

A Survey of Adversarial Attacks on 3D Point Cloud Object Recognition
-
摘要: 当前,人工智能系统在诸多领域都取得了巨大的成功,其中深度学习技术发挥了关键作用。然而,尽管深度神经网络具有强大的推理识别能力,但是依然容易受到对抗样本的攻击,表现出了脆弱性。对抗样本是经过特殊设计的输入数据,能够攻击并误导深度学习模型的输出。随着激光雷达等3维传感器的快速发展,使用深度学习技术解决3维领域的各种智能任务也越来越受到重视。采用深度学习技术处理3维点云数据的人工智能系统的安全性和鲁棒性至关重要,如基于深度学习的自动驾驶3维目标检测与识别技术。为了分析3维点云对抗样本对深度神经网络的攻击方式,揭示3维对抗样本对深度神经网络的干扰机制,该文总结了基于3维点云深度神经网络模型的对抗攻击方法的研究进展。首先,介绍了对抗攻击的基本原理和实现方法,然后,总结并分析了3维点云的数字域对抗攻击和物理域对抗攻击,最后,讨论了3维点云对抗攻击面临的挑战和未来的研究方向。Abstract: Currently, artificial intelligence systems have achieved significant success in various domains, with deep learning technology playing a pivotal role. However, although the deep neural network has strong inference recognition ability, it is still vulnerable to the attack of adversarial examples, showing its vulnerability. Adversarial samples are specially crafted input data designed to attack and mislead the outputs of deep learning models. With the rapid development of 3D sensors such as LiDAR, the use of deep learning technology to address various intelligent tasks in the 3D domain is gaining increasing attention. Ensuring the security and robustness of artificial intelligence systems that process 3D point cloud data, such as deep learning-based autonomous 3D object detection and recognition for self-driving vehicles, is crucial. In order to analyze the methods by which 3D adversarial samples attack deep neural networks, and reveal the interference mechanisms of 3D adversarial samples on deep neural networks, this paper summarizes the research progress on adversarial attack methods for deep neural network models based on 3D point cloud data. The paper first introduces the fundamental principles and implementation methods of adversarial attacks, and then it summarizes and analyzes digital domain adversarial attacks and physical domain adversarial attacks on 3D point clouds. Finally, it discusses the challenges and future research directions in the realm of 3D point cloud adversarial attacks.
-
Key words:
- Adversarial attack /
- Deep learning /
- 3D point cloud /
- Adversarial examples
-
表 1 3维点云对抗攻击的数据集
数据集 类型 特点 ModelNet40 仿真数据集 数据规模小,仿真目标结构完整、形状清晰、无噪声、类别多样 ShapeNet 仿真数据集 数据规模小,仿真目标结构完整、形状清晰、无噪声、类别多样 ScanObjectNN 真实世界数据集 数据规模小,真实世界的室内场景、室内目标扫描而获得的物体数据集 KITTI 真实世界数据集 数据规模较大,面向自动驾驶的真实世界城市和街区的点云数据集 NuScenes 真实世界数据集 数据规模大,面向自动驾驶的真实世界城市的点云数据集 Waymo 真实世界数据集 数据规模大,面向自动驾驶的真实世界城市和郊区的点云数据集  下载: 导出CSV
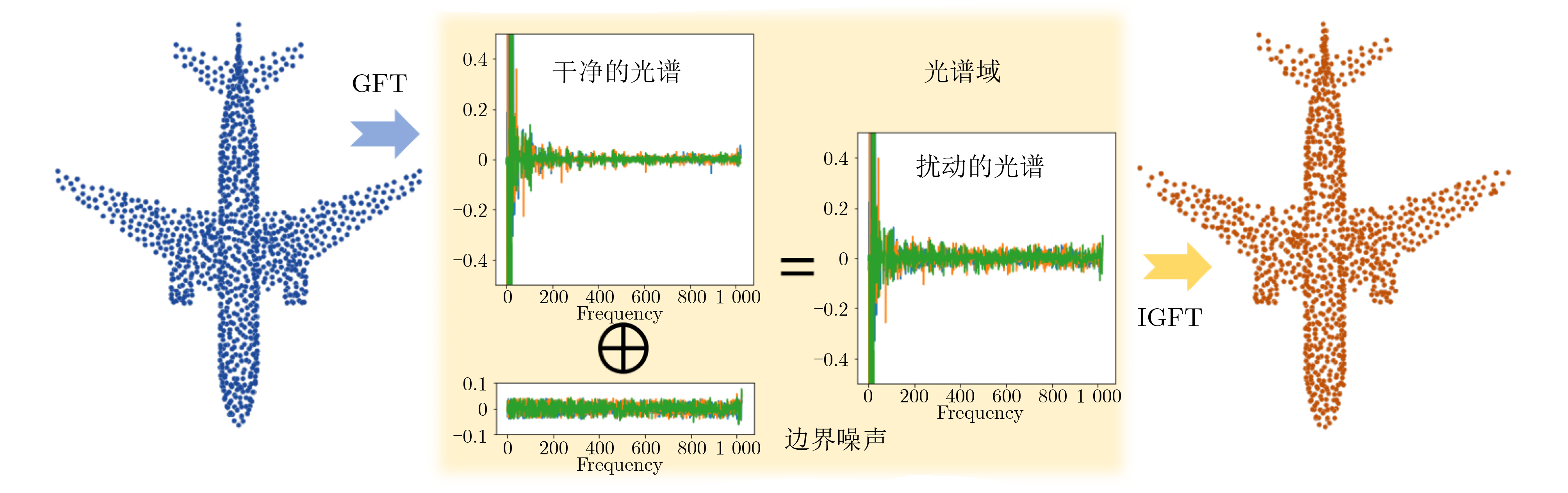
下载: 导出CSV
-
[1] LANCHANTIN J, WANG Tianlu, ORDONEZ V, et al. General multi-label image classification with transformers[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 16473–16483. doi: 10.1109/CVPR46437.2021.01621. [2] SUN Xiao, LIAN Zhouhui, and XIAO Jianguo. SRINet: Learning strictly rotation-invariant representations for point cloud classification and segmentation[C]. The 27th ACM International Conference on Multimedia, Nice, France, 2019: 980–988. doi: 10.1145/3343031.3351042. [3] HUYNH C, TRAN A T, LUU K, et al. Progressive semantic segmentation[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 16750–16759. doi: 10.1109/CVPR46437.2021.01648. [4] LIU Weiquan, GUO Hanyun, ZHANG Weini, et al. TopoSeg: Topology-aware segmentation for point clouds[C]. The Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 2022: 1201–1208. doi: 10.24963/ijcai.2022/168. [5] CHEN Xiangning, XIE Cihang, TAN Mingxing, et al. Robust and accurate object detection via adversarial learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 16617–16626. doi: 10.1109/CVPR46437.2021.01635. [6] MIAO Zhenwei, CHEN JiKai, PAN Hongyu, et al. PVGNet: A bottom-up one-stage 3D object detector with integrated multi-level features[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 3278–3287. doi: 10.1109/CVPR46437.2021.00329. [7] SZEGEDY C, ZAREMBA W, SUTSKEVER I, et al. Intriguing properties of neural networks[C]. The 2nd International Conference on Learning Representations, Banff, Canada, 2014. [8] 刘复昌, 南博, 缪永伟. 基于显著性图的点云替换对抗攻击[J]. 中国图象图形学报, 2022, 27(2): 500–510. doi: 10.11834/jig.210546.LIU Fuchang, NAN Bo, and MIAO Yongwei. Point cloud replacement adversarial attack based on saliency map[J]. Journal of Image and Graphics, 2022, 27(2): 500–510. doi: 10.11834/jig.210546. [9] CAO Yulong, WANG Ningfei, XIAO Chaowei, et al. Invisible for both camera and LiDAR: Security of multi-sensor fusion based perception in autonomous driving under physical-world attacks[C]. 2021 IEEE Symposium on Security and Privacy (SP), San Francisco, USA, 2021: 176–194. doi: 10.1109/SP40001.2021.00076. [10] LIU Danlei, YU R, and SU Hao. Extending adversarial attacks and defenses to deep 3D point cloud classifiers[C]. 2019 IEEE International Conference on Image Processing (ICIP), Taipei, China, 2019: 2279–2283. doi: 10.1109/ICIP.2019.8803770. [11] ZHENG Shijun, LIU Weiquan, SHEN Siqi, et al. Adaptive local adversarial attacks on 3D point clouds[J]. Pattern Recognition, 2023, 144: 109825. doi: 10.1016/j.patcog.2023.109825. [12] HU Qianjiang, LIU Daizong, and HU Wei. Exploring the devil in graph spectral domain for 3D point cloud attacks[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 229–248. doi: 10.1007/978-3-031-20062-5_14. [13] ZHOU Hang, CHEN Dongdong, LIAO Jing, et al. LG-GAN: Label guided adversarial network for flexible targeted attack of point cloud based deep networks[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 10353–10362. doi: 10.1109/CVPR42600.2020.01037. [14] KURAKIN A, GOODFELLOW I J, and BENGIO S. Adversarial examples in the physical world[M]. YAMPOLSKIY R V. Artificial Intelligence Safety and Security. New York: Chapman and Hall/CRC, 2018: 99–112. [15] DONG Yinpeng, LIAO Fangzhou, PANG Tianyu, et al. Boosting adversarial attacks with momentum[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 9185–9193. doi: 10.1109/CVPR.2018.00957. [16] CHARLES R Q, SU Hao, KAICHUN M, et al. Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 77–85. doi: 10.1109/CVPR.2017.16. [17] QI C R, YI Li, SU Hao, et al. PointNet++: Deep hierarchical feature learning on point sets in a metric space[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 5105–5114. [18] WANG Yue, SUN Yongbin, LIU Ziwei, et al. Dynamic graph CNN for learning on point clouds[J]. ACM Transactions on Graphics, 2019, 38(5): 1–12. doi: 10.1145/3326362. [19] LANG A H, VORA S, CAESAR H, et al. PointPillars: Fast encoders for object detection from point clouds[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 12689–12697. doi: 10.1109/CVPR.2019.01298. [20] YANG Zetong, SUN Yanan, LIU Shu, et al. 3DSSD: Point-based 3D single stage object detector[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 11037–11045. doi: 10.1109/CVPR42600.2020.01105. [21] HE Chenhang, ZENG Hui, HUANG Jianqiang, et al. Structure aware single-stage 3D object detection from point cloud[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 11870–11879. doi: 10.1109/CVPR42600.2020.01189. [22] YIN Tianwei, ZHOU Xingyi, and KRÄHENBÜHL P. Center-based 3D object detection and tracking[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 11779–11788. doi: 10.1109/CVPR46437.2021.01161. [23] SHI Shaoshuai, GUO Chaoxu, JIANG Li, et al. PVRCNN: Point-voxel feature set abstraction for 3D object detection[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 10526–10535. doi: 10.1109/CVPR42600.2020.01054. [24] SHI Shaoshuai, JIANG Li, DENG Jiajun, et al. PV-RCNN++: Point-voxel feature set abstraction with local vector representation for 3D object detection[J]. International Journal of Computer Vision, 2023, 131(2): 531–551. doi: 10.1007/s11263-022-01710-9. [25] WU Zhirong, SONG Shuran, KHOSLA A, et al. 3D shapeNets: A deep representation for volumetric shapes[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA, 2015: 1912–1920. doi: 10.1109/CVPR.2015.7298801. [26] YI Li, KIM V G, CEYLAN D, et al. A scalable active framework for region annotation in 3D shape collections[J]. ACM Transactions on Graphics, 2016, 35(6): 210. doi: 10.1145/2980179.2980238. [27] UY M A, PHAM Q H, HUA B S, et al. Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019: 1588–1597. doi: 10.1109/ICCV.2019.00167. [28] GEIGER A, LENZ P, and URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 3354–3361. doi: 10.1109/CVPR.2012.6248074. [29] CAESAR H, BANKITI V, LANG A H, et al. nuScenes: A multimodal dataset for autonomous driving[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 11618–11628. doi: 10.1109/CVPR42600.2020.01164. [30] SUN Pei, KRETZSCHMAR H, DOTIWALLA X, et al. Scalability in perception for autonomous driving: Waymo open dataset[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 2443–2451. doi: 10.1109/CVPR42600.2020.00252. [31] GOODFELLOW I J, SHLENS J, and SZEGEDY C. Explaining and harnessing adversarial examples[C]. The 3rd International Conference on Learning Representations, San Diego, USA, 2015. [32] YANG Jiancheng, ZHANG Qiang, FANG Rongyao, et al. Adversarial attack and defense on point sets[EB/OL]. https://arxiv.org/abs/1902.10899, 2019. [33] MADRY A, MAKELOV A, SCHMIDT L, et al. Towards deep learning models resistant to adversarial attacks[C]. The 6th International Conference on Learning Representations, Vancouver, Canada, 2018. [34] LIU Danlei, YU R, and SU Hao. Adversarial shape perturbations on 3D point clouds[C]. European Conference on Computer Vision, Glasgow, UK, 2020: 88–104. doi: 10.1007/978-3-030-66415-2_6. [35] MA Chengcheng, MENG Weiliang, WU Baoyuan, et al. Efficient joint gradient based attack against SOR defense for 3D point cloud classification[C]. Proceedings of the 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 1819–1827. doi: 10.1145/3394171.3413875. [36] ZHENG Tianhang, CHEN Changyou, YUAN Junsong, et al. PointCloud saliency maps[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019: 1598–1606. doi: 10.1109/ICCV.2019.00168. [37] CARLINI N and WAGNER D. Towards evaluating the robustness of neural networks[C]. 2017 IEEE Symposium on Security and Privacy (SP), San Jose, USA, 2017: 39–57. doi: 10.1109/SP.2017.49. [38] XIANG Chong, QI C R, and LI Bo. Generating 3D adversarial point clouds[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 9128–9136. doi: 10.1109/CVPR.2019.00935. [39] WEN Yuxin, LIN Jiehong, CHEN Ke, et al. Geometry-aware generation of adversarial point Clouds[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(6): 2984–2999. doi: 10.1109/TPAMI.2020.3044712. [40] TSAI T, YANG Kaichen, HO T Y, et al. Robust adversarial objects against deep learning models[C]. Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, USA, 2020: 954–962. doi: 10.1609/aaai.v34i01.5443. [41] KIM J, HUA, B S, NGUYEN D T, et al. Minimal adversarial examples for deep learning on 3D point clouds[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 7777–7786. doi: 10.1109/ICCV48922.2021.00770. [42] ARYA A, NADERI H, and KASAEI S. Adversarial attack by limited point cloud surface modifications[C]. 2023 6th International Conference on Pattern Recognition and Image Analysis, Qom, Islamic Republic of Iran, 2023: 1–8. doi: 10.1109/IPRIA59240.2023.10147168. [43] ZHAO Yiren, SHUMAILOV I, MULLINS R, et al. Nudge attacks on point-cloud DNNs[EB/OL]. https://arxiv.org/abs/2011.11637, 2020. [44] TAN Hanxiao and KOTTHAUS H. Explainability-aware one point attack for point cloud neural networks[C]. 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, USA, 2023: 4570–4579. doi: 10.1109/WACV56688.2023.00456. [45] SHI Zhenbo, CHEN Zhi, XU Zhenbo, et al. Shape prior guided attack: Sparser perturbations on 3D point clouds[C]. Thirty-Sixth AAAI Conference on Artificial Intelligence, Waikoloa, USA, 2022: 8277–8285. doi: 10.1609/aaai.v36i8.20802. [46] LIU Binbin, ZHANG Jinlai, and ZHU Jihong. Boosting 3D adversarial attacks with attacking on frequency[J]. IEEE Access, 2022, 10: 50974–50984. doi: 10.1109/ACCESS.2022.3171659. [47] LIU Daizong, HU Wei, and LI Xin. Point cloud attacks in graph spectral domain: When 3D geometry meets graph signal processing[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(5): 3079–3095. doi: 10.1109/TPAMI.2023.3339130. [48] TAO Yunbo, LIU Daizong, ZHOU Pan, et al. 3DHacker: Spectrum-based decision boundary generation for hard-label 3D point cloud attack[C]. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 14294–14304. doi: 10.1109/ICCV51070.2023.01319. [49] HUANG Qidong, DONG Xiaoyi, CHEN Dongdong, et al. Shape-invariant 3D adversarial point clouds[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 15314–15323. doi: 10.1109/CVPR52688.2022.01490. [50] LIU Daizong and HU Wei. Imperceptible transfer attack and defense on 3D point cloud classification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(4): 4727–4746. doi: 10.1109/TPAMI.2022.3193449. [51] HAMDI A, ROJAS S, THABET A, et al. AdvPC: Transferable adversarial perturbations on 3D point clouds[C]. The 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 2020: 241–257. doi: 10.1007/978-3-030-58610-2_15. [52] TANG Keke, SHI Yawen, WU Jianpeng, et al. NormalAttack: Curvature-aware shape deformation along normals for imperceptible point cloud attack[J]. Security and Communication Networks, 2022, 2022: 1186633. doi: 10.1155/2022/1186633. [53] TU J, REN Mengye, MANIVASAGAM S, et al. Physically realizable adversarial examples for LiDAR object detection[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 13713–13722. doi: 10.1109/CVPR42600.2020.01373. [54] ABDELFATTAH M, YUAN Kaiwen, WANG Z J, et al. Adversarial attacks on camera-LiDAR models for 3D car detection[C]. 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 2021: 2189–2194. doi: 10.1109/IROS51168.2021.9636638. [55] MIAO Yibo, DONG Yinpeng, ZHU Jun, et al. Isometric 3D adversarial examples in the physical world[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1433. [56] YANG Kaichen, TSAI T, YU Honggang, et al. Robust roadside physical adversarial attack against deep learning in Lidar perception modules[C]. The 2021 ACM Asia Conference on Computer and Communications Security, Hong Kong, China, 2021: 349–362. doi: 10.1145/3433210.3453106. [57] ZHU Yi, MIAO Chenglin, ZHENG Tianhang, et al. Can we use arbitrary objects to attack LiDAR perception in autonomous driving?[C/OL]. The 2021 ACM SIGSAC Conference on Computer and Communications Security, 2021: 1945–1960. doi: 10.1145/3460120.3485377. [58] CAO Yulong, BHUPATHIRAJU S H, NAGHAVI P, et al. You can’t see me: Physical removal attacks on LiDAR-based autonomous vehicles driving frameworks[C]. The 32nd USENIX Security Symposium, USENIX Security 2023, Anaheim, USA, 2023. [59] CAO Yulong, XIAO Chaowei, CYR B, et al. Adversarial sensor attack on LiDAR-based perception in autonomous driving[C]. The 2019 ACM SIGSAC Conference on Computer and Communications Security, London, United Kingdom, 2019: 2267–2281. doi: 10.1145/3319535.3339815. [60] SUN Jiachen, CAO Yulong, CHEN Q A, et al. Towards robust LiDAR-based perception in autonomous driving: General black-box adversarial sensor attack and countermeasures[C/OL]. The 29th USENIX Security Symposium, USENIX Security 2020, 2020. -


 下载:
下载:



图(6) / 表(1)
计量
- 文章访问数: 2033
- HTML全文浏览量: 1559
- PDF下载量: 206
- 被引次数: 0
