

Adaptive Oversampling Method Based on Maximum Safe Nearest Neighbor and Local Density
-
摘要: 针对不平衡数据过采样的过程中如何合成有效新样本的问题,该文提出一种基于最大安全近邻与局部密度的自适应过采样方法。该方法利用最大安全近邻和局部密度将少数类样本划分为安全样本、边界样本和离群点;在此基础上,通过组合加权设置样本的采样概率,使得靠近边界的“次边界样本”更容易被选择为根样本,并且自适应地调整K近邻的参数K,选择最优合成区域;针对离群点,采用超球面内的随机过采样策略,进一步增加少数类样本的多样性。最后,将所提方法与合成少数类过采样技术(SMOTE)、自适应合成采样方法(ADASYN)等6种过采样方法在13个公开数据集上进行实验分析,结果表明,所提方法相对于对比方法在F1分数(F1-score)指标上分别平均提高了6.9%, 8.8%, 8.2%, 5.8%, 7.2%和12.5%,在几何平均值(G-mean)指标上分别平均提高了3.0%, 2.5%, 3.0%, 3.2%, 5.3%和8.6%,证明所提方法可以有效解决不平衡数据分类问题。Abstract:
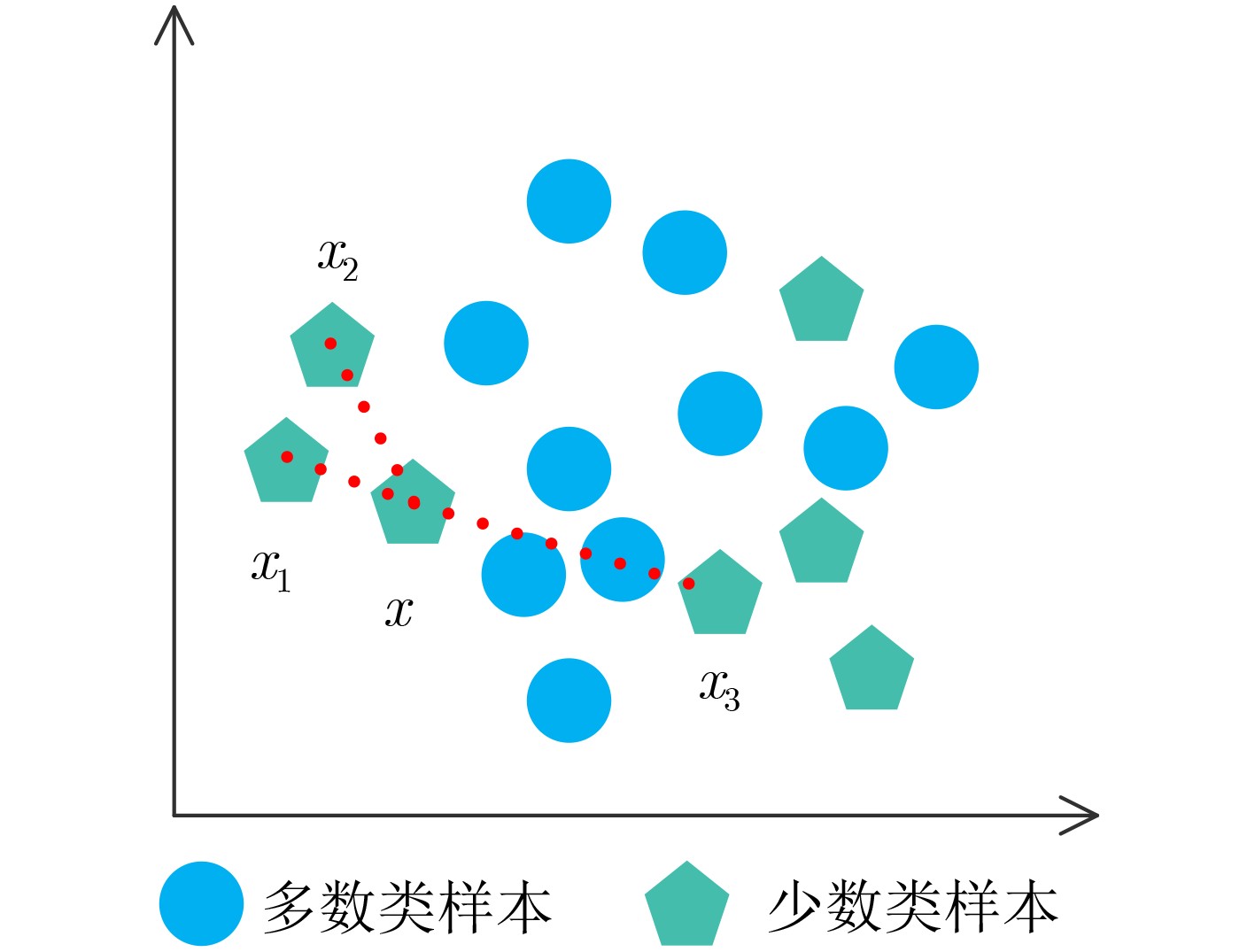
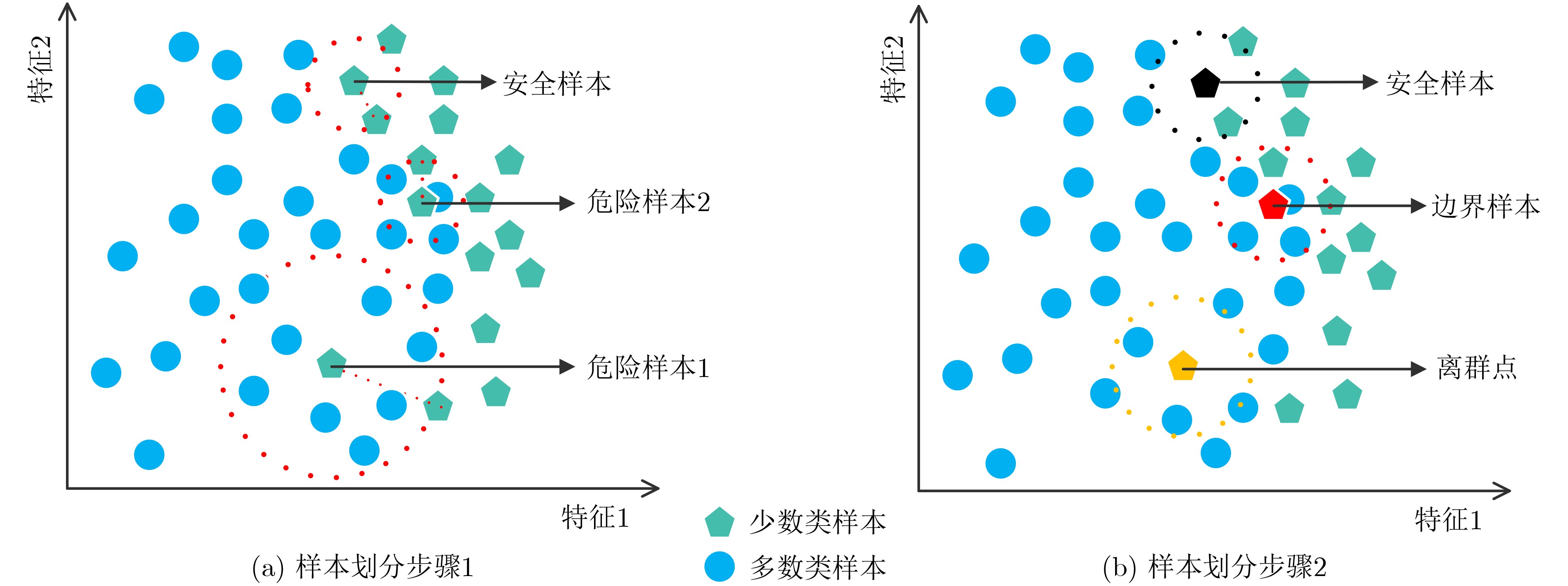
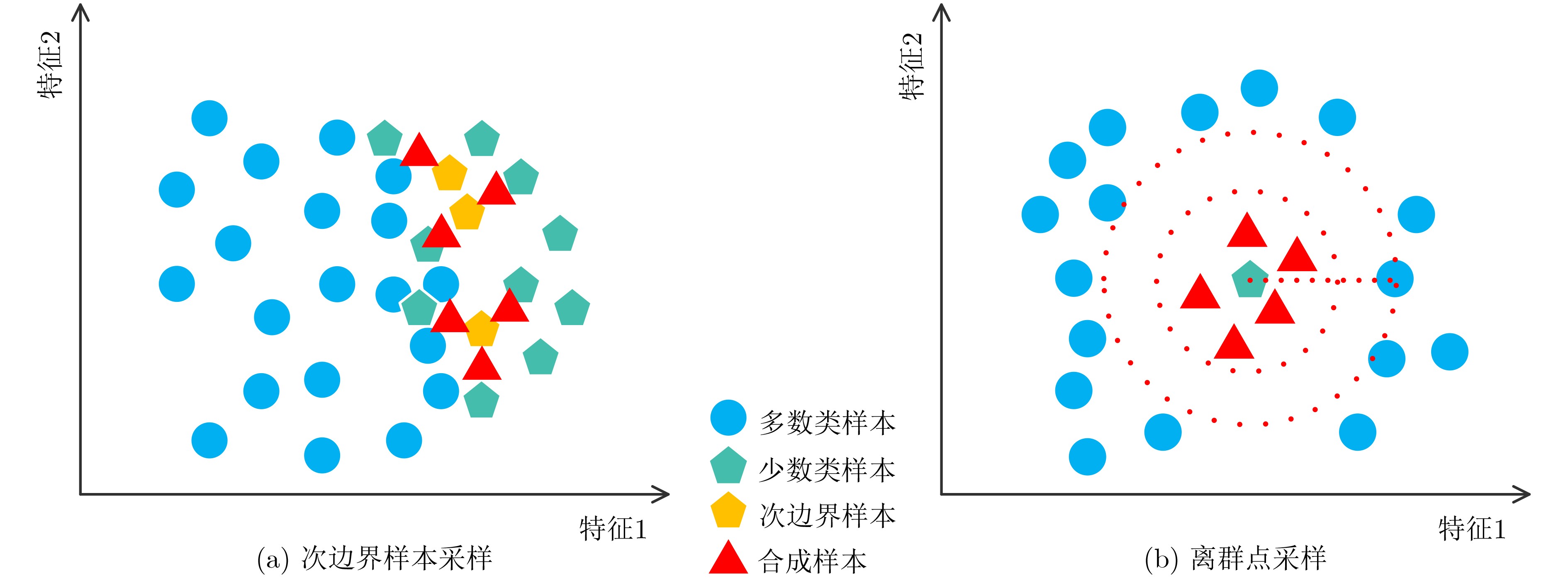
Objective Traditional classifiers tend to optimize overall accuracy when dealing with imbalanced data sets, often resulting in poor classification performance for minority class samples. Among the available strategies, oversampling methods are widely used due to their strong generalization ability. However, conventional oversampling techniques frequently generate new samples with high overlap rates and limited validity, particularly near decision boundaries. To address this issue, this study proposes an adaptive oversampling approach that selects sub-boundary samples—those located near the boundary samples—for sample generation. In addition, the nearest-neighbor parameter space is constrained to refine the synthetic sample region. This method improves the classifier’s performance when learning from imbalanced data sets. Methods This study first identifies the maximum safe like-neighbors of positive class samples and classifies these samples as either hazardous or safe. The local density of each sample is then calculated, and hazardous samples—those more difficult to classify—are further categorized as either boundary samples or outliers. To provide the classifier with more informative positive class samples, “sub-boundary points” are preferentially selected as root samples using a weighted composite factor. The K-value in the K-nearest neighbor algorithm is adaptively adjusted based on the maximum safe nearest neighbor of each sample to improve neighbor selection. Outliers are oversampled randomly within a hypersphere to generate new samples while minimizing increases in spatial complexity. Results and Discussions To evaluate the feasibility and generalization of the proposed method, Logistic Regression (LR) and Support Vector Machine (SVM) classifiers are employed as base classifiers. The range of the distance adjustment coefficient is first determined by comparing results across selected datasets ( Table 3 ). Once the range is established, the effect of different weight adjustment coefficients on performance is assessed (Table 4 ). The proposed method is then compared with six existing oversampling techniques across 13 datasets. For most datasets, the proposed method achieves higher values in more than half of the five evaluation metrics considered (Tables 5 and6 ). These results demonstrate that the proposed approach effectively improves classifier performance on imbalanced data sets.Conclusions This study introduces the maximum safe nearest neighbor number and local density to classify minority class samples into safe samples, boundary samples, and outliers. A weighted sampling probability, based on both local density and the maximum safe nearest neighbor number, is used to guide adaptive K-nearest neighbor oversampling of safe and boundary samples. Random oversampling within a hypersphere is applied to outliers to preserve informative but rare samples. Comparative experiments confirm that the proposed method performs well across datasets with varying imbalance ratios and remains competitive under highly imbalanced conditions. -
表 1 不平衡数据集信息
数据集 样本数 特征数 特征属性(R/I/N) 不平衡比 wisconsin 683 9 (0/9/0) 1.86 pima 768 8 (8/0/0) 1.87 yeast1 1484 8 (8/0/0) 2.46 haberman 306 3 (0/3/0) 2.78 vehicle0 846 18 (0/18/0) 3.25 new-thyroid2 215 5 (4/1/0) 5.14 glass6 214 9 (9/0/0) 6.38 yeast3 1484 8 (8/0/0) 8.10 ecoli3 336 7 (7/0/0) 8.60 abalone9-18 731 8 (7/0/1) 16.4 glass5 214 9 (9/0/0) 22.78 yeast4 1484 8 (8/0/0) 28.10 yeast5 1848 8 (8/0/0) 32.73  下载: 导出CSV
下载: 导出CSV
表 3 指标随调节系数$\alpha $的变化情况
数据集 评价指标 0.01 0.03 0.05 0.07 0.09 0.11 0.13 0.15 yeast1 F1-score 0.572 0.580 0.584 0.591 0.589 0.586 0.579 0.576 G-mean 0.662 0.698 0.708 0.711 0.709 0.706 0.700 0.697 glass6 F1-score 0.754 0.754 0.766 0.779 0.779 0.733 0.779 0.757 G-mean 0.905 0.905 0.908 0.911 0.911 0.884 0.911 0.889 ecoli3 F1-score 0.614 0.628 0.633 0.639 0.613 0.619 0.626 0.619 G-mean 0.893 0.896 0.898 0.900 0.893 0.894 0.886 0.873 abalone9-18 F1-score 0.307 0.372 0.380 0.399 0.414 0.403 0.425 0.419 G-mean 0.714 0.794 0.787 0.795 0.785 0.773 0.778 0.777 glass5 F1-score 0.395 0.395 0.411 0.434 0.425 0.411 0.356 0.370 G-mean 0.882 0.882 0.887 0.892 0.934 0.886 0.827 0.830 vehicle0 F1-score 0.879 0.882 0.888 0.885 0.891 0.894 0.899 0.893 G-mean 0.953 0.953 0.953 0.953 0.955 0.958 0.961 0.956
下载: 导出CSV
表 4 不同权重调节系数$ \lambda $下的指标
数据集 评价指标 (0.2,0.8) (0.4,0.6) (0.5,0.5) (0.6,0.4) (0.8,0.2) ecoli3 AUC 0.936 0.940 0.936 0.938 0.936 F1-score 0.616 0.630 0.610 0.610 0.630 G-mean 0.895 0.898 0.893 0.893 0.895 yeast1 AUC 0.793 0.795 0.794 0.793 0.792 F1-score 0.592 0.598 0.592 0.600 0.597 G-mean 0.715 0.721 0.714 0.720 0.718 yeast3 AUC 0.972 0.973 0.972 0.973 0.973 F1-score 0.732 0.766 0.756 0.765 0.768 G-mean 0.905 0.909 0.905 0.901 0.899 glass6 AUC 0.961 0.963 0.963 0.965 0.963 F1-score 0.887 0.871 0.856 0.905 0.886 G-mean 0.920 0.917 0.914 0.937 0.919 wisconsin AUC 0.994 0.994 0.995 0.994 0.963 F1-score 0.922 0.931 0.930 0.928 0.927 G-mean 0.970 0.976 0.973 0.972 0.967
下载: 导出CSV
表 5 其他采样算法的指标对比
数据集 采样方法 LR SVM Acc AUC F1-score G-mean MCC Acc AUC F1-score G-mean MCC wisconsin SMOTE 0.971 0.996 0.959 0.970 0.936 0.971 0.988 0.959 0.974 0.938 ADASYN 0.972 0.996 0.961 0.975 0.941 0.969 0.985 0.958 0.975 0.936 BSMOTE 0.972 0.996 0.962 0.976 0.939 0.971 0.984 0.960 0.974 0.939 NaN-SMOTE 0.974 0.996 0.963 0.974 0.943 0.969 0.986 0.958 0.972 0.935 SMOTE-NaN-DE 0.969 0.996 0.956 0.966 0.933 0.972 0.989 0.961 0.971 0.939 SADCO 0.972 0.996 0.961 0.972 0.940 0.971 0.986 0.960 0.974 0.938 本文方法 0.974 0.996 0.963 0.974 0.943 0.972 0.989 0.962 0.976 0.941 pima SMOTE 0.744 0.829 0.663 0.737 0.465 0.759 0.839 0.692 0.761 0.507 ADASYN 0.742 0.831 0.668 0.742 0.469 0.753 0.840 0.691 0.760 0.503 BSMOTE 0.739 0.829 0.670 0.743 0.469 0.738 0.836 0.682 0.751 0.485 NaN-SMOTE 0.719 0.832 0.680 0.742 0.479 0.723 0.835 0.685 0.746 0.489 SMOTE-NaN-DE 0.733 0.818 0.622 0.703 0.419 0.754 0.823 0.629 0.706 0.450 SADCO 0.767 0.830 0.623 0.696 0.470 0.771 0.834 0.636 0.709 0.480 本文方法 0.767 0.833 0.690 0.760 0.499 0.738 0.839 0.694 0.759 0.504 yeast1 SMOTE 0.708 0.787 0.581 0.703 0.380 0.687 0.792 0.589 0.701 0.388 ADASYN 0.681 0.786 0.584 0.705 0.379 0.650 0.786 0.581 0.692 0.375 BSMOTE 0.685 0.785 0.581 0.705 0.376 0.650 0.784 0.578 0.690 0.371 NaN-SMOTE 0.679 0.788 0.584 0.705 0.380 0.666 0.786 0.587 0.703 0.385 SMOTE-NaN-DE 0.728 0.781 0.558 0.681 0.364 0.730 0.788 0.575 0.692 0.395 SADCO 0.726 0.752 0.521 0.644 0.333 0.739 0.736 0.440 0.563 0.298 本文方法 0.720 0.790 0.593 0.715 0.400 0.722 0.795 0.597 0.718 0.405 haberman SMOTE 0.676 0.653 0.437 0.594 0.217 0.688 0.688 0.431 0.586 0.270 ADASYN 0.663 0.650 0.440 0.592 0.215 0.693 0.670 0.467 0.581 0.250 BSMOTE 0.660 0.612 0.436 0.592 0.202 0.716 0.687 0.434 0.590 0.260 NaN-SMOTE 0.667 0.658 0.437 0.595 0.209 0.703 0.670 0.410 0.561 0.219 SMOTE-NaN-DE 0.722 0.609 0.409 0.554 0.236 0.729 0.676 0.422 0.561 0.263 SADCO 0.546 0.633 0.436 0.576 0.151 0.490 0.461 0.438 0.540 0.139 本文方法 0.677 0.680 0.518 0.667 0.306 0.630 0.703 0.505 0.640 0.284 vehicle0 SMOTE 0.930 0.984 0.872 0.952 0.839 0.962 0.995 0.926 0.973 0.905 ADASYN 0.923 0.978 0.860 0.947 0.824 0.955 0.994 0.914 0.970 0.890 BSMOTE 0.913 0.976 0.851 0.951 0.812 0.959 0.993 0.920 0.973 0.898 NaN-SMOTE 0.936 0.985 0.881 0.954 0.849 0.963 0.995 0.928 0.972 0.908 SMOTE-NaN-DE 0.918 0.979 0.853 0.942 0.814 0.952 0.992 0.907 0.966 0.881 SADCO 0.922 0.968 0.855 0.936 0.813 0.950 0.990 0.905 0.967 0.880 本文方法 0.944 0.986 0.895 0.960 0.866 0.967 0.995 0.935 0.976 0.916 new-thyroid2 SMOTE 0.977 0.998 0.927 0.961 0.915 0.981 0.998 0.948 0.989 0.940 ADASYN 0.967 0.998 0.910 0.969 0.895 0.967 0.998 0.913 0.980 0.901 BSMOTE 0.963 0.998 0.898 0.966 0.882 0.963 0.998 0.904 0.977 0.956 NaN-SMOTE 0.963 0.997 0.863 0.874 0.857 0.977 0.997 0.925 0.949 0.912 SMOTE-NaN-DE 0.977 0.998 0.923 0.937 0.912 0.986 0.997 0.962 0.992 0.956 SADCO 0.953 0.989 0.824 0.840 0.820 0.977 0.997 0.921 0.925 0.912 本文方法 0.981 0.998 0.939 0.952 0.929 0.991 0.998 0.973 0.994 0.989 glass6 SMOTE 0.925 0.954 0.757 0.890 0.727 0.972 0.948 0.886 0.934 0.876 ADASYN 0.916 0.952 0.743 0.902 0.714 0.967 0.913 0.873 0.931 0.861 BSMOTE 0.935 0.949 0.772 0.883 0.741 0.967 0.904 0.862 0.900 0.852 NaN-SMOTE 0.935 0.959 0.790 0.895 0.766 0.967 0.967 0.848 0.875 0.840 SMOTE-NaN-DE 0.935 0.952 0.786 0.895 0.758 0.949 0.958 0.820 0.908 0.793 SADCO 0.898 0.957 0.716 0.890 0.687 0.953 0.960 0.825 0.906 0.802 本文方法 0.935 0.951 0.792 0.913 0.767 0.981 0.968 0.920 0.940 0.913 yeast3 SMOTE 0.908 0.967 0.679 0.894 0.651 0.931 0.971 0.736 0.904 0.710 ADASYN 0.887 0.968 0.651 0.917 0.638 0.906 0.971 0.694 0.925 0.679 BSMOTE 0.876 0.966 0.623 0.910 0.618 0.902 0.970 0.682 0.920 0.666 NaN-SMOTE 0.910 0.967 0.678 0.884 0.648 0.933 0.971 0.747 0.913 0.723 SMOTE-NaN-DE 0.919 0.967 0.701 0.892 0.671 0.939 0.972 0.759 0.908 0.734 SADCO 0.909 0.965 0.674 0.881 0.643 0.919 0.970 0.708 0.892 0.680 本文方法 0.919 0.968 0.699 0.892 0.670 0.940 0.973 0.761 0.903 0.795 ecoli3 SMOTE 0.869 0.937 0.595 0.888 0.579 0.872 0.938 0.598 0.890 0.583 ADASYN 0.851 0.933 0.572 0.889 0.562 0.860 0.935 0.576 0.883 0.561 BSMOTE 0.860 0.930 0.585 0.895 0.576 0.881 0.943 0.622 0.907 0.611 NaN-SMOTE 0.863 0.943 0.577 0.873 0.556 0.881 0.944 0.608 0.883 0.586 SMOTE-NaN-DE 0.860 0.938 0.579 0.883 0.564 0.884 0.942 0.621 0.896 0.605 SADCO 0.857 0.932 0.576 0.881 0.560 0.863 0.938 0.581 0.884 0.566 本文方法 0.890 0.938 0.640 0.900 0.622 0.902 0.940 0.665 0.907 0.647
下载: 导出CSV
表 6 高不平衡比数据集上采样算法的指标对比
数据集 采样方法 LR SVM Acc AUC F1-score G-mean MCC Acc AUC F1-score G-mean MCC abalone9-18 SMOTE 0.835 0.890 0.338 0.774 0.336 0.852 0.892 0.384 0.820 0.393 ADASYN 0.827 0.894 0.328 0.770 0.327 0.847 0.894 0.378 0.829 0.393 BSMOTE 0.841 0.857 0.313 0.734 0.304 0.859 0.853 0.318 0.706 0.295 NaN-SMOTE 0.858 0.890 0.361 0.779 0.355 0.866 0.886 0.376 0.775 0.367 SMOTE-NaN-DE 0.891 0.854 0.330 0.652 0.295 0.885 0.849 0.341 0.688 0.323 SADCO 0.824 0.804 0.284 0.706 0.263 0.854 0.872 0.303 0.689 0.277 本文方法 0.870 0.883 0.411 0.817 0.413 0.885 0.892 0.424 0.811 0.421 glass5 SMOTE 0.860 0.937 0.324 0.821 0.356 0.949 0.963 0.573 0.863 0.597 ADASYN 0.851 0.924 0.309 0.816 0.343 0.949 0.968 0.573 0.863 0.597 BSMOTE 0.855 0.937 0.316 0.818 0.350 0.944 0.968 0.547 0.860 0.574 NaN-SMOTE 0.869 0.929 0.378 0.878 0.424 0.944 0.912 0.520 0.805 0.535 SMOTE-NaN-DE 0.865 0.936 0.333 0.823 0.366 0.930 0.961 0.480 0.854 0.497 SADCO 0.860 0.905 0.242 0.583 0.228 0.935 0.978 0.535 0.911 0.563 本文方法 0.879 0.937 0.425 0.934 0.486 0.949 0.960 0.573 0.862 0.597 yeast4 SMOTE 0.858 0.876 0.260 0.786 0.294 0.870 0.896 0.277 0.794 0.310 ADASYN 0.840 0.874 0.247 0.800 0.289 0.852 0.893 0.247 0.774 0.278 BSMOTE 0.885 0.868 0.305 0.799 0.335 0.904 0.885 0.338 0.798 0.360 NaN-SMOTE 0.861 0.879 0.266 0.788 0.299 0.873 0.892 0.276 0.785 0.305 SMOTE-NaN-DE 0.892 0.865 0.315 0.803 0.344 0.900 0.886 0.334 0.805 0.361 SADCO 0.836 0.859 0.246 0.796 0.287 0.860 0.873 0.267 0.787 0.299 本文方法 0.894 0.870 0.324 0.804 0.351 0.908 0.888 0.354 0.809 0.378 yeast5 SMOTE 0.934 0.985 0.478 0.965 0.541 0.946 0.985 0.530 0.972 0.584 ADASYN 0.931 0.985 0.457 0.964 0.532 0.945 0.986 0.527 0.971 0.581 BSMOTE 0.930 0.984 0.463 0.963 0.529 0.944 0.986 0.520 0.971 0.576 NaN-SMOTE 0.939 0.985 0.491 0.967 0.552 0.945 0.981 0.521 0.961 0.572 SMOTE-NaN-DE 0.935 0.986 0.483 0.966 0.545 0.945 0.986 0.524 0.971 0.579 SADCO 0.944 0.986 0.520 0.971 0.576 0.937 0.986 0.593 0.967 0.554 本文方法 0.945 0.985 0.524 0.971 0.579 0.949 0.985 0.546 0.973 0.597
下载: 导出CSV
-
[1] 李艳霞, 柴毅, 胡友强, 等. 不平衡数据分类方法综述[J]. 控制与决策, 2019, 34(4): 673–688. doi: 10.13195/j.kzyjc.2018.0865.LI Yanxia, CHAI Yi, HU Youqiang, et al. Review of imbalanced data classification methods[J]. Control and Decision, 2019, 34(4): 673–688. doi: 10.13195/j.kzyjc.2018.0865. [2] GUO Haixiang, LI Yijing, SHANG J, et al. Learning from class-imbalanced data: Review of methods and applications[J]. Expert Systems with Applications, 2017, 73: 220–239. doi: 10.1016/j.eswa.2016.12.035. [3] SHIN K, HAN J, and KANG S. MI-MOTE: Multiple imputation-based minority oversampling technique for imbalanced and incomplete data classification[J]. Information Sciences, 2021, 575: 80–89. doi: 10.1016/j.ins.2021.06.043. [4] 苏逸, 李晓军, 姚俊萍, 等. 不平衡数据分类数据层面方法: 现状及研究进展[J]. 计算机应用研究, 2023, 40(1): 11–19. doi: 10.19734/j.issn.1001-3695.2022.05.0250.SU Yi, LI Xiaojun, YAO Junping, et al. Data-level methods of imbalanced data classification: Status and research development[J]. Application Research of Computers, 2023, 40(1): 11–19. doi: 10.19734/j.issn.1001-3695.2022.05.0250. [5] THABTAH F, HAMMOUD S, KAMALOV F, et al. Data imbalance in classification: Experimental evaluation[J]. Information Sciences, 2020, 513: 429–441. doi: 10.1016/j.ins.2019.11.004. [6] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: Synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16: 321–357. doi: 10.1613/jair.953. [7] ABDI L and HASHEMI S. To combat multi-class imbalanced problems by means of over-sampling techniques[J]. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(1): 238–251. doi: 10.1109/TKDE.2015.2458858. [8] CHEN Baiyun, XIA Shuyin, CHEN Zizhong, et al. RSMOTE: A self-adaptive robust SMOTE for imbalanced problems with label noise[J]. Information Sciences, 2021, 553: 397–428. doi: 10.1016/j.ins.2020.10.013. [9] HAN Hui, WANG Wenyuan, and MAO Binghuan. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning[C]. The International Conference on Intelligent Computing Advances in Intelligent Computing, Hefei, China, 2005: 878–887. doi: 10.1007/11538059_91. [10] HE Haibo, BAI Yang, GARCIA E A, et al. ADASYN: Adaptive synthetic sampling approach for imbalanced learning[C]. 2008 IEEE International Joint Conference on Neural Networks, Hong Kong, China, 2008: 1322–1328. doi: 10.1109/IJCNN.2008.4633969. [11] SOLTANZADEH P and HASHEMZADEH M. RCSMOTE: Range-Controlled synthetic minority over-sampling technique for handling the class imbalance problem[J]. Information Sciences, 2021, 542: 92–111. doi: 10.1016/j.ins.2020.07.014. [12] XU Zhaozhao, SHEN Derong, NIE Tiezheng, et al. A cluster-based oversampling algorithm combining SMOTE and k-means for imbalanced medical data[J]. Information Sciences, 2021, 572: 574–589. doi: 10.1016/j.ins.2021.02.056. [13] 高雷阜, 张梦瑶, 赵世杰. 融合簇边界移动与自适应合成的混合采样算法[J]. 电子学报, 2022, 50(10): 2517–2529. doi: 10.12263/DZXB.20210265.GAO Leifu, ZHANG Mengyao, and ZHAO Shijie. Mixed-sampling algorithm combining cluster boundary movement and adaptive synthesis[J]. Acta Electronica Sinica, 2022, 50(10): 2517–2529. doi: 10.12263/DZXB.20210265. [14] 黄海松, 魏建安, 康佩栋. 基于不平衡数据样本特性的新型过采样SVM分类算法[J]. 控制与决策, 2018, 33(9): 1549–1558. doi: 10.13195/j.kzyjc.2017.0649.HUANG Haisong, WEI Jian’an, and KANG Peidong. New over-sampling SVM classification algorithm based on unbalanced data sample characteristics[J]. Control and Decision, 2018, 33(9): 1549–1558. doi: 10.13195/j.kzyjc.2017.0649. [15] SHI Shengnan, LI Jie, ZHU Dan, et al. A hybrid imbalanced classification model based on data density[J]. Information Sciences, 2023, 624: 50–67. doi: 10.1016/j.ins.2022.12.046. [16] TAO Xinmin, GUO Xinyue, ZHENG Yujia, et al. Self-adaptive oversampling method based on the complexity of minority data in imbalanced datasets classification[J]. Knowledge-Based Systems, 2023, 277: 110795. doi: 10.1016/j.knosys.2023.110795. [17] 周玉, 岳学震, 刘星, 等. 不平衡数据集的自然邻域超球面过采样方法[J]. 哈尔滨工业大学学报, 2024, 56(12): 81–95. doi: 10.11918/202311030.ZHOU Yu, YUE Xuezhen, LIU Xing, et al. A natural neighborhood hypersphere oversampling method for imbalanced data sets[J]. Journal of Harbin Institute of Technology, 2024, 56(12): 81–95. doi: 10.11918/202311030. [18] LENG Qiangkui, GUO Jiamei, JIAO Erjie, et al. NanBDOS: Adaptive and parameter-free borderline oversampling via natural neighbor search for class-imbalance learning[J]. Knowledge-Based Systems, 2023, 274: 110665. doi: 10.1016/j.knosys.2023.110665. [19] THEJAS G S, HARIPRASAD Y, IYENGAR S S, et al. An extension of Synthetic Minority Oversampling Technique based on Kalman filter for imbalanced datasets[J]. Machine Learning with Applications, 2022, 8: 100267. doi: 10.1016/j.mlwa.2022.100267. [20] 胡峰, 王蕾, 周耀. 基于三支决策的不平衡数据过采样方法[J]. 电子学报, 2018, 46(1): 135–144. doi: 10.3969/j.issn.0372-2112.2018.01.019.HU Feng, WANG Lei, and ZHOU Yao. An oversampling method for imbalance data based on three-way decision model[J]. Acta Electronica Sinica, 2018, 46(1): 135–144. doi: 10.3969/j.issn.0372-2112.2018.01.019. [21] ALCALÁ-FDEZ J, SÁNCHEZ L, GARCÍA S, et al. KEEL: A software tool to assess evolutionary algorithms for data mining problems[J]. Soft Computing, 2009, 13(3): 307–318. doi: 10.1007/s00500-008-0323-y. [22] LI Junnan, ZHU Qingsheng, WU Quanwang, et al. A novel oversampling technique for class-imbalanced learning based on SMOTE and natural neighbors[J]. Information Sciences, 2021, 565: 438–455. doi: 10.1016/j.ins.2021.03.041. [23] LI Junnan, ZHU Qingsheng, WU Quanwang, et al. SMOTE-NaN-DE: Addressing the noisy and borderline examples problem in imbalanced classification by natural neighbors and differential evolution[J]. Knowledge-Based Systems, 2021, 223: 107056. doi: 10.1016/j.knosys.2021.107056. -

 下载:
下载:


图(3) / 表(6)
计量
- 文章访问数: 452
- HTML全文浏览量: 326
- PDF下载量: 53
- 被引次数: 0
