

An Efficient Lightweight Network for Intra-pulse Modulation Identification of Low Probability of Intercept Radar Signals
-
摘要: 针对低信噪比(SNRs)下低截获概率(LPI)雷达脉内波形识别准确率低的问题,该文提出一种基于时频分析(TFA)、混合扩张卷积(HDC)、卷积块注意力模块(CBAM)和GhostNet网络的LPI雷达辐射源信号识别方法,旨在提升LPI雷达信号的识别性能。该方法先从信号预处理角度给出一种适合LPI雷达信号的时频图像增强处理方法,并基于双时频特征融合技术,有效提升了后续网络对LPI雷达信号脉内调制的识别准确率。接着改造了一种高效轻量级网络,用于对LPI雷达脉内调制信号识别,该网络在GhostNet基础上,结合HDC和CBAM,形成了改进型GhostNet,扩大了特征图的感受野并增强了网络获取通道和位置信息的能力。仿真结果表明,在–8 dB信噪比下,该方法的雷达信号识别准确率依然能够达到98.98%,并在参数数量上也优于对比网络。该文所提方法在低信噪比环境下显著提高了LPI雷达脉内波形识别的准确率,为LPI雷达信号识别领域提供了新的技术途径。Abstract:
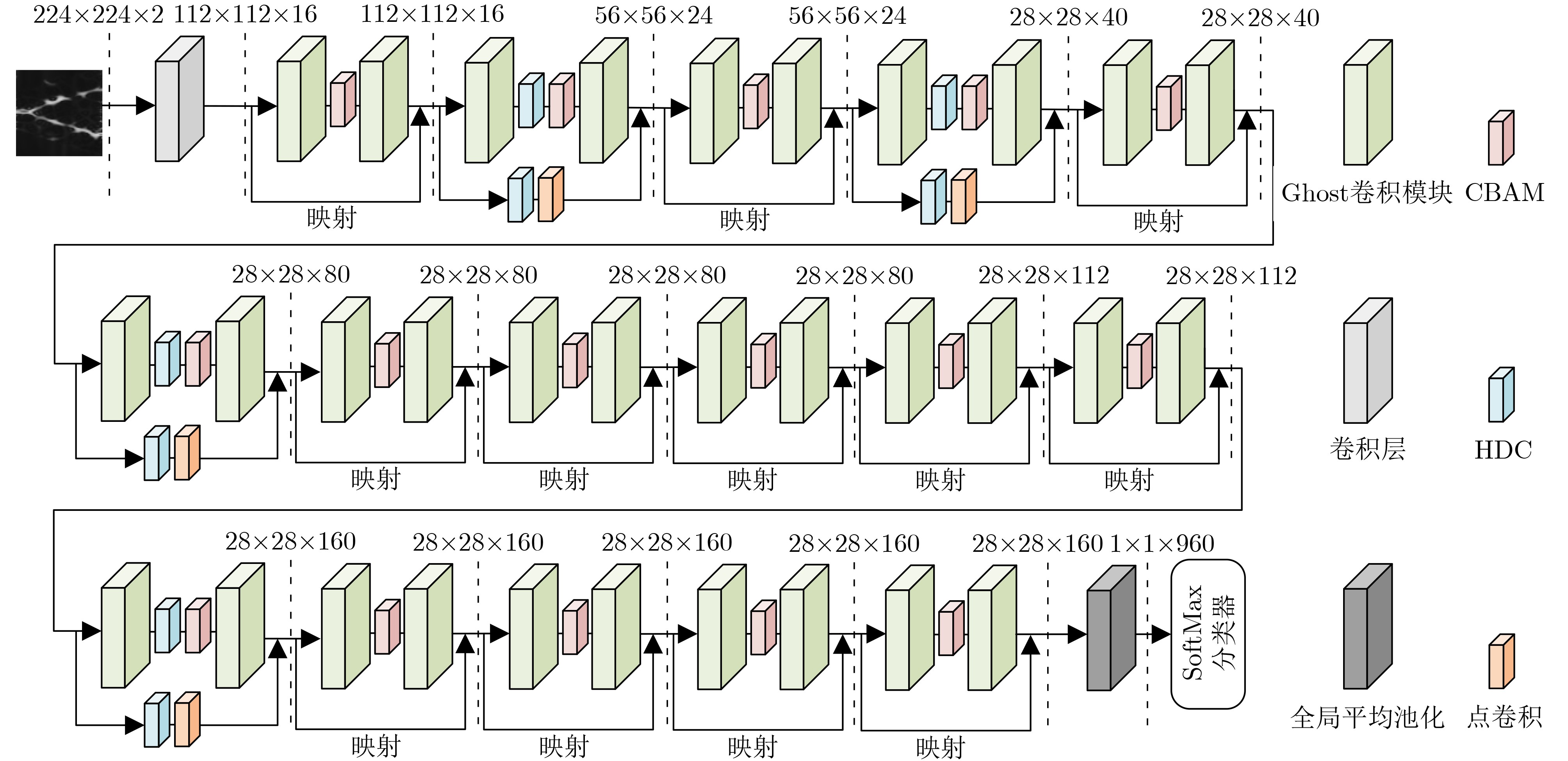
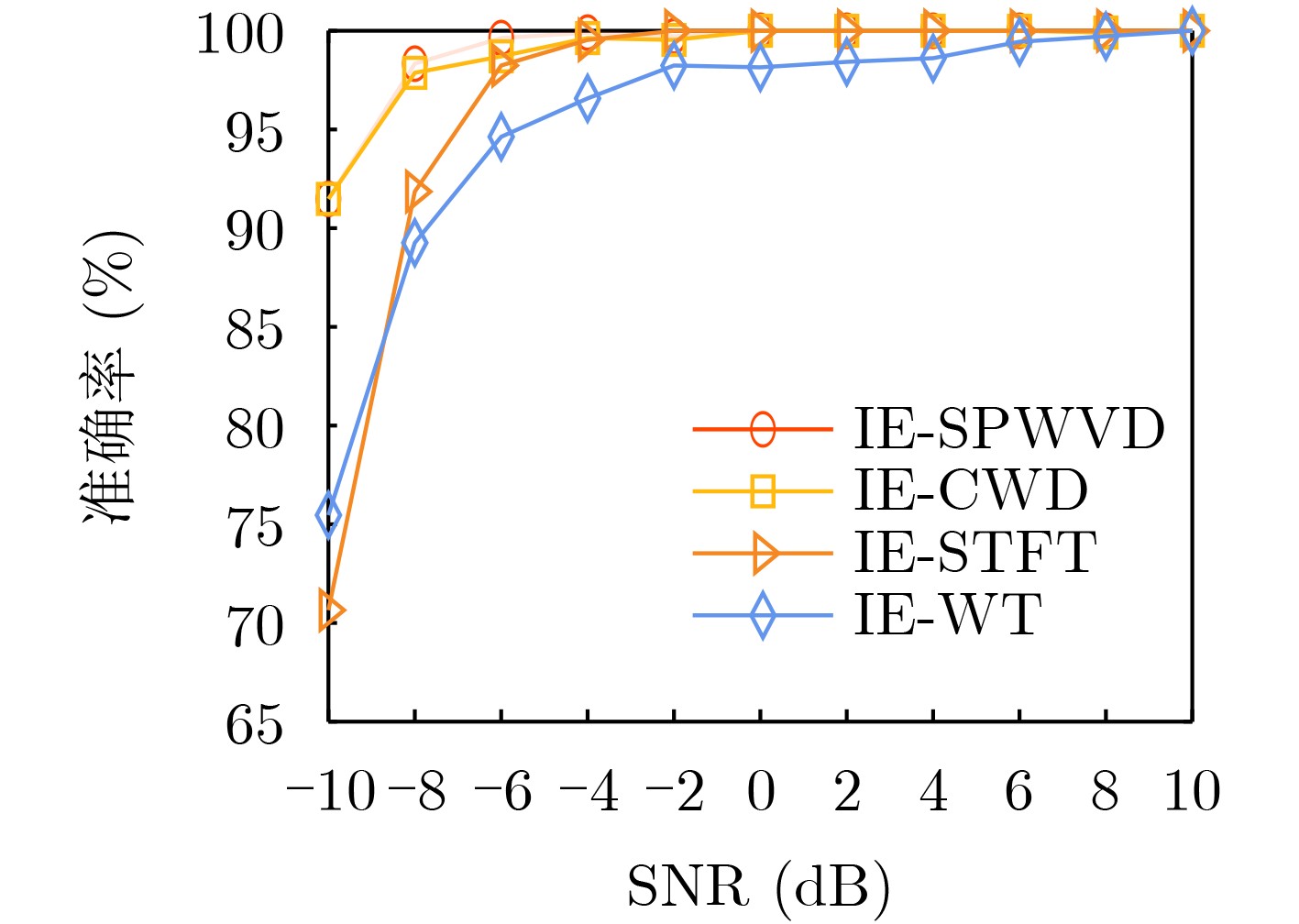
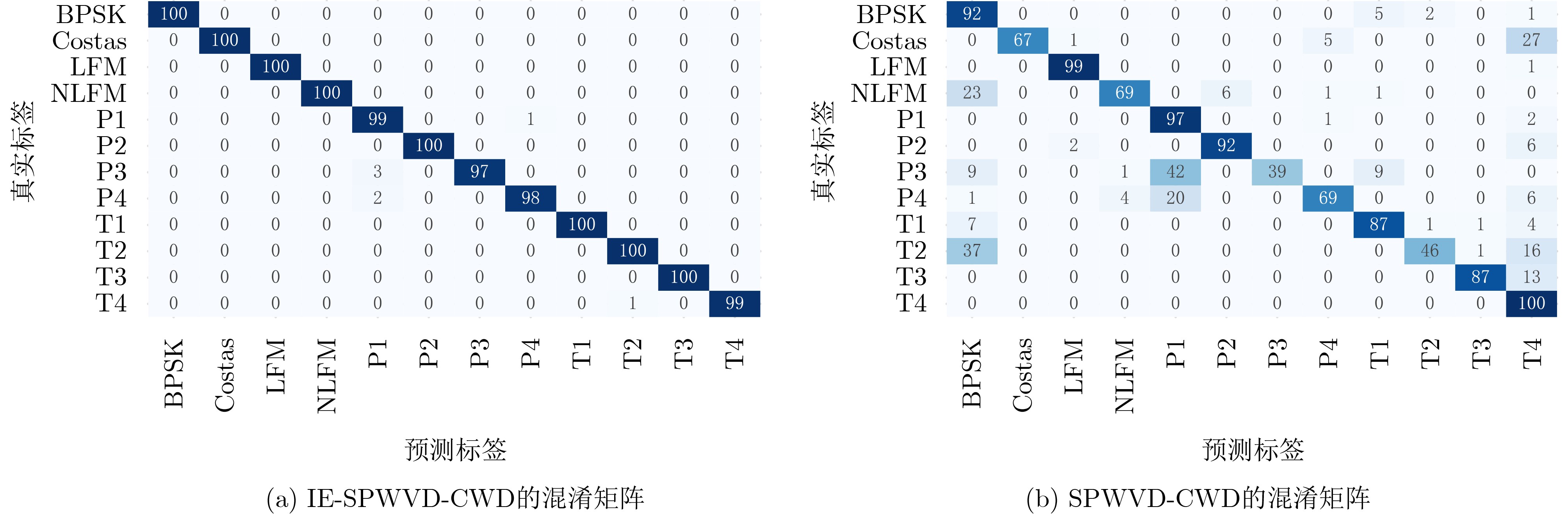
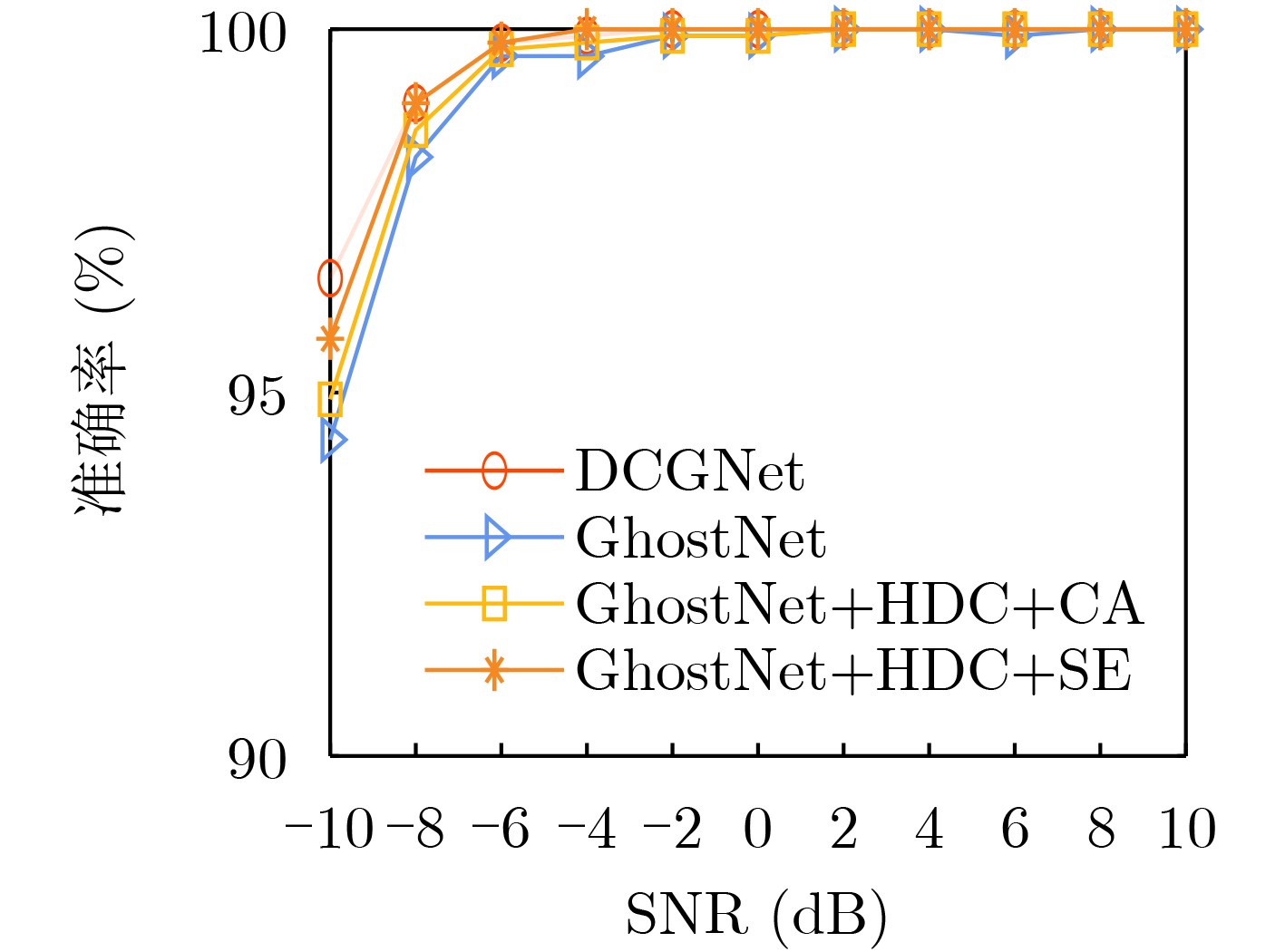
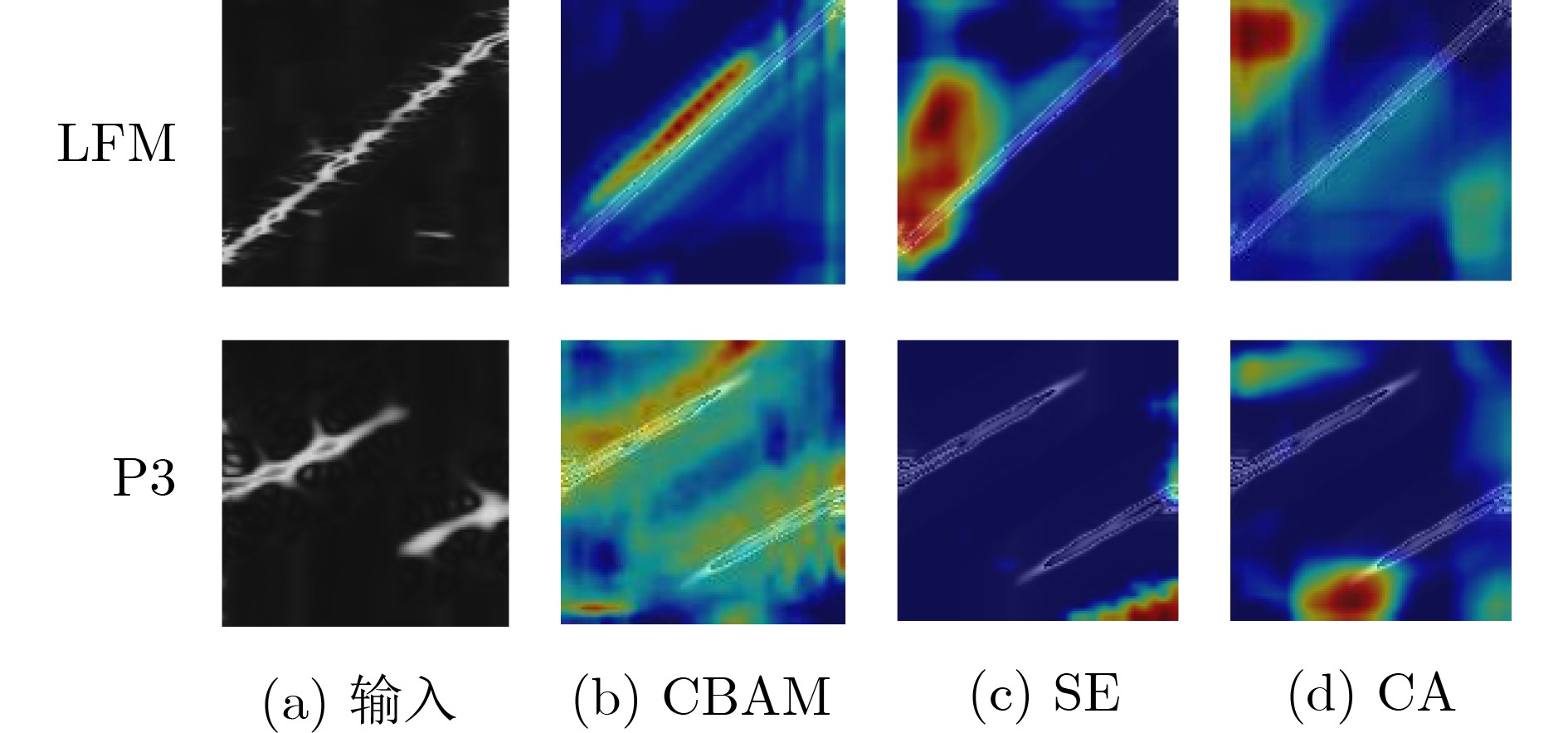
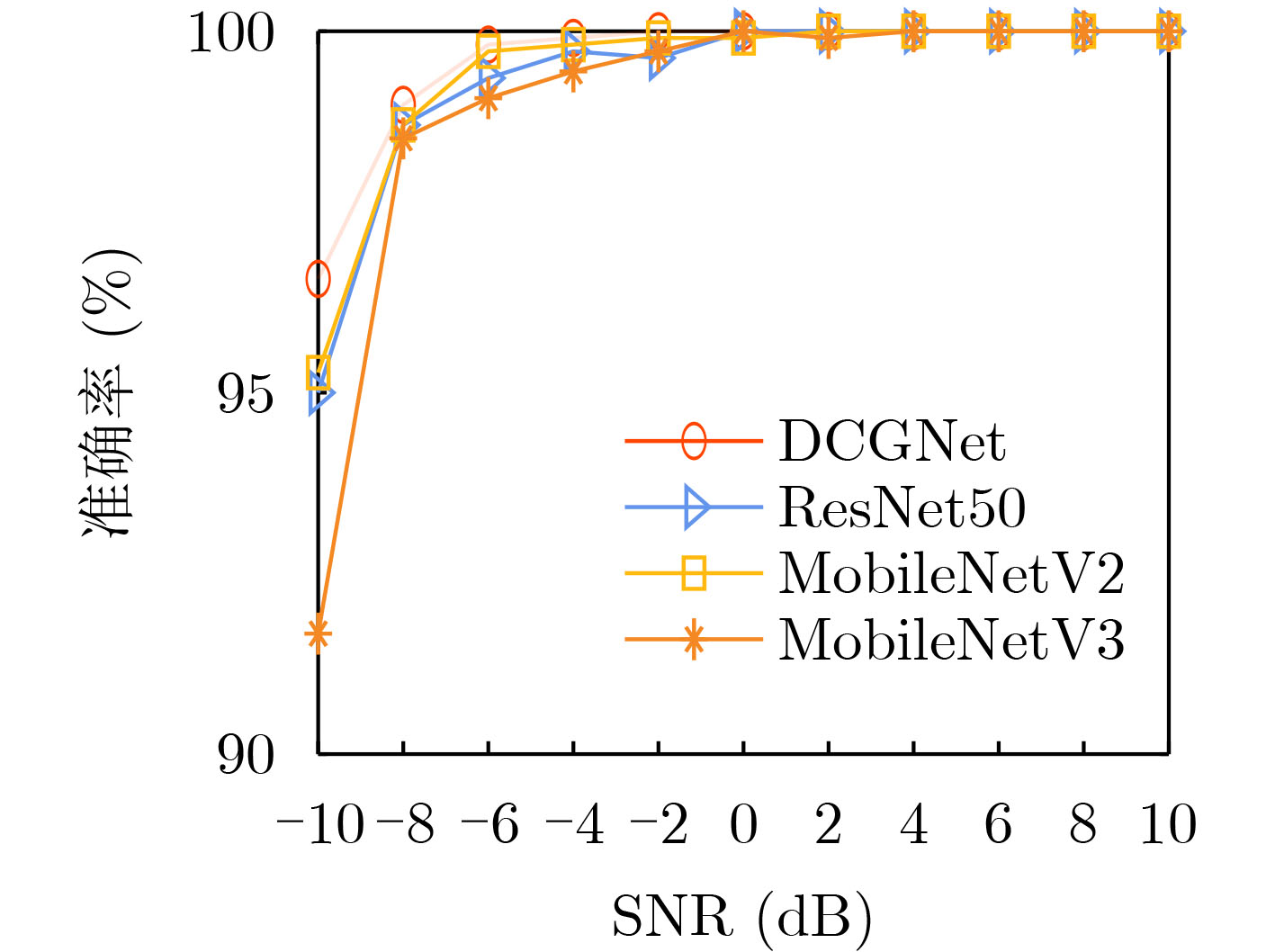
Objective Low Probability of Intercept (LPI) radar enhances stealth, survivability, and operational efficiency by reducing the likelihood of detection, making it widely used in military applications. However, accurately analyzing the intra-pulse modulation characteristics of LPI radar signals remains a key challenge for radar countermeasure technologies. Traditional methods for identifying radar signal modulation suffer from poor noise resistance, limited applicability, and high misclassification rates. These limitations necessitate more robust approaches capable of handling LPI radar signals under low Signal-to-Noise Ratios (SNRs). This study proposes an advanced deep learning-based method for LPI radar signal recognition, integrating Hybrid Dilated Convolutions (HDC) and attention mechanisms to improve performance in low SNR environments. Methods This study proposes a deep learning-based framework for LPI radar signal modulation recognition. The training dataset includes 12 types of LPI radar signals, including BPSK, Costas, LFM, NLFM, four multi-phase, and four multi-time code signals. To enhance model robustness, a comprehensive preprocessing pipeline is applied. Initially, raw signals undergo SPWVD and CWD time-frequency analysis to generate two-dimensional time-frequency feature maps. These maps are then processed through grayscale conversion, Wiener filtering for denoising, principal component extraction, and adaptive cropping. A dual time-frequency fusion method is subsequently applied, integrating SPWVD and CWD to enhance feature distinguishability ( Fig. 2 ). Based on this preprocessed data, the model employs a modified GhostNet architecture, Dilated CBAM-GhostNet (DCGNet). This architecture integrates HDC and the Convolutional Block Attention Module (CBAM), optimizing efficiency while enhancing the extraction of spatial and channel-wise information (Fig. 7 ). HDC expands the receptive field, enabling the model to capture long-range dependencies, while CBAM improves feature selection by emphasizing the most relevant spatial and channel-wise features. The combination of HDC and CBAM strengthens feature extraction, improving recognition accuracy and overall model performance.Results and Discussions This study analyzes the effects of different preprocessing methods, network architectures, and computational complexities on LPI radar signal modulation recognition. The results demonstrate that the proposed framework significantly improves recognition accuracy, particularly under low SNR conditions. A comparison of four time-frequency analysis methods shows that SPWVD and CWD achieve higher recognition accuracy ( Fig. 8 ). These datasets are then fused to evaluate the effectiveness of image enhancement techniques. Experimental results indicate that, compared to datasets without image enhancement, the fusion of SPWVD and CWD reduces signal confusion and improves feature discriminability, leading to better recognition performance (Fig. 9 ). Comparative experiments validate the contributions of HDC and CBAM to recognition performance (Fig. 10 ). The proposed architecture consistently outperforms three alternative network structures under low SNR conditions, demonstrating the effectiveness of HDC and CBAM in capturing spatial and channel-wise information. Further analysis of three attention mechanisms confirms that CBAM enhances feature extraction by focusing more effectively on relevant time-frequency regions (Fig. 11 ). To comprehensively evaluate the proposed network, its performance is compared with ResNet50, MobileNetV2, and MobileNetV3 using the SPWVD and CWD fusion-based dataset (Fig. 12 ). The results show that the proposed network outperforms the other three networks under low SNR conditions, confirming its superior recognition capability for low SNR radar signals. Finally, computational complexity and storage requirements are assessed using floating-point operations and parameter count (Table 2 ). The results indicate that the proposed network maintains relatively low computational complexity and parameter count, ensuring high efficiency and low computational cost. Overall, the proposed deep learning framework improves radar signal recognition performance while maintaining efficiency.Conclusions This study proposes a deep learning-based method for LPI radar signal modulation recognition using the DCGNet model, which integrates dilated convolutions and attention mechanisms. The framework incorporates an advanced image enhancement preprocessing pipeline, leveraging SPWVD and CWD time-frequency feature fusion to improve feature distinguishability and recognition accuracy, particularly under low SNR conditions. Experimental results confirm that DCGNet outperforms existing methods, demonstrating its practical potential for radar signal recognition. Future research will focus on optimizing the model further and extending its applicability to a wider range of radar signal types and scenarios. -
表 1 信号仿真参数表
信号类型 参数 取值范围 单位 BPSK 载频${f_{\text{c}}}$ $ {\text{U}}(1/10,1/3){{\cdot}}{f_{\text{s}}} $ 赫兹(Hz) 巴克码长度${N_{{\text{code}}}}$ $ \{ 7,11,13\} $ 码元(bit) Costas 跳频序列长度${N_{\text{s}}}$ $ \{ 3,4,5,6\} $ - 基准频率${f_{{\text{min}}}}$ $ {\text{U}}(1/24,1/20){{\cdot}}{f_{\text{s}}} $ 赫兹(Hz) LFM
NLFM起始频率${f_{\text{0}}}$ $ {\text{U}}(1/10,1/3){{\cdot}}{f_{\text{s}}} $ 赫兹(Hz) 带宽$B$ $ {\text{U}}(1/10,1/5){{\cdot}}{f_{\text{s}}} $ 赫兹(Hz) P1,P2 载频${f_{\text{c}}}$ $ {\text{U}}(1/10,1/3){{\cdot}}{f_{\text{s}}} $ 赫兹(Hz) 相位控制数$M$ $ [8,12] $,P2码的M为偶数 - 相位子波数${\text{cpp}}$ $ [2,5] $ 个/周期 P3,P4 载频${f_{\text{c}}}$ $ {\text{U}}(1/10,1/3){{\cdot}}{f_{\text{s}}} $ 赫兹(Hz) 相位控制数$M$ $ \{ 36,64,81,100\} $ - 相位子波数${\text{cpp}}$ $ [2,5] $ 个/周期 T1,T2 载频${f_{\text{c}}}$ $ {\text{U}}(1/10,1/3){{\cdot}}{f_{\text{s}}} $ 赫兹(Hz) 波形段数${N_{\text{k}}}$ $ [4,6] $ - T3,T4 载频${f_{\text{c}}}$ $ {\text{U}}(1/10,1/3){{\cdot}}{f_{\text{s}}} $ 赫兹(Hz) 波形段数${N_{\text{k}}}$ $ [4,6] $ - 调制带宽$F$ $ {\text{U}}(1/20,1/8){{\cdot}}{f_{\text{s}}} $ 赫兹(Hz) 注:“-”表示此处是一个计数单位,表示数量。  下载: 导出CSV
下载: 导出CSV
表 2 不同网络浮点运算次数和参数量比较(M)
网络 浮点运算次数 参数量 DCGNet 2.82 1.04 ResNet50 4 090.00 23.53 MobileNetV2 3.15 2.24 MobileNetV3 2.28 4.22
下载: 导出CSV
-
[1] CHEN Binbin, WANG Xudong, ZHU Daiyin, et al. LPI radar signals modulation recognition in complex multipath environment based on improved ResNeSt[J]. IEEE Transactions on Aerospace and Electronic Systems, 2024, 60(6): 8887–8900. doi: 10.1109/TAES.2024.3436634. [2] CHEN Tao, LIU Lizhi, and HUANG Xiangsong. LPI radar waveform recognition based on multi-branch MWC compressed sampling receiver[J]. IEEE Access, 2018, 6: 30342–30354. doi: 10.1109/ACCESS.2018.2845102. [3] LEI Wentai, TAN Xin, LUO Chaopeng, et al. Mutual interference suppression and signal enhancement method for ground-penetrating radar based on deep learning[J]. Electronics, 2024, 13(23): 4722. doi: 10.3390/electronics13234722. [4] HOU Qinghua and WU Huibin. Recognition of LPI radar signal intrapulse modulation based on CNN and time-frequency denoising[J]. Journal of Electronics and Information Science, 2024, 9(1): 142–152. doi: 10.23977/jeis.2024.090119. [5] REN Feitao, QUAN Daying, SHEN Lai, et al. LPI radar signal recognition based on feature enhancement with deep metric learning[J]. Electronics, 2023, 12(24): 4934. doi: 10.3390/electronics12244934. [6] LIANG Jingyue, LUO Zhongtao, and LIAO Renlong. Intra-pulse modulation recognition of radar signals based on efficient cross-scale aware network[J]. Sensors, 2024, 24(16): 5344. doi: 10.3390/s24165344. [7] LIU Yunhao, HAN Sicun, GUO Chengjun, et al. The research of intra-pulse modulated signal recognition of radar emitter under few-shot learning condition based on multimodal fusion[J]. Electronics, 2024, 13(20): 4045. doi: 10.3390/electronics13204045. [8] KONG S H, KIM M, HOANG L M, et al. Automatic LPI radar waveform recognition using CNN[J]. IEEE Access, 2018, 6: 4207–4219. doi: 10.1109/ACCESS.2017.2788942. [9] 石礼盟, 杨承志, 王美玲, 等. 基于深度网络的雷达信号调制方式识别[J]. 兵器装备工程学报, 2021, 42(6): 190–193,218. doi: 10.11809/bqzbgcxb2021.06.033.SHI Limeng, YANG Chengzhi, WANG Meiling, et al. Recognition method of radar signal modulation method based on deep network[J]. Journal of Ordnance Equipment Engineering, 2021, 42(6): 190–193,218. doi: 10.11809/bqzbgcxb2021.06.033. [10] 蒋伊琳, 尹子茹. 基于卷积神经网络的低截获概率雷达信号检测算法[J]. 电子与信息学报, 2022, 44(2): 718–725. doi: 10.11999/JEIT210132.JIANG Yilin and YIN Ziru. Low probability of intercept radar signal detection algorithm based on convolutional neural networks[J]. Journal of Electronics & Information Technology, 2022, 44(2): 718–725. doi: 10.11999/JEIT210132. [11] HUYNH-THE T, DOAN V S, HUA C H, et al. Accurate LPI radar waveform recognition with CWD-TFA for deep convolutional network[J]. IEEE Wireless Communications Letters, 2021, 10(8): 1638–1642. doi: 10.1109/LWC.2021.3075880. [12] DONG Ning, JIANG Hong, LIU Yipeng, et al. Intrapulse modulation radar signal recognition using CNN with second-order STFT-based synchrosqueezing transform[J]. Remote Sensing, 2024, 16(14): 2582. doi: 10.3390/rs16142582. [13] QUAN Daying, REN Feitao, WANG Xiaofeng, et al. WVD‐GAN: A Wigner‐Ville distribution enhancement method based on generative adversarial network[J]. IET Radar, Sonar & Navigation, 2024, 18(6): 849–865. doi: 10.1049/rsn2.12532. [14] LIU Lutao and LI Xinyu. Radar signal recognition based on triplet convolutional neural network[J]. EURASIP Journal on Advances in Signal Processing, 2021, 2021(1): 112. doi: 10.1186/s13634-021-00821-8. [15] KALRA M, KUMAR S, and DAS B. Moving ground target detection with seismic signal using smooth pseudo Wigner-Ville distribution[J]. IEEE Transactions on Instrumentation and Measurement, 2020, 69(6): 3896–3906. doi: 10.1109/TIM.2019.2932176. [16] HEPSIBA D and JUSTIN J. Enhancement of single channel speech quality and intelligibility in multiple noise conditions using wiener filter and deep CNN[J]. Soft Computing, 2022, 26(23): 13037–13047. doi: 10.1007/s00500-021-06291-2. [17] YU Xiao, WANG Songcheng, XU Hongyang, et al. Intelligent fault diagnosis of rotating machinery under variable working conditions based on deep transfer learning with fusion of local and global time–frequency features[J]. Structural Health Monitoring, 2024, 23(4): 2238–2254. doi: 10.1177/14759217231199427. [18] HAN Kai, WANG Yunhe, TIAN Qi, et al. GhostNet: More features from cheap operations[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 1577–1586. doi: 10.1109/CVPR42600.2020.00165. [19] MA Danqing, LI Shaojie, DANG Bo, et al. Fostc3net: A lightweight YOLOv5 based on the network structure optimization[J]. Journal of Physics: Conference Series, 2024, 2824: 012004. doi: 10.1088/1742-6596/2824/1/012004. [20] WANG Zhong and LI Tong. A lightweight CNN model based on GhostNet[J]. Computational Intelligence and Neuroscience, 2022, 2022(1): 8396550. doi: 10.1155/2022/8396550. [21] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 3–19. doi: 10.1007/978-3-030-01234-2_1. [22] SI Weijian, LUO Jiaji, and DENG Zhian. Radar signal recognition and localization based on multiscale lightweight attention model[J]. Journal of Sensors, 2022, 2022(1): 9970879. doi: 10.1155/2022/9970879. [23] BIAN Shengqin, HE Xinyu, XU Zhengguang, et al. Hybrid dilated convolution with attention mechanisms for image denoising[J]. Electronics, 2023, 12(18): 3770. doi: 10.3390/electronics12183770. [24] ZHAO Liquan, WANG Leilei, JIA Yanfei, et al. A lightweight deep neural network with higher accuracy[J]. PLoS One, 2022, 17(8): e0271225. doi: 10.1371/journal.pone.0271225. [25] LEI Yanmin, PAN Dong, FENG Zhibin, et al. Lightweight YOLOv5s human ear recognition based on MobileNetV3 and Ghostnet[J]. Applied Sciences, 2023, 13(11): 6667. doi: 10.3390/app13116667. -


 下载:
下载:







图(12) / 表(2)
计量
- 文章访问数: 1287
- HTML全文浏览量: 893
- PDF下载量: 152
- 被引次数: 0
