

LFTA:Lightweight Feature Extraction and Additive Attention-based Feature Matching Method
-
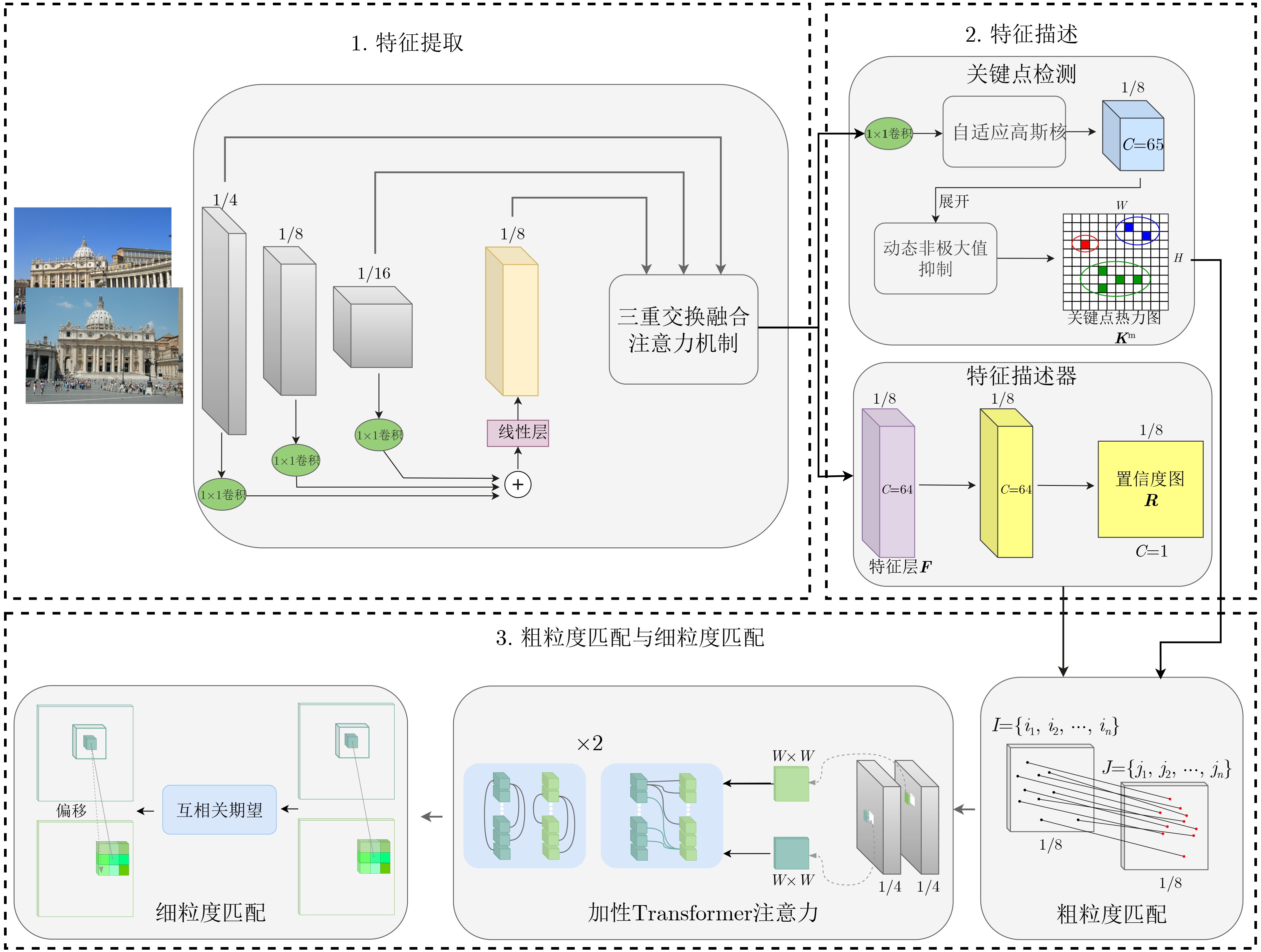
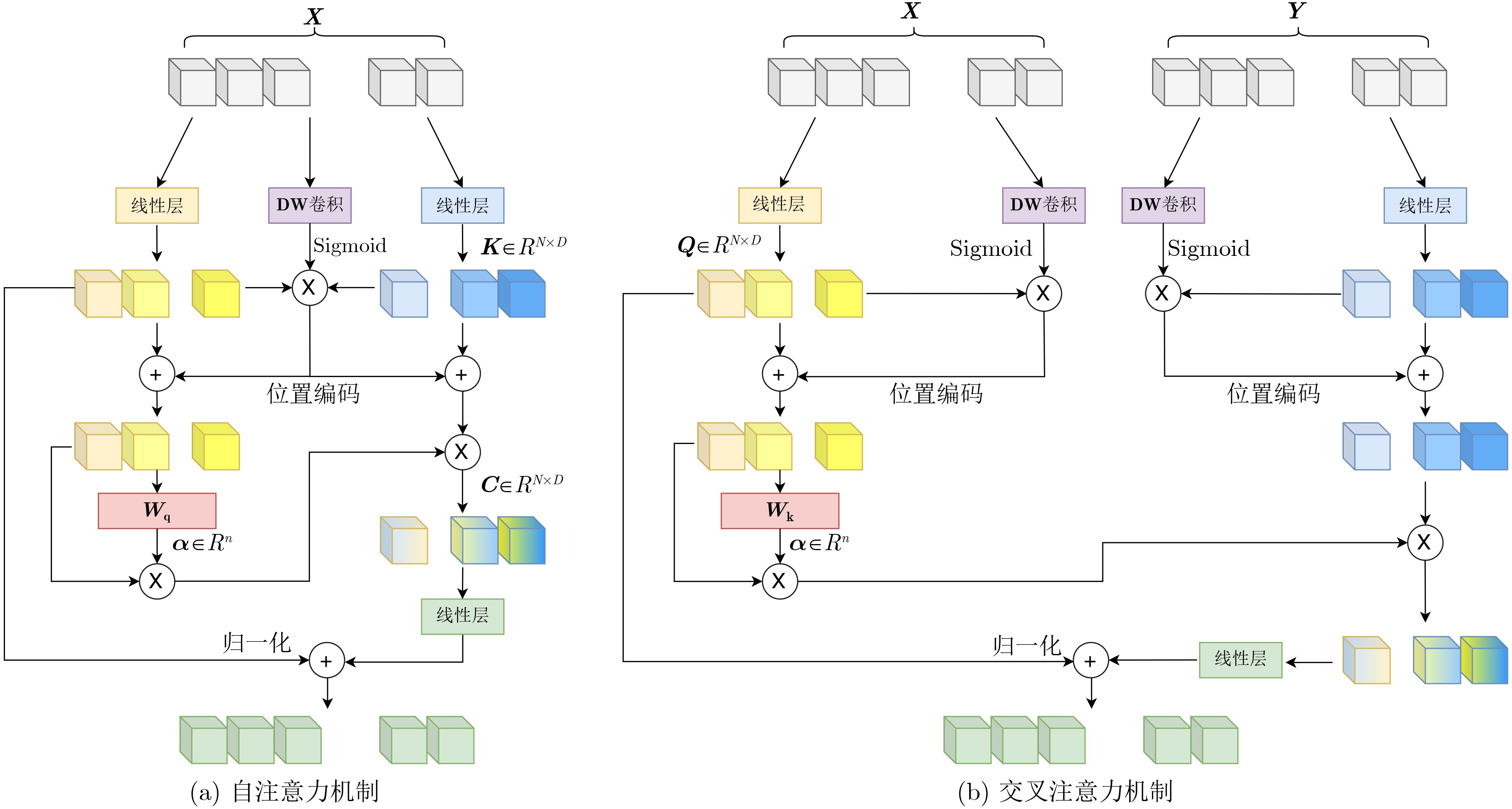
摘要: 近年来,特征匹配技术在计算机视觉任务中得到了广泛应用,如3维重建、视觉定位和即时定位与地图构建(SLAM)等。然而,现有匹配算法面临精度与效率的权衡困境:高精度方法常因复杂模型设计导致计算复杂度攀升,难以满足实时需求;而快速匹配策略通过特征简化或近似计算虽实现亚线性时间复杂度,却因表征能力受限与误差累积,无法达到实际应用中的精度要求。为此,该文提出一种基于加性注意力的轻量化特征匹配方法—LFTA。该方法通过轻量化多尺度特征提取网络生成高效特征表示,并引入三重交换融合注意力机制,提升了在复杂场景下的特征鲁棒性;同时提出了自适应高斯核生成关键点热力图和动态非极大值抑制算法,以提高关键点的提取精度;此外,该文设计了结合加性Transformer注意力机制和深度可分离卷积位置编码的轻量化模块,对粗粒度匹配结果进行微调,从而生成高精度的像素级匹配点对。为了验证所提方法的有效性,在MegaDepth和ScanNet两个公开数据集上进行了实验评估,并通过消融实验和对比实验验证了各模块的贡献和模型的综合性能。实验结果表明,所提算法在姿态估计上的性能相比于轻量化的算法有显著提升,且与性能较高的算法相比推理时间有显著下降,实现了高效性与高精度的平衡。Abstract:
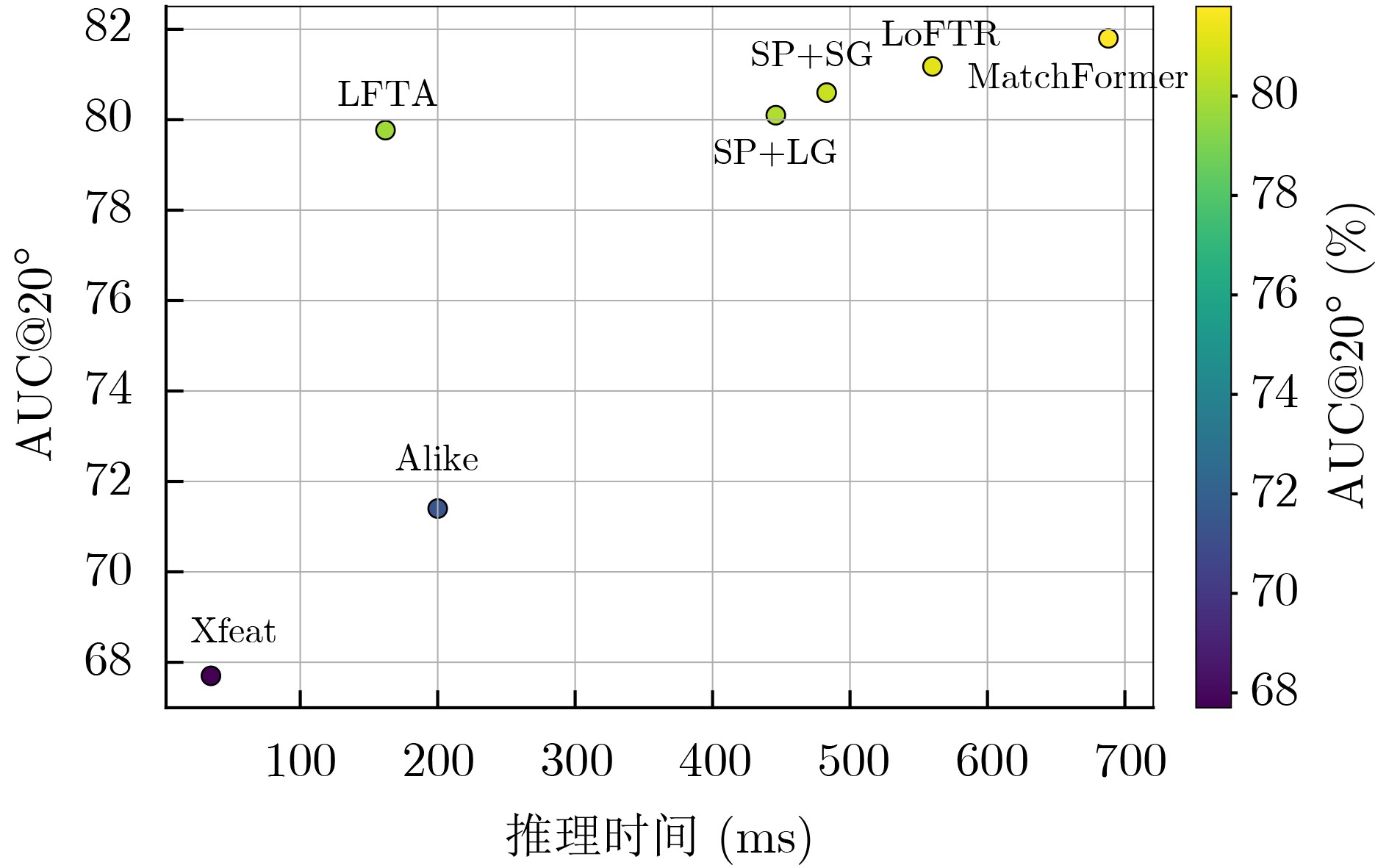
Objective With the rapid development of deep learning, feature matching has advanced considerably, particularly in computer vision. This progress has led to improved performance in tasks such as 3D reconstruction, motion tracking, and image registration, all of which depend heavily on accurate feature matching. Nevertheless, current techniques often face a trade-off between accuracy and computational efficiency. Some methods achieve high matching accuracy and robustness but suffer from slow processing due to algorithmic complexity. Others offer faster processing but compromise matching accuracy, especially under challenging conditions such as dynamic scenes, low-texture environments, or large view-angle variations. The key challenge is to provide a balanced solution that ensures both accuracy and efficiency. To address this, this paper proposes a Lightweight Feature exTraction and matching Algorithm (LFTA), which integrates an additive attention mechanism within a lightweight architecture. LFTA enhances the robustness and accuracy of feature matching while maintaining the computational efficiency required for real-time applications. Methods LFTA utilizes a multi-scale feature extraction network designed to capture information from images at different levels of detail. A triple-exchange fusion attention mechanism merges information across multiple dimensions, including spatial and channel features, allowing the network to learn more robust feature representations. This mechanism improves matching accuracy, particularly in scenarios with sparse textures or large viewpoint variations. LFTA further integrates an adaptive Gaussian kernel to dynamically generate keypoint heatmaps. The kernel adjusts according to local feature strength, enabling accurate keypoint extraction in both high-response and low-response regions. To improve keypoint precision, a dynamic Non-Maximum Suppression (NMS) strategy is applied, which adapts to varying keypoint densities across different image regions. This approach reduces redundancy and improves detection accuracy. In the final stage, LFTA employs a lightweight module with an additive Transformer attention mechanism to refine feature matching. This module strengthens feature fusion while reducing computational complexity through depthwise separable convolutions. These operations substantially lower parameter count and computational cost without affecting performance. Through this combination of techniques, LFTA achieves accurate pixel-level matching with fast inference times, making it suitable for real-time applications. Results and Discussions The performance of LFTA is assessed through extensive experiments conducted on two widely used and challenging datasets: MegaDepth and ScanNet. These datasets offer diverse scenarios for evaluating the robustness and efficiency of feature matching methods, including variations in texture, environmental complexity, and viewpoint changes. The results indicate that LFTA achieves higher accuracy and computational efficiency than conventional feature matching approaches. On the MegaDepth dataset, an AUC@20° of 79.77% is attained, which is comparable to or exceeds state-of-the-art methods such as LoFTR. Notably, this level of performance is achieved while reducing inference time by approximately 70%, supporting the suitability of LFTA for practical, time-sensitive applications. When compared with other efficient methods, including Xfeat and Alike, LFTA demonstrates superior matching accuracy with only a marginal increase in inference time, proving its competitive performance in both accuracy and speed. The improvement in accuracy is particularly apparent in scenarios characterized by sparse textures or large viewpoint variations, where traditional methods often fail to maintain robustness. Ablation studies confirm the contribution of each LFTA component. Exclusion of the triple-exchange fusion attention mechanism results in a significant reduction in accuracy, indicating its function in managing complex feature interactions. Similarly, both the adaptive Gaussian kernel and dynamic NMS are found to improve keypoint extraction, emphasizing their roles in enhancing overall matching precision. Conclusions The LFTA algorithm addresses the long-standing trade-off between feature extraction accuracy and computational efficiency in feature matching. By integrating the triple-exchange fusion attention mechanism, adaptive Gaussian kernels, and lightweight fine-tuning strategies, LFTA achieves high matching accuracy in dynamic and complex environments while maintaining low computational requirements. Experimental results on the MegaDepth and ScanNet datasets demonstrate that LFTA performs well under typical feature matching conditions and shows clear advantages in more challenging scenarios, including low-texture regions and large viewpoint variations. Given its efficiency and robustness, LFTA is well suited for real-time applications such as Augmented Reality (AR), autonomous driving, and robotic vision, where fast and accurate feature matching is essential. Future work will focus on further optimizing the algorithm for high-resolution images and more complex scenes, with the potential integration of hardware acceleration to reduce computational overhead. The method could also be extended to other computer vision tasks, including image segmentation and object detection, where reliable feature matching is required. -
表 2 在ScanNet数据集上的性能评估
模型 姿态估计(%) 推理时间(ms) auc@5° auc@10° auc@20° Xfeat 16.70 32.60 45.24 32 LoFTR 22.06 40.80 57.62 554 Alike 8.00 16.40 25.90 197 MatchFormer 22.89 42.68 60.55 681 SP+SG 14.80 30.80 47.50 443 SP+LG 15.47 32.22 50.13 476 LFTA 20.91 37.51 54.89 154  下载: 导出CSV
下载: 导出CSV
表 3 在MegaDepth数据集上的消融实验
方法 三重交换融合注意力机制 自适应模块 DWP-AT MegaDepth(%) 推理时间(ms) auc@5° auc@10° auc@20° 基准 × × × 42.10 56.20 67.30 34 只有三重交换融合注意力机制 √ × × 43.56 57.63 68.74 62 只有自适应模块 × √ × 42.90 56.82 68.13 38 只有 DWP-AT × × √ 51.48 66.64 78.88 102 没有 DWP-AT √ √ × 43.78 57.89 68.91 67 没有三重交换融合注意力机制 × √ √ 51.24 67.13 79.03 107 没有自适应模块 √ × √ 51.50 67.52 79.41 153 LFTA √ √ √ 51.94 67.81 79.77 162
下载: 导出CSV
表 4 在ScanNet数据集上的消融实验
方法 三重交换融合注意力机制 自适应模块 DWP-AT ScanNet(%) 推理时间(ms) auc@5° auc@10° auc@20° 基准 × × × 16.20 32.10 44.80 29 只有三重交换融合注意力机制 √ × × 17.45 33.24 46.60 57 只有自适应模块 × √ × 17.14 33.11 45.83 36 只有DWP-AT × × √ 20.13 36.85 53.95 97 没有DWP-AT √ √ × 17.71 34.14 47.23 62 没有三重交换融合注意力机制 × √ √ 20.40 37.15 54.26 99 没有自适应模块 √ × √ 20.72 37.26 54.67 149 LFTA √ √ √ 20.91 37.51 54.89 154
下载: 导出CSV
-
[1] ZHANG Jian, XIE Hongtu, ZHANG Lin, et al. Information extraction and three-dimensional contour reconstruction of vehicle target based on multiple different pitch-angle observation circular synthetic aperture radar data[J]. Remote Sensing, 2024, 16(2): 401. doi: 10.3390/rs16020401. [2] LUO Haitao, ZHANG Jinming, LIU Xiongfei, et al. Large-scale 3D reconstruction from multi-view imagery: A comprehensive review[J]. Remote Sensing, 2024, 16(5): 773. doi: 10.3390/rs16050773. [3] GAO Lei, ZHAO Yingbao, HAN Jingchang, et al. Research on multi-view 3D reconstruction technology based on SFM[J]. Sensors, 2022, 22(12): 4366. doi: 10.3390/s22124366. [4] ZHANG He, JIN Lingqiu, and YE Cang. An RGB-D camera based visual positioning system for assistive navigation by a robotic navigation aid[J]. IEEE/CAA Journal of Automatica Sinica, 2021, 8(8): 1389–1400. doi: 10.1109/JAS.2021.1004084. [5] YAN Chi, QU Delin, XU Dan, et al. GS-SLAM: Dense visual slam with 3D Gaussian splatting[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 19595–19604. doi: 10.1109/CVPR52733.2024.01853. [6] WANG Hengyi, WANG Jingwen, and AGAPITO L. CO-SLAM: Joint coordinate and sparse parametric encodings for neural real-time slam[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 13293–13302. doi: 10.1109/CVPR52729.2023.01277. [7] PANCHAL P M, PANCHAL S R, and SHAH S K. A comparison of SIFT and SURF[J]. International Journal of Innovative Research in Computer and Communication Engineering, 2013, 1(2): 323–327. [8] 余淮, 杨文. 一种无人机航拍影像快速特征提取与匹配算法[J]. 电子与信息学报, 2016, 38(3): 509–516. doi: 10.11999/JEIT150676.YU Huai and YANG Wen. A fast feature extraction and matching algorithm for unmanned aerial vehicle images[J]. Journal of Electronics & Information Technology, 2016, 38(3): 509–516. doi: 10.11999/JEIT150676. [9] 陈抒瑢, 李勃, 董蓉, 等. Contourlet-SIFT特征匹配算法[J]. 电子与信息学报, 2013, 35(5): 1215–1221. doi: 10.3724/SP.J.1146.2012.01132.CHEN Shurong, LI Bo, DONG Rong, et al. Contourlet-SIFT feature matching algorithm[J]. Journal of Electronics & Information Technology, 2013, 35(5): 1215–1221. doi: 10.3724/SP.J.1146.2012.01132. [10] DETONE D, MALISIEWICZ T, and RABINOVICH A. SuperPoint: Self-supervised interest point detection and description[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, USA, 2018: 337–33712. doi: 10.1109/CVPRW.2018.00060. [11] ZHAO Xiaoming, WU Xingming, MIAO Jinyu, et al. ALIKE: Accurate and lightweight keypoint detection and descriptor extraction[J]. IEEE Transactions on Multimedia, 2023, 25: 3101–3112. doi: 10.1109/TMM.2022.3155927. [12] JAKUBOVIĆ A and VELAGIĆ J. Image feature matching and object detection using brute-force matchers[C]. 2018 International Symposium ELMAR, Zadar, Croatia, 2018: 83–86. doi: 10.23919/ELMAR.2018.8534641. [13] SARLIN P E, DETONE D, MALISIEWICZ T, et al. SuperGlue: Learning feature matching with graph neural networks[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 4937–4946. doi: 10.1109/CVPR42600.2020.00499. [14] LINDENBERGER P, SARLIN P E, and POLLEFEYS M. LightGlue: Local feature matching at light speed[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 17581–17592. doi: 10.1109/ICCV51070.2023.01616. [15] SHI Yan, CAI Junxiong, SHAVIT Y, et al. ClusterGNN: Cluster-based coarse-to-fine graph neural network for efficient feature matching[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 12507–12516. doi: 10.1109/CVPR52688.2022.01219. [16] POTJE G, CADAR F, ARAUJO A, et al. XFeat: Accelerated features for lightweight image matching[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 2682–2691. doi: 10.1109/CVPR52733.2024.00259. [17] SUN Jiaming, SHEN Zehong, WANG Yuang, et al. LoFTR: Detector-free local feature matching with transformers[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 8918–8927. doi: 10.1109/CVPR46437.2021.00881. [18] CHEN Hongkai, LUO Zixin, ZHOU Lei, et al. ASpanFormer: Detector-free image matching with adaptive span transformer[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 20–36. doi: 10.1007/978-3-031-19824-3_2. [19] WANG Qing, ZHANG Jiaming, YANG Kailun, et al. MatchFormer: Interleaving attention in transformers for feature matching[C]. The 16th Asian Conference on Computer Vision, Macao, China, 2022: 256–273. doi: 10.1007/978-3-031-26313-2_16. [20] YU Jiahuan, CHANG Jiahao, HE Jianfeng, et al. Adaptive spot-guided transformer for consistent local feature matching[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 21898–21908. doi: 10.1109/CVPR52729.2023.02097. -

 下载:
下载:





图(6) / 表(4)
计量
- 文章访问数: 1101
- HTML全文浏览量: 1128
- PDF下载量: 111
- 被引次数: 0
