

A Multi-Agent Path Finding Strategy Combining Selective Communication and Conflict Resolution
-
摘要: 在动态密集场景中,路径规划方法面临计算复杂度高、系统可扩展性差等问题,尤其在障碍物密度大、智能体数量多的结构化环境中,易出现寻路效果不佳及碰撞死锁等现象。针对复杂场景下多智能体路径规划通信与动态冲突的双重挑战,该文提出一种基于选择性通信与冲突解决的多智能体路径规划方式(DCCPR)。该方法构建动态联合屏蔽补充决策机制,通过融合A*算法生成的期望路径与双惩罚项强化学习,在实现任务目标的同时减少路径偏差;引入基于多层次动态加权的优先级冲突解决策略,结合初始距离优先级、任务Q值动态调整及轮流通行机制,有效处理系统中冲突情境。通过在训练期间从未见过的结构化地图上测试,相比决策因果通信(DCC)任务成功率提高约79%,平均回合步长降低了46.4%。Abstract:
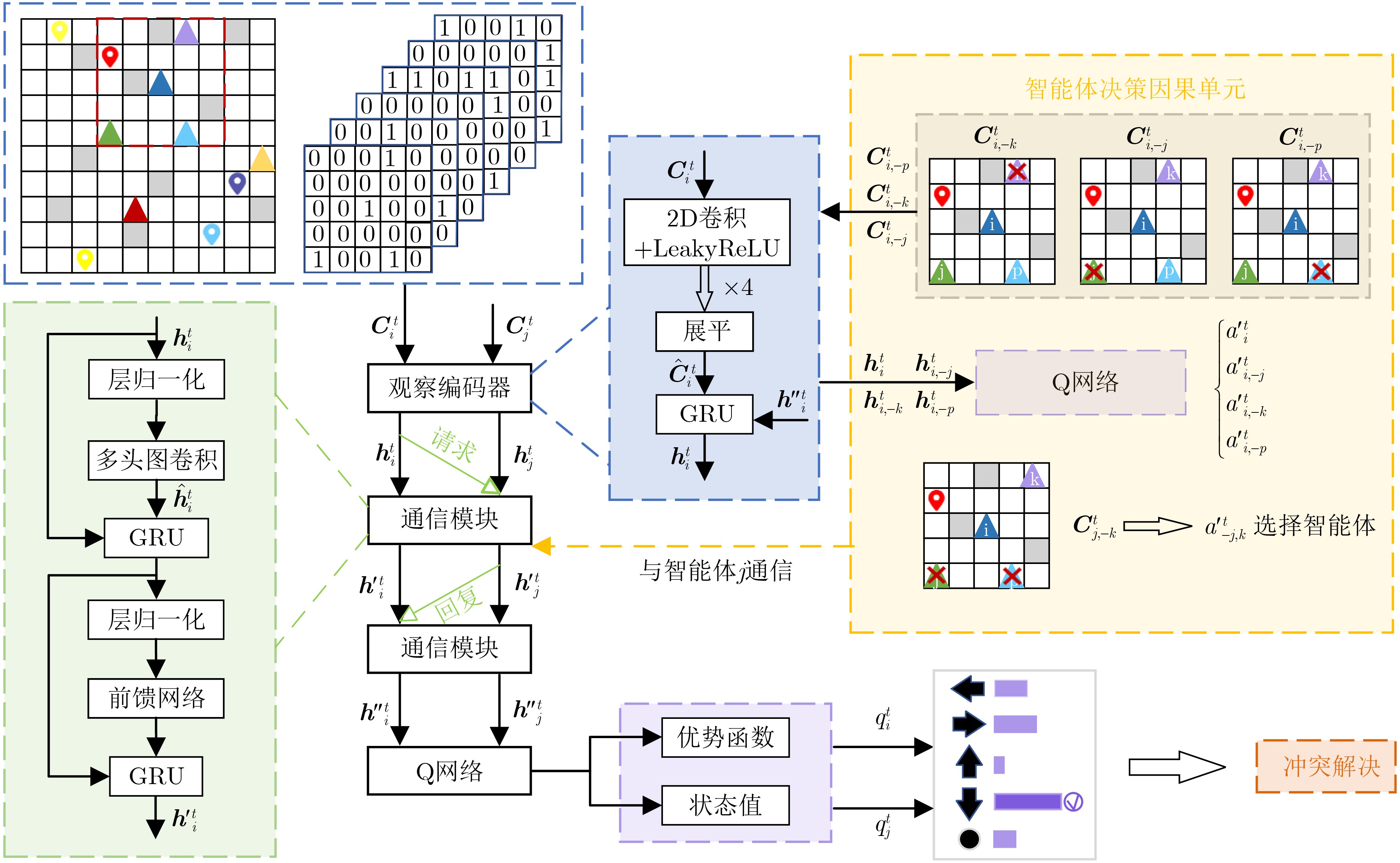
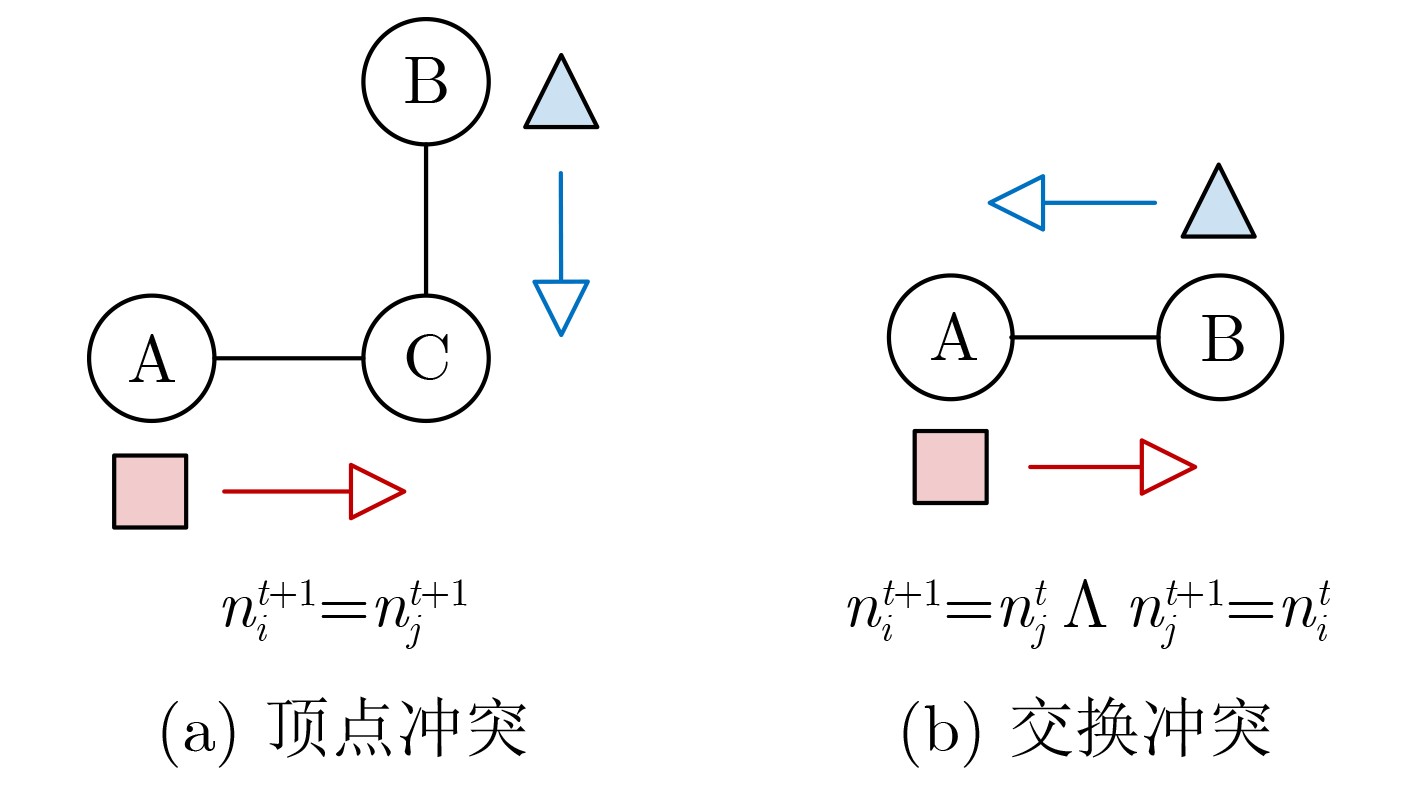
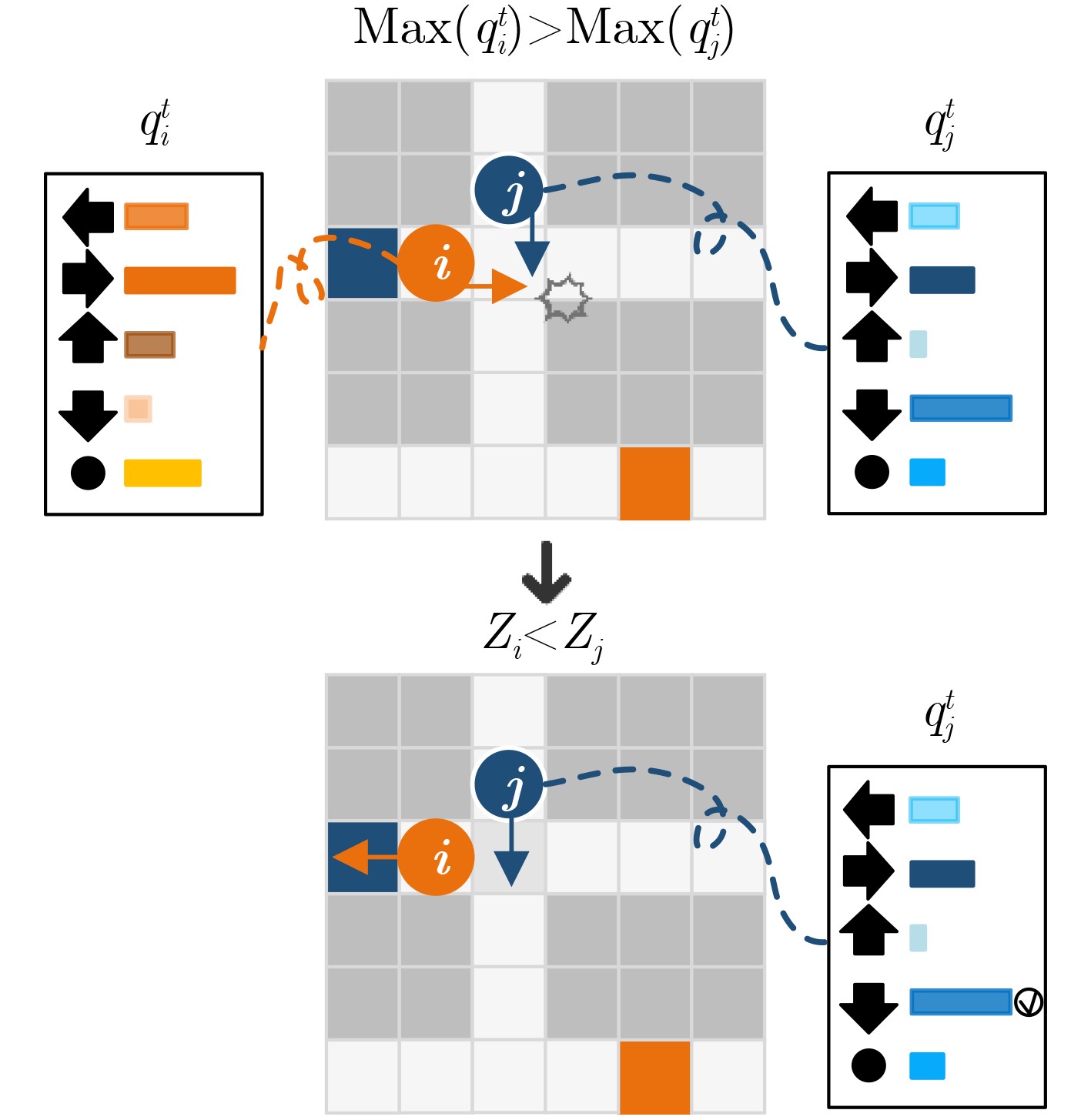
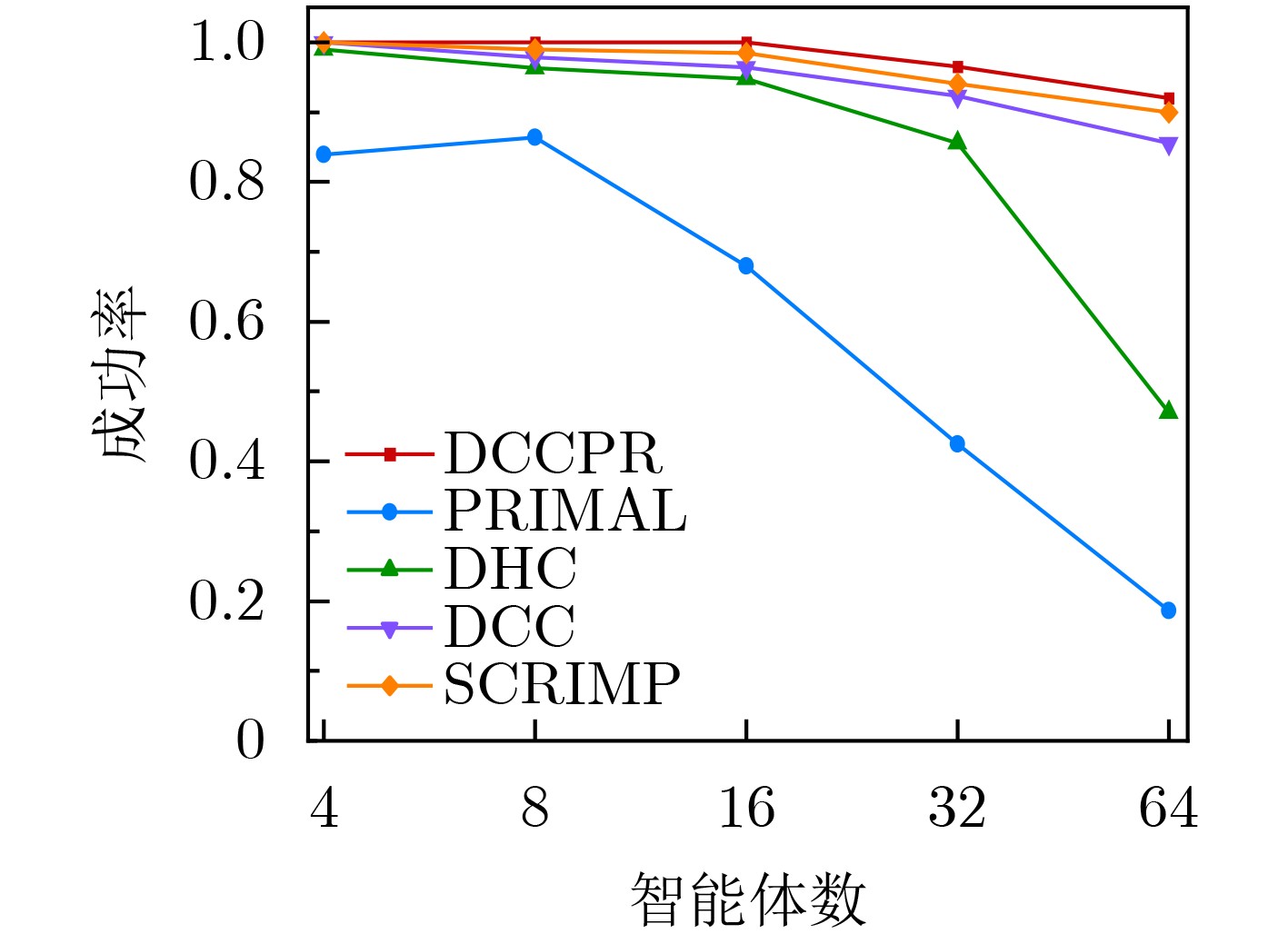
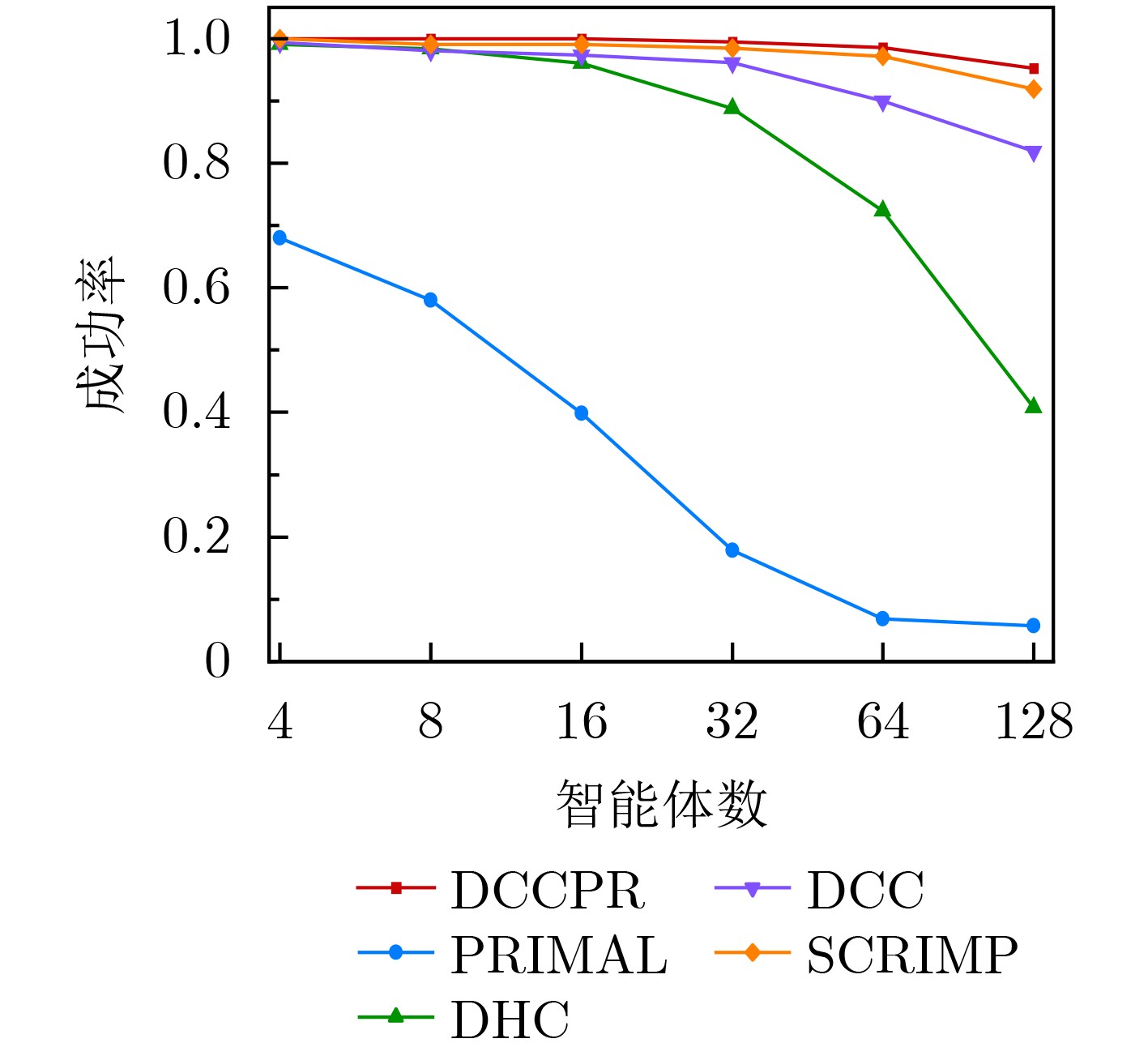
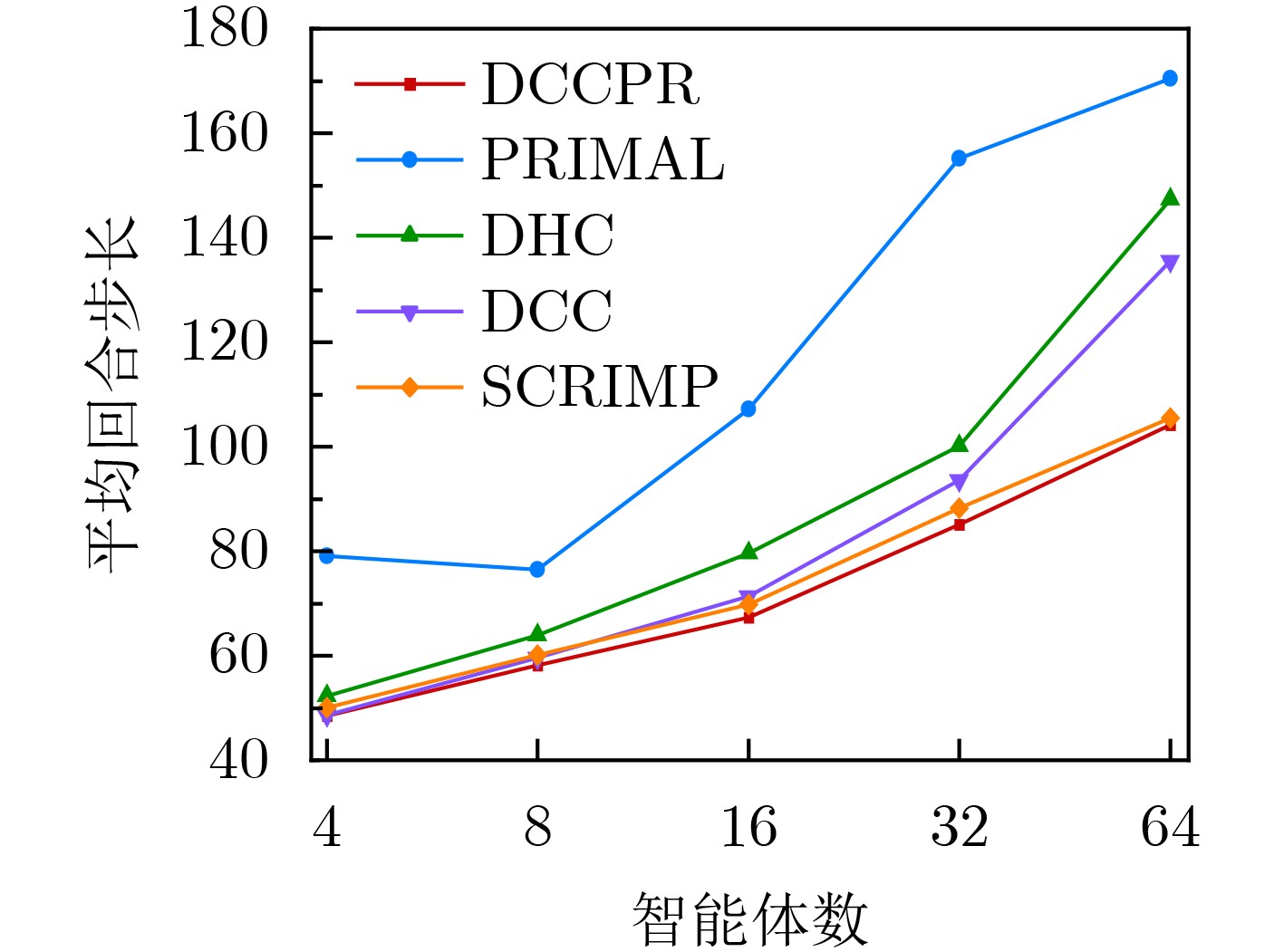
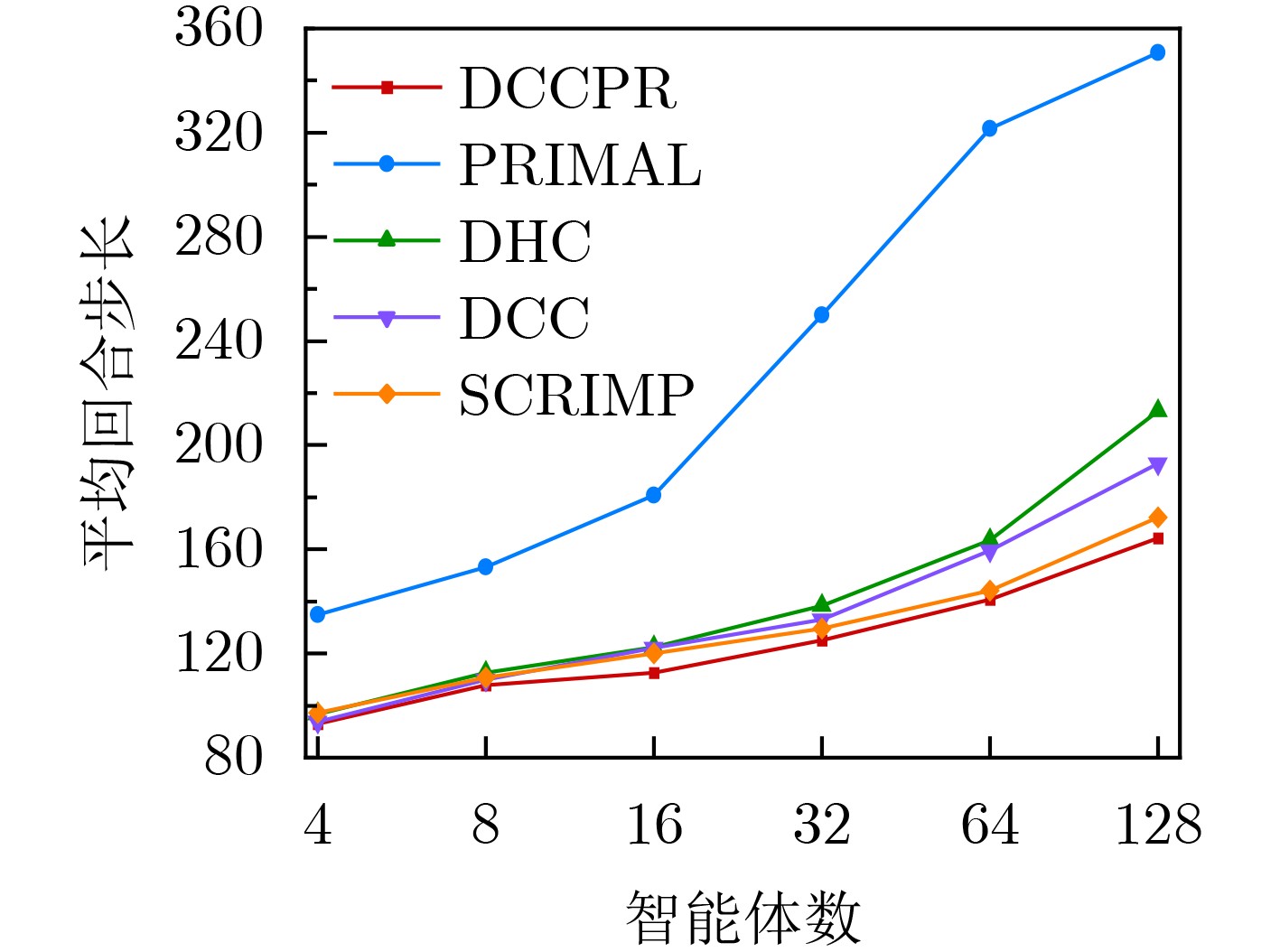
Objective The rapid development of intelligent manufacturing, automated warehousing, and Internet of Things technologies has made Multi-Agent Path Finding (MAPF) a key approach for addressing complex coordination tasks. Traditional centralized methods face limitations in large-scale multi-agent systems due to excessive communication load, high computational complexity, and susceptibility to path conflicts and deadlocks. Existing methods rely on broadcast-based communication, which leads to information overload and poor scalability. Furthermore, current conflict resolution strategies are static and overly simplistic, making them ineffective for dynamically balancing task priorities and environmental congestion. This study proposes an MAPF strategy based on selective communication and hierarchical conflict resolution to optimize communication efficiency, reduce path deviations and deadlocks, and improve path planning performance and task completion rates in complex environments. Methods The proposed Decision Causal Communication with Prioritized Resolution (DCCPR) method integrates reinforcement learning and the A* algorithm and introduces selective communication with hierarchical conflict resolution. A dynamic joint masking decision mechanism enables targeted agent selection within the selective communication framework. The model is instantiated and validated using the Dueling Double Deep Q-Network (D3QN) algorithm, which dynamically selects agents for communication, reducing information redundancy, lowering communication overhead, and enhancing computational efficiency. The Q-network reward function incorporates expected paths generated by the A* algorithm, penalizing path deviations and cumulative congestion to guide agents toward low-congestion routes, thereby accelerating task completion. A hierarchical conflict resolution strategy is also proposed, which considers target distance, task Q-values, and task urgency. By combining dynamic re-planning using the A* algorithm with a turn-taking mechanism, this approach effectively resolves conflicts, enables necessary detours to avoid collisions, increases task success rates, and reduces average task completion time. Results and Discussions The experimental results show that the DCCPR method outperforms conventional approaches in task success rate, computational efficiency, and path planning performance, particularly in large-scale and complex environments. In terms of task success rate, DCCPR demonstrates superior performance across random maps of different sizes. In the 40 × 40 random map environment ( Fig. 6 ), DCCPR consistently maintains a success rate above 90%, significantly higher than other baseline methods, with no apparent decline as the number of agents increases. In contrast, methods such as DHC and PRIMAL exhibit substantial performance degradation, with success rates dropping below 50% as agent numbers grow. DCCPR reduces communication overhead through its selective communication mechanism, while the hierarchical conflict resolution strategy minimizes path conflicts, maintaining stable performance even in high-density environments. In the 80 × 80 map (Fig. 7 ), under extreme conditions with 128 agents, DCCPR’s success rate remains above 90%, confirming its applicability to both small-scale and large-scale, complex scenarios. DCCPR also achieves significantly improved computational efficiency. In the 40 × 40 map (Fig. 8 ), it records the shortest average episode length among all methods, and the increase in episode length with higher agent numbers is substantially lower than that observed in other approaches. In the 80 × 80 environment (Fig. 9 ), despite the larger map size, DCCPR consistently maintains the shortest episode length. The hierarchical conflict resolution strategy effectively reduces path conflicts and prevents deadlocks. In environments with dense obstacles and high agent numbers, DCCPR dynamically adjusts task priorities and employs a turn-taking mechanism to mitigate delays caused by path competition. Moreover, in structured map environments not encountered during training, DCCPR maintains high success rates and efficiency (Table 2 ), demonstrating strong scalability. Compared to baseline methods, DCCPR achieves approximately a 79% improvement in task success rate and a 46.4% reduction in average episode length. DCCPR also performs well in warehouse environments with narrow passages, where congestion typically presents challenges. Through turn-taking and dynamic path re-planning, agents are guided toward previously unused suboptimal paths, reducing oscillatory behavior and lowering the risk of task failure. Overall, DCCPR sustains high computational efficiency while maintaining high success rates, effectively addressing the challenges of multi-agent path planning in complex dynamic environments.Conclusions The DCCPR method proposed in this study provides an effective solution for multi-agent path planning. Through selective communication and hierarchical conflict resolution, DCCPR significantly improves path planning efficiency and task success rates. Experimental results confirm the strong adaptability and stability of DCCPR across diverse complex environments, particularly in dynamic scenarios, where it effectively reduces conflicts and enhances system performance. Future work will focus on refining the communication strategy by integrating global and local communication benefits to improve performance in large-scale environments. In addition, real-world factors such as dynamic environmental changes and the energy consumption of intelligent agents will be considered to further enhance the system’s effectiveness. -
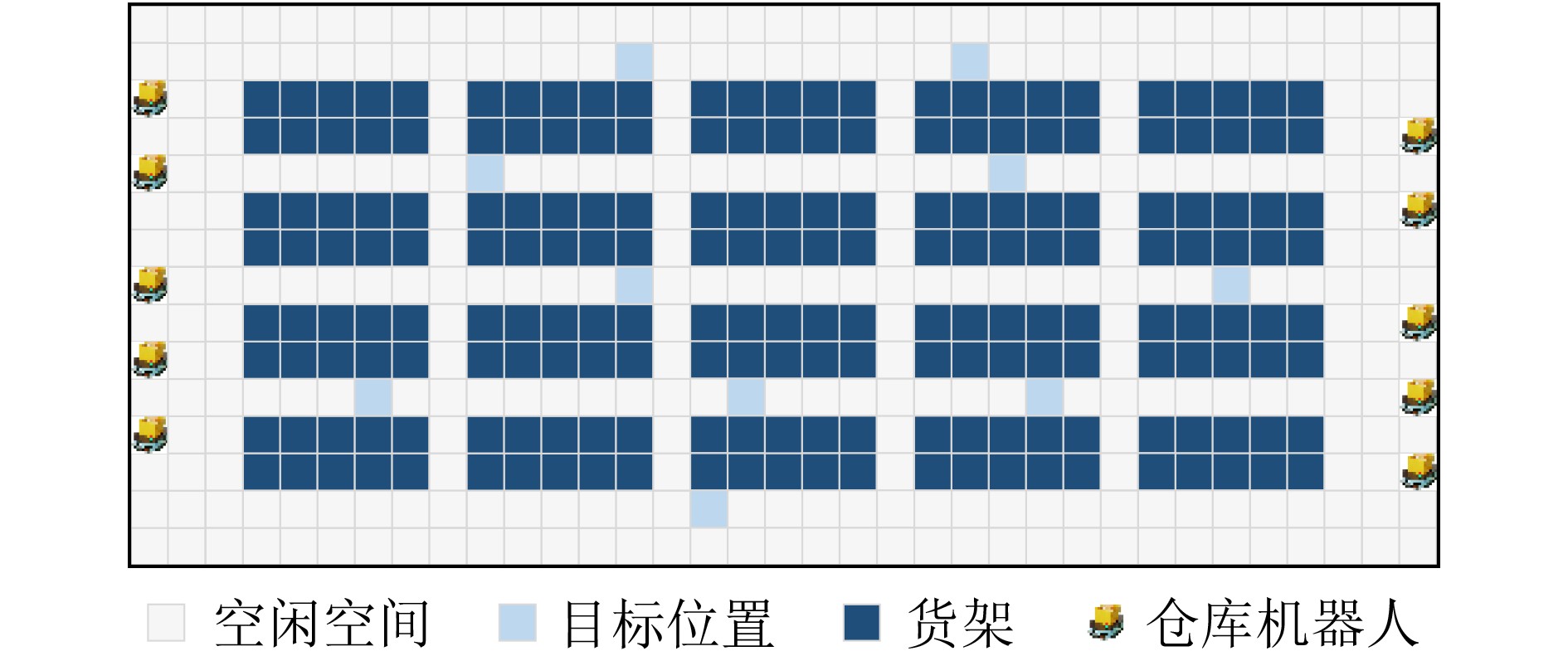
表 2 在结构化地图warehouse与den312d环境中不同算法的平均回合步长及成功率
Map Agent PRIMAL DHC SCRIMP DCC DCCPR EL SR (%) EL SR (%) EL SR (%) EL SR(%) EL SR (%) warehouse
(161×63)4 357.79 43 148.07 99 198.12 87 134.57 99 135.16 100 8 452.18 18 197.38 91 303.97 66 169.77 96 154.53 100 16 492.64 8 282.81 74 366.05 48 208.72 90 178.95 99 32 507.39 4 432.24 28 451.73 21 335.15 58 199.41 98 64 512.00 0 512.00 1 503.51 4 473.31 14 253.67 93 den312d
(65×81)4 198.45 40 87.42 100 82.73 100 83.09 100 82.16 100 8 244.93 9 100.91 100 100.19 100 97.55 99 93.84 100 16 256.00 0 108.36 100 104.97 100 109.46 97 109.38 100 32 256.00 0 126.12 98 115.83 100 119.73 97 118.92 100 64 256.00 0 155.67 92 134.36 99 145.19 94 139.49 99  下载: 导出CSV
下载: 导出CSV
表 3 不同算法在结构化地图warehouse与den312d环境中的通信频率(Hz)
Map Agent DHC DCC DCCPR warehouse
(161×63)4 27.1 7.9 2.5 8 129.4 42.3 7.1 16 693.7 150.6 40.7 32 3 617.5 595.2 173.6 64 19 527.9 2397.7 801.8 den312d
(65×81)4 43.4 3.1 3.7 8 211.6 12.0 15.3 16 892.1 52.8 58.5 32 3 299.5 229.4 196.2 64 11 783.2 1 395.7 1 183.9
下载: 导出CSV
-
[1] BETALO M L, LENG Supeng, SEID A M, et al. Dynamic charging and path planning for UAV-powered rechargeable WSNs using multi-agent deep reinforcement learning[J]. IEEE Transactions on Automation Science and Engineering, 2025, 22: 15610–15626. doi: 10.1109/TASE.2025.3558945. [2] 司明, 邬伯藩, 胡灿, 等. 智能仓储交通信号与多AGV路径规划协同控制方法[J]. 计算机工程与应用, 2024, 60(11): 290–297. doi: 10.3778/j.issn.1002-8331.2310-0113.SI Ming, WU Bofan, HU Can, et al. Collaborative control method of intelligent warehouse traffic signal and multi-AGV path planning[J]. Computer Engineering and Applications, 2024, 60(11): 290–297. doi: 10.3778/j.issn.1002-8331.2310-0113. [3] WANG Zhaofei, WENG Zihao, WANG Jing, et al. An original medical logistics robot system design for the complex environment of hospitals with dynamic obstacles[J]. Robotic Intelligence and Automation, 2025, 45(2): 210–227. doi: 10.1108/RIA-03-2023-0029. [4] 刘志飞, 曹雷, 赖俊, 等. 多智能体路径规划综述[J]. 计算机工程与应用, 2022, 58(20): 43–62. doi: 10.3778/j.issn.1002-8331.2203-0467.LIU Zhifei, CAO Lei, LAI Jun, et al. Overview of multi-agent path finding[J]. Computer Engineering and Applications, 2022, 58(20): 43–62. doi: 10.3778/j.issn.1002-8331.2203-0467. [5] SHARON G, STERN R, FELNER A, et al. Conflict-based search for optimal multi-agent pathfinding[J]. Artificial Intelligence, 2015, 219: 40–66. doi: 10.1016/j.artint.2014.11.006. [6] WALKER T T, STURTEVANT N R, FELNER A, et al. Conflict-based increasing cost search[C]. The 31rd International Conference on Automated Planning and Scheduling, Guangzhou, China, 2021: 385–395. doi: 10.1609/icaps.v31i1.15984. [7] SARTORETTI G, KERR J, SHI Yunfei, et al. PRIMAL: Pathfinding via reinforcement and imitation multi-agent learning[J]. IEEE Robotics and Automation Letters, 2019, 4(3): 2378–2385. doi: 10.1109/LRA.2019.2903261. [8] DAMANI M, LUO Zhiyao, WENZEL E, et al. PRIMAL2: Pathfinding via reinforcement and imitation multi-agent learning-lifelong[J]. IEEE Robotics and Automation Letters, 2021, 6(2): 2666–2673. doi: 10.1109/LRA.2021.3062803. [9] LIU Zuxin, CHEN Baiming, ZHOU Hongyi, et al. MAPPER: Multi-agent path planning with evolutionary reinforcement learning in mixed dynamic environments[C]. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, USA, 2020: 11748–11754. doi: 10.1109/IROS45743.2020.9340876. [10] GUAN Huifeng, GAO Yuan, ZHAO Min, et al. AB-Mapper: Attention and BicNet based multi-agent path finding for dynamic crowded environment[J]. arXiv: 2110.00760, 2021. [11] MA Ziyuan, LUO Yudong, and MA Hang. Distributed heuristic multi-agent path finding with communication[C]. 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 2021: 8699–8705. doi: 10.48550/arXiv.2106.11365. [12] MA Ziyuan, LUO Yudong, and PAN Jia. Learning selective communication for multi-agent path finding[J]. IEEE Robotics and Automation Letters, 2022, 7(2): 1455–1462. doi: 10.1109/LRA.2021.3139145. [13] WANG Yutong, XIANG Bairan, HUANG Shinan, et al. SCRIMP: Scalable communication for reinforcement-and imitation-learning-based multi-agent pathfinding[C]. 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems, Detroit, USA, 2023: 9301–9308. doi: 10.1109/IROS55552.2023.10342305. [14] LIN Qiushi and MA Hang. SACHA: Soft actor-critic with heuristic-based attention for partially observable multi-agent path finding[J]. IEEE Robotics and Automation Letters, 2023, 8(8): 5100–5107. doi: 10.1109/LRA.2023.3292004. [15] MA Jinchao and LIAN Defu. Attention-cooperated reinforcement learning for multi-agent path planning[M]. RAGE U K, GOYAL V, and REDDY P K. Database Systems for Advanced Applications. DASFAA 2022 International Workshops. Cham: Springer, 2022: 272–290. doi: 10.1007/978-3-031-11217-1_20. [16] LI Wenhao, CHEN Hongjun, JIN Bo, et al. Multi-agent path finding with prioritized communication learning[C]. 2022 International Conference on Robotics and Automation, Philadelphia, USA, 2022: 10695–10701. doi: 10.1109/ICRA46639.2022.9811643. [17] 纪苗苗, 吴志彬. 考虑工人路径的多智能体强化学习空间众包任务分配方法[J]. 控制与决策, 2024, 39(1): 319–326. doi: 10.13195/j.kzyjc.2022.1319.JI Miaomiao and WU Zhibin. A multi-agent reinforcement learning algorithm for spatial crowdsourcing task assignments considering workers’ path[J]. Control and Decision, 2024, 39(1): 319–326. doi: 10.13195/j.kzyjc.2022.1319. [18] WANG Yutong, DUHAN T, LI Jiaoyang, et al. LNS2+RL: Combining Multi-agent Reinforcement Learning with Large Neighborhood Search in Multi-agent Path Finding[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025. doi: 10.1609/aaai.v39i22.34501. [19] 田华亭, 李涛, 秦颖. 基于A*改进算法的四向移动机器人路径搜索研究[J]. 控制与决策, 2017, 32(6): 1007–1012. doi: 10.13195/j.kzyjc.2016.0244.TIAN Huating, LI Tao, and QIN Ying. Research of four-way mobile robot path search based on improved A* algorithm[J]. Control and Decision, 2017, 32(6): 1007–1012. doi: 10.13195/j.kzyjc.2016.0244. [20] DING Ziluo, HUANG Tiejun, and LU Zongqing. Learning individually inferred communication for multi-agent cooperation[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1851. [21] PARISOTTO E, SONG H F, RAE J W, et al. Stabilizing transformers for reinforcement learning[C]. The 37th International Conference on Machine Learning, Vienna, Austria, 2020: 694. [22] VAN HASSELT H, GUEZ A, and SILVER D. Deep reinforcement learning with double Q-learning[C]. The 30th AAAI Conference on Artificial Intelligence, Phoenix, USA, 2016. doi: 10.1609/aaai.v30i1.10295. [23] WANG Ziyu, SCHAUL T, HESSEL M, et al. Dueling network architectures for deep reinforcement learning[C]. The 33rd International Conference on Machine Learning, New York, USA, 2016: 1995–2003. [24] CHEN Zhe, HARABOR D, LI Jiaoyang, et al. Traffic flow optimisation for lifelong multi-agent path finding[C]. The 38th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 20674–20682. doi: 10.1609/aaai.v38i18.30054. [25] MAOUDJ A and CHRISTENSEN A L. Improved decentralized cooperative multi-agent path finding for robots with limited communication[J]. Swarm Intelligence, 2024, 18(2): 167–185. doi: 10.1007/s11721-023-00230-7. -

 下载:
下载:



图(9) / 表(3)
计量
- 文章访问数: 942
- HTML全文浏览量: 861
- PDF下载量: 102
- 被引次数: 0
