

A Survey on System and Architecture Optimization Techniques for Mixture-of-Experts Large Language Models
-
摘要: 混合专家已经成为当前进一步提升大语言模型推理能力的重要方法。当下,受限于算力与显存,通过扩大稠密大语言模型参数规模来提高模型推理能力的方法已经陷入瓶颈,即全参数激活带来了严重的显存与算力不足问题。混合专家机制通过构建由多个专家子网络组成的分布“知识库”,在提升大语言模型参数规模的同时,通过路由函数动态选择专家子网络来控制单次推理计算总量。然而,这种动态专家选择机制带来了显著的资源管理和调度问题,需要在加速系统和硬件架构层面有针对性地开展优化。该文将聚焦于混合专家大语言模型部署的系统与架构层:首先,概述了混合专家大模型的定义和发展趋势;之后,详细介绍了现有混合专家大语言模型的系统与架构优化技术并深入分析;最后,该文对混合专家大模型的优化技术进行总结和展望。Abstract:
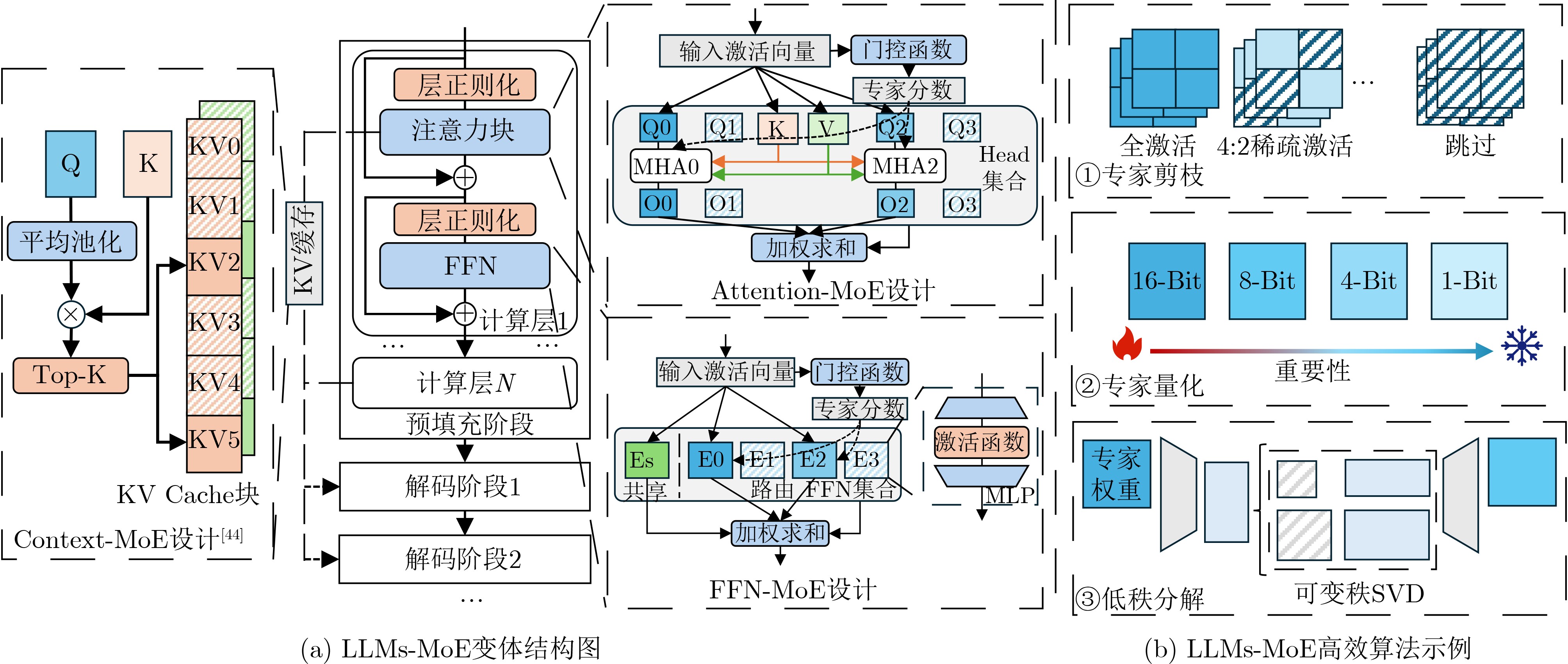
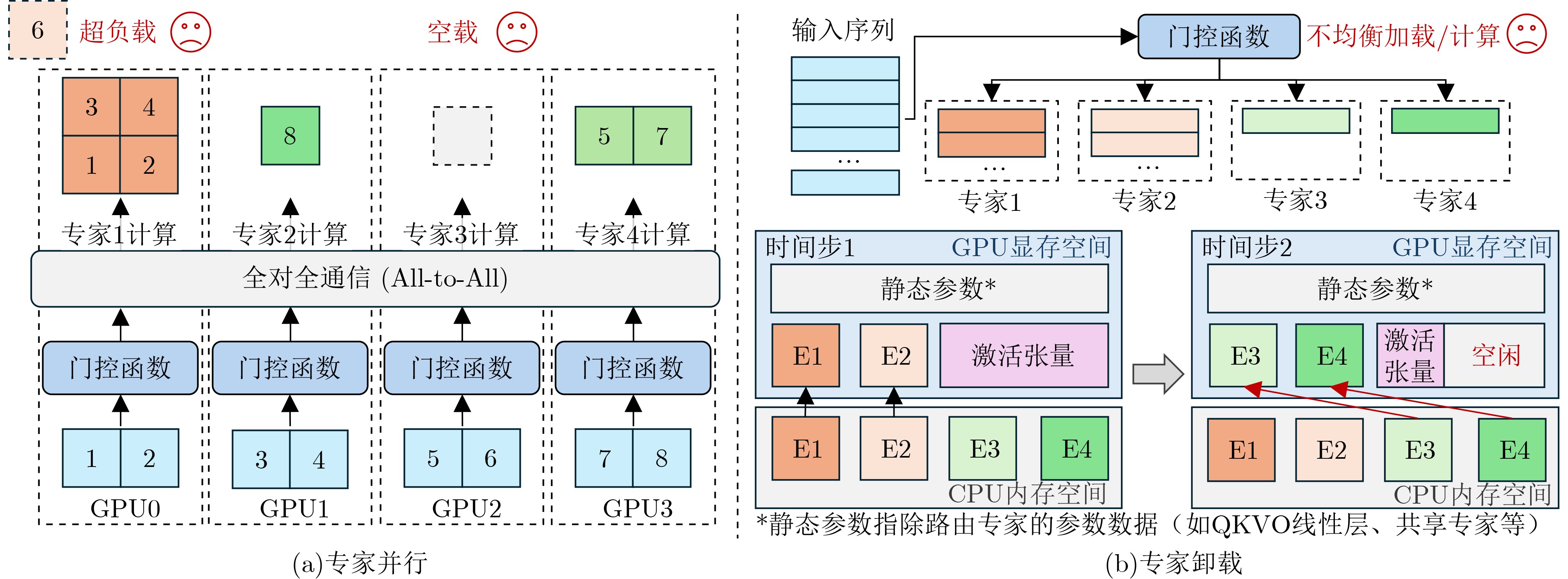
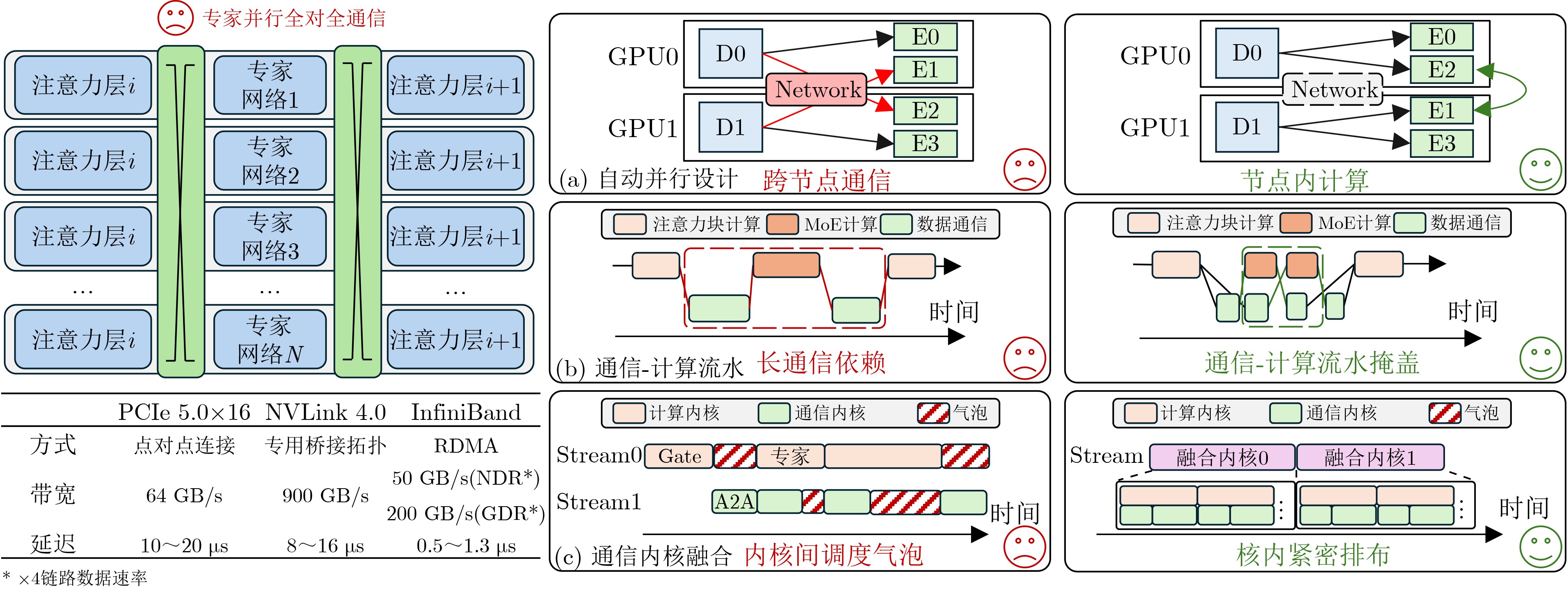
The Mixture-of-Experts (MoE) framework has become a pivotal approach for enhancing the knowledge capacity and inference efficiency of Large Language Models (LLMs). Conventional methods for scaling dense LLMs have reached significant limitations in training and inference due to computational and memory constraints. MoE addresses these challenges by distributing knowledge representation across specialized expert sub-networks, enabling parameter expansion while maintaining efficiency through sparse expert activation during inference. However, the dynamic nature of expert activation introduces substantial challenges in resource management and scheduling, necessitating targeted optimization at both the system and architectural levels. This survey focuses on the deployment of MoE-based LLMs. It first reviews the definitions and developmental trajectory of MoE, followed by an in-depth analysis of current system-level optimization strategies and architectural innovations tailored to MoE. The paper concludes by summarizing key findings and proposing prospective optimization techniques for MoE-based LLMs. Significance The MoE mechanism offers a promising solution to the computational and memory limitations of dense LLMs. By distributing knowledge representation across specialized expert sub-networks, MoE facilitates model scaling without incurring prohibitive computational costs. This architecture alleviates the bottlenecks associated with training and inference in traditional dense models, marking a notable advance in LLM research. Nonetheless, the dynamic expert activation patterns inherent to MoE introduce new challenges in resource scheduling and management. Overcoming these challenges requires targeted system- and architecture-level optimizations to fully harness the potential of MoE-based LLMs. Progress Recent advancements in MoE-based LLMs have led to the development of various optimization strategies. At the system level, approaches such as automatic parallelism, communication-computation pipelining, and communication operator fusion have been adopted to reduce communication overhead. Memory management has been improved through expert prefetching, caching mechanisms, and queue scheduling policies. To address computational load imbalance, both offline scheduling methods and runtime expert allocation strategies have been proposed, including designs that leverage heterogeneous CPU-GPU architectures. In terms of hardware architecture, innovations include dynamic adaptation to expert activation patterns, techniques to overcome bandwidth limitations, and near-memory computing schemes that improve deployment efficiency. In parallel, the open-source community has developed supporting tools and frameworks that facilitate the practical deployment and optimization of MoE-based models. Conclusions This survey presents a comprehensive review of system and architectural optimization techniques for MoE-based LLMs. It highlights the importance of reconciling parameter scalability with computational efficiency through the MoE framework. The dynamic nature of expert activation poses significant challenges in scheduling and resource management, which are systematically addressed in this survey. By evaluating current optimization techniques across both system and hardware layers, the paper offers key insights into the state of the field. It also proposes directions for future work, providing a reference for researchers and practitioners seeking to improve the performance and scalability of MoE-based models. The findings emphasize the need for continued innovation across algorithm development, system engineering, and architectural design to fully realize the potential of MoE in real-world applications. Prospects Future research on MoE-based LLMs is expected to advance the integration of algorithm design, system optimization, and hardware co-design. Key research directions include resolving load imbalance and maximizing resource utilization through adaptive expert scheduling algorithms, refining system frameworks to support dynamic sparse computation more effectively, and exploring hardware paradigms such as near-memory computing and hierarchical memory architectures. These developments aim to deliver more efficient and scalable MoE model deployments by fostering deeper synergy between software and hardware components. -
Key words:
- Large language models /
- Mixture of experts /
- System acceleration /
- Hardware architecture
-
表 1 混合专家大模型参数表
模型名称 发行单位 发布时间 总参数量 稠密/混合
专家层数$ \#\mathit{D} $ $ \#{\mathit{D}}_{\rm{F}\rm{F}\rm{N}} $ $ \#{\mathit{D}}_{\rm{E}\rm{x}\rm{p}.} $ 专家参数量 总专家数 激活专家数
(路由+共享)激活参数量 Gshard*[31] Google 2020.06 37.5 B 18/18 1024 8192 8192 - 128 2+0 1.5 B 150 B 18/18 1024 8192 8192 - 512 2+0 1.5 B 600 B 18/18 1024 8192 8192 - 2048 2+0 1.5 B Switch
Transformers*[28]Google 2021.01 7 B 6/6 768 2048 2048 - 128 1+0 - 26 B 12/12 1024 2816 2816 - 128 1+0 - 395 B 12/12 4096 10240 10240 - 64 1+0 - 1571 B 0/15 2080 6144 6144 1570.3 B 2048 1+0 1.6 B M6-T[30] Alibaba 2021.08 1.4 B 0/5 1024 4096 4096 1.34 B 32 2/4+0 0.14/0.23 B 10.8 B 0/10 1024 4096 4096 10.74 B 128 2/4+0 0.14/0.23 B 103.2 B 0/24 1024 4096 4096 103.09 B 512 2/4+0 0.14/0.23 B 1002.7 B 0/24 1024 21248 21248 1002.63 B 960 2/4+0 2.2/4.3 B GLaM[22] Google 2021.12 1.9 B 6/6 768 3072 3072 1.81 B 64 2+0 0.145 B 27 B 12/12 2048 8192 8192 25.77 B 64 2+0 1.88 B 143 B 16/16 4096 16384 16384 137.44 B 64 2+0 9.8 B 1200 B 32/32 8192 32768 32768 1099.53 B 64 2+0 96.6 B ST-MoE[32] Google 2022.02 4.1 B 0/27 1024 2816 2816 4.98 B 32 2+0 0.8 B 269 B 0/27 5120 20480 20480 362.4 B 64 2+0 32 B NLLB-MoE*[154] FaceBook 2022.07 54.5 B 0/24 1024 8192 8192 51.54 B 128 2+0 3.8 B Qwen2-57B-A14B[155] Alibaba 2023.05 57.4 B 0/28 3584 18944 2560 49.33 B 64 8+0 14 B Mixtral-8x7B[23] Mistral AI 2023.12 46.7 B 0/32 4096 14336 14336 45.1 B 8 2+0 14 B OpenMoE[33] NUS et al. 2023.12 0.65 B 0/3 768 3072 3072 0.34 B 16 2+0 0.339 B 8.7 B 0/4 2048 8192 8192 6.44 B 32 2+0 2.6 B 34 B 0/8 3072 12288 12288 28.99 B 32 2+0 34 B DeepSeek-MoE[24] DeepSeek-AI 2024.01 1.89 B 0/9 1280 5120 1280 2.83 B 64 6+1 0.24 B 16.4 B 3/28 2048 10944 1408 15.51 B 64 6+2 2.8 B 145 B 3/59 4096 14336 1792 166.33 B 128 12+4 22 B Qwen1.5-MoE[156] Alibaba 2024.02 14.3 B 0/24 2048 5632 1408 12.46 B 60 4+4 2.7 B JetMoE[34] MIT et al. 2024.03 8.52 B 0/24 2048 5632 5632 6.64 B 8 2+0 2.2 B Jamba**[26] ai21labs 2024.03 51.6 B 0/32 4096 14336 14336 90.2 B 16 2+0 12 B DBRX[157] Databricks 2024.03 132 B 0/40 6144 10752 10752 126.84 B 16 4+0 36 B Grok-1[25] xAI 2024.03 314 B 0/64 6144 32768 32768 309.24 B 8 2+0 39 B Arctic[158] Snowflake 2024.04 482 B 0/35 7168 4864 4864 43.93 B 12 2+0 17 B Mixtral-8x22B[23] Mistral AI 2024.04 141 B 0/56 6144 16384 16384 135.29 B 8 2+0 39.5 B DeepSeek-V2.5[159] DeepSeek-AI 2024.04 236 B 3/59 5120 12288 1536 222.77 B 160 6+2 21 B Skywork-MoE[160] Kunlun Tech 2024.05 146 B 0/52 4608 12288 12288 141.34 B 16 2+0 22 B Yuan2[161] IEIT-Yuan 2024.05 40 B 0/24 2048 8192 8192 38.66 B 32 2+0 3.7 B LLaMA-MoE[162] Zhu et al. 2024.06 37 B 0/32 4096 11008 11008 34.63 B 8 2+0 3.8 B OLMoE[163] AllenAI 2024.07 6.92 B 0/16 2048 1024 1024 6.44 B 64 8+0 1.3 B Phi-3.5[7] MicroSoft 2024.08 41.9 B 0/32 4096 6400 6400 40.27 B 16 2+0 6.6 B GRIN-MoE[164] MicroSoft 2024.09 41.9 B 0/32 4096 6400 6400 40.27 B 16 2+0 6.6 B Hunyuan-Large[165] Tencent 2024.11 389 B 0/64 6400 18304 18304 359.88 B 16 1+1 52 B DeepSeek-V3[27] DeepSeek-AI 2024.12 671 B 3/58 7168 18432 2048 656.46 B 256 8+1 37 B MiniMax-Text-01[166] MiniMax-AI 2025.01 456 B 0/80 6144 9216 9216 434.88 B 32 2+0 45.9 B Moonlight[167] Moonshot AI 2025.02 16 B 0/26 2048 11264 1408 14.4 B 64 6+2 3 B LLaMA4[168] Meta 2025.04 109 B 0/48 5120 16384 8192 98.1 B 16 1+1 17 B 400 B 24/24 5120 16384 8192 389.6 B 128 1+1 17 B 2000 B - - - - - 16 - 288 B Qwen3-MoE[169] Alibaba 2025.05 30 B 0/48 2048 6144 768 29 B 128 8+0 3 B 235 B 0/94 4096 12288 1536 227 B 128 8+0 22 B * 该模型为“编码器 - 解码器”结构
** 该模型为“Transformer–Mamba[121]”结构 下载: 导出CSV
下载: 导出CSV
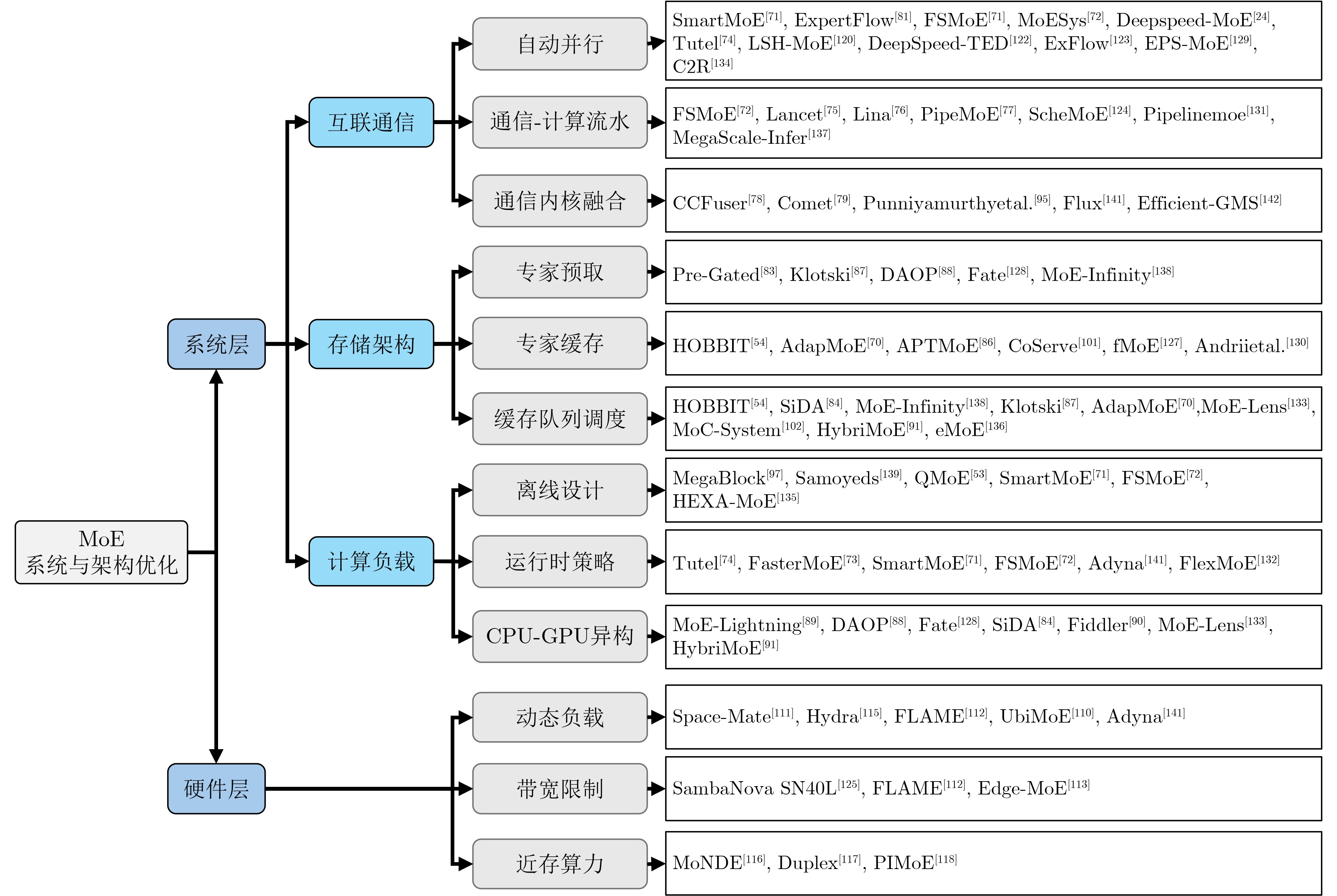
表 2 面向混合专家大模型系统优化开源项目表
名称 年份 组织/单位 通信优化 内存优化 计算优化 链接 EPLB[151] 2025 DeepSeek-AI √ https://github.com/deepseek-ai/eplb DeepEP[150] 2025 DeepSeek-AI √ https://github.com/deepseek-ai/DeepEP Flux[141] 2025 ByteDance √ √ https://github.com/bytedance/flux Ktransformer[108] 2025 KV-Cache √ √ https://github.com/kvcache-ai/ktransformers llama.cpp[149] 2024 GGML √ √ https://github.com/ggml-org/llama.cpp Megatron-LM-MoE[146] 2023 NVIDIA √ √ https://github.com/NVIDIA/Megatron-LM DeepSpeed-MoE[24] 2022 Microsoft √ √ https://github.com/deepspeedai/DeepSpeed Tutel[74] 2023 Microsoft √ √ https://github.com/microsoft/Tutel MegaBlocks[97] 2023 Stanford √ https://github.com/databricks/megablocks vLLM[106] 2023 vLLM √ √ https://github.com/vllm-project/vllm SGLang[107] 2023 UCB, Stanford √ https://github.com/sgl-project/sglang TensorRT-LLM[147] 2025 NVIDIA √ https://github.com/NVIDIA/TensorRT-LLM LMDeploy[148] 2023 InternLM √ √ https://github.com/InternLM/lmdeploy FastMoE[72] 2025 THU √ √ https://github.com/laekov/fastmoe Huggingface-MoE[152] 2023 Huggingface https://huggingface.co Fairseq-MoE[153] 2021 Meta https://github.com/facebookresearch/fairseq
下载: 导出CSV
表 3 部分开源系统优化方法与性能数据
名称 实验硬件平台 基线 并行策略* 部分关键优化技术 性能表现 TensorRT-LLM[147] 2×NVIDIA H100 80 GB - TP+EP 混合并行模式 最高38.4 请求/秒 DeepSpeed-MoE[24] 8/16/32×NVIDIA V100 32 GB PyTorch DP+TP+EP 稀疏映射表简化TopK路由 端到端加速2–3.2× vLLM[106] 4×NVIDIA A100 40 GB PyTorch DP+TP+PP+EP 解码优先调度,预填充分块 单层最大加速4.0× Tutel[74] 512×NVIDIA A100 80 GB Fairseq[153] DP+TP+EP 并行策略随路由自适应切换 单层加速8.49×;
端到端平均加速1.4×Flux[141] 8×NVIDIA H100 80 GB Megatron[146] TP+EP 通信-计算内核细粒度融合 单层加速1.96×;
端到端平均加速1.71×* DP – 数据并行;PP – 流水线并行;TP – 张量并行;EP – 专家并行
下载: 导出CSV
表 4 优化架构参数与性能数据
名称 任务 硬件平台 峰值算力 峰值带宽 对比基线 推理加速比 能效比提升 FLAME[112] 文本生成 Xilinx Alveo U200 - 77GB/s* NVIDIA 3090 GPU1.49× - Edge-MoE[113] 视觉模型 Xilinx ZCU102 - 19.2GB/s* NVIDIA RTX A6000 GPU 0.40× 2.24× UbiMoE[110] 视觉模型 Xilinx ZCU102 304.84GOPS (INT16) 19.2GB/s* NVIDIA Tesla V100S GPU 1.56× 7.85× Xilinx Alveo U280 789.72GOPS (INT16) 460GB/s* 3.88× 6.93× MoNDE[116] 文本生成 NDP + GPU 312TFLOPS (GPU)
2TFLOPS (NDP)512GB/s NVIDIA A100 GPU 1.1~6.7× - Duplex[117] 文本生成 PIM + xPU 756.5TFLOPS (xPU)
106.5TFLOPS (PIM)~12TB/s NVIDIA H100 GPU 1.36~2.67× 4.61× PIMoE[118] 文本生成 PIM + NPU 32.8TFLOPS (NPU)
2.5TFLOPS (PIM)614GB/s NVIDIA A100 GPU 1.6~8.47× 4.8~13.7× *可编程逻辑(PL)单元的内存峰值带宽
下载: 导出CSV
-
[1] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [2] OpenAI. GPT-4 technical report[J]. arXiv preprint arXiv: 2303.08774, 2024. doi: 10.48550/arXiv.2303.08774. [3] Gemini Team Google. Gemini: A family of highly capable multimodal models[J]. arXiv preprint arXiv: 2312.11805, 2025. doi: 10.48550/arXiv.2312.11805. [4] Qwen Team. Qwen2.5 technical report[J]. arXiv preprint arXiv: 2412.15115, 2025. doi: 10.48550/arXiv.2412.15115. [5] DUBEY A, JAUHRI A, PANDEY A, et al. The LLAMA 3 herd of models[J]. arXiv preprint arXiv: 2407.21783, 2024. doi: 10.48550/arXiv.2407.21783. [6] DU Zhengxiao, QIAN Yujie, LIU Xiao, et al. GLM: General language model pretraining with autoregressive blank infilling[C]. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 2022: 320–335. doi: 10.18653/v1/2022.acl-long.26. [7] ABDIN M, ANEJA J, AWADALLA H, et al. Phi-3 technical report: A highly capable language model locally on your phone[J]. arXiv preprint arXiv: 2404.14219, 2024. doi: 10.48550/arXiv.2404.14219. [8] TOUVRON H, MARTIN L, STONE K, et al. LLAMA 2: Open foundation and fine-tuned chat models[J]. arXiv preprint arXiv: 2307.09288, 2023. doi: 10.48550/arXiv.2307.09288. [9] OUYANG Long, WU J, JIANG Xu, et al. Training language models to follow instructions with human feedback[C]. Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 27730–27744. [10] BOCKLISCH T, WERKMEISTER T, VARSHNEYA D, et al. Task-oriented dialogue with in-context learning[J]. arXiv preprint arXiv: 2402.12234, 2024. doi: 10.48550/arXiv.2402.12234. [11] TSAI Y D, LIU Mingjie, and REN Haoxing. Code less, align more: Efficient LLM fine-tuning for code generation with data pruning[J]. arXiv preprint arXiv: 2407.05040, 2024. doi: 10.48550/arXiv.2407.05040. [12] NLLB Team, COSTA-JUSSÀ M R, CROSS J, et al. No language left behind: Scaling human-centered machine translation[J]. arXiv preprint arXiv: 2207.04672, 2022. doi: 10.48550/arXiv.2207.04672. [13] BORDES F, PANG R Y, AJAY A, et al. An introduction to vision-language modeling[J]. arXiv preprint arXiv: 2405.17247, 2024. doi: 10.48550/arXiv.2405.17247. [14] LIU Haotian, LI Chunyuan, WU Qingyang, et al. Visual instruction tuning[C]. Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 34892–34916. [15] WANG Peng, BAI Shuai, TAN Sinan, et al. Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution[J]. arXiv preprint arXiv: 2409.12191, 2024. doi: 10.48550/arXiv.2409.12191. [16] YAO Yuan, YU Tianyu, ZHANG Ao, et al. MiniCPM-V: A GPT-4V level MLLM on your phone[J]. arXiv preprint arXiv: 2408.01800, 2024. doi: 10.48550/arXiv.2408.01800. [17] KAPLAN J, MCCANDLISH S, HENIGHAN T, et al. Scaling laws for neural language models[J]. arXiv preprint arXiv: 2001.08361, 2020. doi: 10.48550/arXiv.2001.08361. [18] HOFFMANN J, BORGEAUD S, MENSCH A, et al. Training compute-optimal large language models[J]. arXiv preprint arXiv: 2203.15556, 2022. doi: 10.48550/arXiv.2203.15556. [19] ANIL R, DAI A M, FIRAT O, et al. PaLM 2 technical report[J]. arXiv preprint arXiv: 2305.10403, 2023. doi: 10.48550/arXiv.2305.10403. [20] JACOBS R A, JORDAN M I, NOWLAN S J, et al. Adaptive mixtures of local experts[J]. Neural Computation, 1991, 3(1): 79–87. doi: 10.1162/neco.1991.3.1.79. [21] SHAZEER N, MIRHOSEINI A, MAZIARZ K, et al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer[J]. arXiv preprint arXiv: 1701.06538, 2017. doi: 10.48550/arXiv.1701.06538. [22] DU Nan, HUANG Yanping, DAI A M, et al. GLaM: Efficient scaling of language models with mixture-of-experts[C]. Proceedings of the 39th International Conference on Machine Learning, Maryland, USA, 2022: 5547–5569. [23] JIANG A Q, SABLAYROLLES A, ROUX A, et al. Mixtral of experts[J]. arXiv preprint arXiv: 2401.04088, 2024. doi: 10.48550/arXiv.2401.04088. [24] RAJBHANDARI S, LI Conglong, YAO Zhewei, et al. DeepSpeed-MoE: Advancing mixture-of-experts inference and training to power next-generation AI scale[C]. Proceedings of the 39th International Conference on Machine Learning, Maryland, USA, 2022: 18332–18346. [25] X-AI. Grok-1[EB/OL]. https://github.com/xai-org/grok-1, 2024. [26] LIEBER O, LENZ B, BATA H, et al. Jamba: A hybrid transformer-mamba language model[J]. arXiv preprint arXiv: 2403.19887, 2024. doi: 10.48550/arXiv.2403.19887. [27] DeepSeek-AI. DeepSeek-V3 technical report[J]. arXiv preprint arXiv: 2412.19437, 2025. doi: 10.48550/arXiv.2412.19437. [28] FEDUS W, ZOPH B, and SHAZEER N. Switch Transformers: Scaling to trillion parameter models with simple and efficient sparsity[J]. arXiv preprint arXiv: 2101.03961, 2022. doi: 10.48550/arXiv.2101.03961. [29] MiniMax. MiniMax-01: Scaling foundation models with lightning attention[J]. arXiv preprint arXiv: 2501.08313, 2025. doi: 10.48550/arXiv.2501.08313. [30] YANG An, LIN Junyang, MEN Rui, et al. M6-T: Exploring sparse expert models and beyond[J]. arXiv preprint arXiv: 2105.15082, 2021. doi: 10.48550/arXiv.2105.15082. [31] LEPIKHIN D, LEE H J, XU Yuanzhong, et al. GShard: Scaling giant models with conditional computation and automatic sharding[J]. arXiv preprint arXiv: 2006.16668, 2020. doi: 10.48550/arXiv.2006.16668. [32] ZOPH B, BELLO I, KUMAR S, et al. ST-MoE: Designing stable and transferable sparse expert models[J]. arXiv preprint arXiv: 2202.08906, 2022. doi: 10.48550/arXiv.2202.08906. [33] XUE Fuzhao, ZHENG Zian, FU Yao, et al. OpenMoE: An early effort on open mixture-of-experts language models[J]. arXiv preprint arXiv: 2402.01739, 2024. doi: 10.48550/arXiv.2402.01739. [34] SHEN Yikang, GUO Zhen, CAI Tianle, et al. JetMoE: Reaching Llama2 performance with 0.1M dollars[J]. arXiv preprint arXiv: 2404.07413, 2024. doi: 10.48550/arXiv.2404.07413. [35] CAI Weilin, JIANG Juyong, WANG Fan, et al. A survey on mixture of experts[J]. arXiv preprint arXiv: 2407.06204, 2025. doi: 10.48550/arXiv.2407.06204. [36] VATS A, RAJA R, JAIN V, et al. The evolution of MoE: A survey from basics to breakthroughs[J]. 2024. [37] PEI Zehua, ZOU Lancheng, ZHEN Huiling, et al. CMoE: Converting mixture-of-experts from dense to accelerate LLM inference[J]. arXiv preprint arXiv: 2502.04416, 2025. doi: 10.48550/arXiv.2502.04416. [38] ZHANG Xiaofeng, SHEN Yikang, HUANG Zeyu, et al. Mixture of attention heads: Selecting attention heads per token[J]. arXiv preprint arXiv: 2210.05144, 2022. doi: 10.48550/arXiv.2210.05144. [39] WANG K C, OSTASHEV D, FANG Yuwei, et al. MoA: Mixture-of-attention for subject-context disentanglement in personalized image generation[C]. SIGGRAPH Asia 2024 Conference Papers, Tokyo, Japan, 2024: 3. doi: 10.1145/3680528.3687662. [40] JIN Peng, ZHU Bo, YUAN Li, et al. MoH: Multi-head attention as mixture-of-head attention[J]. arXiv preprint arXiv: 2410.11842, 2025. doi: 10.48550/arXiv.2410.11842. [41] ZHANG Zhenyu, SHENG Ying, ZHOU Tianyi, et al. H2O: Heavy-hitter oracle for efficient generative inference of large language models[C]. Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 34661–34710. [42] ZANDIEH A, HAN I, MIRROKNI V, et al. SubGen: Token generation in sublinear time and memory[J]. arXiv preprint arXiv: 2402.06082, 2024. doi: 10.48550/arXiv.2402.06082. [43] DONG H, YANG Xinyu, ZHANG Zhangyang, et al. Get more with LESS: Synthesizing recurrence with KV cache compression for efficient LLM inference[J]. arXiv preprint arXiv: 2402.09398, 2024. doi: 10.48550/arXiv.2402.09398. [44] LU Enzhe, JIANG Zhejun, LIU Jingyuan, et al. MoBA: Mixture of block attention for long-context LLMs[J]. arXiv preprint arXiv: 2502.13189, 2025. doi: 10.48550/arXiv.2502.13189. [45] YUAN Jingyang, GAO Huazuo, DAI Damai, et al. Native sparse attention: Hardware-aligned and natively trainable sparse attention[J]. arXiv preprint arXiv: 2502.11089, 2025. doi: 10.48550/arXiv.2502.11089. [46] LU Xudong, LIU Qi, XU Yuhui, et al. Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models[J]. arXiv preprint arXiv: 2402.14800, 2024. doi: 10.48550/arXiv.2402.14800. [47] XIE Yanyue, ZHANG Zhi, ZHOU Ding, et al. MoE-Pruner: Pruning mixture-of-experts large language model using the hints from its router[J]. arXiv preprint arXiv: 2410.12013, 2024. doi: 10.48550/arXiv.2410.12013. [48] LIU Enshu, ZHU Junyi, LIN Zinan, et al. Efficient expert pruning for sparse mixture-of-experts language models: Enhancing performance and reducing inference costs[J]. arXiv preprint arXiv: 2407.00945, 2024. doi: 10.48550/arXiv.2407.00945. [49] ZHANG Zeliang, LIU Xiaodong, CHENG Hao, et al. Diversifying the expert knowledge for task-agnostic pruning in sparse mixture-of-experts[J]. arXiv preprint arXiv: 2407.09590, 2025. doi: 10.48550/arXiv.2407.09590. [50] CHOWDHURY M N R, WANG Meng, EL MAGHRAOUI K, et al. A provably effective method for pruning experts in fine-tuned sparse mixture-of-experts[J]. arXiv preprint arXiv: 2405.16646, 2024. doi: 10.48550/arXiv.2405.16646. [51] SARKAR S, LAUSEN L, CEVHER V, et al. Revisiting SMoE language models by evaluating inefficiencies with task specific expert pruning[J]. arXiv preprint arXiv: 2409.01483, 2024. doi: 10.48550/arXiv.2409.01483. [52] ZHUANG Yan, ZHENG Zhenzhe, WU Fan, et al. LiteMoE: Customizing on-device LLM serving via proxy submodel tuning[C]. Proceedings of the 22nd ACM Conference on Embedded Networked Sensor Systems, Hangzhou, China, 2024: 521–534. doi: 10.1145/3666025.3699355. [53] FRANTAR E and ALISTARH D. QMoE: Sub-1-Bit compression of trillion-parameter models[C]. Proceedings of the 5th MLSys Conference, Santa Clara, USA, 2024: 439–451. [54] TANG Peng, LIU Jiacheng, HOU Xiaofeng, et al. HOBBIT: A mixed precision expert offloading system for fast MoE inference[J]. arXiv preprint arXiv: 2411.01433, 2024. doi: 10.48550/arXiv.2411.01433. [55] KIM Y J, HENRY R, FAHIM R, et al. Who says Elephants can't run: Bringing large scale MoE models into cloud scale production[J]. arXiv preprint arXiv: 2211.10017, 2022. doi: 10.48550/arXiv.2211.10017. [56] KIM Y J, FAHIM R, and AWADALLA H H. Mixture of quantized experts (MoQE): Complementary effect of low-bit quantization and robustness[J]. arXiv preprint arXiv: 2310.02410, 2023. doi: 10.48550/arXiv.2310.02410. [57] HUANG Beichen, YUAN Yueming, SHAO Zelei, et al. MiLo: Efficient quantized MoE inference with mixture of low-rank compensators[J]. arXiv preprint arXiv: 2504.02658, 2025. doi: 10.48550/arXiv.2504.02658. [58] YANG Cheng, SUI Yang, XIAO Jinqi, et al. MoE-I2: Compressing mixture of experts models through inter-expert pruning and intra-expert low-rank decomposition[J]. arXiv preprint arXiv: 2411.01016, 2024. doi: 10.48550/arXiv.2411.01016. [59] GAO Zefeng, LIU Peiyu, ZHAO W X, et al. Parameter-efficient mixture-of-experts architecture for pre-trained language models[J]. arXiv preprint arXiv: 2203.01104, 2022. doi: 10.48550/arXiv.2203.01104. [60] GU Hao, LI Wei, LI Lujun, et al. Delta decompression for MoE-based LLMs compression[J]. arXiv preprint arXiv: 2502.17298, 2025. doi: 10.48550/arXiv.2502.17298. [61] FRANTAR E and ALISTARH D. SparseGPT: Massive language models can be accurately pruned in one-shot[C]. Proceedings of the 40th International Conference on Machine Learning, Honolulu, USA, 2023: 10323–10337. [62] MA Xinyin, FANG Gongfan, and WANG Xinchao. LLM-pruner: On the structural pruning of large language models[C]. Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 21702–21720. [63] XU Yuzhuang, HAN Xu, YANG Zonghan, et al. OneBit: Towards extremely low-bit large language models[J]. arXiv preprint arXiv: 2402.11295, 2024. doi: 10.48550/arXiv.2402.11295. [64] LIN Ji, TANG Jiaming, TANG Haotian, et al. AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration[C]. Proceedings of the 5th MLSys Conference, Santa Clara, USA, 2024: 87–100. [65] FRANTAR E, ASHKBOOS S, HOEFLER T, et al. GPTQ: Accurate post-training quantization for generative pre-trained transformers[EB/OL]. https://arxiv.org/abs/2210.17323, 2023. [66] KAUSHAL A, VAIDHYA T, and RISH I. LORD: Low rank decomposition of monolingual code LLMs for one-shot compression[J]. arXiv preprint arXiv: 2309.14021, 2023. doi: 10.48550/arXiv.2309.14021. [67] GOU Yunhao, LIU Zhili, CHEN Kai, et al. Mixture of cluster-conditional LoRA experts for vision-language instruction tuning[J]. arXiv preprint arXiv: 2312.12379, 2024. doi: 10.48550/arXiv.2312.12379. [68] MUSTAFA B, RIQUELME C, PUIGCERVER J, et al. Multimodal contrastive learning with LIMoE: The language-image mixture of experts[C]. Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 9564–9576. [69] HUANG Haiyang, ARDALANI N, SUN Anna, et al. Towards MoE deployment: Mitigating inefficiencies in mixture-of-expert (MoE) inference[J]. arXiv preprint arXiv: 2303.06182, 2023. doi: 10.48550/arXiv.2303.06182. [70] ZHONG Shuzhang, LIANG Ling, WANG Yuan, et al. AdapMoE: Adaptive sensitivity-based expert gating and management for efficient MoE inference[C]. Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, New York, USA, 2024: 51. doi: 10.1145/3676536.3676741. [71] ZHAI Mingshu, HE Jiaao, MA Zixuan, et al. SmartMoE: Efficiently training Sparsely-Activated models through combining offline and online parallelization[C]. 2023 USENIX Annual Technical Conference, Boston, USA, 2023: 961–975. [72] PAN Xinglin, LIN Wenxiang, ZHANG Lin, et al. FSMoE: A flexible and scalable training system for sparse mixture-of-experts models[C]. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, Rotterdam, Netherlands, 2025: 524–539. doi: 10.1145/3669940.3707272. [73] HE Jiaao, ZHAI Jidong, ANTUNES T, et al. FasterMoE: Modeling and optimizing training of large-scale dynamic pre-trained models[C]. Proceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Seoul, Republic of Korea, 2022: 120–134. doi: 10.1145/3503221.3508418. [74] HWANG C, CUI Wei, XIONG Yifan, et al. Tutel: Adaptive mixture-of-experts at scale[C]. Proceedings of the 6th MLSys Conference, Miami Beach, USA, 2023: 269–287. [75] JIANG Chenyu, TIAN Ye, JIA Zhen, et al. Lancet: Accelerating mixture-of-experts training via whole graph computation-communication overlapping[C]. Proceedings of the 7th MLSys Conference, Santa Clara, USA, 2024: 74–86. [76] LI Jiamin, JIANG Yimin, ZHU Yibo, et al. Accelerating distributed MoE training and inference with Lina[C]. 2023 USENIX Annual Technical Conference, Boston, USA, 2023: 945–959. [77] SHI Shaohuai, PAN Xinglin, CHU Xiaowen, et al. PipeMoE: Accelerating mixture-of-experts through adaptive pipelining[C]. IEEE INFOCOM 2023-IEEE Conference on Computer Communications, New York City, USA, 2023: 1–10. doi: 10.1109/infocom53939.2023.10228874. [78] WANG Hulin, XIA Yaqi, YANG Donglin, et al. Harnessing Inter-GPU shared memory for seamless MoE communication-computation fusion[C]. Proceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, Las Vegas, USA, 2025: 170–182. doi: 10.1145/3710848.3710868. [79] ZHANG Shulai, ZHENG Ningxin, LIN Haibin, et al. Comet: Fine-grained computation-communication overlapping for mixture-of-experts[J]. arXiv preprint arXiv: 2502.19811, 2025. doi: 10.48550/arXiv.2502.19811. [80] GO S and MAHAJAN D. MoETuner: Optimized mixture of expert serving with balanced expert placement and token routing[J]. arXiv preprint arXiv: 2502.06643, 2025. doi: 10.48550/arXiv.2502.06643. [81] HE Xin, ZHANG Shunkang, WANG Yuxin, et al. ExpertFlow: Optimized expert activation and token allocation for efficient mixture-of-experts inference[J]. arXiv preprint arXiv: 2410.17954, 2024. doi: 10.48550/arXiv.2410.17954. [82] ELISEEV A and MAZUR D. Fast inference of mixture-of-experts language models with offloading[J]. arXiv preprint arXiv: 2312.17238, 2023. doi: 10.48550/arXiv.2312.17238. [83] HWANG R, WEI Jianyu, CAO Shijie, et al. Pre-gated MoE: An algorithm-system co-design for fast and scalable mixture-of-expert inference[C]. 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), Buenos Aires, Argentina, 2024: 1018–1031. doi: 10.1109/isca59077.2024.00078. [84] DU Zhixu, LI Shiyu, WU Yuhao, et al. SIDA: Sparsity-inspired data-aware serving for efficient and scalable large mixture-of-experts models[C]. Proceedings of the 7th MLSys Conference, Santa Clara, USA, 2024: 224–238. [85] SONG Xiaoniu, ZHONG Zihang, and CHEN Rong. ProMoE: Fast MoE-based LLM serving using proactive caching[J]. arXiv preprint arXiv: 2410.22134, 2025. doi: 10.48550/arXiv.2410.22134. [86] WEI Yuanxin, DU Jiangsu, JIANG Jiazhi, et al. APTMoE: Affinity-Aware pipeline tuning for MoE models on bandwidth-constrained GPU nodes[C]. SC24: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, USA, 2024: 1–14. doi: 10.1109/sc41406.2024.00096. [87] FANG Zhiyuan, HUANG Yuegui, HONG Zicong, et al. KLOTSKI: Efficient mixture-of-expert inference via expert-aware multi-batch pipeline[C]. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, Rotterdam, Netherlands, 2025: 574–588. doi: 10.1145/3676641.3716261. [88] ZHANG Yujie, AGGARWAL S, and MITRA T. DAOP: Data-aware offloading and predictive pre-calculation for efficient MoE inference[C]. 2025 Design, Automation & Test in Europe Conference (DATE), Lyon, France, 2025: 1–7. doi: 10.23919/DATE64628.2025.10992741. [89] CAO Shiyi, LIU Shu, GRIGGS T, et al. MoE-Lightning: High-throughput MoE inference on memory-constrained GPUs[C]. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, Rotterdam, Netherlands, 2025: 715–730. doi: 10.1145/3669940.3707267. [90] KAMAHORI K, TANG Tian, GU Yile, et al. Fiddler: CPU-GPU orchestration for fast inference of mixture-of-experts models[J]. arXiv preprint arXiv: 2402.07033, 2025. doi: 10.48550/arXiv.2402.07033. [91] ZHONG Shuzhang, SUN Yanfan, LIANG Ling, et al. HybriMoE: Hybrid CPU-GPU scheduling and cache management for efficient MoE inference[J]. arXiv preprint arXiv: 2504.05897, 2025. doi: 10.48550/arXiv.2504.05897. [92] NVIDIA. NCCL[EB/OL]. https://developer.nvidia.com/n-ccl, 2025. [93] XU Yuanzhong, LEE H J, CHEN Dehao, et al. GSPMD: General and scalable parallelization for ML computation graphs[J]. arXiv preprint arXiv: 2105.04663, 2021. doi: 10.48550/arXiv.2105.04663. [94] NVIDIA. NVSHMEM[EB/OL]. https://docs.nvi-dia.com/nvshmem/api/, 2025. [95] PUNNIYAMURTHY K, HAMIDOUCHE K, and BECKMANN B M. Optimizing distributed ML communication with fused computation-collective operations[C]. SC24: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, USA, 2024: 1–17. doi: 10.1109/sc41406.2024.00094. [96] YU Dianhai, SHEN Liang, HAO Hongxiang, et al. MoESys: A distributed and efficient mixture-of-experts training and inference system for internet services[J]. IEEE Transactions on Services Computing, 2024, 17(5): 2626–2639. doi: 10.1109/tsc.2024.3399654. [97] GALE T, NARAYANAN D, YOUNG C, et al. MegaBlocks: Efficient sparse training with mixture-of-experts[C]. Proceedings of the 6th MLSys Conference, Miami Beach, USA, 2023: 288–304. [98] NVIDIA. cuBLAS[EB/OL]. https://developer.nvidia.co-m/cublas, 2025. [99] CAI Zixian, LIU Zhengyang, MALEKI S, et al. Synthesizing optimal collective algorithms[C]. Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Virtual Event, 2021: 62–75. doi: 10.1145/3437801.3441620. [100] ZENG Zhiyuan and XIONG Deyi. SCoMoE: Efficient mixtures of experts with structured communication[C]. The Eleventh International Conference on Learning Representations, Kigali, Rwanda, 2023. [101] SUO Jiashun, LIAO Xiaojian, XIAO Limin, et al. CoServe: Efficient Collaboration-of-Experts (CoE) model inference with limited memory[C]. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, Rotterdam, Netherlands, 2025: 178–191. doi: 10.1145/3676641.3715986. [102] CAI Weilin, QIN Le, and HUANG Jiayi. MoC-System: Efficient fault tolerance for sparse mixture-of-experts model training[C]. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, Rotterdam, Netherlands, 2025: 655–671. doi: 10.1145/3676641.3716006. [103] KOSSMANN F, JIA Zhihao, and AIKEN A. Optimizing mixture of experts using dynamic recompilations[J]. arXiv preprint arXiv: 2205.01848, 2022. doi: 10.48550/arXiv.2205.01848. [104] LI Yinghan, LI Yifei, ZHANG Jiejing, et al. Static batching of irregular workloads on GPUs: Framework and application to efficient MoE model inference[J]. arXiv preprint arXiv: 2501.16103, 2025. doi: 10.48550/arXiv.2501.16103. [105] LMDeploy Contributors. LMDeploy: A toolkit for compressing, deploying, and serving LLM[EB/OL]. https://github.com/InternLM/lmdeploy, 2023. [106] KWON W, LI Zhouhan, ZHUANG Siyuan, et al. Efficient memory management for large language model serving with PagedAttention[C]. Proceedings of the 29th Symposium on Operating Systems Principles, Koblenz, Germany, 2023: 611–626. doi: 10.1145/3600006.3613165. [107] ZHENG Lianmin, YIN Liangsheng, XIE Zhiqiang, et al. SGLang: Efficient execution of structured language model programs[C]. Proceedings of the 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2025: 62557–62583. [108] KVCache-AI. A flexible framework for experiencing cutting-edge LLM inference optimizations[EB/OL]. https://github.com/kvcache-ai/ktransformers, 2025. [109] LIU Jiacheng, TANG Peng, WANG Wenfeng, et al. A survey on inference optimization techniques for mixture of experts models[J]. arXiv preprint arXiv: 2412.14219, 2025. doi: 10.48550/arXiv.2412.14219. [110] DONG Jiale, LOU Wenqi, ZHENG Zhendong, et al. UbiMoE: A ubiquitous mixture-of-experts vision transformer accelerator with hybrid computation pattern on FPGA[J]. arXiv preprint arXiv: 2502.05602, 2025. doi: 10.48550/arXiv.2502.05602. [111] PARK G, SONG S, SANG Haoyang, et al. 20.8 space-mate: A 303.5mW real-time sparse mixture-of-experts-based NeRF-SLAM processor for mobile spatial computing[C]. 2024 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, USA, 2024: 374–376. doi: 10.1109/isscc49657.2024.10454487. [112] LIN Xuanda, TIAN Huinan, XUE Wenxiao, et al. FLAME: Fully leveraging MoE sparsity for transformer on FPGA[C]. Proceedings of the 61st ACM/IEEE Design Automation Conference, San Francisco, USA, 2024: 248. doi: 10.1145/3649329.3656507. [113] SARKAR R, LIANG Hanxue, FAN Zhiwen, et al. Edge-MoE: Memory-efficient multi-task vision transformer architecture with task-level sparsity via mixture-of-experts[C]. 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), San Francisco, USA, 2023: 1–9. doi: 10.1109/iccad57390.2023.10323651. [114] LIANG Hanxue, FAN Zhiwen, SARKAR R, et al. M3ViT: Mixture-of-experts vision transformer for efficient multi-task learning with model-accelerator co-design[C]. Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 28441–28457. [115] HE Siqi, ZHU Haozhe, ZHENG Jiapei, et al. Hydra: Harnessing expert popularity for efficient mixture-of-expert inference on Chiplet system[C]. Proceedings of the 62nd ACM/IEEE Design Automation Conference (DAC), San Francisco, USA, 2025: 1–6. [116] KIM T, CHOI K, CHO Y, et al. MoNDE: Mixture of near-data experts for large-scale sparse models[C]. Proceedings of the 61st ACM/IEEE Design Automation Conference, San Francisco, USA, 2024: 221. doi: 10.1145/3649329.3655951. [117] YUN S, KYUNG K, CHO J, et al. Duplex: A device for large language models with mixture of experts, grouped query attention, and continuous batching[C]. 2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), Austin, USA, 2024: 1429–1443. doi: 10.1109/micro61859.2024.00105. [118] WU Lizhou, ZHU Haozhe, HE Siqi, et al. PIMoE: Towards efficient MoE transformer deployment on NPU-PIM system through throttle-aware task offloading[C]. Proceedings of the 62nd ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 2025: 1–6. [119] Microsoft. ONNX Runtime[EB/OL]. https://onnx-runtime.ai/, 2025. [120] LEE S, KANG S H, LEE J, et al. Hardware architecture and software stack for PIM based on commercial DRAM technology: Industrial product[C]. 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 2021: 43–56. doi: 10.1109/isca52012.2021.00013. [121] GU A and DAO T. Mamba: Linear-time sequence modeling with selective state spaces[J]. arXiv preprint arXiv: 2312.00752, 2024. doi: 10.48550/arXiv.2312.00752. [122] NIE Xiaonan, LIU Qibin, FU Fangcheng, et al. LSH-MoE: Communication-efficient MoE training via locality-sensitive hashing[C]. Proceedings of the 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2025: 54161–54182. [123] SINGH S, RUWASE O, AWAN A A, et al. A hybrid tensor-expert-data parallelism approach to optimize mixture-of-experts training[C]. Proceedings of the 37th International Conference on Supercomputing, Orlando, USA, 2023: 203–214. doi: 10.1145/3577193.3593704. [124] SHI Shaohuai, PAN Xinglin, WANG Qiang, et al. ScheMoE: An extensible mixture-of-experts distributed training system with tasks scheduling[C]. Proceedings of the Nineteenth European Conference on Computer Systems, Athens, Greece, 2024: 236–249. doi: 10.1145/3627703.3650083. [125] PRABHAKAR R, SIVARAMAKRISHNAN R, GANDHI D, et al. SambaNova SN40L: Scaling the AI memory wall with dataflow and composition of experts[C]. 2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), Austin, USA, 2024: 1353–1366. doi: 10.1109/micro61859.2024.00100. [126] YAO Jinghan, ANTHONY Q, SHAFI A, et al. Exploiting inter-layer expert affinity for accelerating mixture-of-experts model inference[C]. 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS), San Francisco, USA, 2024: 915–925. doi: 10.1109/ipdps57955.2024.00086. [127] YU Hanfei, CUI Xingqi, ZHANG Hong, et al. fMoE: Fine-grained expert offloading for large mixture-of-experts serving[J]. arXiv preprint arXiv: 2502.05370, 2025. doi: 10.48550/arXiv.2502.05370. [128] FANG Zhiyuan, HONG Zicong, HUANG Yuegui, et al. Fate: Fast edge inference of mixture-of-experts models via cross-layer gate[J]. arXiv preprint arXiv: 2502.12224, 2025. doi: 10.48550/arXiv.2502.12224. [129] QIAN Yulei, LI Fengcun, JI Xiangyang, et al. EPS-MoE: Expert pipeline scheduler for cost-efficient MoE inference[J]. arXiv preprint arXiv: 2410.12247, 2025. doi: 10.48550/arXiv.2410.12247. [130] SKLIAR A, VAN ROZENDAAL T, LEPERT R, et al. Mixture of cache-conditional experts for efficient mobile device inference[J]. arXiv preprint arXiv: 2412.00099, 2025. doi: 10.48550/arXiv.2412.00099. [131] CHEN Xin, ZHANG Hengheng, GU Xiaotao, et al. Pipeline MoE: A flexible MoE implementation with pipeline parallelism[J]. arXiv preprint arXiv: 2304.11414, 2023. doi: 10.48550/arXiv.2304.11414. [132] NIE Xiaonan, MIAO Xupeng, WANG Zilong, et al. FlexMoE: Scaling large-scale sparse pre-trained model training via dynamic device placement[J]. Proceedings of the ACM on Management of Data, 2023, 1(1): 110. doi: 10.1145/3588964. [133] YUAN Yichao, MA Lin, and TALATI N. MoE-Lens: Towards the hardware limit of high-throughput MoE LLM serving under resource constraints[J]. arXiv preprint arXiv: 2504.09345, 2025. doi: 10.48550/arXiv.2504.09345. [134] ZHANG Mohan, LI Pingzhi, PENG Jie, et al. Advancing MoE efficiency: A collaboration-constrained routing (C2R) strategy for better expert parallelism design[J]. arXiv preprint arXiv: 2504.01337, 2025. doi: 10.48550/arXiv.2504.01337. [135] LUO Shuqing, PENG Jie, LI Pingzhi, et al. HEXA-MoE: Efficient and heterogeneous-aware training for mixture-of-experts[J]. arXiv preprint arXiv: 2411.01288, 2025. doi: 10.48550/arXiv.2411.01288. [136] TAIRIN S, MAHMUD S, SHEN Haiying, et al. eMoE: Task-aware memory efficient mixture-of-experts-based (MoE) model inference[J]. arXiv preprint arXiv: 2503.06823, 2025. doi: 10.48550/arXiv.2503.06823. [137] ZHU Ruidong, JIANG Ziheng, JIN Chao, et al. MegaScale-Infer: Serving mixture-of-experts at scale with disaggregated expert parallelism[J]. arXiv preprint arXiv: 2504.02263, 2025. doi: 10.48550/arXiv.2504.02263. [138] XUE Leyang, FU Yao, LU Zhan, et al. MoE-infinity: Offloading-efficient MoE model serving[J]. arXiv preprint arXiv: 2401.14361, 2025. doi: 10.48550/arXiv.2401.14361. [139] WU Chenpeng, GU Qiqi, SHI Heng, et al. Samoyeds: Accelerating MoE models with structured sparsity leveraging sparse tensor cores[C]. Proceedings of the Twentieth European Conference on Computer Systems, Rotterdam, Netherlands, 2025: 293–310. doi: 10.1145/3689031.3717455. [140] LI Zhiyao, YANG Bohan, LI Jiaxiang, et al. Adyna: Accelerating dynamic neural networks with adaptive scheduling[C]. 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), Las Vegas, USA, 2025: 549–562. doi: 10.1109/hpca61900.2025.00049. [141] Bytedance. Flux[EB/OL]. https://github.com/byte-dance/flux, 2025. [142] LIAN Yaoxiu, GOU Zhihong, HAN Yibo, et al. A cross-model fusion-aware framework for optimizing (gather-matmul-scatter)s workload[C]. Proceedings of the 62nd ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 2025: 1–6. [143] XUE Fuzhao, HE Xiaoxin, REN Xiaozhe, et al. One student knows all experts know: From sparse to dense[C]. The Eleventh International Conference on Learning Representations (ICLR), Kigali, Rwanda, 2023. [144] CERON J S O, SOKAR G, WILLI T, et al. Mixtures of experts unlock parameter scaling for deep RL[C]. Proceedings of the 41st International Conference on Machine Learning, Vienna, Austria, 2024: 38520–38540. [145] ZHENG Zhen, PAN Zaifeng, WANG Dalin, et al. BladeDISC: Optimizing dynamic shape machine learning workloads via compiler approach[J]. Proceedings of the ACM on Management of Data, 2023, 1(3): 206. doi: 10.1145/3617327. [146] NVIDIA. Megatron-LM[EB/OL]. https://github.com/NVIDIA/Megatron-LM, 2023. [147] NVIDIA. TensorRT-LLM[EB/OL]. https://github.com/NVIDIA/TensorRT-LLM, 2025. [148] InternLM. LMDeploy. [EB/OL]. https://github.com/InternLM/lmdeploy, 2023. [149] GGML. llama. cpp[EB/OL]. https://github.com/ggml-org/llama.cpp, 2024. [150] DeepSeek-AI. DeepEP: An efficient expert-parallel communication library[EB/OL]. https://github.com/deepseek-ai/DeepEP, 2025. [151] DeepSeek-AI. Expert parallelism load balancer[EB/OL]. https://github.com/deepseek-ai/EPLB, 2025. [152] SANSEVIERO O, TUNSTALL L, SCHMID P, et al. Mixture of experts explained[EB/OL]. https://huggingface.co/blog/moe, 2023. [153] Facebook Al Research. Sequence-to-sequence toolkit written in python[EB/OL]. https://github.com/facebookresearch/fairseq, 2021. [154] NLLB Team, COSTA-JUSSÀ M R, CROSS J, et al. No language left behind: Scaling human-centered machine translation[J]. arXiv preprint arXiv: 2207.04672, 2022. doi: 10.48550/arXiv.2207.04672. [155] YANG An, YANG Baosong, HUI Binyuan, et al. Qwen2 technical report[J]. arXiv preprint arXiv: 2407.10671v4, 2024. doi: 10.48550/arXiv.2407.10671. [156] Qwen Team. Qwen1.5-MoE: Matching 7B model performance with 1/3 activated parameters[EB/OL]. https://qwenlm.github.io/blog/qwen-moe/, 2024. [157] The Mosaic Research Team. Introducing DBRX: A New State-of-the-Art Open LLM[EB/OL]. https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm, 2024. [158] Snowflake Team. Arctic: Open, efficient foundation language models from snowflake[EB/OL]. https://www.snowflake.com/en/blog/arctic-open-efficient-foundation-language-models-snowflake, 2024. [159] DeepSeek-AI. DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model[J]. arXiv preprint arXiv: 2405.04434, 2024. doi: 10.48550/arXiv.2405.04434. [160] WEI Tianwen, ZHU Bo, ZHAO Liang, et al. Skywork-MoE: A deep dive into training techniques for mixture-of-experts language models[J]. arXiv preprint arXiv: 2406.06563, 2024. doi: 10.48550/arXiv.2406.06563. [161] WU Shaohua, LUO Jiangang, CHEN Xi, et al. Yuan 2.0-M32: Mixture of experts with attention router[J]. arXiv preprint arXiv: 2405.17976, 2024. doi: 10.48550/arXiv.2405.17976. [162] ZHU Tong, QU Xiaoye, DONG Daize, et al. LLaMA-MoE: Building mixture-of-experts from LLaMA with continual pre-training[J]. arXiv preprint arXiv: 2406.16554, 2024. doi: 10.48550/arXiv.2406.16554. [163] MUENNIGHOFF N, SOLDAINI L, GROENEVELD D, et al. OLMoE: Open mixture-of-experts language models[J]. arXiv preprint arXiv: 2409.02060, 2025. doi: 10.48550/arXiv.2409.02060. [164] LIU Liyuan, KIM Y J, WANG Shuohang, et al. GRIN: GRadient-INformed MoE[J]. arXiv preprint arXiv: 2409.12136, 2024. doi: 10.48550/arXiv.2409.12136. [165] SUN Xingwu, CHEN Yanfeng, HUANG Yiqing, et al. Hunyuan-Large: An open-source MoE model with 52 billion activated parameters by tencent[J]. arXiv preprint arXiv: 2411.02265, 2024. doi: 10.48550/arXiv.2411.02265. [166] MiniMax. MiniMax-01: Scaling foundation models with lightning attention[J]. arXiv preprint arXiv: 2501.08313, 2025. doi: 10.48550/arXiv.2501.08313. [167] LIU Jingyuan, SU Jianlin, YAO Xingcheng, et al. Muon is scalable for LLM training[J]. arXiv preprint arXiv: 2502.16982, 2025. doi: 10.48550/arXiv.2502.16982. [168] Meta-AI. LLaMA4[EB/OL]. https://www.llama.com/models/llama-4/, 2025. [169] YANG An, LI Anfeng, YANG Baosong, et al. Qwen3 technical report[J]. arXiv preprint arXiv: 2505.09388, 2025. doi: 10.48550/arXiv.2505.09388. [170] TIAN Changxin, CHEN Kunlong, LIU Jia, et al. Towards greater leverage: Scaling laws for efficient mixture-of-experts language models[J]. arXiv preprint arXiv: 2507.17702, 2025. doi: 10.48550/arXiv.2507.17702. [171] HUANG Quzhe, AN Zhenwei, ZHUANG Nan, et al. Harder tasks need more experts: Dynamic routing in MoE models[J]. arXiv preprint arXiv: 2403.07652, 2024. doi: 10.48550/arXiv.2403.07652. [172] KUNWAR P, VU M N, GUPTA M, et al. TT-LoRA MoE: Unifying parameter-efficient fine-tuning and sparse mixture-of-experts[J]. arXiv preprint arXiv: 2504.21190, 2025. doi: 10.48550/arXiv.2504.21190. [173] WANG Junlin, WANG Jue, ATHIWARATKUN B, et al. Mixture-of-agents enhances large language model capabilities[J]. arXiv preprint arXiv: 2406.04692, 2024. doi: 10.48550/arXiv.2406.04692. [174] YUN S, PARK S, NAM H, et al. The new LLM bottleneck: A systems perspective on latent attention and mixture-of-experts[J]. arXiv preprint arXiv: 2507.15465, 2025. doi: 10.48550/arXiv.2507.15465. [175] AL MARUF H, WANG Hao, DHANOTIA A, et al. TPP: Transparent page placement for CXL-enabled tiered-memory[C]. Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, Vancouver, Canada, 2023: 742–755. doi: 10.1145/3582016.3582063. [176] ZHOU Zhe, CHEN Yiqi, ZHANG Tao, et al. NeoMem: Hardware/software co-design for CXL-native memory tiering[C]. 2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), Austin, USA: IEEE, 2024: 1518–1531. doi: 10.1109/MICRO61859.2024.00111. [177] JIN Chao, JIANG Ziheng, BAI Zhihao, et al. MegaScale-MoE: Large-scale communication-efficient training of mixture-of-experts models in production[J]. arXiv preprint arXiv: 2505.11432, 2025. doi: 10.48550/arXiv.2505.11432. -

 下载:
下载:



图(8) / 表(4)
计量
- 文章访问数: 3442
- HTML全文浏览量: 2596
- PDF下载量: 574
- 被引次数: 0
