

CFS-YOLO: An Early Fire Detection Method via Coarse and Fine Grain Search and Focus Modulation
-
摘要: 早期阶段火灾的目标较小,且易受到遮挡、类火物体的干扰。Faster RCNN, YOLO等火灾检测模型因参数量过大导致推理速度较慢,无法满足实时检测;早期火灾边缘和颜色特征在模型中丢失,造成检测精度较低。针对上述问题,该文提出了一种粗细粒度搜索与焦点调制的早期阶段火灾识别模型CFS-YOLO。通过粗粒度搜索优化特征提取网络,最大化提高推理速度,细粒度搜索用于获取早期火灾的边缘和颜色信息,避免特征信息丢失。采用焦点调制注意力机制,精准地处理关键信息,有效减少干扰。引入一种新型损失函数ShapeIoU,以进一步提高模型收敛速度和检测准确性。在真实火灾场景数据集下的实验结果表明,CFS-YOLO的检测精度和召回率分别达到了98.23%和98.76%。相较于基准模型,所提出的CFS-YOLO参数量降低14.7M,精度、召回率和F1分别提高13.33%, 4.96%和9.36%,fps达到75,验证了CFS-YOLO在满足高精度的同时,达到了较高的推理速度,实现了实时检测。与一系列主流模型相比,该文模型的检测精度和速度均表现出优异性能。Abstract:
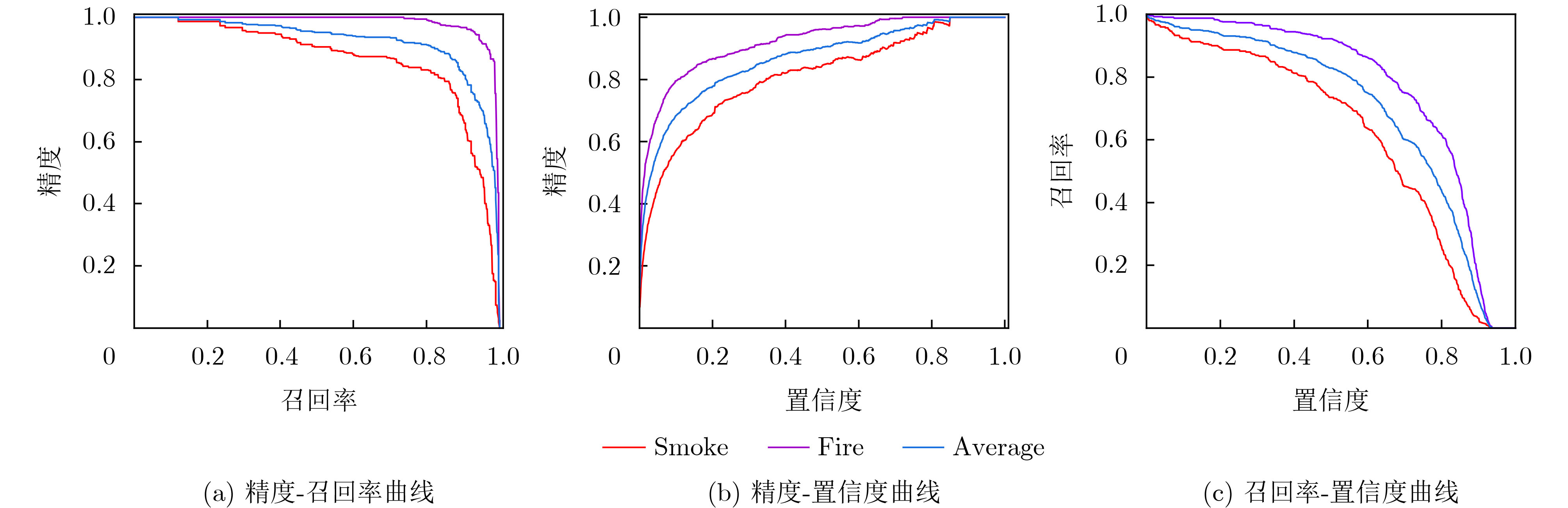
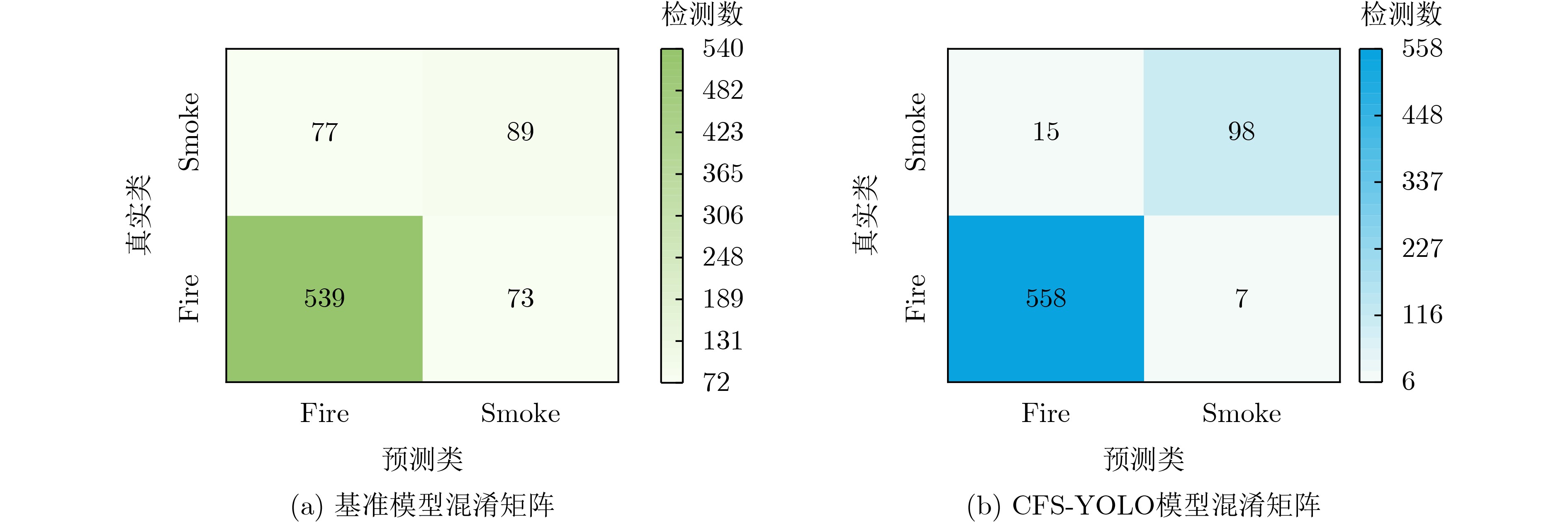
Objective Fire is a frequent disaster, and detecting early fire phenomena effectively can significantly reduce casualties. Traditional fire detection methods, which rely on sensor devices, struggle to accurately detect fires in open spaces. With the development of deep learning, fire detection can be automated through image capture devices like cameras, improving detection accuracy. However, early-stage fires are small and often obscured by occlusion or fire-like objects. Fire detection models, such as Faster Region-based Convolutional Neural Networks (R-CNN) and You Only Look Once (YOLO), often fail to meet real-time detection requirements due to their large number of parameters, which slow down inference. Additionally, existing models face challenges in preserving fire edges and color features, leading to reduced detection accuracy. To address these issues, this paper proposes CFS-YOLO, an early-stage fire recognition model that incorporates coarse- and fine-grained search and focus modulation, enhancing both the speed and accuracy of fire detection. Methods To enhance the detection efficiency of the model, a coarse- and fine-grained search strategy is introduced to optimize the lightweight structure of the Unit Inference Block (UIB) module, which consists of four possible instantiations ( Fig. 2 ). A coarse-grained search quickly evaluates different network architectures by adapting the network topology, adding optional convolutional modules to the UIB, and modifying the arrangement and combination of the modules. Dimensionality tuning is performed during the search process to select feature map dimensions and convolutional kernel sizes, generating candidate architectures by expanding or compressing the network width. During the filtering process, candidate architectures are evaluated based on multiple performance metrics. A multi-objective optimization approach is used to find the Pareto-optimal solution, retaining candidate architectures that balance accuracy and efficiency. Weight sharing is employed to improve parameter reuse. The fine-grained search refines the candidate architectures from the coarse-grained search, dynamically adjusting hyperparameters such as learning rate, batch size, regularization coefficient, and optimization algorithm according to the model's performance during training. It analyzes and adjusts each module layer by layer to accelerate convergence and better adapt to data complexity. To address the challenges posed by complex scenes and interfering objects, a focus-modulated attention mechanism is introduced, as shown in (Fig. 3 ). The input fire images are processed through a lightweight linear layer, followed by selective aggregation of contextual information to the modulators of each query token through a hierarchical contextualization module and gating mechanism. These aggregated modulators are injected into each query token via affine changes to generate outputs. This approach helps tackle the challenges of detecting small targets or objects in complex backgrounds, effectively capturing long-range dependencies and contextual information in the image. Finally, to account for the effects of anchor shape and angle, the model introduces a ShapeIoU loss function (Fig. 4 ). This function considers the influence of distance, shape, and angle between the true and prior frames on the predictor’s frame regression, enabling accurate measurement of the similarity between the true and predicted frames.Results and Discussions ( Table 1 ) presents the results of the ablation experiments. The results show that CFS-YOLO achieved optimal performance. Compared to the baseline model, CFS-YOLO improves precision, recall, and F1 score by 13.33%, 4.96%, and 9.36%, respectively, and increases fps by 22. The model also shows significant improvements in APflame, APsmoke, and mAP, with increases of 11.1%, 16.2%, and 13.65%, respectively, validating the model’s effectiveness. (Fig. 6 ) illustrates the detection heat map for the ablation model, demonstrating that the combination of the focus-modulated attention mechanism and the ShapeIoU loss function effectively captures key features, confirming their synergistic effect. (Fig. 7 ) shows the loss curve plots for IoU and ShapeIoU. At the 80th training cycle, the loss of the baseline model stabilizes and converges to 0.5. In contrast, the bounding box loss and DFL loss with the ShapeIoU loss function converge to 0.3 by the 40th cycle, while the classification loss reaches 0.15 by the 80th epoch, highlighting the effectiveness of the ShapeIoU loss function. (Table 2 ) compares the performance with several state-of-the-art target detection models, while (Table 3 ) presents a comparison of different flame detection algorithms.The results show that CFS-YOLO leads in performance and demonstrates higher computational efficiency, indicating its potential application value in the flame detection field. (Fig. 10 ) and (Fig. 11 ) provide visualizations of the CFS-YOLO detection results, showing its excellent performance in capturing fire information despite background interference and small fire targets.Conclusions CFS-YOLO demonstrates outstanding performance in early fire detection, achieving detection speeds of up to 75 frame. It provides high inference speeds, meeting the requirements for real-time detection. Compared to state-of-the-art object detection models, CFS-YOLO outperforms in both detection accuracy and speed. -
1 粗粒度搜索
1: 输入:候选架构数量 N , 最大训练 epochs 数 E 2: 输出:最优候选架构 Abest 3: SEARCH_SPACE # 初始化候选架构空间 步骤 1: 使用 NAS 生成候选架构 4: for i = 1 to N do 5: Acandidate ← create_random_architecture() # 生成基础架构 6: Acandidate ← adjust_topology(Acandidate) # 调整拓扑结构 7: Acandidate ← adjust_dimensions(Acandidate) # 更改输入输出
通道数8: Acandidate ← flexible_selection(Acandidate)# 选择特征图维度
和卷积核大小9: SEARCH_SPACE.append(Acandidate) # 将候选框架添加到搜
索空间10: end for 步骤 2:评估每个候选架构 11: PERFORMANCE_METRIC # 初始化性能指标 12: for each Aarchitecture ∈ SEARCH_SPACE do 13: model ← build_model(Aarchitecture) # 构建模型 14: train(model, E) #对模型进行 E 次训练 15: performance ← evaluate_model(model) # 评估模型性能 16: PERFORMANCE_METRIC.append(performance) # 储
存性能指标17: end for 步骤 3:执行多目标优化 18: PARETO_FRONT ← compute_pareto_front(PERFORMANCE_METRIC) # 计算架构的 Pareto 最优解 19: Abest ← select_balanced_architecture(PARETO_FRONT) # 选择平衡准确性和效率的最优架构 步骤 4:权重共享 20: for each layer in Abest do 21: apply_weight_sharing(layer) # 在层内实现权重共享 22: end for 23: return Abest # 返回最优候选架构  下载: 导出CSV
下载: 导出CSV
表 1 消融实验结果(%)
实验组号 UIB 焦点调制 ShapeIoU 精度 召回率 F1 fps AP火焰 AP烟雾 mAP 1 × × × 84.90 93.80 89.13 53 88.40 68.50 78.45 2 √ × × 95.70 92.90 94.28 70 91.80 77.40 84.60 3 × √ × 94.10 94.45 94.27 54 96.80 71.50 84.15 4 × × √ 93.75 94.60 94.17 56 98.50 67.10 82.80 5 × √ √ 95.35 95.45 95.39 57 96.90 74.00 85.45 6 √ √ × 98.05 94.65 96.32 73 96.80 82.40 89.60 7 √ × √ 97.50 94.55 96.00 72 96.90 71.60 84.25 8 √ √ √ 98.23 98.76 98.49 75 99.50 84.70 92.10
下载: 导出CSV
表 2 不同算法性能对比
算法 方法 精度 召回率 参数量(M) 主流算法 Faster R-CNN 0.692 0.960 41.30 Deformable DETR 0.911 0.620 40.00 MobileNet 0.800 0.830 3.40 SqueezeNet 0.810 0.930 48.00 AlexNet 0.850 0.900 16.40 GoogLeNet 0.860 0.980 5.00 Resnet50 0.900 0.920 25.60 EfficientNet 0.810 0.820 7.80 YOLOv3 0.817 0.960 61.53 YOLOv5 YOLOv5 0.811 0.938 20.90 YOLOv5-s 0.916 0.896 20.74 FCLGYOLO 0.872 0.881 20.90 YOLOv5+ShuffleNetv2+SIoU 0.893 0.812 17.10 YOLOv8 YOLOv8 0.849 0.938 25.90 SlimNeck-YOLOv8 0.944 0.836 – FFYOLO 0.918 0.905 20.72 LUFFD-YOLO 0.809 0.811 22.45 YOLO-CSQ 0.931 0.877 20.40 CFS-YOLO 0.982 0.988 11.20
下载: 导出CSV
表 3 不同火焰检测算法性能对比
方法 精度 召回率 参数量(M) 文献[26] FCLGYOLO 0.872 0.881 20.90 文献[27] YOLOv5-s 0.916 0.896 20.74 文献[28] Slim Neck-YOLOv8 0.944 0.836 – 文献[29] DPMNet 0.750 0.674 11.00 文献[30] FLE 0.945 0.894 – 文献[31] YOLOv5+ShuffleNetv2+SIou 0.893 0.812 17.10 文献[32] MFE+IDS+CA 0.835 0.774 4.80 文献[33] EdgeFireSmoke 0.757 0.625 1.55 本文算法 CFS-YOLO 0.982 0.988 11.20
下载: 导出CSV
-
[1] CHEN Yute and HWANG J K. A power-line-based sensor network for proactive electrical fire precaution and early discovery[J]. IEEE Transactions on Power Delivery, 2008, 23(2): 633–639. doi: 10.1109/TPWRD.2008.917945. [2] SRIDHAR P, THANGAVEL S K, PARAMESWARAN L, et al. Fire sensor and surveillance camera-based GTCNN for fire detection system[J]. IEEE Sensors Journal, 2023, 23(7): 7626–7633. doi: 10.1109/JSEN.2023.3244833. [3] 李倩, 岳亮. 吸气式感烟火灾探测器设计改进研究[J]. 消防科学与技术, 2021, 40(11): 1644–1647. doi: 10.3969/j.issn.1009-0029.2021.11.018.LI Qian and YUE Liang. Research on design improvement of aspirating smoke detector[J]. Fire Science and Technology, 2021, 40(11): 1644–1647. doi: 10.3969/j.issn.1009-0029.2021.11.018. [4] WANG Yong, HAN Yu, TANG Zhaojia, et al. A fast video fire detection of irregular burning feature in fire-flame using in indoor fire sensing robots[J]. IEEE Transactions on Instrumentation and Measurement, 2022, 71: 7505414. doi: 10.1109/TIM.2022.3212986. [5] CHAOXIA Chenyu, SHANG Weiwei, ZHANG Fei, et al. Weakly aligned multimodal flame detection for fire-fighting robots[J]. IEEE Transactions on Industrial Informatics, 2023, 19(3): 2866–2875. doi: 10.1109/TII.2022.3158668. [6] BUSHNAQ O M, CHAABAN A, and AL-NAFFOURI T Y. The role of UAV-IoT networks in future wildfire detection[J]. IEEE Internet of Things Journal, 2021, 8(23): 16984–16999. doi: 10.1109/JIOT.2021.3077593. [7] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 580–587. doi: 10.1109/CVPR.2014.81. [8] GIRSHICK R. Fast R-CNN[C]. 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1440–1448. doi: 10.1109/ICCV.2015.169. [9] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031. [10] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 779–788. doi: 10.1109/CVPR.2016.91. [11] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot MultiBox detector[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 21–37. doi: 10.1007/978-3-319-46448-0_2. [12] CHAN A B and VASCONCELOS N. Modeling, clustering, and segmenting video with mixtures of dynamic textures[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(5): 909–926. doi: 10.1109/TPAMI.2007.70738. [13] CHAKRABORTY I and PAUL T K. A hybrid clustering algorithm for fire detection in video and analysis with color based thresholding method[C]. The 2010 International Conference on Advances in Computer Engineering, Bangalore, India, 2010: 277–280. doi: 10.1109/ACE.2010.12. [14] WANG Yijun. Simulation study of fuzzy neural control fire alarm system based on clustering algorithm[C]. The 2022 2nd International Conference on Algorithms, High Performance Computing and Artificial Intelligence, Guangzhou, China, 2022: 217–221. doi: 10.1109/AHPCAI57455.2022.10087561. [15] DIMITROPOULOS K, BARMPOUTIS P, and GRAMMALIDIS N. Spatio-temporal flame modeling and dynamic texture analysis for automatic video-based fire detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2015, 25(2): 339–351. doi: 10.1109/TCSVT.2014.2339592. [16] ASIH L C, STHEVANIE F, and RAMADHANI K N. Visual based fire detection system using speeded up robust feature and support vector machine[C]. The 2018 6th International Conference on Information and Communication Technology, Bandung, Indonesia, 2018: 485–488. doi: 10.1109/ICoICT.2018.8528752. [17] YAR H, HUSSAIN T, AGARWAL M, et al. Optimized dual fire attention network and medium-scale fire classification benchmark[J]. IEEE Transactions on Image Processing, 2022, 31: 6331–6343. doi: 10.1109/TIP.2022.3207006. [18] MUHAMMAD K, AHMAD J, LV Zhihan, et al. Efficient deep CNN-based fire detection and localization in video surveillance applications[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019, 49(7): 1419–1434. doi: 10.1109/TSMC.2018.2830099. [19] LI Changdi, LI Guangye, SONG Yichen, et al. Fast forest fire detection and segmentation application for UAV-assisted mobile edge computing system[J]. IEEE Internet of Things Journal, 2024, 11(16): 26690–26699. doi: 10.1109/JIOT.2023.3311950. [20] MUHAMMAD K, KHAN S, ELHOSENY M, et al. Efficient fire detection for uncertain surveillance environment[J]. IEEE Transactions on Industrial Informatics, 2019, 15(5): 3113–3122. doi: 10.1109/TII.2019.2897594. [21] HUANG Lida, LIU Gang, WANG Yan, et al. Fire detection in video surveillances using convolutional neural networks and wavelet transform[J]. Engineering Applications of Artificial Intelligence, 2022, 110: 104737. doi: 10.1016/j.engappai.2022.104737. [22] ZHANG Lin, WANG Mingyang, DING Yunhong, et al. MS-FRCNN: A multi-scale faster RCNN model for small target forest fire detection[J]. Forests, 2023, 14(3): 616. doi: 10.3390/f14030616. [23] CHAOXIA Chenyu, SHANG Weiwei, and ZHANG Fei. Information-guided flame detection based on faster R-CNN[J]. IEEE Access, 2020, 8: 58923–58932. doi: 10.1109/ACCESS.2020.2982994. [24] CHEKNANE M, BENDOUMA T, and BOUDOUH S S. Advancing fire detection: Two-stage deep learning with hybrid feature extraction using faster R-CNN approach[J]. Signal, Image and Video Processing, 2024, 18(6): 5503–5510. doi: 10.1007/s11760-024-03250-w. [25] 赵杰, 汪洪法, 吴凯. 基于特征增强及多层次融合的火灾火焰检测[J]. 中国安全生产科学技术, 2024, 20(1): 93–99. doi: 10.11731/j.issn.1673-193x.2024.01.014.ZHAO Jie, WANG Hongfa, and WU Kai. Fire flame detection based on feature enhancement and multi-level fusion[J]. Journal of Safety Science and Technology, 2024, 20(1): 93–99. doi: 10.11731/j.issn.1673-193x.2024.01.014. [26] REN Dong, ZHANG Yang, WANG Lu, et al. FCLGYOLO: Feature constraint and local guided global feature for fire detection in unmanned aerial vehicle imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024, 17: 5864–5875. doi: 10.1109/JSTARS.2024.3358544. [27] QADIR Z, LE K, BAO V N Q, et al. Deep learning-based intelligent post-bushfire detection using UAVs[J]. IEEE Geoscience and Remote Sensing Letters, 2024, 21: 5000605. doi: 10.1109/LGRS.2023.3329509. [28] 邓力, 周进, 刘全义. 基于改进YOLOv8的火焰与烟雾检测算法[J/OL]. 清华大学学报: 自然科学版: 1–9. https://doi.org/10.16511/j.cnki.qhdxxb.2024.27.036, 2024.DENG Li, ZHOU Jin, and LIU Quanyi. Fire and smoke detection algorithm based on improved YOLOv8[J/OL]. Jouranl of Tsinghua University: Science and Technology: 1–9. https://doi.org/10.16511/j.cnki.qhdxxb.2024.27.036, 2024. [29] WANG Guanbo, LI Haiyan, SHENG V, et al. DPMNet: A remote sensing forest fire real-time detection network driven by dual pathways and multidimensional interactions of features[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2025, 35(1): 783–799. doi: 10.1109/TCSVT.2024.3462432. [30] PATEL A N, SRIVASTAVA G, MADDIKUNTA P K R, et al. A trustable federated learning framework for rapid fire smoke detection at the edge in smart home environments[J]. IEEE Internet of Things Journal, 2024, 11(23): 37708–37717. doi: 10.1109/JIOT.2024.3439228. [31] 曹康壮, 焦双健. 融合注意力机制的轻量级火灾检测模型[J]. 消防科学与技术, 2024, 43(3): 378–383. doi: 10.3969/j.issn.1009-0029.2024.03.017.CAO Kangzhuang and JIAO Shuangjian. A lightweight fire detection model integrating attention mechanism[J]. Fire Science and Technology, 2024, 43(3): 378–383. doi: 10.3969/j.issn.1009-0029.2024.03.017. [32] LI Songbin, YAN Qiandong, and LIU Peng. An efficient fire detection method based on multiscale feature extraction, implicit deep supervision and channel attention mechanism[J]. IEEE Transactions on Image Processing, 2020, 29: 8467–8475. doi: 10.1109/TIP.2020.3016431. [33] ALMEIDA J S, HUANG Chenxi, NOGUEIRA F G, et al. EdgeFireSmoke: A novel lightweight CNN model for real-time video fire–smoke detection[J]. IEEE Transactions on Industrial Informatics, 2022, 18(11): 7889–7898. doi: 10.1109/TII.2021.3138752. [34] ZHENG Zhaohui, WANG Ping, LIU Wei, et al. Distance-IoU loss: Faster and better learning for bounding box regression[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 12993–13000. doi: 10.1609/aaai.v34i07.6999. [35] ZHANG Hao and ZHANG Shuaijie. Shape-IoU: More accurate metric considering bounding box shape and scale[EB/OL]. https://doi.org/10.48550/arXiv.2312.17663, 2023. [36] ZHU Xizhou, SU Weijie, LU Lewei, et al. Deformable DETR: Deformable transformers for end-to-end object detection[C]. The Ninth International Conference on Learning Representations, Vienna, Austria, 2021: 3448. [37] REDMON J and FARHADI A. YOLOv3: An incremental improvement[EB/OL]. https://doi.org/10.48550/arXiv.1804.02767, 2018. [38] JOCHER G, STOKEN A, BOROVEC J, et al. ultralytics/yolov5: v5.0 - YOLOv5-P6 1280 models, AWS, supervise. ly and YouTube integrations[EB/OL]. https://zenodo.org/record/4679653, 2021. [39] VARGHESE R and M S. YOLOv8: A novel object detection algorithm with enhanced performance and robustness[C]. 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems, Chennai, India, 2024: 1–6. doi: 10.1109/ADICS58448.2024.10533619. [40] HOWARD A G, ZHU Menglong, CHEN Bo, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[EB/OL]. https://doi.org/10.48550/arXiv.1704.04861, 2017. [41] IANDOLA F N, HAN Song, MOSKEWICZ M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size[EB/OL]. https://doi.org/10.48550/arXiv.1602.07360, 2016. [42] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84–90. doi: 10.1145/3065386. [43] SZEGEDY C, LIU Wei, JIA Yangqing, et al. Going deeper with convolutions[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 1–9. doi: 10.1109/CVPR.2015.7298594. [44] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [45] DHIMAN A, SHAH N, ADHIKARI P, et al. Firefighting robot with deep learning and machine vision[J]. Neural Computing and Applications, 2022, 34(4): 2831–2839. doi: 10.1007/s00521-021-06537-y. [46] YUN Bensheng, ZHENG Yanan, LIN Zhenyu, et al. FFYOLO: A lightweight forest fire detection model based on YOLOv8[J]. Fire, 2024, 7(3): 93. doi: 10.3390/fire7030093. [47] HAN Yuhang, DUAN Bingchen, GUAN Renxiang, et al. LUFFD-YOLO: A lightweight model for UAV remote sensing forest fire detection based on attention mechanism and multi-level feature fusion[J]. Remote Sensing, 2024, 16(12): 2177. doi: 10.3390/rs16122177. [48] LUAN Tian, ZHOU Shixiong, LIU Lifeng, et al. Tiny-object detection based on optimized YOLO-CSQ for accurate drone detection in wildfire scenarios[J]. Drones, 2024, 8(9): 454. doi: 10.3390/drones8090454. -


 下载:
下载:











图(12) / 表(4)
计量
- 文章访问数: 1636
- HTML全文浏览量: 1093
- PDF下载量: 185
- 被引次数: 0
