

A Novel Adaptive Optimization Strategy for High-Performance CPU Clock Trees
-
摘要: 该文基于精简指令集系统(RISC-V)架构提出了一种新型的自适应全流程(ADFF)时钟树优化方法,高效利用有用偏差(useful skew)来优化高性能CPU时钟树,以满足市场对芯片高性能和低功耗的双重需求。针对时钟树,通过选择关键路径并结合理论延迟和缓冲器制造有用偏差,采用循环迭代的方式,在不同流程自适应修复常规流程无法解决的建立时间违例(setup violation)和保持时间违例(hold violation)。为了在提升性能的同时,最大限度降低功耗,该文对加入的延迟单元进行合并(merge)处理,实现功耗与时序的联合优化。最后采用RISC_V CPU核进行验证,研究结果表明,在确保合理功耗的基础上,所提方法显著改善了时序情况,总时序裕量违例几乎完全消除。Abstract:
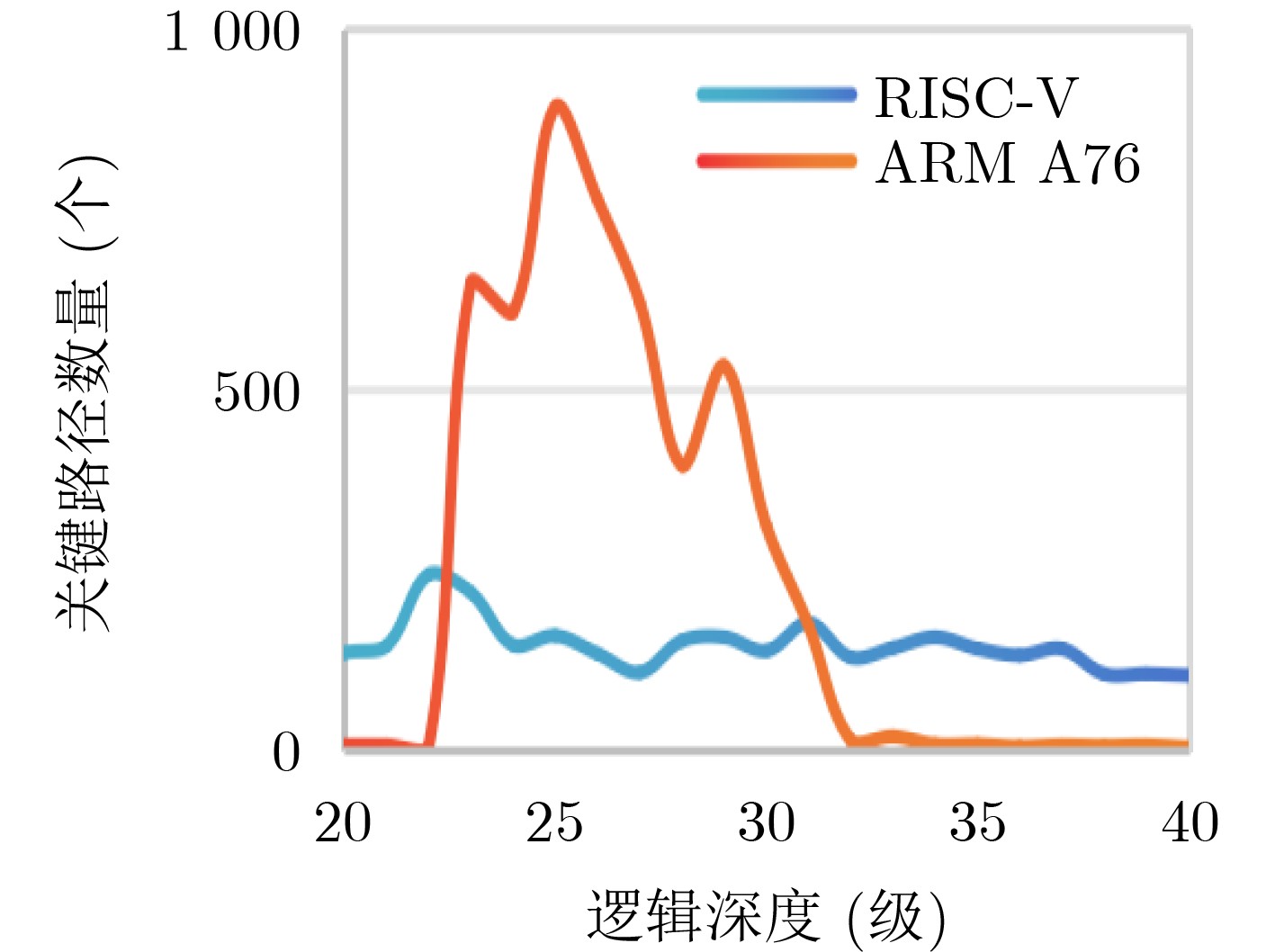
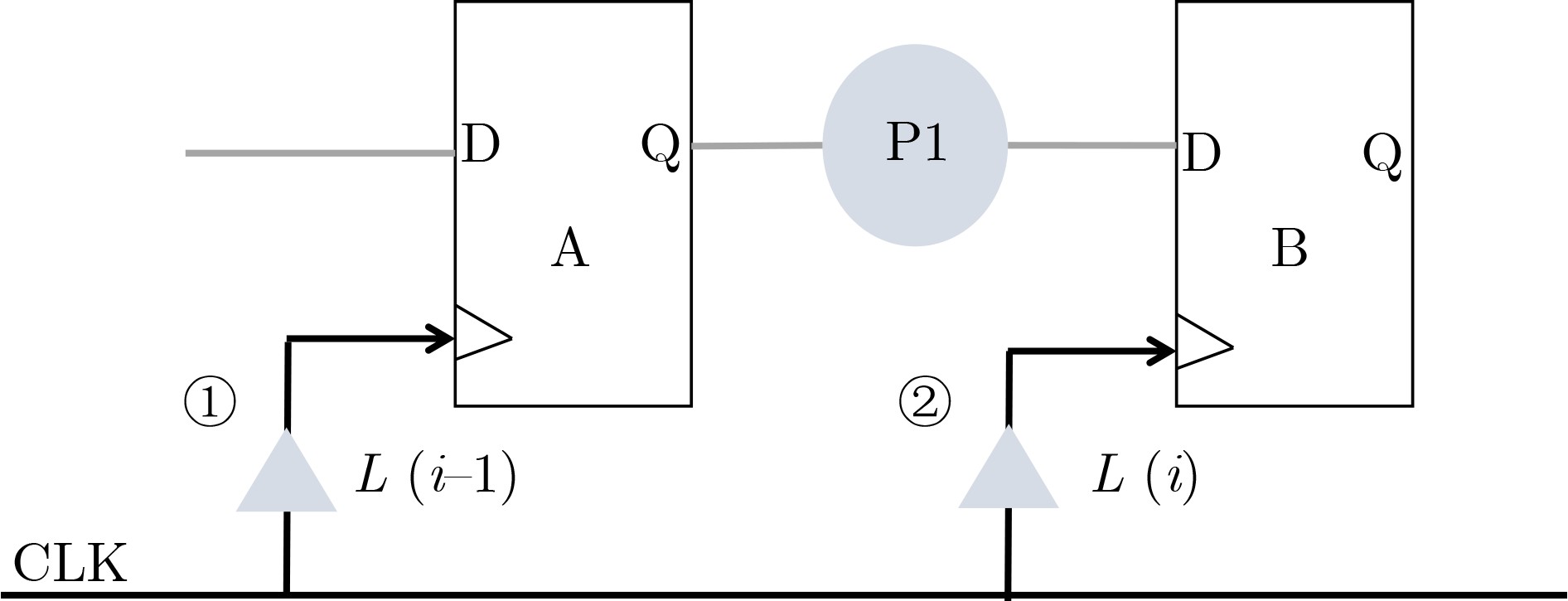
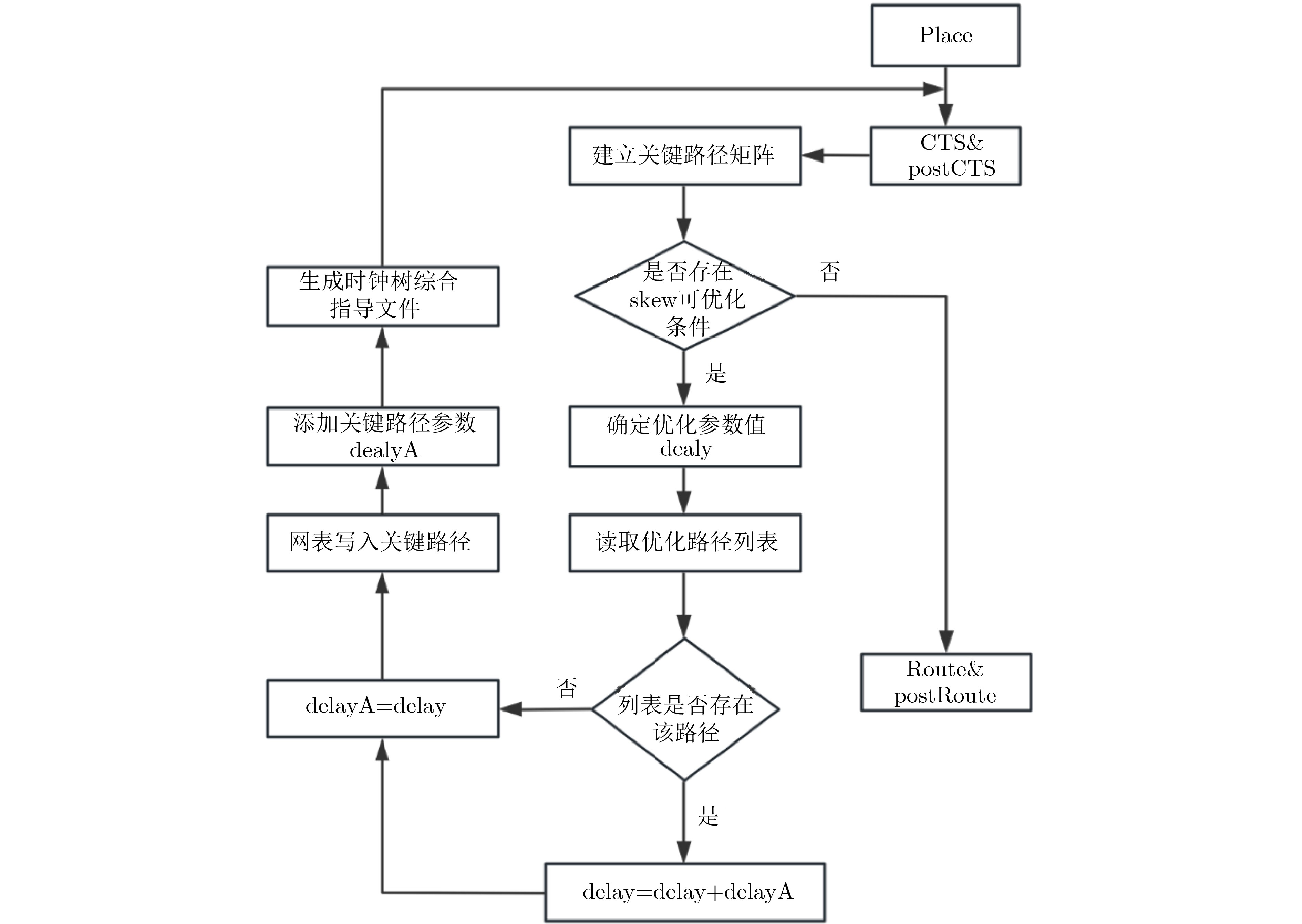
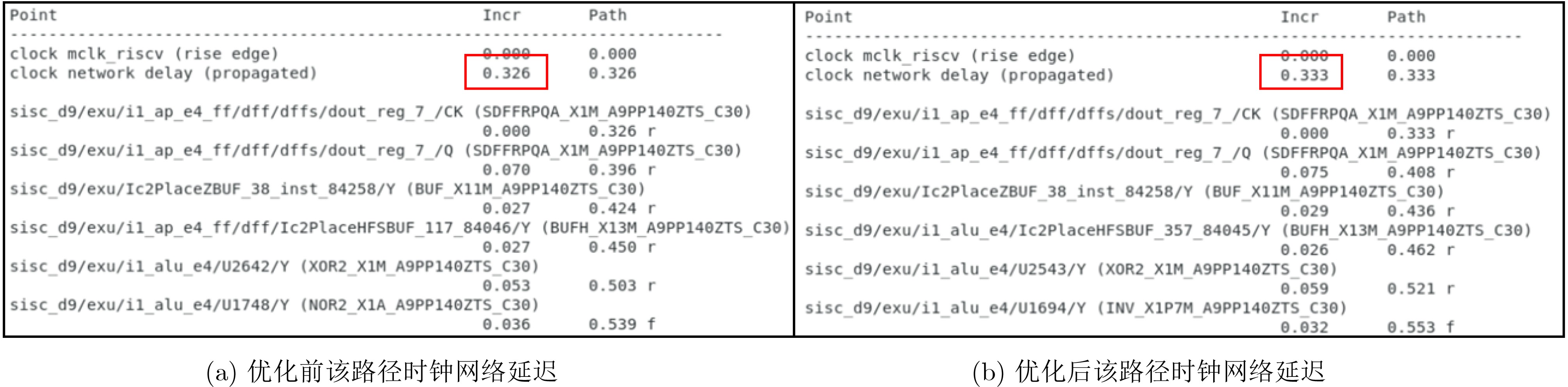
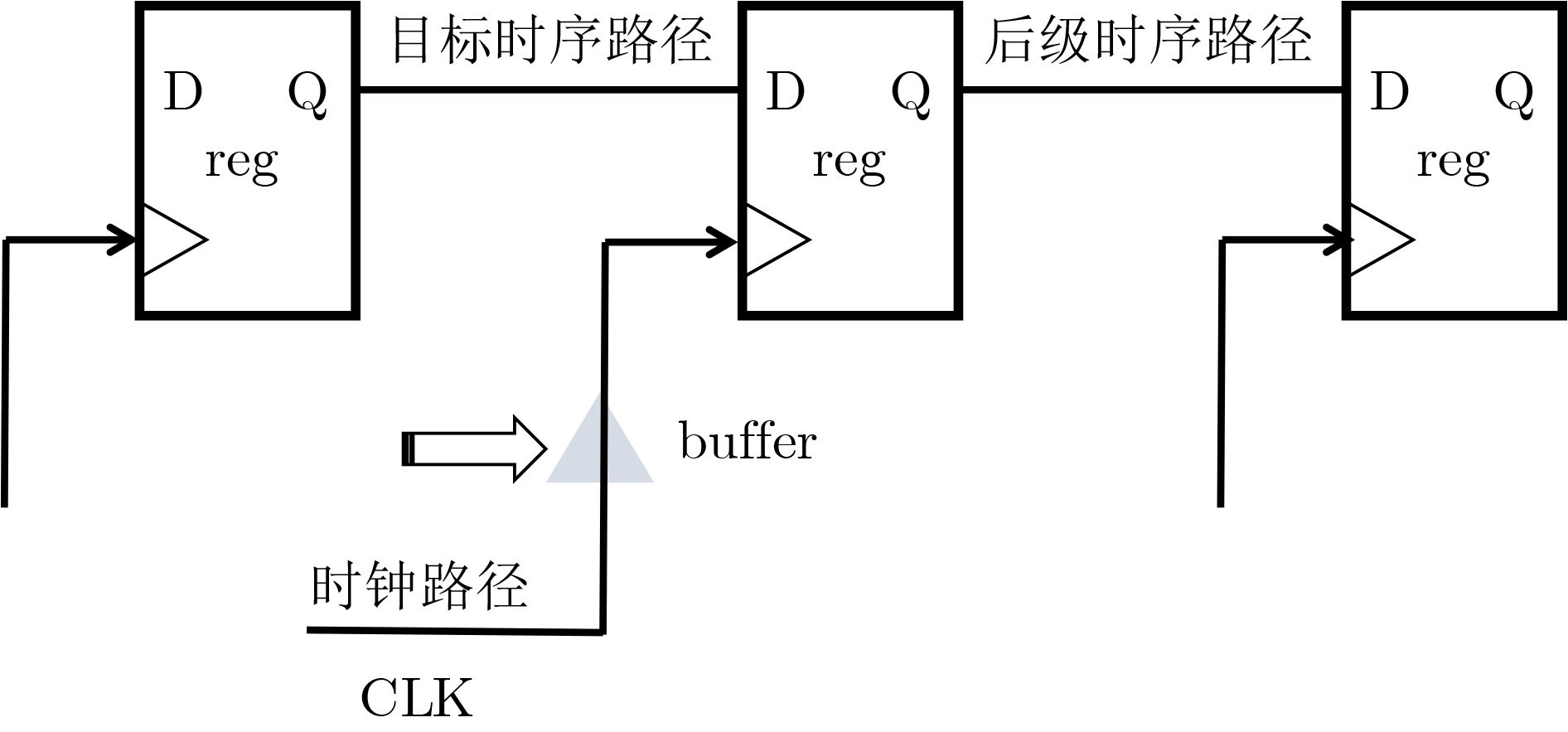
Objective With continuous advancements in Integrated Circuit (IC) process technology, chip integration levels have steadily increased, driving higher market demands for performance. In the era of intelligence and digitalization, an inherent challenge arises: as the number of logic gates increases, both main frequency and power consumption rise, imposing stricter requirements on digital IC designers. Although existing Electronic Design Automation (EDA) tools optimize timing using useful skew in clock trees, this technique has notable limitations. To address this issue, a novel adaptive full-flow clock tree timing violation correction method is proposed. This method corrects timing violations unresolved by conventional flows while reducing power consumption and improving performance, meeting the market’s dual demands for high-performance and low-power chips. Methods The ADaptive Full Flow (ADFF) clock tree optimization method is based on the RISC-V CPU architecture. As an open-source architecture, RISC-V offers openness and flexibility, making it widely used in high-performance, low-power processor design. The method exploits imbalances in key path logic depth to enhance optimization. Useful skew is introduced to adjust logic delay distribution, improving overall performance. Timing feedback is incorporated at multiple stages, ultimately forming a joint optimization strategy for power consumption and timing, which enhances clock tree quality and reduces chip load. The method integrates feedback optimization during both the Clock Tree Synthesis (CTS) and routing stages. In the CTS stage, timing paths are traversed to gather feedback, which is then returned to the pre-CTS stage for early intervention. Adaptive iteration accurately identifies critical paths and resolves setup time violations. In the routing stage, targeted strategies address hold time violations, and the merging method reduces power consumption while optimizing timing correction. This enables full-flow correction of clock tree timing violations while improving power efficiency. Results and Discussions The ADFF clock tree optimization strategy is implemented using Synopsys IC Compiler II for layout and routing, establishing an adaptive full-flow framework for correcting clock tree timing violations ( Fig. 5 ). For setup time violations in the reg2reg group, a loop iteration algorithm dynamically adjusts path delays, updating CTS guidance files to iteratively optimize critical path timing (Fig. 6 ). Using the ADFF method, total timing violations are nearly eliminated, achieving a 55.6% efficiency improvement over the built-in auto useful skew function (Table 2 ). For hold time violations in the reg2mem group (Figs. 9 and10 ), 125 buffers are inserted. Across 50 critical paths, the total timing margin improves significantly, reducing the worst slack from –362.2 ns to near zero (Table 3 ). To further optimize timing, when a clock signal is transmitted to two physically close registers, and buffers in the final clock path stage are used for timing correction, a merging plan consolidates multiple register buffers into a single delay unit (Fig. 11 ). Through a rigorous filtering mechanism in the script language, nearly 700 clock delay units are reduced while maintaining timing integrity. Additionally, clock network nets are reduced (Table 4 ), improving clock tree quality, achieving timing convergence, and enhancing overall design efficiency.Conclusions This paper proposes a novel ADFF clock tree optimization strategy that integrates loop iteration adjustment with IC Compiler II, leveraging useful skew for adaptive full-flow automatic correction of setup and hold time violations. The method extends the traditional concept and has demonstrated significant results on a high-performance RISC-V-based CPU, achieving a main clock frequency of 800 MHz. Compared to conventional timing optimization methods, this strategy resolves timing violations that standard layout and routing processes cannot address, significantly improving timing convergence. Through joint optimization of power consumption and timing, the method reduces the cost and power overhead associated with useful skew optimization and is applicable to CPU pipelines, providing a valuable reference for chip design. Future research may refine filtering conditions, optimize script traversal statements, and incorporate mainstream tool techniques to improve path selection efficiency while minimizing runtime overhead in large designs. Additionally, further refinement of the mathematical model could help identify more suitable targets for power optimization, improving overall performance. -
Key words:
- Clock tree /
- Useful skew /
- Adaptation /
- Timing violation /
- Joint optimization
-
表 1 工具设置不同postpone值的时钟树质量和时序情况
Clock QoR Timing QoR 工具auto useful skew的postpone值(ps) Clock Cell(个) Nets(个) Latency(ns) WNS(ns) TNS(ns) 0 2547 264888 0.386 –0.260 –855.5 100 2920 265203 0.411 –0.228 –782.5 250 3251 265526 0.504 –0.193 –690.3  下载: 导出CSV
下载: 导出CSV
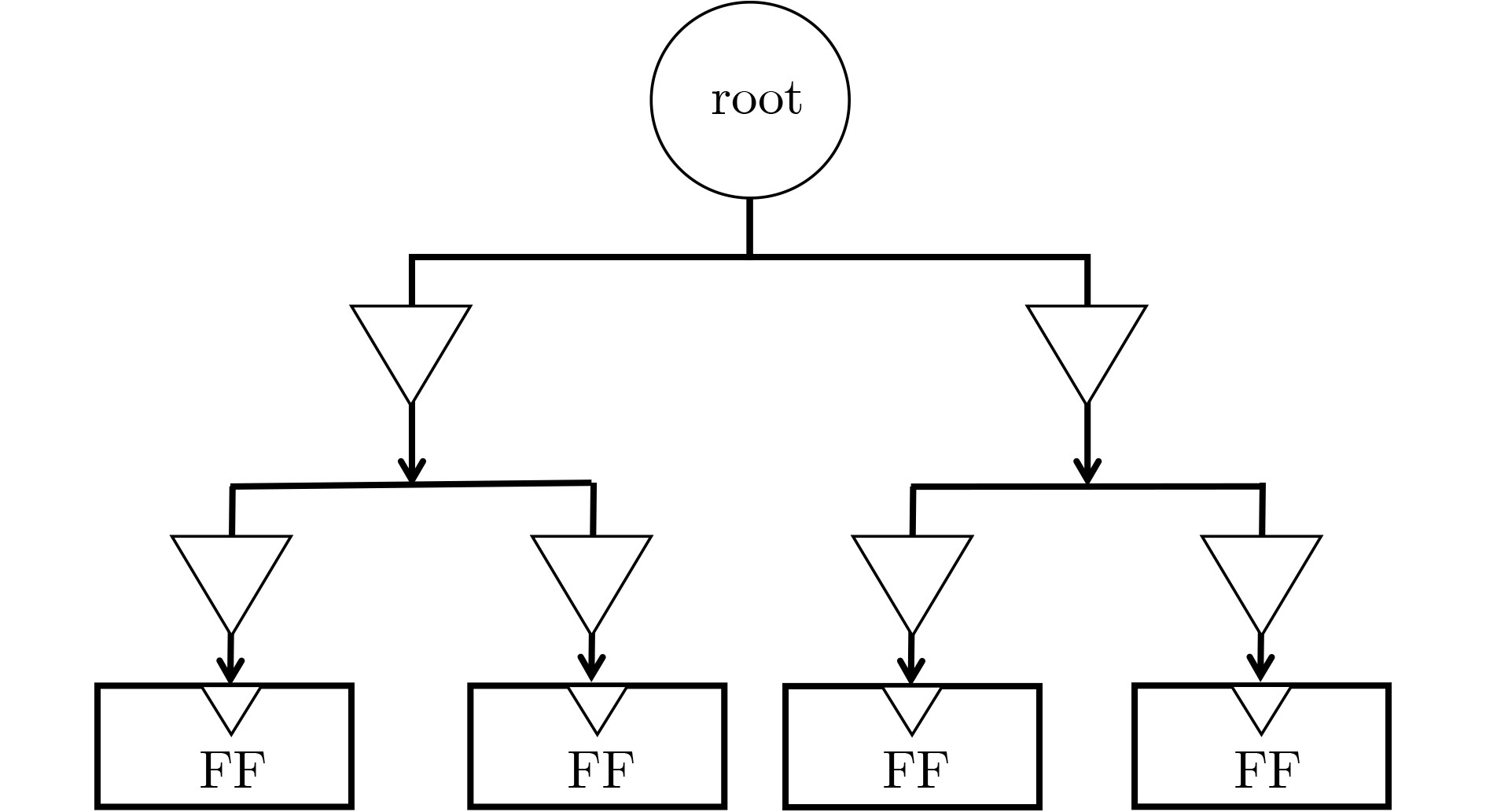
1 基于时钟树综合的关键路径列表自适应时序优化算法
For i=1 to n If (Si>Sth and Hi>Hth) Then If (Pi$ \notin $DelayList) Then △=D0 Else Di= D0+△ △=Di DelayList ← DelayList∪{(Pi, Di)} WriteToGuidanceFile(Pi, Di) Run CTS
下载: 导出CSV
2 基于后缀名筛选适合联合优化的时序路径算法
get_net -of [get_cells *indelaybuffer* -hier] For i=1 to n get_pins -of nets Size of_collection pins number=2
下载: 导出CSV
表 2 不同优化方法reg2reg组测试时序情况(ns)
优化策略 时序路径组别 WNS TNS WNS (hold) TNS (hold) balance case reg2reg(func_N40CSSG0P81_cworst_postcts) –0.252 –876.3 –0.187 –45.8 auto useful skew reg2reg(func_N40CSSG0P81_cworst_postcts) –0.219 –597.2 –0.192 –54.1 ADFF(本文) reg2reg(func_N40CSSG0P81_cworst_postcts) –0.079 –9.100 –0.212 –72.7
下载: 导出CSV
表 3 不同优化方法reg2mem组测试时序情况(ns)
优化策略 时序路径组别 WNS(hold) TNS(hold) balance case reg2mem(func_125CFFG0P99_rcbest_postcts) –0.199 –362.2 auto useful skew reg2mem(func_125CFFG0P99_rcbest_postcts) –0.162 –237.4 ADFF(本文) reg2mem(func_125CFFG0P99_rcbest_postcts) –0.024 –0.2
下载: 导出CSV
表 4 不同情况下的时钟树质量和时序结果
Clock QoR Timing QoR 优化策略 Clock Cell(个) Nets(个) Latency(ns) WNS(ns) TNS(ns) WNS(hold) (ns) TNS(hold) (ns) balance case 2962 272003 0.386 –0.252 –876.3 –0.238 –45.8 ADFF(不含merge) 3754 280599 0.411 –0.044 –9.100 –0.020 –0.201 ADFF(+merge) 3095 274423 0.399 –0.040 –8.112 –0.014 –0.122
下载: 导出CSV
-
[1] 杨亮, 王亚军, 张竣昊, 等. 处理器体系结构模拟器综述[J]. 电子与封装, 2024, 24(8): 080301. doi: 10.16257/j.cnki.1681-1070.2024.0097.YANG Liang, WANG Yajun, ZHANG Junhao, et al. Overview of processor architecture simulators[J]. Electronics & Packaging, 2024, 24(8): 080301. doi: 10.16257/j.cnki.1681-1070.2024.0097. [2] 韩宇昕, 卜刚, 郭钰. 基于RISC-V内核的UHF RFID阅读器SoC设计[J]. 计算机工程与设计, 2024, 45(5): 1588–1594. doi: 10.16208/j.issn1000-7024.2024.05.040.HAN Yuxin, BU Gang, and GUO Yu. SoC of UHF RFID interrogator design based on RISC-V core[J]. Computer Engineering and Design, 2024, 45(5): 1588–1594. doi: 10.16208/j.issn1000-7024.2024.05.040. [3] 柳耀勇, 王研博, 杨龙波, 等. RISC-V技术生态发展趋势及未来展望[J]. 信息化研究, 2024(6): 66–67, 63. doi: 10.3969/j.issn.1672-5158.2024.06.027.LIU Yaoyong, WANG Yanbo, YANG Longbo, et al. Trends and future perspectives of RISC-V technology ecosystem[J]. Informatization-Research, 2024(6): 66–67, 63. doi: 10.3969/j.issn.1672-5158.2024.06.027. [4] 丁志远, 朱家鑫, 吴国全, 等. 面向RISC-V适配开发的x86 built-in函数转换方法[J]. 广西大学学报(自然科学版), 2024, 49(3): 620–636. doi: 10.13624/j.cnki.issn.1001-7445.2024.0620.DING Zhiyuan, ZHU Jiaxin, WU Guoquan, et al. An approach to adapting x86 built-in functions for RISC-V development[J]. Journal of Guangxi University (Natural Science Edition), 2024, 49(3): 620–636. doi: 10.13624/j.cnki.issn.1001-7445.2024.0620. [5] XU Yinan, YU Zihao, TANG Dan, et al. Towards developing high performance RISC-V processors using agile methodology[C]. The 55th IEEE/ACM International Symposium on Microarchitecture, Chicago, USA, 2022: 1178–1199. doi: 10.1109/MICRO56248.2022.00080. [6] ZYUBAN V, TAYLOR S A, CHRISTENSEN B, et al. IBM POWER7+ design for higher frequency at fixed power[J]. IBM Journal of Research and Development, 2013, 57(6): 1: 1–1: 18. doi: 10.1147/JRD.2013.2279597. [7] 戈喆, 王志鸿, 厉媛玥. 基于Innovus的低功耗物理设计[J]. 电子技术应用, 2016, 42(8): 21–24. doi: 10.16157/j.issn.0258-7998.2016.08.003.GE Zhe, WANG Zhihong, and LI Yuanyue. Low power physical design in Innovus[J]. Application of Electronic Technique, 2016, 42(8): 21–24. doi: 10.16157/j.issn.0258-7998.2016.08.003. [8] 王虎虎, 雷倩倩, 刘露, 等. 一种快速实现时序收敛的设计方法[J]. 微电子学与计算机, 2024, 41(4): 123–131. doi: 10.19304/J.ISSN1000-7180.2023.0050.WANG Huhu, LEI Qianqian, LIU Lu, et al. A design methodology for fast timing closure[J]. Microelectronics & Computer, 2024, 41(4): 123–131. doi: 10.19304/J.ISSN1000-7180.2023.0050. [9] 朱佳琪, 陈岚, 王海永. 一种低功耗时钟树的设计和优化方法[J]. 微电子学与计算机, 2021, 38(10): 85–90. doi: 10.19304/J.ISSN1000-7180.2021.0015.ZHU Jiaqi, CHEN Lan, and WANG Haiyong. A low-power clock tree design and optimization method[J]. Microelectronics & Computer, 2021, 38(10): 85–90. doi: 10.19304/J.ISSN1000-7180.2021.0015. [10] 杜文静. 基于TSMC6nm工艺的GPU模块低功耗物理设计[D]. [硕士论文], 西安理工大学, 2023. doi: 10.27398/d.cnki.gxalu.2023.000795.DU Wenjing. Low-power physical design of GPU module based on TSMC 6nm process[D]. [Master dissertation], Xi’an University of Technology, 2023. doi: 10.27398/d.cnki.gxalu.2023.000795. [11] 翟金标, 李建成. 基于28 nm数字芯片的分步式时钟树综合设计[J]. 中国集成电路, 2022, 31(8): 40–44. doi: 10.3969/j.issn.1681-5289.2022.08.007.ZHAI Jinbiao and LI Jiancheng. Clock tree syntehsis of step by step based on 28nm digital chip[J]. China Integrated Circuit, 2022, 31(8): 40–44. doi: 10.3969/j.issn.1681-5289.2022.08.007. [12] NAIR R K R, POTHIRAJ S, NAIR T R R, et al. A novel power aware placement and adaptive radix tree based clock tree synthesis for 3D-integrated circuits[J]. Microprocessors and Microsystems, 2020: 103455. doi: 10.1016/j.micpro.2020.103455. [13] DO S G, KIM S, KANG S. Skew control methodology for useful-skew implementation[C]. 2016 International SoC Design Conference, Jeju, Korea (South), 2016: 221–222. doi: 10.1109/ISOCC.2016.7799867. [14] GARG V. Common path pessimism removal: An industry perspective: Special session: Common path pessimism removal[C]. 2014 IEEE/ACM International Conference on Computer-Aided Design, San Jose, USA, 2014: 592–595. doi: 10.1109/ICCAD.2014.7001412. [15] YANG Tianhao, ZHAO Zhenyu, HAN Ao, et al. Automatic timing ECO using stage-based path delay prediction[C]. The 20th IEEE Interregional NEWCAS Conference (NEWCAS), Quebec City, Canada, 2022: 455–459. doi: 10.1109/NEWCAS52662.2022.9842155. [16] 张祥, 赵启林. 基于缓冲器的ASIC芯片时序优化设计[J]. 集成电路与嵌入式系统, 2024, 24(12): 33–37. doi: 10.20193/j.ices2097-4191.2024.0046.ZHANG Xiang and ZHAO Qilin. Timing optimization design of ASIC chip based on buffer[J]. Integrated Circuits and Embedded Systems, 2024, 24(12): 33–37. doi: 10.20193/j.ices2097-4191.2024.0046. [17] FENG W, WEI Q, LI Y, et al. Analysis and testing NeoKylin’s clock system[C]. 2014 International Conference on Simulation and Modeling Methodologies, Technologies and Applications (SMTA 2014 VI), Information Engineering Research Institute, USA, Department of Computer Simulation Techniques, Luoyang Electronic Equipment Test Center of China, 2014: 8. -

 下载:
下载:










图(14) / 表(6)
计量
- 文章访问数: 832
- HTML全文浏览量: 690
- PDF下载量: 52
- 被引次数: 0
