识。实验表明经此数据集训练后,新模型相比基线模型在各种Verilog设计任务上平均减少了10%~15%的板上资源占用,降低了8%~12%的功耗,并缩短了5%~8%的关键路径延迟。
-
关键词:
- PPA优化 /
- 硬件语言生成 /
- 多维代码数据增强方案 /
- 双任务架构训练
Abstract:Objective As a predominant hardware description language, the quality of Verilog code directly affects the Power, Performance, and Area (PPA) metrics of the resulting circuits. Current Large Language Model (LLM)-based approaches for generating hardware description languages face a central challenge: incorporating a design feedback mechanism informed by PPA metrics to guide model optimization, rather than relying solely on syntactic and functional correctness. The field faces three major limitations: the absence of PPA metric annotations in training data, which prevents models from learning the effects of code modifications on physical characteristics; evaluation frameworks that remain disconnected from downstream engineering needs; and the lack of systematic data augmentation methods to generate functionally equivalent code with differentiated PPA characteristics. To address these gaps, we present VCodePPA, a large-scale dataset that establishes precise correlations between Verilog code structures and PPA metrics. The dataset comprises 17 342 entries and provides a foundation for data-driven optimization paradigms in hardware design. Methods The dataset construction is initiated by collecting representative Verilog code samples from GitHub repositories, OpenCores projects, and standard textbooks. After careful selection, a seed dataset of 3 500 samples covering 20 functional categories is established. These samples are preprocessed through functional coverage optimization, syntax verification with Yosys, format standardization, deduplication, and complexity filtering. An automated PPA extraction pipeline is implemented in Vivado to evaluate performance characteristics, with metrics including LookUp Table (LUT) count, register usage, maximum operating frequency, and power consumption. To enhance dataset diversity while preserving functional equivalence, a multi-dimensional code transformation framework is applied, consisting of nine methods across three dimensions: architecture layer (finite state machine encoding, interface protocol reconstruction, arithmetic unit replacement), logic layer (control flow reorganization, operator rewriting, logic hierarchy restructuring), and timing layer (critical path cutting, register retiming, pipeline insertion or deletion). Efficient exploration of the transformation space is achieved through a Homogeneous Verilog Mutation Search (HVMS) algorithm based on Monte Carlo Tree Search, which generates 5~10 PPA-differentiated variants for each seed code. A dual-task LLM training strategy with PPA-guided adaptive loss functions is subsequently employed, incorporating contrastive learning mechanisms to capture the relationship between code structure and physical implementation. Results and Discussions The VCodePPA dataset achieves broad coverage of digital hardware design scenarios, representing approximately 85%~90% of common design contexts. The multi-dimensional transformation framework generates functionally equivalent yet structurally diverse code variants, with PPA differences exceeding 20%, thereby exposing optimization trade-offs inherent in hardware design. Experimental evaluation demonstrates that models trained with VCodePPA show marked improvements in PPA optimization across multiple Verilog functional categories, including arithmetic, memory, control, and hybrid modules. In testing scenarios, VCodePPA-trained models produced implementations with superior PPA metrics compared with baseline models. The PPA-oriented adaptive loss function effectively overcame the traditional limitation of language model training, which typically lacks sensitivity to hardware implementation efficiency. By integrating contrastive learning and variant comparison loss mechanisms, the model achieved an average improvement of 17.7% across PPA metrics on the test set, influencing 32.4% of token-level predictions in code generation tasks. Notably, VCodePPA-trained models reduced on-chip resource usage by 10%$ \sim $15%, decreased power consumption by 8%$ \sim $12%, and shortened critical path delay by 5%$ \sim $8% relative to baseline models. Conclusions This paper introduces VCodePPA, a large-scale Verilog dataset with precise PPA annotations, addressing the gap between code generation and physical implementation optimization. The main contributions are as follows: (1)construction of a seed dataset spanning 20 functional categories with 3 500 samples, expanded through systematic multi-dimensional code transformation to 17 000 entries with comprehensive PPA metrics; (2)development of an MCTS-based homogeneous code augmentation scheme employing nine transformers across architectural, logical, and timing layers to generate functionally equivalent code variants with significant PPA differences; and (3)design of a dual-task training framework with PPA-oriented adaptive loss functions, enabling models to learn PPA trade-off principles directly from data rather than relying on manual heuristics or single-objective constraints. Experimental results demonstrate that models trained on VCodePPA effectively capture PPA balancing principles and generate optimized hardware description code. Future work will extend the dataset to more complex design scenarios and explore advanced optimization strategies for specialized application domains. -
表 1 VCodePPA数据集采用的PPA评估指标
类别 参数及评估意义 面积 LUT数量:反映组合逻辑复杂度和面积占用 FF数量:指示时序元素使用和状态复杂度 IO口数量:影响封装需求和接口复杂度 总cell数量:反映设计整体规模和资源利用 性能 最大工作频率:决定系统处理速度上限 端到端延迟:反映系统响应时间和传输效率 关键路径延迟:指示时序瓶颈,引导优化方向 功耗 模块总功耗:影响散热需求和系统能效比  下载: 导出CSV
下载: 导出CSV
1 同源Verilog变化搜索(HVMS)算法
输入: Seed code set Seeds, Target mutation count TargetCount, PPA threshold threshold 输出: AugmentedDataset (1) Initialization: (2) Transformer set T = {FSM encoding, Interface protocol, Arithmetic unit, Control flow, Operator rewriting, Logic hierarchy, Critical
path, Register retuning, Pipeline}(3) AugmentedDataset ← Ø; (4) foreach seed code seed in Seeds do: (5) BasePPA ← EvaluatePPA(seed) (6) VariantSet ← ParallelNGTSSearch(seed, BasePPA, TargetCount) (7) foreach variant i in VariantSet do: (8) Δ$ {{\mathrm{PPA}}}_{i} $ ← $ \frac{|{{\mathrm{PPA}}}_{i}-{{{\mathrm{Base}}{\mathrm{PPA}}}}|}{{\mathrm{Base}}{\mathrm{PPA}}} $; (9) if Δ$ {{\mathrm{PPA}}}_{i} $ > threshold then (10) AugmentedDataset ← AugmentedDataset ∪ {(variant.code, $ {{\mathrm{PPA}}}_{i} $)} (11) end (12) end (13) end (14) Function ParallelNGTSSearch(seed, BasePPA, TargetCount): (15) while |VariantSet| < TargetCount do: (16) Execute multiple search paths in parallel:; (17) path ← ExplorePath(seed, random_depth(1,2,3)); (18) Batch PPA evaluation of valid paths; (19) Filter variants with significant PPA changes into VariantSet; (20) end (21) return VariantSet; (22) end (23) Function ExplorePath(current_code, max_depth): (24) for path = 1 to max_depth do: (25) AvailableTransforms ← GetApplicableTransforms(current_code, T) (26) selected_T ← RandomChoice(AvailableTransforms) (27) new_code ← selected_T.transform(current_code) (28) if VerifyEquivalence(current_code, new_code) then: (29) current_code ← new_code (30) end (31) else (32) break; (33) end (34) end (35) return current_code; (36) end (37) Function EvaluatePPA(code): (38) Obtain through Vivado toolchain synthesis: (39) return {LUT count, FF count, Max frequency, Total power, Critical path delay}; (40) end (41) return AugmentedDataset;
下载: 导出CSV
表 2 不同模型在典型硬件模块上的详细PPA指标对比
模块类型 模型 LUT数量 FF数量 IO口数量 总cell数量 端到端路径
延时(ns)寄存器
关键路径延时(ns)总功耗
(mW)PPA评分 adder_16bit DeepSeek-Coder-6.7b 8 0 26 37 4.713 N/A 0.164 42.7 VCodePPA-DeepSeek 32 0 50 82 10.474 N/A 0.169 47.4 DeepSeek-V3 16 0 26 42 4.851 N/A 0.164 48.6 GPT-4o 16 0 50 78 5.543 N/A 0.17 53.9 Claude 3.7 12 0 26 38 5.179 N/A 0.164 49.5 fsm DeepSeek-Coder-6.7b 5 5 4 17 N/A 7.765 0.161 67.6 VCodePPA-DeepSeek 4 4 4 15 N/A 4.208 0.163 68.8 DeepSeek-V3 15 16 19 57 N/A 7.864 0.179 71.6 GPT-4o N/A N/A N/A N/A N/A N/A N/A 生成失败 Claude 3.7 4 5 4 17 4.192 7.769 0.166 66.2 asyn_fifo DeepSeek-Coder-6.7b N/A N/A N/A N/A N/A N/A N/A 生成失败 VCodePPA-DeepSeek 8 8 25 56 N/A 4.215 0.16 72.2 DeepSeek-V3 69 166 24 298 N/A N/A 0.165 57.9 GPT-4o 77 151 24 267 N/A N/A 0.165 57.8 Claude 3.7 20 48 24 120 N/A N/A 0.161 66.0 freq_div DeepSeek-Coder-6.7b 10 9 5 29 N/A 0.838 0.166 68.8 VCodePPA-DeepSeek 16 28 5 59 N/A 0.976 0.163 70.7 DeepSeek-V3 10 12 5 32 N/A 1.027 0.163 68.3 GPT-4o 11 13 5 34 3.122 0.85 0.163 67.9 Claude 3.7 10 12 5 32 N/A 1.027 0.163 68.3
下载: 导出CSV
表 3 不同模型在典型硬件模块设计上的PPA评分对比
模块设计 DeepSeek-Coedr-6.7b VCodePPA-DeepSeek DeepSeek-V3 GPT-4o Claude 3.7 adder_16bit 42.7 47.4 48.6 53.9 49.5 alu 42.7 生成失败 37.7 37.7 39.2 asyn_fifo 生成失败 72.3 57.9 57.8 66.0 barrel_shifter 51.3 51.4 44.7 51.3 51.3 div_16bit 43.3 52.3 生成失败 33.4 35.2 edge_detect 70.7 70.8 70.7 70.7 70.7 fixed_point_adder 54.1 55.5 43.5 44.9 43.4 freq_div 68.8 70.7 68.3 67.9 68.3 fsm 67.6 68.8 71.6 生成失败 66.2 LFSR 74.1 75.1 71.5 71.5 71.5 multi_8bit 43.3 44.3 44.7 44.7 44.7 parallel2serial 65.6 67.1 66.0 52.4 66.0 RAM 生成失败 66.0 65.5 65.5 65.5 serial2parallel 65.5 65.6 64.1 64.2 64.1 signal_generator 65.5 73.8 66.5 66.5 64.8 traffic_light 生成失败 62.9 72.0 生成失败 72.0 up_down_counter 71.6 71.7 71.7 71.7 71.6
下载: 导出CSV
表 4 消融实验
模块类型 单任务PPA
评分(代码生成)双任务PPA
评分(代码生成+
PPA预测)改进幅度
(%)fsm 67.6 68.8 +1.8 freq_div 68.8 70.7 +2.8 adder_16 bit 42.7 47.4 +11.0 Div_16 bit 43.3 52.3 +20.8 fixed_point_adder 54.1 55.5 +2.6 signal_generator 65.5 73.8 +12.7
下载: 导出CSV
-
[1] THAKUR S, AHMAD B, FAN Zhenxing, et al. Benchmarking large language models for automated Verilog RTL code generation[C]. 2023 Design, Automation & Test in Europe Conference & Exhibition (DATE), Antwerp, Belgium, 2023: 1–6. doi: 10.23919/DATE56975.2023.10137086. [2] LU Yao, LIU Shang, ZHANG Qijun, et al. RTLLM: An open-source benchmark for design RTL generation with large language model[C]. 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC), Incheon, Republic of Korea, 2024: 722–727. doi: 10.1109/ASP-DAC58780.2024.10473904. [3] LIU Mingjie, PINCKNEY N, KHAILANY B, et al. Invited paper: VerilogEval: Evaluating large language models for Verilog code generation[C]. 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), San Francisco, USA, 2023: 1–8. doi: 10.1109/ICCAD57390.2023.10323812. [4] LIU Mingjie, TSAI Y D, ZHOU Wenfei, et al. CraftRTL: High-quality synthetic data generation for Verilog code models with correct-by-construction non-textual representations and targeted code repair[C]. The Thirteenth International Conference on Learning Representations, Singapore, Singapore, 2025. [5] ZHAO Yang, HUANG Di, LI Chongxiao, et al. CodeV: Empowering LLMs for Verilog generation through multi-level summarization[EB/OL]. https://arxiv.org/abs/2407.10424v4, 2024. [6] THAKUR S, AHMAD B, PEARCE H, et al. VeriGen: A large language model for Verilog code generation[J]. ACM Transactions on Design Automation of Electronic Systems, 2024, 29(3): 46. doi: 10.1145/3643681. [7] LIU Shang, FANG Wenji, LU Yao, et al. RTLCoder: Fully open-source and efficient LLM-assisted RTL code generation technique[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2025, 44(4): 1448–1461. doi: 10.1109/TCAD.2024.3483089. [8] NADIMI B and ZHENG H. A multi-expert large language model architecture for Verilog code generation[C]. 2024 IEEE LLM Aided Design Workshop (LAD), San Jose, USA, 2024: 1–5. doi: 10.1109/LAD62341.2024.10691683. [9] WU Peiyang, GUO Nan, LV Junliang, et al. RTLRepoCoder: Repository-level RTL code completion through the combination of fine-tuning and retrieval augmentation[EB/OL]. https://arxiv.org/abs/2504.08862, 2025. [10] THORAT K, ZHAO Jiahui, LIU Yaotian, et al. Advanced Large Language Model (LLM)-driven Verilog development: Enhancing power, performance, and area optimization in code synthesis[EB/OL]. https://arxiv.org/abs/2312.01022, 2023. [11] PEI Zehua, ZHEN Huiling, YUAN Mingxuan, et al. BetterV: Controlled Verilog generation with discriminative guidance[C]. Forty-First International Conference on Machine Learning, Vienna, Austria, 2024. [12] TSAI Y, LIU Mingjie, and REN Haoxing. RTLFixer: Automatically fixing RTL syntax errors with large language model[C]. The 61st ACM/IEEE Design Automation Conference, San Francisco, USA, 2024: 53. doi: 10.1145/3649329.3657353. [13] PULAVARTHI V, NANDAL D, DAN S, et al. AssertionBench: A benchmark to evaluate large-language models for assertion generation[C]. Findings of the Association for Computational Linguistics: NAACL 2025, Albuquerque, New Mexico, 2025: 8058–8065. doi: 10.18653/v1/2025.findings-naacl.449. [14] QIU Ruidi, ZHANG G L, DRECHSLER R, et al. AutoBench: Automatic testbench generation and evaluation using LLMs for HDL design[C]. The 2024 ACM/IEEE 6th International Symposium on Machine Learning for CAD, Salt Lake City, USA, 2024: 1–10. doi: 10.1109/MLCAD62225.2024.10740250. [15] QIU Ruidi, ZHANG G L, DRECHSLER R, et al. CorrectBench: Automatic testbench generation with functional self-correction using LLMs for HDL design[C]. 2025 Design, Automation & Test in Europe Conference (DATE), Lyon, France, 2025: 1–7. doi: 10.23919/DATE64628.2025.10992873. [16] NADIMI B, BOUTAIB G O, and ZHENG Hao. VeriMind: Agentic LLM for automated Verilog generation with a novel evaluation metric[EB/OL]. https://arxiv.org/abs/2503.16514, 2025. [17] ABDELATTY M, MA Jingxiao, and REDA S. MetRex: A benchmark for Verilog code metric reasoning using LLMs[C]. The 30th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 2025: 995–1001. doi: 10.1145/3658617.3697625. [18] ZHANG Yongan, YU Zhongzhi, FU Yonggan, et al. MG-Verilog: Multi-grained dataset towards enhanced LLM-assisted Verilog generation[C]. 2024 IEEE LLM Aided Design Workshop (LAD), San Jose, USA, 2024: 1–5. doi: 10.1109/LAD62341.2024.10691738. [19] WEI Anjiang, TAN Huanmi, SURESH T, et al. VeriCoder: Enhancing LLM-based RTL code generation through functional correctness validation[EB/OL]. https://arxiv.org/abs/2504.15659, 2025. [20] ALLAM A and SHALAN M. RTL-repo: A benchmark for evaluating LLMs on large-scale RTL design projects[C]. 2024 IEEE LLM Aided Design Workshop (LAD), San Jose, USA, 2024: 1–5. doi: 10.1109/LAD62341.2024.10691810. [21] LIU Shang, LU Yao, FANG Wenji, et al. OpenLLM-RTL: Open dataset and benchmark for LLM-aided design RTL generation[C]. The 43rd IEEE/ACM International Conference on Computer-Aided Design, New York, USA, 2024: 60. doi: 10.1145/3676536.3697118. [22] BUSH S, DELORENZO M, TIEU P, et al. Free and fair hardware: A pathway to copyright infringement-free Verilog generation using LLMs[C]. 62nd ACM/IEEE Design Automation Conference (DAC), San Francisco, USA, 2025: 1–7. doi: 10.1109/DAC63849.2025.11132658. [23] WENG Lilian. Contrastive representation learning. Lil’Log[EB/OL]. https://lilianweng.github.io/posts/2021-05-31-contrastive/, 2021. [24] GAO Tianyu, YAO Xingcheng, and CHEN Danqi. SimCSE: Simple contrastive learning of sentence embeddings[C]. The 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 2021: 6894–6910. doi: 10.18653/v1/2021.emnlp-main.552. [25] NEELAKANTAN A, XU Tao, PURI R, et al. Text and code embeddings by contrastive pre-training[EB/OL]. https://arxiv.org/abs/2201.10005, 2022. -

 下载:
下载:


图(4) / 表(5)
计量
- 文章访问数: 1161
- HTML全文浏览量: 842
- PDF下载量: 106
- 被引次数: 0
