

A Review on Action Recognition Based on Contrastive Learning
-
摘要: 人体动作具有类别数量多、类内/类间差异不均衡等特性,导致动作识别对数据标签数量与质量的依赖度过高,大幅增加了学习模型的训练成本,而对比学习是解决该问题的有效方法之一,近年来基于对比学习的动作识别逐渐成为研究热点。基于此,该文全面论述了对比学习在动作识别中的最新进展,将对比学习的研究分为3大阶段:传统对比学习、基于聚类的对比学习以及不使用负样本的对比学习。在每一阶段,首先概述具有代表性的对比学习模型,然后分析了当前基于该类模型的主要动作识别方法。另外,介绍了主流基准数据集,总结了经典方法在数据集上的性能对比。最后,探讨了对比学习模型在动作识别研究中的局限性和可延展之处。Abstract:
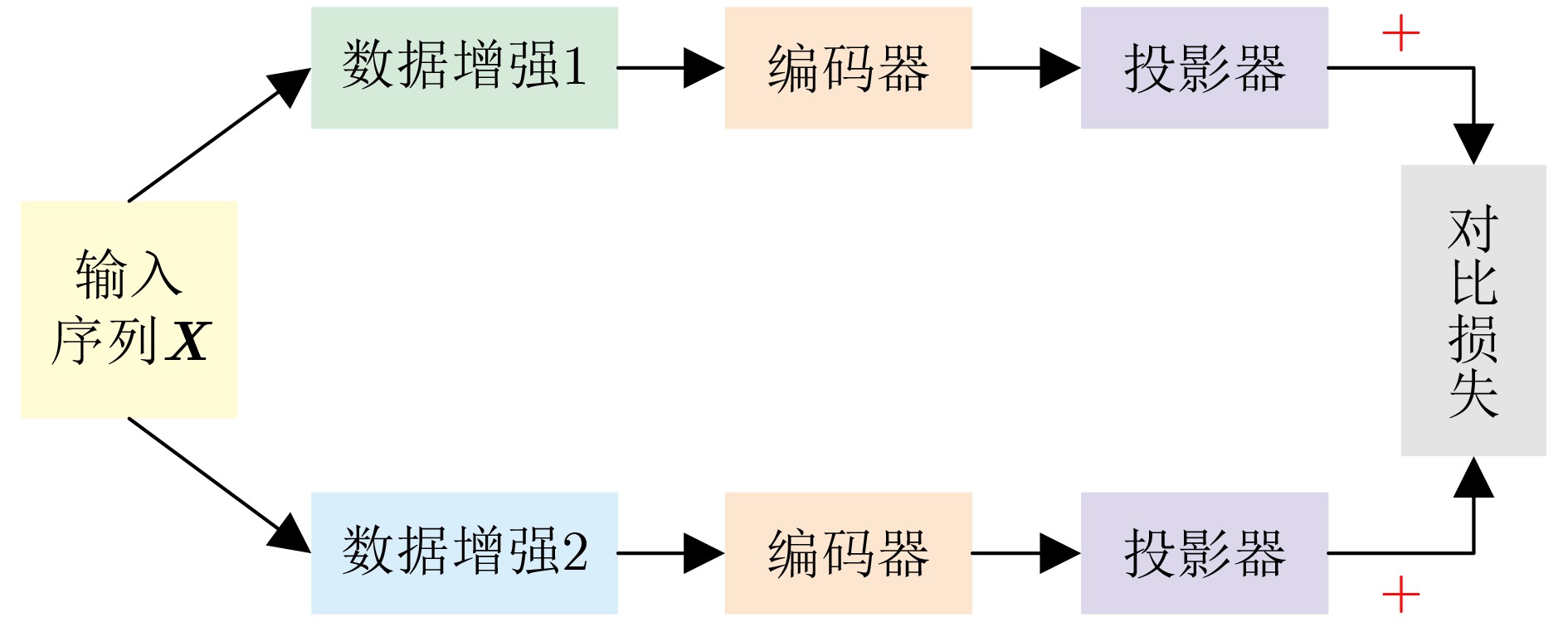
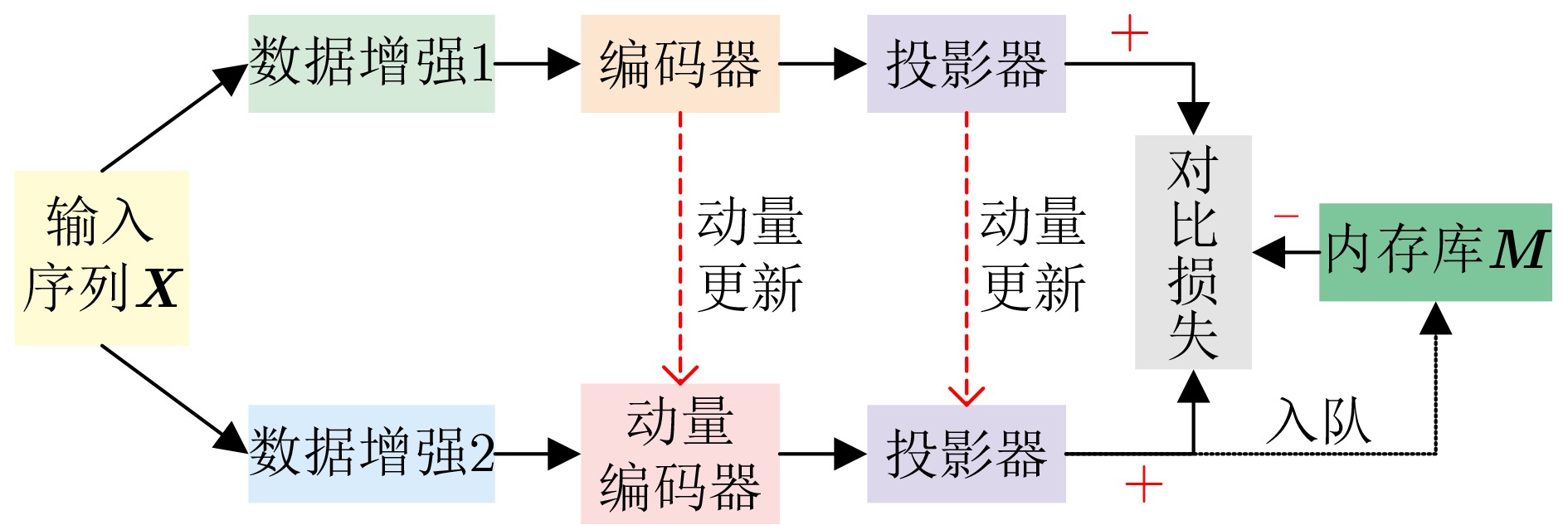
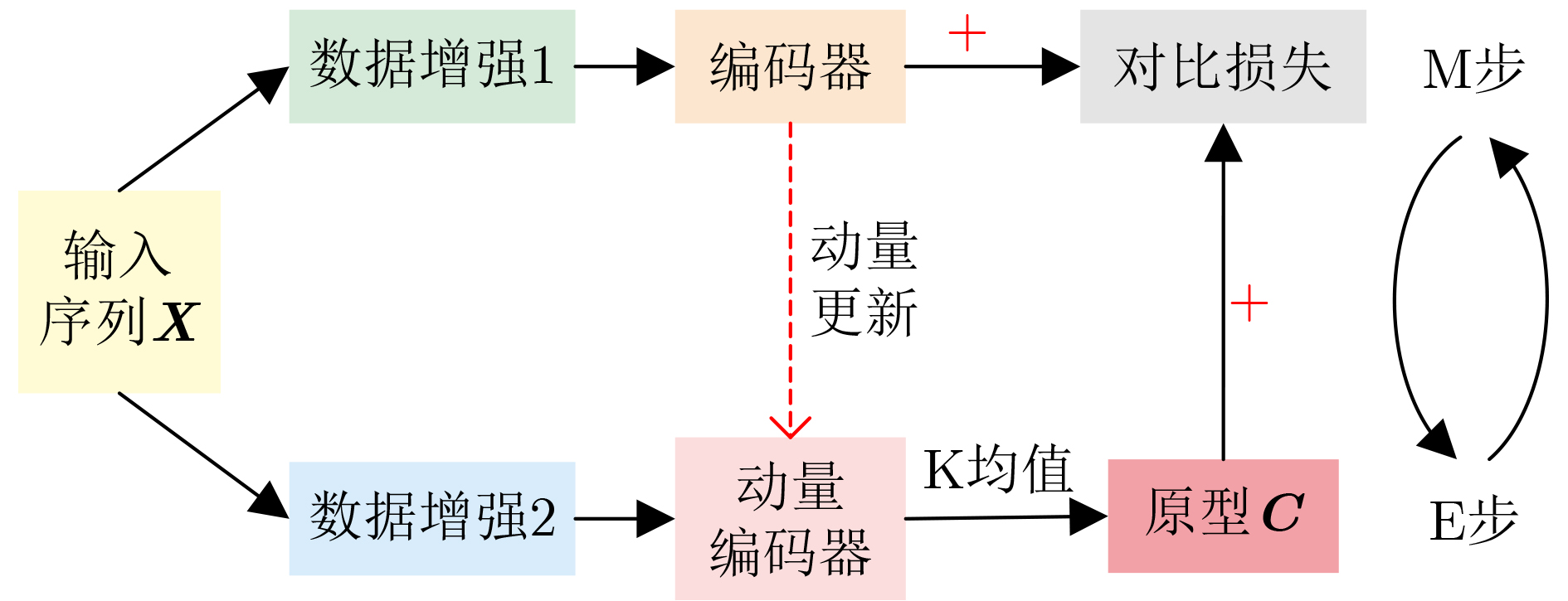
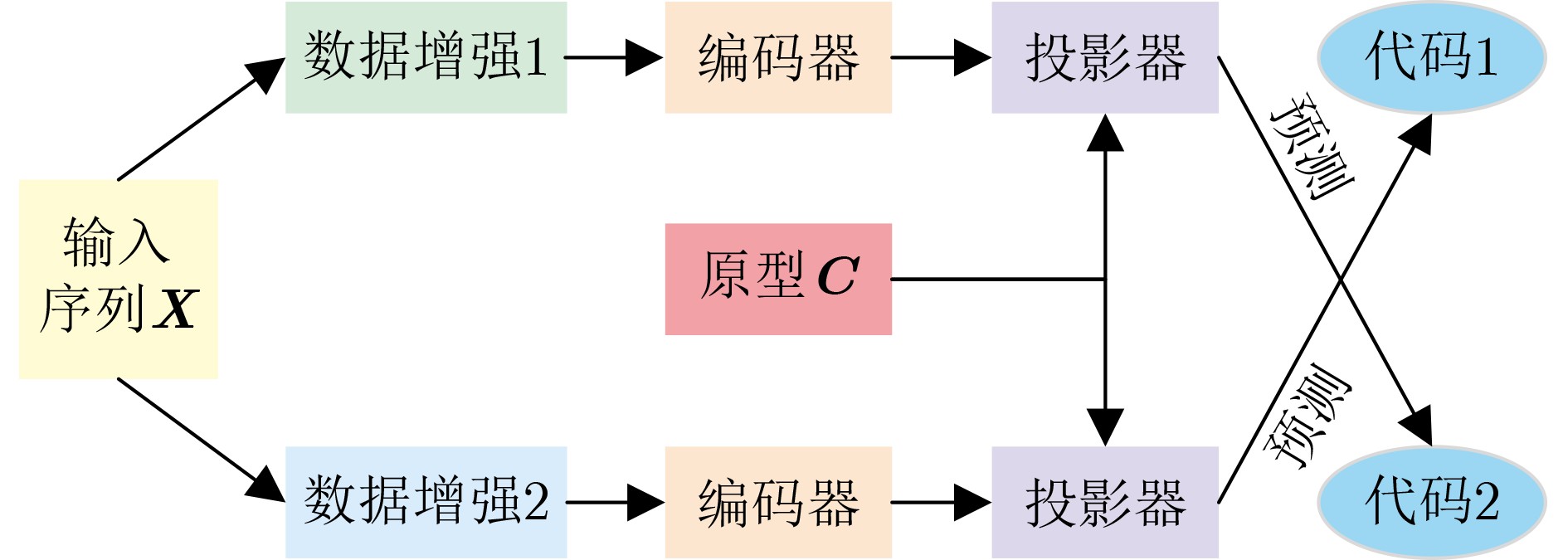
Significance Action recognition is a key topic in computer vision research and has evolved into an interdisciplinary area integrating computer vision, deep learning, and pattern recognition. It seeks to identify human actions by analyzing diverse modalities, including skeleton sequences, RGB images, depth maps, and video frames. Currently, action recognition plays a central role in human-computer interaction, video surveillance, virtual reality, and intelligent security systems. Its broad application potential has led to increasing attention in recent years. However, the task remains challenging due to the large number of action categories and significant intra-class variation. A major barrier to improving recognition accuracy is the reliance on large-scale annotated datasets, which are costly and time-consuming to construct. Contrastive learning offers a promising solution to this problem. Since its initial proposal in 1992, contrastive learning has undergone substantial development, yielding a series of advanced models that have demonstrated strong performance when applied to action recognition. Progress Recent developments in contrastive learning-based action recognition methods are comprehensively reviewed. Contrastive learning is categorized into three stages: traditional contrastive learning, clustering-based contrastive learning, and contrastive learning without negative samples. In the traditional contrastive learning stage, mainstream action recognition approaches are examined with reference to the Simple framework for Contrastive Learning of visual Representations (SimCLR) and Momentum Contrast v2 (MoCo-v2). For SimCLR-based methods, the principles are discussed progressively across three dimensions: temporal contrast, spatio-temporal contrast, and the integration of spatio-temporal and global-local contrast. For MoCo-v2, early applications in action recognition are briefly introduced, followed by methods proposed to enrich the positive sample set. Cross-view complementarity is addressed through a summary of methods incorporating knowledge distillation. For different data modalities, approaches that exploit the hierarchical structure of human skeletons are reviewed. In the clustering-based stage, methods are examined under the frameworks of Prototypical Contrastive Learning (PCL) and Swapping Assignments between multiple Views of the same image (SwAV). For contrastive learning without negative samples, representative methods based on Bootstrap Your Own Latent (BYOL) and Simple Siamese networks (SimSiam) are analyzed. Additionally, the roles of data augmentation and encoder design in the integration of contrastive learning with action recognition are discussed in detail. Data augmentation strategies are primarily dependent on input modality and dimensionality, whereas encoder selection is guided by the characteristics of the input and its representation mapping. Various contrastive loss functions are categorized systematically, and their corresponding formulas are provided. Several benchmark datasets used for evaluation are introduced. Performance results of the reviewed methods are presented under three categories: unsupervised single-stream, unsupervised multi-stream, and semi-supervised approaches. Finally, the methods are compared both horizontally (across techniques) and vertically (across stages). Conclusions In the data augmentation analysis, two dimensions are considered: modality and transformation type. For RGB images or video frames, which contain rich pixel-level information, augmentations such as spatial cropping, horizontal flipping, color jittering, grayscale conversion, and Gaussian blurring are commonly applied. These operations generate varied views of the same content without altering its semantic meaning. For skeleton sequences, augmentation methods are selected to preserve structural integrity. Common strategies include shearing, rotation, scaling, and the use of view-invariant coordinate systems. Skeleton data can also be segmented by individual joints, multiple joints, all joints, or along spatial and temporal axes separately. Regarding dimensional transformations, spatial augmentations include cropping, flipping, rotation, and axis masking, all of which enhance the salience of key spatial features. Temporal transformations apply time-domain cropping and flipping, or resampling to different frame rates, to leverage temporal continuity and short-term action invariance. Spatio-temporal transformations typically use Gaussian blur and Gaussian noise to simulate real-world perturbations while preserving overall action semantics. For encoder selection, temporal modeling commonly uses Gated Recurrent Units (GRUs), Long Short-Term Memory networks (LSTMs), and Sequence-to-Sequence (S2S) models. LSTM is suitable for long-term temporal dependencies, while bidirectional GRU captures temporal patterns in both forward and backward directions, allowing for richer temporal representations. Spatial encoders are typically based on the ResNet architecture. ResNet18, a shallower model, is preferred for small datasets or low-resource scenarios, whereas ResNet50, a deeper model, is better suited for complex feature extraction on larger datasets. For spatio-temporal encoding, ST-GCN are employed to jointly model spatial configurations and temporal dynamics of skeletal actions. In the experimental evaluation, performance comparisons of the reviewed methods yield several constructive insights and summaries, providing guidance for future research on contrastive learning in action recognition. Prospects The limitations and potential developments of action recognition methods based on contrastive learning are discussed from three aspects: runtime efficiency, the quality of negative samples, and the design of contrastive loss functions. -
Key words:
- Action recognition /
- Contrastive learning /
- Contrastive loss /
- Unsupervised learning
-
表 1 所有方法的对比学习结构详情
方法 年份 模态 数据增强 编码器 MS2L 2020 S 时间掩蔽,时间拼图 1层双向GRU PCRP 2021 S - 3层单向GRU AS-CAL 2021 S 旋转、错切、颠倒、高斯噪声、高斯模糊、关节掩蔽、通道掩蔽
空间:错切,时间:裁剪LSTM CrosSCLR 2021 S 不同帧率采样视频 ST-GCN TCL 2021 V 正常增强(空间:错切,时间:裁剪)
极端增强(空间:错切、空间翻转、旋转、轴掩模,ResNet18/ResNet50 AimCLR 2022 S 时间:裁剪、时间翻转,时空:高斯噪声、高斯模糊)
空间:姿态增强、关节抖动
时间:时域裁剪-调整大小ST-GCN CMD 2022 S 时空:先时间增强后空间增强,二者随机组合 3层双向GRU CPM 2022 S 空间:错切,时间:裁剪 ST-GCN Hi-TRS 2022 S 空间:关节替换 时间:置换时序 Hi-TRS MAC-Learning 2023 S - GCN HiCo 2023 S - S2S X-CAR 2023 S 旋转→错切→缩放(带有可学习控制因素) 残差图卷积编码器 PCM3 2023 S 骨架间:时间裁剪-调整大小、错切、关节抖动
骨架内:cutMix[37], ResizeMix[38], Mixup[39]3层双向GRU SDS-CL 2023 S - DSTA[40] ST-Graph CMRL 2023 S 时态子图 ST-GCN TimeBalance 2023 V - ResNet18/ResNet50 VARD 2023 V,A 视频:调大小、裁剪、翻转、颜色抖动、缩放、高斯模糊
音频:替换噪声、增加噪声、基于密度变化的噪声、丢弃C3D/R3D-18 MoLo 2023 V - ResNet50 HaLP 2023 S 同CMD 3层双向GRU Han等人 2023 V,A - V:R(2+1)D-18 A:ResNet-22 ST-CL 2023 S 时间:移动阶段裁剪 空间:观察视点转换 GCN+TCN SkeAttnCLR 2023 S 全局:同CrosSCLR 局部:同SkeleMixCLR[41] ST-GCN HYSP 2023 S 同AimCLR ST-GCN CSTCN 2024 S 同CMD 3层双向GRU Lin等人 2024 S 第1组(正常增强:错切、时间裁剪、关节抖动
极端增强:翻转、旋转、高斯噪声)
第2组(空间:cutMix, ResizeMix, Mixup 时间:洗牌)3层双向GRU  下载: 导出CSV
下载: 导出CSV
表 2 对比学习模型的损失函数
对比学习模型 公式 损失函数类型 SimCLR $ {L}_{\mathrm{N}\mathrm{T}{\text{-}}\mathrm{X}\mathrm{e}\mathrm{n}\mathrm{t}}=-\mathrm{l}\mathrm{n}\dfrac{\mathrm{e}\mathrm{x}\mathrm{p}\left(\dfrac{\mathrm{s}\mathrm{i}\mathrm{m}\left({\boldsymbol{z}}_{{i}},{\boldsymbol{z}}_{{j}}\right)}{\tau }\right)}{\displaystyle\sum _{k=1\mathbb{l}\left[k\ne i\right]}^{2N}\mathrm{e}\mathrm{x}\mathrm{p}\left(\dfrac{\mathrm{s}\mathrm{i}\mathrm{m}\left({\boldsymbol{z}}_{{i}},{\boldsymbol{z}}_{{k}}\right)}{\tau }\right)} $ NT-Xent
(InfoNCE+余弦相似度)MoCo-v2 $ {L}_{\mathrm{I}\mathrm{n}\mathrm{f}\mathrm{o}\mathrm{N}\mathrm{C}\mathrm{E}}=-\mathrm{l}\mathrm{n}\dfrac{\mathrm{e}\mathrm{x}\mathrm{p}\left({\boldsymbol{z}}_{{q}}\cdot \dfrac{{\boldsymbol{z}}_{{k}}}{\tau }\right)}{\mathrm{e}\mathrm{x}\mathrm{p}\left({\boldsymbol{z}}_{{q}}\cdot\dfrac{{\boldsymbol{z}}_{{k}}}{\tau }\right)+\displaystyle\sum\limits_{i=1}^{M}\mathrm{e}\mathrm{x}\mathrm{p}\left({\boldsymbol{z}}_{{q}}\cdot \dfrac{{\boldsymbol{m}}_{{i}}}{\tau }\right)} $ InfoNCE PCL $ {L}_{\mathrm{P}\mathrm{r}\mathrm{o}\mathrm{t}\mathrm{o}\mathrm{N}\mathrm{C}\mathrm{E}}=\dfrac{1}{N}\displaystyle\sum\limits _{n=1}^{N}-\mathrm{l}\mathrm{n}\dfrac{\mathrm{e}\mathrm{x}\mathrm{p}\left({\boldsymbol{v}}_{{n}}\cdot \dfrac{{\boldsymbol{c}}_{{k}}}{{\varphi }_{k}}\right)}{\displaystyle\sum\limits_{i=1}^{K}\mathrm{e}\mathrm{x}\mathrm{p}\left(\dfrac{{\boldsymbol{v}}_{\boldsymbol{n}}{\boldsymbol{c}}_{{i}}}{{\varphi }_{i}}\right)} $ ProtoNCE
(InfoNCE+聚类)SwAV $ \mathcal{l}\left({\boldsymbol{z}}_{{i}},{\boldsymbol{q}}_{{j}}\right)=-\displaystyle\sum\limits_{k}{\boldsymbol{q}}_{{j}}^{\left(k\right)}\mathrm{l}\mathrm{n}\dfrac{\mathrm{e}\mathrm{x}\mathrm{p}\left(\dfrac{{\mathbf{z}}_{{i}}^{\mathrm{T}}{\cdot \boldsymbol{c}}_{{k}}}{\tau }\right)}{\displaystyle\sum\limits_{{{k}}^{{{'}}}}\mathrm{e}\mathrm{x}\mathrm{p}\left(\dfrac{{\boldsymbol{z}}_{{i}}^{\mathrm{T}}{\cdot {\boldsymbol{c}}}_{{k}^{{'}}}}{\tau }\right)} $ InfoNCE+传统交叉熵+聚类 BYOL $ {L}_{i,j}\triangleq {\|\bar{{q}}\left({\boldsymbol{z}}_{{i}}\right)-{\bar{\boldsymbol{z}}_{{j}}}\|}_{2}^{2}=2-2\cdot \dfrac{\left\langle{{q}\left({\boldsymbol{z}}_{{i}}\right),{\boldsymbol{z}}_{{j}}}\right\rangle}{{\|{q}\left({\boldsymbol{z}}_{{i}}\right)\|}_{2}\cdot {\|{\boldsymbol{z}}_{{j}}\|}_{2}} $ MSE SimSiam $ {L}_{\mathrm{S}\mathrm{i}\mathrm{m}\mathrm{S}\mathrm{i}\mathrm{a}\mathrm{m}}=-\left(\dfrac{1}{2}\dfrac{{\boldsymbol{p}}_{{i}}}{{\parallel {\boldsymbol{p}}_{{i}}\parallel }_{2}}\cdot \dfrac{\mathrm{s}\mathrm{g}\left({\boldsymbol{z}}_{{j}}\right)}{{\parallel \mathrm{s}\mathrm{g}\left({\boldsymbol{z}}_{{j}}\right)\parallel }_{2}}+\dfrac{1}{2}\dfrac{{\boldsymbol{p}}_{{j}}}{{\parallel {\boldsymbol{p}}_{{j}}\parallel }_{2}}\cdot \dfrac{\mathrm{s}\mathrm{g}\left({\boldsymbol{z}}_{{i}}\right)}{{\parallel \mathrm{s}\mathrm{g}\left({\boldsymbol{z}}_{{i}}\right)\parallel }_{2}}\right) $ 余弦相似度
下载: 导出CSV
表 3 一些主流的动作识别数据集
数据集 年份 模态 种类数 受试者数 样本数 视点数 HMDB51[46] 2011 RGB 51 - 6 766 - UCF101[47] 2012 RGB 101 - 13 320 - NW-UCLA[48] 2014 RGB, S, D 10 10 1 475 3 NTU-RGB+D[49] 2016 RGB, S, D, IR 60 40 56 880 80 PKUMMD[50] 2017 RGB, S, D, IR 51 66 1 076 3 Kinetics-400[51] 2017 RGB 400 - 306 245 - Something-Something-V2[52] 2017 RGB 174 - 220 847 - NTU-RGB+D 120[53] 2019 RGB, S, D, IR 120 106 114 480 155 Jester[54] 2019 RGB 27 1376 148 092 - Mini-Something-V2[55] 2021 RGB 87 - 94 000 -
下载: 导出CSV
表 4 基于对比学习的无监督动作识别方法的性能比较(单流)(%)
方法 年份 对比学习模型 NTU-RGB+D NTU-RGB+D 120 NW-UCLA PKUMMD xsub xview xsub xset I II MS2L 2020 SimCLR 52.6 - - 76.8 64.9 27.6 AS-CAL 2021 MoCo-v2 58.5 64.8 48.6 49.2 - - - CrosSCLR 2021 MoCo-v2 72.9 79.9 - - - - - PCRP 2021 PCL 54.9 63.4 43.0 44.6 86.1 - - AimCLR 2022 MoCo-v2 74.3 79.7 63.4 63.4 - 83.4 - CMD 2022 MoCo-v2 79.8 86.9 70.3 71.5 - - 43.0 CPM 2022 SimSiam 78.7 84.9 68.7 69.6 - 88.8 48.3 ST-Graph CMRL 2023 SimCLR 74.7 82.6 69.2 68.7 - 83.6 39.9 ST-CL 2023 SimCLR 68.1 69.4 54.2 55.6 81.2 - - HYSP 2023 BYOL 78.2 82.6 61.8 64.6 - 83.8 - SkeAttnCLR 2023 MoCo-v2 80.3 86.1 66.3 74.5 - 87.3 52.9 HiCo 2023 MoCo-v2 81.4 88.8 73.7 74.5 - 89.4 54.7 Hi-TRS 2023 MoCo-v2 86.0 93.0 80.6 81.6 - - - PCM3 2023 MoCo-v2 83.9 90.4 76.5 77.5 - - 51.5 HaLP 2023 MoCo-v2 79.7 86.8 71.1 72.2 - - 43.5 CSTCN 2024 SwAV 83.1 88.7 72.5 77.4 - - 48.0 Lin等人 2024 MoCo-v2 83.9 90.3 75.7 77.2 - 89.7 -
下载: 导出CSV
表 5 基于对比学习的无监督动作识别方法的性能比较(多流)(%)
方法 年份 对比学习模型 NTU-RGB+D NTU-RGB+D 120 PKUMMD xsub xview xsub xset I II 3s-CrosSCLR 2021 MoCo-v2 77.8 83.4 67.9 66.7 - - 3s-AimCLR 2022 MoCo-v2 78.9 83.8 68.2 68.8 87.8 38.5 3s-CMD 2022 MoCo-v2 84.1 90.9 74.7 76.1 - 52.6 3s-CPM 2022 SimSiam 83.2 87.0 73.0 74.0 90.7 51.5 3s-HYSP 2023 BYOL 79.1 85.2 64.5 67.3 88.8 - 3s-SkeAttnCLR 2023 MoCo-v2 82.0 86.5 77.1 80.0 89.5 55.5 Hi-TRS-3S 2023 MoCo-v2 90.0 95.7 85.3 87.4 - - 3s-PCM3 2023 MoCo-v2 87.4 93.1 80.0 81.2 - 58.2 3s-CSTCN 2024 SwAV 85.8 92.0 77.5 78.5 - 53.9 3s-Lin等人 2024 MoCo-v2 87.0 92.9 79.4 81.2 91.7 —
下载: 导出CSV
表 6 基于对比学习的半监督动作识别方法的性能比较(%)
方法 年份 对比学习模型 NTU-RGB+D NW-UCLA PKUMMD xsub xview I II MS2L 2020 SimCLR 65.2 - 70.3 26.1 AS-CAL 2021 MoCo-v2 52.2 57.2 - - - 3s-CrosSCLR 2021 MoCo-v2 74.4 77.8 - 82.9 28.6 3s-AimCLR 2022 MoCo-v2 78.2 81.6 - 86.1 33.4 X-CAR 2022 BYOL 76.1 78.2 68.7 - - 3s-CMD 2022 MoCo-v2 79.0 82.4 - - - CPM 2022 SimSiam 73.0 77.1 - - - CMD 2022 MoCo-v2 75.4 80.2 - - - 3s-HYSP 2023 BYOL 80.5 85.4 - 88.7 - MAC-Learning 2023 SimCLR 74.2 78.5 63.0 - - 3s-SkeAttnCLR 2023 MoCo-v2 81.5 83.8 - - - HiCo 2023 MoCo-v2 73.0 78.3 - - - Hi-TRS-3S 2023 MoCo-v2 77.7 81.1 - - - PCM3 2023 MoCo-v2 77.1 82.8 - - - SDS-CL 2023 SimCLR 77.2 83.0 67.0 - - 3s-CSTCN 2024 SwAV 84.7 87.5 - - - 3s-Lin等人 2024 MoCo-v2 81.7 86.0 - - -
下载: 导出CSV
表 7 来自其余数据集的基于对比学习的动作识别方法的性能比较(%)
方法 年份 对比学习模型 监督模式 UCF101 Kinetics-400 Jester Mini-Something-V2 HMDB51 TCL 2021 SimCLR 半监督 - 30.28(5) 94.64 40.7 - TimeBalance 2023 SimCLR 半监督 81.1 61.2 - - 54.5(60) MoLo 2023 SimCLR 5-样本 95.5 85.6 - 56.4 77.4 VARD 2023 SimSiam 无监督 72.6 - - - 34.9
下载: 导出CSV
-
[1] CHEN Ting, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]. The 37th International Conference on Machine Learning, Vienna, Austria, 2020: 149. [2] CHEN Xinlei, FAN Haoqi, GIRSHICK R, et al. Improved baselines with momentum contrastive learning[EB/OL]. https://doi.org/10.48550/arXiv.2003.04297, 2020. [3] LIN Lilang, SONG Sijie, YANG Wenhan, et al. MS2L: Multi-task self-supervised learning for skeleton based action recognition[C]. The 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 2490–2498. doi: 10.1145/3394171.3413548. [4] SINGH A, CHAKRABORTY O, VARSHNEY A, et al. Semi-supervised action recognition with temporal contrastive learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 10384–10394. doi: 10.1109/CVPR46437.2021.01025. [5] DAVE I R, RIZVE M N, CHEN C, et al. TimeBalance: Temporally-invariant and temporally-distinctive video representations for semi-supervised action recognition[C]. Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 2341–2352. doi: 10.1109/CVPR52729.2023.00232. [6] GAO Xuehao, YANG Yang, ZHANG Yimeng, et al. Efficient spatio-temporal contrastive learning for skeleton-based 3-D action recognition[J]. IEEE Transactions on Multimedia, 2023, 25: 405–417. doi: 10.1109/TMM.2021.3127040. [7] XU Binqian, SHU Xiangbo, ZHANG Jiachao, et al. Spatiotemporal decouple-and-squeeze contrastive learning for semisupervised skeleton-based action recognition[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(8): 11035–11048. doi: 10.1109/TNNLS.2023.3247103. [8] BIAN Cunling, FENG Wei, MENG Fanbo, et al. Global-local contrastive multiview representation learning for skeleton-based action recognition[J]. Computer Vision and Image Understanding, 2023, 229: 103655. doi: 10.1016/j.cviu.2023.103655. [9] WANG Xiang, ZHANG Shiwei, QING Zhiwu, et al. MoLo: Motion-augmented long-short contrastive learning for few-shot action recognition[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 18011–18021. doi: 10.1109/CVPR52729.2023.01727. [10] SHU Xiangbo, XU Binqian, ZHANG Liyan, et al. Multi-granularity anchor-contrastive representation learning for semi-supervised skeleton-based action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(6): 7559–7576. doi: 10.1109/TPAMI.2022.3222871. [11] WU Zhirong, XIONG Yuanjun, YU S X, et al. Unsupervised feature learning via non-parametric instance discrimination[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3733–3742. doi: 10.1109/CVPR.2018.00393. [12] VAN DEN OORD A, LI Yazhe, and VINYALS O. Representation learning with contrastive predictive coding[EB/OL]. http://arxiv.org/abs/1807.03748, 2018. [13] RAO Haocong, XU Shihao, HU Xiping, et al. Augmented skeleton based contrastive action learning with momentum LSTM for unsupervised action recognition[J]. Information Sciences, 2021, 569: 90–109. doi: 10.1016/j.ins.2021.04.023. [14] LI Linguo, WANG Minsi, NI Bingbing, et al. 3D human action representation learning via cross-view consistency pursuit[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 4739–4748. doi: 10.1109/CVPR46437.2021.00471. [15] HUA Yilei, WU Wenhan, ZHENG Ce, et al. Part aware contrastive learning for self-supervised action recognition[C]. The Thirty-Second International Joint Conference on Artificial Intelligence, Macao, China, 2023: 855–863. doi: 10.24963/ijcai.2023/95. [16] GUO Tianyu, LIU Hong, CHEN Zhan, et al. Contrastive learning from extremely augmented skeleton sequences for self-supervised action recognition[C]. The 36th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2022: 762–770. doi: 10.1609/aaai.v36i1.19957. [17] SHAH A, ROY A, SHAH K, et al. HaLP: Hallucinating latent positives for skeleton-based self-supervised learning of actions[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 18846–18856. doi: 10.1109/CVPR52729.2023.01807. [18] MAO Yunyao, ZHOU Wengang, LU Zhenbo, et al. CMD: Self-supervised 3D action representation learning with cross-modal mutual distillation[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 734–752. doi: 10.1007/978-3-031-20062-5_42. [19] ZHANG Jiahang, LIN Lilang, and LIU Jiaying. Prompted contrast with masked motion modeling: Towards versatile 3D action representation learning[C]. The 31st ACM International Conference on Multimedia, Ottawa, Canada, 2023: 7175–7183. doi: 10.1145/3581783.3611774. [20] LIN Lilang, ZHANG Jiahang, and LIU Jiaying. Mutual information driven equivariant contrastive learning for 3D action representation learning[J]. IEEE Transactions on Image Processing, 2024, 33: 1883–1897. doi: 10.1109/TIP.2024.3372451. [21] DONG Jianfeng, SUN Shengkai, LIU Zhonglin, et al. Hierarchical contrast for unsupervised skeleton-based action representation learning[C]. The Thirty-Seventh AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 525–533. doi: 10.1609/aaai.v37i1.25127. [22] CHEN Yuxiao, ZHAO Long, YUAN Jianbo, et al. Hierarchically self-supervised transformer for human skeleton representation learning[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 185–202. doi: 10.1007/978-3-031-19809-0_11. [23] LI Junnan, ZHOU Pan, XIONG Caiming, et al. Prototypical contrastive learning of unsupervised representations[C]. The 9th International Conference on Learning Representations, Virtual Event, Austria, 2021. [24] DEMPSTER A P, LAIRD N M, and RUBIN D B. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the Royal Statistical Society: Series B (Methodological), 1977, 39(1): 1–22. doi: 10.1111/j.2517-6161.1977.tb01600.x. [25] XU Shihao, RAO Haocong, HU Xiping, et al. Prototypical contrast and reverse prediction: Unsupervised skeleton based action recognition[J]. IEEE Transactions on Multimedia, 2023, 25: 624–634. doi: 10.1109/TMM.2021.3129616. [26] ZHOU Huanyu, LIU Qingjie, and WANG Yunhong. Learning discriminative representations for skeleton based action recognition[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 10608–10617. doi: 10.1109/CVPR52729.2023.01022. [27] CARON M, MISRA I, MAIRAL J, et al. Unsupervised learning of visual features by contrasting cluster assignments[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 831. [28] WANG Mingdao, LI Xueming, CHEN Siqi, et al. Learning representations by contrastive spatio-temporal clustering for skeleton-based action recognition[J]. IEEE Transactions on Multimedia, 2024, 26: 3207–3220. doi: 10.1109/TMM.2023.3307933. [29] HAN Haochen, ZHENG Qinghua, LUO Minnan, et al. Noise-tolerant learning for audio-visual action recognition[J]. IEEE Transactions on Multimedia, 2024, 26: 7761–7774. doi: 10.1109/TMM.2024.3371220. [30] GRILL J B, STRUB F, ALTCHÉ F, et al. Bootstrap your own latent a new approach to self-supervised learning[C]. Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1786. [31] XU Binqian, SHU Xiangbo, and SONG Yan. X-invariant contrastive augmentation and representation learning for semi-supervised skeleton-based action recognition[J]. IEEE Transactions on Image Processing, 2022, 31: 3852–3867. doi: 10.1109/TIP.2022.3175605. [32] FRANCO L, MANDICA P, MUNJAL B, et al. Hyperbolic self-paced learning for self-supervised skeleton-based action representations[C]. The Eleventh International Conference on Learning Representations, Kigali, Rwanda, 2023: 1–5. [33] KUMAR M P, PACKER B, and KOLLER D. Self-paced learning for latent variable models[C]. The 24th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2010: 1189–1197. [34] CHEN Xinlei and HE Kaiming. Exploring simple siamese representation learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 15745–15753. doi: 10.1109/CVPR46437.2021.01549. [35] ZHANG Haoyuan, HOU Yonghong, ZHANG Wenjing, et al. Contrastive positive mining for unsupervised 3D action representation learning[C]. Proceedings of the 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 36–51. doi: 10.1007/978-3-031-19772-7_3. [36] LIN Wei, DING Xinghao, HUANG Yue, et al. Self-supervised video-based action recognition with disturbances[J]. IEEE Transactions on Image Processing, 2023, 32: 2493–2507. doi: 10.1109/TIP.2023.3269228. [37] YUN S, HAN D, CHUN S, et al. CutMix: Regularization strategy to train strong classifiers with localizable features[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 2019: 6022–6031. doi: 10.1109/ICCV.2019.00612. [38] REN Sucheng, WANG Huiyu, GAO Zhengqi, et al. A simple data mixing prior for improving self-supervised learning[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 14575–14584. doi: 10.1109/CVPR52688.2022.01419. [39] ZHANG Hongyi, CISSE M, DAUPHIN Y N, et al. mixup: Beyond empirical risk minimization[C]. The 6th International Conference on Learning Representations, Vancouver, Canada, 2018. [40] SHI Lei, ZHANG Yifan, CHENG Jian, et al. Decoupled spatial-temporal attention network for skeleton-based action-gesture recognition[C]. Proceedings of the 15th Asian Conference on Computer Vision, Kyoto, Japan, 2020: 38–53. doi: 10.1007/978-3-030-69541-5_3. [41] ZHAN Chen, LIU Hong, GUO Tianyu, et al. Contrastive learning from spatio-temporal mixed skeleton sequences for self-supervised skeleton-based action recognition[EB/OL]. https://arxiv.org/abs/2207.03065, 2022. [42] LEE I, KIM D, KANG S, et al. Ensemble deep learning for skeleton-based action recognition using temporal sliding LSTM networks[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 1012–1020. doi: 10.1109/ICCV.2017.115. [43] YAN Sijie, XIONG Yuanjun, and LIN Dahua. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]. The 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018: 912. doi: 10.1609/aaai.v32i1.12328. [44] LE-KHAC P H, HEALY G, and SMEATON A F. Contrastive representation learning: A framework and review[J]. IEEE Access, 2020, 8: 193907–193934. doi: 10.1109/ACCESS.2020.3031549. [45] 张重生, 陈杰, 李岐龙, 等. 深度对比学习综述[J]. 自动化学报, 2023, 49(1): 15–39. doi: 10.16383/j.aas.c220421.ZHANG Chongsheng, CHEN Jie, LI Qilong, et al. Deep contrastive learning: A survey[J]. Acta Automatica Sinica, 2023, 49(1): 15–39. doi: 10.16383/j.aas.c220421. [46] KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: A large video database for human motion recognition[C]. 2011 International Conference on Computer Vision, Barcelona, Spain, 2011: 2556–2563. doi: 10.1109/ICCV.2011.6126543. [47] SOOMRO K, ZAMIR A R, and SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[EB/OL]. https://doi.org/10.48550/arXiv.1212.0402, 2012. [48] WANG Jiang, NIE Xiaohan, XIA Yin, et al. Cross-view action modeling, learning, and recognition[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 2649–2656. doi: 10.1109/CVPR.2014.339. [49] SHAHROUDY A, LIU Jun, NG T-T, et al. NTU RGB+D: A large scale dataset for 3D human activity analysis[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1010–1019. doi: 10.1109/CVPR.2016.115. [50] LIU Chunhui, HU Yueyu, LI Yanghao, et al. PKU-MMD: A large scale benchmark for skeleton-based human action understanding[C]. Proceedings of the Workshop on Visual Analysis in Smart and Connected Communities, Mountain View, USA, 2017: 1–8. doi: 10.1145/3132734.3132739. [51] KAY W, CARREIRA J, SIMONYAN K, et al. The Kinetics human action video dataset[EB/OL]. http://arxiv.org/abs/1705.06950, 2017. [52] GOYAL R, KAHOU S E, MICHALSKI V, et al. The “Something Something” video database for learning and evaluating visual common sense[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 5843–5851. doi: 10.1109/ICCV.2017.622. [53] LIU Jun, SHAHROUDY A, PEREZ M, et al. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2684–2701. doi: 10.1109/TPAMI.2019.2916873. [54] MATERZYNSKA J, BERGER G, BAX I, et al. The Jester dataset: A large-scale video dataset of human gestures[C]. 2019 IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Korea, 2019: 2874–2882. doi: 10.1109/ICCVW.2019.00349. [55] CHEN C F R, PANDA R, RAMAKRISHNAN K, et al. Deep analysis of CNN-based spatio-temporal representations for action recognition[C]. Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 6161–6171. doi: 10.1109/CVPR46437.2021.00610. -


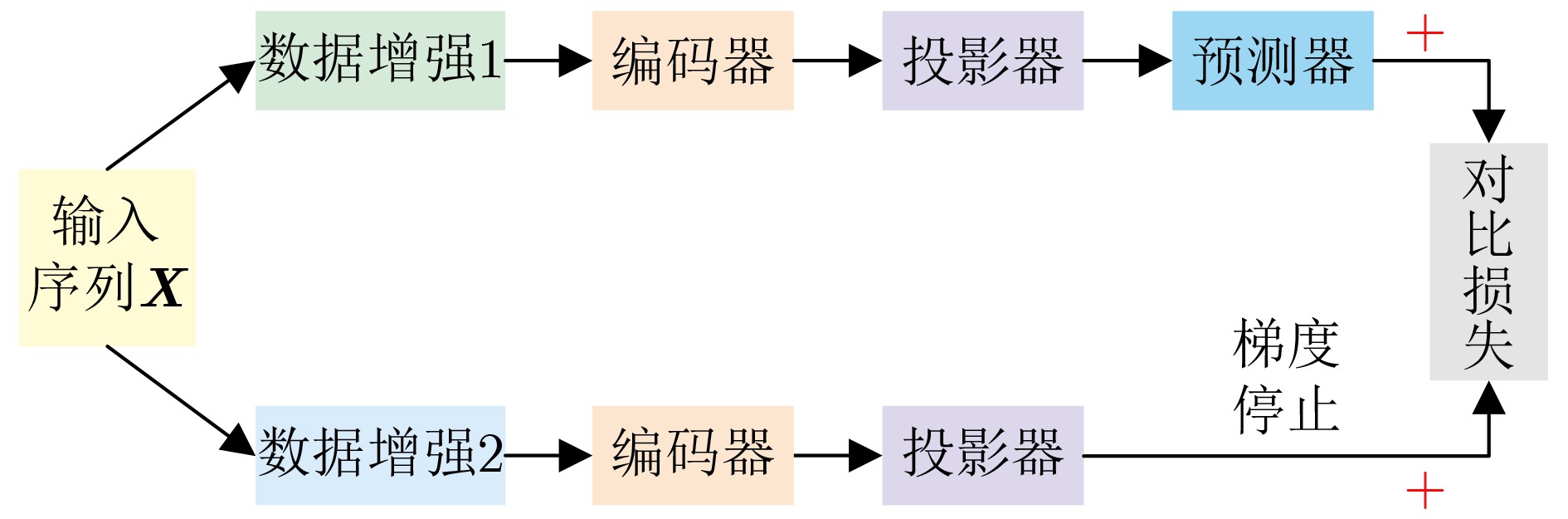


图(6) / 表(7)
计量
- 文章访问数: 1086
- HTML全文浏览量: 834
- PDF下载量: 103
- 被引次数: 0
 下载:
下载:
