

Vision-Language Tracking Method Combining Bi-level Routing Perception and Scattered Vision Transformation
-
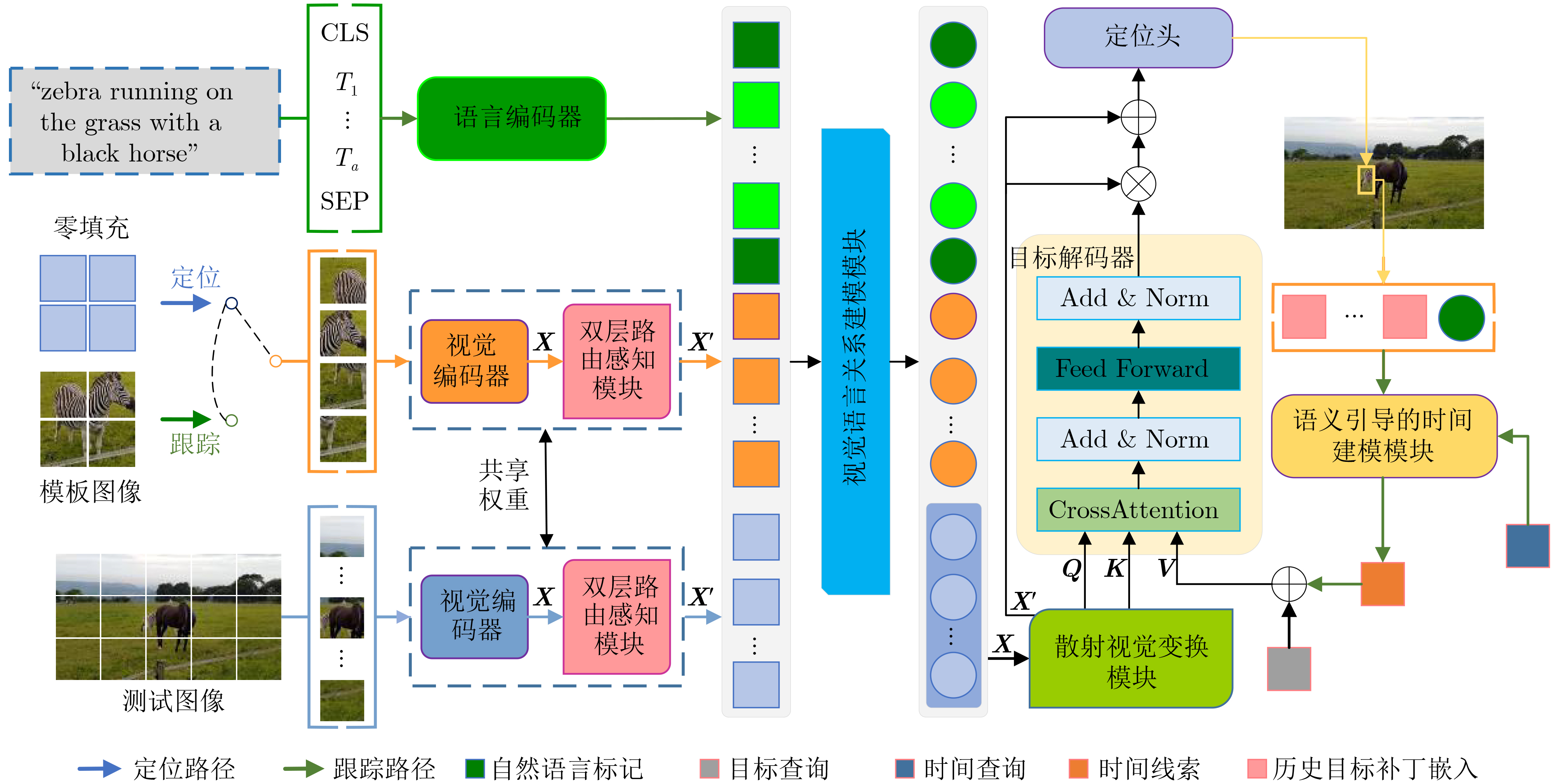
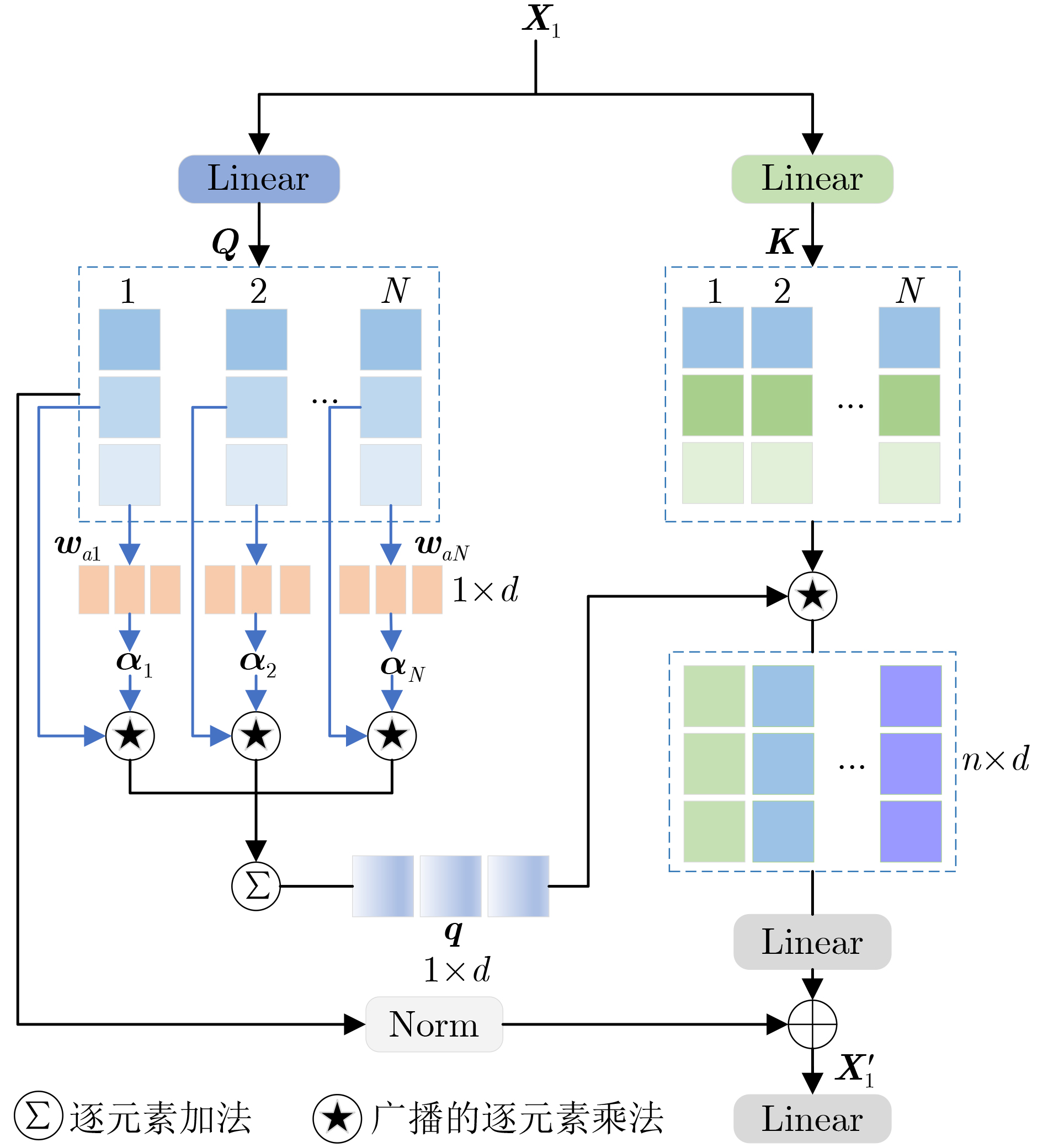
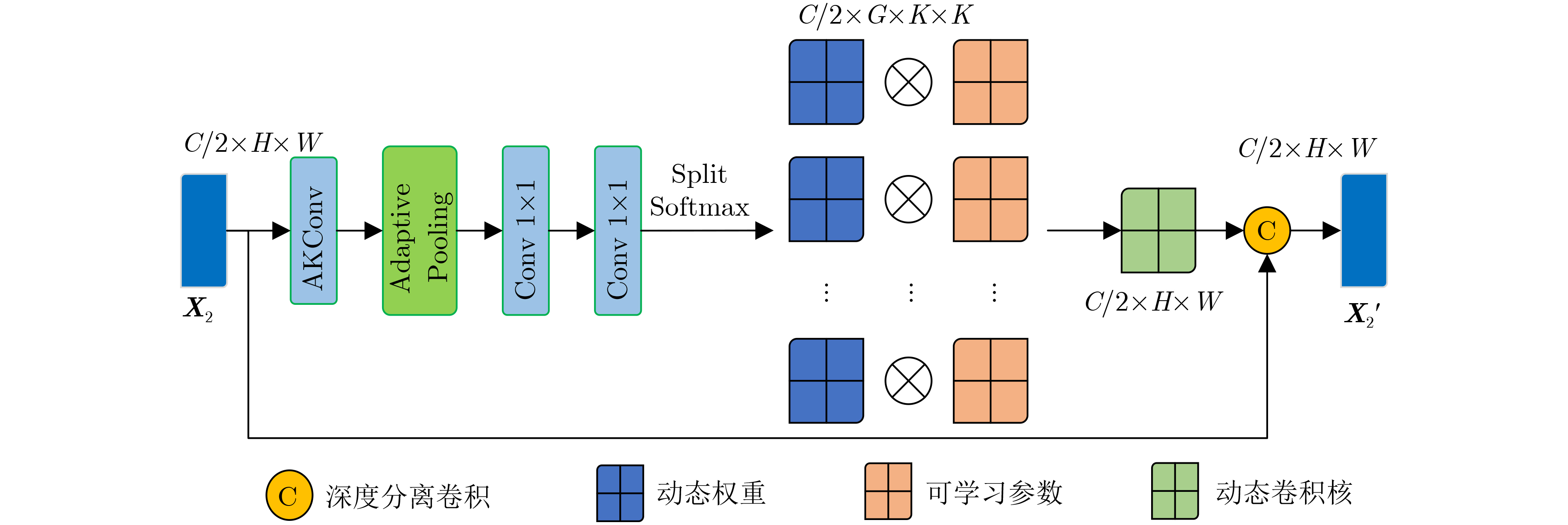
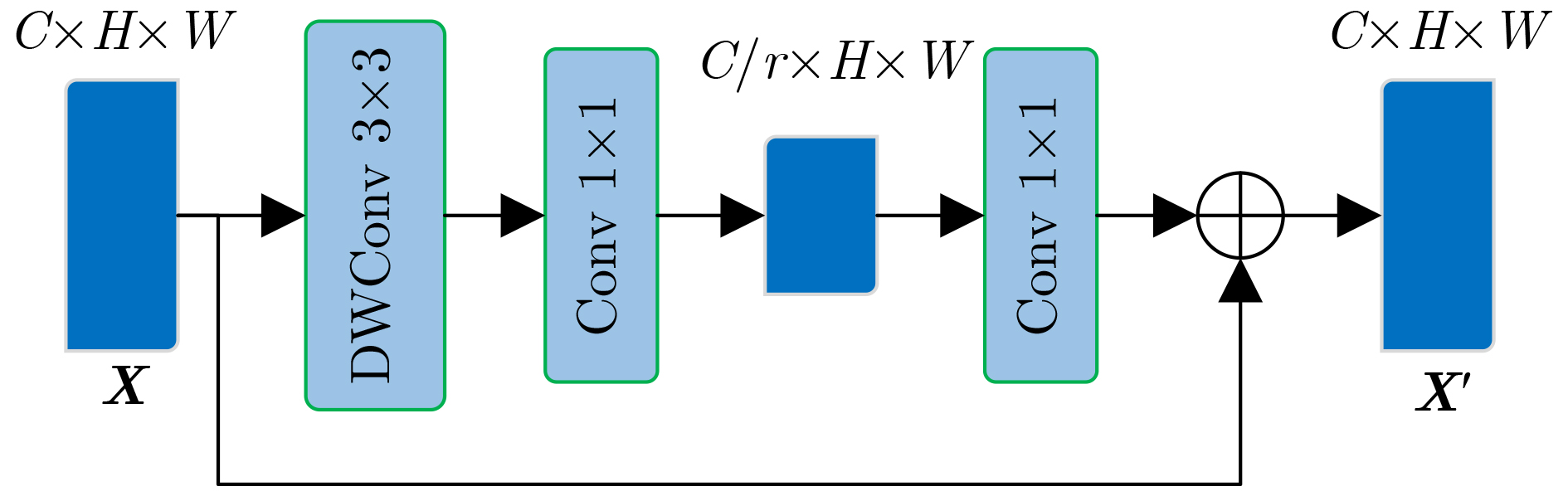
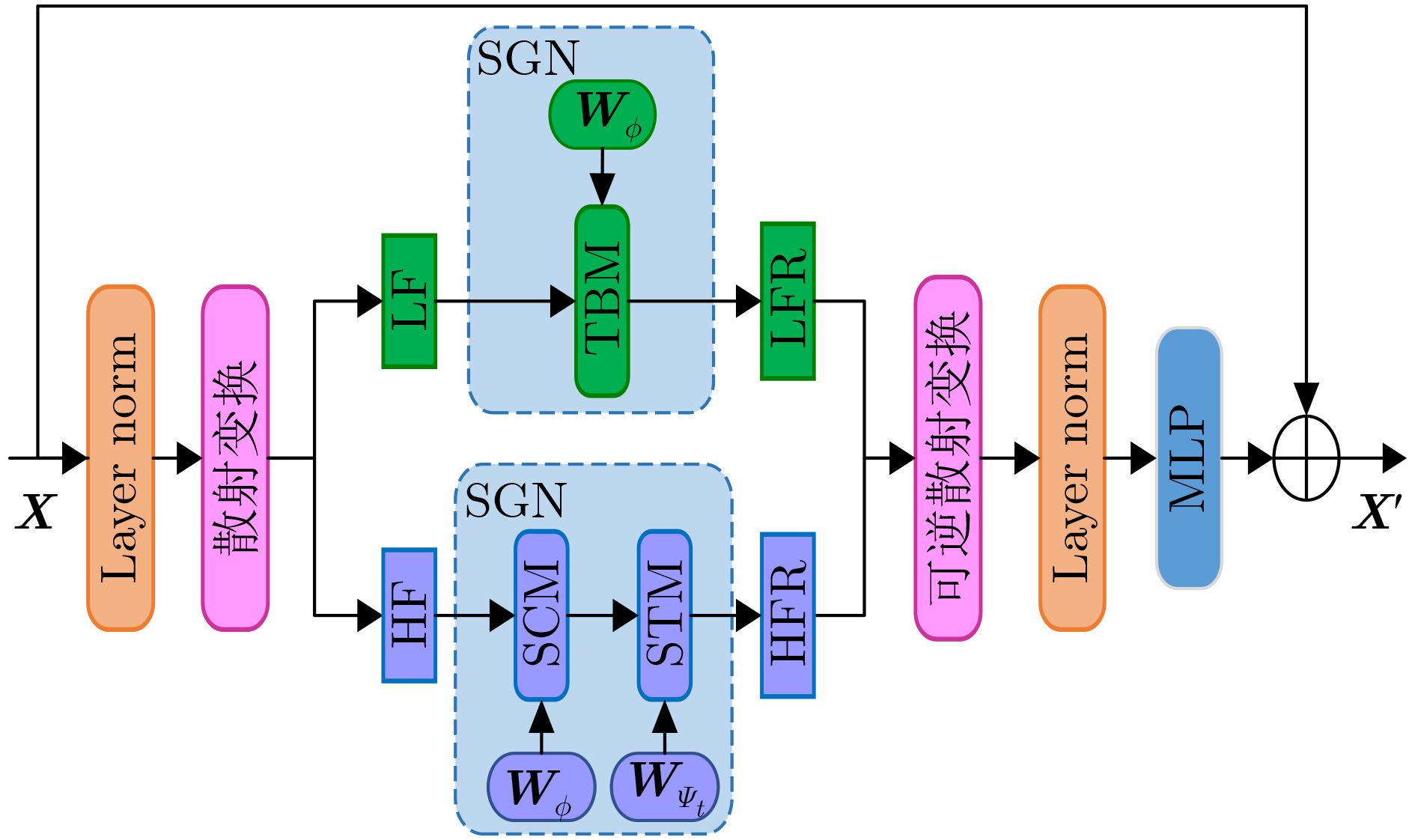
摘要: 针对视觉-语言关系建模中存在感受野有限和特征交互不充分问题,该文提出一种结合双层路由感知和散射视觉变换的视觉-语言跟踪框架(BPSVTrack)。首先,设计了一种双层路由感知模块(BRPM),通过将高效的加性注意力(EAA)与双动态自适应模块(DDAM)并行结合起来进行双向交互来扩大感受野,使模型更加高效地整合不同窗口和尺寸之间的特征,从而提高模型在复杂场景中对目标的感知能力。其次,通过引入基于双树复小波变换(DTCWT)的散射视觉变换模块(SVTM),将图像分解为低频和高频信息,以此来捕获图像中目标结构和细粒度信息,从而提高模型在复杂环境下的鲁棒性和准确性。在OTB99, LaSOT, TNL2K 3个跟踪数据集上分别取得了86.1%, 64.4%, 63.2%的精度,在RefCOCOg数据集上取得了70.21%的准确率,在跟踪和定位方面的性能均优于基准模型。Abstract: Considering the issues of limited receptive field and insufficient feature interaction in vision-language tracking framework combineing Bi-level routing Perception and Scattering Visual Trans-formation (BPSVTrack) is proposed in this paper. Initially, a Bi-level Routing Perception Module (BRPM) is designed which combines Efficient Additive Attention(EAA) and Dual Dynamic Adaptive Module(DDAM) in parallel to enable bidirectional interaction for expanding the receptive field. Consequently, enhancing the model’s ability to integrate features between different windows and sizes efficiently, thereby improving the model’s ability to perceive objects in complex scenes. Secondly, the Scattering Vision Transform Module(SVTM) based on Dual-Tree Complex Wavelet Transform(DTCWT) is introduced to decompose the image into low frequency and high frequency information, aiming to capture the target structure and fine-grained details in the image, thus improving the robustness and accuracy of the model in complex environments. The proposed framework achieves accuracies of 86.1%, 64.4%, and 63.2% on OTB99, LaSOT and TNL2K tracking datasets respectively. Moreover, it attains an accuracy of 70.21% on the RefCOCOg dataset, the performance in tracking and locating surpasses that of the baseline model.
-
表 1 模型的3种变体在数据集LaSOT和TNL2K上的AUC和Pre
变体 LaSOT TNL2K AUC Pre AUC Pre JointNLT 0.569 0.593 0.546 0.550 JointNLT +BRPM 0.547 0.569 0.521 0.516 JointNLT +SVT 0.562 0.580 0.543 0.539 JointNLT +BRPM+SVT 0.574 0.612 0.550 0.563  下载: 导出CSV
下载: 导出CSV
表 2 双层路由感知模块在LaSOT和TNL2K上的AUC和Pre
模型 LaSOT TNL2K AUC Pre AUC Pre BRPM 0.547 0.569 0.521 0.516 BRPM-FI 0.538 0.560 0.517 0.504 EAA-O 0.537 0.554 0.513 0.507 DDAM-O 0.540 0.559 0.517 0.510 BRPM-STE 0.539 0.564 0.515 0.512
下载: 导出CSV
表 3 标记压缩-增强模块在数据集LaSOT和TNL2K上的PRE和P
模型 LsSOT TNL2K 模型 PRE PRE STE-S 0.569 0.516 155.4M STE-NS 0.563 0.511 155.9M
下载: 导出CSV
表 4 分离方法和联合方法以及定位和跟踪之间的比较
分离的方法 联合的方法 VLTVG+STARK VTLVG+OSTrack SepRM JointNLT BPSVTrack FLOPs 定位 39.6G 39.6G 34.7G 34.9G 35.9G 跟踪 20.4G 48.3G 38.5G 42.0G 43.1G fps 定位 28.2 ms 28.2 ms 26.4 ms 34.8 ms 36.0 ms 跟踪 22.9 ms 8.3 ms 20.6 ms 25.3 ms 28.4 ms P 总量 169.8M 214.7M 214.4M 153.0M 155.4M AUC LaSOT 0.446 0.524 0.518 0.569 0.574 TNL2K 0.373 0.399 0.491 0.546 0.550
下载: 导出CSV
表 5 不同方法在数据集OTB99, LaSOT和TNL2K上的AUC和Pre
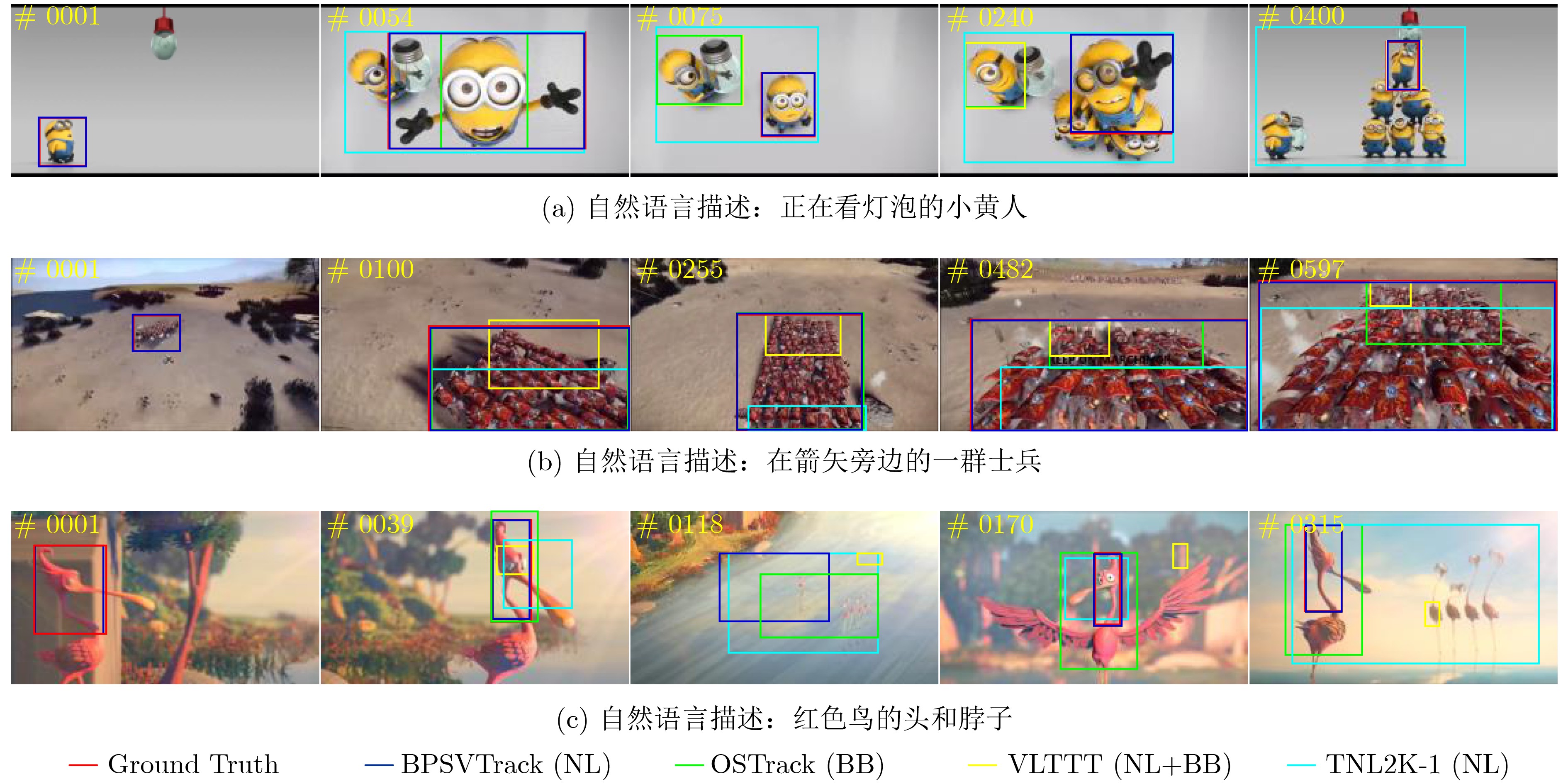
方法 来源 初始化方式 OTB99 LaSOT TNL2K AUC Pre AUC Pre AUC Pre AutoMatch[27] ICCV21 BB – – 0.583 0.599 0.472 0.435 TrDiMP[28] CVPR21 BB – – 0.639 0.663 0.523 0.528 TransT[29] CVPR21 BB – – 0.649 0.690 0.507 0.517 STARK[26] ICCV21 BB – – 0.671 0.712 – – KeepTrack[30] ICCV21 BB – – 0.671 0.702 – – SwinTrack-B[31] NeurIPS22 BB – – 0.696 0.741 – – OSTrack-384[14] ECCV2022 BB – – 0.711 0.776 0.559 – TNLS-II[15] CVPR17 NL 0.250 0.290 – – – – RTTNLD[17] WACV20 NL 0.540 0.780 0.280 0.280 – – GTI[16] TCSVT20 NL 0.581 0.732 0.478 0.476 – – TNL2K-1[3] CVPR21 NL 0.190 0.240 0.510 0.490 0.110 0.060 CTRNLT[4] CVPR22 NL 0.530 0.720 0.520 0.510 0.140 0.090 JointNLT CVPR23 NL 0.592 0.776 0.569 0.593 0.546 0.550 BPSVTrack 本文 NL 0.603 0.786 0.574 0.612 0.550 0.563 TNLS-III[15] CVPR17 NL+BB 0.550 0.720 – – – – RTTNLD WACV20 NL+BB 0.610 0.790 0.350 0.350 0.250 0.270 TNL2K-2[3] CVPR21 NL+BB 0.680 0.880 0.510 0.550 0.420 0.420 SNLT[5] CVPR21 NL+BB 0.666 0.804 0.540 0.576 0.276 0.419 VLTTT[3] NeurIPS22 NL+BB 0.764 0.931 0.673 0.721 0.531 0.533 JointNLT CVPR23 NL+BB 0.653 0.856 0.604 0.636 0.569 0.581 BPSVTrack 本文 NL+BB 0.664 0.861 0.621 0.644 0.609 0.632
下载: 导出CSV
-
[1] GUO Mingzhe, ZHANG Zhipeng, JING Liping, et al. Divert more attention to vision-language object tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence. doi: 10.1109/TPAMI.2024.3409078. [2] 许廷发, 王颖, 史国凯, 等. 深度学习单目标跟踪方法的基础架构研究进展[J]. 光学学报, 2023, 43(15): 1510003. doi: 10.3788/AOS230746.XU Tingfa, WANG Ying, SHI Guokai, et al. Research progress in fundamental architecture of deep learning-based single object tracking method[J]. Acta Optica Sinica, 2023, 43(15): 1510003. doi: 10.3788/AOS230746. [3] WANG Xiao, SHU Xiujun, ZHANG Zhipeng, et al. Towards more flexible and accurate object tracking with natural language: Algorithms and benchmark[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 13758–13768. doi: 10.1109/cvpr46437.2021.01355. [4] LI Yihao, YU Jun, CAI Zhongpeng, et al. Cross-modal target retrieval for tracking by natural language[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, New Orleans, USA, 2022: 4927–4936. doi: 10.1109/cvprw56347.2022.00540. [5] FENG Qi, ABLAVSKY V, BAI Qinxun, et al. Siamese natural language tracker: Tracking by natural language descriptions with Siamese trackers[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 5847–5856. doi: 10.1109/cvpr46437.2021.00579. [6] ZHENG Yaozong, ZHONG Bineng, LIANG Qihua, et al. Toward unified token learning for vision-language tracking[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(4): 2125–2135. doi: 10.1109/TCSVT.2023.3301933. [7] ZHAO Haojie, WANG Xiao, WANG Dong, et al. Transformer vision-language tracking via proxy token guided cross-modal fusion[J]. Pattern Recognition Letters, 2023, 168: 10–16. doi: 10.1016/j.patrec.2023.02.023. [8] ZHOU Li, ZHOU Zikun, MAO Kaige, et al. Joint visual grounding and tracking with natural language specification[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 23151–23160. doi: 10.1109/cvpr52729.2023.02217. [9] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [10] SONG Zikai, LUO Run, YU Junqing, et al. Compact transformer tracker with correlative masked modeling[C]. The 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 2321–2329. doi: 10.1609/aaai.v37i2.25327. [11] WANG Yuanyun, ZHANG Wenshuang, LAI Changwang, et al. Adaptive temporal feature modeling for visual tracking via cross-channel learning[J]. Knowledge-Based Systems, 2023, 265: 110380. doi: 10.1016/j.knosys.2023.110380. [12] ZHAO Moju, OKADA K, and INABA M. TrTr: Visual tracking with transformer[J]. arXiv: 2105.03817, 2021. doi: 10.48550/arXiv.2105.03817. [13] TANG Chuanming, WANG Xiao, BAI Yuanchao, et al. Learning spatial-frequency transformer for visual object tracking[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(9): 5102–5116. doi: 10.1109/tcsvt.2023.3249468. [14] YE Botao, CHANG Hong, MA Bingpeng, et al. Joint feature learning and relation modeling for tracking: A one-stream framework[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 341–357. doi: 10.1007/978-3-031-20047-2_20. [15] LI Zhenyang, TAO Ran, GAVVES E, et al. Tracking by natural language specification[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 7350–7358. doi: 10.1109/cvpr.2017.777. [16] YANG Zhengyuan, KUMAR T, CHEN Tianlang, et al. Grounding-tracking-integration[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(9): 3433–3443. doi: 10.1109/tcsvt.2020.3038720. [17] FENG Qi, ABLAVSKY V, BAI Qinxun, et al. Real-time visual object tracking with natural language description[C]. 2020 IEEE Winter Conference on Applications of Computer Vision, Snowmass, USA, 2020: 689–698. doi: 10.1109/wacv45572.2020.9093425. [18] ZHANG Xin, SONG Yingze, SONG Tingting, et al. AKConv: Convolutional kernel with arbitrary sampled shapes and arbitrary number of parameters[J]. arXiv: 2311.11587, 2023. doi: 10.48550/arXiv.2311.11587. [19] SELESNICK I W, BARANIUK R G, and KINGSBURY N C. The dual-tree complex wavelet transform[J]. IEEE Signal Processing Magazine, 2005, 22(6): 123–151. doi: 10.1109/MSP.2005.1550194. [20] ROGOZHNIKOV A. Einops: Clear and reliable tensor manipulations with Einstein-like notation[C]. The 10th International Conference on Learning Representations, 2022: 1–21. [21] MAO Junhua, HUANG J, TOSHEV A, et al. Generation and comprehension of unambiguous object descriptions[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 11–20. doi: 10.1109/cvpr.2016.9. [22] FAN Heng, LIN Liting, YANG Fan, et al. LaSOT: A high-quality benchmark for large-scale single object tracking[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5369–5378. doi: 10.1109/cvpr.2019.00552. [23] DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, 2018: 4171–4186. doi: 10.18653/v1/N19-1423. [24] LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 9992–10002. doi: 10.1109/iccv48922.2021.00986. [25] YANG Li, XU Yan, YUAN Chunfeng, et al. Improving visual grounding with visual-linguistic verification and iterative reasoning[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 9489–9498. doi: 10.1109/cvpr52688.2022.00928. [26] YAN Bin, PENG Houwen, FU Jianlong, et al. Learning spatio-temporal transformer for visual tracking[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 10428–10437. doi: 10.1109/iccv48922.2021.01028. [27] ZHANG Zhipeng, LIU Yihao, WANG Xiao, et al. Learn to match: Automatic matching network design for visual tracking[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 13319–13328. 10. doi: 1109/iccv48922.2021.01309. [28] WANG Ning, ZHOU Wengang, WANG Jie, et al. Transformer meets tracker: Exploiting temporal context for robust visual tracking[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 1571–1580. doi: 10.1109/cvpr46437.2021.00162. [29] CHEN Xin, YAN Bin, ZHU Jiawen, et al. Transformer tracking[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 8122–8131. doi: 10.1109/CVPR46437.2021.00803. [30] MAYER C, DANELLJAN M, PAUDEL D P, et al. Learning target candidate association to keep track of what not to track[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 13424–13434. doi: 10.1109/iccv48922.2021.01319. [31] LIN Liting, FAN Heng, ZHANG Zhipeng, et al. SwinTrack: A simple and strong baseline for transformer tracking[C]. The 36th Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 16743–16754. [32] LIU Daqing, ZHANG Hanwang, ZHA Zhengjun, et al. Learning to assemble neural module tree networks for visual grounding[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 4672–4681. doi: 10.1109/iccv.2019.00477. [33] HUANG Binbin, LIAN Dongze, LUO Weixin, et al. Look before you leap: Learning landmark features for one-stage visual grounding[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 16883–16892. doi: 10.1109/cvpr46437.2021.01661. [34] YANG Zhengyuan, CHEN Tianlang, WANG Liwei, et al. Improving one-stage visual grounding by recursive sub-query construction[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 387–404. doi: 10.1007/978-3-030-58568-6_23. [35] DENG Jiajun, YANG Zhengyuan, CHEN Tianlang, et al. TransVG: End-to-end visual grounding with transformers[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 1749–1759. doi: 10.1109/iccv48922.2021.00179. -

 下载:
下载:



图(7) / 表(6)
计量
- 文章访问数: 1092
- HTML全文浏览量: 575
- PDF下载量: 51
- 被引次数: 0
