

Geometrically Consistent Based Neural Radiance Field for Satellite City Scene Rendering and Digital Surface Model Generation in Sparse Viewpoints
-
摘要: 卫星遥感提供了全球、连续、多尺度的地表观测能力。近年来,神经辐射场(NeRF)因其连续渲染和隐式重建特性,在自动驾驶与大场景重建等领域表现出良好鲁棒性,受到广泛关注。然而,NeRF在卫星对地观测中的应用效果有限,主要因其训练需大量多视角图像,而卫星影像获取受限。在视角稀疏时,模型易对训练视角过拟合,导致新视角下性能下降。针对上述问题,该文提出一种新的方法,通过在NeRF的训练过程中引入场景深度与表面法线的几何约束,旨在提升在稀疏视角条件下的渲染与数字表面模型(DSM)生成能力。通过在DFC2019数据集上进行广泛实验,验证了所提出方法的有效性。实验结果表明,采用几何约束的NeRF模型在稀疏视角条件下的新视角合成和DSM生成任务上均取得了领先的结果,显示出其在稀疏视角条件下卫星观测场景中的应用潜力。Abstract:
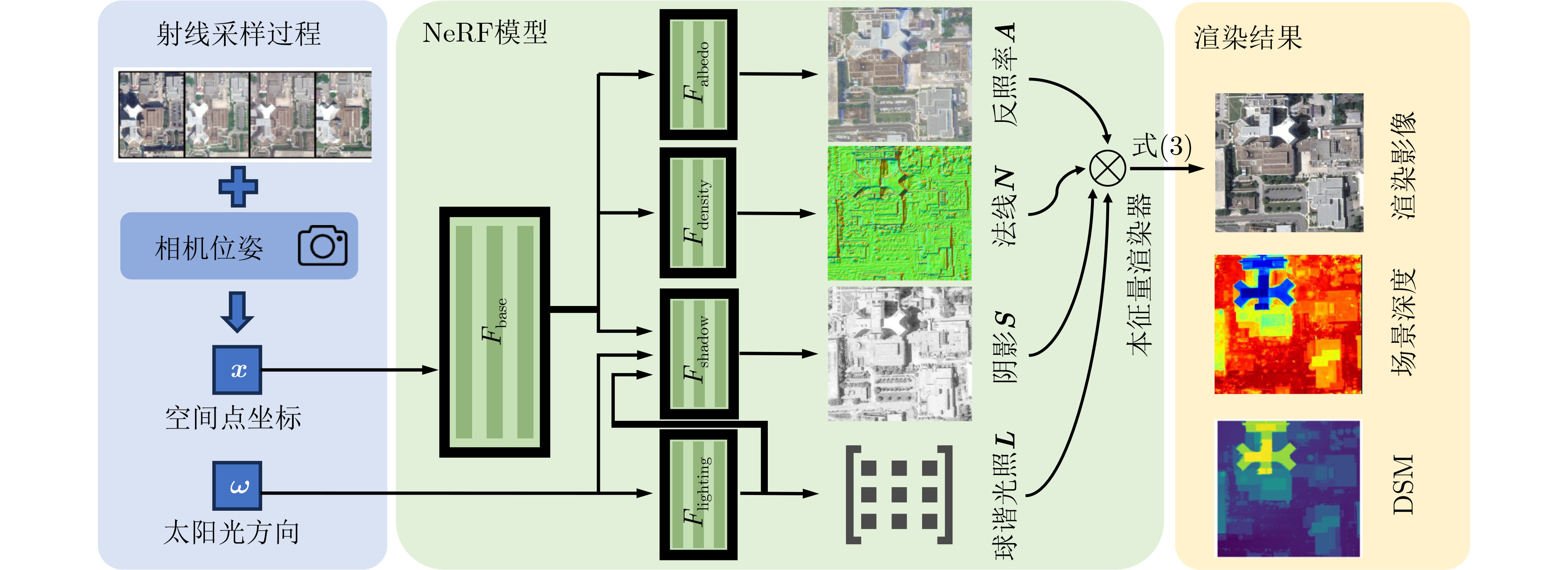
Objective Satellite-based Earth observation enables global, continuous, multi-scale, and multi-dimensional surface monitoring through diverse remote sensing techniques. Recent progress in 3D modelling and rendering has seen widespread adoption of Neural Radiance Fields (NeRF), owing to their continuous-view synthesis and implicit geometry representation. Although NeRF performs robustly in areas such as autonomous driving and large-scale scene reconstruction, its direct application to satellite observation scenarios remains limited. This limitation arises primarily from the nature of satellite imaging, which often lacks the tens or hundreds of viewpoints typically required for NeRF training. Under sparse-view conditions, NeRF tends to overfit the available training perspectives, leading to poor generalization to novel viewpoints. Methods To address the performance limitations of NeRF under sparse-view conditions, this study proposes an approach that introduces geometric constraints on scene depth and surface normals during model training. These constraints are designed to compensate for the lack of prior knowledge inherent in sparse-view satellite imagery and to improve rendering and DSM generation. The approach leverages the importance of scene geometry in both novel view synthesis and DSM generation, particularly in accurately representing spatial structures through DSMs. To mitigate the degradation in NeRF performance under limited viewpoint conditions, the geometric relationships between scene depth and surface normals are formulated as loss functions. These functions enforce consistency between estimated depth and surface orientation, enabling the model to learn more reliable geometric features despite limited input data. The proposed constraints guide the model toward generating geometrically coherent and realistic scene reconstructions. Results and Discussions The proposed method is evaluated on the DFC2019 dataset to assess its effectiveness in novel view synthesis and DSM generation under sparse-view conditions. Experimental results demonstrate that the NeRF model with geometric constraints achieves superior performance across both tasks, confirming its applicability to satellite observation scenarios with limited viewpoints. For novel view synthesis, model performance is assessed using 2, 3, and 5 input images. The proposed method consistently outperforms existing approaches across all configurations. In the JAX 004 scene, Peak Signal-to-Noise Ratio (PSNR) values of 21.365 dB, 21.619 dB, and 23.681 dB are achieved under the 2-view, 3-view, and 5-view settings, respectively. Moreover, the method exhibits the smallest degradation in PSNR and Structural Similarity Index (SSIM) as the number of training views decreases, indicating greater robustness under sparse input conditions. Qualitative results further confirm that the method yields sharper and more detailed renderings across all view configurations. For DSM generation, the proposed method achieves comparable or better performance relative to other NeRF-based approaches in most test scenarios. In the JAX 004 scene, Mean Absolute Error (MAE) values of 2.414 m, 2.198 m, and 1.602 m are obtained under the 2-view, 3-view, and 5-view settings, respectively. Qualitative assessments show that the generated DSMs exhibit clearer structural boundaries and finer geometric details compared to those produced by baseline methods. Conclusions Incorporating geometric consistency constraints between scene depth and surface normals enhances the model’s ability to capture the spatial structure of objects in satellite imagery. The proposed method achieves state-of-the-art performance in both novel view synthesis and DSM generation tasks under sparse-view conditions, outperforming both NeRF-based and traditional Multi-View Stereo (MVS) approaches. -
表 1 DFC2019数据集具体细节
JAX 004 JAX 068 JAX 214 JAX 260 训练/测试样本数量 9/2 17/2 21/3 15/2 高程范围(m) [–24, 1] [–27. 30] [–29, 73] [–30, 13]  下载: 导出CSV
下载: 导出CSV
表 2 各种方法在不同AOI上的实验结果表格
(a)JAX004实验结果 训练视角数量 PSNR SSIM Altitude MAE (m) 2 3 5 2 3 5 2 3 5 NeRF[1] 12.168 13.376 14.279 0.421 0.474 0.493 5.273 5.137 4.493 S-NeRF[2] 15.867 16.972 18.687 0.691 0.717 0.757 4.513 4.337 4.001 Sat-NeRF[3] 20.619 20.831 22.186 0.794 0.794 0.814 2.917 2.907 2.738 基线模型[29] 20.614 20.943 22.167 0.786 0.781 0.804 2.614 2.437 1.986 本文算法 21.365 21.619 23.681 0.801 0.812 0.848 2.414 2.198 1.602 S2P[29] – – – – – – 1.932 1.804 1.437 (b) JAX068实验结果 训练视角数量 PSNR SSIM Altitude MAE (m) 2 3 5 2 3 5 2 3 5 NeRF[1] 7.329 7.845 8.772 0.411 0.42 0.456 9.132 6.467 4.545 S-NeRF[2] 15.874 17.129 20.191 0.781 0.799 0.816 6.179 4.777 3.826 Sat-NeRF[3] 16.536 18.425 21.215 0.803 0.810 0.843 5.842 4.387 3.411 基线模型[29] 18.473 18.431 22.017 0.800 0.831 0.843 4.539 3.048 2.619 本文算法 19.837 19.493 23.271 0.807 0.833 0.843 3.316 2.531 2.249 S2P[29] – – – – – – 2.883 2.314 2.032 (c) JAX214实验结果 训练视角数量 PSNR SSIM Altitude MAE (m) 2 3 5 2 3 5 2 3 5 NeRF[1] 10.892 12.543 12.632 0.421 0.433 0.487 9.964 9.176 8.721 S-NeRF[2] 12.816 12.997 14.573 0.557 0.571 0.599 8.142 8.157 7.134 Sat-NeRF[3] 15.834 16.214 17.691 0.804 0.806 0.814 5.101 5.147 4.721 基线模型[29] 16.117 16.924 18.871 0.817 0.863 0.840 4.617 4.394 3.466 本文算法 18.991 20.505 21.317 0.820 0.867 0.831 3.217 2.496 2.408 S2P[29] – – – – – – 3.014 2.837 2.414 (d) JAX260实验结果 训练视角数量 PSNR SSIM Altitude MAE (m) 2 3 5 2 3 5 2 3 5 NeRF[1] 8.762 8.712 10.753 0.318 0.346 0.384 7.816 7.591 6.622 S-NeRF[2] 11.259 11.573 13.836 0.543 0.551 0.654 6.165 6.189 5.432 Sat-NeRF[3] 16.007 15.715 16.314 0.641 0.644 0.694 3.857 3.423 2.995 基线模型[29] 16.179 16.197 18.423 0.688 0.689 0.735 3.386 3.214 2.887 本文算法 16.728 17.150 19.934 0.690 0.690 0.742 3.016 2.926 2.119 S2P[29] – – – – – – 3.423 2.873 2.317
下载: 导出CSV
表 3 本文使用各种损失函数在JAX068场景中的实验结果表格
训练视角数量 PSNR SSIM Altitude MAE (m) 2 3 5 2 3 5 2 3 5 基线模型 18.473 18.431 22.017 0.800 0.831 0.843 4.539 3.048 2.619 基线模型+${L_{{\text{DS}}}}$ 18.857 19.011 22.719 0.796 0.831 0.837 3.817 2.764 2.418 基线模型+${L_{{\text{GC}}}}$ 19.017 19.082 22.947 0.804 0.831 0.840 3.782 2.716 2.298 基线模型+${L_{{\text{full}}}}$ 19.837 19.493 23.271 0.807 0.833 0.843 3.316 2.531 2.249
下载: 导出CSV
-
[1] MILDENHALL B, SRINIVASAN P P, TANCIK M, et al. NeRF: Representing scenes as neural radiance fields for view synthesis[J]. Communications of the ACM, 2021, 65(1): 99–106. doi: 10.1145/3503250. [2] DERKSEN D and IZZO D. Shadow neural radiance fields for multi-view satellite photogrammetry[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 1152–1161. doi: 10.1109/CVPRW53098.2021.00126. [3] MARÍ R, FACCIOLO G, and EHRET T. Sat-NeRF: Learning multi-view satellite photogrammetry with transient objects and shadow modeling using rpc cameras[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 1310–1320. doi: 10.1109/CVPRW56347.2022.00137. [4] LE SAUX B, YOKOYA N, HANSCH R, et al. 2019 Data fusion contest [technical committees][J]. IEEE Geoscience and Remote Sensing Magazine, 2019, 7(1): 103–105. doi: 10.1109/MGRS.2019.2893783. [5] TANCIK M, MILDENHALL B, WANG T, et al. Learned initializations for optimizing coordinate-based neural representations[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 2846–2855. doi: 10.1109/CVPR46437.2021.00287. [6] JAIN A, TANCIK M, and ABBEEL P. Putting NeRF on a diet: Semantically consistent few-shot view synthesis[C]. The IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 5865–5874. doi: 10.1109/ICCV48922.2021.00583. [7] HIRSCHMULLER H. Accurate and efficient stereo processing by semi-global matching and mutual information[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, San Diego, USA, 2005: 807–814. doi: 10.1109/CVPR.2005.56. [8] D'ANGELO P and KUSCHK G. Dense multi-view stereo from satellite imagery[C]. Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 2012: 6944–6947. doi: 10.1109/IGARSS.2012.6352565. [9] BEYER R A, ALEXANDROV O, and MCMICHAEL S. The ames stereo pipeline: NASA’s open source software for deriving and processing terrain data[J]. Earth and Space Science, 2018, 5(9): 537–548. doi: 10.1029/2018EA000409. [10] DE FRANCHIS C, MEINHARDT-LLOPIS E, MICHEL J, et al. An automatic and modular stereo pipeline for pushbroom images[C]. The ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Zürich, Switzerland, 2014: 49–56. doi: 10.5194/isprsannals-ii-3-49-2014. [11] GONG K and FRITSCH D. DSM generation from high resolution multi-view stereo satellite imagery[J]. Photogrammetric Engineering & Remote Sensing, 2019, 85(5): 379–387. doi: 10.14358/PERS.85.5.379. [12] HIRSCHMULLER H. Stereo processing by semiglobal matching and mutual information[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(2): 328–341. doi: 10.1109/TPAMI.2007.1166. [13] YAO Yao, LUO Zixin, LI Shiwei, et al. MVSNet: Depth inference for unstructured multi-view stereo[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 785–801. doi: 10.1007/978-3-030-01237-3_47. [14] GU Xiaodong, FAN Zhiwen, ZHU Siyu, et al. Cascade cost volume for high-resolution multi-view stereo and stereo matching[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 2492–2501. doi: 10.1109/CVPR42600.2020.00257. [15] CHENG Shuo, XU Zexiang, ZHU Shilin, et al. Deep stereo using adaptive thin volume representation with uncertainty awareness[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 2521–2531. doi: 10.1109/CVPR42600.2020.00260. [16] YANG Jiayu, MAO Wei, ALVAREZ J M, et al. Cost volume pyramid based depth inference for multi-view stereo[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 4876–4885. doi: 10.1109/CVPR42600.2020.00493. [17] GAO Jian, LIU Jin, and JI Shunping. A general deep learning based framework for 3D reconstruction from multi-view stereo satellite images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2023, 195: 446–461. doi: 10.1016/j.isprsjprs.2022.12.012. [18] MARÍ R, FACCIOLO G, and EHRET T. Multi-date earth observation NeRF: The detail is in the shadows[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 2035–2045. doi: 10.1109/CVPRW59228.2023.00197. [19] SUN Wenbo, LU Yao, ZHANG Yichen, et al. Neural radiance fields for multi-view satellite photogrammetry leveraging intrinsic decomposition[C]. The IEEE International Geoscience and Remote Sensing Symposium, Athens, Greece, 2024: 4631–4635. doi: 10.1109/IGARSS53475.2024.10641455. [20] YU A, YE V, TANCIK M, et al. pixelNeRF: Neural radiance fields from one or few images[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 4576–4585. doi: 10.1109/CVPR46437.2021.00455. [21] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. Proceedings of the 9th International Conference on Learning Representations, 2021. [22] XU Dejia, JIANG Yifan, WANG Peihao, et al. SinNeRF: Training neural radiance fields on complex scenes from a single image[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 736–753. doi: 10.1007/978-3-031-20047-2_42. [23] AMIR S, GANDELSMAN Y, BAGON S, et al. Deep vit features as dense visual descriptors[J]. arXiv preprint arXiv: 2112.05814, 2021. [24] DENG Kangle, LIU A, ZHU Junyan, et al. Depth-supervised NeRF: Fewer views and faster training for free[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 12872–12881. doi: 10.1109/CVPR52688.2022.01254. [25] TRUONG P, RAKOTOSAONA M J, MANHARDT F, et al. SPARF: Neural radiance fields from sparse and noisy poses[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 4190–4200. doi: 10.1109/CVPR52729.2023.00408. [26] WANG Guangcong, CHEN Zhaoxi, LOY C C, et al. SparseNeRF: Distilling depth ranking for few-shot novel view synthesis[C]. The IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 9031–9042. doi: 10.1109/ICCV51070.2023.00832. [27] SHI Ruoxi, WEI Xinyue, WANG Cheng, et al. ZeroRF: Fast sparse view 360° reconstruction with zero pretraining[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 21114–21124. doi: 10.1109/CVPR52733.2024.01995. [28] ZHANG Lulin and RUPNIK E. SparseSat-NeRF: Dense depth supervised neural radiance fields for sparse satellite images[J]. arXiv preprint arXiv: 2309.00277, 2023. [29] FACCIOLO G, DE FRANCHIS C, and MEINHARDT-LLOPIS E. Automatic 3D reconstruction from multi-date satellite images[C]. The IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, USA, 2017: 1542–1551. doi: 10.1109/CVPRW.2017.198. [30] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248–255. doi: 10.1109/CVPR.2009.5206848. -

 下载:
下载:




图(3) / 表(3)
计量
- 文章访问数: 840
- HTML全文浏览量: 561
- PDF下载量: 55
- 被引次数: 0
