

Weakly Supervised Image Semantic Segmentation Based on Multi-Seeded Information Aggregation and Positive-Negative Hybrid Learning
-
摘要: 基于图像级标签的弱监督语义分割(WSSS)旨在通过类激活映射(CAM)生成伪标签(种子),然后将其用于训练语义分割模型,为耗时且昂贵的像素级标注节省大量人力和财力。现有方法主要围绕CAM进行改进以获取单个优良的种子,同时通过一些后处理手段进一步提升种子的质量,但其得到的种子仍存在不等程度的噪声。为了减少噪声标签对分割网络造成的影响,考虑多个不同种子更能有效提取出正确信息,该文从多种子信息互补的角度,提出一种基于多种子信息聚合和正负混合学习的弱监督图像语义分割方法,通过在分类网络中改变输入图像尺度以及调整Dropout层随机隐藏神经元的概率,获取多个优良种子;依据它们对每个像素分配的类别标签情况进行优选获得聚合种子,并进一步区分该像素标签为干净标签还是噪声标签;利用正负混合学习训练语义分割网络,引入预测约束损失以避免网络对噪声标签给予过高的预测值,进而对干净标签应用正学习发挥正确信息的准确性,对噪声标签应用负学习抑制错误信息的影响,从而有效提升分割网络的性能。在PASCAL VOC 2012和MS COCO 2014验证集上实验结果表明,该文方法在基于卷积神经网络框架的分割网络中,mIoU分别达到了72.5%和40.8%,与RCA及URN方法相比分别提升了0.3%与0.1%;在基于Transformer框架的分割网络中,mIoU则提升至76.8%和46.7%,与CoBra及ECA方法相比分别提升了2.5%与1.6%,验证了方法的有效性。Abstract:
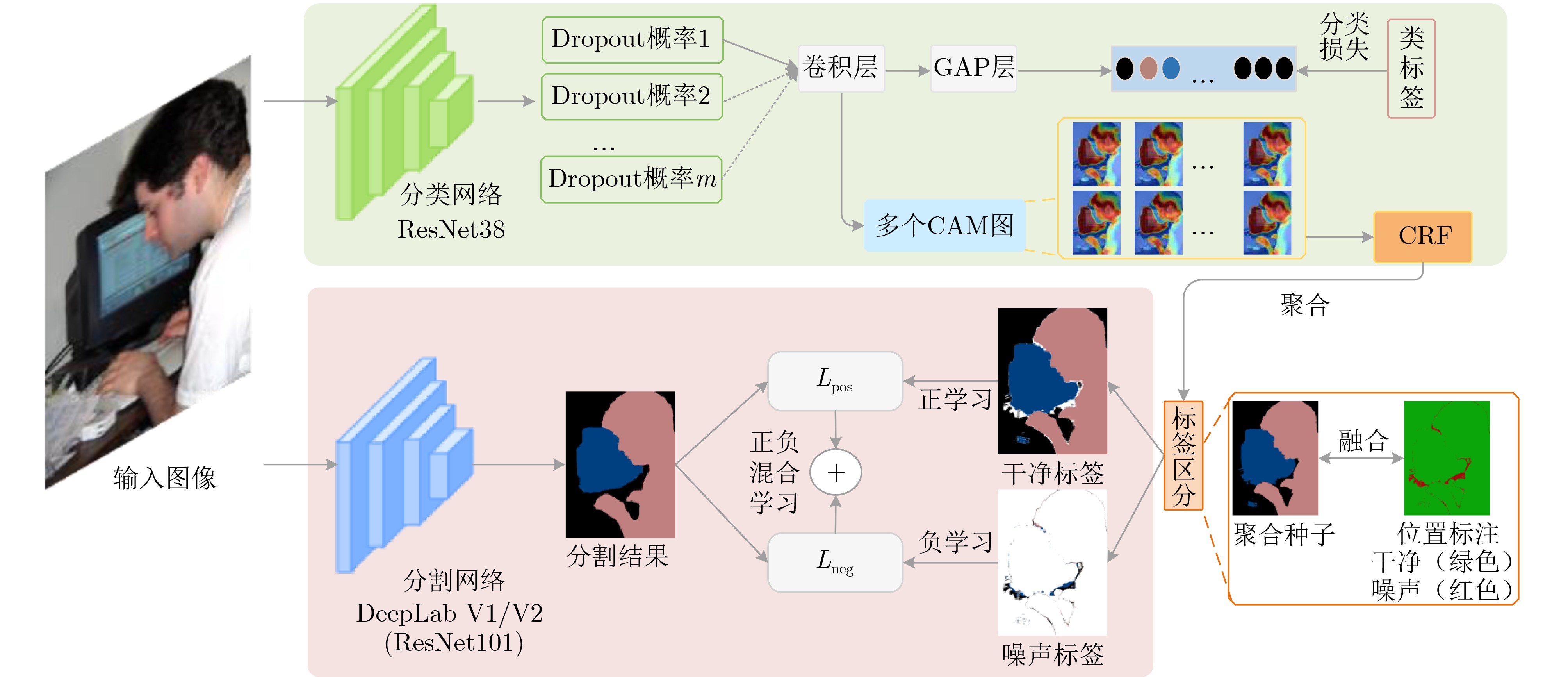
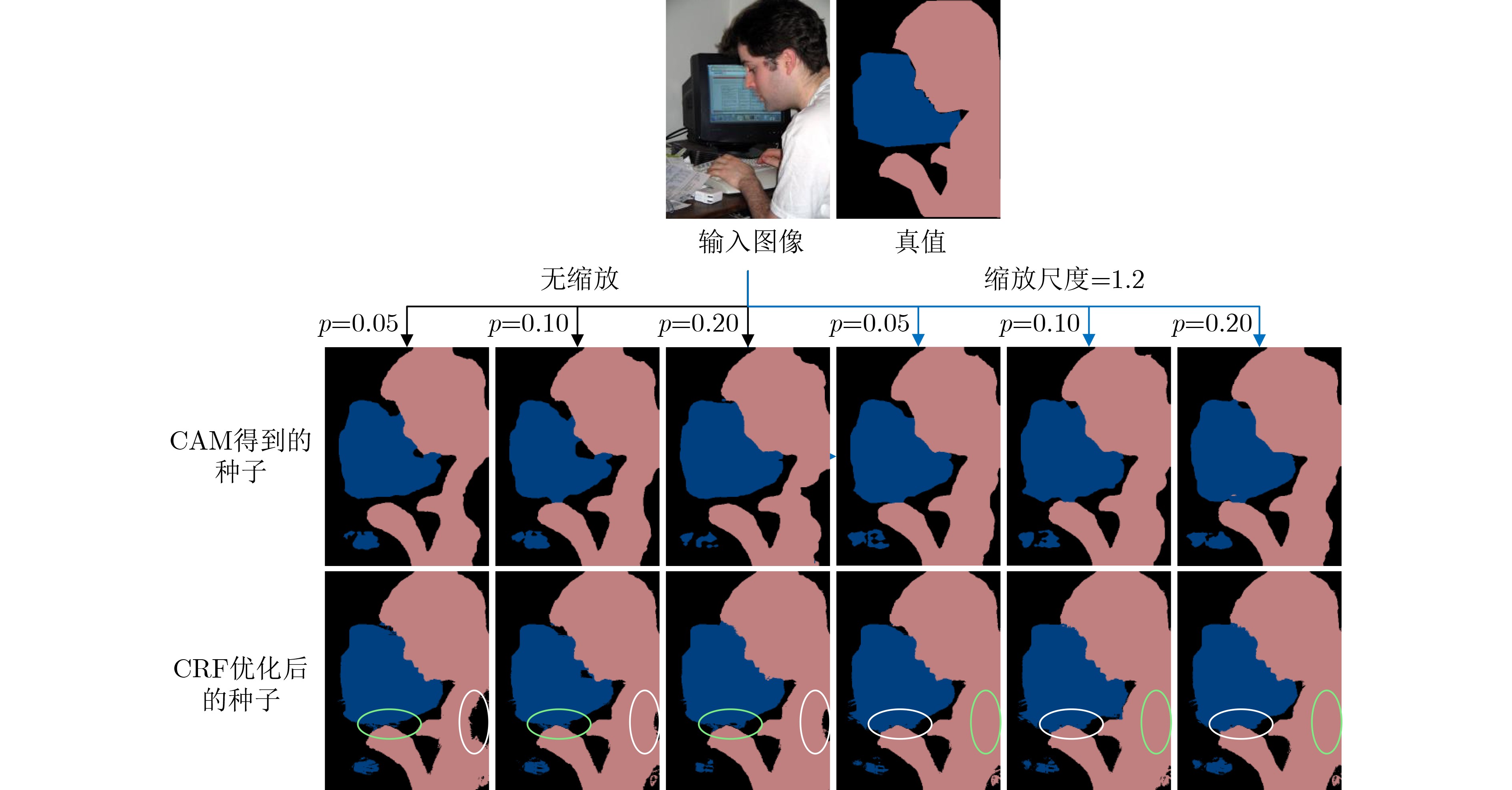
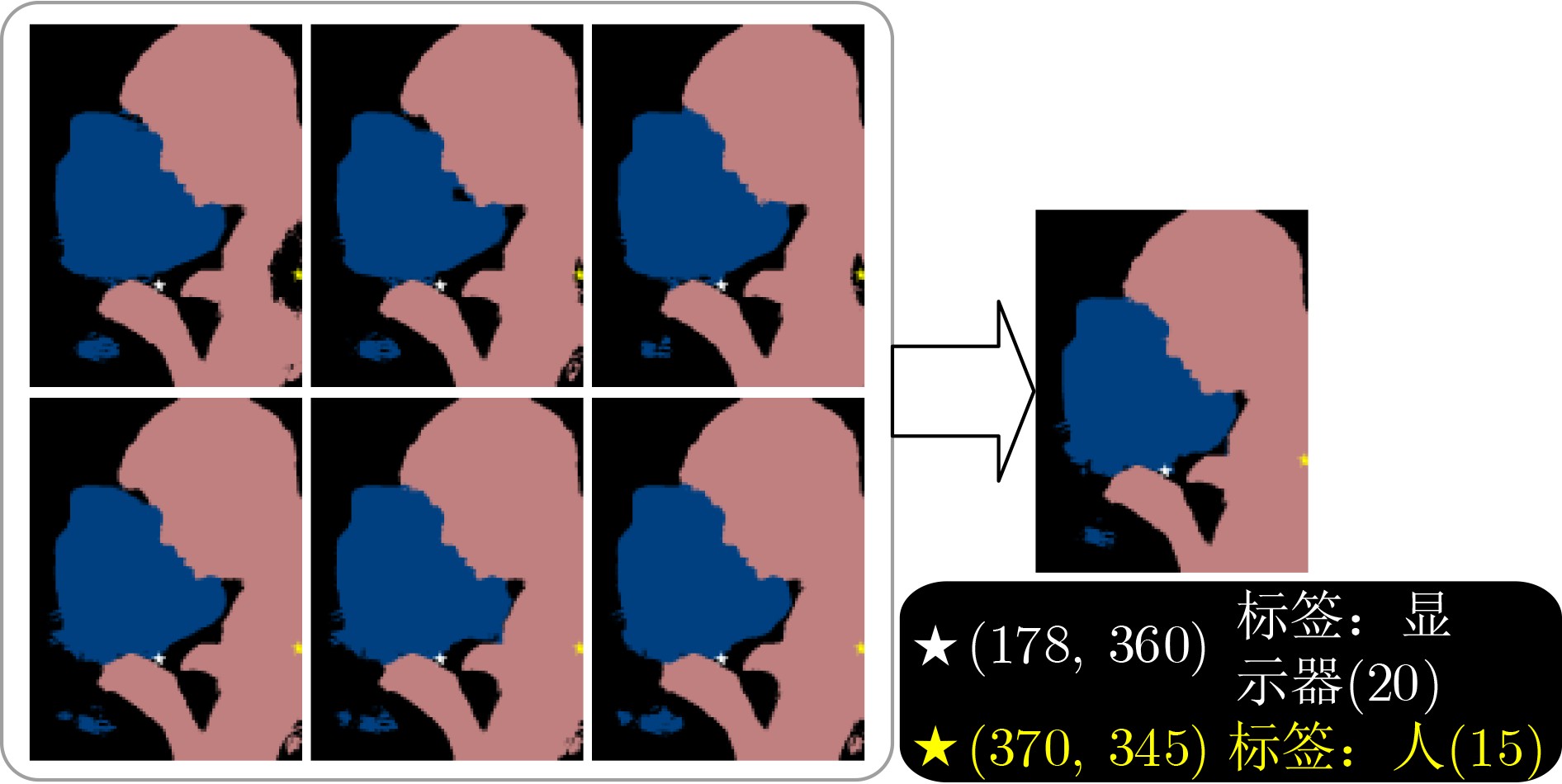
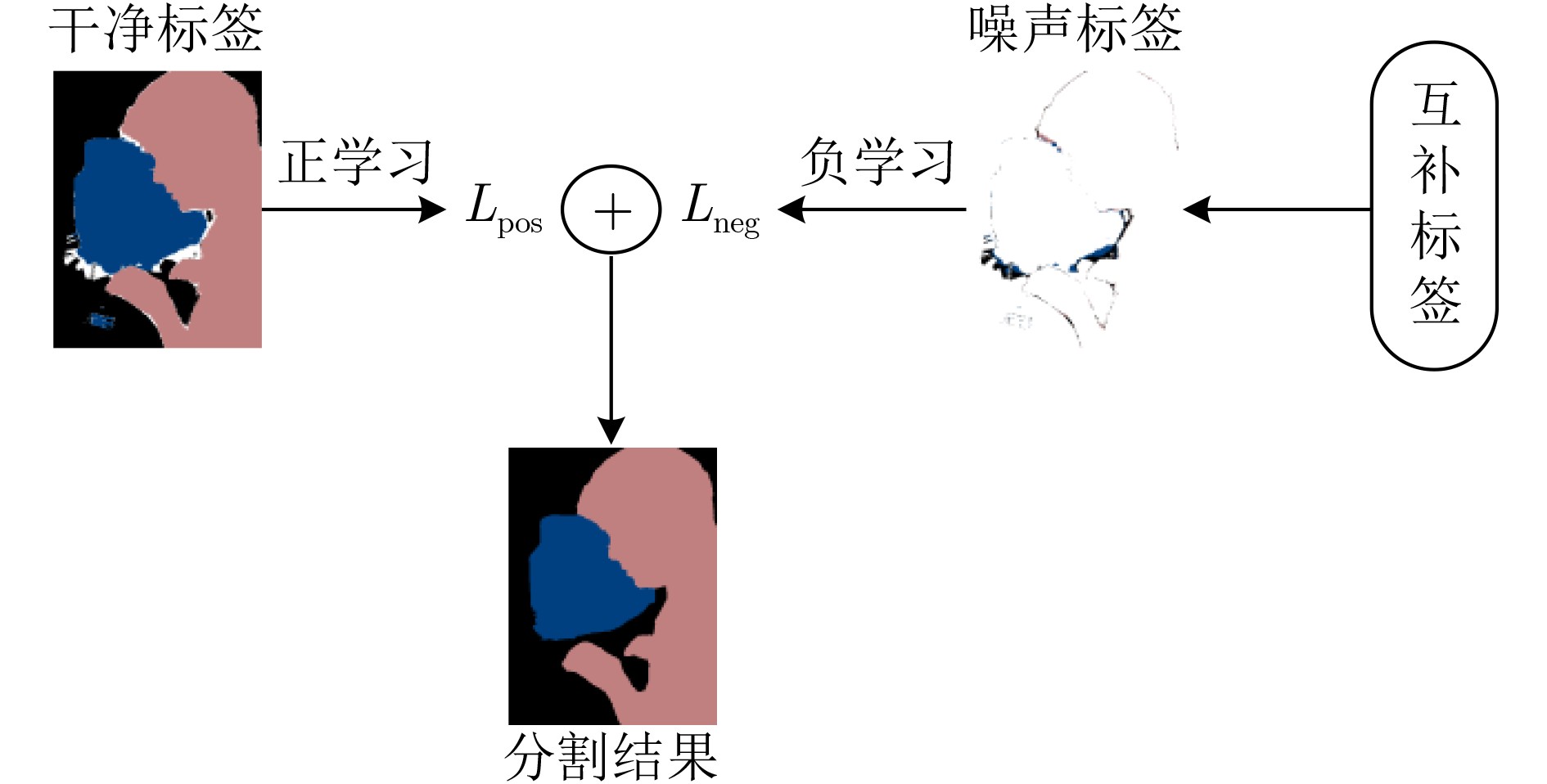
Objective The rapid development of deep learning techniques, particularly Convolutional Neural Networks (CNN), has led to notable advances in semantic segmentation, enabling applications in medical imaging, autonomous driving, and remote sensing. However, conventional semantic segmentation tasks typically rely on large numbers of pixel-level annotated images, which is both time-consuming and expensive. To address this limitation, Weakly Supervised Semantic Segmentation (WSSS) using image-level labels has emerged as a promising alternative. This approach aims to reduce annotation costs while maintaining or enhancing segmentation performance, thus supporting broader adoption of semantic segmentation techniques. Most existing methods focus on optimizing Class Activation Mapping (CAM) to generate high-quality seed regions, with further refinement through post-processing. However, the resulting seed labels often contain varying degrees of noise. To mitigate the effect of noisy labels on the segmentation network and to efficiently extract accurate information by leveraging multiple complementary seed sources, this study proposes a weakly supervised semantic segmentation method based on multi-seed information aggregation and positive-negative hybrid learning. The proposed approach improves segmentation performance by integrating complementary information from different seeds while reducing noise interference. Methods Building on the idea that combining multiple seeds can effectively extract accurate information, this study proposes a weakly supervised image semantic segmentation method based on multi-seed information aggregation and positive-negative hybrid learning. The approach employs a generalized classification network to generate diverse seed regions by varying the input image scale and modifying the Dropout layer to randomly deactivate neurons with different probabilities. This process enables the extraction of complementary information from multiple sources. Subsequently, a semantic segmentation network is trained using a hybrid positive-negative learning strategy based on the category labels assigned to each pixel across these seeds. Clean labels, identified with high confidence, guide the segmentation network through a positive learning process, where the model learns that “the input image belongs to its assigned labels.” Conversely, noisy labels are addressed using two complementary strategies. Labels determined as incorrect are trained under the principle that “the input image does not belong to its assigned labels,” representing a form of positive learning for error suppression. Additionally, an indirect negative learning strategy is applied, whereby the network learns that “the input image does not belong to its complementary labels,”further mitigating the influence of noisy labels. To reduce the adverse effects of noisy labels, particularly the tendency of conventional cross-entropy loss to assign higher prediction confidence to such labels, a prediction constraint loss is introduced. This loss function enhances the model’s predictive accuracy for reliable labels while reducing overfitting to incorrect labels. The overall framework effectively suppresses noise interference and improves the segmentation network’s performance. Results and Discussions The proposed weakly supervised image semantic segmentation method based on multi-seed information aggregation and positive-negative hybrid learning generates diverse seeds by randomly varying the Dropout probability and input image scale, with Conditional Random Field (CRF) optimization applied to further refine seed quality. To limit noise introduction while maintaining the effectiveness of positive-negative hybrid learning, six complementary seeds are selected ( Table 5 ). The integration of multi-source information from these seeds enhances segmentation performance, as demonstrated in (Table 7 ) . Pixel labels within these seeds are classified as clean or noisy based on a defined confidence threshold. The segmentation network is subsequently trained using a positive-negative hybrid learning strategy, which suppresses the influence of noisy labels and improves segmentation accuracy. Experimental results confirm that positive-negative hybrid learning effectively reduces label noise and enhances segmentation performance (Table 8 ). The proposed method was validated on the PASCAL VOC 2012 and MS COCO 2014 datasets. With a CNN-based segmentation network, the mean Intersection over Union (mIoU) reached 72.5% and 40.8%, respectively. When using a Transformer-based segmentation network, the mIoU improved to 76.8% and 46.7% (Table 1 ,Table 3 ). These results demonstrate that the proposed method effectively enhances segmentation accuracy while controlling the influence of noisy labels.Conclusions This study addresses the challenge of inaccurate seed labels in WSSS based on image-level annotations by proposing a multi-seed label differentiation strategy that leverages complementary information to improve seed quality. In addition, a positive-negative hybrid learning approach is introduced to enhance segmentation performance and mitigate the influence of erroneous pixel labels on the segmentation model. The proposed method achieves competitive results on the PASCAL VOC 2012 and MS COCO 2014 datasets. Specifically, the mIoU reaches 72.5% and 40.8%, respectively, using a CNN-based segmentation network. With a Transformer-based segmentation network, the mIoU further improves to 76.8% and 46.7%. These results demonstrate the effectiveness of the proposed method in improving segmentation accuracy while reducing noise interference. Although the method does not yet achieve ideal label precision, label differentiation combined with positive-negative hybrid learning effectively suppresses misinformation propagation and outperforms approaches based on single-seed generation and positive learning alone. -
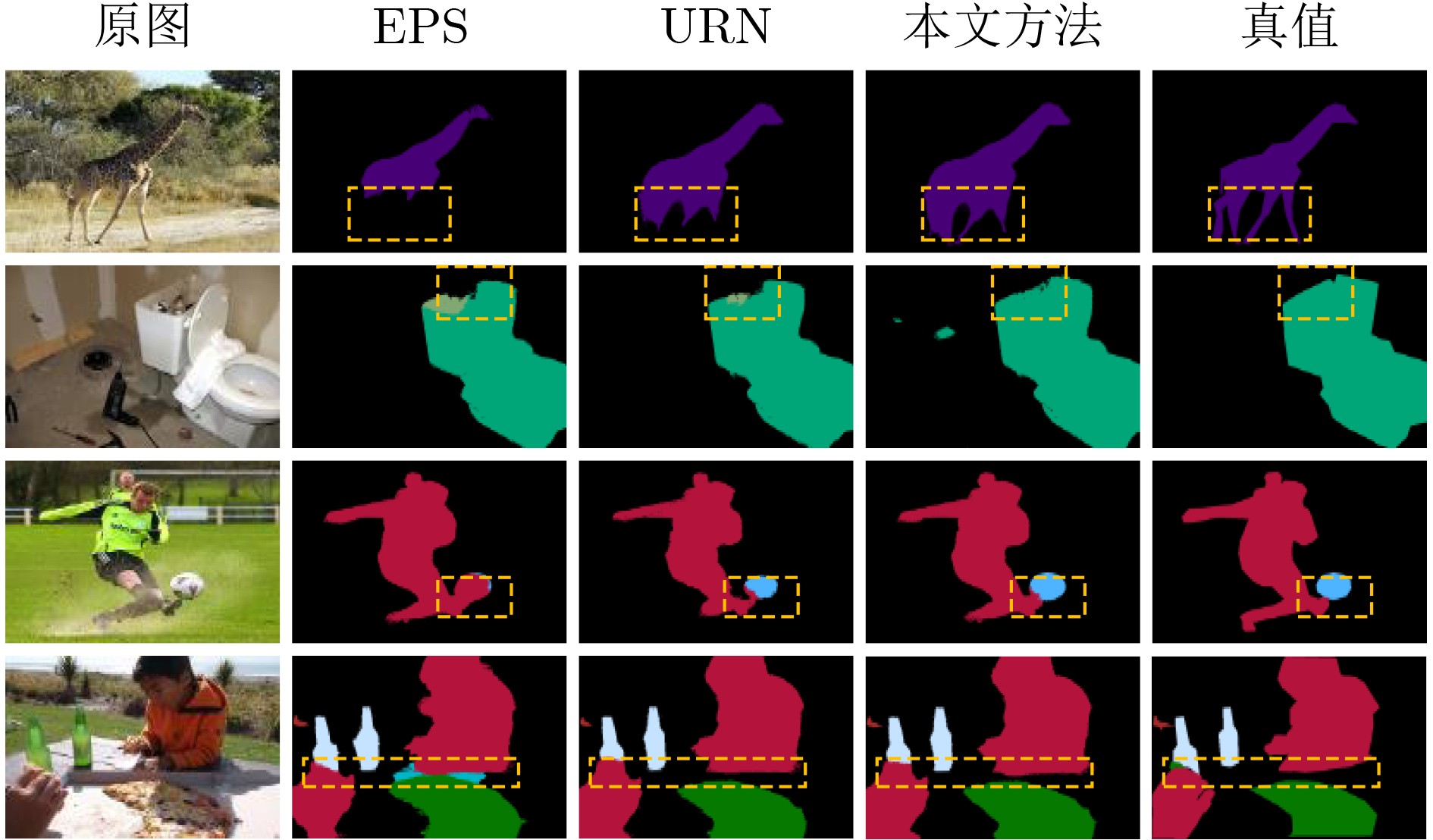
表 1 本文方法与不同模型在PASCAL VOC 2012验证集与测试集上的性能对比(粗体表示最优值)
模型 骨干网络 mIoU(%) 验证集 测试集 基于CNN方法 SIPE(CVPR22)[36] DeepLab-V2+ResNet101 68.8 69.7 FPR(CVPR23)[37] DeepLab-V2+ResNet101 70.3 70.1 ReCAM(CVPR22)[33] DeepLab-V2+ResNet101 71.6 71.4 EPS(CVPR21)[12] DeepLab-V1+ResNet101 71.0 71.8 BECO(CVPR23) [17] DeepLab-V3+[38]+ResNet101 72.1 71.8 RCA(CVPR23) [34] DeepLab-V2+ResNet101 72.2 72.8 本文方法 DeepLab-V1+ResNet101 72.1 73.1 DeepLab-V2+ResNet101 72.5 73.9 基于Transformer方法 BECO(CVPR23) [17] SegFormer-MiT-B2 73.7 73.5 CoBra(PR25)[35] SegFormer-MiT-B2 74.3 74.2 本文方法 SegFormer-MiT-B2 75.3 75.9 Mask2Former+Swin-L 76.8 77.5  下载: 导出CSV
下载: 导出CSV
表 2 在PASCAL VOC 2012验证集上的每类分割结果(%)
方法 背景 飞机 自行车 鸟 船 瓶子 公共
汽车汽车 猫 椅子 牛 餐桌 狗 马 摩托车 人 盆栽
植物羊 沙发 火车 电视/
显示器mIoU ADELE[42] 91.1 77.6 33.0 88.9 67.1 71.7 88.8 82.5 89.0 26.6 83.8 44.6 84.4 77.8 74.8 78.5 43.8 84.8 44.6 56.1 65.3 69.3 W-OoD[13] 91.0 80.1 34.1 88.1 64.8 68.3 87.4 84.4 89.8 30.1 87.8 34.7 87.5 85.9 79.8 75.0 56.4 84.5 47.8 80.4 46.4 70.7 EPS[12] 91.7 89.4 40.6 84.7 67.0 71.6 87.8 82.7 87.4 33.6 81.9 37.3 82.5 82.9 76.6 82.8 54.0 79.7 39.1 85.4 51.7 71.0 EPS++[43] 91.9 89.7 41.7 82.4 68.4 73.7 89.5 80.8 86.9 31.8 86.9 43.0 82.7 86.6 81.1 77.7 47.8 84.8 41.1 84.1 50.6 71.6 本文方法 92.2 89.5 40.1 89.5 74.8 76.2 87.6 82.2 88.3 31.9 85.8 34.7 85.8 82.3 74.2 82.0 55.6 86.2 36.8 83.7 53.9 72.1(V1) 92.2 90.4 40.4 88.2 76.3 73.8 88.4 83.0 89.1 33.1 87.0 36.1 86.7 86.2 76.4 81.7 54.2 83.9 38.2 84.8 51.7 72.5(V2) 注:粗体表示最优值,下划线表示次优值
下载: 导出CSV
表 3 本文方法与不同模型在MS COCO 2014验证集上的性能对比
模型 骨干网络 mIoU(%) 验证集 基于CNN
方法EPS(CVPR21)[12] DeepLab-V2+ResNet101 35.7 OC-CSE(ICCV21)[8] DeepLab-V1+ResNet38 36.4 MDBA(TIP23)[16] DeepLab-V2+ResNet101 37.8 SIPE(CVPR22)[36] DeepLab-V2+ResNet101 40.6 URN(AAAI22) [44] PSPNet+ResNet101 40.7 本文方法 DeepLab-V2+ResNet101 40.8 基于
Transformer
方法TSCD(AAAI23)[46] SegFormer+MiT-B1 40.1 ECA(ACM MM24)[45] SegFormer+MiT-B1 42.9 本文方法 SegFormer+MiT-B2 45.1 Mask2Former+Swin-L 46.7 注:粗体表示最优值
下载: 导出CSV
表 4 在PASCAL VOC 2012训练集上种子的每类mIoU值(%)
种子 背景 飞机 自行车 鸟 船 瓶子 公共
汽车汽车 猫 椅子 牛 餐桌 狗 马 摩托车 人 盆栽
植物羊 沙发 火车 电视/
显示器mIoU 0.05-1.0 91.4 87.9 45.9 85.0 80.6 75.3 83.7 81.0 86.0 34.9 83.5 44.4 85.4 86.1 80.8 80.0 54.7 86.7 41.0 80.1 54.9 72.8 0.05-1.2 91.4 87.3 44.5 87.0 80.8 73.5 83.6 80.7 86.8 34.5 85.1 48.7 83.3 87.0 79.9 80.7 52.5 85.9 41.9 78.9 55.4 72.8 0.10-1.0 91.5 87.3 45.0 86.5 80.2 75.2 84.3 82.0 85.7 34.5 84.0 43.6 84.7 86.0 80.8 80.3 57.3 89.3 40.6 79.0 55.9 73.0 0.10-1.2 91.5 88.0 41.9 86.2 80.1 74.0 82.9 80.6 87.7 34.6 84.9 49.6 84.6 86.5 79.9 80.7 54.0 87.3 41.9 78.6 56.5 73.0 0.20-1.0 91.5 87.0 45.9 85.9 80.2 74.1 83.6 80.7 86.6 35.3 83.7 46.0 85.1 86.3 80.3 80.0 55.4 86.8 38.4 80.1 55.5 72.8 0.20-1.2 91.5 87.8 45.1 86.7 79.4 72.5 84.1 82.0 87.1 34.2 84.5 47.6 83.9 86.8 79.8 80.8 55.0 86.6 41.1 79.1 55.8 72.9 0.30-1.0 91.3 87.5 41.2 85.5 79.6 73.8 83.7 81.4 86.3 34.0 84.3 44.8 85.4 86.8 80.5 79.5 54.7 86.7 40.4 78.0 54.4 72.4 0.30-1.2 91.5 87.3 44.4 86.6 78.9 72. 5 83.3 80.8 87.5 33.8 84.2 46.3 83.7 86.9 79.4 80.9 56.7 86.7 42.7 79.6 56.9 72.9 注:粗体表示最优值
下载: 导出CSV
表 5 在PASCAL VOC 2012训练集上每个种子类激活图的mIoU值(%)
种子 0.05-1.0 0.05-1.2 0.10-1.0 0.10-1.2 0.2-1.0 0.3-1.2 mIoU 69.15 69.10 69.34 69.30 69.27 69.63
下载: 导出CSV
表 6 种子在PASCAL VOC 2012验证集中的mIoU值(%)
Dropout Scale Deeplabv1+ResNet101 DeeplabV2+ResNet101 0.05 1.0 71.38 71.92 1.2 71.82 72.27 0.10 1.0 71.36 72.29 1.2 71.80 72.27 0.20 1.0 71.06 71.80 0.30 1.2 71.11 72.13 聚合种子 1.0 71.85 72.30 注:粗体表示最优值
下载: 导出CSV
表 7 正负混合学习性能对比(%)
学习方式 DeepLabV1+ResNet101 DeepLabV2+ResNet101 正负学习
(不同阈值t)3 71.87 72.34 4 71.89 72.37 5 71.99 72.42 6 72.06 72.46 注:粗体表示最优值
下载: 导出CSV
表 9 六个种子及聚合种子与真值标签在同一像素位置的类别标签一致率和不一致率比较(%)
不同种子 一致率(%) 不一致率(%) 0.05-1.0 89.8000 10.2000 0.05-1.2 89.8000 10.2000 0.10-1.0 89.8711 10.1289 0.10-1.2 89.9034 10.0966 0.20-1.2 89.8732 10.1268 0.30-1.2 89.8284 10.1716 聚合种子 89.9964 10.0036 注:粗体表示最优值
下载: 导出CSV
表 10 优选标签在不同阈值下标记的干净情况与真值标签的一致率和不一致率比较(%)
不同阈值t 优选的种子标签与真值标签一致 (a)标记为干净(正确标记) (b)标记为噪声(错误标记) 3 89.9042 0.0022 4 89.5418 0.3647 5 88.8536 1.0528 6 87.8883 2.0182
下载: 导出CSV
表 11 优选标签在不同阈值下标记的噪声情况与真值标签的一致率和不一致率比较(%)
不同阈值t 优选的种子标签与真值标签不一致 (c)标记为噪声(正确标记) (d)标记为干净(错误标记) 3 0.0033 10.0002 4 0.4725 9.6211 5 1.1762 8.9174 6 2.0201 8.0734
下载: 导出CSV
-
[1] LIU Huan, LI Wei, XIA Xianggen, et al. SegHSI: Semantic segmentation of hyperspectral images with limited labeled pixels[J]. IEEE Transactions on Image Processing, 2024, 33: 6469–6482. doi: 10.1109/TIP.2024.3492724. [2] 张印辉, 张金凯, 何自芬, 等. 全局感知与稀疏特征关联图像级弱监督病理图像分割[J]. 电子与信息学报, 2024, 46(9): 3672–3682. doi: 10.11999/JEIT240364.ZHANG Yinhui, ZHANG Jinkai, HE Zifen, et al. Global perception and sparse feature associate image-level weakly supervised pathological image segmentation[J]. Journal of Electronics & Information Technology, 2024, 46(9): 3672–3682. doi: 10.11999/JEIT240364. [3] LI Jiale, DAI Hang, HAN Hao, et al. MSeg3D: Multi-modal 3D semantic segmentation for autonomous driving[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 21694–21704. doi: 10.1109/CVPR52729.2023.02078. [4] 梁燕, 易春霞, 王光宇, 等. 基于多尺度语义编解码网络的遥感图像语义分割[J]. 电子学报, 2023, 51(11): 3199–3214. doi: 10.12263/DZXB.20220503.LIANG Yan, YI Chunxia, WANG Guangyu, et al. Semantic segmentation of remote sensing image based on multi-scale semantic encoder-decoder network[J]. Acta Electronica Sinica, 2023, 51(11): 3199–3214. doi: 10.12263/DZXB.20220503. [5] OH Y, KIM B, and HAM B. Background-aware pooling and noise-aware loss for weakly-supervised semantic segmentation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 6909–6918. doi: 10.1109/CVPR46437.2021.00684. [6] LIANG Zhiyuan, WANG Tiancai, ZHANG Xiangyu, et al. Tree energy loss: Towards sparsely annotated semantic segmentation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 16886–16895. doi: 10.1109/CVPR52688.2022.01640. [7] ZHAO Yuanhao, SUN Genyun, LING Ziyan, et al. Point-based weakly supervised deep learning for semantic segmentation of remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5638416. doi: 10.1109/TGRS.2024.3409903. [8] KWEON H, YOON S H, KIM H, et al. Unlocking the potential of ordinary classifier: Class-specific adversarial erasing framework for weakly supervised semantic segmentation[C]. IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 6974–6983. doi: 10.1109/ICCV48922.2021.00691. [9] ZHOU Bolei, KHOSLA A, LAPEDRIZA A, et al. Learning deep features for discriminative localization[C]. IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2921–2929. doi: 10.1109/CVPR.2016.319. [10] WANG Xiang, YOU Shaodi, LI Xi, et al. Weakly-supervised semantic segmentation by iteratively mining common object features[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 1354–1362. doi: 10.1109/CVPR.2018.00147. [11] WANG Xun, ZHANG Haozhi, HUANG Weilin, et al. Cross-batch memory for embedding learning[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 6387–6396. doi: 10.1109/CVPR42600.2020.00642. [12] LEE S, LEE M, LEE J, et al. Railroad is not a train: Saliency as pseudo-pixel supervision for weakly supervised semantic segmentation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 5491–5501. doi: 10.1109/CVPR46437.2021.00545. [13] LEE J, OH S J, YUN S, et al. Weakly supervised semantic segmentation using out-of-distribution data[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 16876–16885. doi: 10.1109/CVPR52688.2022.01639. [14] CHANG Yuting, WANG Qiaosong, HUNG W C, et al. Weakly-supervised semantic segmentation via sub-category exploration[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 8988–8997. doi: 10.1109/CVPR42600.2020.00901. [15] ARPIT D, JASTRZĘBSKI S, BALLAS N, et al. A closer look at memorization in deep networks[C]. 34th International Conference on Machine Learning, Sydney, Australia, 2017: 233–242. [16] CHEN Tao, YAO Yazhou, and TANG Jinhui. Multi-granularity denoising and bidirectional alignment for weakly supervised semantic segmentation[J]. IEEE Transactions on Image Processing, 2023, 32: 2960–2971. doi: 10.1109/TIP.2023.3275913. [17] RONG Shenghai, TU Bohai, WANG Zilei, et al. Boundary-enhanced co-training for weakly supervised semantic segmentation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 19574–19584. doi: 10.1109/CVPR52729.2023.01875. [18] WU Zifeng, SHEN Chunhua, and VAN DEN HENGEL A. Wider or deeper: Revisiting the ResNet model for visual recognition[J]. Pattern Recognition, 2019, 90: 119–133. doi: 10.1016/j.patcog.2019.01.006. [19] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929–1958. [20] LI Mingjia, XIE Binhui, LI Shuang, et al. VBLC: Visibility boosting and logit-constraint learning for domain adaptive semantic segmentation under adverse conditions[C]. 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 8605–8613. doi: 10.1609/aaai.v37i7.26036. [21] YANG Guoqing, ZHU Chuang, and ZHANG Yu. A self-training framework based on multi-scale attention fusion for weakly supervised semantic segmentation[C]. IEEE International Conference on Multimedia and Expo, Brisbane, Australia, 2023: 876–881. doi: 10.1109/ICME55011.2023.00155. [22] KRÄHENBÜHL P and KOLTUN V. Efficient inference in fully connected CRFs with gaussian edge potentials[C]. 25th International Conference on Neural Information Processing Systems, Granada, Spain, 2011: 109–117. [23] LEE J, KIM E, LEE S, et al. FickleNet: Weakly and semi-supervised semantic image segmentation using stochastic inference[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5262–5271. doi: 10.1109/CVPR.2019.00541. [24] KIM Y, YIM J, YUN J, et al. NLNL: Negative learning for noisy labels[C]. IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 101–110. doi: 10.1109/ICCV.2019.00019. [25] KIM Y, YUN J, SHON H, et al. Joint negative and positive learning for noisy labels[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 9437–9446. doi: 10.1109/CVPR46437.2021.00932. [26] EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The PASCAL visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303–338. doi: 10.1007/s11263-009-0275-4. [27] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]. 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 740–755. doi: 10.1007/978-3-319-10602-1_48. [28] HARIHARAN B, ARBELÁEZ P, BOURDEV L, et al. Semantic contours from inverse detectors[C]. International Conference on Computer Vision, Barcelon, Spain, 2011: 991–998. doi: 10.1109/ICCV.2011.6126343. [29] SHELHAMER E, LONG J, and DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640–651. doi: 10.1109/TPAMI.2016.2572683. [30] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]. IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248–255. doi: 10.1109/CVPR.2009.5206848. [31] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[C]. 3rd International Conference on Learning Representations, San Diego, USA, 2015: 24–37. [32] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834–848. doi: 10.1109/TPAMI.2017.2699184. [33] CHEN Zhaozheng, WANG Tan, WU Xiongwei, et al. Class re-activation maps for weakly-supervised semantic segmentation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 959–968. doi: 10.1109/CVPR52688.2022.00104. [34] ZHOU Tianfei, ZHANG Meijie, ZHAO Fang, et al. Regional semantic contrast and aggregation for weakly supervised semantic segmentation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 4289–4299. doi: 10.1109/CVPR52688.2022.00426. [35] HAN W, KANG S, CHOO K, et al. Complementary branch fusing class and semantic knowledge for robust weakly supervised semantic segmentation[J]. Pattern Recognition, 2025, 157: 110922. doi: 10.1016/j.patcog.2024.110922. [36] CHEN Qi, YANG Lingxiao, LAI Jianhuang, et al. Self-supervised image-specific prototype exploration for weakly supervised semantic segmentation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 4278–4288. doi: 10.1109/CVPR52688.2022.00425. [37] CHEN Liyi, LEI Chenyang, LI Ruihuang, et al. FPR: False positive rectification for weakly supervised semantic segmentation[C]. IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 1108–1118. doi: 10.1109/ICCV51070.2023.00108. [38] CHEN L C, ZHU Yukun, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]. 15th European Conference on Computer Vision, Munich, Germany, 2018: 833–851. doi: 10.1007/978-3-030-01234-2_49. [39] XIE Enze, WANG Wenhai, YU Zhiding, et al. SegFormer: Simple and efficient design for semantic segmentation with transformers[C]. 35th International Conference on Neural Information Processing Systems, 2021: 924. [40] LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 9992–10002. doi: 10.1109/ICCV48922.2021.00986. [41] CHENG Bowen, MISRA I, SCHWING A G, et al. Masked-attention mask transformer for universal image segmentation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 1280–1289. doi: 10.1109/CVPR52688.2022.00135. [42] LIU Sheng, LIU Kangning, ZHU Weicheng, et al. Adaptive early-learning correction for segmentation from noisy annotations[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 2596–2606. doi: 10.1109/CVPR52688.2022.00263. [43] LEE M, LEE S, LEE J, et al. Saliency as pseudo-pixel supervision for weakly and semi-supervised semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(10): 12341–12357. doi: 10.1109/TPAMI.2023.3273592. [44] LI Yi, DUAN Yiqun, KUANG Zhanghui, et al. Uncertainty estimation via response scaling for pseudo-mask noise mitigation in weakly-supervised semantic segmentation[C]. 36th AAAI Conference on Artificial Intelligence, Palo Alto, 2022: 1447–1455. doi: 10.1609/aaai.v36i2.20034. [45] WU Yuanchen, LI Xiaoqiang, LI Jide, et al. DINO is also a semantic guider: Exploiting class-aware affinity for weakly supervised semantic segmentation[C]. 32nd ACM International Conference on Multimedia, Melbourne, Australia, 2024: 1389–1397. doi: 10.1145/3664647.3681710. [46] XU Rongtao, WANG Changwei, SUN Jiaxi, et al. Self correspondence distillation for end-to-end weakly-supervised semantic segmentation[C]. 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 3045–3053. doi: 10.1609/aaai.v37i3.25408. -







计量
- 文章访问数: 498
- HTML全文浏览量: 302
- PDF下载量: 36
- 被引次数: 0
 下载:
下载:
