

Low-Light Object Detection via Joint Image Enhancement and Feature Adaptation
-
摘要: 针对低光照图像目标特征弱、检测精度不足等问题,该文提出了一种基于图像增强与特征自适应联合学习的目标检测模型,该模型采用串联结构,将有监督的图像增强模块与YOLOv5目标检测模块相结合,以端到端的方式实现低光照图像目标检测。首先,利用正常光数据集生成匹配的正常光与低光图像对,实现数据集增强,并据此指导图像增强模块的学习;其次,联合图像增强损失、特征匹配损失和目标检测损失,从像素级和特征级两个层面优化目标检测结果;最后,基于真实低光照数据集进行模型参数的优化和微调。实验结果表明,该方法在仅使用真实正常光数据集训练的情况下,在LLVIP和Polar3000低光照数据集上的检测精度分别达到79.5%和85.7%,进一步在真实低光照数据集上微调后,检测精度分别提升至91.7%和92.3%,显著优于主流的低光照图像目标检测方法,并在ExDark和DarkFace的泛化实验中取得最佳检测效果。此外,该方法在提升检测精度的同时,仅带来2.5%的参数增加,具有良好的实时检测性能。Abstract:
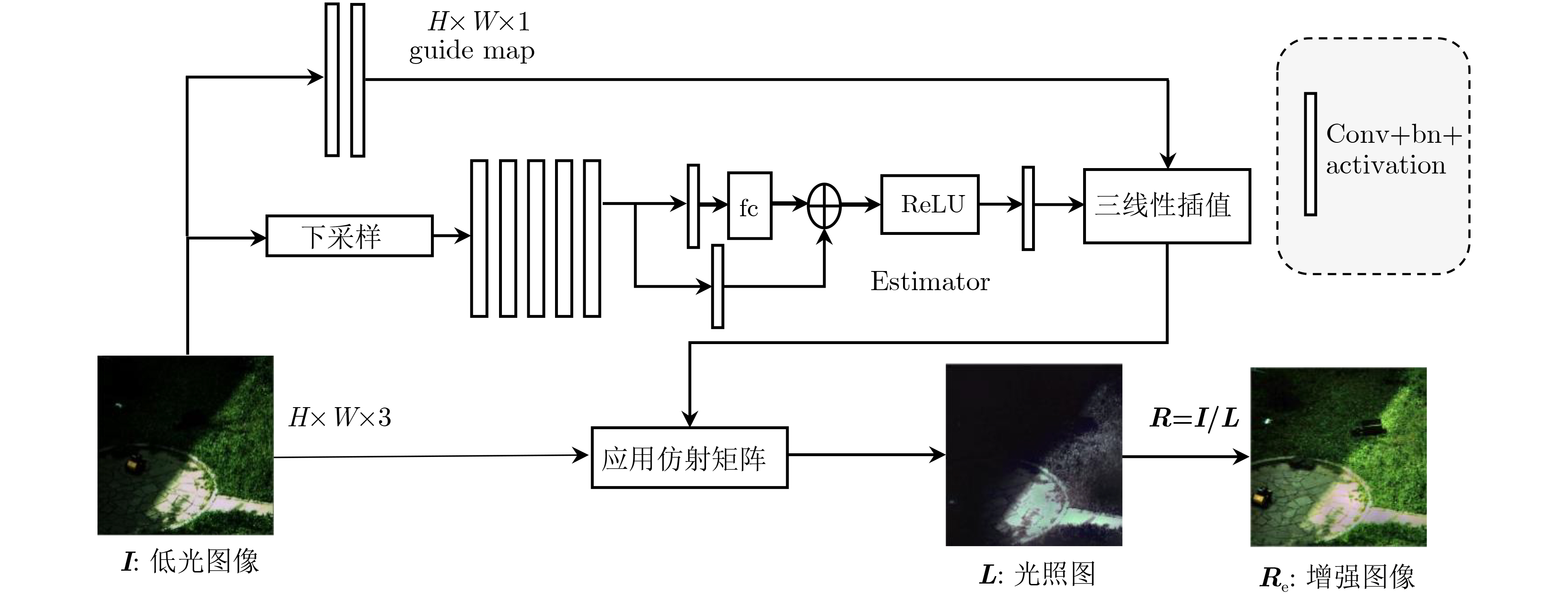
Objective Object detection has advanced significantly under normal lighting conditions, supported by numerous high-accuracy, high-speed deep learning algorithms. However, in low-light environments, images exhibit reduced brightness, weak contrast, and severe noise interference, leading to blurred object edges and loss of color information, which substantially degrades detection accuracy. To address this challenge, this study proposes an end-to-end low-light object detection algorithm that balances detection accuracy with real-time performance. Specifically, an end-to-end network is designed to enhance feature quality and improve detection accuracy in real time under low-light conditions. Methods To improve object detection performance under low-light conditions while maintaining detection accuracy and real-time processing, this study proposes an end-to-end low-light image object detection method. Detection accuracy is enhanced through joint learning of image enhancement and feature adaptation, with the overall network structure shown in Fig. 1 . First, a data augmentation module synthesizes low-light images from normal-light images. The paired normal-light and low-light images are mixed using the MixUp function provided by YOLOv5 to generate the final low-light images. These synthesized images are input into the low-light image enhancement module. In parallel, the matched normal-light images are provided as supervision to train the image enhancement network. Subsequently, both the enhanced low-light images and the corresponding normal-light images are fed into the object detection module. After processing through the YOLOv5 backbone, a matching loss is computed to guide feature adaptation.Result and Discussions The experiments are conducted primarily on the Polar3000 and LLVIP datasets. Fig. 3 presents the detection results obtained using YOLOv5 with different image enhancement methods applied to the Polar3000 dataset. Most existing methods tend to misclassify overexposed regions as bright Unmanned Aerial Vehicles (UAVs). In contrast, the proposed method demonstrates accurate object detection in low-light conditions without misidentifying overexposed areas as UAVs (Fig. 3 ). Furthermore, the detection performance of the proposed method, termed MAET, is compared with that of a standalone YOLOv5 model. Quantitative experiments show that the proposed method outperforms both image-enhancement-first detection pipelines and recent low-light object detection methods across both experimental groups A and B, irrespective of low-light fine-tuning. On the LLVIP dataset, the proposed method achieves a detection accuracy of 91.7% (Table 1 ), while on the Polar3000 dataset, it achieves 92.3% (Table 2 ). The model also demonstrates superior generalization performance on the ExDark and DarkFace datasets (Tables 4 and3 ). Additionally, compared to the baseline YOLOv5 model, the proposed method increases parameter size by only 2.5% while maintaining real-time detection speed (Table 5 ).Conclusions This study proposes a low-light object detection method based on joint learning of image enhancement and feature adaptation. The approach simultaneously optimizes image enhancement loss, feature matching loss, and object detection loss within an end-to-end framework. It improves image illumination, preserves fine details, and aligns the features of enhanced images with those acquired under normal lighting conditions, enabling high-precision object detection in low-light environments. Comparative experiments on the LLVIP and Polar3000 datasets demonstrate that the proposed method achieves improved detection accuracy while maintaining real-time performance. Furthermore, the method achieves the best generalization results on the ExDark and DarkFace datasets. Future work will explore low-light object detection based on multimodal data fusion of visible and infrared images to further enhance detection performance in extremely dark conditions. -
Key words:
- Object detection /
- Low-light images /
- Feature matching /
- Image enhancement network
-
表 1 Winderperson→LLVIP的对比实验结果(%)
A组实验 B组实验 方法 mAP50 mAP75 方法 mAP50 mAP75 YOLOv5 55.6 10.2 YOLOv5 82.1 37.9 +LIME[19] 59.1 11.8 +EMNet 74.6 31.8 +NeRCo[22] 60.5 12.9 +NeRCo 75.2 33.4 +EMNet[23] 62.9 13.5 +LIME 75.1 35.2 MAET[16](YOLOv3) 24.5 3.1 MAET(YOLOv3) 62.1 12.9 FEYOLO[15](YOLOv5) 64.6 14.1 PEYOLO(YOLOv5) 84.1 36.8 Ours(YOLOv5) 79.5 20.3 Ours(YOLOv5) 91.7 53.1 Ours(YOLO11) 83.5 24.1 Ours(YOLO11) 93.8 59.1  下载: 导出CSV
下载: 导出CSV
表 2 Polar3000的对比实验结果(%)
A组实验 B组实验 方法 mAP50 mAP75 方法 mAP50 mAP75 YOLOv5 5.7 2.7 YOLOv5 82.1 37.9 +DeepUPE[5] 10.8 2.8 +ZeroDCE 75.1 38.9 +ZeroDCE[2] 20.6 9.0 +LIME 77.1 43.8 +LIME[19] 34.9 21.5 +DeepUPE 80.5 46.3 PEYOLO[8](YOLOv5) 53.9 38.9 PEYOLO(YOLOv5) 75.1 49.3 MAET[16](YOLOv3) 58.9 16.1 MAET(YOLOv3) 85.7 1.0 本文方法(YOLOv5) 85.7 72.0 本文方法(YOLOv5) 92.3 76.1 本文方法(YOLO11) 87.9 74.1 本文方法(YOLO11) 93.7 77.4
下载: 导出CSV
表 3 Winderface→DackFace的对比实验结果(%)
A组实验 B组实验 方法 mAP50 mAP75 方法 mAP50 mAP75 YOLOv5 11.5 0.66 YOLOv5 40.8 8.33 +DeepUPE[5] 17.5 0.59 +PairLIE 42.0 8.30 +PairLIE[21] 21.8 0.92 +DeepUPE 42.1 8.28 +EMNet[23] 22.2 1.30 +EMNet 43.9 8.81 PEYOLO[8](YOLOv5) 10.2 0.68 PEYOLO(YOLOv5) 38.9 7.92 MAET[16](YOLOv3) 14.9 1.12 MAET(YOLOv3) 35.7 7.52 本文方法(YOLOv5) 29.3 1.63 本文方法(YOLOv5) 55.5 16.6
下载: 导出CSV
表 5 模型复杂度比较
方法 参数量 浮点运算次数(GFLOPs) 推理时间(每张图像) YOLOv5 47, 025, 981 115.3 14.0 ms PEYOLO (YOLOv5) 47, 117, 184 137.7 49.0 ms FEYOLO](YOLOv5) 47, 165, 381 202.0 26.2 ms 本文方法(YOLOv5) 48, 245, 503 141.5 19.1 ms
下载: 导出CSV
表 6 消融实验结果(%)
任务 数据增强 增强损失 匹配损失 是否微调 mAP50 mAP75 Lcfm L2 Lcf Winderperson
→LLVIP× × × × × × 55.6 10.2 √ × × × × × 71.2 19.1 √ √ × × × × 73.1 19.7 √ √ × √ × × 73.5 19.2 √ √ × × √ × 75.6 19.7 √ √ √ × × × 79.5 20.3 √ × √ × × × 77.1 19.6 √ √ × × × √ 89.1 52.2 √ √ √ × × √ 91.7 53.1
下载: 导出CSV
-
[1] WEI Chen, WANG Wenjing, YANG Wenhan, et al. Deep retinex decomposition for low-light enhancement[C]. Proceedings of British Machine Vision Conference, Newcastle, UK, 2018: 155. [2] GUO Chunle, LI Chongyi, GUO Jichang, et al. Zero-reference deep curve estimation for low-light image enhancement[C]. Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 1777–1786. doi: 10.1109/CVPR42600.2020.00185. [3] LUO Yu, CHEN Xuanrong, LING Jie, et al. Unsupervised low-light image enhancement with self-paced learning[J]. IEEE Transactions on Multimedia, 2025, 27: 1808–1820. doi: 10.1109/TMM.2024.3521752. [4] WANG Qiang, CUI Yuning, LI Yawen, et al. RFFNet: Towards robust and flexible fusion for low-light image denoising[C]. Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, Australia, 2024: 836–845. doi: 10.1145/3664647.3680675. [5] WANG Ruixing, ZHANG Qing, FU C W, et al. Underexposed photo enhancement using deep illumination estimation[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 6842–6850. doi: 10.1109/CVPR.2019.00701. [6] JOCHER G, STOKEN A, BOROVEC J, et al. ultralytics/yolov5: v5.0-YOLOv5-P6 1280 models, AWS, supervise. ly and YouTube integrations[EB/OL]. https://zenodo.org/records/4679653, 2021. [7] QIN Qingpao, CHANG Kan, HUANG Mengyuan, et al. DENet: Detection-driven enhancement network for object detection under adverse weather conditions[C]. Proceedings of the 16th Asian Conference on Computer Vision, Macao, China, 2022: 491–507. doi: 10.1007/978-3-031-26313-2_30. [8] YIN Xiangchen, YU Zhenda, FEI Zetao, et al. PE-YOLO: Pyramid enhancement network for dark object detection[C]. Proceedings of the 32nd International Conference on Artificial Neural Networks on Artificial Neural Networks and Machine Learning, Heraklion, Crete, Greece, 2023: 163–174. doi: 10.1007/978-3-031-44195-0_14. [9] REDMON J and FARHADI A. YOLOv3: An incremental improvement[J]. arXiv preprint arXiv: 1804.02767, 2018. doi: 10.48550/arXiv.1804.02767. [10] LIU Wenyu, REN Gaofeng, YU Runsheng, et al. Image-adaptive YOLO for object detection in adverse weather conditions[C]. Proceedings of the 36th AAAI Conference on Artificial Intelligence, 2022: 1792–1800. doi: 10.1609/aaai.v36i2.20072. [11] JIA Xinyu, ZHU Chuang, LI Minzhen, et al. LLVIP: A visible-infrared paired dataset for low-light vision[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Montreal, Canada, 2021: 3489–3497. doi: 10.1109/ICCVW54120.2021.00389. [12] FENG Bin, XIAO Jinpei, ZHANG Junchao, et al. Color-polarization synergistic target detection method considering shadow interference[J]. Defence Technology, 2024, 37: 50–61. doi: 10.1016/j.dt.2024.01.007. [13] WANG Shuhang and LUO Gang. Naturalness preserved image enhancement using a priori multi-layer lightness statistics[J]. IEEE Transactions on Image Processing, 2018, 27(2): 938–948. doi: 10.1109/TIP.2017.2771449. [14] LOH Y P and CHAN C S. Getting to know low-light images with the exclusively dark dataset[J]. Computer Vision and Image Understanding, 2019, 178: 30–42. doi: 10.1016/j.cviu.2018.10.010. [15] HASHMI K A, KALLEMPUDI G, STRICKER D, et al. FeatEnHancer: Enhancing hierarchical features for object detection and beyond under low-light vision[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 6702–6712. doi: 10.1109/ICCV51070.2023.00619. [16] CUI Ziteng, QI Guojun, GU Lin, et al. Multitask AET with orthogonal tangent regularity for dark object detection[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 2533–2542. doi: 10.1109/ICCV48922.2021.00255. [17] DU Zhipeng, SHI Miaojing, and DENG Jiankang. Boosting object detection with zero-shot day-night domain adaptation[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 12666–12676. doi: 10.1109/CVPR52733.2024.01204. [18] ZHANG Qing, NIE Yongwei, and ZHENG Weishi. Dual illumination estimation for robust exposure correction[J]. Computer Graphics Forum, 2019, 38(7): 243–252. doi: 10.1111/cgf.13833. [19] GUO Xiaojie, LI Yu, and LING Haibin. LIME: Low-light image enhancement via illumination map estimation[J]. IEEE Transactions on Image Processing, 2017, 26(2): 982–993. doi: 10.1109/TIP.2016.2639450. [20] XU Xiaogang, WANG Ruixing, FU C W, et al. SNR-aware low-light image enhancement[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 17693–17703. doi: 10.1109/CVPR52688.2022.01719. [21] FU Zhenqi, YANG Yan, TU Xiaotong, et al. Learning a simple low-light image enhancer from paired low-light instances[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 22252–22261. doi: 10.1109/CVPR52729.2023.02131. [22] YANG Shuzhou, DING Moxuan, WU Yanmin, et al. Implicit neural representation for cooperative low-light image enhancement[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 12872–12881. doi: 10.1109/ICCV51070.2023.01187. [23] YE Dongjie, NI Zhangkai, YANG Wenhan, et al. Glow in the dark: Low-light image enhancement with external memory[J]. IEEE Transactions on Multimedia, 2024, 26: 2148–2163. doi: 10.1109/TMM.2023.3293736. [24] GHARBI M, CHEN Jiawen, BARRON J T, et al. Deep bilateral learning for real-time image enhancement[J]. ACM Transactions on Graphics (TOG), 2017, 36(4): 118. -


 下载:
下载:





图(5) / 表(6)
计量
- 文章访问数: 994
- HTML全文浏览量: 684
- PDF下载量: 139
- 被引次数: 0
