

Edge Network Data Scheduling Optimization Method Integrating Improved Jaya and Cluster Center Selection Algorithm
-
摘要: 在智能化浪潮与数据激增的推动下,物联网设备、传感器及智能终端数量迅速增长,传统集中式网络与云计算架构在带宽、延迟与存储等方面面临严峻挑战。边缘计算作为一种将计算与存储资源部署至靠近用户的网络边缘的新型计算范式,成为应对大规模数据处理与低时延需求的有效解决方案。然而,如何在边缘计算环境下应对数据密集型业务带来的挑战,合理划分边缘节点集群并优化资源调度,成为关键问题。为此,该文提出一种融合改进Jaya和集群中心选择算法的边缘网络数据调度优化方法,针对数据密集型业务,将业务所涉及到的边缘节点划分集群,选择出集群中心,以集群为单位,将边缘节点的数据先汇聚到多个集群中心,再通过集群中心进一步上传到云端,实现边缘网络数据资源的调度和优化管理。首先通过对传统Jaya算法进行改进,引入非线性衰减策略和构建多阶段搜索策略,提升路径规划的全局搜索能力与局部精细调整能力,从而求解边缘节点间的最短路径。在此基础上,提出优化集群中心选择算法,综合考虑最短路径和可用网络资源,选择通信与资源条件最优的节点作为集群中心,并为每个集群中心划分集群成员,构建合理的边缘网络集群结构。实验结果表明,改进后的Jaya算法在收敛速度与寻优精度方面均优于对比算法,所提集群中心选择方法表现出良好的鲁棒性,并且验证了该方法在边缘计算场景资源调度中的可行性与有效性。Abstract:
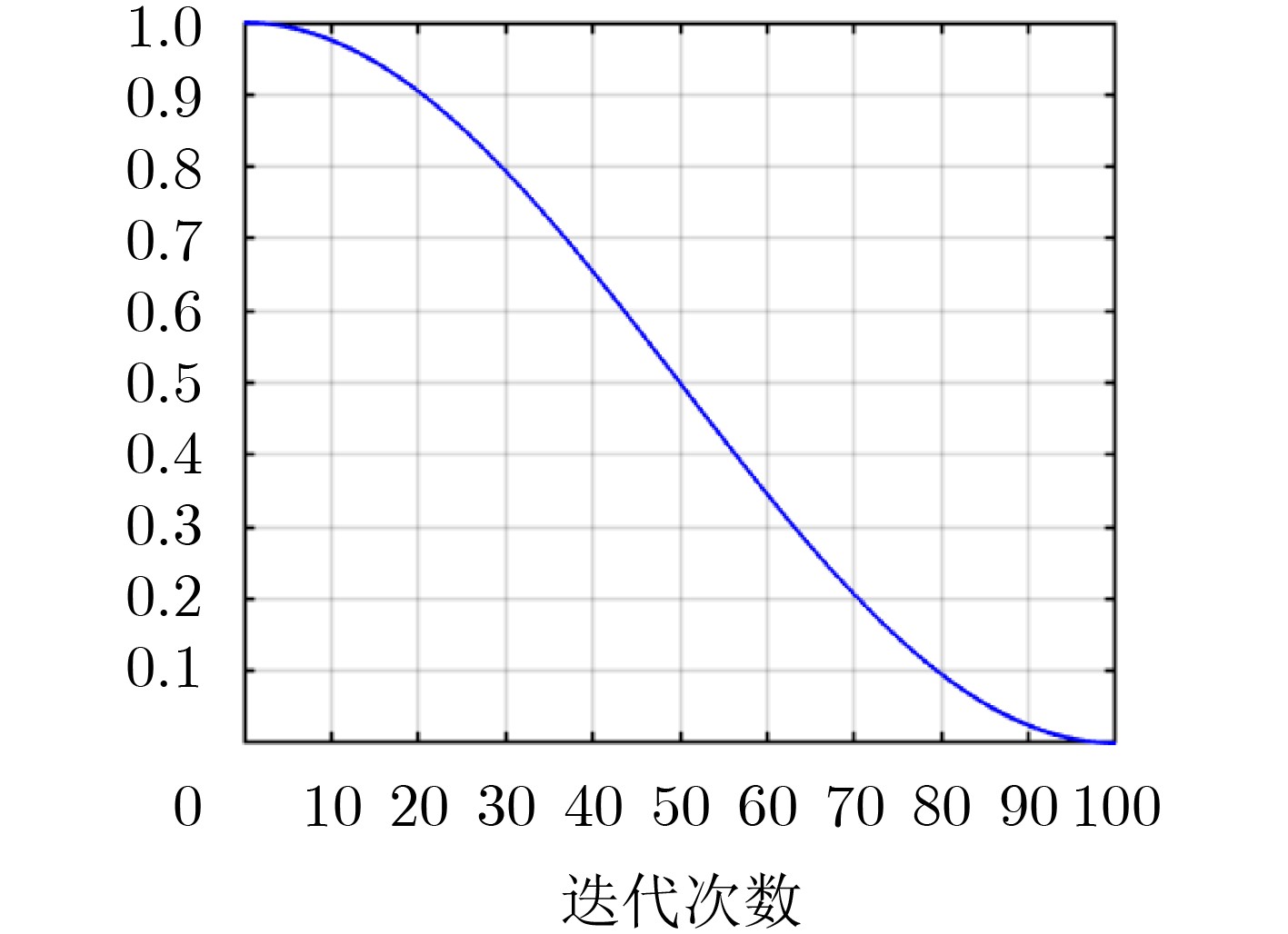
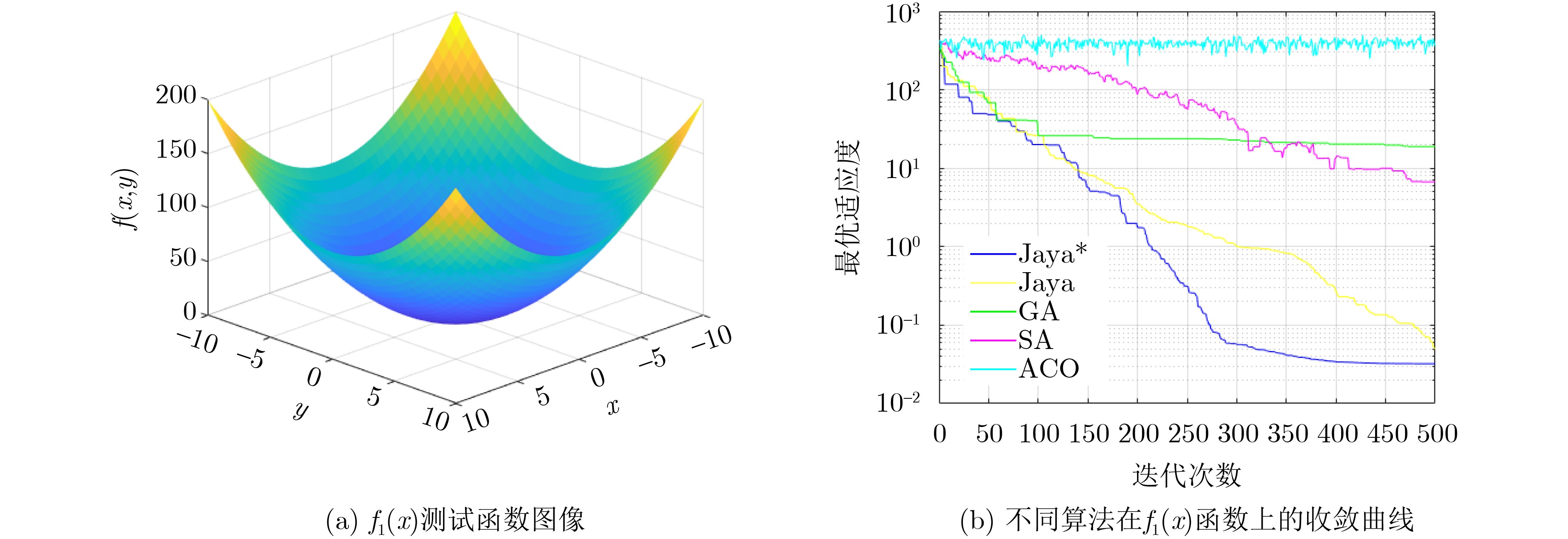
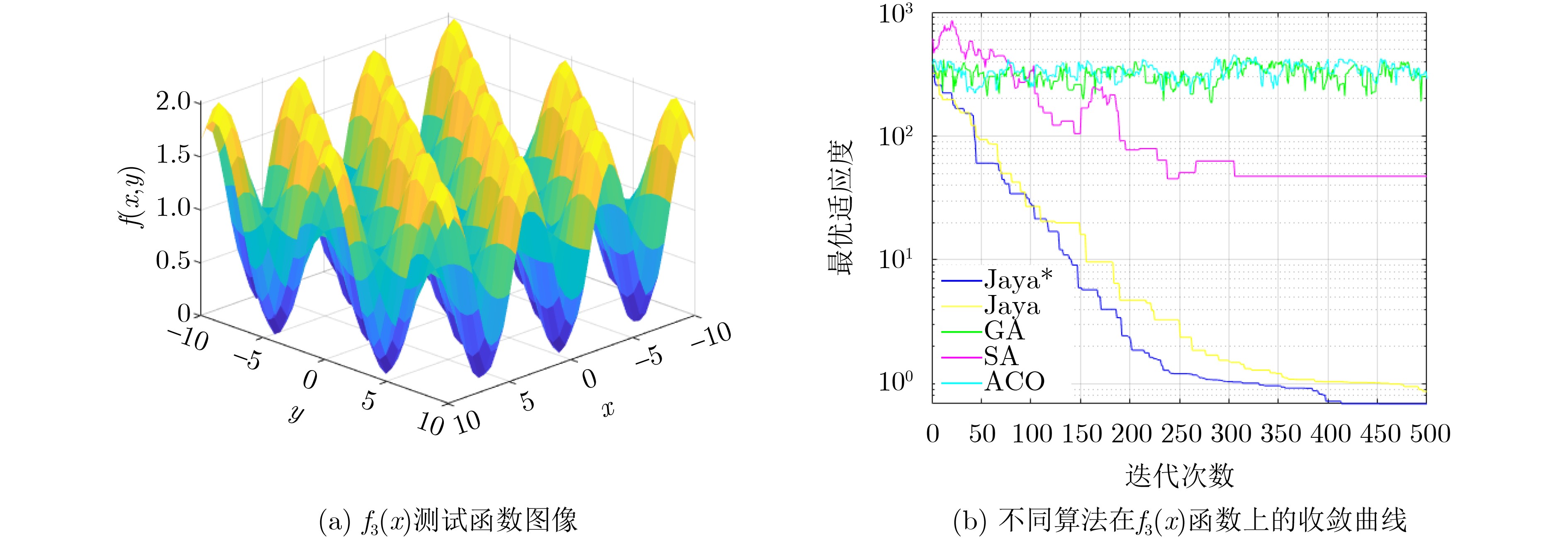
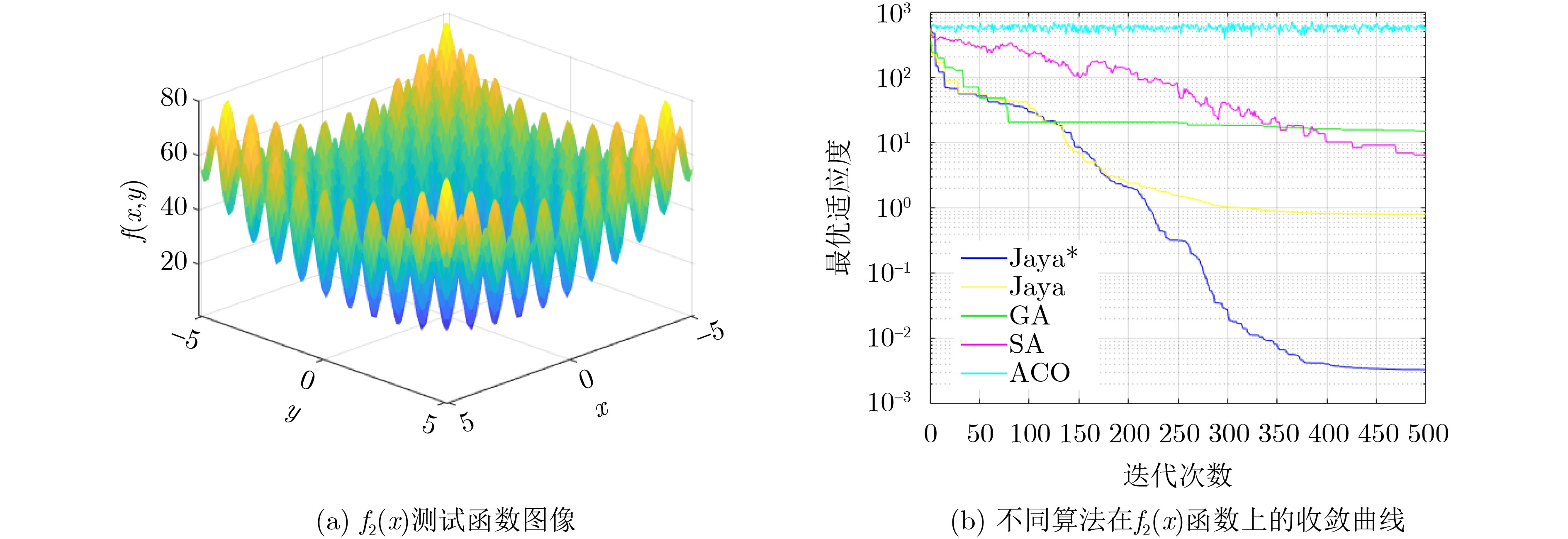
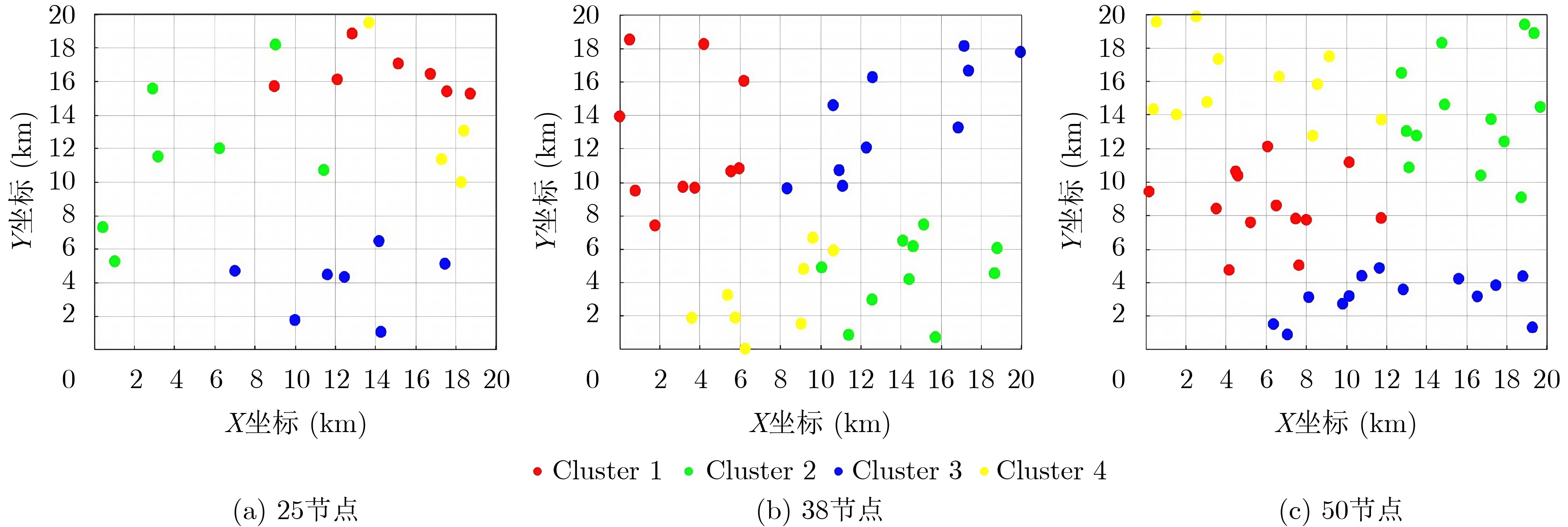
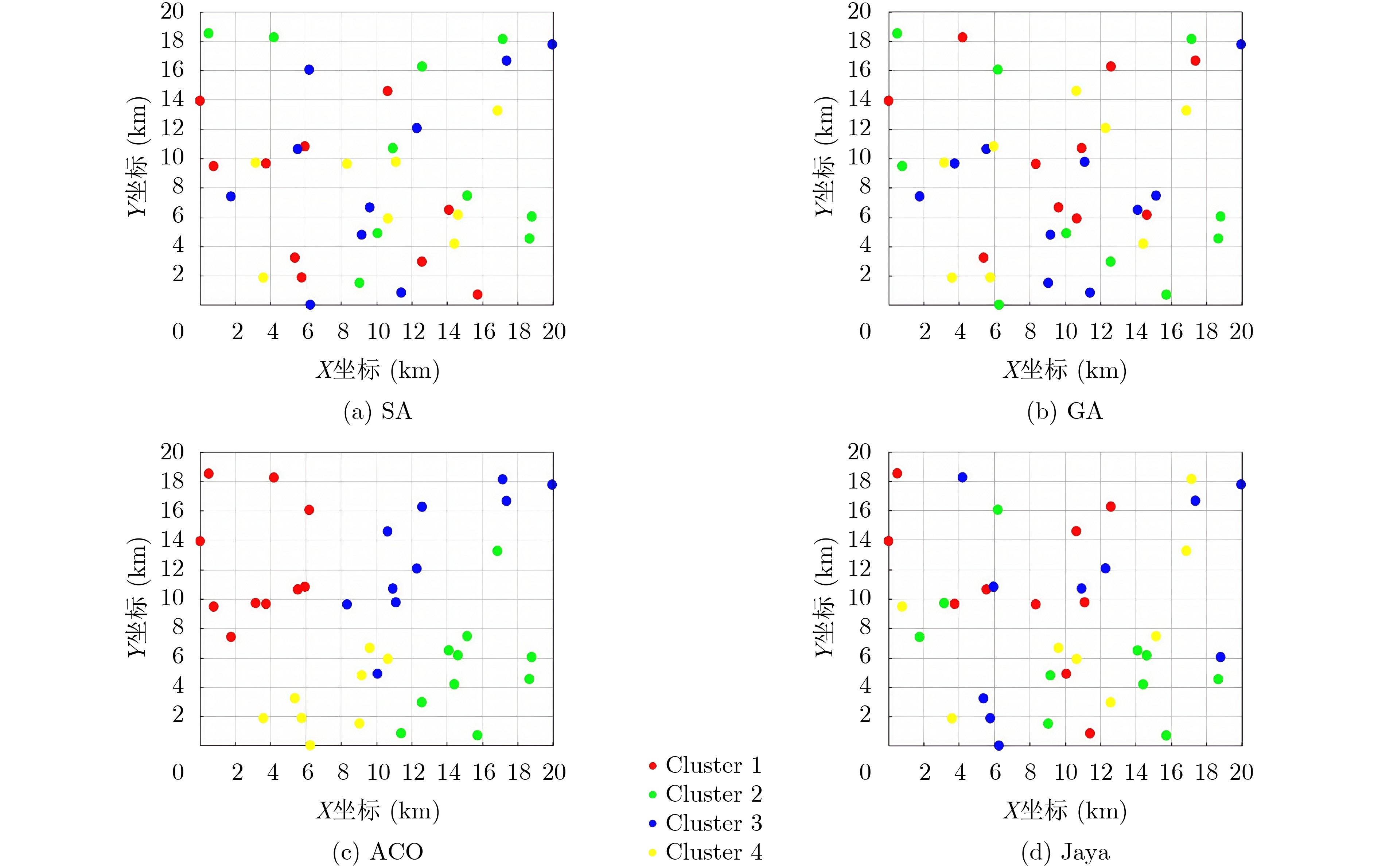
Objective The rapid advancement of technologies such as artificial intelligence and the Internet of Things has placed increasing strain on traditional centralized cloud computing architectures, which struggle to meet the communication and computational demands of large-scale data processing. Due to the physical separation between cloud servers and end-users, data transmission typically incurs considerable latency and energy consumption. Therefore, edge computing—by deploying computing and storage resources closer to users, has emerged as a viable paradigm for supporting data-intensive and latency-sensitive applications. However, effectively addressing the challenges of data-intensive services in edge computing environments, such as efficient edge node clustering and resource scheduling, remains a key issue. This study proposes a data scheduling optimization method for edge networks that integrates an improved Jaya algorithm with a cluster center selection strategy. Specifically, for data-intensive services, the method partitions edge nodes into clusters and identifies optimal cluster centers. Data are first aggregated at these centers before being transmitted to the cloud. By leveraging cluster-based aggregation, the method facilitates more efficient data scheduling and improved resource management in edge environments. Methods The proposed edge network data scheduling optimization method comprises two core components: a shortest-path selection algorithm based on an improved Jaya algorithm and an optimal cluster center selection algorithm. The scheduling framework accounts for both the shortest communication paths among edge nodes and the availability of network resources. The improved Jaya algorithm incorporates a cosine-based nonlinear decay function and a multi-stage search strategy to dynamically optimize inter-node paths. The nonlinear decay function modulates the variation of random factors across iterations, allowing adaptive adjustment of the algorithm’s exploration capacity. This mechanism helps prevent premature convergence and reduces the likelihood of becoming trapped in local optima during the later optimization stages. To further enhance performance, a multi-stage search strategy divides the optimization process into two phases: an exploration phase during early iterations, which prioritizes global search across the solution space, and an exploitation phase during later iterations, which refines solutions locally. This staged approach improves the trade-off between convergence speed and solution accuracy, increasing the algorithm’s robustness in complex edge network environments. Based on the optimized paths and available bandwidth, a criterion is established for selecting the initial cluster center. Subsequently, a selection scheme for additional cluster centers is formulated by evaluating inter-cluster center distances. Finally, a partitioning method assigns edge nodes to their respective clusters based on the optimized topology. Results and Discussions The simulation experiments comprise two parts: performance evaluation of the improved Jaya algorithm (Jaya*) and analysis of the cluster partitioning scheme. To assess convergence speed and optimization accuracy, three benchmark test functions are used to compare Jaya* with four existing algorithms: Simulated Annealing (SA), Genetic Algorithm (GA), Ant Colony Optimization (ACO), and the standard Jaya algorithm. Building on these results, two additional experiments—cluster center selection and cluster partitioning—are conducted to evaluate the feasibility and effectiveness of the proposed optimal cluster center selection algorithm for resource scheduling. A parameter sensitivity analysis using the multi-modal Rastrigin function is performed to investigate the effects of different population sizes and maximum iteration counts on optimization accuracy and stability ( Table 2 andTable 3 ). The optimal configuration is determined to be $ {\text{po}}{{\text{p}}_{{\text{size}}}} = 50 $ and $ {t_{\max }} = 500 $, which achieves a favorable balance between accuracy and computational efficiency. Subsequently, a multi-algorithm comparison experiment is carried out under consistent conditions. The improved Jaya algorithm outperforms the four alternatives in convergence speed and optimization accuracy across three standard functions: Sphere (Fig. 4 ), Rastrigin (Fig. 5 ), and Griewank (Fig. 6 ). The algorithm also demonstrates superior stability. Its convergence trajectory is characterized by a rapid initial decline followed by gradual stabilization in later stages. Based on these findings, the cluster center selection algorithm is applied to tactical edge networks of varying scales—25, 38, and 50 nodes (Fig. 7 ). The parameter mi is calculated (Fig. 8 ), and various numbers of cluster centers are set to complete center selection and cluster member assignment (Table 5 ). Evaluation using the Average Sum of Squared Errors (AvgSSE) under different cluster center counts reveals that the minimum AvgSSE for all three network sizes occurs when the number of cluster centers is 4 (Table 6 ), indicating that this configuration yields the optimal clustering outcome. Therefore, the proposed method effectively selects cluster centers and derives the optimal clustering configuration (Fig. 9 ), while maintaining low clustering error and enhancing the efficiency and accuracy of resource scheduling. Finally, in a 38-node edge network scenario with four cluster centers, a multi-algorithm cluster partitioning comparison is conducted (Table 7 ). The improved Jaya algorithm achieves the best AvgSSE result of 16.22, significantly outperforming the four baseline algorithms. These results demonstrate its superiority in convergence precision and global search capability.Conclusions To address data resource scheduling challenges in edge computing environments, this study proposes an edge network data scheduling optimization method that integrates an improved Jaya algorithm with a cluster center selection strategy. The combined approach achieves high clustering accuracy, robustness, and generalization performance. It effectively enhances path planning precision and central node selection, leading to improved data transmission performance and resource utilization in edge networks. -
Key words:
- Edge network /
- Data scheduling /
- Data aggregation /
- Cluster center selection /
- Path planning
-
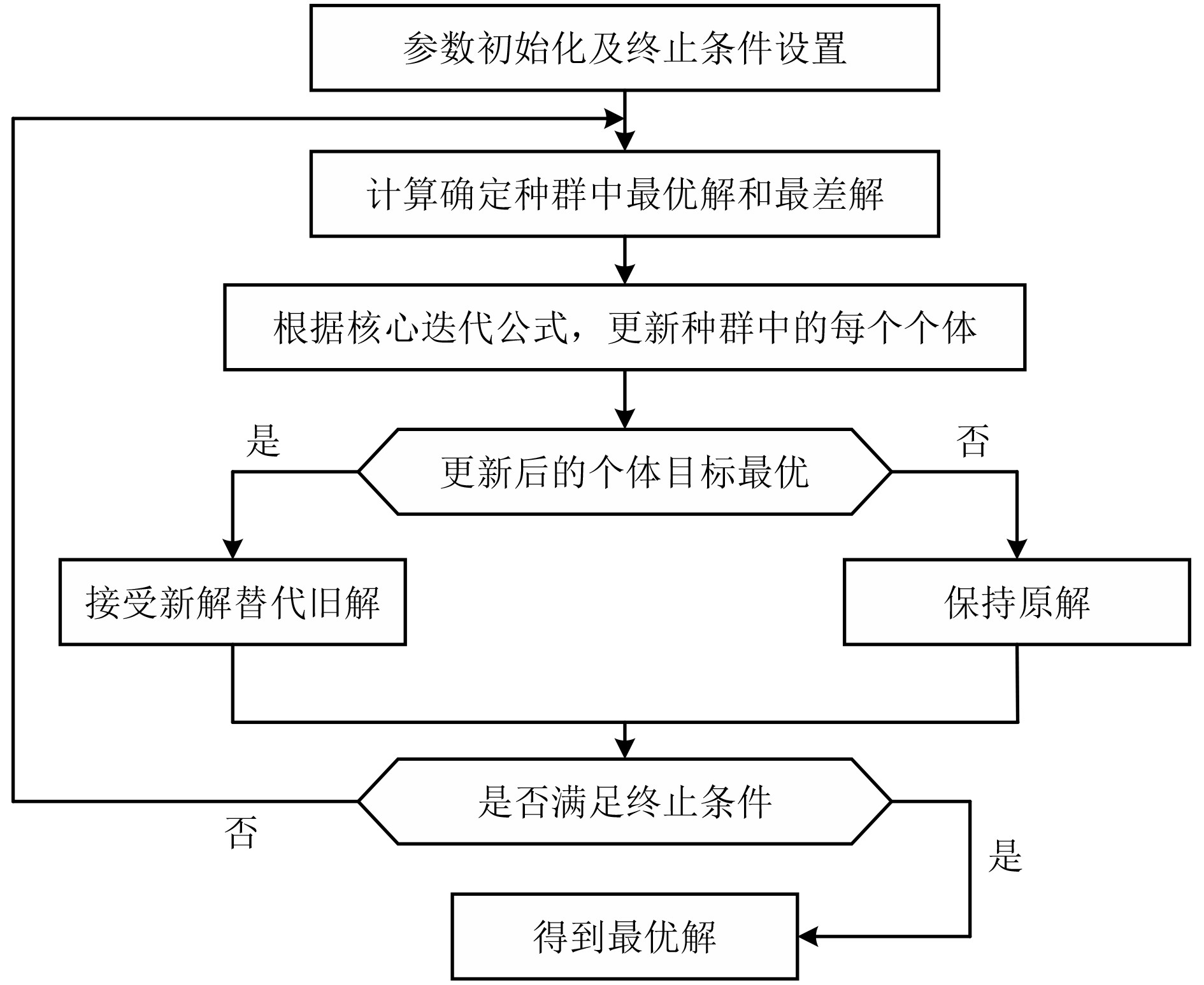
1 Jaya迭代优化
输入:起始节点start node,结束节点end node, 当前种群pop,
$ {\text{po}}{{\text{p}}_{{\text{size}}}} $, $ {t_{\max }} $, $ {{{\boldsymbol{P}}}_{{\text{best}}}} $, $ {{{\boldsymbol{P}}}_{{\text{worst}}}} $输出:最优路径$ {\bf{best\_path}} $和最短路径长度$ {L_{\min }} $ (1) for $ 1 \to {t_{\max }} $ (2) 根据式(3),计算余弦衰减因子$ r_{n} $ (3) 遍历种群:对于每个个体$ i \in {\text{pop}} $ (4) 根据式(4)选取$ {\text{nu}}{{\text{m}}_{{\text{dis}}}} $个节点: (5) 选取$ {\text{nu}}{{\text{m}}_{{\text{dis}}}} $个随机中间节点 (排除起点与终点) (6) 计算Jaya更新 (7) 根据式(6)计算$ {{{\boldsymbol{P}}}_{{\text{new}}}} $,选择最接近$ {{{\boldsymbol{P}}}_{{\text{new}}}} $的邻居节点作
为新节点(8) 计算新路径适应度: (9) if 若新路径优于当前路径前阶段的瓶颈集群 (10) 更新 $ {\text{pop}}\left[ i \right] \leftarrow {\bf{new\_path}} $ (11) $ {\text{fitness}}\left[ i \right] \leftarrow {\text{new\_fit}} $ (12) end (13) $ {\bf{best\_path}} \leftarrow {\text{pop}}[\arg \min ({\text{fitness}})] $ (14) return 最优路径$ {\bf{best\_path}} $,最短路径长度$ I_{\min } $  下载: 导出CSV
下载: 导出CSV
表 1 3种测试函数信息
编号 函数名 表达式 最优值 $ {f_1}(x) $ Sphere函数 $ {f_1}(x) = \displaystyle\sum\limits_{i = 1}^n {x_i^2} $ 0 $ {f_2}(x) $ Rastrigin函数 $ {f_2}(x) = \displaystyle\sum\limits_{i = 1}^n {\left( {x_i^2 - 10\cos \left( {2{\pi}{x_i}} \right) + 10} \right)} $ 0 $ {f_3}(x) $ Griewank函数 $ {f_3}(x) = \dfrac{1}{{4\;000}}\displaystyle\sum\limits_{i = 1}^D {\left( {x_i^2} \right)} - \displaystyle\prod\limits_{i = 1}^D {\cos } \left( {\frac{{{x_i}}}{{\sqrt i }}} \right) + 1 $ 0
下载: 导出CSV
表 2 参数敏感性分析结果(平均适应度)
种群规模 最大迭代次数 250 500 750 1 000 25 8.837 3 4.863 9 8.333 2 11.27 70 50 4.025 5 0.275 8 0.144 2 1.338 5×10–4 75 4.124 0 0.033 9 2.459 0×10–4 4.351 8×10–6 100 4.210 1 0.029 1 4.145 0×10–4 5.441 3×10–6
下载: 导出CSV
表 3 参数敏感性分析结果(标准差)
种群规模 最大迭代次数 250 500 750 1000 25 10.273 0 3.876 2 9.134 4 10.352 0 50 2.819 5 0.338 7 0.388 4 2.086 0×10–4 75 3.066 0 0.026 9 2.518 3×10–4 9.455 3×10–6 100 2.236 4 0.017 7 3.960 8×10–4 1.110 4×10–6
下载: 导出CSV
表 4 算法参数信息
SA GA ACO 参数名称 值 参数名称 值 参数名称 值 初始温度 200 交叉概率 0.8 蚂蚁数量 50 冷却速率 0.95 变异概率 0.1 信息素重要性因子 1 终止温度 0.1 - - 启发式因子 2 - - - - 信息素挥发系数 0.1
下载: 导出CSV
表 5 集群中心选择信息
集群中心数量 25节点边缘网络 38节点边缘网络 50节点边缘网络 nn + 1 集群中心 nn + 1 集群中心 nn+ 1 集群中心 3 9 [25;14;20] 13 [14;4;28] 17 [47;32;6] 4 7 [25;14;20;8] 10 [14;4;28;21] 13 [47;32;6;11] 5 5 [25;14;20;8;5] 8 [14;4;28;21;18] 10 [47;32;6;11;50]
下载: 导出CSV
表 6 不同集群中心数目下各节点边缘网络AvgSSE值
集群中心数目 25节点边缘网络 38节点边缘网络 50节点边缘网络 3 27.74 34.47 45.65 4 18.37 16.22 16.87 5 40.16 30.69 48.6
下载: 导出CSV
表 7 38节点边缘网络环境下多算法集群划分实验结果
对比方法 集群中心 各集群中心及分配集群成员 AvgSSE值 SA [14;4;28;21] [14,29,8,36,13,19,24,27,1,26];[4,9,33,18,20,15,37,35,38,30]
[28,2,32,6,10,31,16,22,25,5];[21,34,11,17,12,23,7,3]56.42 GA [14;4;28;21] [14,37,20,3,36,5,22,7,12,30];[4,8,33,38,32,18,15,1,24,2]
[28,31,35,16,34,25,9,26,29,10];[21,6,13,23,19,17,27,11]58.82 ACO [14;4;28;21] [14,8,18,26,30,17,2,25,27,31];[4,15,11,9,1,29,24,7,16,23]
[28,5,38,37,19,6,34,20,3,33];[21,10,12,35,22,32,13,36]19.46 Jaya [14;4;28;21] [14,19,37,31,3,18,34,33,26,16];[4,1,10,17,2,25,7,11,29,35]
[28,30,32,13,15,36,5,6,27,20];[21,12,23,38,9,8,22,24]55.26 Jaya* [14;4;28;21] [14,8,18,25,17,26,30,31,27,2];[4,15,9,7,29,11,24,1,16,33]
[28,5,38,23,6,20,34,19,37,3];[21,22,12,10,35,36,13,32]16.22
下载: 导出CSV
-
[1] LI Bingyao, HOU Jingming, WANG Xinghua, et al. High-resolution flood numerical model and Dijkstra algorithm based risk avoidance routes planning[J]. Water Resources Management, 2023, 37(8): 3243–3258. doi: 10.1007/s11269-023-03500-5. [2] BAI Wenbin and TAMARU H. Research on collision avoidance route planning based on A-star algorithm[J]. Navigation, 2023, 223: 31–32. doi: 10.18949/jinnavi.223.0_31. [3] ARNAU R, CALABUIG J M, GARCÍA-RAFFI L M, et al. A Bellman-Ford algorithm for the path-length-weighted distance in graphs[J]. Mathematics, 2024, 12(16): 2590. doi: 10.3390/math12162590. [4] 安阳, 王秀青, 赵明华. 基于策略融合及Spiking DRL的移动机器人路径规划方法[J]. 计算机科学, 2024, 51(11A): 240100211. doi: 10.11896/jsjkx.240100211.AN Yang, WANG Xiuqing, and ZHAO Minghua. Mobile robots' path planning method based on policy fusion and Spiking deep reinforcement learning[J]. Computer Science, 2024, 51(11A): 240100211. doi: 10.11896/jsjkx.240100211. [5] KONG Fuchen, WANG Qi, GAO Shang, et al. B-APFDQN: A UAV path planning algorithm based on deep Q-network and artificial potential field[J]. IEEE Access, 2023, 11: 44051–44064. doi: 10.1109/ACCESS.2023.3273164. [6] KONAR A, CHAKRABORTY I G, SINGH S J, et al. A deterministic improved Q-learning for path planning of a mobile robot[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2013, 43(5): 1141–1153. doi: 10.1109/TSMCA.2012.2227719. [7] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529–533. doi: 10.1038/nature14236. [8] 刘筱成. 基于强化学习的无人机路径规划研究[D]. [硕士论文], 青岛大学, 2024.LIU Xiaocheng. Research on UAV path planning based on reinforcement learning[D]. [Master dissertation], Qingdao University, 2024. [9] DORIGO M and BLUM C. Ant colony optimization theory: A survey[J]. Theoretical Computer Science, 2005, 344(2/3): 243–278. doi: 10.1016/j.tcs.2005.05.020. [10] DAI Xiaolin, LONG Shuai, ZHANG Zhiwe, et al. Mobile robot path planning based on ant colony algorithm with A* evaluation function[J]. Frontiers in Neurorobotics, 2019, 13: 15. doi: 10.3389/fnbot.2019.00015. [11] CHEN Di. Application of improved genetic algorithms in path planning[J]. Journal of Internet Technology, 2024, 25(7): 1091–1099. doi: 10.70003/160792642024122507013. [12] MIAO Hui and TIAN Yuchu. Dynamic robot path planning using an enhanced simulated annealing approach[J]. Applied Mathematics and Computation, 2013, 222: 420–437. doi: 10.1016/j.amc.2013.07.022. [13] DEHGHANI M and TROJOVSKÝ P. Osprey optimization algorithm: A new bio-inspired metaheuristic algorithm for solving engineering optimization problems[J]. Frontiers in Mechanical Engineering, 2023, 8: 1126450. doi: 10.3389/fmech.2022.1126450. [14] BRAIK M, HAMMOURI A, ATWAN J, et al. White Shark Optimizer: A novel bio-inspired meta-heuristic algorithm for global optimization problems[J]. Knowledge-Based Systems, 2022, 243: 108457. doi: 10.1016/j.knosys.2022.108457. [15] AKBARI M A, ZARE M, AZIZIPANAH-ABARGHOOEE B, et al. The cheetah optimizer: A nature-inspired metaheuristic algorithm for large-scale optimization problems[J]. Scientific Reports, 2022, 12(1): 10953. doi: 10.1038/s41598-022-14338-z. [16] VENKATA RAO R. Jaya: A simple and new optimization algorithm for solving constrained and unconstrained optimization problems[J]. International Journal of Industrial Engineering Computations, 2016, 7(1): 19–34. doi: 10.5267/j.ijiec.2015.8.004. [17] 杨晅, 陈宏宇. 基于数据与压缩率预测的空间机器人集群中心节点选择策略[J]. 中国科学院大学学报(中英文), 2024, 41(5): 695–704. doi: 10.7523/j.ucas.2023.007.YANG Xuan and CHEN Hongyu. Central node selection strategy of spatial robot cluster based on data and compression ratio prediction[J]. Journal of University of Chinese Academy of Sciences, 2024, 41(5): 695–704. doi: 10.7523/j.ucas.2023.007. [18] 华翔, 石成泷, 李宝华, 等. 一种自适应的无人集群中心节点选择方法[J]. 系统仿真学报, 2021, 33(11): 2636–2646. doi: 16182/j.issn1004731x.joss.21-FZ0770.HUA Xiang, SHI Chenglong, LI Baohua, et al. Adaptive center node selection method for unmanned cluster[J]. Journal of System Simulation, 2021, 33(11): 2636–2646. doi: 16182/j.issn1004731x.joss.21-FZ0770. [19] BOU S, KITAGAWA H, and AMAGASA T. CPiX: Real-time analytics over out-of-order data streams by incremental sliding-window aggregation[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(11): 5239–5250. doi: 10.1109/TKDE.2021.3054898. [20] NAGHIBI M and BARATI H. SHSDA: Secure hybrid structure data aggregation method in wireless sensor networks[J]. Journal of Ambient Intelligence and Humanized Computing, 2021, 12(12): 10769–10788. doi: 10.1007/s12652-020-02751-z. [21] CHENG Long, WANG Ying, LIU Qingzhi, et al. Network-aware locality scheduling for distributed data operators in data centers[J]. IEEE Transactions on Parallel and Distributed Systems, 2021, 32(6): 1494–1510. doi: 10.1109/TPDS.2021.3053241. [22] ULLAH I and YOUN H. Efficient data aggregation with node clustering and extreme learning machine for WSN[J]. The Journal of Supercomputing, 2020, 76(12): 10009–10035. doi: 10.1007/s11227-020-03236-8. -

 下载:
下载:





图(10) / 表(8)
计量
- 文章访问数: 432
- HTML全文浏览量: 352
- PDF下载量: 30
- 被引次数: 0
