

Multi-Scale Attention Recurrent Network with Multi-order Taylor Differential Knowledge for Deep Spatiotemporal Sequence Prediction
-
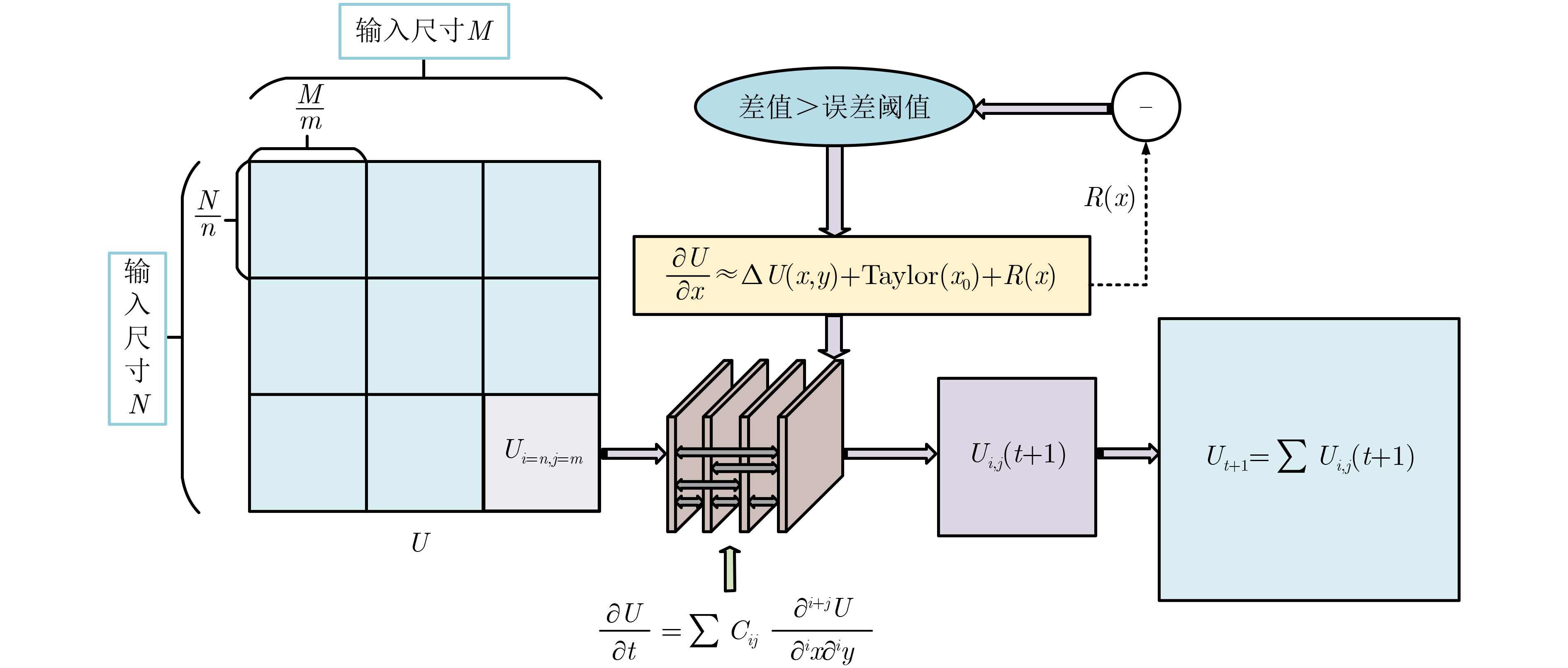
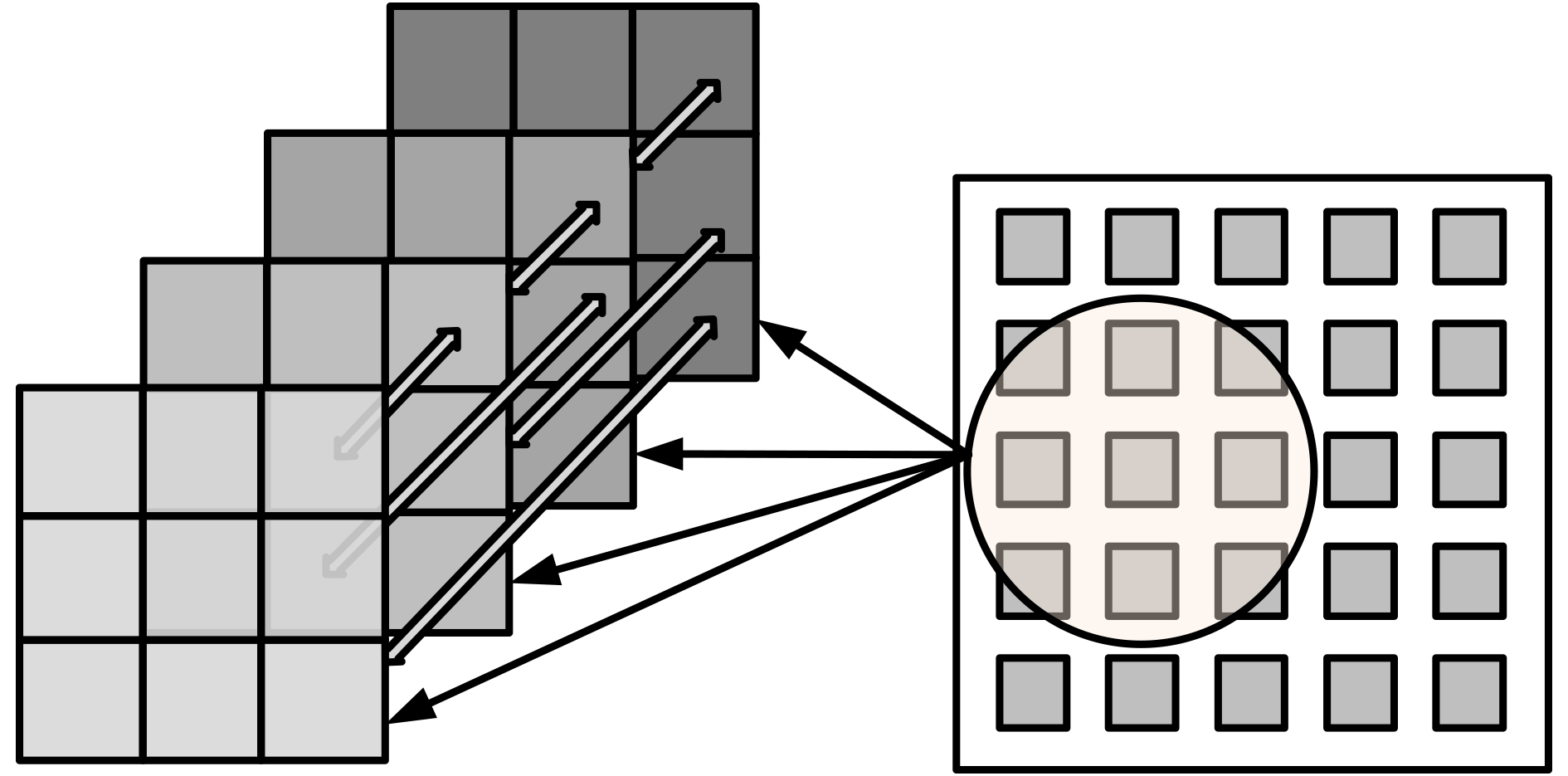
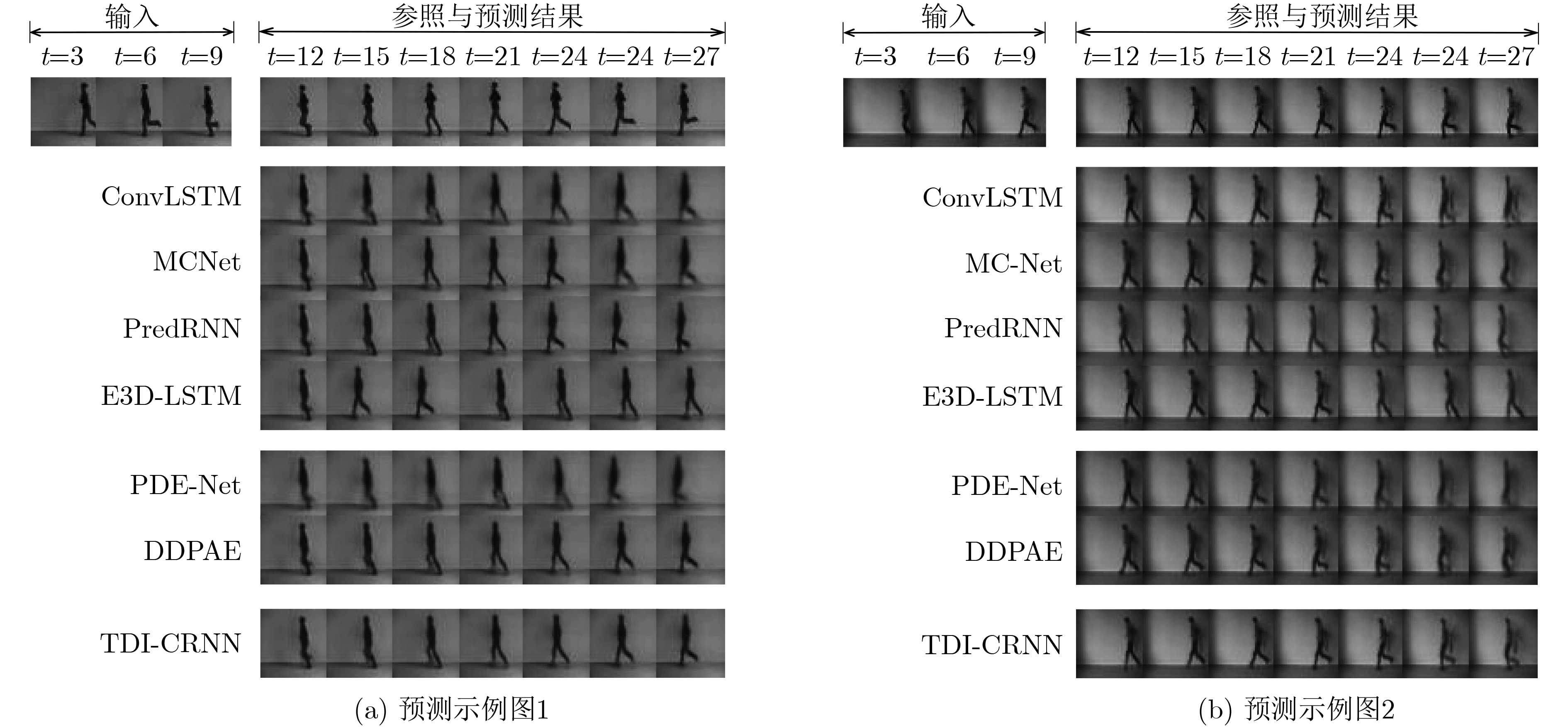
摘要: 融合先验物理知识的深度时空序列预测方法通常使用偏微分方程(PDE)进行建模,这种做法通常存在两大问题:(1)偏微分方程的近似精度低;(2)无法在循环网络中有效捕捉多种空间尺度的时空特征和时空序列的边缘相关空间信息。为此,该文提出了融合泰勒微分的卷积循环神经网络(TDI-CRNN)。首先,为了提高高阶偏微分方程的近似精度并缓解偏微分方程应用的局限性,设计了一种多阶泰勒近似物理模块。该模块首先使用泰勒展开式对输入序列作微分逼近,再将不同阶数之间的微分卷积层使用微分系数耦合,最后动态调整泰勒展开结果的截断阶数与微分项数。其次,为了捕获循环网络隐藏状态的多种空间尺度特征并更好地捕捉时空序列的边缘相关空间信息,设计了一种多尺度注意力循环模块(MSARM),在该模块的多尺度卷积空间注意力UNet(即MCSA-UNet)的卷积层中使用了多尺度卷积和空间注意力机制,目的是关注时空序列的局部空间区域。在Moving MNIST, KTH以及CIKM数据集上开展了大量实验,Moving MNIST数据集的均方误差(MSE)指标下降到42.7,结构相似性指数(SSIM)提高到0.912;KTH数据集的SSIM和峰值信噪比(PSNR)分别提高到0.882和29.03;CIKM数据集上的临界成功指数(CSI)提高到0.515。最终的可视化和定量预测结果均验证了TDI-CRNN模型的合理性和有效性。Abstract: Deep spatiotemporal sequence prediction methods that incorporate a priori physical knowledge are commonly characterized by the utilization of Partial Differential Equations (PDE) for modeling. However, two main issues are concerned: (1) the limited precision in approximations with PDEs; and (2) the inability to efficiently capture spatiotemporal features at multiple spatial scales as well as the edge spatial information of the spatiotemporal sequences in the recurrent network. To address these challenges, one Taylor Differential Incorporated Convolutional Recurrent Neural Network (TDI-CRNN) is proposed in this paper. Firstly, in order to enhance the approximation accuracy of higher-order partial differential equations and to alleviate the limitations of PDE applications, one physical module with multi-order Taylor approximation is designed. The module is firstly used for the differential approximation of the input sequence by means of the Taylor expansion, and then couples the differential convolution layers with different orders via differential coefficients, and dynamically adjusts the truncation order and the number of differential terms of the Taylor expansions. Secondly, to capture the multiple spatial scale features of the hidden states in the recurrent network and to better capture the edge spatial information of the spatiotemporal sequences, one Multi-Scale Attention Recurrent Module (MSARM) is devised. Multi-scale convolution and spatial attention mechanisms are utilized in the convolution layer of the Multi-scale Convolution Spatial Attention UNet (MCSA-UNet), aiming to focus on local spatial regions within spatiotemporal sequences. Extensive experiments are conducted on the Moving MNIST, KTH, and CIKM datasets. The Mean Squared Error (MSE) on the Moving MNIST dataset dropped to 42.7, while the Structural Similarity Index Measure (SSIM) increased to 0.912. The SSIM and Peak Signal-to-Noise Ratio (PSNR) on the KTH dataset increased to 0.882 and 29.03, respectively. The Correct Skill Index (CSI) on the real weather radar echo CIKM dataset increased to 0.515. The final visualization and quantitative prediction results verify the rationality and effectiveness of the TDI-CRNN model.
-
表 1 数据驱动的预测模型
类别 模型内涵 模型名称 模型思想 基于门控机制或堆叠方式的改进模型 ConvLSTM[5] 提出使用卷积运算代替LSTM中的普通乘法运算 Conv-TT-LSTM[8] 提出了高阶卷积LSTM PredRNN[9] 使用共享输出门实现无缝的记忆融合 MIM[12] 提出的网络能够同时捕捉平稳信息和非平稳信息 E3D-LSTM[26] 将三维卷积集成到循环网络中 ZNet[27] 提出新的堆叠方式,隐藏状态沿Z曲线更新 IM-LSTM[28] 设计了SIM模块,用于更新隐藏状态 DFN[29] 生成动态卷积学习,以实现自适应特征提取 使用编码器-解码器架构的模型 MCNet[30] 在编码器-解码器以及ConvLSTM上进行预测 STMFANet[31] 提出空间小波分析模块,统一处理时空信息 FRNN[32] 堆叠多个循环单元层,得到自动编码器 引入注意力机制的模型 SA-ConvLSTM[7] 加入自注意机制,捕获长程空间依赖关系 CSAConvLSTM[33] 加入自注意力机制,捕获全局时空特征  下载: 导出CSV
下载: 导出CSV
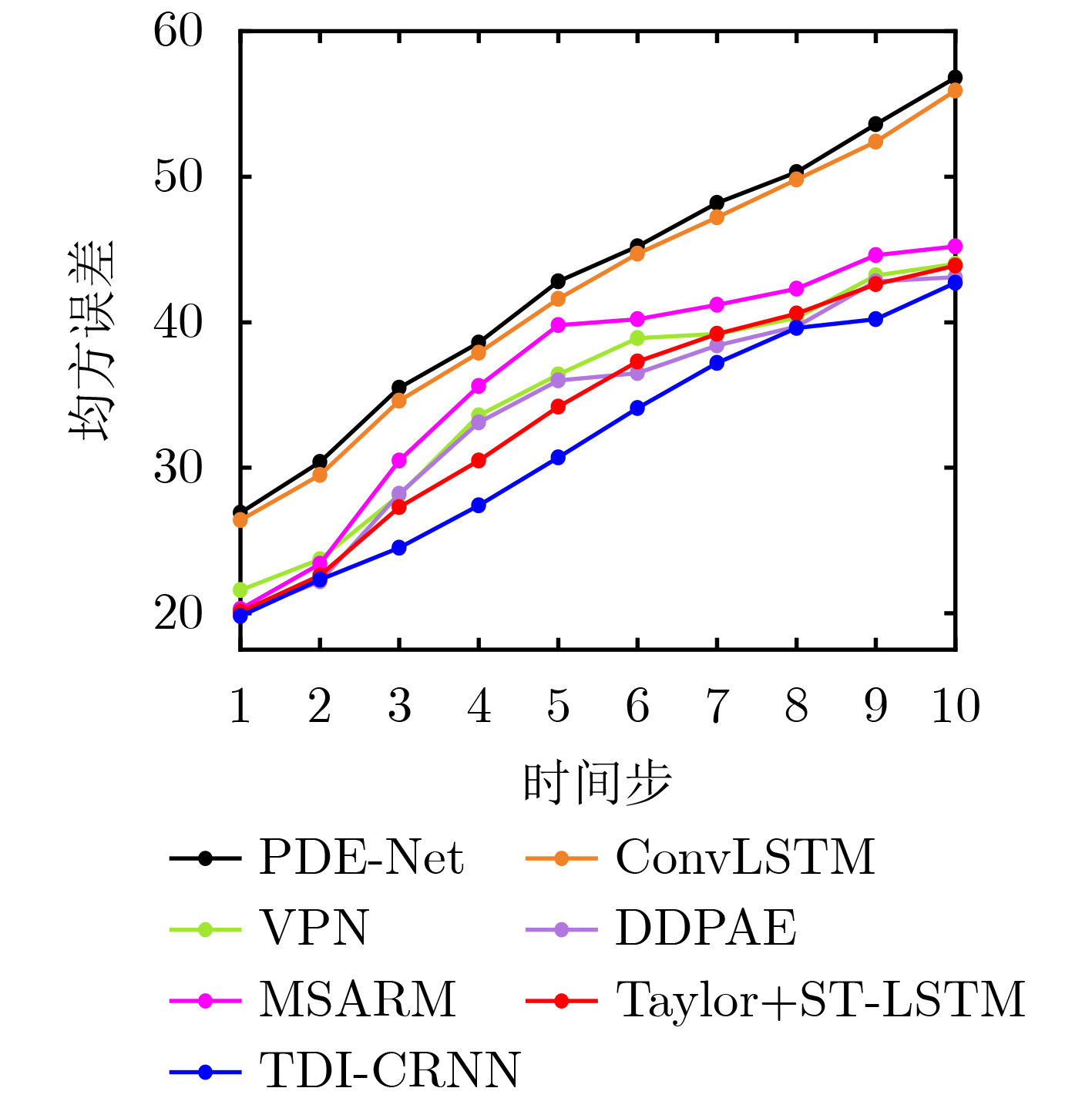
表 3 Moving MNIST数据集上的实验结果(10个时间步上的平均预测结果)
模型 SSIM↑ $ \varDelta $ MSE↓ $ \varDelta $ ConvLSTM[5]* 0.707 – 103.3 – IM-LSTM[28]* 0.876 +0.169 67.4 –35.9 PredRNN[9]* 0.867 +0.160 56.8 –46.5 Conv-TT-LSTM[8]* 0.905 +0.198 53.0 –50.3 MIM[12]* 0.901 +0.194 44.2 –59.1 SA-ConvLSTM[7]* 0.903 +0.196 43.9 –59.4 LMC-memory[34]* 0.904 +0.197 42.9 –60.4 PDE-Net[16]· 0.621 –0.086 160.2 +56.9 CDNA[19]· 0.721 +0.014 97.4 –5.9 VPN[22]· 0.870 +0.163 70.2 –33.1 DDPAE[18]· 0.905 +0.198 43.5 –59.8 MSARM(4层)× 0.873 +0.166 43.9 –59.4 Taylor+ST-LSTM(4层)× 0.893 +0.186 44.2 –59.1 TDI-CRNN 0.912 +0.205 42.7 –60.6
下载: 导出CSV
表 4 不同泰勒截断阶数和微分项数对模型性能的影响
微分项数 截断阶数 2 3 4 3阶 MSE=45.80
SSIM=0.886MSE=44.31
SSIM=0.892MSE=45.26
SSIM=0.8844阶 MSE=43.77
SSIM=0.902MSE=42.71
SSIM=0.910MSE=43.54
SSIM=0.8975阶 MSE=46.27
SSIM=0.886MSE=43.54
SSIM=0.898MSE=46.514
SSIM=0.880
下载: 导出CSV
表 5 KTH数据集的实验结果(20个时间步上的平均预测结果)
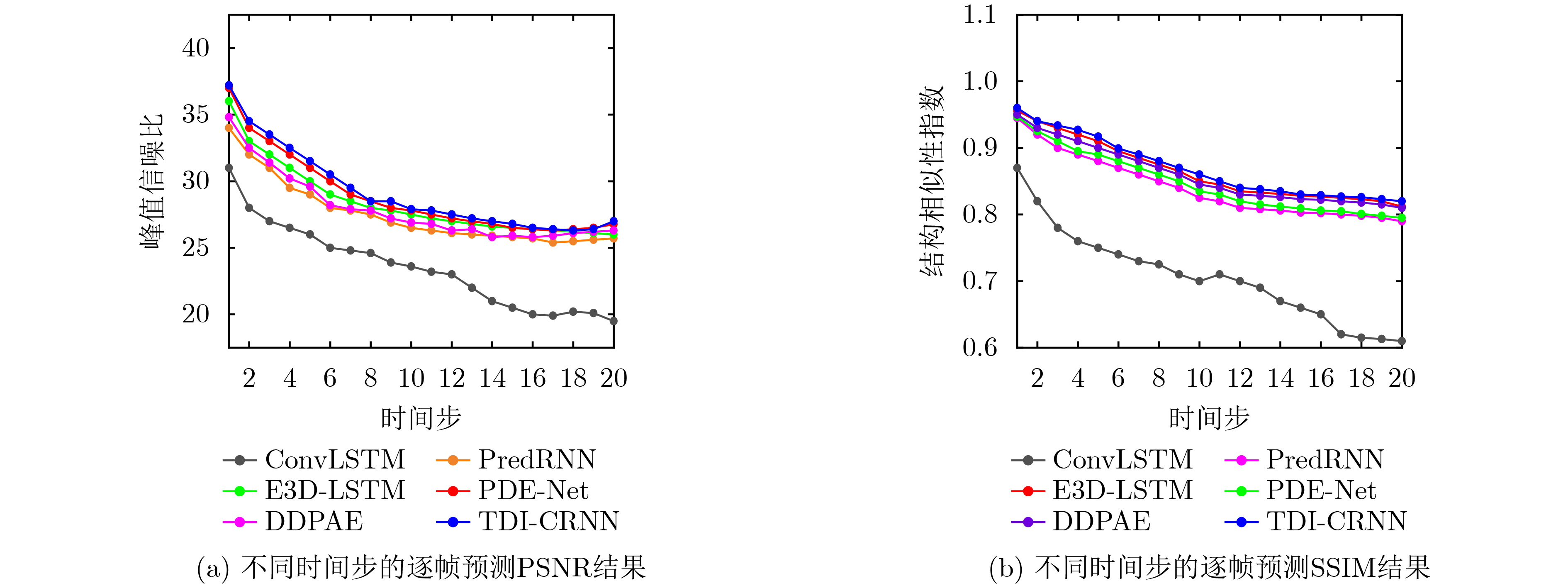
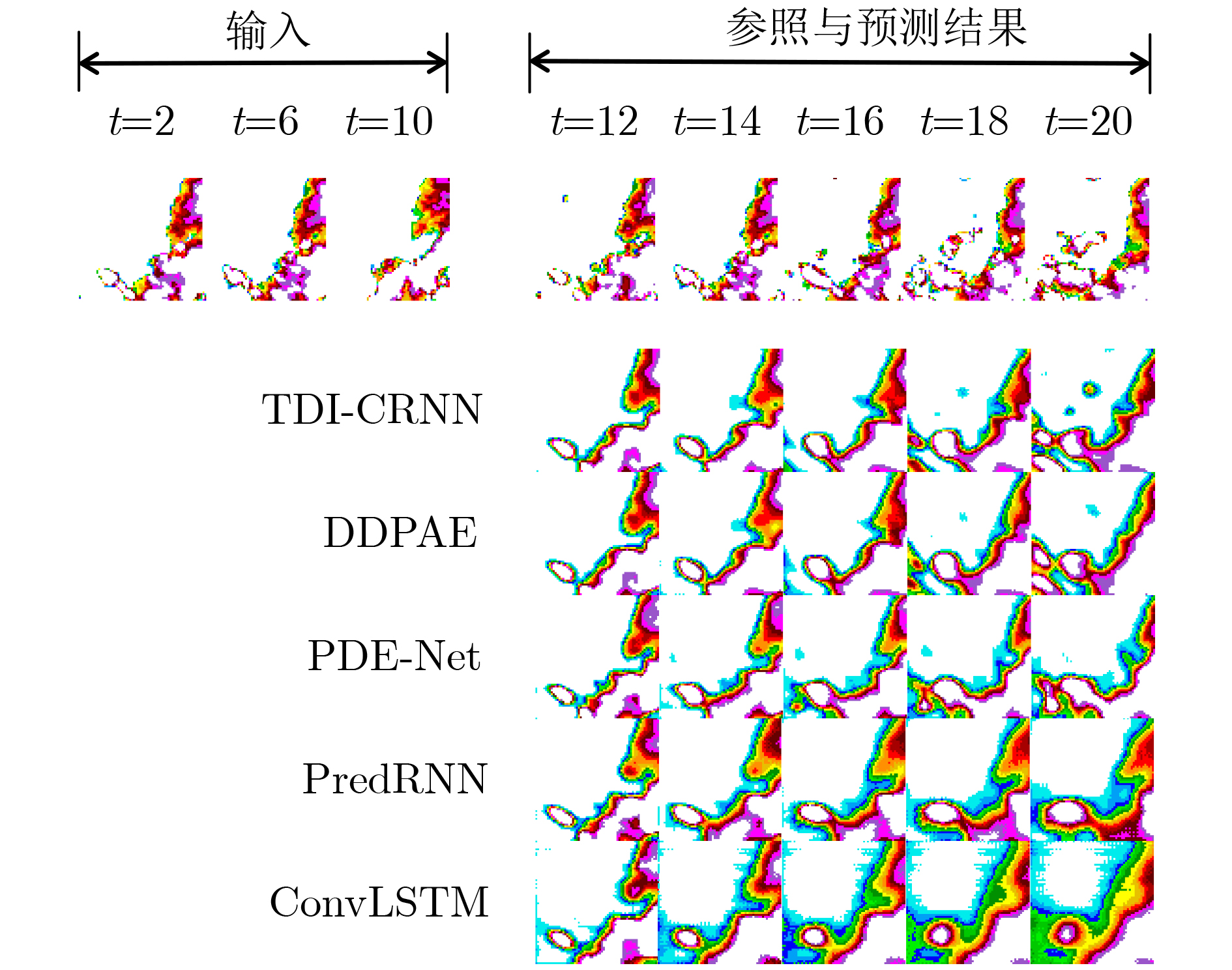
模型 SSIM↑ $ \varDelta $ PSNR (dB)↑ $ \varDelta $ ConvLSTM[5]* 0.712 — 23.58 — FRNN[32]* 0.771 +0.059 26.12 +2.54 DFN[29]* 0.794 +0.082 27.26 +3.68 ZNet[27]* 0.817 +0.105 27.58 +4.00 MCNet[30]* 0.804 +0.092 25.95 +2.37 PredRNN[9]* 0.839 +0.127 27.55 +3.97 CSAConvLSTM[33]* 0.840 +0.128 27.91 +4.33 STMFANet[31]* 0.851 +0.139 27.24 +3.66 E3D-LSTM[26]* 0.879 +0.167 29.31 +5.73 PDE-Net[16]· 0.662 –0.05 22.45 –1.13 DDPAE[18]· 0.845 +0.133 28.42 +4.84 TDI-CRNN 0.882 +0.170 29.03 +5.45
下载: 导出CSV
表 6 CIKM雷达回波数据集在十个时间步上的平均预测结果
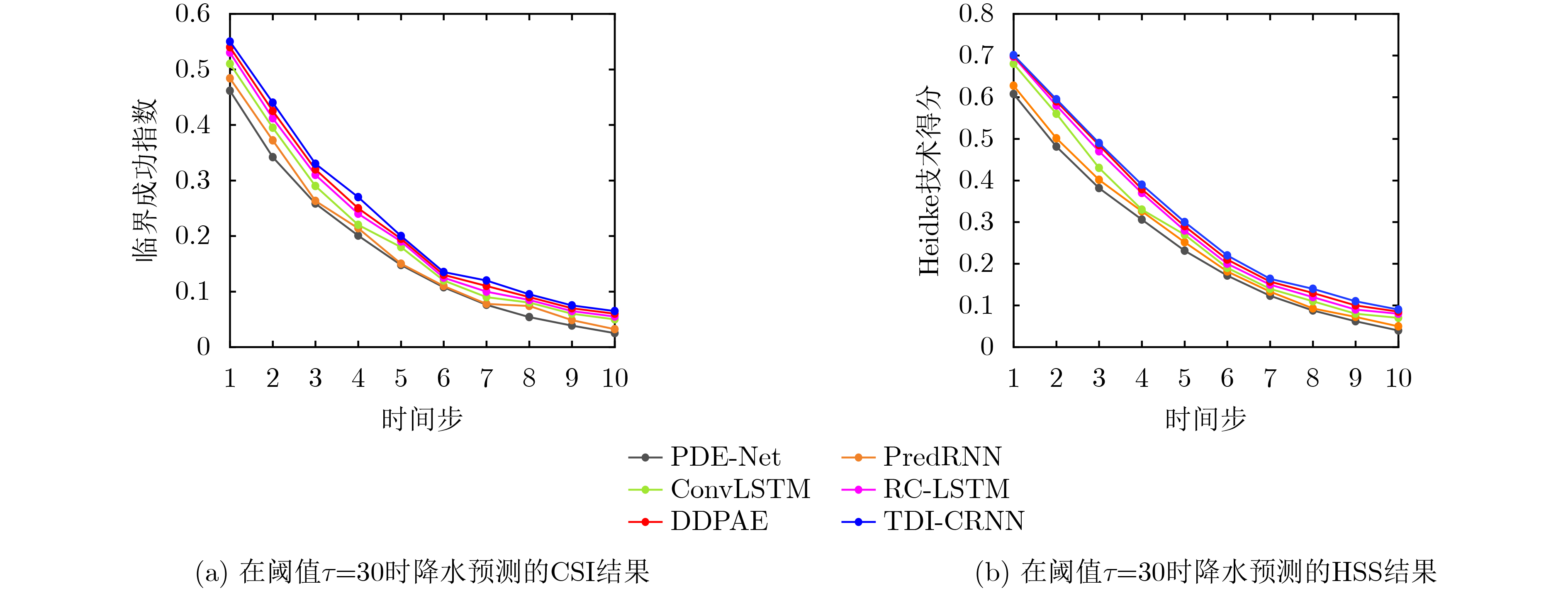
模型 HSS↑ CSI↑ MSE↓ $\tau \ge 5$ $\tau \ge 15$ $\tau \ge 30$ 平均值 $ \varDelta $ $\tau \ge 5$ $\tau \ge 15$ $\tau \ge 30$ 平均值 $ \varDelta $ $ \varDelta $ ConvLSTM[5]* 0.662 0.569 0.272 0.501 — 0.743 0.557 0.185 0.495 — 94.7 — PredRNN[9]* 0.678 0.571 0.281 0.508 +0.007 0.755 0.569 0.199 0.508 +0.013 104.1 +9.3 RC-LSTM[34]* 0.682 0.580 0.288 0.513 +0.012 0.761 0.571 0.225 0.509 +0.014 88.2 –9.2 PDE-Net[16]· 0.664 0.574 0.275 0.503 +0.002 0.749 0.558 0.192 0.501 +0.006 78.6 –16.1 Advection-diffusion[21]· 0.679 0.579 0.288 0.509 +0.008 0.759 0.571 0.209 0.510 +0.015 55.4 –39.3 DDPAE[18]· 0.682 0.581 0.291 0.514 +0.013 0.764 0.572 0.227 0.512 +0.017 43.2 –51.5 TDI-CRNN 0.685 0.582 0.293 0.516 +0.015 0.767 0.578 0.260 0.515 +0.02 36.8 –57.9
下载: 导出CSV
-
[1] 刘博, 王明烁, 李永, 等. 深度学习在时空序列预测中的应用综述[J]. 北京工业大学学报, 2021, 47(8): 925–941. doi: 10.11936/bjutxb2020120037.LIU Bo, WANG Mingshuo, LI Yong, et al. Deep learning for spatio-temporal sequence forecasting: A survey[J]. Journal of Beijing University of Technology, 2021, 47(8): 925–941. doi: 10.11936/bjutxb2020120037. [2] 周康辉. 基于深度卷积神经网络的强对流天气预报方法研究[D]. [博士论文], 中国气象科学研究院, 2021. doi: 10.27631/d.cnki.gzqky.2021.000006.ZHOU Kanghui. Convective weather forecasting with convolutional neural networks[D]. [Ph. D. dissertation], Chinese Academy of Meteorological Sciences, 2021. doi: 10.27631/d.cnki.gzqky.2021.000006. [3] 杨函. 基于深度学习的气象预测研究[D]. [硕士论文], 哈尔滨工业大学, 2017.YANG Han. Research on weather forecasting based on deep learning[D]. [Master dissertation], Harbin Institute of Technology, 2017. [4] 徐成鹏, 曹勇, 张恒德, 等. U-Net模型在京津冀临近降水预报中的应用和检验评估[J]. 气象科学, 2022, 42(6): 781–792. doi: 10.12306/2022jms.0078.XU Chengpeng, CAO Yong, ZHANG Hengde, et al. Application and test evaluation of U-Net model in Beijing-Tianjin-Hebei precipitation nowcasting[J]. Journal of the Meteorological Sciences, 2022, 42(6): 781–792. doi: 10.12306/2022jms.0078. [5] SHI Xingjian, CHEN Zhourong, WANG Hao, et al. Convolutional LSTM network: A machine learning approach for precipitation nowcasting[C]. The 28th International Conference on Neural Information Processing Systems, Montreal, Canada, 2015: 802–810. [6] SHI Xingjian, GAO Zhihan, LAUSEN L, et al. Deep learning for precipitation nowcasting: A benchmark and a new model[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 5622–5632. [7] LIN Zhihui, LI Maomao, ZHENG Zhuobin, et al. Self-attention ConvLSTM for spatiotemporal prediction[C]. The Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, USA, 2020: 11531–11538. doi: 10.1609/aaai.v34i07.6819. [8] SU Jiahao, BYEON W, KOSSAIFI J, et al. Convolutional tensor-train LSTM for spatio-temporal learning[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1150. [9] WANG Yunbo, WU Haixu, ZHANG Jianjin, et al. PredRNN: A recurrent neural network for spatiotemporal predictive learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 2208–2225. doi: 10.1109/TPAMI.2022.3165153. [10] WANG Yunbo, GAO Zhifeng, LONG Mingsheng, et al. PredRNN++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning[C]. The 35th International Conference on Machine Learning, Stockholm, Sweden, 2018: 5123–5132. [11] WU Haixu, YAO Zhiyu, WANG Jianmin, et al. MotionRNN: A flexible model for video prediction with spacetime-varying motions[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 15430–15439. doi: 10.1109/CVPR46437.2021.01518. [12] WANG Yunbo, ZHANG Jianjin, ZHU Hongyu, et al. Memory in memory: A predictive neural network for learning higher-order non-stationarity from spatiotemporal dynamics[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 9146–9154. doi: 10.1109/CVPR.2019.00937. [13] 王杨刚, 郝丽荣, 黄辉, 等. 基于空间数据和专家知识驱动的地质编图技术研究与应用[J]. 地质通报, 2019, 38(12): 2067–2076. doi: 10.12097/j.issn.1671-2552.2019.12.015.WANG Yanggang, HAO Lirong, HUANG Hui, et al. Research on geological map compilation technology based on spatial data and geological knowledge[J]. Geological Bulletin of China, 2019, 38(12): 2067–2076. doi: 10.12097/j.issn.1671-2552.2019.12.015. [14] 毛超利. 基于深度学习的偏微分方程求解方法[J]. 智能物联技术, 2021, 53(5): 18–23,30.MAO Chaoli. A method for solving partial differential equations based on deep learning[J]. Technology of IoT & AI, 2021, 53(5): 18–23,30. [15] 金哲, 张引, 吴飞, 等. 数据驱动与知识引导结合下人工智能算法模型[J]. 电子与信息学报, 2023, 45(7): 2580–2594. doi: 10.11999/JEIT220700.JIN Zhe, ZHANG Yin, WU Fei, et al. Artificial intelligence algorithms based on data-driven and knowledge-guided models[J]. Journal of Electronics & Information Technology, 2023, 45(7): 2580–2594. doi: 10.11999/JEIT220700. [16] LONG Zichao, LU Yiping, MA Xianzhong, et al. PDE-Net: Learning PDEs from data[C]. The 35th International Conference on Machine Learning, Stockholm, Sweden, 2018: 3208–3216. [17] LE GUEN V and THOME N. Disentangling physical dynamics from unknown factors for unsupervised video prediction[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 11471–11481. doi: 10.1109/CVPR42600.2020.01149. [18] HSIEH J T, LIU Bingbin, HUANG Dean, et al. Learning to decompose and disentangle representations for video prediction[C]. The 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, 2018: 515–524. [19] FINN C, GOODFELLOW I, and LEVINE S. Unsupervised learning for physical interaction through video prediction[C]. The 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 2016: 64–72. [20] REN Pu, RAO Chengping, YANG Liu, et al. PhyCRNet: Physics-informed convolutional-recurrent network for solving spatiotemporal PDEs[J]. Computer Methods in Applied Mechanics and Engineering, 2022, 389: 114399. doi: 10.1016/j.cma.2021.114399. [21] DE BÉZENAC E, PAJOT A, and GALLINARI P. Deep learning for physical processes: Incorporating prior scientific knowledge[J]. Journal of Statistical Mechanics: Theory and Experiment, 2019, 2019: 124009. doi: 10.1088/1742-5468/ab3195. [22] KALCHBRENNER N, VAN DEN OORD A, SIMONYAN K, et al. Video pixel networks[C]. The 34th International Conference on Machine Learning, Sydney, Australia, 2017: 1771–1779. [23] SRIVASTAVA N, MANSIMOV E, and SALAKHUTDINOV R. Upervised learning of video representations using LSTMs[C]. The 32nd International Conference on International Conference on Machine Learning, Lille, France, 2015: 843–852. [24] SCHULDT C, LAPTEV I, and CAPUTO B. Recognizing human actions: A local SVM approach[C]. The 17th International Conference on Pattern Recognition, Cambridge, UK, 2004: 32–36. doi: 10.1109/ICPR.2004.1334462. [25] 阿里巴巴天池大赛, CIKM AnalytiCup2017短时定量降水预测数据[EB/OL].https://tianchi.aliyun.com/dataset/1085.2018. [26] WANG Yunbo, LU Jiang, YANG M H, et al. Eidetic 3D LSTM: A model for video prediction and beyond[C]. The 7th International Conference on Learning Representations, New Orleans, USA, 2019: 1–14. [27] ZHANG Jianjin, WANG Yunbo, LONG Mingsheng, et al. Z-Order recurrent neural networks for video prediction[C]. 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 2019: 230–235. doi: 10.1109/ICME.2019.00048. [28] LIU Guixin and MA Zhonghua. Prediction of spatiotemporal sequence based on IM-LSTM[C]. 2022 2nd International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI), Nanjing, China, 2022: 247–250. doi: 10.1109/CEI57409.2022.9950135. [29] DE BRABANDERE B, JIA Xu, TUYTELAARS T, et al. Dynamic filter networks[C]. The 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 2016: 667–675. [30] VILLEGAS R, YANG Jimei, HONG S, et al. Decomposing motion and content for natural video sequence prediction[C]. 5th International Conference on Learning Representations, Toulon, France, 2017. [31] JIN Beibei, HU Yu, TANG Qiankun, et al. Exploring spatial-temporal multi-frequency analysis for high-fidelity and temporal-consistency video prediction[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 4553–4562. doi: 10.1109/CVPR42600.2020.00461. [32] OLIU M, SELVA J, and ESCALERA S. Folded recurrent neural networks for future video prediction[C]. 15th European Conference on Computer Vision, Munich, Germany, 2018: 745–761. doi: 10.1007/978-3-030-01264-9_44. [33] XIONG Taisong, HE Jianxing, WANG Hao, et al. Contextual Sa-attention convolutional LSTM for precipitation nowcasting: A spatiotemporal sequence forecasting view[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 12479–12491. doi: 10.1109/JSTARS.2021.3128522. [34] LEE S, KIM H G, CHOI D H, et al. Video prediction recalling long-term motion context via memory alignment learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 3053–3062. doi: 10.1109/CVPR46437.2021.00307. -

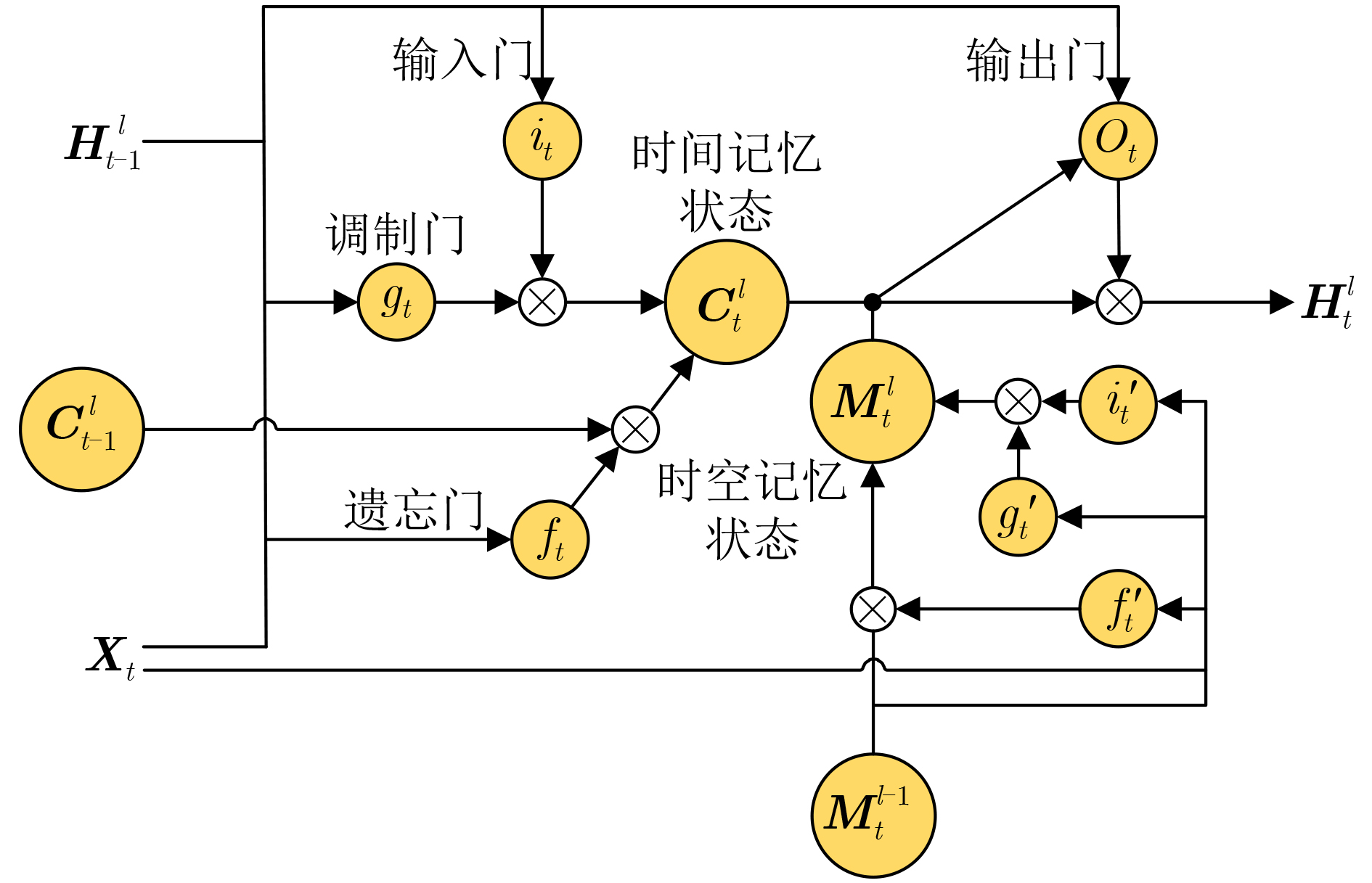
 下载:
下载:
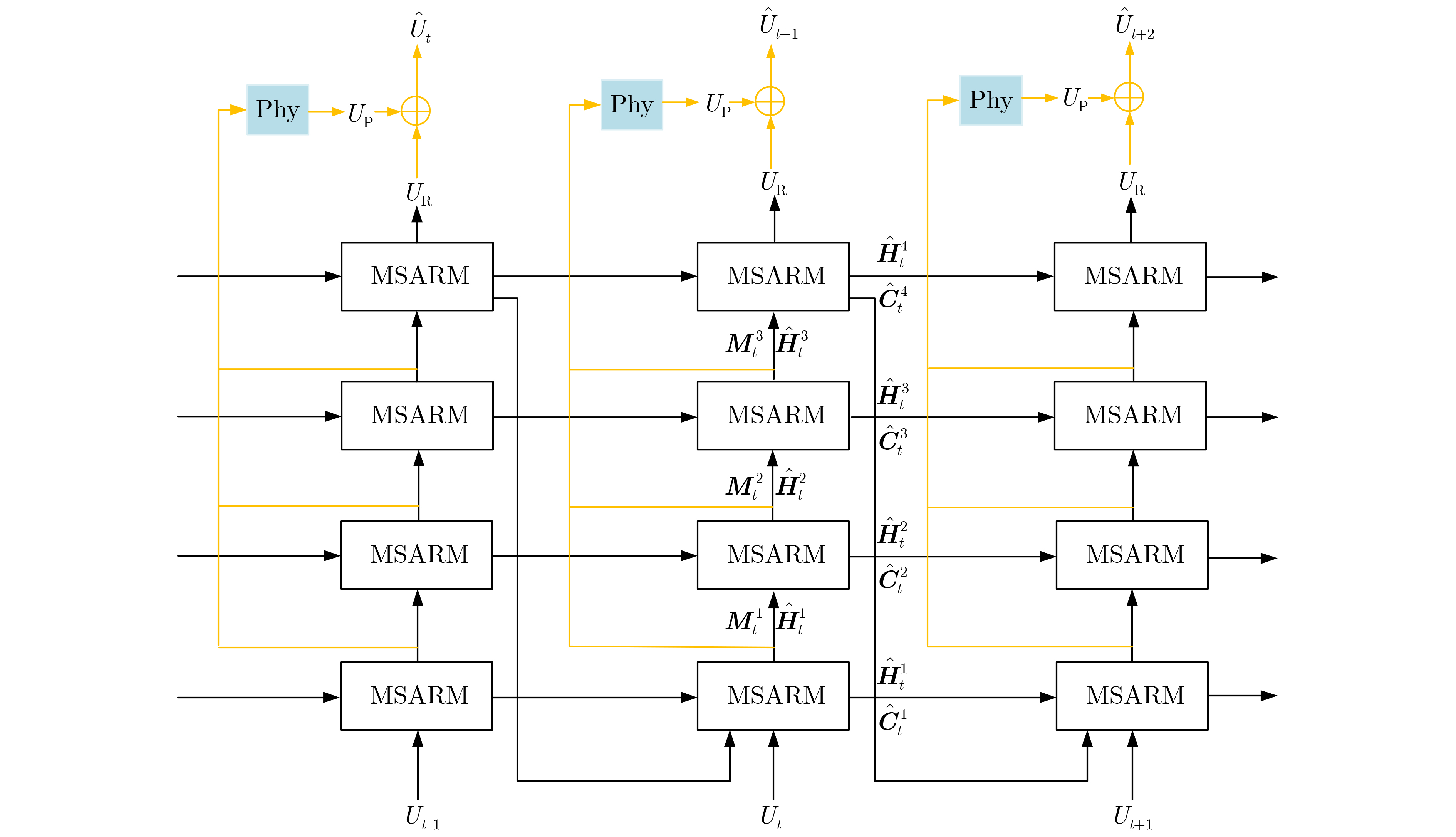
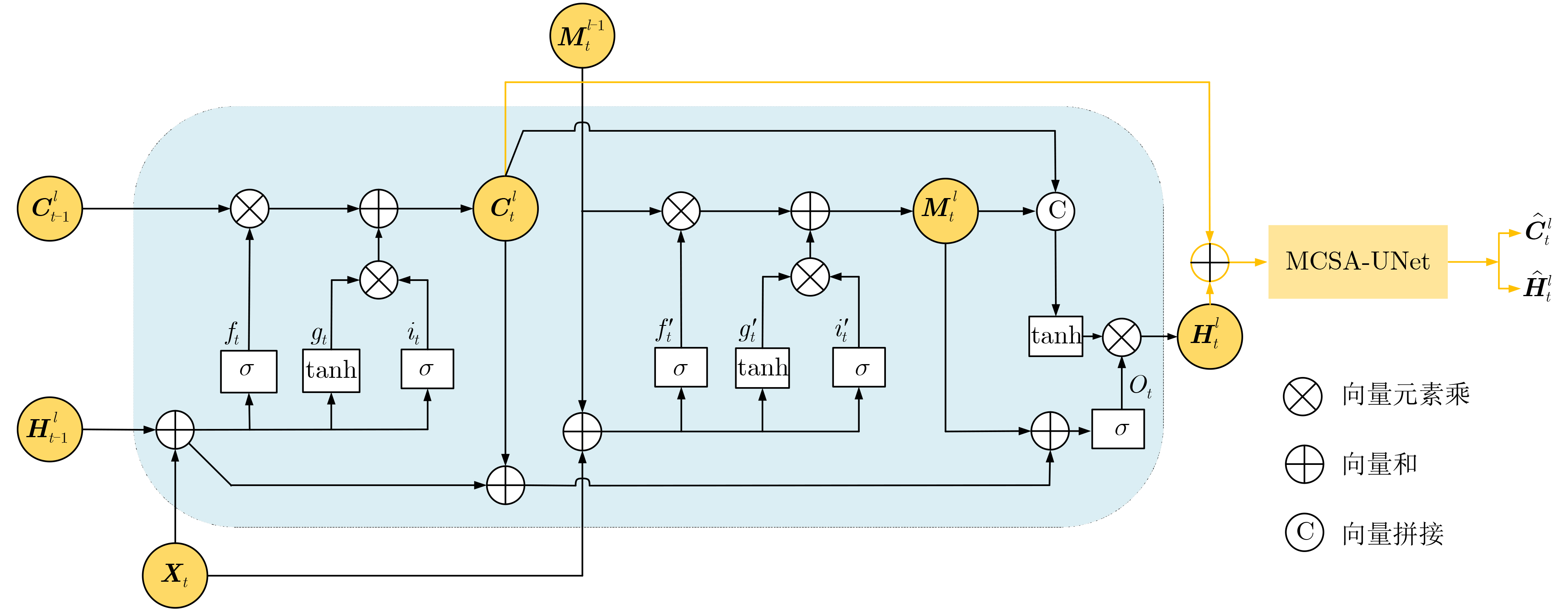
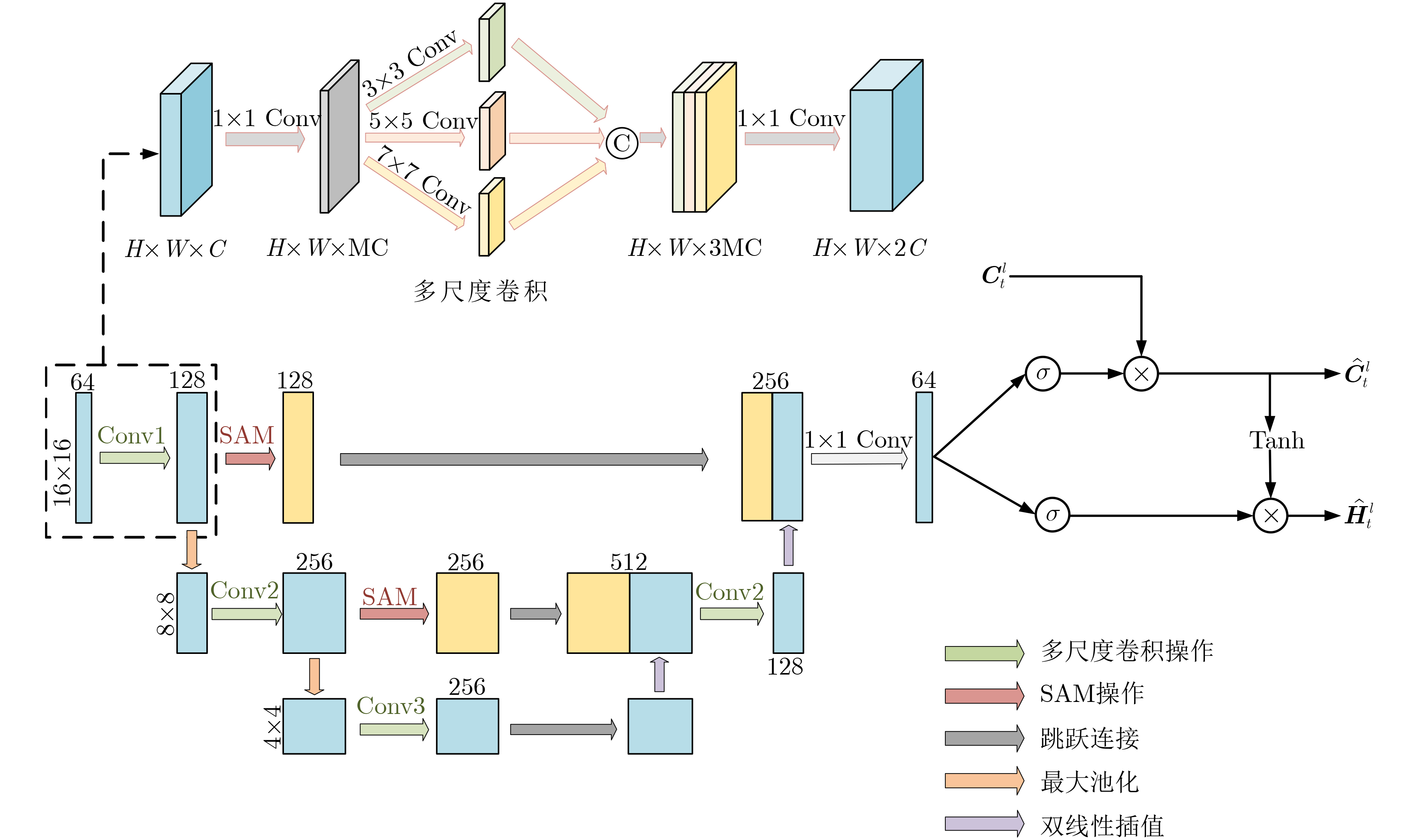



图(12) / 表(6)
计量
- 文章访问数: 1422
- HTML全文浏览量: 839
- PDF下载量: 93
- 被引次数: 0
