

A Review of Ground-to-Aerial Cross-View Localization Research
-
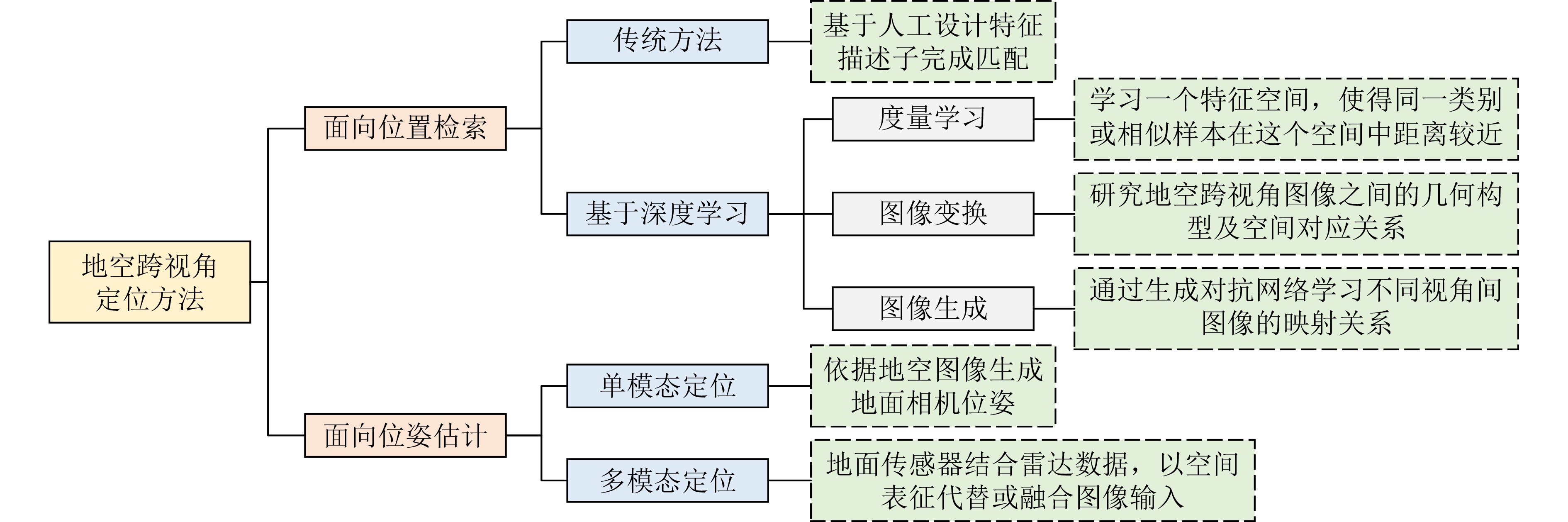
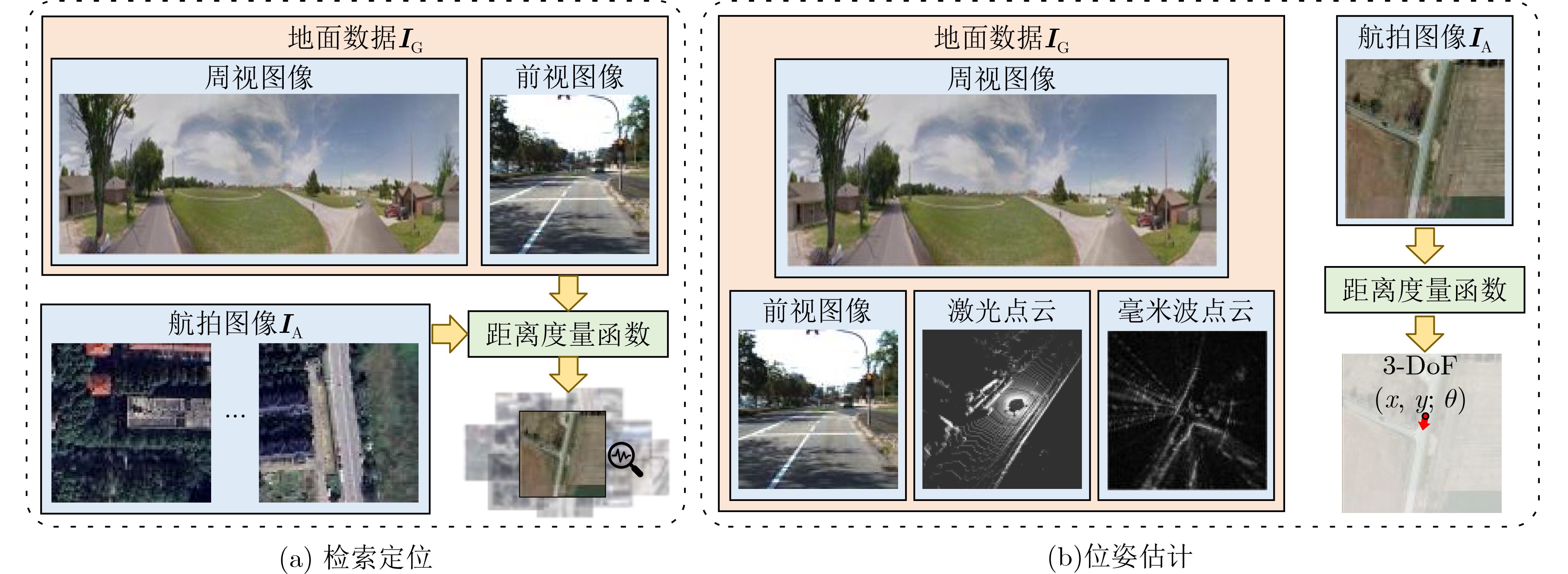
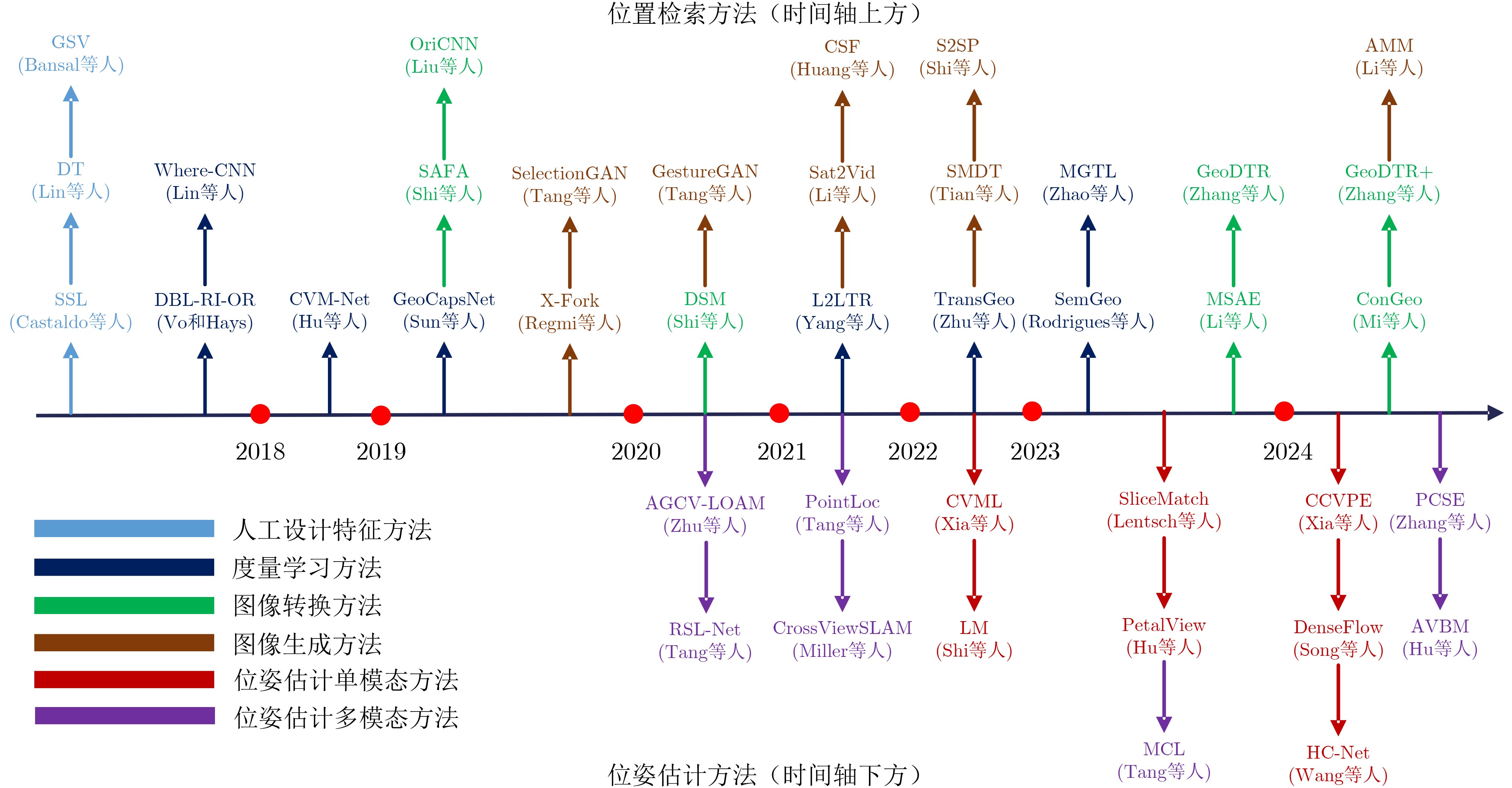
摘要: 地空跨视角定位指的是利用空中视角图像作为参考,确定待查询的地面传感器位姿的过程。随着无人驾驶汽车、无人机导航等技术的发展,地空跨视角定位技术在智能交通、城市管理等领域扮演着越来越重要的角色。地空跨视角定位技术的发展经历了几个阶段:从早期基于人工设计特征的传统方法,到深度学习技术的引入衍生出的度量学习、图像变换及图像生成方法,以及结合距离传感器的定位技术。这些技术的发展标志着从依赖手工特征到自动学习特征表示的转变,以及从单一模态到多模态数据融合的进步。尽管取得了丰富的成果,地空跨视角定位领域仍存在很多挑战,尤其是在处理时空差异导致的定位误差问题上。这些挑战包括季节变化、日夜交替、天气状况差异等时间维度上的差异,以及视角改变、场景布局变化等空间维度上的差异,这些都对算法的鲁棒性和准确性提出了更高的要求。该文聚焦于地空跨视角定位,系统梳理了主要方法、关键数据集和评价方法,并对未来的发展趋势进行了分析。同时,该文首次系统化地整理了结合距离传感器的地空跨视角定位算法,为该领域的研究提供了新的视角和思路。Abstract:
Significance This paper presents a comprehensive review of ground-to-aerial cross-view localization, systematically organizes representative methods, benchmark datasets, and evaluation metrics. Notably, it is the first review to systematically organize ground-to-aerial cross-view localization algorithms that integrate range sensors, such as Light Detection and Ranging (LiDAR) and millimeter-wave radar, thereby providing new perspectives for subsequent research. Ground-to-aerial cross-view localization has emerged as a key topic in computer vision, aiming to determine the precise pose of ground-based sensors by referencing aerial imagery. This technology is increasingly applied in autonomous driving, unmanned aerial vehicle navigation, intelligent transportation systems, and urban management. Despite substantial progress, ground-to-aerial cross-view localization continues to face major challenges arising from temporal and spatial variations, including seasonal changes, day-night transitions, weather conditions, viewpoint differences, and scene layout changes. These factors require more robust and accurate algorithms to reduce localization errors. This review summarizes the state of the art and provides a forward-looking discussion of challenges and research directions. Progress Ground-to-aerial cross-view localization has advanced rapidly, particularly through the integration of range sensors such as LiDAR and millimeter-wave radar, which has opened new research directions and application scenarios. The development of this field can be divided into several stages. Early studies rely on manually designed features, marking a transition from same-view localization to cross-view geographic localization. With the emergence of deep learning, metric learning, image transformation, and image generation methods are adopted to learn correspondences between images captured from different viewpoints. However, many deep learning models exhibit limited robustness to temporal and spatial variations, especially in long-term cross-season scenarios in which visual appearances at the same location differ markedly across seasons. Additionally, the large-scale nature of urban environments presents difficulties for efficient image retrieval and matching. Range sensors provide accurate distance measurements and three-dimensional structural information, which support reliable localization in scenes where visual cues are weak or absent. Nevertheless, effective fusion of range-sensor data and visual data remains challenging because of discrepancies in spatial resolution, sampling frequency, and sensing coverage. Conclusions This paper reviews the evolution of ground-to-aerial cross-view localization technologies, analyzes major technical advances and their driving factors at different stages. From an algorithmic perspective, the main categories of ground-to-aerial cross-view localization methods are systematically discussed to provide a clear theoretical framework and technical overview. The role of benchmark datasets in promoting progress in this field is highlighted by comparing the performance of representative models across datasets, thereby clarifying differences and relative advantages among methods. Although notable progress has been achieved, several challenges persist, including cross-region localization accuracy, precise localization over large-scale aerial imagery, and sensitivity to temporal changes in geographic features. Further research is required to improve the robustness, accuracy, and efficiency of localization systems. Prospects Future research on ground-to-aerial cross-view localization is expected to concentrate on several directions. Greater attention should be paid to transform range-sensor data into feature representations that align effectively with image features, enabling efficient cross-modal information fusion. Multi-branch network architectures, in which different modalities are processed separately and then fused, may support richer feature extraction. Graph-based models may also be explored to capture shared semantics between ground and aerial views and to support information propagation across modalities. In addition, algorithms that adapt to seasonal variation, day-night cycles, and changing weather conditions are required to enhance robustness and localization accuracy. The integration of multi-scale and multi-temporal data may further improve adaptability to spatio-temporal variation, for example through the combination of images with different spatial resolutions or acquisition times. For large-scale urban environments, efficient search and matching strategies remain essential. Parallel computing frameworks may be applied to manage large datasets and accelerate retrieval, whereas algorithmic strategies such as pruning can reduce computational redundancy and improve matching efficiency. Overall, although ground-to-aerial cross-view localization continues to face challenges, it shows substantial potential for further methodological development and practical deployment. -
Key words:
- Ground-to-aerial cross-view localization /
- Computer vision /
- Deep learning /
- Range sensors /
- Multimodal
-
表 1 位置检索四种类别方法对比
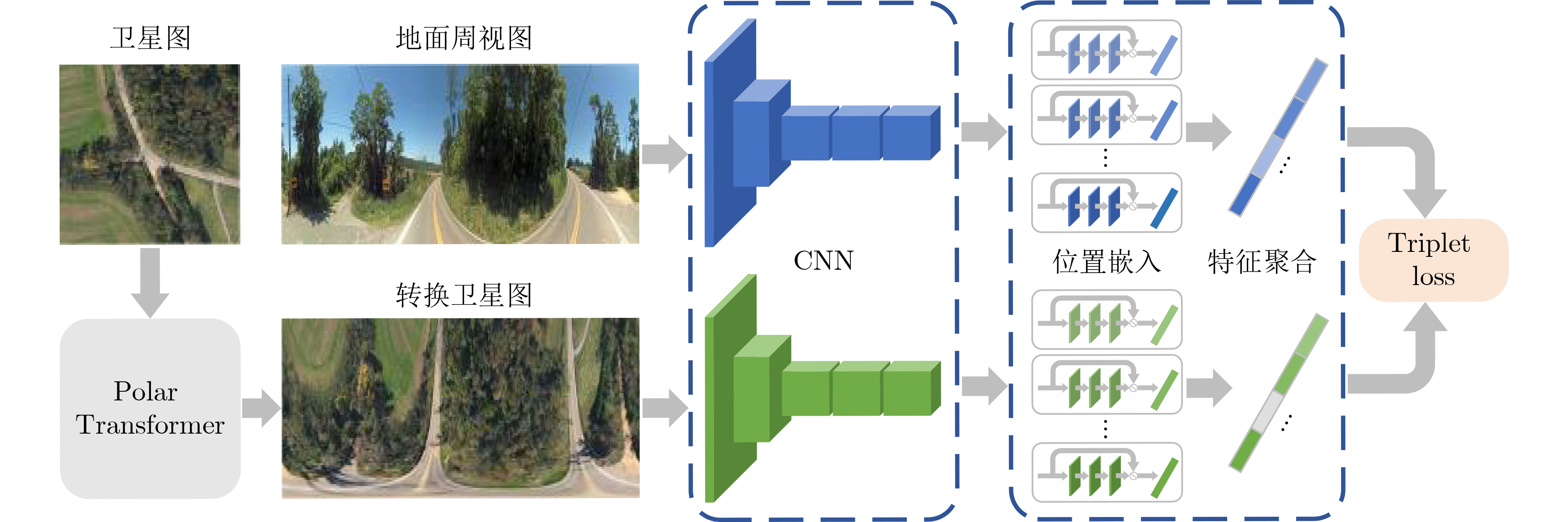
维度 人工特征方法 度量学习方法 图像变换方法 图像生成方法 核心目的 基于设计特征进行关联匹配 学习判别性特征进行匹配 显式建模补偿视角几何差异 生成目标视图图像 主要驱动力 特征工程、先验模型 深度表征学习、优化目标 几何投影模型 生成对抗网络 核心价值 奠基性、可解释性 高精度、强大特征表示能力 增强几何鲁棒性 有效弥合视角域差异 核心创新 特定特征设计与利用 自动特征学习机制 几何变换规则 视角映射与图像合成 主要优势 计算要求低、设计目标精准 精度高、泛化性强 几何鲁棒性强 缩小域差距、无监督潜力大 主要局限 鲁棒性差、表达能力瓶颈 算力依赖高、几何建模隐式 简化现实几何变换畸变风险 生成质量依赖高、模型复杂 演进趋势 逐渐被深度学习模型替代 结合Transformer持续发展 解决特定几何挑战 探索域差异新解法  下载: 导出CSV
下载: 导出CSV
表 2 跨视角定位常用数据集
名称 介绍 特点 视觉数据
(空-地)有无
GNSS有无
IMU任务目标 CVUSA[22] 涵盖纽约、洛杉矶、迈阿密等美国20个城市,包含 35532 对用于训练的图像和8884 对用于测试的图像。支持多尺度的跨视角训练,通过引入同一地理位置的多尺度航拍图,提高了模型在
大规模应用场景中的定位精度。图像-图像 无 无 检索定位 CVACT[50] 覆盖了澳大利亚首都堪培拉的300 km2的地理区域,具体包括了 35532 组训练用图像对
和92802 组测试用图像对。通过谷歌地图API采集地空图像对,并对每个街景图
配备GNSS标签。用于验证方法在更大地理范围内的跨视角定位实例上的泛化能力,并引入了一种全新的Siamese CNN架构,能够同时从外观和方向几何信息中学习特征嵌入。 图像-图像 有 无 检索定位 VIGOR[21] 覆盖了美国4个主要城市(旧金山、纽约、西雅图和芝加哥),收集了共计 90618 张航拍图像和238696 张街景全景图。通过密集采样来实现区域的无缝覆盖,确保了即便街景图像出现在任意位置,至少被1张航拍图像覆盖。突破现有数据集1对1检索限制,引入了航拍图像是在查询图像出现之前捕获这一更贴近实际场景的假设,构建了一个更加现实的跨视角地理定位问题框架,并首次从米级实际距离的角度评估了定位准确性。 图像-图像 有 无 检索定位/
位姿回归KITTI[20] 在德国卡尔斯鲁厄周边不同交通场景下,通过地面车载传感器记录了长达6 h的交通数据,涵盖了公路、乡村到城市的多样场景,包含大量静态和动态物体。 场景趋于城乡多元化,融合了点云数据
作为环境感知输入图像-图像/
图像-点云有 有 位姿回归 Oxford
RobotCar[51,52]通过一个固定的路线定期穿越中心牛津市区,平均每周2次,在19个月期间共记录了
约1 010 km 的驾驶路程。数据集包括2 000万张图像,这些图像来源于车辆上安装的六个摄像头,以及包括LiDAR,GNSS和惯性导航系统在内的地面实况数据偏向于同区域内的长时跨季数据,采集期间的道路和建筑施工导致路线的某些部分从数据收集开始到结束发生了显著变化 图像-图像/
图像-点云有 有 位姿回归 Oxford Radar
RobotCar[53]在Oxford RobotCar原平台基础上进行了扩展,在加装毫米波雷达的前提下,历时一个月在牛津中心遍历32圈,共计约280 km。通过毫米波雷达发射出的电磁波对雨、雾、夜间等场景重新扫描,实现相同区域内生成光学数据与电磁数据,彼此互补。 相较于Oxford RobotCar数据集,Oxford Radar RobotCar聚焦毫米波雷达,更偏向于鲁棒性与扫描范围,通过将雷达里程计与视觉-惯导-激光一起做全局优化后,得到的轨迹弥补了在城区漂移较大的缺陷。 图像-图像/
图像-点云有 有 位姿回归 Ford Multi-
AV[54]由福特自动驾驶汽车车队V1, V2, V3 3辆车辆在2017$ \sim $2018年的不同日期和时间收集。这些车辆在密歇根州的平均行驶里程为66 km,涵盖多种驾驶场景。 包含了动态城市环境中天气、光照、建筑和交通条件的季节性变化,有助于设计的算法对季节和城市变化更具鲁棒性 图像-图像/
图像-点云有 有 位姿回归
下载: 导出CSV
表 3 CVUSA和CVACT数据集模型表现(%)
方法 CVUSA CVACT r@1 r@5 r@10 r@1% r@1 r@5 r@10 r@1% 度量学习 Workman等人[22] - - - 34.30 - - - - Vo等人[14] - - - 63.70 - - - - Zhai等人[15] - - - 43.20 - - - - CVM-Net[32] 22.47 49.98 63.18 93.62 5.41 14.79 25.63 54.53 L2LTR[55] 94.05 98.27 98.99 99.67 60.72 85.85 89.88 96.12 TransGeo[33] 94.08 98.36 99.04 99.77 - - - - OR-CVFI[58] 98.05 99.48 99.64 - 91.03 96.31 97.02 - 图像变换 GeoDTR+[59] 95.40 98.44 99.05 99.75 67.57 89.84 92.57 98.54 Liu等人[50] 40.79 66.82 76.36 96.12 19.90 34.82 41.23 63.79 AMPLE[60] 93.22 97.90 98.76 99.75 85.69 93.42 94.66 97.58 ArcGeo[61] 97.47 99.48 - 99.67 90.90 95.84 96.77 - HADGEO[62] 95.01 98.45 99.10 - 86.48 94.21 95.50 - SAFA[35] 89.84 96.93 98.14 99.64 55.50 79.94 85.08 94.49 Shi等人[56] 91.96 97.50 98.54 99.67 35.55 60.17 67.95 86.71 图像生成 Regmi等人[57] 48.75 - 81.27 95.98 - - - - Toker等人[26] 92.56 97.55 98.33 99.57 61.29 85.13 89.14 98.32
下载: 导出CSV
表 4 VIGOR数据集模型表现(%)
方法 同区域 跨区域 r@1 r@5 r@10 r@1% Hit rate r@1 r@5 r@10 r@1% hit rate SAFA[35] 18.69 43.64 55.36 97.55 21.90 2.77 8.61 12.94 62.64 3.16 SAFA+Mining[21] 38.02 62.87 71.12 97.63 41.81 9.23 21.12 28.02 77.84 9.92 VIGOR[21] 41.07 65.81 74.05 98.37 44.71 11.00 23.56 30.76 80.22 11.64 TransGeo[33] 61.48 87.54 91.88 99.56 73.09 18.99 38.24 46.91 88.94 21.21 SAIG[64] 55.60 81.83 - 99.43 63.57 22.35 42.43 - 90.83 24.69 EP-BEV[63] 82.18 97.10 98.17 99.70 - 72.19 88.68 91.68 98.56 - InfoNCE[65] 76.15 94.46 96.28 99.53 87.24 - - - - - GeoDTR[66] 56.51 80.37 86.21 99.25 61.76 30.02 52.67 61.45 94.40 30.19 GeoDTR+[59] 59.01 81.77 87.10 99.07 67.41 36.01 59.06 67.22 94.95 39.40
下载: 导出CSV
表 5 KITTI数据集模型表现
类型 方法 有无
先验同区域 跨区域 均值误差 中值误差 均值误差 中值误差 距离(m) 角度(°) 距离(m) 角度(°) 距离(m) 角度(°) 距离(m) 角度(°) 图像到图像 LM[67] √ 12.08 3.72 11.42 2.83 12.58 3.95 12.11 3.03 SliceMatch[68] √ 7.96 4.12 4.39 3.65 13.50 4.20 9.77 6.61 CCVPE[69] √ 1.22 0.67 0.62 0.54 9.16 1.55 3.33 0.84 HC-Net[70] √ 0.80 0.45 0.50 0.33 8.47 3.22 4.57 1.63 BevSplat[71] √ 2.86 0.33 2.00 0.28 6.24 0.33 2.68 0.28 Petalview[72] √ 2.10 3.94 - - - - - - CVR[21] √ 9.36 - 8.49 - - - - - CVML[41] √ 1.40 - 0.99 - - - - - Song等人[42] √ 1.48 0.49 0.47 0.30 7.97 2.17 3.52 1.21 LM[67] × 15.51 89.91 15.97 90.75 15.50 89.84 16.02 89.85 SliceMatch[68] × 9.39 8.71 5.41 4.42 14.85 23.64 11.85 7.96 CCVPE[69] × 6.88 15.01 3.47 6.12 13.94 77.84 10.98 63.84 Petalview[72] × 2.32 8.86 - - 23.79 57.10 - - 图像到雷达 RSL-Net[44] × - - - - 3.71 1.59 - - Tang等人[73] × - - - - 4.37 1.67 - - Tang等人[47] × - - - - 4.02 3.70 - - Tang等人[48] × - - - - 3.76 3.36 - - AVBM[74] × - - - - 4.96 5.13 4.04 4.22 Hu等人[18] × - - - - 3.66 1.85 2.95 1.62
下载: 导出CSV
-
[1] SHI Yujiao, YU Xin, LIU Liu, et al. Optimal feature transport for cross-view image geo-localization[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 11990–11997. doi: 10.1609/aaai.v34i07.6875. [2] WANG Tingyu, ZHENG Zhedong, YAN Chenggang, et al. Each part matters: Local patterns facilitate cross-view geo-localization[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(2): 867–879. doi: 10.1109/TCSVT.2021.3061265. [3] WANG Shan, ZHANG Yanhao, PERINCHERRY A, et al. View consistent purification for accurate cross-view localization[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 8163–8172. doi: 10.1109/ICCV51070.2023.00753. [4] RODRIGUES R and TANI M. Are these from the same place? Seeing the unseen in cross-view image geo-localization[C]. 2021 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2021: 3752–3760. doi: 10.1109/WACV48630.2021.00380. [5] HU Di, YUAN Xia, and ZHAO Chunxia. Active layered topology mapping driven by road intersection[J]. Knowledge-Based Systems, 2025, 315: 113305. doi: 10.1016/j.knosys.2025.113305. [6] DURGAM A, PAHEDING S, DHIMAN V, et al. Cross-view geo-localization: A survey[J]. IEEE Access, 2024, 12: 192028–192050. doi: 10.1109/ACCESS.2024.3507280. [7] ZHANG Kai, YUAN Xia, CHEN Shuntong, et al. Multi-modality semantic-shared cross-view ground-to-aerial localization[C]. The 6th ACM International Conference on Multimedia in Asia, Auckland, New Zealand, 2024: 72. doi: 10.1145/3696409.3700233. [8] WILSON D, ZHANG Xiaohan, SULTANI W, et al. Image and object geo-localization[J]. International Journal of Computer Vision, 2024, 132(4): 1350–1392. doi: 10.1007/s11263-023-01942-3. [9] 张硝, 高艺, 夏宇翔, 等. 跨视角图像地理定位数据集综述[J]. 遥感学报, 2025, 29(8): 2511–2530. doi: 10.11834/jrs.20254348.ZHANG Xiao, GAO Yi, XIA Yuxiang, et al. Review of cross-view image geo-localization datasets[J]. National Remote Sensing Bulletin, 2025, 29(8): 2511–2530. doi: 10.11834/jrs.20254348. [10] ASPERTI A, FIORILLA S, NARDI S, et al. A review of recent techniques for person re-identification[J]. Machine Vision and Applications, 2025, 36(1): 25. doi: 10.1007/s00138-024-01622-3. [11] ZHANG Yuxin, GUI Jie, CONG Xiaofeng, et al. A comprehensive survey and taxonomy on point cloud registration based on deep learning[C]. The 33rd International Joint Conference on Artificial Intelligence, Jeju, South Korea, 2024: 8344–8353. doi: 10.24963/ijcai.2024/922. [12] BANSAL M, SAWHNEY H S, CHENG Hui, et al. Geo-localization of street views with aerial image databases[C]. The 19th ACM International Conference on Multimedia, Scottsdale, USA, 2011: 1125–1128. doi: 10.1145/2072298.2071954. [13] BANSAL M, DANIILIDIS K, and SAWHNEY H. Ultrawide baseline facade matching for geo-localization[M]. ZAMIR A R, HAKEEM, A VAN GOOL L, et al. Large-Scale Visual Geo-Localization. Cham: Springer, 2016: 77–98. doi: 10.1007/978-3-319-25781-5_5. [14] VO N N and HAYS J. Localizing and orienting street views using overhead imagery[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 494–509. doi: 10.1007/978-3-319-46448-0_30. [15] ZHAI Menghua, BESSINGER Z, WORKMAN S, et al. Predicting ground-level scene layout from aerial imagery[C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 4132–4140. doi: 10.1109/CVPR.2017.440. [16] MILLER I D, COWLEY A, KONKIMALLA R, et al. Any way you look at it: Semantic crossview localization and mapping with LiDAR[J]. IEEE Robotics and Automation Letters, 2021, 6(2): 2397–2404. doi: 10.1109/LRA.2021.3061332. [17] KIM J and KIM J. Fusing lidar data and aerial imagery with perspective correction for precise localization in urban canyons[C]. Proceedings of 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems, Macau, China, 2019: 5298–5303. doi: 10.1109/IROS40897.2019.8967711. [18] HU Di, YUAN Xia, XI Huiying, et al. Road structure inspired UGV-satellite cross-view geo-localization[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024, 17: 16767–16786. doi: 10.1109/JSTARS.2024.3457756. [19] SHI Qian, HE Da, LIU Zhengyu, et al. Globe230k: A benchmark dense-pixel annotation dataset for global land cover mapping[J]. Journal of Remote Sensing, 2023, 3: 0078. doi: 10.34133/remotesensing.0078. [20] GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: The kitti dataset[J]. The International Journal of Robotics Research, 2013, 32(11): 1231–1237. doi: 10.1177/0278364913491297. [21] ZHU Sijie, YANG Taojiannan, and CHEN Chen. VIGOR: Cross-view image geo-localization beyond one-to-one retrieval[C]. Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 5316–5325. doi: 10.1109/CVPR46437.2021.00364. [22] WORKMAN S, SOUVENIR R, and JACOBS N. Wide-area image geolocalization with aerial reference imagery[C]. Proceedings of 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 3961–3969. doi: 10.1109/ICCV.2015.451. [23] 黄高爽, 周杨, 胡校飞, 等. 图像地理定位研究进展[J]. 地球信息科学学报, 2023, 25(7): 1336–1362. doi: 10.12082/dqxxkx.2023.230073.HUANG Gaoshuang, ZHOU Yang, HU Xiaofei, et al. A survey of the research progress in image geo-localization[J]. Journal of Geo-information Science, 2023, 25(7): 1336–1362. doi: 10.12082/dqxxkx.2023.230073. [24] MA Yuexin, WANG Tai, BAI Xuyang, et al. Vision-centric BEV perception: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 10978–10997. doi: 10.1109/TPAMI.2024.3449912. [25] 周博文, 李阳, 马鑫骥, 等. 深度学习的跨视角地理定位方法综述[J]. 中国图象图形学报, 2024, 29(12): 3543–3563. doi: 10.11834/jig.230858.ZHOU Bowen, LI Yang, MA Xinji, et al. A survey of cross-view geo-localization methods based on deep learning[J]. Journal of Image and Graphics, 2024, 29(12): 3543–3563. doi: 10.11834/jig.230858. [26] TOKER A, ZHOU Qunjie, MAXIMOV M, et al. Coming down to earth: Satellite-to-street view synthesis for geo-localization[C]. Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 6484–6493. doi: 10.1109/CVPR46437.2021.00642. [27] TANG Hao, LIU Hong, and SEBE N. Unified generative adversarial networks for controllable image-to-image translation[J]. IEEE Transactions on Image Processing, 2020, 29: 8916–8929. doi: 10.1109/TIP.2020.3021789. [28] LI Ang, MORARIU V I, and DAVIS L S. Planar structure matching under projective uncertainty for geolocation[C]. Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 265–280. doi: 10.1007/978-3-319-10584-0_18. [29] LIN T Y, BELONGIE S, and HAYS J. Cross-view image geolocalization[C]. Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 891–898. doi: 10.1109/CVPR.2013.120. [30] CAO Song and SNAVELY N. Graph-based discriminative learning for location recognition[C]. Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 700–707. doi: 10.1109/CVPR.2013.96. [31] WORKMAN S and JACOBS N. On the location dependence of convolutional neural network features[C]. Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, USA, 2015: 70–78. doi: 10.1109/CVPRW.2015.7301385. [32] HU Sixing, FENG Mengdan, NGUYEN R M H, et al. CVM-Net: Cross-view matching network for image-based ground-to-aerial geo-localization[C]. Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7258–7267. doi: 10.1109/CVPR.2018.00758. [33] ZHU Sijie, SHAH M, and CHEN Chen. TransGeo: Transformer is all you need for cross-view image geo-localization[C]. Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 1152–1161. doi: 10.1109/CVPR52688.2022.00123. [34] MEI Shaohui, LIAN Jiawei, WANG Xiaofei, et al. A comprehensive study on the robustness of deep learning-based image classification and object detection in remote sensing: Surveying and benchmarking[J]. Journal of Remote Sensing, 2024, 4: 0219. doi: 10.34133/remotesensing.0219. [35] SHI Yujiao, LIU Liu, YU Xin, et al. Spatial-aware feature aggregation for cross-view image based geo-localization[C]. Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 905. doi: 10.5555/3454287.3455192. [36] MI Li, XU Chang, CASTILLO-NAVARRO J, et al. ConGeo: Robust cross-view geo-localization across ground view variations[C]. Proceedings of the 18th European Conference on Computer Vision, Milan, Italy, 2024: 214–230. doi: 10.1007/978-3-031-72630-9_13. [37] ZHANG Xiaohan, LI Xingyu, SULTANI W, et al. Cross-view geo-localization via learning disentangled geometric layout correspondence[C]. Proceedings of the 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 3480–3488. doi: 10.1609/aaai.v37i3.25457. [38] REGMI K and BORJI A. Cross-view image synthesis using geometry-guided conditional GANs[J]. Computer Vision and Image Understanding, 2019, 187: 102788. doi: 10.1016/j.cviu.2019.07.008. [39] ZHAO Luying, ZHOU Yang, HU Xiaofei, et al. Street-to-satellite view synthesis for cross-view geo-localization[C]. Proceedings of SPIE 13166, International Conference on Remote Sensing Technology and Survey Mapping, Changchun, China, 2024: 1316608. doi: 10.1117/12.3029089. [40] SHI Yujiao, CAMPBELL D, YU Xin, et al. Geometry-guided street-view panorama synthesis from satellite imagery[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(12): 10009–10022. doi: 10.1109/TPAMI.2022.3140750. [41] XIA Zimin, BOOIJ O, MANFREDI M, et al. Visual cross-view metric localization with dense uncertainty estimates[C]. Proceedings of the 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 90–106. doi: 10.1007/978-3-031-19842-7_6. [42] SONG Zhenbo, ZE Xianghui, LU Jianfeng, et al. Learning dense flow field for highly-accurate cross-view camera localization[C]. Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 3094. doi: 10.5555/3666122.3669216. [43] FERVERS F, BULLINGER S, BODENSTEINER C, et al. Uncertainty-aware vision-based metric cross-view geolocalization[C]. Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 21621–21631. doi: 10.1109/CVPR52729.2023.02071. [44] TANG T Y, DE MARTINI D, BARNES D, et al. RSL-Net: Localising in satellite images from a radar on the ground[J]. IEEE Robotics and Automation Letters, 2020, 5(2): 1087–1094. doi: 10.1109/LRA.2020.2965907. [45] FU Mengyin, ZHU Minzhao, YANG Yi, et al. LiDAR-based vehicle localization on the satellite image via a neural network[J]. Robotics and Autonomous Systems, 2020, 129: 103519. doi: 10.1016/j.robot.2020.103519. [46] CHEN Lei, FENG Changzhou, MA Yunpeng, et al. A review of rigid point cloud registration based on deep learning[J]. Frontiers in Neurorobotics, 2024, 17: 1281332. doi: 10.3389/fnbot.2023.1281332. [47] TANG T Y, DE MARTINI D, and NEWMAN P. Get to the point: Learning lidar place recognition and metric localisation using overhead imagery[C]. Proceedings of Robotics: Science and Systems 2021, Electr network, 2021. doi: 10.15607/RSS.2021.XVII.003. [48] TANG T Y, DE MARTINI D, and NEWMAN P. Point-based metric and topological localisation between lidar and overhead imagery[J]. Autonomous Robots, 2023, 47(5): 595–615. doi: 10.1007/s10514-023-10085-w. [49] GE Chongjian, CHEN Junsong, XIE Enze, et al. MetaBEV: Solving sensor failures for 3D detection and map segmentation[C]. Proceedings of 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 8687–8697. doi: 10.1109/ICCV51070.2023.00801. [50] LIU Liu and LI Hongdong. Lending orientation to neural networks for cross-view geo-localization[C]. Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5617–5626. doi: 10.1109/CVPR.2019.00577. [51] MADDERN W, PASCOE G, LINEGAR C, et al. 1 year, 1000 km: The oxford robotcar dataset[J]. The International Journal of Robotics Research, 2017, 36(1): 3–15. doi: 10.1177/0278364916679498. [52] MADDERN W, PASCOE G, GADD M, et al. Real-time kinematic ground truth for the oxford robotcar dataset[J]. arXiv: 2002.10152, 2020. doi: 10.48550/arXiv.2002.10152. [53] BARNES D, GADD M, MURCUTT P, et al. The oxford radar robotcar dataset: A radar extension to the oxford RobotCar dataset[C]. Proceedings of 2020 IEEE International Conference on Robotics and Automation, Paris, France, 2020: 6433–6438. doi: 10.1109/ICRA40945.2020.9196884. [54] AGARWAL S, VORA A, PANDEY G, et al. Ford multi-AV seasonal dataset[J]. The International Journal of Robotics Research, 2020, 39(12): 1367–1376. doi: 10.1177/0278364920961451. [55] YANG Hongji, LU Xiufan, and ZHU Yingying. Cross-view geo-localization with layer-to-layer transformer[C]. Proceedings of the 35th International Conference on Neural Information Processing Systems, Electr network, 2021: 2222. doi: 10.5555/3540261.3542483 [56] SHI Yujiao, YU Xin, CAMPBELL D, et al. Where am I looking at? Joint location and orientation estimation by cross-view matching[C]. Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 4063–4071. doi: 10.1109/CVPR42600.2020.00412. [57] REGMI K and SHAH M. Bridging the domain gap for ground-to-aerial image matching[C]. Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 470–479. doi: 10.1109/ICCV.2019.00056. [58] CHENG Lei, WANG Teng, LI Jiawen, et al. Offset regression enhanced cross-view feature interaction for ground-to-aerial geo-localization[J]. IEEE Transactions on Intelligent Vehicles, 2025, 10(1): 205–216. doi: 10.1109/TIV.2024.3411098. [59] ZHANG Xiaohan, LI Xingyu, SULTANI W, et al. GeoDTR+: Toward generic cross-view geolocalization via geometric disentanglement[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 10419–10433. doi: 10.1109/TPAMI.2024.3443652. [60] LI Chaoran, YAN Chao, XIANG Xiaojia, et al. AMPLE: Automatic progressive learning for orientation unknown ground-to-aerial geo-localization[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5800115. doi: 10.1109/TGRS.2024.3517654. [61] SHUGAEV M, SEMENOV I, ASHLEY K, et al. ArcGeo: Localizing limited field-of-view images using cross-view matching[C]. Proceedings of 2024 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2024: 208–217. doi: 10.1109/WACV57701.2024.00028. [62] LI Chaoran, YAN Chao, XIANG Xiaojia, et al. HADGEO: Image based 3-DoF cross-view geo-localization with hard sample mining[C]. Proceedings of 2024 IEEE International Conference on Acoustics, Speech and Signal Processing, Seoul, Korea, Republic of, 2024: 3520–3524. doi: 10.1109/ICASSP48485.2024.10445839. [63] YE Junyan, LV Zhutao, LI Weijia, et al. Cross-view image geo-localization with panorama-BEV Co-retrieval network[C]. Proceedings of the 18th European Conference on Computer Vision, Milan, Italy, 2024: 74–90. doi: 10.1007/978-3-031-72913-3_5. [64] ZHU Yingying, YANG Hongji, LU Yuxin, et al. Simple, effective and general: A new backbone for cross-view image geo-localization[J]. arXiv: 2302.01572, 2023. doi: 10.48550/arXiv.2302.01572. [65] PARK J, SUNG C, LEE S, et al. Cross-view geo-localization via effective negative sampling[C]. Proceedings of the 2024 24th International Conference on Control, Automation and Systems, Jeju, Korea, Republic of, 2024: 1078–1083. doi: 10.23919/ICCAS63016.2024.10773330. [66] ZHANG Xiaohan, SULTANI W, and WSHAH S. Cross-view image sequence geo-localization[C]. Proceedings of 2023 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2023: 2913–2922. doi: 10.1109/WACV56688.2023.00293. [67] SHI Yujiao and LI Hongdong. Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image[C]. Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 16989–16999. doi: 10.1109/CVPR52688.2022.01650. [68] LENTSCH T, XIA Zimin, CAESAR H, et al. SliceMatch: Geometry-guided aggregation for cross-view pose estimation[C]. Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 17225–17234. doi: 10.1109/CVPR52729.2023.01652. [69] XIA Zimin, BOOIJ O, and KOOIJ J F P. Convolutional cross-view pose estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(5): 3813–3831. doi: 10.1109/TPAMI.2023.3346924. [70] WANG Xiaolong, XU Runsen, CUI Zuofan, et al. Fine-grained cross-view geo-localization using a correlation-aware homography estimator[C]. Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 234. doi: 10.5555/3666122.3666356. [71] WANG Qiwei, WU Shaoxun, and SHI Yujiao. BevSplat: Resolving height ambiguity via feature-based Gaussian primitives for weakly-supervised cross-view localization[J]. arXiv: 2502.09080, 2025. doi: 10.48550/arXiv.2502.09080. [72] HU Wenmiao, ZHANG Yichen, LIANG Yuxuan, et al. PetalView: Fine-grained location and orientation extraction of street-view images via cross-view local search[C]. Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, Canada, 2023: 56–66. doi: 10.1145/3581783.3612007. [73] TANG T Y, DE MARTINI D, WU Shangzhe, et al. Self-supervised localisation between range sensors and overhead imagery[C]. Proceedings of Robotics: Science and Systems, Corvalis, USA, 2020. doi: 10.15607/RSS.2020.XVI.057. [74] HU Di, ZHANG Kai, YUAN Xia, et al. Real-time road intersection detection in sparse point cloud based on augmented viewpoints beam model[J]. Sensors, 2023, 23(21): 8854. doi: 10.3390/s23218854. -

 下载:
下载:


图(7) / 表(5)
计量
- 文章访问数: 1036
- HTML全文浏览量: 502
- PDF下载量: 103
- 被引次数: 0
