

A Model Pre-training Method with Self-Supervised Strategies for Multimodal Remote Sensing Data
-
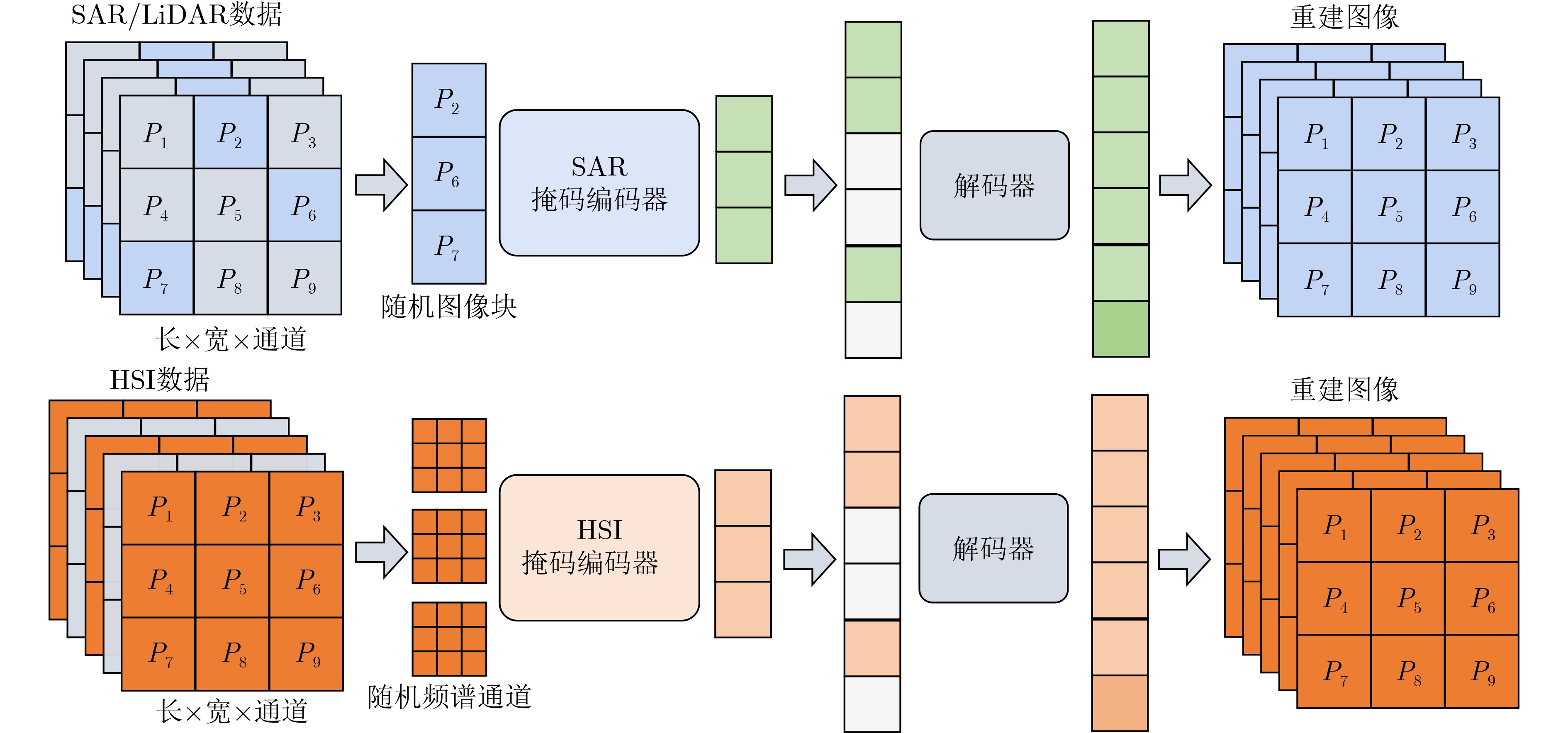
摘要: 随着遥感领域以及大模型技术的发展,自监督学习能够通过掩码-重建的方式实现基于未标注遥感数据的模型训练。然而,现有的掩码策略更多基于空间特征建模,而忽略了光谱特征建模,导致光谱数据不能充分挖掘其光谱维度信息问题。为了充分挖掘不同模态遥感数据信息,该文通过探索遥感成像机理和数据特性,构建了支持合成孔径雷达(SAR)、激光探测雷达(LiDAR)数据和高光谱(HSI)数据输入的基于掩码自编码器(MAE)自监督学习的预训练基础模型,通过空间分支随机掩码像素块重建缺失像素以及光谱分支随机掩码频谱通道重建通道,使模型能够有效表征多模态遥感图像数据的空间特征以及光谱特征,进而提升了像素级地物分类的精度。该文为了验证提出模型的有效性,对模型针对两个公开的数据集进行了分类实验,均证明了该模型训练方法的优越效果。Abstract:
Objective With the advancement of the remote sensing field and large model technologies, self-supervised learning enables model training on unlabeled remote sensing data through a mask-and-reconstruction approach. However, existing masking strategies primarily focus on spatial feature modeling while overlooking spectral feature modeling, resulting in an insufficient exploitation of spectral dimension information in spectral data. To address these challenges, this paper explores the imaging mechanisms and data characteristics of remote sensing and constructs a foundational pretraining model for self-supervised learning that supports multimodal remote sensing image data input, thereby providing a new approach for pretraining on multimodal remote sensing image data. Methods By exploring the imaging mechanisms and data characteristics of remote sensing, this paper constructs a foundational pretraining model for self-supervised learning based on Masked AutoEncoders (MAE) that supports the input of Synthetic Aperture Radar (SAR), Light Detection And Ranging (LiDAR), and HyperSpectral Imaging (HSI) data. The model employs a spatial branch that randomly masks pixel blocks to reconstruct missing pixels, and a spectral branch that randomly masks spectral channels to reconstruct the missing frequency information. This dual-branch design enables the model to effectively capture both spatial and spectral features of multimodal remote sensing image data, thereby improving the accuracy of pixel-level land cover classification. Results and Discussions The model was evaluated on land cover classification tasks using two publicly available datasets: the Berlin dataset and the Houston dataset. The experimental results demonstrate that the dual-channel attention mechanism more effectively extracts features from multimodal remote sensing image data. Through iterative parameter tuning, the model determined optimal hyperparameters tailored to each dataset. Compared to mainstream self-supervised learning methods such as BYOL, SimCLR, and SimCLRv2, our model achieved improvements in land cover classification accuracy of 1.98% on the Berlin dataset ( Table.3 ,Fig.7 ) and 2.49% on the Houston dataset (Table.4 ,Fig.8 ), respectively.Conclusions This paper proposes a model for multimodal remote sensing image data classification, which comprises two main components: a spatial branch and a spectral branch. The spatial branch is designed to process the spatial information of images by applying masking to randomly selected image patches and reconstructing the missing pixels, thereby enhancing the model’s understanding of spatial structures. The spectral branch performs masking on randomly selected spectral channels with the goal of reconstructing the missing spectral responses, effectively leveraging the spectral dimension of hyperspectral data. Experimental results indicate that the proposed model can efficiently extract and utilize both spatial and spectral information, leading to a significant improvement in classification accuracy. -
表 1 不同预训练样本数下模型分类精度(%)
预训练样本数 柏林数据集 休斯顿数据集 1000 71.34 91.82 10000 71.89 91.93 50000 72.02 92.55 100000 72.87 92.05 200000 73.32 91.73  下载: 导出CSV
下载: 导出CSV
表 2 不同空间/频谱信道掩码比例下模型分类精度(%)
掩码比例 柏林数据集 休斯顿数据集 0.1 72.11 91.08 0.3 73.65 92.32 0.5 72.86 93.01 0.7 72.31 92.34 0.9 71.44 92.54
下载: 导出CSV
表 3 柏林数据集不同模型分类性能指标(%)
分类类别/性能参数 BYOL SimCLR SimCLRv2 本文 森林 58.64 14.32 56.32 59.18 居住区 21.61 44.06 77.35 90.78 工业区 44.37 40.28 29.42 55.39 低矮植物 68.93 28.00 25.64 70.33 裸露土壤 47.33 26.87 15.60 49.72 耕地 17.65 19.86 9.68 25.68 商业区 34.43 19.77 11.39 26.92 水源 56.99 40.96 54.32 65.38 OA 69.32 70.28 71.25 73.23 AA 54.59 55.91 57.37 58.26 Kappa 50.65 55.38 59.48 58.31
下载: 导出CSV
表 4 休斯顿数据集不同模型分类性能指标(%)
分类类别/性能参数 BYOL SimCLR SimCLRv2 本文 健康草地 82.60 62.55 67.30 85.29 践踏草地 23.45 58.82 81.23 97.53 人造草坪 92.14 27.76 35.37 91.19 常绿乔木 67.16 80.62 86.49 94.63 落叶乔木 82.98 24.88 21.89 84.87 裸土 68.12 26.58 54.56 88.76 水 86.32 20.66 4.47 81.98 住宅建筑 80.20 55.89 60.07 86.56 非住宅建筑 89.92 84.30 87.80 92.55 道路 93.89 83.85 45.72 89.11 人行道 75.43 55.93 33.28 81.43 人行横道 19.09 3.25 2.77 28.06 主干道 85.21 46.45 72.84 90.42 高速公路 88.67 18.05 46.50 90.55 铁路 87.31 19.59 69.14 88.11 铺设路面停车场 45.06 31.84 87.25 96.04 未铺设路面停车场 5.32 0.00 1.30 91.33 汽车 81.65 29.54 50.12 93.92 火车 89.73 44.29 45.84 92.91 体育场 83.81 16.60 56.88 93.65 OA 91.85 90.95 91.02 93.51 AA 95.26 92.36 95.21 96.58 Kappa 90.19 88.72 89.18 91.62
下载: 导出CSV
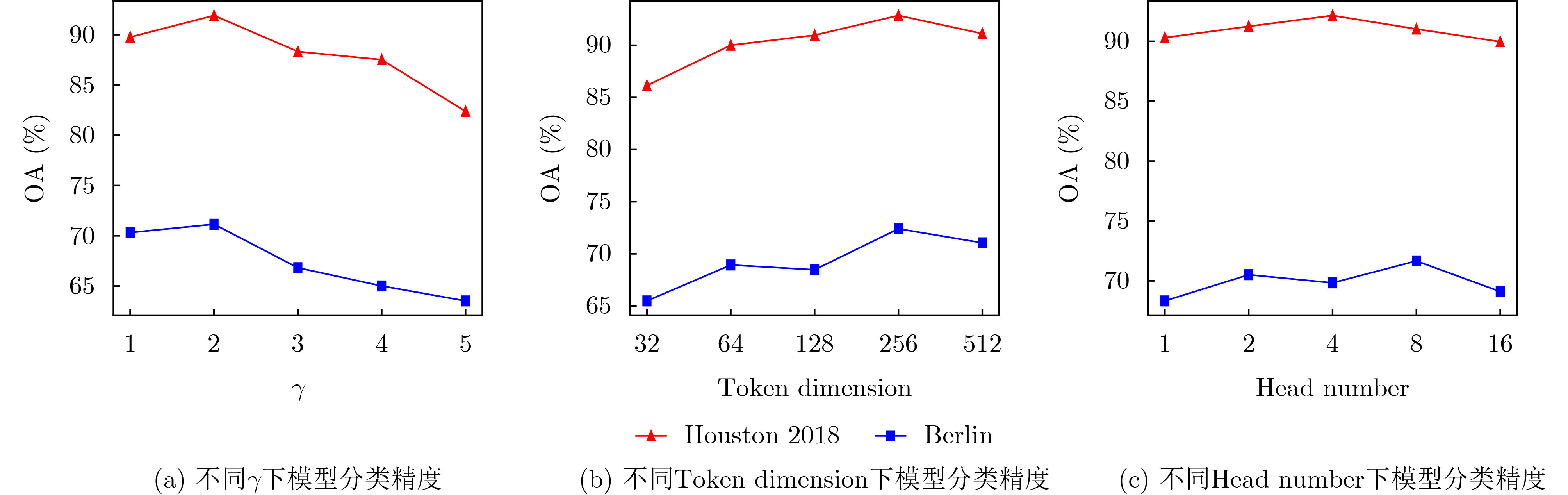
表 5 针对空间、光谱注意力机制消融实验分类结果(%)
空间注意力机制 光谱注意力机制 柏林数据集 休斯顿数据集 √ × 67.42 86.73 × √ 70.73 90.81 √ √ 73.43 92.43
下载: 导出CSV
-
[1] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [2] LIU Quanyong, PENG Jiangtao, CHEN Na, et al. Category-specific prototype self-refinement contrastive learning for few-shot hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5524416. doi: 10.1109/TGRS.2023.3317077. [3] SHI Junfei and JIN Haiyan. Riemannian nearest-regularized subspace classification for polarimetric SAR images[J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: 4028605. doi: 10.1109/LGRS.2022.3224556. [4] LUO Fulin, ZHOU Tianyuan, LIU Jiamin, et al. Multiscale diff-changed feature fusion network for hyperspectral image change detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5502713. doi: 10.1109/TGRS.2023.3241097. [5] GUO Tan, WANG Ruizhi, LUO Fulin, et al. Dual-view spectral and global spatial feature fusion network for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5512913. doi: 10.1109/TGRS.2023.3277467. [6] WU Ke, FAN Jiayuan, YE Peng, et al. Hyperspectral image classification using spectral–spatial token enhanced transformer with hash-based positional embedding[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5507016. doi: 10.1109/TGRS.2023.3258488. [7] LIU Guangyuan, LI Yangyang, CHEN Yanqiao, et al. Pol-NAS: A neural architecture search method with feature selection for PolSAR image classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022, 15: 9339–9354. doi: 10.1109/JSTARS.2022.3217047. [8] HE Kaiming, FAN Haoqi, WU Yuxin, et al. Momentum contrast for unsupervised visual representation learning[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 9726–9735. doi: 10.1109/CVPR42600.2020.00975. [9] CHEN Ting, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]. The 37th International Conference on Machine Learning, Vienna, Austria, 2020: 149. [10] HE Kaiming, CHEN Xinlei, XIE Saining, et al. Masked autoencoders are scalable vision learners[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 15979–15988. doi: 10.1109/CVPR52688.2022.01553. [11] CONG Yezhen, KHANNA S, MENG Chenlin, et al. SatMAE: Pre-training transformers for temporal and multi-spectral satellite imagery[C]. The 36th Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 197–211. [12] ROY S K, DERIA A, HONG Danfeng, et al. Multimodal fusion transformer for remote sensing image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5515620. doi: 10.1109/TGRS.2023.3286826. [13] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[C]. The 9th International Conference on Learning Representations, 2021. [14] JIANG Jiarui, HUANG Wei, ZHANG Miao, et al. Unveil benign overfitting for transformer in vision: Training dynamics, convergence, and generalization[C]. The 38th Conference on Neural Information Processing Systems, Vancouver, Canada, 2024: 135464–135625. [15] ROUET-LEDUC B and HULBERT C. Automatic detection of methane emissions in multispectral satellite imagery using a vision transformer[J]. Nature Communications, 2024, 15(1): 3801. doi: 10.1038/s41467-024-47754-y. [16] YANG Bin, WANG Xuan, XING Ying, et al. Modality fusion vision transformer for hyperspectral and LiDAR data collaborative classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024, 17: 17052–17065. doi: 10.1109/JSTARS.2024.3415729. [17] LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 9992–10002. doi: 10.1109/ICCV48922.2021.00986. [18] CHEN C F R, FAN Quanfu, and PANDA R. CrossViT: Cross-attention multi-scale vision transformer for image classification[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 347–356. doi: 10.1109/ICCV48922.2021.00041. [19] GRAHAM B, EL-NOUBY A, TOUVRON H, et al. LeViT: A vision transformer in ConvNet’s clothing for faster inference[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 12239–12249. doi: 10.1109/ICCV48922.2021.01204. [20] ZHANG Yuwen, PENG Yishu, TU Bing, et al. Local information interaction transformer for hyperspectral and LiDAR data classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2023, 16: 1130–1143. doi: 10.1109/JSTARS.2022.3232995. [21] ZHANG Jinli, CHEN Ziqiang, JI Yuanfa, et al. A multi-branch feature fusion model based on convolutional neural network for hyperspectral remote sensing image classification[J]. International Journal of Advanced Computer Science and Applications (IJACSA), 2023, 14(6): 147–156. doi: 10.14569/IJACSA.2023.0140617. [22] WANG Jinping, LI Jun, SHI Yanli, et al. AM3Net: Adaptive mutual-learning-based multimodal data fusion network[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(8): 5411–5426. doi: 10.1109/TCSVT.2022.3148257. [23] GRILL J B, STRUB F, ALTCHÉ F, et al. Bootstrap your own latent a new approach to self-supervised learning[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1786. [24] CHEN Ting, KORNBLITH S, SWERSKY K, et al. Big self-supervised models are strong semi-supervised learners[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1865. -

 下载:
下载:







图(8) / 表(5)
计量
- 文章访问数: 1323
- HTML全文浏览量: 704
- PDF下载量: 107
- 被引次数: 0
